토큰화부터 다음 토큰 예측까지, 현대 Transformer 기반 LLM의 핵심 메커니즘을 수학 부담 없이 직관적으로 설명합니다.
월요일. 2026년 6월 1일 - 26분
이 글은 LLM이 어떻게 작동하는지 차근차근 살펴보는 안내서입니다. 현대의 LLM은 대부분 transformer 블록을 반복해서 쌓아 만들어지므로, transformer의 작동 원리를 이해하면 전체 구조의 대부분을 이해하게 됩니다.
이 글에서는 현대의 transformer 기반 LLM 내부의 핵심 메커니즘을, 끈적한 수학 이야기 없이 다룹니다. 오해하지는 마세요. 수학은 배워야 합니다. 하지만 이 글은 좋은 입문이 될 수 있습니다.
대부분의 현대 LLM은 같은 transformer 계열의 뼈대를 공유합니다. 차이는 각 모델이 어떤 데이터로 학습되었는지, 규모와 구성 선택이 무엇인지, 그리고 그 위에 어떤 사후 학습이 추가되었는지에서 나옵니다. 글을 다 읽고 나면 많은 현대 LLM 논문이나 모델 카드를 읽을 때, 각 섹션이 아키텍처의 어느 부분을 말하는지 알 수 있게 될 것입니다.
여기서 따라갈 경로는 다음과 같습니다:
배경지식과 상관없이 누구나 따라올 수 있도록, 글 전반에 작은 설명을 함께 넣었습니다.
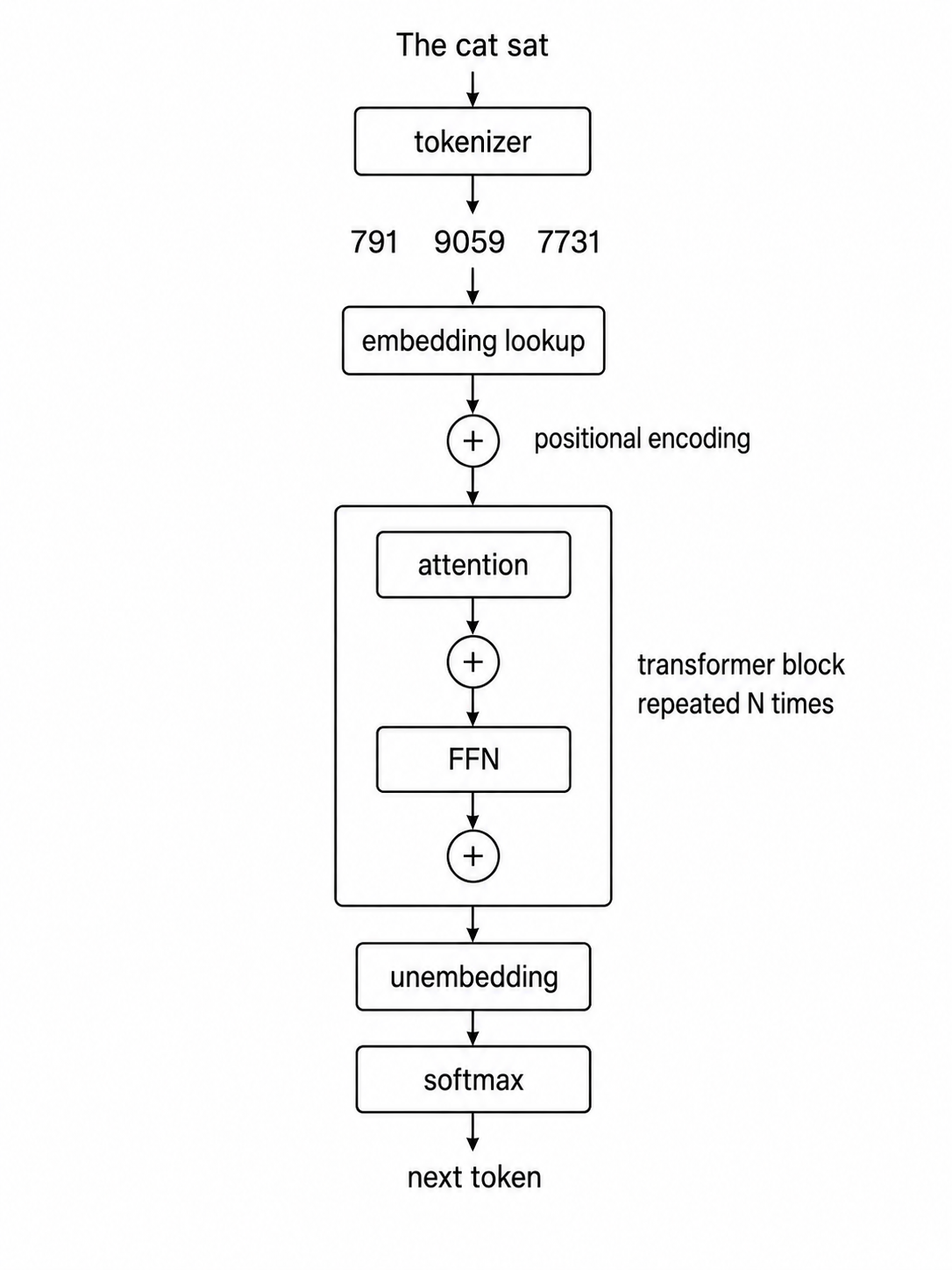
모델은 텍스트를 직접 읽지 않습니다. 정수 ID를 읽습니다. 여러분의 프롬프트를 그런 정수들의 시퀀스로 바꾸는 단계가 있습니다.
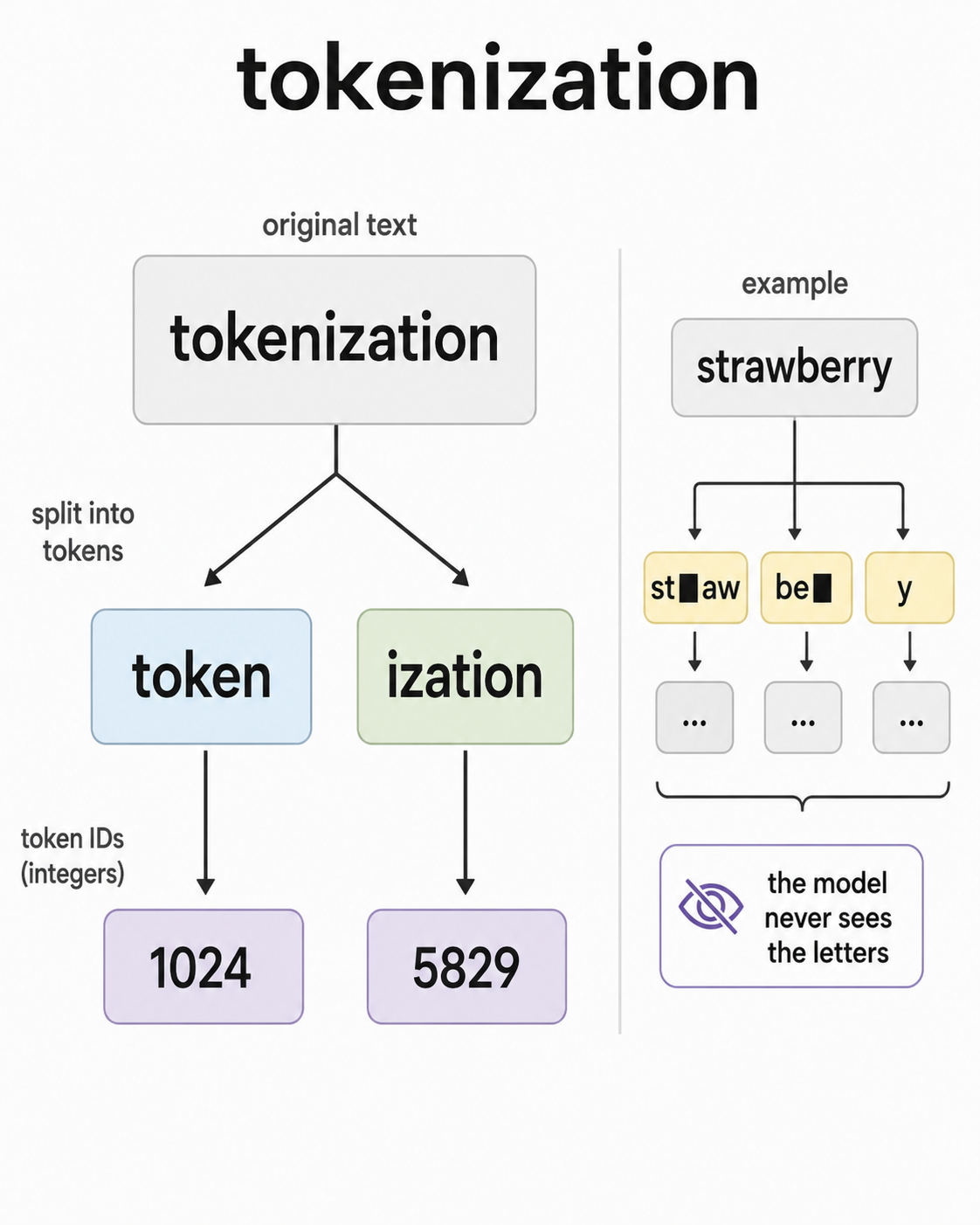
이 변환 단계는 토큰화라고 합니다. 토크나이저는 문자열을 받아 정수 시퀀스를 만들어 내며, 각 정수는 고정된 어휘집의 한 항목을 가리킵니다. 현대 LLM의 어휘집은 보통 수만 개에서 수십만 개의 항목을 포함합니다.
