외부 상태 변경이 포함된 API 요청을 안전하게 재시도할 수 있도록, Postgres와 원자적 단계(atomic phases)를 이용해 Stripe처럼 멱등성 키를 구현하는 방법을 Rocket Rides 예제로 설명한다.
URL: https://brandur.org/idempotency-keys
API에서 멱등성(idempotency)은 강력한 개념이다. 멱등 엔드포인트는 몇 번을 호출하더라도 부작용(side effect)이 오직 한 번만 발생함을 보장한다. 클라이언트와 서버가 가끔 크래시하거나 요청 도중 연결이 끊어질 수 있는 지저분한 현실에서, 멱등성은 시스템을 장애에 훨씬 강하게 만들어준다. 요청이 성공했는지 실패했는지 확신할 수 없는 클라이언트는, 확정적인 응답을 받을 때까지 같은 요청을 계속 재시도하면 된다.
이 글에서 보겠지만, 서버의 모든 요청을 완벽하게 멱등하게 만들기는 항상 쉽지 않다. 로컬의 ACID 데이터베이스 안에서만 상태를 변경하는 엔드포인트라면, 내가 몇 주 전에 더 자세히 썼던 것처럼 요청을 트랜잭션에 매핑하는 방식으로 견고하면서도 단순한 멱등성 구현이 가능하다. 이 접근은 여기서 설명할 것보다 훨씬 쉽고 덜 복잡하며, 가능하다면 그 길을 택하길 권한다.
로컬 ACID 저장소 바깥(즉, 외부 상태)에서 동기적으로 변경을 일으켜야 하는 구현은 설계가 다소 더 어렵다. 기본적인 예로, 앱이 Stripe에 결제 생성(charge) 요청을 보내고 그것이 실제로 처리됐는지 요청 흐름(in-band) 안에서 알아야 하는 경우가 있다. 그래야 어떤 상품이나 서비스를 제공할지 결정할 수 있다. 이런 타입의 엔드포인트에서 멱등성을 보장하려면 멱등성 키(idempotency keys)를 도입해야 한다.
멱등성 키는 클라이언트가 생성해 요청과 함께 API로 전송하는 유일한 값이다. 서버는 그 키를 저장해 해당 요청의 상태를 추적(장부 기록)하는 데 사용한다. 요청이 중간에 실패하면 클라이언트는 같은 멱등성 키 값으로 재시도하고, 서버는 그 키로 요청의 상태를 조회해 중단된 지점에서 이어서 처리한다. “멱등성 키”라는 이름은 Stripe API에서 유래했다.
멱등성 키는 보통 HTTP 헤더로 전달한다:
POST /v1/charges
...
Idempotency-Key: 0ccb7813-e63d-4377-93c5-476cb93038f3
...
amount=1000¤cy=usd
서버가 요청이 성공 또는 복구 불가능한 방식의 실패로 확정적으로 끝났음을 알게 되면, 요청 결과를 저장하고 그 결과를 멱등성 키에 연결한다. 클라이언트가 같은 키로 다시 요청하면 서버는 즉시(short circuit) 저장된 결과를 반환한다.
키는 영구적인 요청 아카이브가 아니라 단기적인 정확성을 보장하기 위한 메커니즘이다. 서버는 유용성이 떨어지는 시점(예: 24시간 정도)을 지나면 시스템에서 키를 회수(recycle)해야 한다.
레퍼런스 구현을 만들어 보면서 API에 멱등성 키를 설계하는 방법을 살펴보자.
Stripe의 훌륭한 개발자 관계(dev relations) 팀은 Connect 플랫폼과 API의 다른 흥미로운 부분을 보여주기 위해 Rocket Rides라는 앱을 만들었다. Rocket Rides에서 급한 사용자들은 제트팩 자격증을 가진 파일럿과 함께 라이드(ride)를 공유해 목적지까지 빠르게 이동한다. SOMA의 꽉 막힌 교통 체증은 처참히 뒤로 멀어지고, 새하얀 하늘을 가르며 자유롭게 날아간다. 이동은 Lyft보다 약간 위험할 수 있으니, 여분의 낙하산을 챙기자.
