서브루틴, 프로시저, 함수로 대표되는 비지역적 제어 개념을 소개하고, 인자 전달 방식, 재귀와 재진입성, 중첩과 유효범위, 변수 수명, 일급 함수와 클로저, 호출 전후의 제어 흐름(다중 반환, 비지역 goto, 예외)을 이론과 구현 전략(정적 할당, 스택 프레임, 접근 링크, 힙 할당 클로저/객체) 관점에서 설명한다.



많은 프로그램은 일부 연산을 두 번 이상 수행한다. 예를 들어, 계산기하 응용은 여러 개의 2차 방정식을 풀어야 할 수 있다. 다음의 코드를 한 번만 작성해두고, 2차 방정식을 풀어야 할 때마다 간단히 “호출”하려면 어떻게 해야 할까?
D = SQRT(BB - 4AC) X1 = (-B - D) / (2A) X2 = (-B + D) / (2*A)
옛날에는 프로그램을 “루틴(routine)”이라 불렀고, 따라서 재사용 가능한 코드 조각을 자연스럽게 “서브루틴(subroutine)”, 나중에는 “서브프로그램(subprogram)”이라 불렀다.
어셈블리 언어의 서브루틴. “계산된 점프(computed jump)” 명령이 있는 언어라면 어디서든 서브루틴을 구현할 수 있다. 예를 들어, 다음은 2차 방정식을 푸는 서브루틴의 개요를 어셈블리로 쓴 것이다:
; 2차 방정식 AX^2 + BX + C = 0 해 구하기
; 입력: r1에 A, r2에 B, r3에 C, r4에 복귀 주소
; 출력: 해를 r1, r2에 저장
quadratic:
mul r5, r2, r2 ; 해 계산
...
jmp r4 ; 호출자에게 복귀
세 매개변수 A, B, C에 더해, 이 서브루틴은 네 번째 매개변수로 서브루틴이 끝났을 때 점프해야 할 코드 주소(복귀 주소)를 받는다. 서브루틴의 각 호출은 점프하기 전에 이 복귀 주소를 설정한다:
mov r4, L100 ; 복귀 주소 설정
jmp quadratic ; 서브루틴 호출
L100: ... ; 여기서부터 실행 재개
대부분의 명령어 집합은 호출 시 다음 명령의 주소를 레지스터나 스택에 저장하면서 주어진 코드 주소로 점프하는 call 명령을 제공한다. 단일 call 명령으로 서브루틴을 호출할 수 있다:
call quadratic, r4 ; 첫 번째 호출
... ; 여기서부터 실행 재개
...
call quadratic, r4 ; 두 번째 호출
... ; 여기서부터 실행 재개
중첩된 서브루틴, 즉 다른 서브루틴을 호출하는 서브루틴은 서로 다른 복귀 주소를 r4, r5 등의 서로 다른 레지스터에 저장하거나, 보통 호출 스택(call stack)에 복귀 주소를 메모리에 저장함으로써 처리할 수 있다.
Fortran I의 서브루틴. Fortran I에는 계산된 점프(GOTO DEST, 여기서 DEST는 변수)와, 레이블의 값을 변수에 대입하는 기능(ASSIGN LBL TO DEST)이 있다. 이는 변수로 매개변수와 복귀 주소를 전달하며 어셈블리와 동일한 방식으로 서브루틴을 작성하기에 충분하다. 예를 들어:
200 D = SQRT(B*B - 4*A*C)
X1 = (-B + D) / (2*A)
X2 = (-B - D) / (2*A)
GOTO RETADDR
이 서브루틴의 호출 예는 다음과 같다:
1000 A = 3
B = -8
C = 1
ASSIGN 1010 TO RETADDR
GOTO 200
1010 PRINT X1
위와 같은 단순 서브루틴은 코드 재사용에 불편하다. 서브루틴과 메인 프로그램이 모든 변수를 공유하기 때문에, 서로 다른 서브루틴에서 다른 변수 이름을 조심해서 써야 한다. 1958년 Fortran II, 곧이어 1960년 Algol은 코드 재사용을 더 잘 지원하는 언어적 수단, 즉 프로시저(procedure)와 함수(function)를 도입했다. 오늘날 거의 모든 언어에서 이를 찾을 수 있다.
