AI 데이터 센터의 투자·전력 소비를 FLOPS 관점에서 풀어보고, H100 GPU와 iPhone 16의 연산 성능을 비교해 데이터 센터의 계산 능력 규모를 가늠한다.
매일 AI 데이터 센터를 짓는 데 들어가는 막대한 투자에 관한 새로운 이야기가 나온다. 월스트리트저널은 보도하기를, GDP 대비 비중으로 볼 때 2026년 한 해의 AI 자본 지출만으로도 국가 철도망을 10년에 걸쳐 확충한 데 쓴 비용, 연방정부가 주간고속도로(interstate) 시스템을 만드는 데 쓴 지출, 혹은 아폴로 계획 전체에 들어간 비용보다 더 클 것이라고 한다. 블룸버그는 AI 데이터 센터 지출이 최대 3조 달러에 이를 수 있다고 보도한다. 전력연구기관 Electric Power Research Institute는 데이터 센터가 2030년까지 미국 전체 전력의 최대 17%를 소비할 것이라고 전망한다.
하지만 데이터 센터를 지출된 달러나 소비된 전력 같은 관점에서 말하는 것은 다소 추상적이다. 철도나 주간고속도로 건설의 _규모_를 “선로 몇 마일”, “도로 몇 마일”로 가늠할 수 있듯이, 이런 지표들은 우리가 실제로 구축하고 있는 인프라가 어떤 역량을 갖는지에 대해서는 많은 것을 말해주지 못한다. 나는 데이터 센터 구축이 계산 능력이라는 관점에서는 어떤 모습인지 더 잘 이해하고 싶었다.
AI 데이터 센터 구축을 압도적으로 가장 크게 이끄는 동인은 **스케일링 법칙(scaling laws)**이다. 간단히 말해, AI 모델을 학습시키는 데 더 많은 데이터를 쓰고, 그 모델이 더 크고 계산 비용이 더 많이 들수록, 모델 성능이 더 좋아진다. 따라서 더 낫고 더 강력한 AI 모델을 만들려면 학습과 실행에 필요한 계산량이 계속 늘어나야 하고, 그 계산이 수행되는 곳이 바로 데이터 센터다.
AI 모델의 계산 능력을 재는 흔한 척도는 FLOPS(초당 부동소수점 연산 수, floating-point operations per second)이다. OpenAI의 GPT-2 모델은 학습에 대략 FLOP이 든 것으로 추정되는 반면, 더 발전한 GPT-4는 학습에 대략 FLOP이 든 것으로 추정된다. 이는 GPT-2보다 거의 10,000배 많은 계산량이며, 20조 조(trillion trillion) 번이 넘는 연산이다.
(물론 컴퓨터 성능에는 FLOPS 말고도 훨씬 많은 요소가 있지만, 이는 계산 능력을 나타내는 유용한 척도이고 여기서는 이를 기준으로 하겠다.)
부동소수점 연산은 말 그대로 부동소수점 수에 대해 수행되는 수학 연산(덧셈, 뺄셈, 곱셈, 나눗셈)이다. 부동소수점 수는 컴퓨터에서 분수나 소수를 디지털로 표현하는 방식으로, 컴퓨터는 모든 것을 0과 1의 연속으로 저장한다. 보통 세 부분으로 이뤄진다. 부호(sign)(양수인지 음수인지), 가수(significand)(어떤 자릿수들의 연속), 그리고 밑을 지수만큼 거듭제곱한 값(소수점을 어디에 둘지 결정)이다.
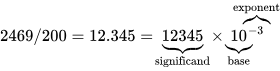
부동소수점 수의 구조. 여기서는 양의 부호가 생략돼 있다. Wikipedia 참조.
서로 다른 부동소수점 인코딩 표준은 서로 다른 메모리 크기에서 이 세 부분에 서로 다른 비트 수를 배정한다. 예를 들어 IEEE 754 부동소수점 연산 표준은 32비트 부동소수점 수(일반용 컴퓨터에서 흔히 쓰이는 부동소수점 수의 크기)를 부호 1비트, 지수 8비트, 가수 23비트로 규정한다. 이렇게 공간이 유한하기 때문에 부동소수점 연산은 근본적으로 정밀도에 한계가 있다. 할당하는 공간이 적을수록 수의 정밀도는 낮아진다. 16비트 부동소수점 수는 32비트보다 정밀도가 낮고, 32비트는 64비트보다 정밀도가 낮다. (이 점은 나중에 중요해진다.)

Wikipedia에서 가져온 32비트 부동소수점 수로서의 0.15625.
그렇다면 전형적인 AI 데이터 센터는 얼마나 많은 FLOPS를 낼 수 있을까?