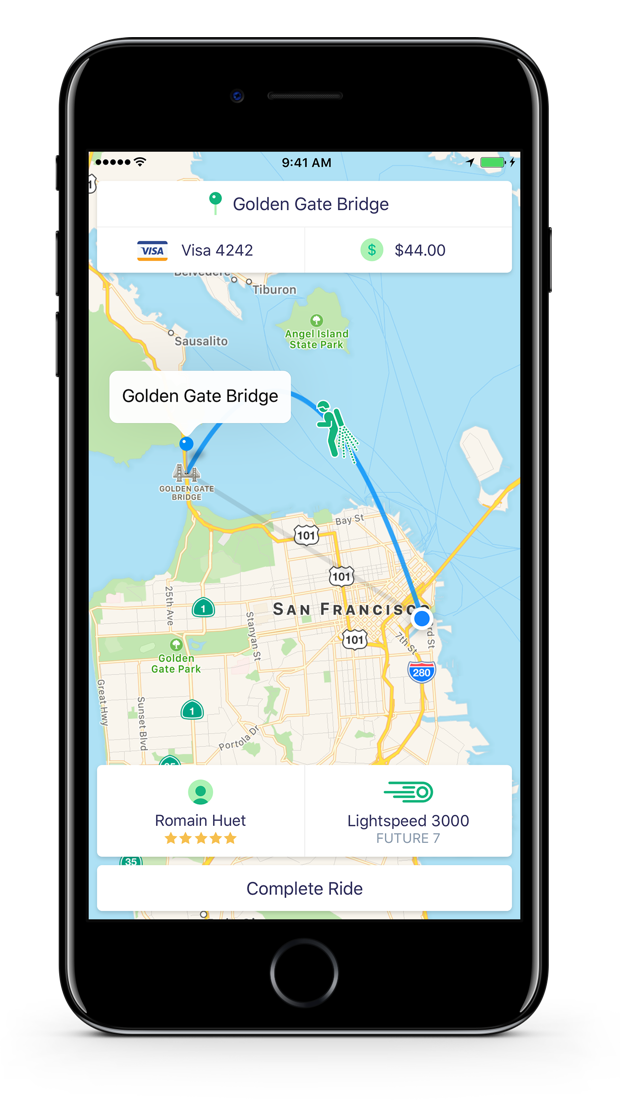
Rocket Rides 앱.
Rocket Rides 저장소에는 간단한 서버 구현이 포함돼 있지만, 소프트웨어는 시간이 지나며 커지기 마련이다. 그래서 15명의 엔지니어와 반 다스의 프로덕트 오너가 있는 실제 서비스에 더 가깝게 만들기 위해, 여기서는 몇 가지 장식을 더해 복잡도를 높여 보겠다.
새 라이드 요청이 들어오면 다음 작업을 수행한다:

장식이 추가된 Rocket Rides 백엔드로 들어오는 전형적인 API 요청.
우리 백엔드는 Rocket Rides 모바일 앱에서 멱등성 키와 함께 호출된다. 요청이 실패하면 앱은 같은 키로 계속 재시도할 것이고, 백엔드 구현자인 우리의 일은 이것이 안전하도록 보장하는 것이다. 요청 과정에서 사용자 신용카드를 청구할 것이므로, 두 번 청구되는 위험은 절대 감수할 수 없다.
대부분의 경우 Rocket Rides API 호출은 순조롭게 진행되고 모든 작업이 문제 없이 성공할 것이다. 하지만 하루 수천 건 규모가 되면 여기저기서 문제가 나타나기 시작한다. 셀룰러 연결 품질 때문에 요청이 실패하거나, Stripe 호출이 가끔 실패하거나, 초음속으로 날 때 생기는 난기류 때문에 사용자가 주기적으로 오프라인이 될 수도 있다. 하루 수백만 건 규모가 되면 기본적인 확률만으로도 이런 일이 상시 발생하게 된다.
다음은 발생할 수 있는 문제들의 예시다:
이제 전제를 갖췄으니, 이 문제를 우아하게 해결할 아이디어들을 소개하겠다.
백엔드를 튼튼하게 만들기 위해서는 어디에서 외부 상태 변경(foreign state mutations)을 하는지 파악하는 것이 핵심이다. 즉, 다른 시스템을 호출해 그 시스템의 데이터를 조작하는 지점이다. 예를 들어 Stripe에 charge를 만들거나, DNS 레코드를 추가하거나, 이메일을 보내는 작업 등이 해당된다.
어떤 외부 상태 변경은 본질적으로 멱등이다(예: DNS 레코드 추가). 어떤 것은 멱등이 아니지만 멱등성 키를 통해 멱등하게 만들 수 있다(예: Stripe 결제, 이메일 전송). 또 어떤 것은 멱등이 아니며(대부분은 외부 서비스가 그렇게 설계하지 않았고 멱등성 키 같은 메커니즘을 제공하지 않기 때문에) 멱등하게 만들기도 어렵다.
로컬 vs 외부의 구분이 중요한 이유는, 로컬 작업은 ACID 저장소를 이용해 마음에 들지 않는 결과를 롤백할 수 있지만, 첫 번째 외부 상태 변경을 수행하는 순간부터는 어느 쪽이든 되돌리기 어렵게 “커밋”되기 때문이다1. 우리 경계를 넘어선 시스템에 데이터를 밀어 넣었고, 그것을 추적에서 놓치면 안 된다.