작은 설명: 토큰 ID
토큰 ID는 모델이 어휘집의 한 항목을 나타내기 위해 사용하는 정수입니다. 모델은 적힌 단어 자체가 아니라 그 숫자를 다룹니다.
토큰은 보통 완전한 단어가 아닙니다. 대개는 하위 단어 조각입니다. “tokenization”은 [“token”, “ization”]으로 쪼개질 수 있습니다. “running”은 [“run”, “ning”]으로 나뉠 수 있습니다. 이유는 효율성입니다. 단어 전체를 기준으로 한 어휘집은 너무 크고 새로운 단어에 일반화하기 어렵습니다. 문자 단위 어휘집은 너무 작아서 가장 단순한 패턴조차 모델이 처음부터 배워야 합니다. 하위 단어 토큰화는 그 중간에 있습니다. 가장 흔한 조각은 하나의 토큰이 되고, 드물거나 새로운 단어는 더 작은 조각들로 조합됩니다.
작은 설명: 어휘집
어휘집은 토크나이저가 가진 고정된 조각 목록입니다. 각 조각에는 ID가 있고, 모델은 그 목록의 ID만 직접 입력으로 받을 수 있습니다.
이 절충은 사람들이 예상하지 못한 곳에서 드러납니다. 고전적인 예시는 이렇습니다. LLM에게 “strawberry”에 R이 몇 개 있는지 물어보면, 예전에는 종종 틀렸습니다. 이것은 모델이 세기를 못해서가 아닙니다. 모델이 문자를 직접 다루지 않고, 사람이 글자를 하나씩 나눠 보는 단어를 우연히 구성하는 토큰 ID만 다루기 때문입니다.
모델 계열마다 서로 다른 토크나이저를 사용합니다. GPT 계열은 Byte Pair Encoding 변형을 사용합니다. SentencePiece는 LLaMA 계열 모델에서 흔합니다. 이 선택은 계산량에 영향을 줍니다. 토큰 수가 적을수록 일이 줄어들기 때문입니다. 다국어 지원 범위 같은 부분에도 영향을 줍니다. 하지만 기본 형태는 같습니다. 텍스트가 들어오고, 정수가 나갑니다.
이제 프롬프트가 정수 시퀀스가 되었으니, 다음 단계는 그 정수들에 의미를 부여하는 것입니다.
1024 같은 토큰 ID는 그저 행 인덱스일 뿐입니다. 그 자체로는 아무 의미가 없습니다. 의미를 부여하는 것은 임베딩 행렬이라고 불리는 거대한 표입니다.
모든 모델에는 이것이 있습니다. 어휘집의 각 항목마다 하나의 행이 있고, 각 행은 긴 숫자 벡터입니다. 각 행의 길이는 모델의 히든 크기입니다. 많은 7B급 모델에서는 이것이 토큰당 4,096개의 숫자를 뜻합니다. 더 큰 모델은 보통 더 넓은 벡터를 사용합니다.
작은 설명: 벡터
벡터는 숫자 목록입니다. transformer에서는 각 토큰이 벡터가 되어야 모델이 그 위에서 수학적 연산을 할 수 있습니다.
토크나이저가 모델에 정수를 넘기면, 모델은 해당 행을 찾아 그 벡터를 대신 사용합니다. 이 벡터가 토큰의 임베딩입니다. 학습 과정에서 익힌, 그 토큰이 무엇을 “의미하는지”에 대한 모델의 표현입니다.
작은 설명: 임베딩 행렬
임베딩 행렬은 조회 테이블입니다. 토큰 ID가 들어오면 학습된 벡터가 나갑니다.
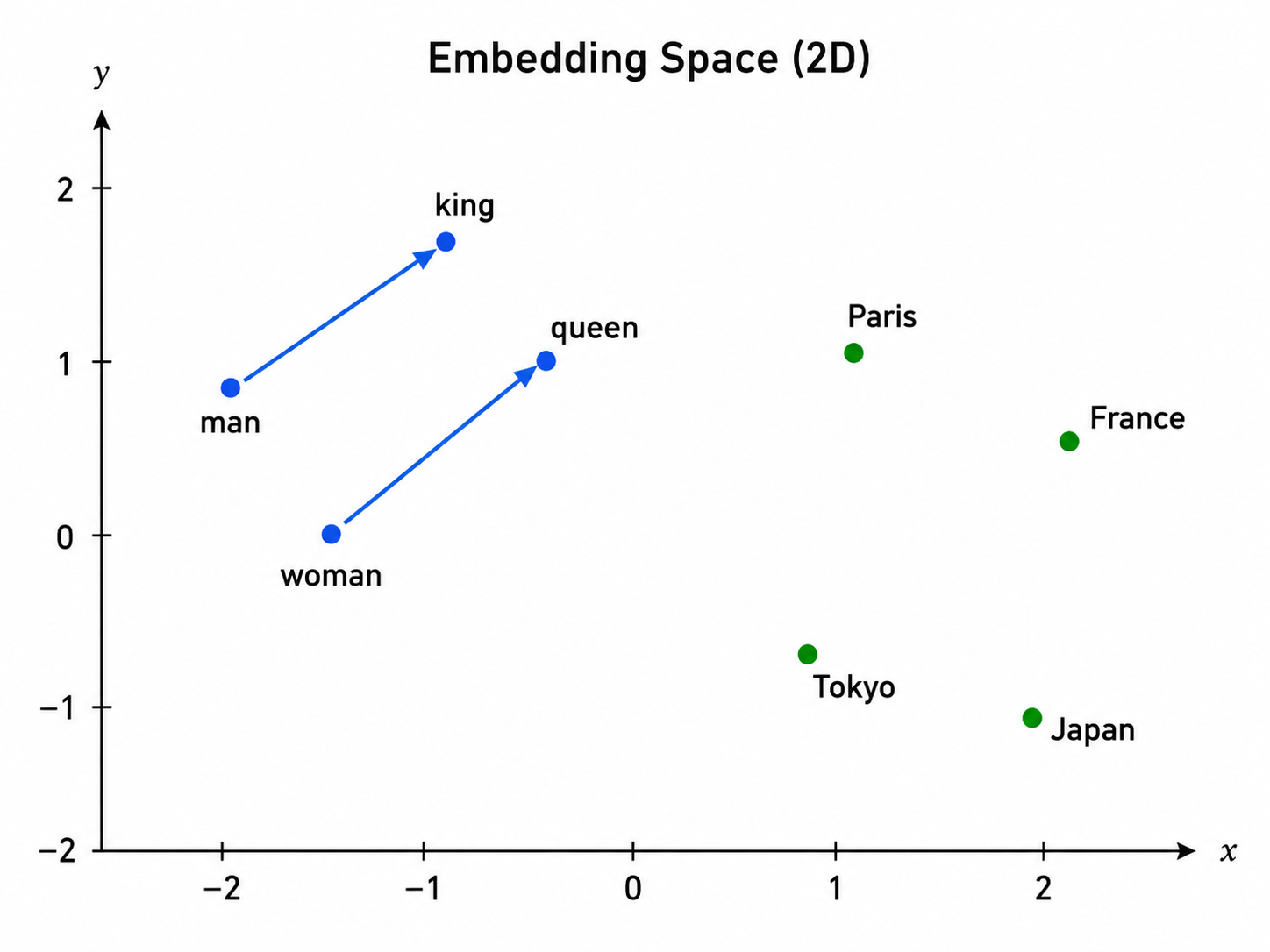
이 임베딩의 흥미로운 성질은 의미적으로 비슷한 토큰들이 비슷한 벡터로 모인다는 점입니다. “king”의 벡터는 공간상에서 “queen”에 가깝고, “Paris”의 벡터는 “France”에 가깝습니다. 이것은 하드코딩된 것이 아닙니다. 충분한 텍스트로 학습하는 과정에서 자연스럽게 나타나며, 모델은 이런 위치 배치가 텍스트 예측에 유리하기 때문에 그렇게 학습합니다.
