LLVM IR로 바이트코드를 리프팅하고 최적화 패스를 통해 가상화 레이어를 벗겨내는 순진한 디버추얼라이저 구현 과정을 다룹니다.

순진한 LLVM 기반 디버추얼라이저 작성하기
Published:2026-05-07 | Category: Reverse Engineering
난독화 해제, 특히 디버추얼라이제이션에 관심이 있다면, 접근 방식 중 하나로 LLVM IR로 리프팅하는 방법을 읽어봤거나 들어봤을 가능성이 매우 높습니다. 어떤 의미에서는 난독화를 컴파일러의 비최적화로 볼 수 있고, 수많은 효율적인 최적화 패스를 갖춘 LLVM은 디난독화에 매우 잘 작동할 수 있습니다. 하지만 이용 가능한 대부분의 자료는 지나치게 학술적이거나 매우 기술적이라 접근하기 어렵고, 아니면 리프팅 과정의 세부 사항은 건너뛴 채 높은 수준에서 파이프라인만 설명하면서 구체적인 내용이나 코드는 보여주지 않습니다. 이 주제를 처음 접하는 사람으로서, 저는 서로 다른 도구와 프레임워크들 때문에 혼란스러웠습니다. 각각은 서로 다른 주의사항이 있고, 학습 곡선이 가파르거나, 혹은 특정 PoC 밖에서는 제대로 동작하지 않았습니다.
그래서 저는 일단 직접 부딪혀 보기로 했고, 읽기만 멈추고 새로운 것을 배우고 싶을 때 항상 하듯이 제가 떠올릴 수 있는 가장 순진한 방식으로 뭔가를 구현해 보기로 했습니다. 따라서 이 글은 튜토리얼이나 디버추얼라이제이션 입문서라기보다는 일기장 기록 / 개발 로그처럼 읽는 것이 더 적절합니다.
저는 많은 가상 머신을 작성해 봤고, 여러 멀웨어 샘플에서 마주친 커스텀 VM도 몇 개 리버싱해 봤지만, 보통은 핸들러를 분석하고 디스어셈블러를 작성한 뒤 바이트코드를 수작업으로 분석하는 선에서 끝냈습니다. 이런 방식은 단순한 멀웨어 언패킹 VM에는 통하지만, 대상이 Themida나 VMProtect 같은 것으로 보호되어 있다면 그렇지 않습니다. 저는 늘 제대로 된 디버추얼라이저를 작성하고 싶었기 때문에, tuts4you에서 아무 VM crackme 하나를 골라 바로 시작했습니다.
계획은 단순했습니다. 가상화된 바이트코드를 LLVM으로 리프팅하고, 최적화하고, 다시 컴파일하면, 가상화 계층이 제거된 원래 프로그램을 얻게 되는 것입니다.
커스텀 VM을 어떻게 리버싱하는지, VM이 무엇인지, 혹은 LLVM을 자세히 설명하지는 않겠습니다. 이 주제들이 익숙하지 않다면 도움이 될 만한 링크를 몇 개 적어두겠습니다.
이 crackme는 간단한 플래그 검사기이며, 플래그 검사 로직이 가상화되어 있습니다:
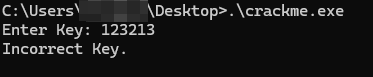
목표는 VM을 리버싱하고 올바른 키를 알아내는 것입니다.
아주 간단히 말해, 소프트웨어 보호 수단으로서의 커스텀 가상 머신은 어떤 가상의(혹은 실제의) 아키텍처를 위한 에뮬레이터로 볼 수 있으며, 어떤 종류의 프로그램(즉 "바이트코드")을 실행합니다. 이 crackme의 VM은 전형적인 스택 기반 가상 머신으로, 어느 정도 x86 아키텍처를 닮아 있고 리버싱하기도 매우 쉽습니다. 커스텀 VM을 한 번도 리버스 엔지니어링해 본 적이 없다면, 이것은 아주 좋은 입문 사례입니다.
앞서 언급했듯이, 이런 VM을 리버스 엔지니어링하는 고전적인 접근은 VM의 진입점을 찾고 디스패치 메커니즘을 파악하는 것입니다. 보통은 fetch-decode-execute 루프이거나, 각 핸들러가 다음 핸들러로 디스패치하는 모델인데, 이 VM은 후자에 해당합니다. 그 다음에는 각 opcode 핸들러를 파싱해서 디스어셈블러를 작성할 수 있습니다.
하지만 이 글은 이 특정 VM 자체보다는 리프팅 과정에 관한 것이므로, opcode 하나를 어떻게 리버싱하는지 예시만 보여드리겠습니다.
이것이 VMENTER로, 호스트 스택을 푸시하여 가상 머신의 레지스터와 스택 공간을 초기화하는 함수입니다:
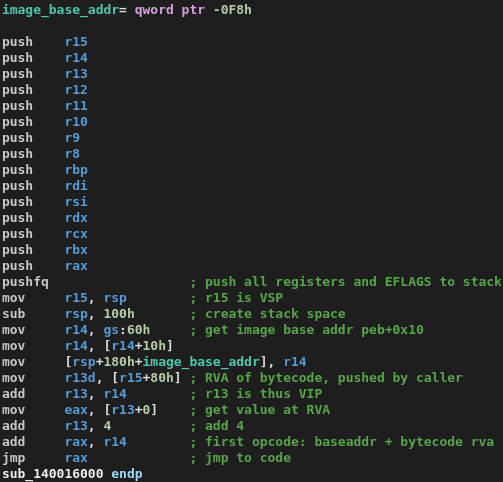
이제 R13이 VIP(virtual instruction pointer), R14가 이후 디스패처에서 RVA를 실제 주소로 계산하는 데 필요한 이미지 베이스, 그리고 R15가 우리의 VSP(virtual stack pointer)라는 것을 알 수 있습니다.