Stripe 호출을 흔한 예로 들지만, 여러분 인프라 내부의 외부 호출도 전부 포함된다는 점을 기억하자. Kafka에 레코드를 emit하는 것을, 성공률이 워낙 높아 마치 원자적 작업의 일부처럼 취급하고 싶을 수 있다. 하지만 아니다. 다른 오류가 날 수 있는 외부 상태 변경과 똑같이 취급해야 한다.
원자적 단계(atomic phase)란 외부 상태 변경 사이에 존재하는, 트랜잭션 안에서 수행되는 로컬 상태 변경들의 묶음이다. Postgres 같은 ACID 준수 DB를 이용해 “전부 수행되거나, 아니면 하나도 수행되지 않음”을 보장할 수 있으므로 원자적이라고 부른다.
원자적 단계는 외부 상태 변경을 시작하기 전에 안전하게 커밋돼야 한다. 외부 호출이 실패하더라도 로컬 상태에는 그 호출이 일어나려 했다는 기록이 남아, 재시도에 사용할 수 있다.
복구 지점(recovery point)은 어떤 원자적 단계 또는 외부 상태 변경을 성공적으로 실행한 뒤 도달하는 체크포인트의 이름이다. 목적은 재시도되는 요청이 마지막 시도에서 실패한 직전 지점으로 되돌아가(정확히는 그 지점부터) 재개할 수 있게 하는 것이다.
편의상, 우리가 만들 멱등성 키 테이블에 도달한 복구 지점 이름을 저장하겠다. 모든 요청은 처음에 started 복구 지점을 갖고, 요청이 완료되면(성공이든 확정 실패든) finished로 설정된다. 원자적 단계 안에 있을 때 복구 지점 전이는 해당 단계의 트랜잭션 일부로 커밋되어야 한다.
요청 흐름(in-band)에서 외부 상태 변경을 수행하면 요청이 느려지고 추론하기도 어려워지므로, 가능하면 피해야 한다. 많은 경우 요청이 끝난 뒤 백그라운드 잡 큐로 보내 작업을 미룰 수 있다.
Rocket Rides 예제에서는 Stripe 결제는 아마 미룰 수 없다. 성공 여부를 즉시 알아야 하고, 실패하면 요청을 거부해야 한다. 반면 이메일 전송은 미룰 수 있고 미루는 편이 좋다.
트랜잭션으로 스테이징되는 잡 드레인(transactionally-staged job drain)을 사용하면, 트랜잭션으로 잡을 격리함으로써 “작업할 준비가 됐는지” 확인하기 전까지 워커에게 잡이 보이지 않게 할 수 있다. 이는 백그라운드 작업을 원자적 단계의 일부로 만들며 운영 특성을 크게 단순화한다. 가능하다면 언제나 작업을 백그라운드 큐로 오프로딩해야 한다.
몇 가지 핵심 개념을 다뤘으니, 이제 상상 가능한 어떤 장애에도 견딜 수 있도록 Rocket Rides를 강화해 보자. 기본 스키마를 만들고, 라이프사이클을 원자적 단계로 나누고, 장애에서 복구할 수 있는 간단한 구현을 조립하겠다.
이 모든 것(테스트 포함)의 동작하는 버전은 Atomic Rocket Rides 저장소에서 볼 수 있다. 코드를 내려받아 따라가는 편이 더 쉬울 수도 있다.
git clone https://github.com/brandur/rocket-rides-atomic.git
앱에서 멱등성 키를 위한 Postgres 스키마를 설계해 보자:
CREATE TABLE idempotency_keys (
id BIGSERIAL PRIMARY KEY,
created_at TIMESTAMPTZ NOT NULL DEFAULT now(),
idempotency_key TEXT NOT NULL
CHECK (char_length(idempotency_key) <= 100),
last_run_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
locked_at TIMESTAMPTZ DEFAULT now(),
-- parameters of the incoming request
request_method TEXT NOT NULL
CHECK (char_length(request_method) <= 10),
request_params JSONB NOT NULL,
request_path TEXT NOT NULL
CHECK (char_length(request_path) <= 100),
-- for finished requests, stored status code and body
response_code INT NULL,
response_body JSONB NULL,
recovery_point TEXT NOT NULL
CHECK (char_length(recovery_point) <= 50),
user_id BIGINT NOT NULL
);
CREATE UNIQUE INDEX idempotency_keys_user_id_idempotency_key
ON idempotency_keys (user_id, idempotency_key);
여기서 눈여겨볼 필드 몇 가지:
idempotency_key: 사용자가 지정한 멱등성 키. UUID처럼 랜덤성이 좋은 값을 보내는 것이 좋은 관행이지만 필수는 아니다. 너무 특이한 값을 보내지 못하도록 길이를 제한했다.idempotency_key는 유니크로 만들었지만 (user_id, idempotency_key) 조합에 대해 유니크로 만들었다. 서로 다른 사용자 계정이라면 같은 멱등성 키 값을 사용할 수 있도록 하기 위함이다.
