1965–1975년 구조적 프로그래밍 운동과 goto 논쟁을 개관하고, goto 제거 정리, Kosaraju식 환원, 환원 가능한 제어 흐름 그래프와 지배자 트리, Ramsey 알고리즘 등을 통해 구조적 제어의 표현력과 이론적 기반을 설명한다.
URL: https://xavierleroy.org/control-structures/book/main004.html
Title: Chapter 2 Structured programming



오늘날 “구조적 프로그래밍”은 저수준의 goto 점프 대신 고수준 제어 구조(조건문, 반복문 등)를 사용해 프로그램을 작성하는, 이견의 여지가 거의 없는 실천을 가리킨다. 그러나 1965–1975년 무렵에는, 구조적 프로그래밍이 소프트웨어를 보는 새로운 관점으로의 운동인 동시에, 좋은 프로그램을 어떻게 작성해야 하는가를 둘러싼 논쟁의 대상이기도 했다.
구조적 프로그래밍 운동은 소프트웨어를 바라보는 방식의 급진적 변화를 이끌었다. 1960년대 초에는, 프로그램에 대한 표준적 관점이란 고수준 기술로서의 순서도(flowchart)와, 그 기술을 구체화한 어셈블리 코드나 기타 저수준 프로그래밍이었다.
구조적 프로그래밍은 프로그램을 고수준 언어로 작성된 구성적이고 구조화된 소스 텍스트로 보게 한다. 이 소스 텍스트는 순서도나 기타 외부 문서에 의존하지 않고도 그 자체로 이해 가능해야 하며, 프로그램에 대한 추론을(처음에는 비형식적으로, 나중에는 프로그램 논리를 사용해 수학적으로) 뒷받침해야 한다.
이 운동의 선언문은 Dahl 등(1972)의 책 『Structured programming』이다. 이 책의 세 편의 에세이는 현대 소프트웨어 공학에 깊은 영향을 끼친 고수준 프로그래밍 개념들을 소개한다. 형식적 방법, 프로그램 정련, 자료구조, 타입 대수, 객체와 클래스, 코루틴 등이 그것이다. 프로그램을 goto로 쓰느냐 아니냐는 이 책의 관점에서는 사소한 문제다.
구조적 제어 논쟁은 구조적 프로그래밍 운동보다 훨씬 좁은 쟁점을 다뤘다. 이는 두 가지 프로그래밍 스타일의 충돌이었다. 한쪽에는 순서도의 단순한 전사로 얻은, goto가 많은 프로그램이 있었고, 다른 한쪽에는 순서도의 도움 없이 곧바로 작성한, 전적으로 또는 거의 전적으로 제어 구조(조건문, 반복문 등)만 사용하는 프로그램이 있었다. 이 논쟁은 Dijkstra(1968)의 유명한 논문 제목에서 따온 표어 “Go to statement considered harmful”로 알려지게 된다.
초기 사례들. Knuth(1974)는 전산 문헌에서 구조적 프로그래밍의 초기 단서를 정리한다. 예컨대 1966년에 Dewey Val Schorre는 어셈블리 코드를 문서화할 때 순서도 대신 들여쓰기 민감한 텍스트 아웃라인을 사용했다고 언급한다:
1960년 여름부터 나는 아웃라인 형태로 프로그램을 작성해 왔으며, 제어 흐름을 나타내기 위해 들여쓰기 규약을 사용했다. 나는 이 규약에 예외를 두기 위해 go 문장을 사용하는 것이 필요했던 적이 한 번도 없다. 예전에는 순서도를 쓰는 대신 이 아웃라인을 프로그램의 원본 문서로 보관했다 … 그리고 그 아웃라인으로부터 어셈블리 언어 코드를 작성하곤 했다. 모두가 순서도보다 이 아웃라인을 더 좋아했다.
1963년에 Peter Naur는 goto 문과 순서도의 사용을 비판한다:
자세히 들여다보면 놀랄 만큼 자주, 뒤로 향하는 go to 문이 사실은 감춰진 for 문임을 발견할 것이다. 그리고 그 for 절을 제자리에 삽입했을 때 알고리즘의 명료성이 얼마나 좋아지는지 보고 기뻐할 것이다. [프로그래밍 강좌의] 목적이 Algol 프로그래밍을 가르치는 것이라면, 내 생각에 순서도의 사용은 득보다 실이 많을 것이다.