Fortran II의 서브루틴과 함수. Fortran II는 명시적 매개변수를 가진 세 종류의 서브프로그램을 지원한다: 서브루틴, 단순 함수(simple function), 일반 함수(general function).
서브루틴은 오늘날 우리가 프로시저라고 부르는 것과 대응한다. 매개변수를 받고 여러 위치에서 호출될 수 있는 명령들의 집합이다. 예를 들어, 2차 방정식 해법을 Fortran II로 쓰면 다음과 같다:
SUBROUTINE QUADRATIC(A, B, C, X1, X2)
D = SQRT(B*B - 4*A*C)
X1 = (-B + D) / (2*A)
X2 = (-B - D) / (2*A)
RETURN
END
이 프로시저를 호출하는 예:
CALL QUADRATIC(1.0, -2.0, 5.0, Y1, Y2)
CALL 명령은 서브루틴으로 제어를 넘기고 복귀 후 다음 명령으로 돌아오는 것뿐 아니라, 매개변수 전달도 수행한다. 변수나 배열인 인자는 참조에 의한 전달(call by reference)이다. 따라서 QUADRATIC 안에서 X1, X2에 하는 대입은 실제로 호출자 쪽의 Y1, Y2에 대한 대입이 된다. 그 외의 인자는 값에 의한 전달(call by value)이다. 따라서 QUADRATIC 안의 변수 A, B, C는 각각 1.0, -2.0, 5.0으로 초기화된다.
모든 변수는 COMMON으로 선언되지 않는 한 서브프로그램이나 메인 프로그램에 로컬이다. 위 예에서 QUADRATIC의 D에 한 대입은 호출자 쪽의 D에는 아무 영향이 없다. 서로 다른 변수이기 때문이다.
Fortran II의 단순 함수는 매개변수를 가진 하나의 식(expression)일 뿐이다. 예를 들어, 두 값 A와 B 사이를 선형 보간하는 함수를 다음과 같이 정의할 수 있다:
INTPOL(X) = A * X + B * (1 - X)
그리고 내장 함수 SIN, COS 등과 마찬가지로 식 안에서 사용할 수 있다:
X2 = INTPOL(0.5)
X3 = INTPOL(0.3333) - INTPOL(0.6666)
반면 일반 함수는 서브루틴처럼 하나 이상의 명령으로 이루어진다. 호출자에게 값을 반환하기 위해, 함수는 자신의 이름과 같은 이름의 변수에 값을 대입한다. 예를 들어, 숫자 배열의 평균을 계산하여 반환하는 함수는 다음과 같다:
FUNCTION AVRG(ARR, N)
DIMENSION ARR(N)
SUM = ARR(1)
DO 10 I = 2, N
SUM = SUM + ARR(I)
10 CONTINUE
AVRG = SUM / FLOATF(N)
RETURN
END
10행의 AVRG에 대한 대입에 주목하라. 이것이 이 함수가 반환하는 값을 정의한다.
일반 함수는 단순 함수와 마찬가지로 식 안에서 호출된다:
X = AVRG(A, 20) + AVRG(B, 10)
Algol 60의 프로시저는 Fortran II의 서브루틴과 일반 함수에 가깝다. 대략적으로, 프로시저는 매개변수가 있는 블록 문이며, 선택적으로 반환 값을 가질 수 있어 함수처럼 사용할 수 있다. 그러나 Fortran II와 달리 Algol 60은 매개변수 선언에 따라 값을 통한 전달(call by value) 또는 이름을 통한 전달(call by name)을 사용한다. 또한 프로시저는 재귀적(recursive)일 수 있고, 다른 프로시저 안에 중첩(nested)될 수 있으며, 다른 프로시저의 인자로 전달될 수 있다.
다음은 Algol 프로시저로 쓴 2차 방정식 해법이다:
procedure quadratic(a, b, c, x1, x2);
value a, b, c;
real a, b, c, x1, x2;
begin
real d;
d := sqrt(b * b - 4 * a * c);
x1 := (-b + d) / (2 * a);
x2 := (-b - d) / (2 * a)
end;
매개변수 x1과 x2는 value로 선언되지 않았으므로 이름에 의한 전달이다. 따라서 quadratic 안에서 x1과 x2에 하는 대입은 호출자가 제공한 인자에 영향을 미치지만, a, b, c에 대한 대입은 quadratic 밖에는 영향을 주지 않는다.