locked_at: 현재 이 멱등성 키가 작업 중인지 나타내는 필드. 처음 키를 만드는 API 요청은 자동으로 잠그고, 이후 재시도도 같은 키를 사용해 재잠금함으로써 단 하나의 요청만 작업을 수행하도록 한다.
params: 요청의 입력 파라미터. 같은 멱등성 키로 서로 다른 파라미터의 요청을 보내는 경우를 에러 처리하기 위해 저장한다. 또한 미완료 요청을 백엔드가 자체적으로 끝까지 밀어붙이는 데도 사용할 수 있다(아래 completionist 참고).
recovery_point: 멱등 요청에서 마지막으로 완료된 단계의 텍스트 라벨(위의 복구 지점 참고). 초기 값은 started이며 요청이 완료된 것으로 간주되면 finished로 설정된다.
앞서 Rocket Rides의 목표 API 라이프사이클을 떠올려 보자.
장식이 추가된 Rocket Rides 백엔드로 들어오는 전형적인 API 요청.
감사 레코드, 라이드, 사용자 등 이 앱을 만들기 위해 필요한 나머지 Postgres 테이블들을 만들자. 신뢰성을 극대화하려는 목표에 맞춰, 가능한 한 NOT NULL, 유니크, 외래 키 제약을 최대한 활용하겠다.
--
-- A relation to hold records for every user of our app.
--
CREATE TABLE users (
id BIGSERIAL PRIMARY KEY,
email TEXT NOT NULL UNIQUE
CHECK (char_length(email) <= 255),
-- Stripe customer record with an active credit card
stripe_customer_id TEXT NOT NULL UNIQUE
CHECK (char_length(stripe_customer_id) <= 50)
);
--
-- Now that we have a users table, add a foreign key
-- constraint to idempotency_keys which we created above.
--
ALTER TABLE idempotency_keys
ADD CONSTRAINT idempotency_keys_user_id_fkey
FOREIGN KEY (user_id) REFERENCES users(id) ON DELETE RESTRICT;
--
-- A relation that hold audit records that can help us piece
-- together exactly what happened in a request if necessary
-- after the fact. It can also, for example, be used to
-- drive internal security programs tasked with looking for
-- suspicious activity.
--
CREATE TABLE audit_records (
id BIGSERIAL PRIMARY KEY,
-- action taken, for example "created"
action TEXT NOT NULL
CHECK (char_length(action) <= 50),
created_at TIMESTAMPTZ NOT NULL DEFAULT now(),
data JSONB NOT NULL,
origin_ip CIDR NOT NULL,
-- resource ID and type, for example "ride" ID 123
resource_id BIGINT NOT NULL,
resource_type TEXT NOT NULL
CHECK (char_length(resource_type) <= 50),
user_id BIGINT NOT NULL
REFERENCES users ON DELETE RESTRICT
);
--
-- A relation representing a single ride by a user.
-- Notably, it holds the ID of a successful charge to
-- Stripe after we have one.
--
CREATE TABLE rides (
id BIGSERIAL PRIMARY KEY,
created_at TIMESTAMPTZ NOT NULL DEFAULT now(),
-- Store a reference to the idempotency key so that we can recover an
-- already-created ride. Note that idempotency keys are not stored
-- permanently, so make sure to SET NULL when a referenced key is being
-- reaped.
idempotency_key_id BIGINT
REFERENCES idempotency_keys ON DELETE SET NULL,
-- origin and destination latitudes and longitudes
origin_lat NUMERIC(13, 10) NOT NULL,
origin_lon NUMERIC(13, 10) NOT NULL,
target_lat NUMERIC(13, 10) NOT NULL,
target_lon NUMERIC(13, 10) NOT NULL,
-- ID of Stripe charge like ch_123; NULL until we have one
stripe_charge_id TEXT UNIQUE
CHECK (char_length(stripe_charge_id) <= 50),
user_id BIGINT NOT NULL
REFERENCES users ON DELETE RESTRICT,
CONSTRAINT rides_user_id_idempotency_key_unique UNIQUE (user_id, idempotency_key_id)
);
CREATE INDEX rides_idempotency_key_id
ON rides (idempotency_key_id)
WHERE idempotency_key_id IS NOT NULL;
--
-- A relation that holds our transactionally-staged jobs
-- (see "Background jobs and job staging" above).