논쟁의 촉발. 구조적 제어에 관한 논쟁에 불을 붙인 것은 Dijkstra의 짧은 커뮤니케이션 「Go to statement considered harmful」(Dijkstra, 1968)이다. 그는 이 글을 통신 편지로 Communications of the ACM 편집부에 보냈고, 제목은 없었다. 편집자가 지금은 유명해진 제목을 붙였다. 전형적인 Dijkstra의 문체대로, 이 글은 강렬한 문장으로 시작한다:
수년 동안 나는 프로그래머의 자질이 그들이 만든 프로그램에 들어 있는 go to 문장의 밀도의 감소 함수라는 관찰을 해 왔다. 최근에 나는 왜 go to 문장의 사용이 그런 참담한 결과를 낳는지 알게 되었고, go to 문장은 모든 “고급” 프로그래밍 언어(아마도 순수한 기계어를 제외한 모든 것)에서 폐지되어야 한다는 확신을 갖게 되었다. 그 당시에는 이 발견이 그다지 중요하다고 생각하지 않았다. 그러나 아주 최근의 토론에서 이 주제가 다시 등장했을 때, 나는 이를 출판하라는 권유를 받아, 지금 나의 고찰을 제출한다.
이 글은 이어서 왜 goto가 폐지되어야 하는지에 대한 Dijkstra의 “결정적 논거”를 설명한다. 이는 프로그램 실행 중 “우리가 지금 어디에 있는가”를 파악하는 어려움, 그리고 프로그램 시작부터 현재 지점까지의 경로를 기술하고 추론하는 어려움과 관련이 있다.
기본 연산의 순차로만 이루어진 프로그램이라면, 현재의 프로그램 지점만으로 실행 경로를 기술하는 데 충분하다. if-then-else 조건문이 있으면, 이전 조건문의 불리언 값들도 알아야 한다. 프로그램 지점이 하나 이상의 구조적 반복문 내부에 있다면, 이 반복문들이 몇 번 실행되었는지도 알아야 한다. 다음을 보자:
while (x < y) { ⇐ 두 번째 반복
while (a[x] != 0) { ⇐ 다섯 번째 반복
if (x == 0) { ⇐ 참이었음
...
}
if (y == 0) { ...
⇐ 지금 여기
}
}
}
Dijkstra의 표현을 빌리면, 실행 경로는 소수의 좌표 집합으로 완전히 기술된다. 두 반복문의 반복 횟수, 각 반복에서의 x == 0 테스트의 불리언 값, 그리고 현재 프로그램 지점이 그것이다.
그러나 프로그램이 임의의 go to 문장을 사용하면 “과정의 진행을 기술할 수 있는 의미 있는 좌표계 집합을 찾기가 무척 어렵다”고 Dijkstra는 쓴다. 다음을 보자:
if (x == 0) {
L: ...;
}
if (y == 0) {
...
goto L;
}
goto 문장은 두 조건문을 부분적으로 겹치는 반복을 만들어, 가능한 실행 경로들을 기술하기 어렵게 만든다. 이러한, 실행 경로가 뒤얽힌 종류의 프로그램을 흔히 “스파게티 코드”라고 부른다. 모양만 봐도 이유를 알 수 있다.
goto 문장 없이 프로그래밍하는 것은 1970년대 초에 많은 연구의 대상이 되었다. 먼저, 순수한 구조적 프로그래밍이, 규범 있게 goto를 사용하는 것보다는 정말로 프로그램 구조를 표현하는 최선의 방법인지 평가하기 위해서였고, 다음으로는 기존 프로그램에서 goto 문장을 제거하는 방법을 고안하기 위해서였다. 이는 개별 사례별로 하거나, 프로그램 변환을 통해 체계적으로 수행할 수 있다.
Knuth의 서베이 「Structured Programming with go to Statements」(Knuth, 1974)는 적절히 선택된 예들을 통해 goto 제거의 효과를 논한다. 특히 코드 조각의 중복이나 불리언 플래그의 추가가 발생하면, 코드의 명료성을 해치거나 성능을 떨어뜨릴 수 있음을 지적한다.
다음은 Knuth에서 가져온 예를 약간 변형한 것이다. 선형 조사(linear probing)를 사용하는 해시 테이블 삽입. 테이블은 두 배열로 표현된다. 키를 담는 A[N]과 연결된 값을 담는 B[N].
void add(key k, data d) {
int i = hash(k);
while (1) {
if (A[i] == 0) goto notfound;
if (A[i] == k) goto found;
i = i + 1;
if (i >= N) i = 0;
}
notfound:
A[i] = k;
found:
B[i] = d;
}이 C 코드는 두 라벨 notfound와 found 덕분에 간결하면서도 꽤 자기 설명적이다. 그러나 goto 문장이 두 개 들어 있다.