이 지식을 바탕으로 PUSH_REG64 핸들러를 리버싱하는 것은 매우 간단합니다:
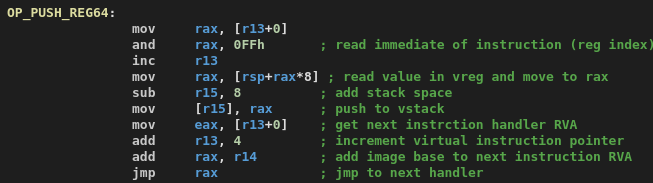
이 경우에는 핸들러 자체에 어떤 난독화도 적용되어 있지 않기 때문에, 모든 핸들러를 수동으로도 꽤 빠르게 리버싱할 수 있습니다.
핸들러를 수동으로 리버싱하는 것 외에도, 심볼릭 실행을 사용해서 각 핸들러를 실행하고 우리가 관심 있는 심볼릭 값들을 어떻게 변환하는지 기록할 수 있습니다. 이 경우 저는 miasm 프레임워크와 IDA domain API를 사용하여, 현재 커서가 가리키는 핸들러를 실행하는 IDA 스크립트로 이를 구현했습니다.
수동 분석을 통해 R13이 VIP, R14가 이미지 베이스, R15가 우리의 VSP라는 점을 추론했기 때문에, 아래 스크립트의 pretty-printing 메서드에 그 내용을 반영했습니다:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47 from ida_domain import Database
from miasm.analysis.machine import Machine
from miasm.core.locationdb import LocationDB
from miasm.ir.symbexec import SymbolicExecutionEngine
from miasm.expression.expression import ExprInt, ExprId, ExprMem
from miasm.ir.ir import AssignBlock
def render(expr):
with Database.open() as db:
ea = db.current_ea
code = db.bytes.get_bytes_at(ea, 0x200) # enough for our handlers
loc_db = LocationDB()
machine = Machine("x86_64")
mdis = machine.dis_engine(code, loc_db=loc_db)
asmcfg = mdis.dis_multiblock(0)
ira = machine.ira(loc_db)
ircfg = ira.new_ircfg_from_asmcfg(asmcfg)
symb = SymbolicExecutionEngine(ira)
init_blk = AssignBlock({
ExprId("RAX", 64): ExprInt(0, 64),
ExprId("R13", 64): ExprInt(ea, 64), # VIP
ExprId("R14", 64): ExprInt(0x140000, 64), # image base
ExprId("R15", 64): ExprInt(0x1000, 64), # VSP
ExprMem(ExprInt(0x1000, 64), 64): ExprInt(0xAAAAAAAAAAAAAAAA, 64)
})
symb.eval_assignblk(init_blk)
entry = next(iter(ircfg.blocks))
irblock = ircfg.blocks[entry]
for assignblk in irblock:
symb.eval_updt_assignblk(assignblk)
if any("IRDst" in str(dst) for dst in assignblk.keys()):
break # stop on jmp
print("----------------------------")
print("EA:", hex(ea))
print("VSP:", render(symb.eval_expr(ExprId("R15", 64))))
print("VIP:", render(symb.eval_expr(ExprId("R13", 64))))
print("STACK[0]:", render(symb.eval_expr(ExprMem(ExprId("R15", 64), 64))))
이제 이것을 예시 핸들러, 여기서는 0x140016195에 대해 실행하면 IDA Python 콘솔에서 심볼릭 효과 덤프를 얻을 수 있습니다:
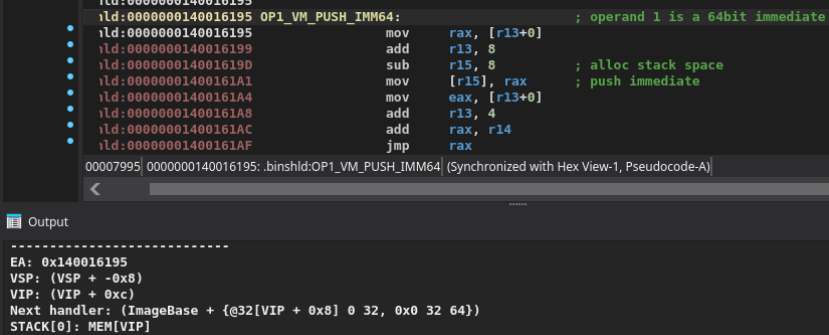
여기서부터 해당 핸들러가 무엇을 하는지 알아내기에 충분한 의미를 추론할 수 있습니다:
VIP가 가리키는 메모리의 8바이트가 스택에 푸시됩니다(명령어의 immediate 값)VSP는 8바이트 전진합니다즉 이것은 스택에 64비트 immediate를 푸시하는 PUSH_IMM64 명령어입니다!
이 접근의 장점은 이제 이러한 심볼릭 델타를 명령어 시그니처로 사용할 수 있다는 점입니다. 나중에 이 VM을 다시 마주쳤는데 opcode가 섞이는 등의 난독화가 적용되어 있다면, 각 핸들러를 다시 심볼릭 실행한 뒤 시그니처와 매칭하여 각 핸들러의 의미를 파악할 수 있습니다.