--
CREATE TABLE staged_jobs (
id BIGSERIAL PRIMARY KEY,
job_name TEXT NOT NULL,
job_args JSONB NOT NULL
);
데이터가 어떤 형태여야 할지 감이 잡혔으니, API 요청을 구분된 원자적 단계로 나눠 보자. 이를 식별하는 기본 규칙은 다음과 같다:
따라서 이 예제에서는 멱등성 키 삽입(tx1)과 Stripe 결제 호출 및 결과 저장(tx3)을 위한 원자적 단계가 있고, tx1과 tx3 주변의 나머지 작업은 tx2, tx4 두 단계로 묶인다. tx2~tx4는 각각 직전 트랜잭션이 커밋하며 설정한 복구 지점(started, ride_created, charge_created)에서 도달할 수 있다.

외부 상태 변경과 원자적 단계로 분해된 Rocket Rides API 요청.
원자적 단계 구현은 모든 것을 트랜잭션 블록으로 감싼다(루비를 사용하지만, 이 개념은 어떤 언어에서도 가능하다). 그리고 각 단계는 세 가지 반환 옵션 중 하나를 가진다:
RecoveryPoint. 나머지 단계 로직과 같은 트랜잭션 안에서 수행되어 원자성이 보장된다. 실행은 다음 단계로 정상 진행된다.finished로 설정하고 사용자에게 응답을 돌려주는 Response. 정상 성공 조건에서 사용되며, 복구 불가능한 에러로 조기 반환할 때도 사용된다. 예를 들어 사용자 카드가 유효하지 않다면, 아무리 재시도해도 성공하지 못한다.NoOp.코드를 너무 자세히 해석할 필요는 없지만, 대략 이런 모습이다:
def atomic_phase(key, &block)
error = false
begin
DB.transaction(isolation: :serializable) do
ret = block.call
if ret.is_a?(NoOp) || ret.is_a?(RecoveryPoint) || ret.is_a?(Response)
ret.call(key)
else
raise "Blocks to #atomic_phase should return one of " \
"NoOp, RecoveryPoint, or Response"
end
end
rescue Sequel::SerializationFailure
# you could possibly retry this error instead
error = true
halt 409, JSON.generate(wrap_error(Messages.error_retry))
rescue
error = true
halt 500, JSON.generate(wrap_error(Messages.error_internal))
ensure
# If we're leaving under an error condition, try to unlock the idempotency
# key right away so that another request can try again.
if error && !key.nil?
begin
key.update(locked_at: nil)
rescue StandardError
# We're already inside an error condition, so swallow any additional
# errors from here and just send them to logs.
puts "Failed to unlock key #{key.id}."
end
end
end
end
# Represents an action to perform a no-op. One possible option for a return
# from an #atomic_phase block.
class NoOp
def call(_key)
# no-op
end
end
# Represents an action to set a new recovery point. One possible option for a
# return from an #atomic_phase block.
class RecoveryPoint
attr_accessor :name
def initialize(name)
self.name = name
end
def call(key)
raise ArgumentError, "key must be provided" if key.nil?
key.update(recovery_point: name)
end
end
# Represents an action to set a new API response (which will be stored onto an
# idempotency key). One possible option for a return from an #atomic_phase
# block.
class Response
attr_accessor :data
attr_accessor :status
def initialize(status, data)
self.status = status
self.data = data
end
def call(key)
raise ArgumentError, "key must be provided" if key.nil?
key.update(
locked_at: nil,
recovery_point: RECOVERY_POINT_FINISHED,
response_code: status,
response_body: data
)
end
end
직렬화 오류가 나면 거의 확실히 동시 요청이 충돌했다는 뜻이므로 다음을 반환한다:
409
Conflict
실제 앱에서는 이번에는 성공할 가능성이 높으니 즉시 재시도하는 편이 좋을 것이다.
그 외 오류는 500 Internal Server Error를 반환한다. 어떤 오류든, 끝나기 전에 멱등성 키를 언락해 다른 요청이 재시도할 기회를 갖도록 한다.
새 멱등성 키 값이 API로 들어오면, 진행 상황을 추적할 행을 생성하거나 업데이트한다.
가장 쉬운 경우는 이 키를 처음 보는 경우다. 적절한 값으로 새 행을 삽입하면 된다.