다음은 함수를 매개변수로 받는, 단순한 적분 계산 예이다:
real procedure integral(f, a, b, steps);
value a, b, steps;
real procedure f;
real a, b;
integer steps;
begin
real sum;
sum := 0;
for x := a step (b - a) / steps until b do
sum := sum + f(x);
integral := sum / steps
end
다음은 중첩 프로시저를 보여주는 integral 사용 예이다:
real procedure test(a, b);
value a, b;
real a, b;
begin
real procedure interpolate(x);
value x;
real x;
begin
interpolate := a * x + b * (1 - x)
end;
test := integral(interpolate, 0.0, 10.0, 200)
end
내부 프로시저 interpolate는 둘러싼 프로시저 test의 변수 a, b에 접근할 수 있음을 주의하라.
Algol 60의 인자 전달은 유명한 “복사 규칙(copy rule)”로 지정된다. ALGOL 60 보고서(Backus et al., 1960)에는 다음과 같이 서술되어 있다:
값 목록에 인용되지 않은 모든 형식 매개변수는 프로시저 본문 전체에서 해당 실제 매개변수로 대체된다 […] 이 과정에서 삽입된 식별자와 이미 프로시저 본문 내에 존재하는 다른 식별자 사이의 잠재적 충돌은 형식 또는 지역 식별자에 대한 적절하고 체계적인 변경을 통해 회피된다 […] 마지막으로, 위와 같이 수정된 프로시저 본문은 프로시저 호출문을 대체하여 삽입되고 실행된다.
이 설명은 람다 계산법과 관련 함수형 언어의 “이름에 의한 호출(call by name)”을 떠올리게 하며(5.4절 참조), Scheme과 같은 언어의 “위생적인 매크로 전개(hygienic macro expansion)”도 연상시킨다. 그러나 Algol은 람다 계산법과 달리 명령형 언어이며, 복사 규칙과 결합될 때 놀라운 동작을 낳기도 한다! 다음의 합(sum) 함수 예를 보자:
real procedure sum(k, l, u, ak)
value l, u;
integer k, l, u;
real ak;
begin
real s;
s := 0;
for k := l step 1 until u do
s := s + ak;
sum := s
end;
이 함수는 매우 범용적이며 다음과 같이 사용할 수 있다:
sum(i, 1, m, A[i])sum(i, 1, n, i * i)sum(i, 1, m, sum(j, 1, m, A[i, j]))이 세 예에서 복사 규칙은 루프 인덱스 k를 i로 바꾸고, 인자 ak를 i에 의존하는 식으로 바꾼다. 따라서 루프는 기대한 합을 수행한다. (이 요령은 “젠센의 기법(Jensen’s device)”으로 알려져 있다.)
복사 규칙은 코드만 읽고서는 추측하기 어려운 바람직하지 않은 효과도 낳을 수 있다. 다음 프로시저를 보자:
procedure swap(a, b)
integer a, b;
begin
integer temp;
temp := a;
a := b;
b := temp
end;
이 프로시저는 항상 인자를 교환하지는 않는다! 예를 들어 swap(A[i], A[j])는 기대한 대로 동작하지만, swap(i, A[i])는 복사 규칙에 따르면 다음과 동등하다:
begin
integer temp;
temp := i;
i := A[i];
A[i] := temp
end
i에 대한 대입이 이어지는 A[i]에 대한 대입을 교란한다.
이러한 복사 규칙의 미묘함, 그리고 이를 정확하고 효율적으로 구현하기가 어렵다는 이유로, Algol 계열의 후속 언어들(Algol 68, Pascal, Ada, C, C++)은 이름에 의한 호출을 버리고 값/참조(포인터 포함)/복사-입력/복사-출력 등의 조합을 사용했다.
용어. 이 장의 나머지에서 우리는 “함수(function)”라는 용어를 서브프로그램, 서브루틴, 프로시저, 함수 전반을 가리키는 일반 용어로 사용한다. 서브루틴과 프로시저는 값을 반환하지 않는 함수(예: C 계열 언어의 void 함수)로 볼 수 있다.