모든 명령어와 opcode를 리버싱하고 나면, 이 VM을 위한 바이트코드 파서, 좀 더 정확히는 디스어셈블러를 작성할 수 있습니다. VM에는 더 많은 opcode가 구현되어 있지만, 아래 opcode들은 이 바이트코드에서 실제로 사용되는 것들이므로 이 crackme에서는 이것들만 신경 쓰면 됩니다. 이름만 봐도 의미는 분명할 것입니다:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24//===------------------------------------------------------------------===//
// OPCODE, {operands, name, address (same as opcode), instruction length}
{0x1606A, {1, "PUSH_REG64", 0x1606A, 5}},
{0x16090, {1, "PUSH_REG32", 0x16090, 5}},
{0x16101, {1, "POP64", 0x16101, 5}},
{0x16126, {1, "POP32", 0x16126, 5}},
{0x16194, {1, "PUSH_IMM64", 0x16194, 12}},
{0x161B1, {1, "PUSH_IMM32", 0x161B1, 8}},
{0x1620A, {0, "PUSH_VSP64", 0x1620A, 4}},
{0x1626C, {0, "POP_VSP64", 0x1626C, 4}},
{0x1627D, {0, "POP_VSP32", 0x1627D, 4}},
{0x162B1, {0, "ADD64", 0x162B1, 4}},
{0x162C9, {0, "ADD32", 0x162C9, 4}},
{0x1631F, {0, "SUB64", 0x1631F, 4}},
{0x16337, {0, "SUB32", 0x16337, 4}},
{0x163A5, {0, "XOR32", 0x163A5, 4}},
{0x163FB, {0, "AND64", 0x163FB, 4}},
{0x16413, {0, "AND32", 0x16413, 4}},
{0x16481, {0, "OR32", 0x16481, 4}},
{0x16689, {0, "LOAD64", 0x16689, 4}},
{0x1669F, {0, "LOAD32", 0x1669F, 4}},
{0x166EC, {0, "STORE64", 0x166EC, 4}},
{0x16707, {0, "STORE32", 0x16707, 4}},
{0x1676B, {1, "JNZ", 0x1676B, 8}}
덧붙이자면, 심볼릭 실행만으로도 crackme 전체를 풀 수는 있지만, 그런 접근은 더 복잡하거나 더 난독화된 VM으로 갈수록 잘 확장되지 않습니다. 우리는 확장 가능한 워크플로와 실제 프로그램의 디버추얼라이제이션에 관심이 있으므로, 이제 리프팅을 시작해 봅시다.
이미 언급했듯이, 사용 가능한 리프팅 프레임워크와 리프터의 수가 너무 많아 저는 오히려 직접 LLVM C++ API를 사용해 만들기로 했습니다. 그런데 이 부분이 저에게는 꽤 골칫거리였습니다. 제 계획은 각 opcode를 LLVM으로 리프팅해서, 디스어셈블러를 실행하면 가상화된 바이트코드 프로그램을 새로운 LLVM 프로그램으로 리프팅하고, 이를 컴파일해서 IDA에 넣을 수 있게 하는 것이었습니다.
그래서 일반적인 접근은 API를 사용해 LLVM 심볼을 수동으로 내보내는 것이었습니다. 예를 들어 가상 레지스터에서 값을 로드하려면 다음과 같이 했습니다:
1 llvm::LoadInst* reg_val = builder.CreateLoad(i64t, regs[reg]);
이런 구성 요소들을 바탕으로 PUSH_IMM64, JNZ 등의 각 명령어에 대한 LLVM IR 표현을 작성할 수 있었습니다.
기본 파이프라인은 다음과 같습니다:
VM 바이트코드
↓
디스어셈블러
↓
Opcode 스트림
↓
LLVM IR로 리프팅
↓
최적화되지 않은 IR
↓
LLVM 최적화 패스
↓
디버추얼라이즈된 프로그램
그런데 저를 꽤 고민하게 만든 것은 VM 스택을 어떻게 에뮬레이션할지, 아니면 아예 에뮬레이션하지 않을지였습니다.
처음에는 VM 스택을 LLVM 안이 아니라 리프터 자체에 떠넘기려 했습니다. 저는 llvm::Value*들의 std::vector를 두고, 현재 명령어가 어떤 변수를 참조하는지 추적한 다음 그 변수를 삽입하는 방식으로 사용했습니다. 제 생각에는 결과 코드에 스택이 남아 있기를 원하지 않았습니다. 그것은 VM의 일부이기 때문에 LLVM 바깥에 두려 했던 것입니다.
하지만 값을 수동으로 추적하는 방식은 LLVM 자체의 작동을 방해했고 여러 측면에서 SSA 형식을 깨뜨렸습니다. 제 리프터가 유효한 IR을 내놓더라도 최적화가 잘 되지 않았고, 많은 반복에서는 IR이 완전히 망가졌습니다. 최적화 패스는 IR을 대상으로 추론하는데, 제 외부 C++ 북키핑에 대해서는 아무런 통찰도 없기 때문에 많은 패스가 제대로 동작하지 못했습니다. VM 상태의 일부를 외부 C++ 북키핑 구조 안에 숨겨둠으로써, 저는 사실상 의미론을 옵티마이저로부터 숨기고 있었던 셈입니다. dead store elimination, mem2reg, instruction combining 같은 패스는 값의 흐름을 올바르게 추론할 수 없었는데, 실제 의존성이 IR 자체가 아니라 제 리프터 안에만 존재했기 때문입니다.
한동안 이런 식으로 하다가, 결국 그만두고 스택 로직도 LLVM IR 안에 구현하기로 했습니다. 처음에는 이것이 직관에 어긋나는 것처럼 느껴졌습니다. 우리는 스택이 일부를 이루는 가상화 계층을 벗겨내려는 것인데, 왜 그것을 LLVM 코드 안에 구현해야 할까요?