이미 본 적이 있는 키라면, 동시 실행 중인 다른 요청이 같은 작업을 하지 못하도록 키를 잠근다. 키가 이미 잠겨 있었다면 사용자에게 다음을 반환한다:
409
Conflict
이미 finished인 키는 그대로 흐름을 타고, 표준 성공 경로에서 저장된 응답을 반환하게 된다. 곧 보게 된다.
key = nil
atomic_phase(key) do
key = IdempotencyKey.first(user_id: user.id, idempotency_key: key_val)
if key
# Programs sending multiple requests with different parameters but the
# same idempotency key is a bug.
if key.request_params != params
halt 409, JSON.generate(wrap_error(Messages.error_params_mismatch))
end
# Only acquire a lock if the key is unlocked or its lock has expired
# because the original request was long enough ago.
if key.locked_at && key.locked_at > Time.now - IDEMPOTENCY_KEY_LOCK_TIMEOUT
halt 409, JSON.generate(wrap_error(Messages.error_request_in_progress))
end
# Lock the key and update latest run unless the request is already
# finished.
if key.recovery_point != RECOVERY_POINT_FINISHED
key.update(last_run_at: Time.now, locked_at: Time.now)
end
else
key = IdempotencyKey.create(
idempotency_key: key_val,
locked_at: Time.now,
recovery_point: RECOVERY_POINT_STARTED,
request_method: request.request_method,
request_params: Sequel.pg_jsonb(params),
request_path: request.path_info,
user_id: user.id,
)
end
# no response and no need to set a recovery point
NoOp.new
end
겉보기엔 거의 동시에 들어온 두 요청이 같은 키를 잠그려 할 때 안전하지 않아 보일 수 있지만, 원자적 단계가 SERIALIZABLE 트랜잭션으로 감싸져 있으므로 안전하다. 두 트랜잭션이 하나의 키를 잠그려 하면 Postgres가 그중 하나를 중단(abort)시킨다.
나머지 API 요청은 상태들이 유향 비순환 그래프(DAG) 형태인 간단한 상태 머신으로 구현한다. DAG는 일반 그래프와 달리 한 방향으로만 움직이고, 자기 자신으로 되돌아오는 사이클이 없다.
각 원자적 단계는 복구 지점에서 활성화된다. 복구 지점은 복구된 멱등성 키에서 읽어오거나, 이전 원자적 단계가 설정한 값이다. finished 상태에 도달할 때까지 단계를 진행하고, finished에 도달하면 루프를 탈출해 사용자에게 응답을 반환한다.
이미 finished인 멱등성 키는 루프에 들어오자마자 즉시 빠져나와 저장된 응답을 그대로 반환한다.
loop do
case key.recovery_point
when RECOVERY_POINT_STARTED
atomic_phase(key) do
...
end
when RECOVERY_POINT_RIDE_CREATED
atomic_phase(key) do
...
end
when RECOVERY_POINT_CHARGE_CREATED
atomic_phase(key) do
....
end
when RECOVERY_POINT_FINISHED
break
else
raise "Bug! Unhandled recovery point '#{key.recovery_point}'."
end
# If we got here, allow the loop to move us onto the next phase of the
# request. Finished requests will break the loop.
end
[key.response_code, JSON.generate(key.response_body)]
두 번째 단계(위 다이어그램의 tx2)는 단순하다. 로컬 DB에 ride 레코드를 만들고, audit 레코드를 삽입하고, 복구 지점을 ride_created로 설정한다.
atomic_phase(key) do
ride = Ride.create(
idempotency_key_id: key.id,
origin_lat: params["origin_lat"],
origin_lon: params["origin_lon"],
target_lat: params["target_lat"],
target_lon: params["target_lon"],
stripe_charge_id: nil, # no charge created yet
user_id: user.id,
)
# in the same transaction insert an audit record for what happened
AuditRecord.insert(
action: AUDIT_RIDE_CREATED,
data: Sequel.pg_jsonb(params),
origin_ip: request.ip,
resource_id: ride.id,
resource_type: "ride",
user_id: user.id,
)
RecoveryPoint.new(RECOVERY_POINT_RIDE_CREATED)
end
기본 레코드를 마련했으니 외부 상태 변경을 수행할 차례다. Stripe로 결제를 시도한다. 여기서는 사용자 레코드에 저장된 Stripe customer ID를 이용해 $20 결제를 생성한다. 성공하면 이전 단계에서 만든 ride 레코드에 Stripe charge ID를 업데이트하고 복구 지점을 charge_created로 설정한다.
atomic_phase(key) do
# retrieve a ride record if necessary (i.e. we're recovering)
ride = Ride.first(idempotency_key_id: key.id) if ride.nil?