설계 차원. 대부분의 프로그래밍 언어는 다양한 표현력과 사용성을 가진 함수를 지원한다. 다음과 같은 설계 차원을 구분할 수 있다:
이러한 설계 선택은 실행 중의 런타임 환경(runtime environment)을 표현하는 구현 기술과 밀접하게 관련된다. 런타임 환경은 프로그램의 주어진 지점에서 해당 스코프에 있는 변수들에 값을 할당한다. 컴파일된 코드에서 환경은 여러 형태의 저장소(프로세서 레지스터, 고정 메모리 위치, 호출 스택의 위치, 가비지 컬렉션 또는 명시적 관리 힙의 위치 등)를 사용해 구체화된다. 환경을 구현하는 전략에 따라 위에서 열거한 함수 기능 중 일부는 지원되거나 제한될 수 있다.
정적으로 할당된 환경. 이는 초기 Fortran 컴파일러들이 사용한 전략이다. 환경은 전역, 정적 할당 메모리 위치로 표현된다. COMMON 변수마다 하나, 각 함수의 변수와 매개변수마다 하나, 각 함수마다 하나의 위치(해당 함수를 호출한 쪽의 복귀 주소 보관) 등이다. 왼쪽의 프로그램을 보자:
DIMENSION A(10)
SUBROUTINE F(A, N)
... I ... J...
SUBROUTINE G(X, Y)
COMMON A
... A ... I ... J ...
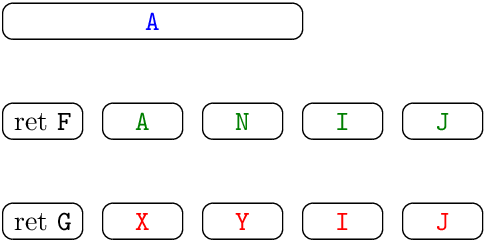
환경의 표현이 오른쪽에 나와 있다. 전역 변수 A와 서브루틴 F의 매개변수 A는 서로 다른 프로그램 변수를 나타내므로 서로 다른 메모리 위치에 놓이는 점에 주목하라. F와 G의 지역 변수 I, J 역시 마찬가지다.
이 구현 기법은 매우 단순하다. 환경을 표현하는 데 쓰이는 모든 메모리는 링크 타임에 정적으로 할당되며, 프로그램 실행 중에는 동적 할당이 일어나지 않는다. 주요 한계는 재귀와 기타 재진입성을 지원하지 못한다는 점이다. 예컨대 위의 함수 F가 재귀적이라면, 지역 변수 A, N, I, J에 대한 다중 바인딩이 동시에 활성화되고, F의 호출자들에 대한 복귀 주소도 여러 개 기록해야 한다. 이는 변수 바인딩과 복귀 주소의 동적 메모리 할당을 요구하며, 보통 스택을 사용한다.
스택 프레임으로서의 환경. 이 접근법은 활성 레코드(activation record), 또는 스택 프레임(stack frame)의 스택을 사용한다. 각 함수 호출은 새로운 프레임을 스택에 푸시한다. 이 프레임에는 호출된 함수의 매개변수 값, 지역 변수, 복귀 주소가 담긴다. 함수가 반환되면 프레임이 스택에서 팝된다. 전역 변수는 계속 정적으로 할당된다.
왼쪽의 Algol 재귀 프로시저와 오른쪽의 스택을 보자:
procedure g(x, y)
integer x, y; value x, y;
begin
integer i, j;
...
end;
procedure f(n)
integer n; value n;
begin
integer i;
if n = 0 then f(1)
else g(...)
end
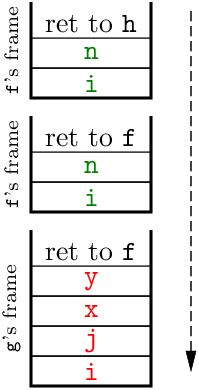
스택은 아래로 자란다. 다른 프로시저 h에서 인자 0으로 f를 처음 호출하면, h로의 복귀 주소와 f의 변수 n과 i의 바인딩을 담은 프레임이 푸시된다. 이어 f는 자기 자신을 재귀 호출하여, f로의 복귀 주소와 n, i 바인딩을 담은 두 번째 프레임을 푸시한다. 인자 1로 호출된 두 번째 f는 g를 호출하며, 스택 맨 아래에 표시된 세 번째 프레임( f로의 복귀 주소와 g의 변수·매개변수 바인딩)이 푸시된다.