이를 초기 종료나 goto 없이, 구조적 while 반복문으로 다음과 같이 다시 쓸 수 있다.
void add(key k, data d) {
int i = hash(k);
while (! (A[i] == 0 || A[i] == k)) {
i = i + 1;
if (i >= N) i = 0;
}
if (A[i] == 0) A[i] = k;
B[i] = d;
}하지만 A[i] == 0 검사가 중복되며, 컴파일러가 적극적으로 최적화하지 않으면 실행 시간 오버헤드를 유발할 수 있다.
또 다른 시도는 break 문을 통한(구조적인) 조기 종료가 있는 while 반복문을 사용한다.
void add(key k, data d) {
int i = hash(k);
while (1) {
if (A[i] == 0) {
A[i] = k;
B[i] = d;
break;
}
if (A[i] == k) {
B[i] = d;
break;
}
i = i + 1;
if (i >= N) i = 0;
}
}여기서는 데이터 저장 B[i] = d가 “없음” 분기와 “있음” 분기 모두에서 중복된다. 하지만 이는 가독성이나 성능에 크게 영향을 주지 않는다.
좀 더 현대적인 예에서, C 코드에서 goto를 피하기 어려운 부분은 자원 해제와 함께하는 오류 처리이다. 이는 C로 작성된 시스템 코드의 일반적인 관용구다. 오류가 발생하면, 지금까지 획득한 자원을 해제하는 코드로 goto로 점프한다. 이렇게 하면 이 자원 해제 코드를 모든 오류 경우와 정상 경우가 공유할 수 있다.
파일을 열고 임시 메모리를 할당하는 함수를 생각해 보자:
int retcode = -1; // error
int fd = open(filename, O_RDONLY);
if (fd == -1) goto err1;
char * buf = malloc(bufsiz);
if (buf == NULL) goto err2;
...
if (something goes wrong) goto err3;
...
retcode = 0; // success
err3:
free(buf);
err2:
close(fd);
err1:
return retcode;함수의 에필로그는, 반환하기 전에 자원 buf와 fd를 해제하고 성공/오류 코드를 반환하는데, 이 코드는 한 번만 작성된다. 오류 상황에서는 할당된 자원에 따라 err3, err2, err1 라벨로 점프한다.
이 코드는 goto 없이도 쉽게 다시 쓸 수 있지만, 자원 해제 코드가 중복되고, 일관되게 해제하지 못할 위험이 있다.
int fd = open(filename, O_RDONLY);
if (fd == -1) return -1;
char * buf = malloc(bufsiz);
if (buf == NULL) {
close(fd);
return -1;
}
...
if (something goes wrong) {
free(buf);
close(fd);
return -1;
}
...
free(buf);
close(fd);
return 0;이전 예와 마찬가지로, 조기 종료가 있는 반복문을 사용하면 goto 없이도 오류 처리 코드를 공유할 수 있다. 이 반복문들은 특이한 형태(do ... while(0) 본문이 정확히 한 번 실행됨)인데, 조기 종료가 있는 블록의 역할을 수행한다.
int retcode = -1; // error
do {
int fd = open(filename, O_RDONLY);
if (fd == -1) break;
do {
char * buf = malloc(bufsiz);
if (buf == NULL) break;
do {
...
if (something goes wrong) break;
...
retcode = 0; // success
} while (0);
free(buf);
} while (0);
close(fd);
} while(0);
return retcode;이 예들은 goto 문장을 구조적 구성으로 대체할 수 있음을 시사한다. 그러나 이때 추가 실행 시간 테스트나 코드 중복이 필요할 수도 있다. 항상 그런가? 이 장의 나머지 부분이 이 질문에 답한다.
구조적 프로그래밍 논쟁에서 중심적 역할을 한 기술적 질문은 “goto 제거 문제”였다. 즉, 비구조적 프로그램(goto와 if…goto를 사용하여 작성된)을, 블록, 조건문, 반복문과 같은 Algol 스타일의 구조만을 사용하는 동등한 구조적 프로그램으로 항상 변환할 수 있는가?
구조적 프로그램에 원래보다 더 많은 변수를 허용하면, 이 문제는 간단히 해결된다.