# if ride is still nil by this point, we have a bug
raise "Bug! Should have ride for key at #{RECOVERY_POINT_RIDE_CREATED}." \
if ride.nil?
raise "Simulated fail with `raise_error` param." if raise_error
# Rocket Rides is still a new service, so during our prototype phase
# we're going to give $20 fixed-cost rides to everyone, regardless of
# distance. We'll implement a better algorithm later to better
# represent the cost in time and jetfuel on the part of our pilots.
begin
charge = Stripe::Charge.create({
amount: 20_00,
currency: "usd",
customer: user.stripe_customer_id,
description: "Charge for ride #{ride.id}",
}, {
# Pass through our own unique ID rather than the value
# transmitted to us so that we can guarantee uniqueness to Stripe
# across all Rocket Rides accounts.
idempotency_key: "rocket-rides-atomic-#{key.id}"
})
rescue Stripe::CardError
# Sets the response on the key and short circuits execution by
# sending execution right to 'finished'.
Response.new(402, wrap_error(Messages.error_payment(error: $!.message)))
rescue Stripe::StripeError
Response.new(503, wrap_error(Messages.error_payment_generic))
else
ride.update(stripe_charge_id: charge.id)
RecoveryPoint.new(RECOVERY_POINT_CHARGE_CREATED)
end
end
Stripe 호출은 복구 불가능한 에러 몇 가지 가능성을 만든다(즉, 아무리 재시도해도 절대로 성공하지 않는 경우). 그런 경우 요청을 finished로 만들고 적절한 응답을 반환한다. 예를 들어 카드가 유효하지 않거나 결제 게이트웨이가 거래를 거절한 경우가 그렇다.
결제가 영속화됐으니 다음은 사용자에게 영수증을 보내는 것이다. 외부 메일 호출은 보통 별도의 외부 상태 변경 단계가 필요하지만, 트랜잭션으로 스테이징되는 잡 드레인을 사용하므로 트랜잭션의 나머지 부분과 함께 커밋된다는 보장을 얻는다.
atomic_phase(key) do
StagedJob.insert(
job_name: "send_ride_receipt",
job_args: Sequel.pg_jsonb({
amount: 20_00,
currency: "usd",
user_id: user.id
})
)
Response.new(201, wrap_ok(Messages.ok))
end
마지막 단계는 사용자에게 “모든 것이 정상 동작했다”는 응답을 설정하는 것이다. 끝났다.
API를 실행하는 웹 프로세스 외에도, 모든 것이 동작하려면 몇 가지 프로세스가 더 필요하다(전체 목록은 _Atomic Rocket Ride_의 Procfile 및 같은 저장소의 구현을 참고).
삽입 트랜잭션이 커밋된 후 staged_jobs의 잡을 실제 잡 큐로 옮기는 enqueuer가 있어야 한다. 구축 방법은 이 글 또는 _Atomic Rocket Rides_의 구현을 참고하자.
이 구현의 한 문제는, 불확정 상태 요청(예: 타임아웃처럼 보였던 요청)을 완료로 밀어 넣는 역할을 클라이언트의 재시도에 의존한다는 점이다. 보통 클라이언트는 요청이 성공하길 원하므로 이를 해주지만, 어떤 경우엔 클라이언트가 작업을 시작한 뒤 끝까지 마치지 못하고 영영 사라질 수도 있다.
확장 목표로 completer를 구현할 수 있다. completer의 유일한 일은 “끝까지 완료되지 않은 것처럼 보이고”, “클라이언트가 버린 것으로 보이는” 요청을 찾아서, 끝까지 처리를 밀어 완료시키는 것이다.
스택이 어떻게 구현됐는지 특별한 지식이 필요하지도 않다. 멱등성 키를 읽는 법과, 누구의 요청이든 재시도할 수 있도록 하는 특수한 내부 인증 경로만 알면 된다.
Atomic Rocket Rides 저장소의 completer 구현을 참고하자.
멱등성 키는 멱등성을 보장하기 위한 메커니즘이지, 역사적 요청의 영구 아카이브가 아니다. 일정 시간이 지나면 reaper 프로세스가 키들을 훑어 삭제해야 한다.
72시간 정도를 임계값으로 권한다. 금요일에 배포된 버그로 인해 유효한 요청이 대량으로 오류 나더라도, 주말 동안 기록을 유지하고 월요일에 개발자가 수정 커밋을 한 뒤 completer가 성공 경로로 밀어 넣을 수 있기 때문이다.
이상적인 reaper는 완료될 수 없었던 요청을 감지해 정리(cleanup)를 시도할 수도 있다. 정리가 어렵거나 불가능하면, 사람이 확인할 수 있도록 어딘가 목록에 넣어 둬야 한다.
Atomic Rocket Rides 저장소의 reaper 구현을 참고하자.
이제 모든 부품이 준비됐으니, 머피의 법칙이 참이라고 가정하고, 클라이언트 앱이 새로운 Atomic Rocket Rides 백엔드와 통신하는 동안 발생할 수 있는 시나리오를 상상해 보자:
클라이언트가 요청을 보냈지만 백엔드에 도달하기 전에 연결이 끊긴다: 클라이언트는 멱등성 키를 사용했으므로 재시도가 안전하다는 것을 알고 재시도한다. 다음 시도는 성공한다.