이 스택 기반 환경 구현은 오늘날 거의 보편적으로 사용된다. 자연스럽게 재귀를 지원한다. C처럼(Algol과 달리) 중첩 함수가 금지되면, 함수는 일급 값으로도 쉽게 지원된다. 함수 값은 함수 코드의 진입점을 가리키는 코드 포인터일 뿐이다. 중첩되지 않은 프로시저의 자유 변수[1]는 모두 정적으로 할당된 전역 변수이므로, 함수를 호출할 때 환경의 동적 부분을 전달할 필요가 없다.
중첩 함수의 스택 프레임. Algol처럼 중첩 함수가 있는 경우, 함수는 자신을 둘러싼 함수들의 지역 변수에 접근해야 한다. 이를 위해 함수의 중첩 구조를 따라 스택 프레임을 사슬로 연결할 수 있다. 즉, 어떤 함수 활성의 스택 프레임은 “접근 링크(access link)”라 불리는 포인터를 가지고, 이는 바로 바깥 함수의 최신 활성에 대한 스택 프레임을 가리킨다. 이 스택 프레임 사슬을 따라가면, 함수에 보이는 어떤 변수의 값도 찾을 수 있다.
다음은 앞선 예의 변형으로, 프로시저 g가 이제 프로시저 f 안에 중첩되어 있다:
procedure f(n)
integer n; value n;
begin
integer i;
procedure g(x, y)
integer x, y; value x, y;
begin
integer j;
...
end;
if n = 0 then f(1)
else g(...)
end
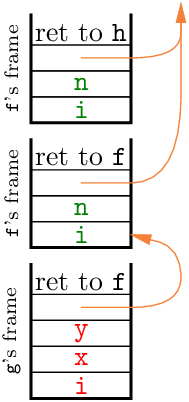
g의 프레임에서 g를 둘러싼 프로시저 f의 가장 최근 호출 프레임으로 향하는 접근 링크(빨간 화살표)에 주목하라. 이 링크 덕분에 g는 f에 선언된 변수 i와 n에 접근할 수 있다. 마찬가지로 f의 두 프레임 모두 자신을 둘러싼 프로시저(있다면)의 가장 최근 프레임을 가리키는 접근 링크를 포함하고, 둘러싼 프로시저가 없다면 null 포인터를 가진다. 또한 접근 링크는 호출 스택에 나타나는 순서대로 프레임을 연결하지 않는다. 일반적으로 함수의 호출자는 즉시 둘러싼 함수가 아니기 때문이다. 위 예에서 f의 재귀 호출이 이를 보여준다.
이 접근에서는 함수 값을 단순한 코드 포인터로 표현할 수 없다. 함수의 자유 변수가 이제 다른 함수의 지역 변수일 수 있고, 그 값은 동적으로 할당된 스택 프레임에 있기 때문이다. 따라서 함수 값은 “클로저(closure)”, 즉 함수 코드 포인터와 둘러싼 함수들의 스택 프레임 사슬을 가리키는 포인터의 쌍으로 표현해야 한다. 다만 이런 함수 클로저는 수명이 짧다. 둘러싼 함수 중 하나라도 반환하면 프레임 사슬이 무효화되기 때문이다. 이런 이유로 Algol과 Pascal은 함수를 다른 함수의 인자로 전달하는 것은 허용하지만, 함수 결과로 반환하거나 데이터 구조에 저장하는 것은 허용하지 않는다.
힙 할당 클로저와 객체. 이런 제약을 없애고 함수를 일급 값으로 사용하려면, 함수 클로저와 런타임 환경의 일부를 스택 규율을 따르지 않는 메모리 힙에 할당해야 한다. 이렇게 하면 클로저는 함수가 반환되어도 무효화되지 않는다. 힙이 자동 메모리 관리(가비지 컬렉션)를 사용한다면 프로그램 실행 내내, 수동 메모리 관리라면 명시적으로 해제할 때까지 유효하다.