정리 1 임의의 비구조적 프로그램(동치로, 임의의 순서도)은 단 하나의 while 반복문과 하나의 추가 정수 변수를 갖는 구조적 프로그램과 동등하다.
이 결과는 원래 프로그램으로부터 구조적 프로그램을 명시적으로 구성하여 쉽게 증명할 수 있다. 비구조적 프로그램이, 순차 계산 s1, s2, …, sn(보통은 대입문과 프로시저 호출의 연속)으로 구성되어 있고, 제어는 라벨 1, 2, …, n, 무조건 점프 goto ℓ, 그리고 조건 점프 if b then goto ℓ(여기서 b는 불리언 식)로 표현되어 있다고 하자.
1: s1
if b1 then goto 3
2: s2
goto 4
3: s3
4: s4
if b4 then goto 1
먼저, 프로그램을 기본 블록들의 집합으로 재구성한다. 기본 블록은 무조건 점프 goto ℓ 또는 양방향 조건 점프 if b then goto ℓ1 else ℓ2로 항상 끝나는, 순차 계산이다. 이렇게 하면 암묵적 폴스루(fall-through) 동작을, 바로 다음 라벨로의 명시적 점프로 구체화한다. 또한 프로그램의 끝을 나타내는 특별 라벨 “0”을 추가한다. 위 예를 이렇게 바꿀 수 있다.
1: s1
if b1 then goto 3 else goto 2
2: s2
goto 4
3: s3
goto 4
4: s4
if b4 then goto 1 else goto 0
다음으로, 0, 1, …, n의 라벨 범위를 갖는 새로운 정수 변수 pc(프로그램 카운터)를 도입한다. pc는 다음에 실행할 기본 블록을 가리킨다. goto 문은 pc로의 대입이 된다. 기본 블록은 pc의 값에 따라 분기하는 다중 분기(case) 문장의 분기들이 된다.
case pc of
1: s1
if b1 then pc := 3 else pc := 2
2: s2
pc := 4
3: s3
pc := 4
4: s4
if b4 then pc := 1 else pc := 0
end case
마지막으로, pc가 0이 될 때까지 case 문장을 반복하는 while 반복문을 추가한다. pc가 0이면 프로그램은 종료된다.
pc := 1; while pc != 0 do
case pc of
1: s1
if b1 then pc := 3 else pc := 2
2: s2
pc := 4
3: s3
pc := 4
4: s4
if b4 then pc := 1 else pc := 0
end case
end while
위 구성은 전이 함수를 반복 적용하는 것으로 이해할 수 있다. 전이 함수는 다중 분기 case 문으로 구현된다. 이는 pc 변수가 지정하는 기본 블록을 실행하고, 그에 따라 pc와 다른 변수들을 갱신한다. 반복은 while 반복문으로 구현되어, pc가 0이 될 때까지 전이를 실행한다.
이 구성의 여러 변형이 알려져 있다. 정수 변수 pc를 여러 불리언 변수로 대체할 수 있고, 다중 분기 case 문을 if-then-else 조건문의 연쇄로 대체할 수도 있다.
구전된 결과. 정리1은 흔히 C. Böhm과 G. Jacopini에게 귀속된다. 그러나 1964년의 그들의 논문 「Flow diagrams, Turing machines and languages with only two formation rules」(Böhm and Jacopini, 1966)은 더 약한 결과(모든 순서도는 여러 while 반복문과 보조 불리언 변수를 가진 구조적 프로그램으로 다시 쓸 수 있음)를 보이며, 지역적 그래프 재작성에 기반한 더 복잡한 증명을 사용한다.
정리1과 위에 개략한 단순한 증명은 1967년에 D.C. Cooper가 Comm. ACM 편집부에 보낸 편지에 등장한다(Cooper, 1967). Harel(1980)이 설명하듯, 이 정리와 그 단순한 증명은 1967년 이후 수십, 아마 수백 편의 논문과 교과서에서 “구조적 프로그래밍의 수학적 정당화”로 언급되었으나, Cooper에게 귀속되는 경우는 드물고, Böhm과 Jacopini에게 귀속되거나 아예 출처가 생략되는 경우가 많았다.
Harel은 이 결과를 S.C. Kleene의 1936년 증명까지 거슬러 올라간다. 모든 부분 재귀 함수는 어떤 원시 재귀 함수의 최소화(minimization)임을 보인 그 증명에서, 여기서 원래의 순서도는 부분 재귀 함수, case 기반 전이 함수는 원시 재귀 함수, while 반복문은 Kleene의 최소화 연산자에 해당한다.
goto 제거 문제의 일반화로서, Kosaraju(1974)는 두 언어 사이의 제어 구조의 환원(reduction) 개념을 도입했다.