임베딩에 산술 연산을 해 보면 때때로 실제로 잘 작동합니다. 유명한 예시는 king − man + woman ≈ queen입니다. 임베딩 공간의 기하 구조에는 실제 의미적 구조가 담겨 있습니다. 누구도 모델에게 그렇게 만들라고 말하지 않았는데도 말입니다.
분명히 해둘 점이 있습니다. 이 단계에서는 모든 토큰이 임베딩으로 치환되었지만, 임베딩만으로는 그 토큰이 시퀀스의 어디에 놓였는지 알 수 없습니다. “dog”의 벡터는 프롬프트의 첫 번째 단어일 때나 다섯 번째 단어일 때나 같습니다. 이것은 문제입니다.
이 빈자리를 채우는 것이 위치 인코딩입니다.
순수한 self-attention에는 단어 순서를 나타내는 내장 표현이 없습니다. 어떤 위치 신호도 없다면, “dog”가 “bites”보다 앞에 왔는지 뒤에 왔는지 직접 알 방법이 없습니다.
단어 순서는 의미를 바꿉니다. 그래서 모델에는 다른 한 조각이 더 필요합니다. 각 토큰의 위치를 수학 연산 속에 주입하는 방법이 필요합니다.
작은 설명: 위치 인코딩
위치 인코딩은 모델이 순서 정보를 얻는 방식입니다. 각 토큰이 시퀀스의 어디에 있는지 모델에 알려줍니다.
원래 transformer 논문(Vaswani et al. 2017)은 각 위치마다 고유한 숫자 패턴을 부여하고, 다른 처리에 들어가기 전에 그것을 각 토큰 임베딩에 직접 더하는 방식으로 이를 해결했습니다. 위치 1은 한 패턴을, 위치 5는 다른 패턴을, 위치 100은 또 다른 패턴을 가졌습니다. 이 패턴들은 서로 다른 주파수의 사인파와 코사인파에서 왔습니다. 이제 위치 1의 “dog” 임베딩은 위치 5의 “dog” 임베딩과 달라졌습니다. 단지 더해진 위치 패턴이 달랐기 때문입니다.
이 방식은 작동했고, 사인파 기반 인코딩은 학습 중 보지 못한 시퀀스 길이 너머로도 외삽할 수 있다는 점 때문에 선택되기도 했습니다. 하지만 더하기 방식의 위치 체계에는 모델이 커질수록 중요해진 두 가지 문제가 있었습니다.
첫째, 임베딩이 의미와 위치를 같은 숫자 집합 안에 함께 담아야 했습니다. 담을 수 있는 양에는 한계가 있습니다.
둘째, 특히 학습된 절대 위치 임베딩은 깔끔하게 일반화되지 않습니다. 프롬프트 길이 2,048 토큰까지로 학습했다면, 모델은 학습 중 위치 5,000을 본 적이 없고, 그 위치의 임베딩도 같은 방식으로 학습되지 않았습니다.
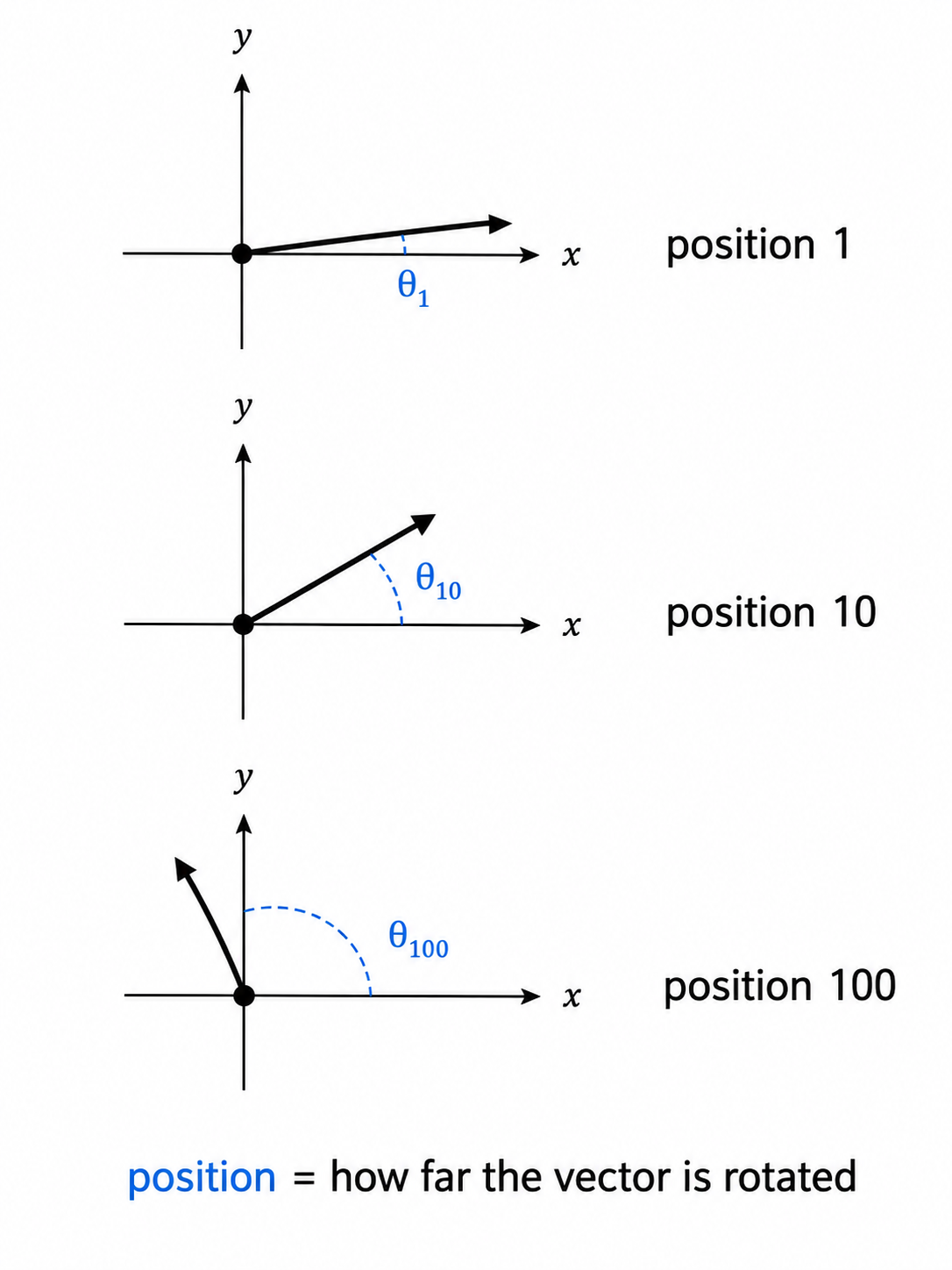
현대 모델은 대부분 Rotary Position Embeddings, 즉 RoPE라고 불리는 다른 방식을 사용합니다. 이는 2021년 Su 등에서 제안되었고, 현재는 LLaMA, Mistral, Gemma, Qwen, 그리고 대부분의 오픈 웨이트 계열에서 사용됩니다. 직관은 이렇습니다. 각 토큰 벡터에 위치 정보를 더하는 대신, RoPE는 Query와 Key 벡터를 토큰의 위치에 따라 결정되는 각도로 회전시킵니다. 위치 1의 토큰은 조금 회전하고, 위치 100의 토큰은 더 크게 회전합니다. 나중에 두 토큰을 어텐션에서 비교할 때 중요한 것은 그들의 Query와 Key 회전 차이이며, 이것이 둘 사이의 거리를 인코딩합니다.
작은 설명: RoPE
RoPE는 Rotary Position Embeddings의 약자입니다. 위치 벡터를 더하는 대신 Query와 Key 벡터를 회전시켜, 상대적 거리가 어텐션 중에 드러나게 합니다.
실용적인 장점은 분명합니다. RoPE는 상대 위치를 자연스럽게 인코딩합니다. 이것은 어텐션이 실제로 필요로 하는 것에 더 가깝습니다. 더 긴 문맥에도 더 잘 일반화됩니다. 그리고 모델에 새로운 파라미터를 추가하지도 않습니다.