순진하게는 모든 함수 호출의 활성 레코드를 힙에 할당할 수도 있지만, 이는 비용이 클 수 있다. 더 나은 대안은 함수 클로저에 실제로 필요한 런타임 환경의 부분, 즉 함수의 자유 변수 값만 힙에 할당하는 것이다. 오늘날 대부분의 함수형 언어가 이 접근을 사용한다. 함수 클로저는 힙에 할당된 레코드로, 첫 필드는 함수 코드 포인터이며, 나머지 필드는 함수의 자유 변수 값이다. 반환 주소와 클로저에 포획되지 않은 변수 바인딩은 여전히 활성 레코드 스택에 저장한다.
예를 들어, OCaml의 fun x -> a * x + b에서 a와 b는 함수 바깥에서 바인딩된 자유 변수이다. 이 함수를 a=2, b=5인 문맥에서 평가하면, 힙에 다음과 같은 함수 클로저가 만들어진다:

여기서 함수 코드는 C 문법으로 표시되어 있다. 이는 첫 번째 인자로 자신(클로저)을 받아, 그 안에서 자유 변수 a와 b의 값을 꺼내 쓰는 폐쇄된 함수이다. 이 클로저 c에 인자 8을 적용하는 것은, 예를 들어 c->code(c, 8)처럼 함수 c->code를 호출하되 클로저 c를 추가 인자로 넘기는 것과 같다.
이러한 자기-적용 의미론은 객체지향 언어에서도 사용된다. 객체(클래스의 인스턴스)의 런타임 표현은 함수 클로저와 유사하다. 클래스의 인스턴스 변수 값들과, 메서드 이름을 코드 포인터에 매핑하는 “v-테이블” 포인터를 담은 레코드다. 메서드를 구현하는 코드는 객체에 대한 포인터를 추가 인자로 받아 인스턴스 변수에 접근한다. 이런 관점에서 함수 클로저는 단일 apply 메서드를 가진 객체로 볼 수 있고, 객체는 여러 진입점(메서드당 하나)을 가진 함수 클로저로 볼 수 있다.
단순한 함수 호출. Fortran II에서 함수 호출 전후의 제어 흐름은 단순하다. 함수가 반환하면 실행은 항상 호출을 문법적으로 바로 잇는 명령으로 이어진다. 다시 말해, CALL proc(e1, …, en) 호출은 대입 x = e와 마찬가지로 기본 명령이지만, 호출이 종료된다는 보장은 없다. 또한 코드 레이블은 함수에 로컬이므로, 한 함수에서 다른 함수로 goto로 점프할 수 없다.
다중 반환 지점. Fortran 77에서는 서브루틴이 CALL 뒤의 기본 반환 지점 이외에도 다른 반환 지점을 가질 수 있다. 이러한 대체 반환 지점은 추가 인자로 전달되는 레이블이다.
예를 들어, 실해가 없으면 대체 지점으로 돌아가도록 하는 2차 방정식 해법은 다음과 같다:
SUBROUTINE QUADRATIC(A, B, C, X1, X2, *)
D = B*B - 4*A*C
IF (D .LT. 0) RETURN 1
D = SQRT(D)
X1 = (-B + D) / (2*A)
X2 = (-B - D) / (2*A)
RETURN
END
사용 예:
CALL QUADRATIC(1.0, -2.0, 12.5, X1, X2, *99)
...
99: WRITE (*,*) 'Error - no real solutions'
STOP
매개변수 목록의 별표(*) 하나하나가 대체 반환 지점을 나타낸다. 이는 CALL의 인자 목록에 있는 레이블(여기서는 *99)에 대응한다. RETURN 1은 “첫 번째 대체 반환 지점으로 분기”를 의미하고, 평범한 RETURN은 “기본 반환 지점으로 분기”를 의미한다.
비지역 goto. Algol 60과 그 후속 언어에서는 goto L이 레이블 L의 정의 스코프 안에 있는 한 하나 이상의 둘러싼 블록 바깥으로 점프할 수 있다. 심지어 goto가 레이블 L의 정의와 다른 프로시저 안에 있더라도, 스코프 제약만 만족하면 된다.
다음 Algol 프로그램을 보자:
begin
procedure fatal_error;
begin
writeln('Fatal error, exiting');
goto terminate
end;
...
terminate:
end
프로그램 어디에서든 fatal_error를 호출하면 오류 메시지를 출력하고 프로그램 맨 끝에 있는 terminate 레이블로 점프하여 즉시 종료한다.