같은 기본 명령(대입, 프로시저 호출 등)을 지원하지만 제어 구조는 서로 다른 두 프로그래밍 언어 ℒ1과 ℒ2를 생각하자(예를 들어, 한쪽은 구조적 조건문과 반복문을 갖고, 다른 한쪽은 goto와 if-goto만 가진다).
정의 1(Kosaraju) ℒ1이 ℒ2로 환원 가능(reducible) 하다는 것은, 각 ℒ1 프로그램에 대해 동등한 ℒ2 프로그램이 존재하여, 같은 기본 명령을 사용하고(코드 중복 없음), 추가 변수를 사용하지 않음을 의미한다.
예제 1: 반복문의 검사가 각 반복의 끝에 오는 do-while 반복문은, 각 반복의 시작에서 검사하는 while 반복문으로는 Kosaraju 의미에서 환원되지 않는다. 실제로,
do s while b
를 제거하려면, 다음처럼 s를 중복하거나
begin s; while b do s end
아니면 다음처럼 추가 불리언 변수를 사용해야 한다.
loop := true; while loop do begin s; loop := b end
반면, do-while 반복문은 조기 종료(break)가 있는 while 반복문으로는 환원 가능하다.
while true do begin s; if not b then break end
Kosaraju의 두 조건이 만족된다. 기본 명령 s의 중복이 없고, 추가 변수도 없다.
예제 2: 순환이 없는 순서도(cycle-free flowchart)는, if-then-else 구조 조건문으로 환원되지 않는다. 중첩 조건문은 자연스럽게 기본 명령들의 트리를 기술하지만, 코드 중복이나 추가 불리언 변수 없이, 비순환 그래프에 존재하는 기본 명령의 공유를 포착할 수 없다. 예를 들어 다음 순서도를 보자.
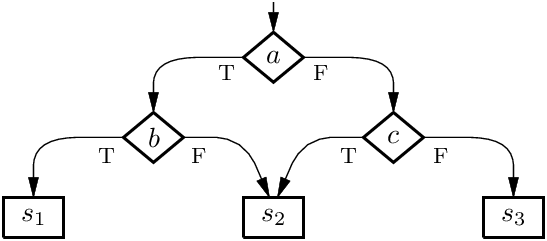
구조적 조건문을 사용하면, 명령 s2를 중복하든지
if a then if b then s1 else s2 else if c then s2 else s3
아니면 나중에 s2를 수행해야 하는지를 기록하는 불리언 변수를 추가해야 한다.
do_s2 := false
if a then
if b then s1 else do_s2 := true
else
if c then do_s2 := true else s3;
if do_s2 then s2
하지만 목표 언어에 조기 종료가 있는 블록 block … break … endblock도 있다면, 올바른 Kosaraju 환원이 가능하다.
block
if a then
if b then begin s1; break end else skip
else
if c then skip else begin s3; break end;
s2
endblock
위 예들이 시사하듯, 반복의 조기 종료(break 문)와 다단계 종료(break N, 여기서 N은 빠져나갈 중첩 반복문의 수)는 큰 차이를 만든다. Kosaraju(1974)는 조기 종료가 있는 반복 언어는 순수 반복 언어로 환원되지 않고, 또한 깊이 N+1의 종료를 가진 언어는 깊이 N 이하의 종료만 가진 언어로 환원되지 않음을 증명했다.
제어 흐름 그래프(CFG)는 순서도의 형식화다. CFG는 컴파일러에서 프로그램의 중간 표현(IR)로 자주 사용된다. 구조적 제어와 비구조적 제어를 모두 표현할 수 있으며, 많은 프로그램 변환, 정적 분석, 최적화를 지원한다.
CFG는 방향 그래프다. CFG의 노드는 기본 블록이며, 이는 무조건 분기, 조건 분기, 함수 반환과 같은 제어 전송으로 끝나는 기본 명령들(대입, 함수 호출 등)의 열이다. CFG의 간선은 가능한 모든 전송을 나타낸다. 노드는 무조건 분기로 끝나면 하나의 출력 간선을, if-then-else 조건문으로 끝나면 두 개를, N-방향 분기로 끝나면 N개를, 함수 반환으로 끝나면 0개를 갖는다.