데이터 센터의 계산은 엄청난 수의 그래픽 처리 장치(GPU, graphics processing units)에서 수행된다. GPU는 많은 산술 연산을 동시에 수행하도록 설계된 특수한 컴퓨터다. (GPU는 원래 컴퓨터 게임 같은 것의 그래픽을 렌더링하기 위해 설계됐고, 오랫동안 Nvidia는 주로 컴퓨터 게임용 그래픽 카드 제조사였다.) 흔히 쓰이는 GPU로는 Nvidia의 H100이 있는데, 2022년에 처음 출시됐고 여전히 AI 관련 연산 작업에서 가장 인기 있는 GPU 중 하나다. 데이터 센터 용량은 종종 “H100 등가(H100 equivalents)” 기준으로 추정한다. Epoch AI의 대형 GPU 클러스터 데이터셋에 따르면, 일반적인 AI 데이터 센터에는 H100 등가가 약 100,000개 정도 있고, 매우 큰 곳은 100만 개 이상일 수도 있다. Meta가 루이지애나에 계획 중인 5기가와트 데이터 센터 캠퍼스는 완공 시 H100 등가가 400만 개를 넘을 것으로 추정된다.
H100 하나의 계산 용량은 어느 정도일까?
여기서부터 복잡해진다. H100 같은 AI 작업용 GPU는 정밀도가 낮은 수에 대해 더 많은 계산을 수행할 수 있다. 전형적인 32비트 부동소수점 수(FP32)의 경우 H100은 구성에 따라 60–67 테라FLOPS를 낼 수 있다. 초당 최대 , 즉 67조 번의 부동소수점 연산이다. 하지만 16비트 수(FP16)에서는 H100이 1,979 테라FLOPS를 달성할 수 있는데, 거의 30배 증가다. 그리고 8비트 부동소수점 수(FP8)에서는 다시 두 배로 늘어 3,958 테라FLOPS가 된다.
하지만 FP32와 FP64를 제외하면, 이런 성능 수준은 _희소성(sparsity)_이라는 것을 통해 달성된다. 희소성은 행렬에서 네 개 값으로 이뤄진 한 묶음 중 최소 두 개가 0일 때 발생한다. 이렇게 되면 GPU는 0인 값의 곱셈을 건너뛸 수 있어, 사실상 수행해야 할 연산 수를 절반으로 줄인다. 행렬이 희소하지 않다면(행렬이 _밀집(dense)_해 있다면) 공개된 성능 수치는 대략 절반 정도로 떨어진다.
AI 모델을 학습할 때는 희소성을 사실상 전혀 달성할 수 없다. 모델을 실행할 때는 가능할 수 있지만, 이를 활용하려면 가지치기(pruning)라는 추가 단계를 거쳐야 한다. 따라서 이런 공개된 H100 성능 수준은 특정한 경우에만 실제로 도달할 수 있다.
대부분의 범용 계산은 더 높은 정밀도의 FP32 부동소수점 수를 사용해 수행된다. 하지만 AI 모델을 학습하고 실행할 때는 16비트, 8비트, 심지어 4비트 부동소수점 수로도 좋은 결과를 얻을 수 있다는 것이 밝혀졌다.
그렇다면 H100의 계산 용량은 다른 종류의 컴퓨터, 예컨대 iPhone과 비교하면 어떨까?
iPhone 16은 Apple의 A18 칩을 사용하며 Pro 버전에는 6코어 GPU가 들어 있다. A18의 계산용량에 대한 추정치는 다양하지만, FP32 기준으로 대략 2–3 테라FLOPS 정도이고, FP16을 쓰면 아마 그 두 배 정도인 것으로 보인다. A18에는 또한 16코어 NPU(신경망 처리 장치, neural processing unit)가 있는데, 8비트 정수(INT8)로 보이는 연산에서 초당 35조 번의 연산(TOPS)을 낼 수 있다. 비교하자면 H100은 희소성을 적용한 INT8에서 최대 3,958 TOPS를 낼 수 있는데, 113배 증가다. (A18에도 CPU가 있지만, 이것이 더해주는 계산 용량은 무시할 만한 수준인 것으로 보인다.)
이를 종합하면 다음과 같다. H100은 32비트 부동소수점 수로 수학 연산을 수행할 때 iPhone 16 GPU의 계산 용량보다 20–30배 크지만, 16비트 수로 작업할 때는 (희소성 적용 여부에 따라) 약 137–275배의 용량을 가진다. 그리고 H100은 A18의 NPU 용량의 약 56–113배 수준이다. NPU와 GPU를 함께 사용할 수 있다고 가정하면, H100은 iPhone 16의 대략 50–100배 정도의 계산 용량을 가진다는 뜻이 된다.1 H100 등가 100,000개를 갖춘 전형적인 AI 데이터 센터는 iPhone 16 500만–1,000만 대와 대략 맞먹고, 거대한 5 GW 데이터 센터는 iPhone 16 2억–4억 대(!)와 맞먹는다.
물론 실제로 iPhone 여러 대를 연결해도 H100 같은 성능을 낼 수는 없다. H100은 수천 개의 다른 H100과 연결되도록 설계됐고, 이를 가능하게 하는 막대한 인터커넥트 및 메모리 대역폭을 갖추고 있지만 iPhone에는 그런 것이 없기 때문이다. 하지만 이 비교를 통해 관련된 계산 용량의 규모를 대략적으로 가늠할 수 있다.
또 다른 비교: H100에는 트랜지스터가 약 800억 개 있는 반면, A18에는 약 200억 개가 있다.