MrExodia showed me how much I underestimated the power of LLVM optimization passes. 제대로 구현하기만 하면, 최적화 패스는 우리가 관심 있는 의미론만 남기고 스택을 완전히 접어 없앨 수 있습니다. 다음의 에뮬레이트된 스택 기반 add 연산에서 실제로 작동하는 모습을 볼 수 있습니다:
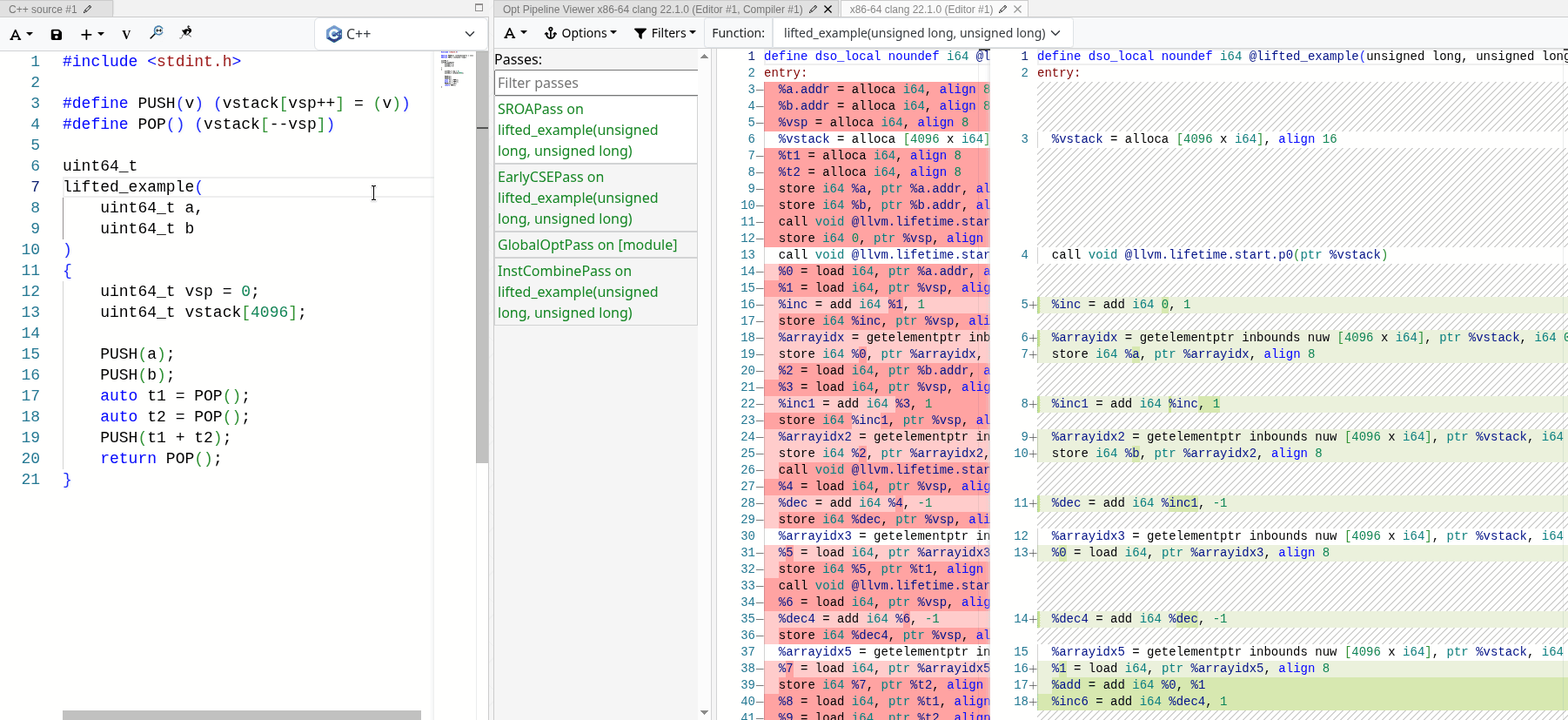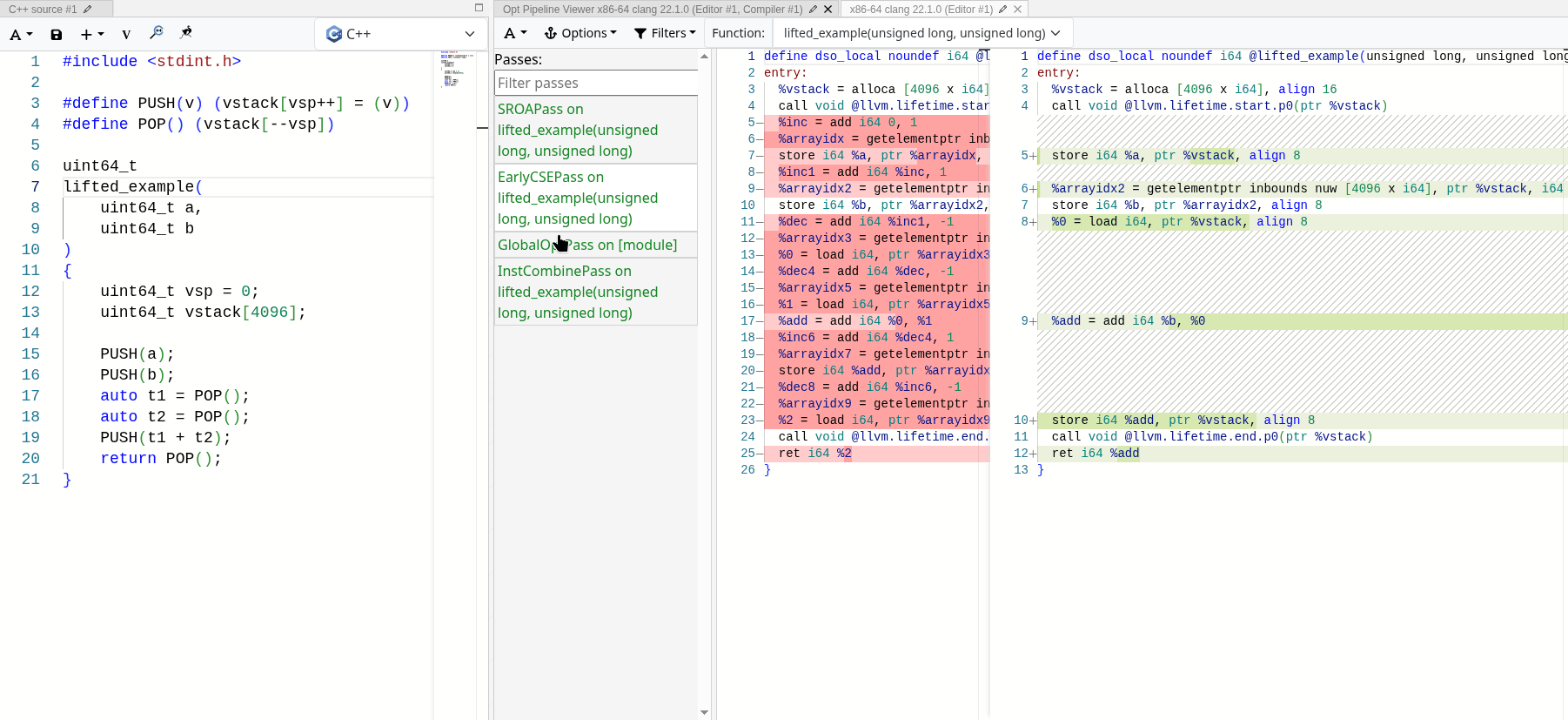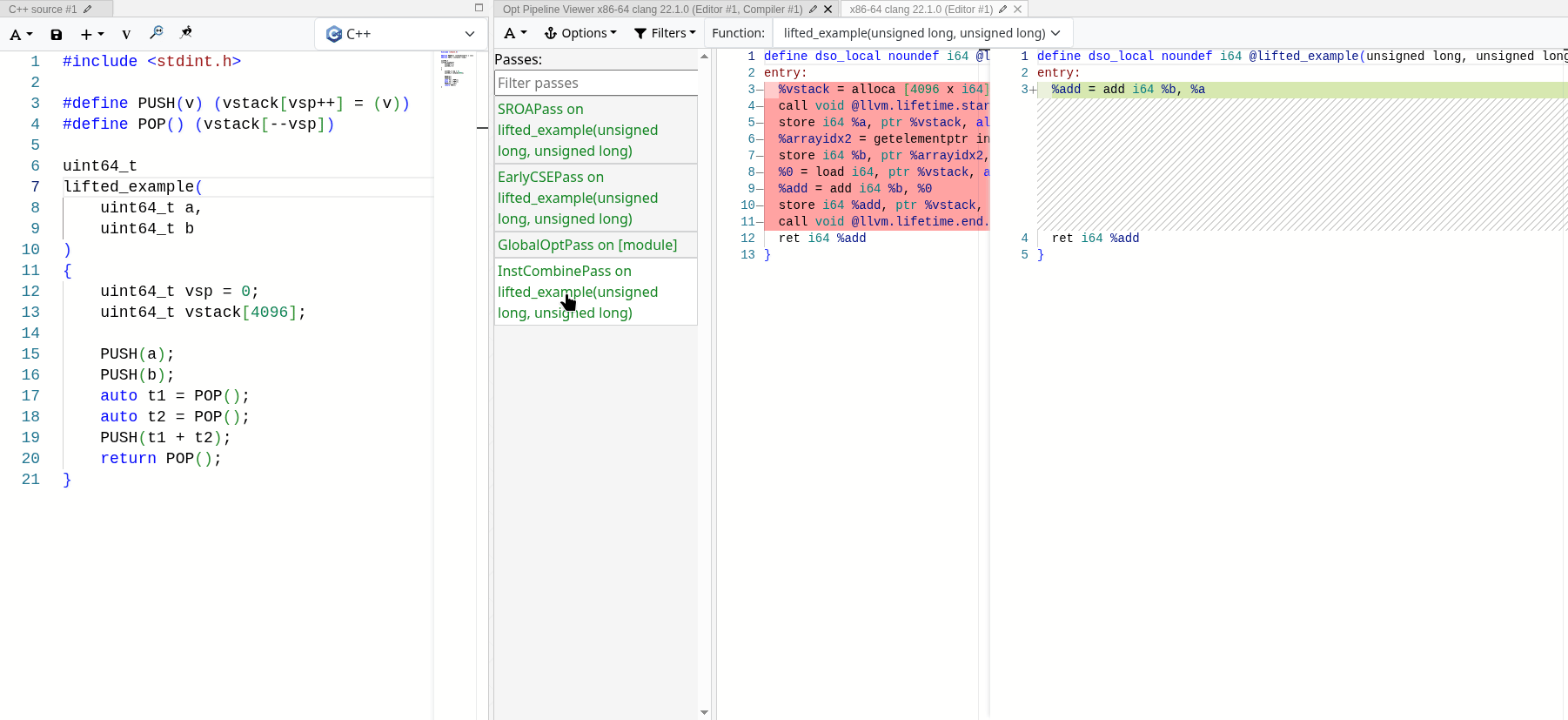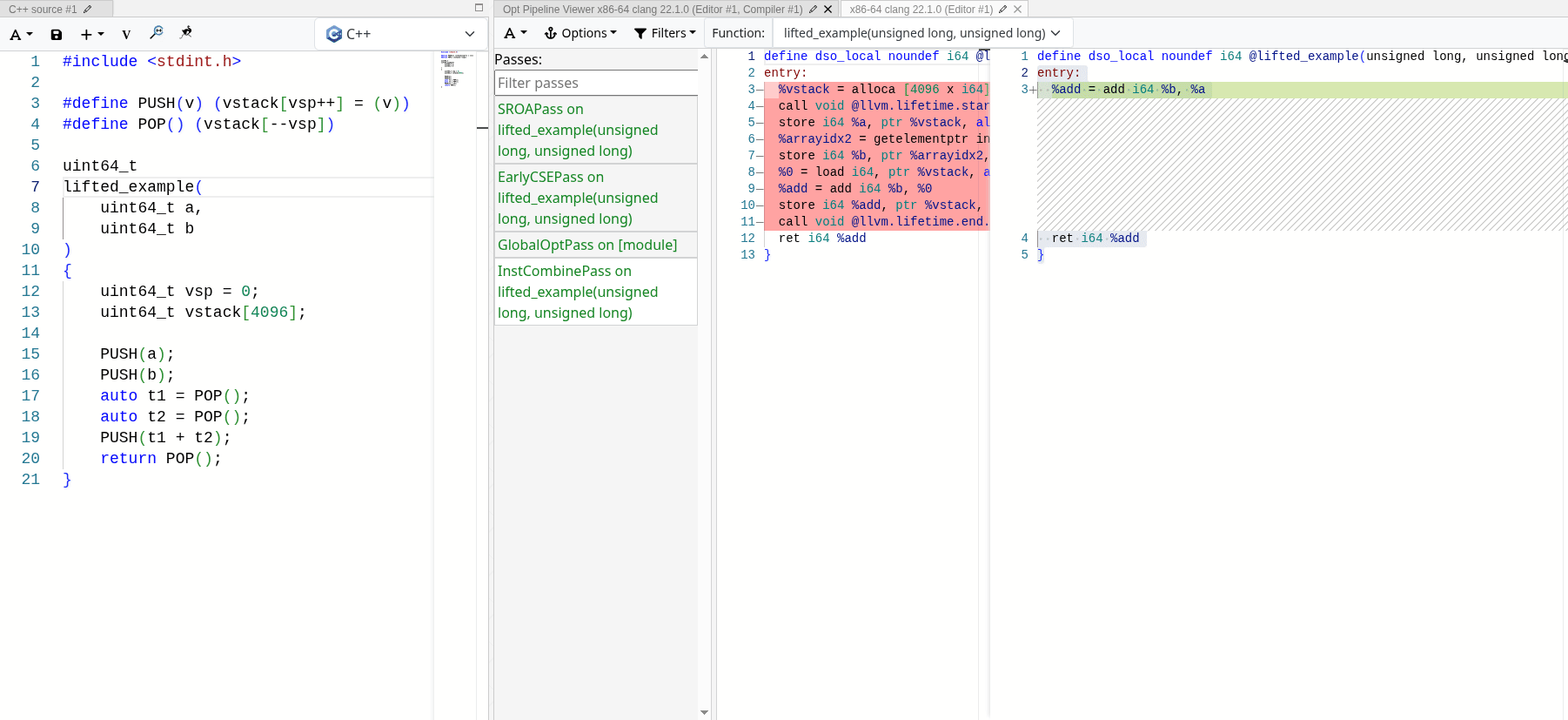
모든 최적화 패스가 끝나고 나면 실제 연산만 남고, 스택 연산은 완전히 제거됩니다. 스택 접근은 모두 지역적이고 결정적이므로, LLVM은 이를 최적화해서 제거하고 에뮬레이트된 스택을 SSA 값으로 접어 넣을 수 있습니다.
이제 VM 스택을 LLVM으로부터 숨길 필요가 없고, 어차피 최적화 과정에서 제거된다는 사실을 알게 되었으므로, 저는 각 opcode 핸들러에 대한 리프팅 함수를 구현해 그에 대응하는 LLVM 명령어를 내보내는 방식으로 구현을 마무리했습니다.
전체 코드는 여기에서 볼 수 있습니다.
이 crackme는 하나의 루틴만 가상화했고 제어 흐름도 비교적 단순했기 때문에, 저는 바이트코드 프로그램 전체를 하나의 LLVM 함수로 모델링했습니다. 입력값을 매개변수로 받고 여러 개의 basic block을 가지는 형태입니다. 스택은 로컬 변수 안의 단순한 메모리 배열이고, VSP는 그것을 가리키는 포인터이며, VM의 레지스터들은 llvm::Value*로 표현했고, 명령어 리프터에서 인덱스로 접근할 수 있도록 리프터 내부의 벡터에 보관했습니다:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27// Flat byte array for the VM stack
// STACK_HEADROOM bytes above cover positive-offset frame accesses (access to caller stack frame)
arrayType = llvm::ArrayType::get(i8t, STACK_SIZE * 8 + STACK_HEADROOM);
// init stack (8byte aligned so i64 stores/loads into it are not UB)
stack = builder.CreateAlloca(arrayType, nullptr, "mem");
stack->setAlignment(llvm::Align(8));
// VSP is tracked as an i64 byte offset from the stack base
// Starts at STACK_SIZE * 8
vsp = builder.CreateAlloca(i64t, nullptr, "vsp");
builder.CreateStore(builder.getInt64(STACK_SIZE * 8), vsp)->setAlignment(llvm::Align(8));
// init registers