예를 들어, 다음은 작은 구조적 프로그램과 그에 해당하는 CFG이다.
for (i = 0; i < 5; i++) {
printf("*");
}
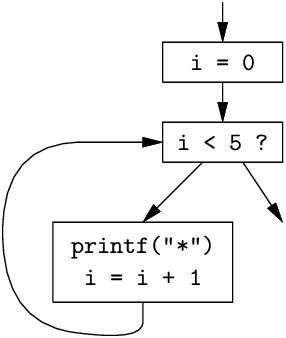
지배(dominance) 개념은 CFG의 구조를 분석하는 데 유용하다. CFG의 노드 A가 노드 B를 지배한다(dominates) 는 것은, A가 반드시 B 전에 실행된다는 뜻이다. 즉, 시작 노드에서 B로 가는 모든 경로가 A를 지난다. 다음 CFG를 보자.
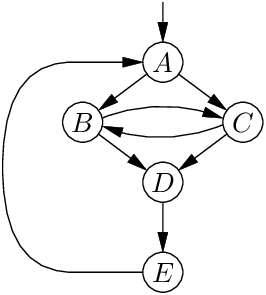
각 노드는 자기 자신을 지배한다. 시작 노드 A는 모든 노드를 지배한다. 노드 E에 도달하려면 반드시 D를 지나야 하므로, D는 E를 지배한다. 반면, B는 D를 지배하지 않는다. 경로 ACD는 B를 피하기 때문이다. 마찬가지로 C도 D를 지배하지 않는다. 또한, D와 E는 시작 노드 A를 지배하지 않는다. 자명한 경로 A가 D나 E를 지나지 않기 때문이다.
지배 개념은 CFG 간선의 분류로 이어진다. 간선 U → V에서, 도착지 V가 출발지 U를 지배하면 이를 역간선(back edge) 이라 하고, 그렇지 않으면 순간선(forward edge) 이라 한다. 위 예에서 간선 E → A는 역간선이고, 나머지 간선은 모두 순간선이다.
역간선은 CFG에서의 반복(loop)에 자연스럽게 대응한다. U → V 간선이 있고, V가 U를 지배한다면, V →* U 경로도 존재하므로, U → V →* U 사이클이 생긴다. 그러나 모든 반복이 역간선을 포함하는 것은 아니다. 위 예에서는 B와 C 사이에 반복이 있지만, 어느 쪽도 다른 쪽을 지배하지 않는다.
환원 가능한 CFG는 모든 반복이 역간선을 포함하는 CFG다. 더 정확히는, 순간선들만 남겼을 때 비순환(acyclic) 그래프가 되면 그 CFG는 환원 가능(reducible) 하다.
위 예에서, 역간선 E → A를 지운 후에도 B와 C 사이에 사이클이 남아 있으므로, 그 CFG는 환원 가능하지 않다. 그러나 아래 CFG는 C에서 B로의 간선이 없어, 역간선 E → A를 지우고 나면 사이클이 남지 않는다. 따라서 환원 가능하다.
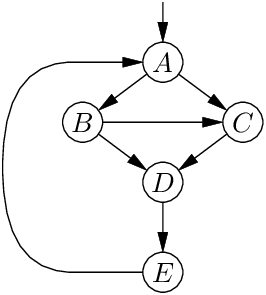
환원 가능성의 동치인 다른 정의도 여럿 있다. 예를 들어, 아래의 변환 T1과 T2를 반복적으로 적용해 단일 노드와 간선 없는 상태로 줄일 수 있을 때, 그 CFG는 환원 가능하다.
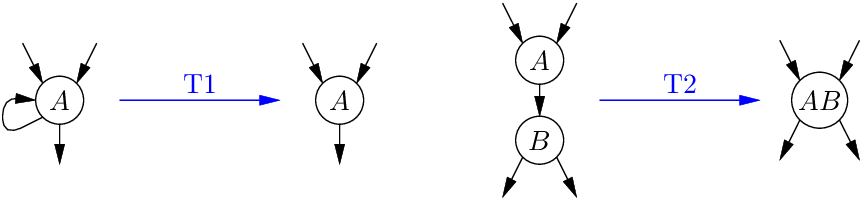
T1은 자기 자신으로의 루프(self-loop)를 제거하고, T2는 유일한 선행자 A만 가진 노드 B를 A와 합친다.