좋은 위치 인코딩이 있어도, 현대 LLM에는 잘 알려진 “중간에서 잊어버림” 문제(Liu et al. 2023)가 있습니다. 긴 프롬프트에서 시작 부분과 끝 부분의 정보는 비교적 안정적으로 사용하지만, 가운데 깊숙이 묻힌 정보는 덜 안정적으로 사용합니다. 그래서 “중요한 맥락을 앞에 두라”거나 “핵심 정보를 끝에 한 번 더 반복하라” 같은 프롬프트 엔지니어링 팁이 실제로 도움이 됩니다. 모델은 프롬프트의 모든 부분을 똑같이 잘 활용하지 않습니다.
토큰의 의미와 위치가 모두 인코딩되었으니, 다음 질문은 토큰들이 실제로 어떻게 정보를 교환하느냐입니다.
이 메커니즘이 바로 이 아키텍처에 이름을 준 핵심입니다. 어텐션입니다.
모든 transformer 레이어 안에서, 어텐션은 한 가지 일을 합니다. 각 토큰이 볼 수 있도록 허용된 다른 토큰들을 살펴보고, 그중 어떤 것이 다음에 올 것을 결정하는 데 중요한지 판단하게 합니다.
이를 위해 각 토큰은 동시에 세 가지 역할을 부여받습니다. 각 토큰은 Query, Key, Value(Q, K, V)라고 불리는 세 개의 새로운 벡터로 변환됩니다.
작은 설명: Q, K, V
Query는 “나는 무엇을 찾고 있는가”, Key는 “나는 무엇과 잘 맞는가”, Value는 “잘 맞았을 때 복사되어 전달되는 정보”를 뜻합니다.
같은 토큰이 동시에 이 세 역할을 모두 수행합니다. Q, K, V 변환은 학습된 행렬이므로, 모델은 학습 과정에서 각 토큰이 무엇을 찾아야 하고 무엇을 제공해야 하는지 스스로 익힙니다.
매칭은 유사도 점수를 통해 일어납니다. 각 토큰의 Query는 볼 수 있도록 허용된 각 토큰의 Key와 scaled dot product를 사용해 비교됩니다. 직관적으로는 두 벡터가 얼마나 잘 정렬되는지를 재는 것입니다. 스케일링은 softmax 이전에 수치가 안정적으로 유지되도록 해 줍니다.
작은 설명: 내적
내적은 두 벡터가 얼마나 정렬되어 있는지를 점수로 매기는 간단한 방법입니다. 정렬이 높을수록 더 강한 매칭을 뜻합니다.
그다음 이 매칭 점수는 softmax를 통해 가중치로 바뀝니다. Softmax는 임의의 숫자 집합을 받아 합이 1이 되는 확률 비슷한 분포로 바꿉니다. 매칭 점수가 높은 토큰은 높은 가중치를 받고, 그렇게 얻은 가중치는 value 벡터들의 가중 평균을 계산하는 데 사용됩니다.
작은 설명: softmax
Softmax는 원시 점수를 합이 1이 되는 가중치로 바꿉니다. 큰 점수는 큰 가중치가 되고, 작은 점수는 작은 가중치가 됩니다.
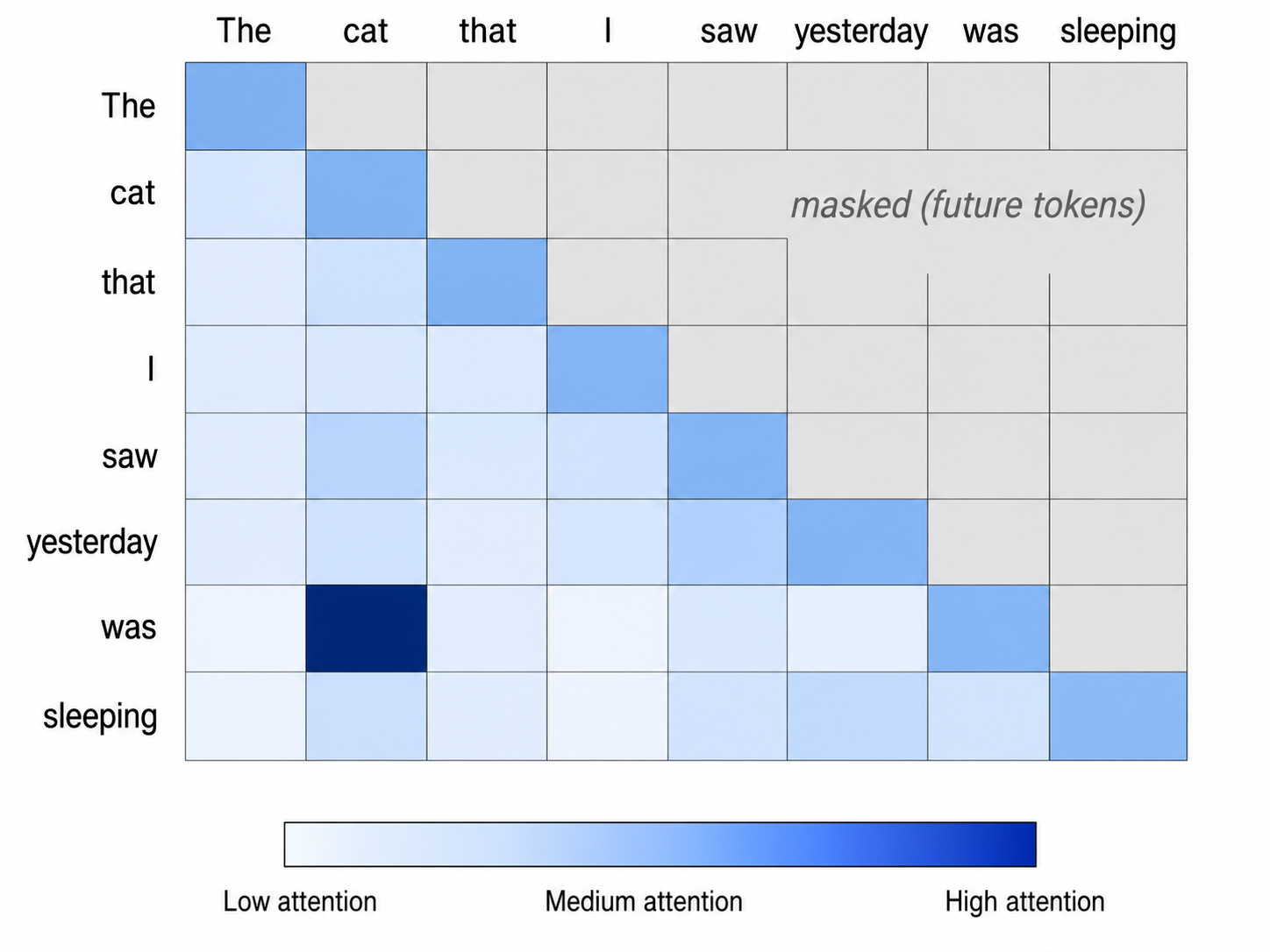
예를 들어 보겠습니다. “The cat that I saw yesterday was sleeping.”이라는 문장을 생각해 봅시다. 모델이 “was”를 처리할 때, 누가 자고 있는지를 파악해야 합니다. “was”의 Query 벡터는 볼 수 있는 토큰들의 Key 벡터와 비교됩니다. “cat”과의 내적은 높습니다. 모델이 “was” 같은 동사는 주어를 필요로 하고, “cat” 같은 주어는 잘 맞는 Key 벡터를 만든다는 것을 학습했기 때문입니다. 반면 “yesterday”와의 내적은 낮습니다. Softmax는 이 점수들을 가중치로 바꾸고, “cat”은 높은 가중치를, “yesterday”는 낮은 가중치를 받습니다. 그러면 모델은 해당 value 벡터들의 가중합을 취하고, 결과에서는 “cat”의 value가 크게 작용합니다. 이제 “was”의 새로운 표현은 대부분 “cat”의 value에 의해 형성됩니다. 이렇게 몇 위치 앞에 있던 토큰이 지시 대상이 됩니다.
GPT 스타일 언어 모델에는 특별한 제약이 하나 있습니다. 이들은 왼쪽에서 오른쪽으로 텍스트를 생성합니다. 위치 5의 토큰은 위치 1부터 5까지만 어텐드할 수 있습니다. 위치 6, 7, 8의 토큰에는 어텐드할 수 없습니다. 아직 생성되지 않았기 때문입니다. 이것을 인과 마스킹이라고 합니다. 구현은 단순합니다. 미래 토큰은 매칭 점수를 매우 낮게 받아 softmax 이후 사실상 0의 가중치를 갖게 됩니다.
작은 설명: 인과 마스킹
인과 마스킹은 미래 토큰을 가립니다. 이것은 decoder-only 언어 모델이 다음 토큰을 예측할 때 앞을 내다보지 못하게 합니다.