regs = std::vectorllvm::Value*(0x11, nullptr);
for (int i = 0; i < regs.size(); ++i)
{
std::string name = "r" + std::to_string(i);
regs.at(i) = builder.CreateAlloca(i64t, nullptr, name);
builder.CreateStore(llvm::ConstantInt::get(i64t, 0), regs.at(i))->setAlignment(llvm::Align(8));
}
// Store function input parameter into r3 (maps to rcx/first argument)
llvm::Value* input = mainFunc->getArg(0);
input->setName("input");
llvm::Value* input64 = builder.CreateZExt(input, i64t, "input_zext");
builder.CreateStore(input64, regs[3])->setAlignment(llvm::Align(8));
그 다음에는 PUSH와 POP 같은 스택 관리 함수를 몇 개 구현해야 했습니다:
1
2
3
4
5
6
7
8
9 void Lifter::vm_push64(llvm::Value* value)
{
// Decrement VSP by 8 bytes (one i64 slot)
llvm::Value* cur_vsp = load_vsp();
llvm::Value* new_vsp = builder.CreateGEP(i8t, cur_vsp, builder.getInt64(-8), "vsp_dec");
store_vsp(new_vsp);
// Store value at new top (new_vsp IS the slot pointer)
builder.CreateStore(value, new_vsp)->setAlignment(llvm::Align(8));
}
이러한 스택 원시 연산을 갖추고 나면, 다양한 opcode를 꽤 직관적으로 모델링할 수 있습니다(이 부분은 이상한 프로그래밍 API를 사용하는 에뮬레이터 개발처럼 느껴졌습니다):
1
2
3
4
5
6
7
8
9
10
11
12
13
14 void Lifter::op_pop64(const uint64_t reg)
{
// Pops a 64 bit value off the stack into the register reg
builder.CreateStore(vm_pop64(), regs.at(reg))->setAlignment(llvm::Align(8));
}
void Lifter::op_push_reg32(const uint64_t reg)
{
// Load full i64 reg, truncate to lower 32 bits, then push
llvm::LoadInst* reg_val = builder.CreateLoad(i64t, regs[reg]);
reg_val->setAlignment(llvm::Align(8));
llvm::Value* reg_val32 = builder.CreateTrunc(reg_val, i32t, "trunc32");
vm_push32(reg_val32);