환원 가능한 CFG가 일반 CFG보다 분석과 최적화가 쉬운 한 가지 이유는, 각 반복이 자연 반복(natural loop) 이고 하나의 반복 헤더(loop header) 를 갖기 때문이다. 형식적으로, 반복 L은 강연결(strongly connected)인 노드 집합이다. L이 자연 반복이라는 것은, L의 모든 노드를 지배하는 H ∈ L(반복 헤더)이 존재하고, L의 모든 노드가 L 내부에 머무르는 경로로 H에 도달할 수 있음을 뜻한다.
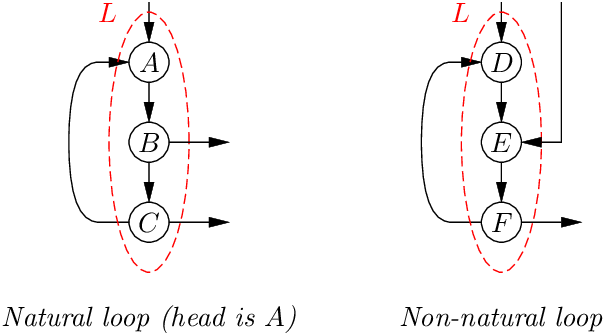
위 예에서 ABC는 헤더 A를 갖는 자연 반복이다. B와 C에 두 개의 종료점은 있지만, A를 통해서만 진입할 수 있다. 반대로 DEF는 두 곳(맨 위 D와 중간 E)에서 진입할 수 있으므로 자연 반복이 아니다. 그 결과 D는 E를 지배하지 않으며, 반복 헤더도 없다.
구조적 제어는 CFG의 환원 가능성과 밀접하게 관련되어 있다. 한 방향으로는, 지금까지 본 모든 제어 구조는 컴파일 후 환원 가능한 CFG를 낳는다. 조건문(if-then-else, 다중 switch), 반복문(시작, 끝, 중간 검사), 조기 종료(return, break, continue) 등이 포함된다. 사실 이 모든 구성은 유일한 헤더를 가진 자연 반복을 만들어낸다. 환원 불가능한 CFG를 얻으려면, 두 군데에서 진입할 수 있는 반복이 필요하다. 즉, 구조적 반복 내부로 점프하는 goto가 있거나, goto만으로 만든 비구조적 반복이어야 한다. 소스 언어가 일반적인 goto를 지원하지 않으면, 비환원 CFG는 발생할 수 없다.
다른 방향으로는, 다음 정리가 있다. 이는 Peterson 등(1973)이 처음 증명하고 출판했다.
정리 2 환원 가능한 제어 흐름 그래프의 언어는, 블록 구조 제어를 가진 언어(조건문, 블록, 무한 반복, 다단계 종료(break N, continue N))로 Kosaraju 의미에서 환원 가능하다.
Peterson 등의 증명은 구성적이다. 환원 가능한 CFG가 주어지면, 동등한 구조적 프로그램을 구성하는 알고리즘의 개요를 제시한다. 그러나 이 알고리즘은 3 패스이며 꽤 복잡하다. 최근 Ramsey(2022)는 주어진 CFG의 지배자 트리(dominator tree) 에 대한 귀납으로 진행하는 더 단순한 1-패스 알고리즘을 발표했다.
지배자 트리는 CFG와 같은 노드를 갖는다. 노드 A의 자식은 A의 직접 지배자(immediate dominator)로서 A를 갖는 노드 B들이다. 즉, A ≠ B이고 A가 B를 지배하며, A와 B “사이”에 다른 지배자가 없다(만약 A가 X를 지배하고 X가 B를 지배한다면, X = A 또는 X = B여야 한다).
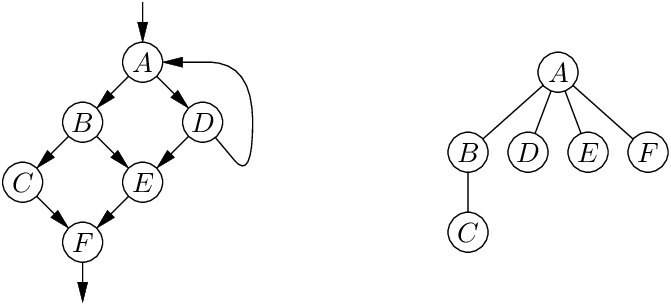
예를 들어, 위 왼쪽의 CFG는 오른쪽과 같은 지배자 트리를 갖는다. 노드 A는 네 개의 자식 B, D, E, F를 갖는다. B와 D는 CFG에서 A의 직접 후속자이며, E와 F는 직접 후속자는 아니지만 A에서 두 가지 방법으로 도달 가능하다.