해석 가능성 연구에서 가장 흥미로운 발견 중 하나는 2022년 Anthropic이 찾은 induction head라는 특수한 어텐션 헤드에 관한 것입니다. 이 헤드들은 프롬프트에서 “A B … A” 형태의 패턴을 포착하고, 다음에 B가 온다고 예측하는 법을 배웁니다. 모델이 두 번째로 “A”를 볼 때, induction head는 이전에 “A”가 등장했던 곳을 돌아보고 그 뒤에 무엇이 왔는지 확인한 뒤 그것을 복사합니다. 이것은 문맥 내 학습, 즉 LLM이 여러분의 프롬프트에서 패턴을 포착해 그대로 이어 가는 능력의 가장 분명하게 알려진 메커니즘 중 하나입니다.
작은 설명: induction head
induction head는 프롬프트 안의 반복 패턴을 알아차리고 그것을 이어 가는 데 도움을 주는 어텐션 헤드입니다.
어텐션에는 큰 비용이 하나 있습니다. 완전 어텐션에서는 각 토큰이 볼 수 있는 모든 토큰과 비교하므로, 프롬프트 길이가 두 배가 되면 계산량은 대략 네 배가 됩니다. 이것이 긴 프롬프트를 실행하는 비용이 비싼 이유이고, 최근 연구의 많은 부분이 어텐션을 더 효율적으로 만드는 데 집중하는 이유입니다. FlashAttention, sparse attention, linear attention이 그런 예입니다.
하지만 하나의 어텐션 헤드만으로는 이런 관계들에 대해 모델이 학습한 하나의 관점만 제공할 뿐입니다.
단일 어텐션 패스는 어떤 토큰이 다른 어떤 토큰에 중요한지를 결정하는 한 가지 방식만 제공합니다. 그것만으로는 충분하지 않습니다. 언어에는 동시에 여러 관계가 일어납니다. 주어와 동사의 일치, 대명사와 그것이 가리키는 이름, 문장 사이의 장거리 참조, 단어 순서와 지역 구문 등이 있습니다.
멀티헤드 어텐션은 어텐션을 여러 번 병렬로 실행함으로써 이를 해결합니다. 각각의 병렬 패스는 자신만의 더 작은 공간에서 작동합니다. 이 병렬 패스 하나를 헤드라고 부릅니다.
작은 설명: 어텐션 헤드
어텐션 헤드는 자신만의 학습된 투영을 가진 독립적인 어텐션 패스 하나입니다.
이 부분은 많은 튜토리얼에서도 자주 잘못 설명됩니다. 각 헤드가 원래 토큰 벡터의 문자 그대로의 조각을 받는 것은 아닙니다. 각 헤드는 전체 토큰 벡터를 자기만의 더 작은 Q, K, V 벡터로 사상하는 고유한 학습 투영 행렬을 가집니다. 그래서 모델이 토큰당 4,096개의 숫자를 가지고 헤드가 32개라면, 각 헤드는 보통 128차원 공간에서 작동하지만, 그 128개 숫자는 전체 4,096에 대한 학습된 투영이지 고정된 조각이 아닙니다. 같은 토큰에 대한 서로 다른 “관점”이지, 서로 다른 덩어리가 아닙니다.
각 헤드는 독립적으로 자신의 어텐션 패스를 수행합니다. 그런 다음 모든 헤드의 출력은 이어 붙여지고, 그것들을 다시 하나의 전체 크기 벡터로 섞는 마지막 선형 레이어를 거칩니다. 이 마지막 섞기 역시 모델이 학습합니다.
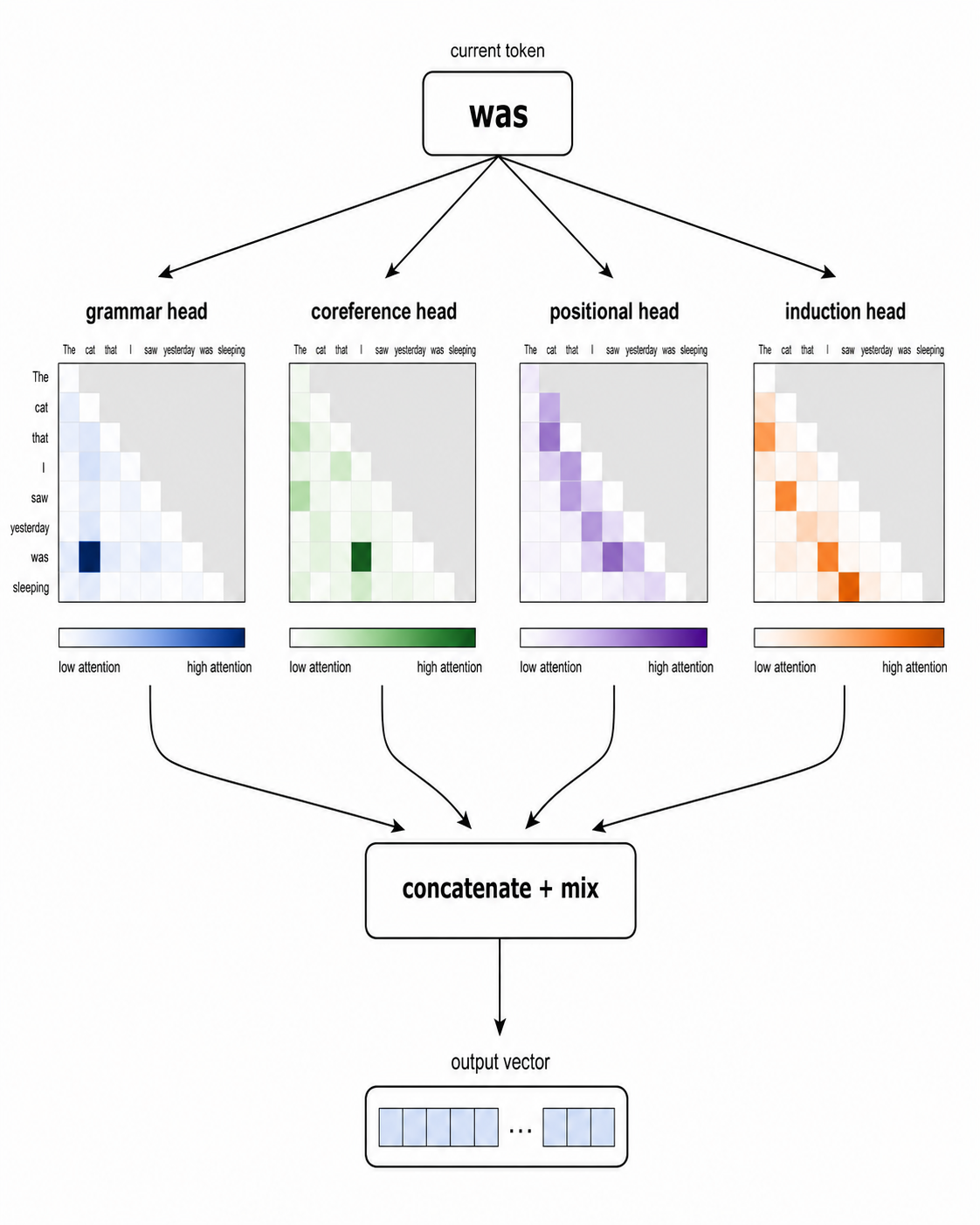
이것이 흥미로운 이유는 서로 다른 헤드가 종종 부분적으로 특화되기 때문입니다. 모델은 각 헤드가 무엇을 해야 하는지 직접 지시받지 않습니다. 특화는 학습 중 자연스럽게 나타납니다. 연구자들은 문법을 추적하는 헤드, 예를 들어 동사와 목적어를 연결하거나 관사와 명사를 연결하는 헤드, 어떤 대명사가 어떤 이름을 가리키는지 알아내는 헤드, 위치 패턴을 추적하는 헤드, induction head 등 수많은 종류를 찾아냈습니다. transformer 한 레이어에 32개의 헤드가 있을 수 있습니다. 현대의 최전선 모델은 수십 개의 레이어를 가집니다. 그래서 전형적인 LLM에는 전체적으로 수천 개의 어텐션 헤드가 있으며, 각 헤드는 자신만의 학습된 관점을 더합니다.
최근의 아키텍처 변화는 실용적인 비용 문제에서 나왔습니다. 각 헤드는 이미 생성된 모든 토큰에 대한 Key와 Value 벡터를 메모리에 유지해야 합니다. 그래야 새 토큰이 생성될 때 모델이 처음부터 모든 것을 다시 계산하지 않아도 됩니다. 이것을 KV 캐시라고 하며, 긴 문맥 길이에서 LLM을 실행할 때 가장 큰 메모리 비용입니다.