}
특별히 주의를 기울여야 하는 명령어는 실제로 제어 흐름을 만드는 유일한 명령어인 JNZ입니다. 점프 대상에 basic block을 만들기 위해, 저는 두 단계 리프팅 파이프라인을 구현했습니다. 첫 번째 단계에서는 점프 대상과 그 "fallthrough" 블록들에 basic block을 만듭니다(LLVM에는 고전적 의미의 fallthrough block이 없고, 명시적인 점프만 있습니다. 따라서 fallthrough도 명시적으로 만들어야 합니다):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22// First pass: create basic blocks for JNZ targets and their fallthroughs
std::unordered_map<uint64_t, llvm::BasicBlock*> addr_to_bb;
for (size_t i = 0; i < instructions.size(); ++i)
{
const auto& inst = instructions[i];
if (inst.name == "JNZ")
{
// BB for the JNZ target address
uint64_t target_addr = inst.operands[0];
if (addr_to_bb.find(target_addr) == addr_to_bb.end())
addr_to_bb[target_addr] = llvm::BasicBlock::Create(context, "bb_" + std::to_string(target_addr), mainFunc);
// BB for the fallthrough (instruction immediately after JNZ)
if (i + 1 < instructions.size())
{
uint64_t ft_addr = instructions[i + 1].vip;
if (addr_to_bb.find(ft_addr) == addr_to_bb.end())
addr_to_bb[ft_addr] = llvm::BasicBlock::Create(context, "bb_" + std::to_string(ft_addr), mainFunc);
}
}
}
두 번째 단계에서는 디스어셈블러 루프 안의 큰 조건문이 opcode에 해당하는 LLVM IR을 내보내도록 처리합니다:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19 if (inst.name == "PUSH_REG64")
op_push_reg64(inst.operands[0]);
else if (inst.name == "PUSH_REG32")
op_push_reg32(inst.operands[0]);
else if (inst.name == "PUSH_VSP64")
op_push_vsp64();
else if (inst.name == "POP64")
op_pop64(inst.operands[0]);
else if (inst.name == "POP32")
op_pop32(inst.operands[0]);
else if (inst.name == "PUSH_IMM64")
op_push_imm64(inst.operands[0]);