두 요청이 동시에 같은 멱등성 키를 만들려 한다: DB의 UNIQUE 제약이 오직 하나만 성공하도록 보장한다. 하나는 통과하고, 다른 하나는 409 Conflict를 받는다.
멱등성 키가 생성됐지만 직후 DB가 다운된다: 클라이언트는 API가 다시 온라인이 될 때까지 계속 재시도한다. 온라인이 되면 생성된 키를 복구하고 요청을 이어서 처리한다.
Stripe가 다운된다: Stripe 요청이 포함된 원자적 단계가 실패하고, API는 클라이언트에게 재시도하라는 에러를 응답한다. Stripe가 복구되면 결제가 성공할 때까지 계속 재시도한다.
Stripe 응답을 기다리던 중 서버 프로세스가 죽는다: 다행히 Stripe 호출도 멱등성 키로 수행됐다. 클라이언트가 재시도하면 같은 키로 Stripe 호출이 다시 이뤄지고, Stripe의 멱등성 보장이 사용자를 이중 청구하지 않았음을 보장한다.
잘못된 배포로 모든 요청이 중간에서 500을 낸다: 개발자들이 서둘러 버그를 수정해 배포한다. 수정 후 클라이언트는 재시도하고, 원래 요청은 버그가 제거된 경로로 성공한다. 수정이 너무 늦어 클라이언트가 사라졌다면, completer 프로세스가 요청을 완료로 밀어 넣는다.
장애 안전 설계를 신경 써서 구현한 덕분에, 다양한 실패 가능성에도 시스템은 안전하다.
외부 상태 변경이 멱등이거나(혹은 Stripe처럼) 멱등성 키를 지원한다는 것을 안다면, 실패를 재시도해도 안전하다는 것을 안다.
하지만 모든 서비스가 이 보장을 제공하진 않는다. 멱등이 아닌 외부 상태 변경을 시도하다 실패를 보면, 이 작업을 영구 실패로 기록해야 할 수 있다. 많은 경우 재시도가 안전한지 알 수 없으므로, 보수적으로 실패 처리해야 한다.
예외는, 멱등이 아닌 API가 에러를 반환하긴 했지만 명시적으로 “재시도해도 된다”고 알려주는 경우다. 연결 리셋이나 타임아웃 같은 불확정 에러는 실패로 표시해야 한다.
이것이 모든 서비스에 멱등성 및/또는 멱등성 키를 구현해야 하는 이유다!
MongoDB 같은 비-ACID 저장소에서는 이 모든 것이 불가능하다는 점을 언급할 가치가 있다. 트랜잭션 의미론이 없으면 데이터베이스는 두 작업이 원자적으로 커밋됨을 보장할 수 없다. 그 결과 DB에 대한 모든 작업이 외부 상태 변경과 동등해지고, 원자적 단계라는 개념 자체가 성립하지 않는다.
이 글은 API에 초점을 맞추지만, 같은 기법은 다른 소프트웨어에도 재사용 가능하다. 웹 앱에서 흔한 문제는 폼의 이중 제출이다. 사용자가 “Submit” 버튼을 빠르게 두 번 클릭하면 두 개의 HTTP 호출이 시작될 수 있고, 제출이 멱등이 아닌 부작용(예: 과금)을 일으키면 문제가 된다.
처음 폼을 렌더링할 때, 다음과 같은
<input
type="hidden">
필드를 추가해 그 안에 멱등성 키를 넣을 수 있다. 이 값은 여러 번 제출해도 동일하게 유지되며, 서버는 이를 이용해 요청을 중복 제거(dedup)할 수 있다.
API 백엔드는 _수동적으로 안전(passively safe)_해야 한다. 어떤 종류의 실패가 던져져도 안정적인 상태로 수렴해야 하고, 극단적인 상황에서도 사용자가 깨진 상태로 방치되어서는 안 된다. 그런 기반 위에서 능동적 메커니즘들이 시스템을 완전한 일관성으로 이끌 수 있다. 이상적으로는 사람 운영자가 개입해 고쳐야 하는 일이 없거나(또는 가능한 한 드물게) 되는 것이 좋다.
순수하게 멱등인 트랜잭션과 여기서 설명한 원자적 단계 기반의 멱등성 키는 그 방향으로 나아가는 두 가지 방법이다. 실패는 “가능할 뿐 아니라 예상되는 것”으로 취급되며, 시스템 설계에 충분한 사고를 적용해 어떤 일이 일어나도 실패를 깔끔히 견딜 것임을 알 수 있도록 한다.