작은 설명: KV 캐시
KV 캐시는 생성 중 이전 Key와 Value 벡터를 저장합니다. 덕분에 모델은 토큰 하나를 추가할 때마다 전체 프롬프트를 다시 계산하지 않아도 됩니다.
현대의 decoder-only LLM은 대부분 Grouped-Query Attention, 즉 GQA라는 변형을 사용합니다. 모든 헤드가 각자 자기만의 key와 value를 갖는 대신, 여러 헤드가 같은 key와 value 헤드를 공유합니다. LLaMA-2 70B는 query 헤드가 64개지만 key/value 헤드는 8개뿐입니다. Mistral 7B는 query 헤드 32개와 key/value 헤드 8개를 가집니다. 결과적으로 전체 멀티헤드 어텐션과 거의 같은 정확도를 유지하면서도 메모리 압박과 추론 비용은 훨씬 줄어듭니다.
작은 설명: GQA
Grouped-Query Attention은 여러 query 헤드가 더 적은 수의 key/value 헤드를 공유하게 합니다. 이렇게 하면 많은 query 관점을 유지하면서도 KV 캐시 메모리를 줄일 수 있습니다.
어텐션이 토큰들 사이의 정보를 섞는 일을 마치고 나면, 각 레이어에는 사람들이 그만큼 자주 이야기하지 않는 두 번째 단계가 있습니다. 피드포워드 네트워크입니다.
어텐션이 토큰들이 서로 대화하는 것이라면, 피드포워드 네트워크는 각 토큰이 스스로 추가 처리를 하는 것입니다. 이것은 각 토큰 벡터에 독립적으로 적용되며, 토큰 사이의 혼합은 일어나지 않습니다.
피드포워드 네트워크는 순서대로 세 가지 일을 합니다.
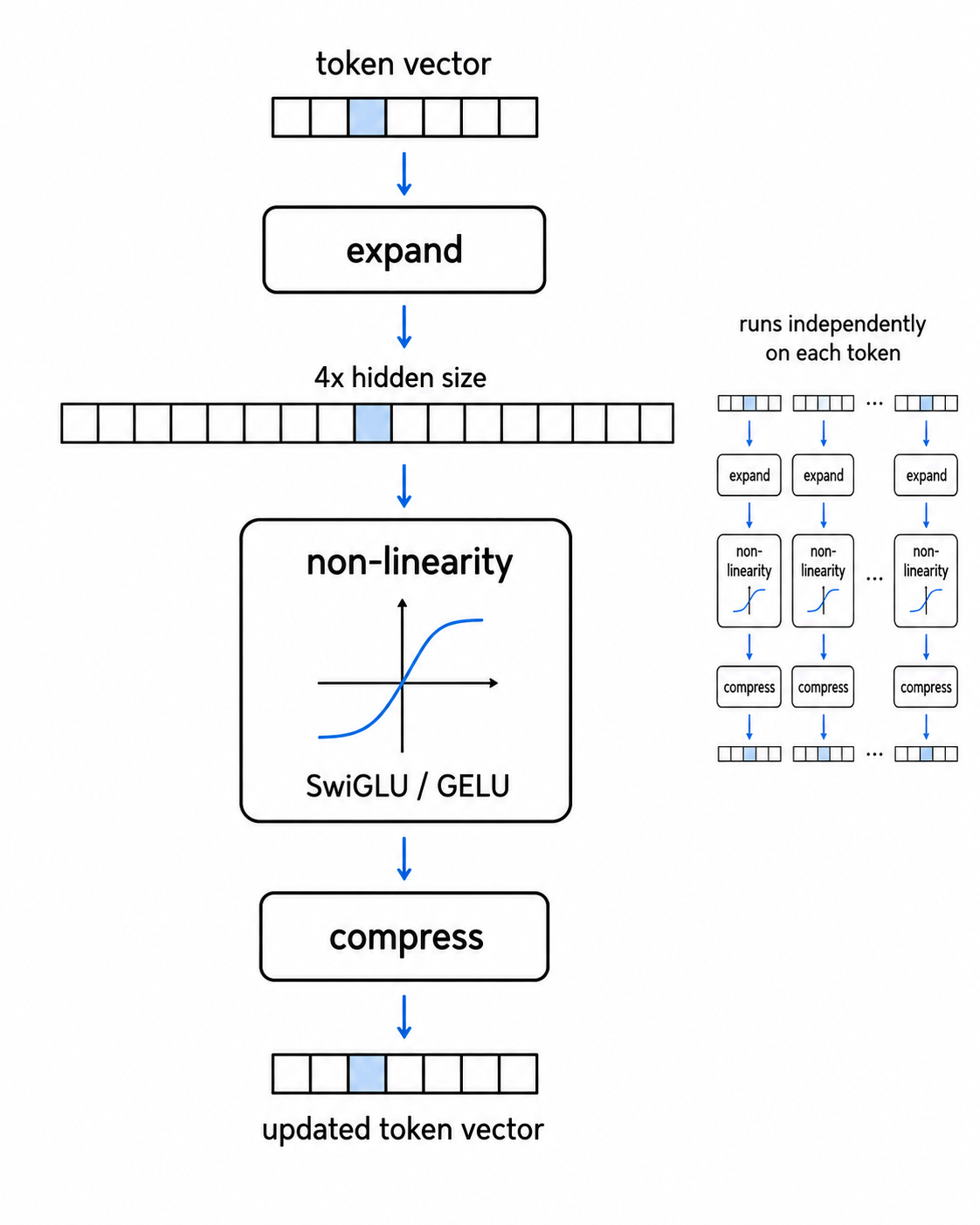
가운데의 비선형 단계는 무엇을 하는지 이해할 가치가 있습니다. 비선형성은 입력을 굽히는 함수입니다. 가장 단순한 것인 ReLU는 음수에는 0을 출력하고 양수는 그대로 통과시킵니다.
작은 설명: 비선형성
비선형성은 네트워크가 거대한 하나의 선형 변환으로 붕괴되는 것을 막는 함수입니다.
이것이 없으면 FFN은 단지 두 개의 선형 레이어를 쌓은 것에 불과하고, 순수한 선형 연산의 중첩은 결국 하나로 접혀 버립니다. 수학적으로 연속된 두 개의 선형 레이어는 하나의 선형 레이어와 같고, 연속된 백 개의 선형 레이어도 결국 하나와 같습니다. 비선형성은 그런 붕괴를 막는 요소이며, FFN이 단일 행렬 곱보다 더 풍부한 일을 할 수 있게 해 주는 이유입니다.
원래 transformer는 ReLU를 사용했습니다. GPT와 BERT는 GELU로 넘어갔습니다. LLaMA, Mistral, PaLM 같은 현대 모델은 SwiGLU를 사용합니다. 확장한 뒤 다시 압축하는 구조는 그대로 유지되었습니다. 반복적으로 개선된 것은 비선형 함수 자체입니다.
조밀한 transformer 모델의 파라미터 대부분은 어텐션이 아니라 FFN에 있습니다. 가중치의 큰 비중이 피드포워드 레이어에 들어 있습니다.
그리고 그 파라미터들은 일반적인 것이 아닙니다. 모델의 사실적, 의미적 구조 중 큰 부분이 바로 거기에 저장됩니다. 연구자들은 FFN 내부의 일부 뉴런이 특정 개념이나 사실과 강하게 연관된다는 것을 발견했습니다. 어떤 뉴런은 Eiffel Tower와 관련된 텍스트에서 강하게 활성화되고, 다른 것은 프로그래밍 언어에서, 또 다른 것은 과거형 동사에서 강하게 활성화될 수 있습니다. 모델이 Paris가 France의 수도라는 것을 “안다”는 사실은 특정 레이어들의 FFN 가중치와 활성화 전반에 걸쳐 표현됩니다.
이 저장된 기억의 성질은 흥미로운 결과를 낳습니다. 연구자들은 재학습 없이도 학습된 모델의 일부 사실을 직접 수정하는 방법을 알아냈습니다. ROME(Rank-One Model Editing) 같은 방법은 특정 FFN 가중치 행렬에 표적화된 저랭크 수정을 가해 “the Eiffel Tower is in Paris”를 “the Eiffel Tower is in Rome”으로 바꿀 수 있습니다. 그러면 모델은 수정된 연관관계와 일관된 텍스트를 생성하는 경향을 보입니다.