Ramsey의 알고리즘은 지배자 트리에 대해 재귀적으로 진행한다. 각 노드에 대해, 그 노드의 자식들에 대해 생성된 구조적 명령들을 포함하는 구조적 명령을 만든다. 루트 A부터 시작하자. A는 반복 헤더이므로, 반복을 생성한다:
loop {
...
}
A는 지배자 트리에서 B와 D라는 두 자식을 가지며, 이들은 CFG에서 A의 직접 후속자이다. 따라서 A 위에서 B와 D를 “then”과 “else” 분기로 하는 조건문을 만든다. 그러나 A는 지배자 트리에서 E와 F라는 두 자식도 갖는데, 이들은 바로 뒤에 배치하여 break 문으로 점프할 수 있어야 한다. 결과 형태는 다음과 같다.
loop {
block {
block {
if (A) {
/* B 자리 */
} else {
/* D 자리 */
}
}
/* E 자리 */
}
/* F 자리 */
}
E는 F로 흐르기 때문에, E는 안쪽 블록에, F는 바깥 블록에 놓아야 한다. Ramsey의 알고리즘은 이 블록 중첩을 결정하기 위해 CFG의 역후위(reverse postorder) 번호 매기기를 사용한다.
이제 네 개의 부분 지배자 트리에 대해 재귀를 수행하여, 위에서 B, D, E, F로 표시한 자리들에 결과 명령을 삽입한다. 다음을 얻는다.
loop {
block {
block {
if (A) {
if (B) {
C ...
} else {
...
}
} else {
if (D) {
...
} else {
...
}
}
}
E ...
}
F ...
}
남은 일은 CFG가 지정한 제어 전송을 구현하는 명령으로 점들을 채우는 것이다. 제어가 그냥 폴스루라면 아무 것도 넣지 않아도 된다. 아니면 둘러싼 블록이나 반복문 N개를 종료하는 break N, 또는 N번째 둘러싼 반복을 재시작하는 continue N 명령을 쓸 수 있다. 여기서 C는 두 개의 둘러싼 블록을 건너 F로 이어져야 하므로 break 2가 필요하다. D의 “then” 분기는 한 블록 떨어진 E로 이어지므로 break 1을 쓴다. D의 “else” 분기는 반복 헤더 A로 이어지므로 continue 1을 쓴다. 마지막으로 다음과 같은 구조적 프로그램을 얻는다.
loop {
block {
block {
if (A) {
if (B) {
C; break 2;
} else {
break 1;
}
} else {
if (D) {
break 1;
} else {
continue 1;
}
}
}
E;
}
F;
break 1;
}
알고리즘의 완전한 Haskell 코드와 정당성 개요는 Ramsey(2022)를 보라.
Knuth의 서베이(Knuth, 1974)는 1960년대 후반과 1970년대 초의 구조적 프로그래밍 논쟁을 역사적으로 잘 요약한다. 또한 1970년대의 숙련된 프로그래머가 goto 문장의 적절한 사용과 대안적 구조적 프로그래밍 관용구에 대한 더 나은 언어 지원을 어떻게 균형 잡힌 시각으로 보는지를 보여주는 흥미로운 글이다.
제어 흐름 그래프와 이를 중간 표현으로 사용하는 방법은 많은 컴파일러 교과서에서 다룬다. Cooper와 Torczon(2004)은 제어 흐름 그래프(5.2절), 지배와 지배자 트리, 그리고 정적 단일 대입(SSA) 중간 표현과의 관련성(9.2, 9.3절)을 잘 개관한다. Aho 등(2006)의 9.6절은 반복, 지배, 환원 가능성을 더 자세히 논한다.
환원 가능한 CFG를 구조적 프로그램으로 번역하는 방법은 Ramsey(2022)가 아름답게 설명하며, Haskell 기준 구현과 선행 연구에 대한 폭넓은 논의가 포함되어 있다. Ramshaw(1988)는 원래 코드의 구조를 가능한 한 유지하면서, 상당한 규모의 코드베이스(텍(TEX)의 Pascal 소스)에서 goto 문장을 제거한 사례를 보고한다. 비슷한 이슈는 기계어에서 고수준 구조적 언어로 디컴파일할 때도 나타난다(Brumley 등, 2013, Yakdan 등, 2015).