else if (inst.name == "PUSH_IMM32")
op_push_imm32(inst.operands[0]);
else if (inst.name == "SUB64")
op_sub64();
else if (inst.name == "ADD64")
op_add64();
// [...]
JNZ 명령어는 첫 번째 단계에서 생성했던 basic block들을 단순히 연결합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 else if (inst.name == "JNZ")
{
// Find target BB
uint64_t target_addr = inst.operands[0];
auto tgt_it = addr_to_bb.find(target_addr);
llvm::BasicBlock* target_bb = tgt_it->second;
// Find fallthrough
uint64_t ft_addr = instructions[i + 1].vip;
auto ft_it = addr_to_bb.find(ft_addr);
llvm::BasicBlock* fallthrough_bb = ft_it->second;
// Create branches for target BB and fallthrough BB
llvm::Value* zf = vm_pop64();
llvm::Value* is_nz = builder.CreateICmpEQ(zf, builder.getInt64(0), "jnz_cond"); // here zf==0 means not zero
builder.CreateCondBr(is_nz, target_bb, fallthrough_bb);
}
이 리프팅이 끝나면 LLVM의 llvm::verifyFunction API를 사용해 함수가 유효한 IR인지 검증하고, 결과 IR에 최적화 패스를 적용합니다:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 void Lifter::optimize()
{
llvm::PassBuilder PB;
llvm::LoopAnalysisManager LAM;
llvm::FunctionAnalysisManager FAM;
llvm::CGSCCAnalysisManager CGAM;
llvm::ModuleAnalysisManager MAM;
PB.registerModuleAnalyses(MAM);
PB.registerCGSCCAnalyses(CGAM);
PB.registerFunctionAnalyses(FAM);
PB.registerLoopAnalyses(LAM);
PB.crossRegisterProxies(LAM, FAM, CGAM, MAM);
llvm::ModulePassManager MPM = PB.buildPerModulQeDefaultPipeline(llvm::OptimizationLevel::O1);
MPM.run(*module, MAM);
}
최적화 전의 IR은 약 8000줄에 달하는 스택 셔플링과 메모리 접근으로 이루어져 있었습니다:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// [...]