일부 현대 최전선 모델은 조밀한 FFN을 Mixture of Experts, 즉 MoE라고 불리는 것으로 대체하기 시작했습니다. 레이어마다 하나의 피드포워드 네트워크를 두는 대신, 모델은 여러 개의 병렬 FFN, 즉 전문가들을 두고, 아주 작은 라우터 네트워크가 각 토큰을 어떤 전문가가 처리할지 선택합니다. Mixtral 8x7B는 레이어당 전문가가 8개이며, 어떤 토큰이든 그중 2개만 활성화됩니다. 전체 파라미터 수는 크게 늘어나지만, 토큰당 계산량은 훨씬 더 천천히 증가합니다. 이것이 추론 비용을 비례해서 늘리지 않으면서 파라미터 수를 키우는 방법입니다.
작은 설명: MoE
Mixture of Experts는 모델이 여러 개의 피드포워드 네트워크를 가지고, 각 토큰을 그중 일부만 통과시키는 구조를 뜻합니다.
Mixtral 8x7B는 전체 파라미터 수가 467억 개이지만, 토큰당 실제로 사용하는 것은 약 129억 개입니다. 이것은 매우 큰 모델에서 흔한 선택지가 되었는데, 파라미터 수를 계속 늘리면서도 추론 비용이 비례해서 커지지 않게 해 주기 때문입니다.
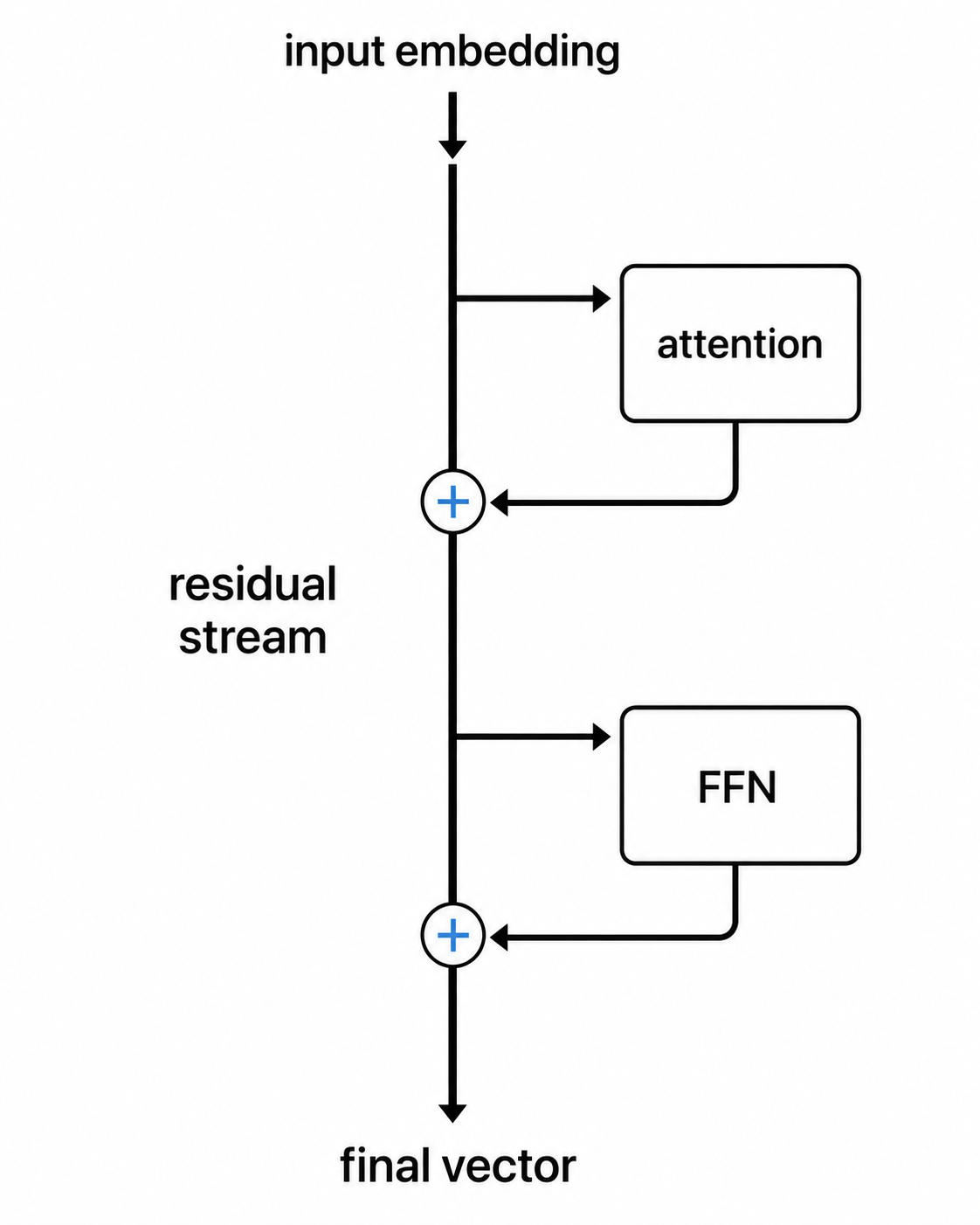
잔차 스트림은 모델이 “대체”하는 방식이 아니라 “더하는” 방식으로 작동하게 만드는 요소입니다. 어텐션이 실행된 뒤나 피드포워드 네트워크가 실행된 뒤, 그 결과는 보통 토큰 벡터를 대체하지 않습니다. 대신 그 벡터에 더해집니다. 위치별로 말입니다. 새로운 벡터는 이전 벡터에 하위 블록의 출력을 더한 값이 됩니다.
작은 설명: 잔차 연결
잔차 연결은 블록의 출력을 시작했던 벡터에 다시 더합니다. 이것은 정보와 그래디언트가 네트워크를 통과하는 지름길을 제공합니다.
30개, 50개, 혹은 100개의 레이어를 거치면서 각 레이어의 기여는 이전 벡터를 덮어쓰는 대신 누적됩니다. 이 누적 합을 잔차 스트림이라고 하며, 여기에는 묘한 성질이 있습니다. 원래 입력 임베딩이 여전히 후반부 레이어까지 직접적인 가산 경로를 유지하고, 그 사이사이에 모든 하위 블록의 기여가 섞여 들어갑니다.
잔차 연결은 transformer를 위해 발명된 것이 아닙니다. 원래는 이미지 인식을 위한 ResNet(He et al. 2015)에서 왔습니다. 동기는 깊은 네트워크를 학습시키는 것이 불가능했다는 점이었습니다. 학습 신호가 많은 레이어를 거슬러 올라가는 동안 너무 약해지거나 때로는 너무 강해졌습니다. 모델이 자신의 실수로부터 실제로 학습할 수 없었습니다. 지름길 경로를 추가하자 신호가 출력에서 입력으로 직접 흘러갈 수 있게 되었습니다. 그러자 수백 개 레이어의 네트워크도 학습시킬 수 있게 되었습니다. Transformer는 같은 요령을 이어받았습니다.
현대의 해석 가능성 연구에서는 잔차 스트림이 중심 대상이 되었습니다. 모든 구성 요소, 모든 어텐션 헤드, 모든 피드포워드 네트워크, 심지어 마지막의 언임베딩 단계까지도 잔차 스트림을 읽고 다시 거기에 씁니다.
두 번째 요소인 레이어 정규화는 훨씬 더 실용적인 이유로 존재합니다. 이것이 없으면 잔차 스트림은 안정적으로 유지되지 않습니다. 수십 번의 덧셈을 거치는 숫자들은 위로 폭주하거나 0 쪽으로 붕괴하는 경향이 있습니다. 어느 쪽이든 학습은 실패합니다. 레이어 정규화는 하위 블록들 사이에서 각 토큰 벡터를 다시 제어된 범위로 재조정합니다.
작은 설명: 레이어 정규화
레이어 정규화는 토큰 벡터의 숫자들이 안정적인 범위에 머물도록 재조정하는 과정입니다.
원래 2017년 transformer는 각 하위 블록 뒤에 정규화를 적용했습니다. 이것을 post-norm이라고 합니다. 이 방식은 얕은 모델에서는 작동했지만, 깊이가 깊어질수록 안정적으로 학습시키기가 어려워졌습니다. 현대 transformer들, 예를 들어 GPT-2 이후 모델, LLaMA, Mistral은 보통 각 하위 블록 앞에 정규화를 적용합니다. 이것이 pre-norm입니다. 이것이 매우 깊은 transformer를 더 쉽게 학습시킬 수 있게 만든 변화 중 하나였습니다.
함수 자체도 바뀌었습니다. 많은 현대 오픈 모델, 예를 들어 LLaMA, Mistral, Gemma, Phi는 RMSNorm이라는 더 단순한 변형을 사용합니다. 원래 레이어 정규화는 두 가지 일을 동시에 했습니다. 각 벡터를 0 쪽으로 이동시키고, 그다음 숫자들의 크기를 다시 조정했습니다. RMSNorm은 이동 단계를 버리고 크기 재조정만 남깁니다. 경험적으로는 크기 재조정이 이점의 대부분을 가져오면서 계산 비용은 더 낮습니다.