Algol은 레이블을 프로시저의 인자로 전달하는 것도 지원한다. 이는 Fortran 77의 다중 반환 지점 스타일의 프로시저를 구현하는 데 사용할 수 있다. 예를 들어, 오류 처리를 포함한 2차 방정식 해법은 다음과 같다:
procedure quadratic(a, b, c, x1, x2, err);
value a, b, c;
real a, b, c, x1, x2;
label err;
begin
real d;
d := b * b - 4 * a * c;
if d < 0 then goto err;
d := sqrt(d);
x1 := (-b + d) / (2 * a);
x2 := (-b - d) / (2 * a)
end;
Pascal은 레이블을 함수 인자로 전달하는 것을 지원하지 않지만, 원하는 레이블로의 goto를 본문으로 갖는 프로시저를 전달하는 방식으로 같은 효과를 낼 수 있다.
이런 비지역 goto의 사용은 Fortran 77의 다중 반환 지점보다 더 강력하다. quadratic에 전달되는 레이블 err는 반드시 quadratic의 호출자에 정의되어 있을 필요가 없고, 둘러싼 어떤 함수에든 정의되어 있을 수 있다. 따라서 goto err는 반드시 호출자로 돌아오는 것이 아니라, 호출 스택의 어디로든 점프할 수 있다.
예외. 함수에서 “밖으로 점프”하여 오류를 신호하는 이 관용구는 C++, Java, Python, OCaml과 같은 언어의 예외(exception)를 사용해 구현할 수도 있다. 예외와 예외 처리는 9장에 자세히 논의된다. 간단히 말해, 예외는 두 가지 언어 구성으로 지원된다. 첫 번째는 Java의 throw처럼 예외를 발생시키는 것으로, 현재 계산을 중단하고 예외 처리기로 점프한다. 두 번째는 try s1 catch(ex) s2처럼 s1을 실행하는 동안 발생한 ex 예외를 가로채 s2를 실행하는 것이다.
다음은 Java에서 예외를 사용한 오류 보고와 처리의 예이다:
static double[] quadratic(double a, double b, double c) throws NoSolution {
double d = b * b - 4 * a * c;
if (d < 0) throw new NoSolution();
...
}
static void solve(double a, double b, double c) {
try {
double[] sols = quadratic(a, b, c);
System.out.println("Solutions: " + sols[0] + ", " + sols[1]);
} catch (NoSolution e) {
System.out.println("No real solutions");
} finally {
System.out.println("I'm done!");
}
}
throw 문이 예외를 발생시키면, 호출 스택을 따라 예외를 처리할 수 있는 try 문을 가진 호출 함수가 동적으로 탐색된다. 어떤 try 문은(예외를 처리할 수 없으면) 건너뛸 수 있지만, 그들의 finally 절은 항상 실행된다.
예외와 비지역 goto의 주요 차이는, 예외 처리기(즉, throw의 목표)가 전적으로 동적으로 결정되는 반면, goto 문은 목표를 정적으로 자체에 명시한다는 점이다. 예외는 더 유연하고 사용이 쉽지만, 그만큼 제어 흐름이 덜 예측 가능하고 예외 처리를 빠뜨릴 위험이 커진다. 9.4절에서 이러한 문제와 가능한 우회책을 더 자세히 논의한다.
Scott and Aldrich (2025) 9장은 서브루틴, 매개변수 전달 방식, 구조적 예외, 그리고 그 스택 기반 구현을 잘 개관한다. Pratt and Zelkowitz (2000) 9.3절도 다양한 매개변수 전달 의미론과 그 구현을 논한다. Aho et al. (2006) 7장은 런타임 환경 구현 기법과 그것들이 지원하는 다양한 함수 유형을 더 상세히 다룬다.
렉시컬 바인딩을 가진 일급 함수 구현에 클로저를 사용하는 아이디어는 Landin (1964)에서 비롯되었고, Scheme 언어(Sussman and Steele, 1975)가 널리 알렸다. Appel (1998) 15장은 클로저를 사용하는 함수형 언어의 컴파일을 설명하며, 같은 책 14장은 객체지향 언어의 컴파일을 설명하므로 비교해볼 수 있다.
1 함수의 자유 변수(free variable)는 함수 본문과 매개변수에서 정의되지 않았지만 참조되는 변수들이다.