%vsp_dec248 = add i64 %vsp_off247, -8
store i64 %vsp_dec248, ptr %vsp, align 8
%121 = getelementptr i8, ptr %mem, i64 %vsp_dec248
store i64 35, ptr %121, align 8
%vsp_off249 = load i64, ptr %vsp, align 8
%122 = getelementptr i8, ptr %mem, i64 %vsp_off249
%popped64250 = load i64, ptr %122, align 8
%popped32251 = trunc i64 %popped64250 to i32
%vsp_inc252 = add i64 %vsp_off249, 8
store i64 %vsp_inc252, ptr %vsp, align 8
%vsp_off253 = load i64, ptr %vsp, align 8
%123 = getelementptr i8, ptr %mem, i64 %vsp_off253
%popped64254 = load i64, ptr %123, align 8
%popped32255 = trunc i64 %popped64254 to i32
// [...]
-O1 최적화 후, 최종 IR 전체는 다음과 같이 바뀌었습니다:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20; ModuleID = 'byteshield_module'
source_filename = "byteshield_module"
; Function Attrs: mustprogress nofree norecurse nosync nounwind willreturn memory(none)
define i32 @main(i32 %input) local_unnamed_addr #0 {
main:
%zf1168 = icmp eq i32 %input, 1859
%zf1764 = icmp eq i32 %input, 2418
%narrow = or i1 %zf1764, %zf1168
%zf2362 = icmp eq i32 %input, 1638
%narrow5460 = or i1 %zf2362, %narrow
%zf3003 = icmp eq i32 %input, 299902
%zf3694 = icmp eq i32 %input, 29763
%0 = or i1 %zf3694, %zf3003
%narrow5462 = select i1 %0, i1 true, i1 %narrow5460
%mem.sroa.579.4.off32 = zext i1 %narrow5462 to i32
ret i32 %mem.sroa.579.4.off32
}
attributes #0 = { mustprogress nofree norecurse nosync nounwind willreturn memory(none) }
이제 남은 것은 결과 .ll 파일을 다음과 같이 실행 파일로 컴파일하는 것뿐이었습니다.
clang
devirt.ll -o program
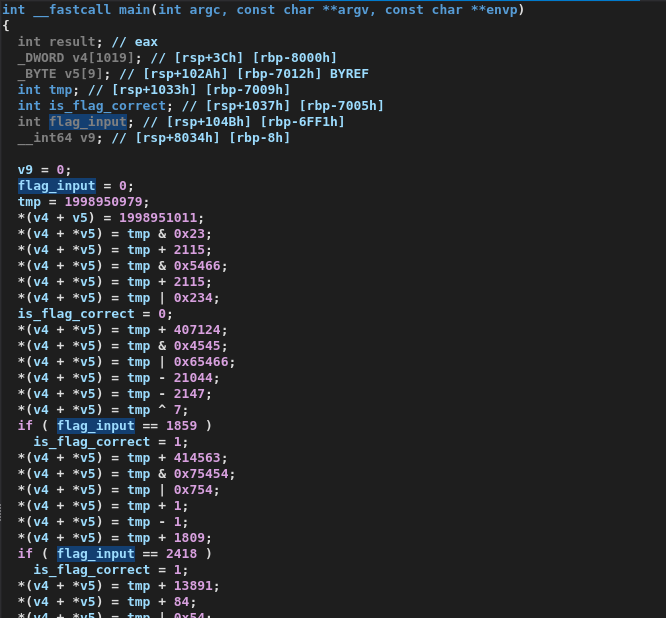
. 우리는 바이트코드를 완전히 디버추얼라이즈했습니다! 그 다음 저는 디버추얼라이즈된 프로그램을 IDA에서 분석할 수 있었고, 모든 계산 로직이 접혀 사라져 플래그 검사만 남았습니다:

이전에 실패했던 시도 중 하나는 바이트코드가 실제로 무엇을 하는지 보여주었습니다. 대부분의 플래그는 하드코딩되어 있었고, 단 하나의 플래그만 다양한 산술 연산에 의존했습니다. (이전의 결함 있는 접근에서는 스택을 올바르게 모델링하지 못했기 때문에 이것이 접혀 사라지지 않았습니다):
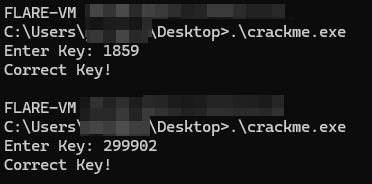
키를 시험해 보면 crackme를 제대로 풀었는지 확인할 수 있습니다:
이것이 제가 LLVM IR을 직접 내보내 본 첫 경험이었기 때문에, LLVM IR이 어떻게 구성되는지와 그 함정들에 대해 꽤 많은 것을 배웠습니다.
가장 중요한 점은 LLVM이 최적화의 마법을 부릴 수 있도록, 올바르면서도 최적화 가능하게 IR을 내보내는 것입니다. 의미론이 LLVM IR에 정확하게 표현되기만 하면, LLVM의 최적화 패스는 가상화의 큰 부분을 자동으로 제거할 수 있습니다.
디버추얼라이제이션과 리프팅은 재미있습니다. 해보고 싶다면 이 crackme에 꼭 도전해 보시길 권합니다.
즐거운 해킹 되세요!
Next: Driver Reverse Engineering 101 - Part I: Static Analysis

Reverse Engineer, Malware Researcher, Windows Kernel Enthusiast
Content
Powered by Hexo | Theme based on Bamboo | logo by @01Xyris<3