작은 설명: RMSNorm
RMSNorm은 평균을 먼저 빼지 않고 벡터의 크기만 재조정하는 더 저렴한 정규화 방법입니다.
그러니 이것이 화려하지 않은 핵심 기계 장치입니다. 잔차 연결이 없으면 매우 깊은 모델은 학습시키기가 훨씬 어려워집니다. 레이어 정규화가 없으면 누적 합이 폭주하거나 붕괴할 수 있습니다. 둘이 함께 있을 때 수백 레이어 깊이의 모델이 가능해집니다.
어텐션과 피드포워드 처리의 모든 레이어가 끝나면, 모델은 시퀀스의 각 토큰에 대해 하나의 벡터를 갖게 됩니다. 생성 중에 다음 단어를 예측하려면, 마지막 토큰의 최종 벡터 하나만 사용합니다.
이 마지막 벡터는 가능한 다음 토큰마다 하나씩의 숫자로 변환됩니다. 어휘집에 100,000개의 토큰이 있다면 숫자도 100,000개입니다. 이 숫자들을 로짓이라고 합니다. 아직 확률은 아닙니다. 양수일 수도 있고 음수일 수도 있으며, 크기는 무엇이든 될 수 있습니다.
작은 설명: 로짓
로짓은 가능한 각 다음 토큰에 대한 원시 점수입니다. softmax를 거친 뒤에야 확률이 됩니다.
Softmax는 이 로짓들을 가능한 다음 토큰들에 대한 모델의 확률 분포로 바꿉니다. 앞에서와 같은 연산이지만, 모델의 다른 위치에서 사용되는 것입니다.
모델은 보통 매번 가장 확률이 높은 토큰만 고르지는 않습니다. 디코딩 설정이 출력이 얼마나 결정적인지, 혹은 얼마나 다양할지를 조절합니다. Temperature는 분포가 얼마나 날카로운지를 바꾸고, top-k와 top-p는 가장 그럴듯한 다음 토큰들로 선택지를 제한합니다. 그래서 같은 모델도 어떤 설정에서는 정확하고 보수적으로 느껴지고, 다른 설정에서는 더 창의적으로 느껴질 수 있습니다.
작은 설명: temperature
Temperature는 샘플링 중 무작위성을 조절합니다. 낮으면 모델이 더 보수적으로 되고, 높으면 더 다양해집니다.
토큰이 하나 선택되면, 그것은 입력에 추가됩니다. 모델은 더 길어진 시퀀스에 대해 다음 단계를 실행합니다. 보통은 KV 캐시를 재사용하므로 전체 접두부를 처음부터 다시 계산하지 않습니다. 새 토큰에 대한 새로운 어텐션, 새로운 피드포워드, 새로운 최종 벡터, 새로운 예측이 이어집니다. 이 루프는 모델이 시퀀스 종료 토큰을 내보내거나 길이 제한에 도달할 때까지 계속됩니다. 하나의 긴 문단도 결국 이 루프가 토큰 하나씩 반복된 결과입니다.
이 단일 목표, 즉 다음 토큰 예측은 기본 LLM의 핵심 학습 신호입니다. 기본 모델은 사실 정확성, 대화 능력, 추론, 코딩을 직접 목표로 학습되지 않습니다. 방대한 양의 텍스트에서 다음 토큰을 예측하도록 학습됩니다. 이후의 사후 학습이 지시 따르기, 선호, 안전성, 대화 행동 등을 조정합니다.
알아둘 만한 큰 효율성 혁신도 있습니다. speculative decoding이라고 부릅니다. 작은 빠른 모델이 여러 토큰을 앞서 제안하고, 큰 모델이 그것들을 병렬로 검증합니다. 제안된 토큰들이 큰 모델의 확률 아래에서 수용되면 그대로 채택합니다. 그렇지 않으면 큰 모델로 되돌아갑니다. 올바르게 수행하면 출력 분포는 큰 모델만 단독으로 실행한 것과 같지만, 루프는 훨씬 더 빨라질 수 있습니다.
작은 설명: speculative decoding
speculative decoding은 작은 초안 모델이 앞을 내다보며 추측하고, 더 큰 모델이 추측한 여러 토큰을 한 번에 검증하는 방식입니다.
다음 토큰 예측 루프는 아키텍처에서 가장 단순한 부분이지만, 전체 시스템이 작동하게 만드는 핵심입니다.
지금까지 핵심 메커니즘을 살펴봤습니다. 토큰, 임베딩, 위치 인코딩, 어텐션, 멀티헤드 어텐션, 피드포워드 네트워크, 잔차 스트림과 정규화, 그리고 출력 쪽의 다음 토큰 루프까지였습니다. 이것이 기본 아키텍처를 한 바퀴 돈 모습입니다.
그렇다면 GPT와 Claude와 Gemini와 LLaMA 사이에 실제로 다른 것은 무엇일까요? 공개된 세부사항은 제각각이고, 비공개 모델들은 모든 아키텍처 선택을 공개하지 않습니다. 하지만 이 글이 다루는 수준에서는, 이들 모두가 대체로 같은 transformer 계열 설계 공간 안에 있습니다.
대부분의 현대 transformer 기반 LLM은 같은 넓은 구조를 사용합니다. 토큰화, 임베딩, 위치 인코딩, 쌓아 올린 transformer 레이어들, 각 레이어 안의 멀티헤드 어텐션과 피드포워드 네트워크, 잔차 스트림, 레이어 정규화, 그리고 다음 토큰 예측입니다.
모델 간에 바뀌는 것은 다음과 같습니다.
작은 설명: 가중치
가중치는 모델 내부의 학습된 숫자들입니다. 학습은 모델이 텍스트를 잘 예측할 때까지 그 숫자들을 바꿉니다.
2023년부터 2025년까지의 “현대 transformer” 스택은, 서로 다른 팀들이 독립적으로 도달했음에도 불구하고, 많은 진지한 최전선 모델과 오픈 웨이트 모델들 사이에서 공통된 선택지로 수렴했습니다. Pre-norm 배치, RMSNorm, RoPE, SwiGLU, Grouped-Query Attention, 그리고 가장 큰 일부 모델에서는 Mixture of Experts가 그것들입니다. 이들 중 어느 것도 한 번에 발명된 것은 아니었습니다. 모두가 2017년 원래 설계 위에 약 5년에 걸친 개선을 통해 축적된 것입니다.
transformer 계열 아키텍처를 중심으로 한 수렴은 기계학습 역사에서 드문 일입니다. 이 분야의 대부분 역사 동안에는 문제마다 전용 네트워크가 따로 있었습니다. 이미지 인식에는 한 종류, 언어에는 다른 종류, 오디오에는 세 번째 종류가 쓰였습니다. 비전 팀과 언어 팀은 방법을 거의 공유하지 않았습니다.
이제는 transformer 스타일 모델이 언어, 비전, 오디오, 멀티모달 시스템 전반에 나타납니다. Transformer가 이 분야의 큰 부분을 흡수했습니다.
물론 이것은 바뀔 수 있습니다. Mamba와 다른 state-space 모델은 특히 매우 긴 시퀀스에서 신뢰할 만한 대안입니다. 하이브리드 아키텍처도 탐색되고 있습니다. Mixture-of-experts는 이미 “아키텍처”라는 말의 의미를 최전선에서 바꿔 놓았고, 5년 전이라면 이국적으로 보였을 방식들이 이제는 현실이 되었습니다.
하지만 이 글의 핵심 메커니즘, 즉 토큰, 임베딩, 위치 인코딩, 어텐션, 피드포워드 네트워크, 잔차 스트림과 정규화, 다음 토큰 예측은 오래 남을 부분입니다. 아키텍처가 바뀌더라도, 어떤 시퀀스 모델이든 결국 어떤 형태로든 해결해야 하는 문제들이기 때문입니다.
여기까지 읽었다면, 이제 많은 현대 transformer 논문이나 모델 카드를 읽으면서 각 섹션이 무엇을 가리키는지 알 수 있을 것입니다. 그것이 이 글의 목표입니다.
피드백은 정말 환영합니다. 이 내용이 조금이라도 흥미로웠다면 X로 연락 주세요. 새로운 친구를 사귀는 걸 정말 좋아합니다.
피드백은 정말 환영합니다. 이 내용이 조금이라도 흥미로웠다면 X로 연락 주세요. 새로운 친구를 사귀는 걸 정말 좋아합니다.