여러 Linux 커널 버전에서 libaio와 io_uring의 비동기 디스크 I/O 성능을 비교하고, io_uring의 향상과 IOMMU 기본 활성화가 만든 뜻밖의 성능 함정을 분석합니다.

10분 읽기
23시간 전
Linux에는 효율적인 비동기 디스크 I/O를 위한 두 가지 인터페이스가 있습니다. 전통적인 AIO (libaio)와 더 새로운 io_uring (liburing)입니다. io_uring이 AIO보다 더 뛰어난 성능을 보인다는 사실은 널리 알려져 있습니다. 이를 보여주는 여러 논문이 있으며, 커널 개발자들도 초기 릴리스 이후 io_uring 성능이 크게 향상되었다고 자주 언급합니다. 하지만 이 성능이 커널 버전별로 어떻게 발전했는지를 보여주는 구체적인 수치를 찾기는 놀라울 정도로 어렵습니다. 대부분의 벤치마크는 단일 커널에서 API를 비교하기 때문에, 시간에 따른 전체 그림은 분명하지 않습니다.
YDB에서는 데이터베이스 성능을 개선할 방법을 지속적으로 찾고 있습니다. 우리의 프로덕션 서버는 일반적으로 Linux 5.4, 5.15 또는 6.6을 실행하고 있으며, 6.12로 이동하는 중이어서 이런 궁금증이 생겼습니다. 커널 버전 자체가 비동기 I/O 성능에 얼마나 영향을 줄까? 그래서 fio를 사용해 직접 측정하기로 했습니다. 다음은 랜덤 4K 쓰기에 대한 결과입니다.
전체 크기로 이미지를 보려면 엔터를 누르거나 클릭하세요
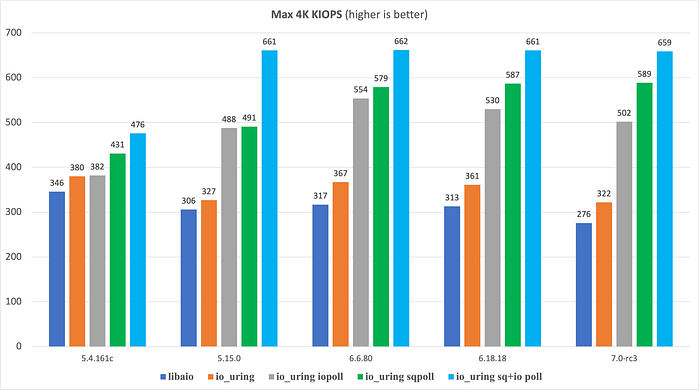
위 그림에서 핵심 결과는 다음과 같습니다.
io_uring은 libaio를 이길 뿐만 아니라, 새로운 커널에서 성능이 눈에 띄게 향상됩니다. 하지만 몇 가지 미묘한 함정도 있습니다. 그 과정에서 우리는 커널 회귀처럼 보였던 현상을 조사했고, 실제 원인은 릴리스 사이에 Intel IOMMU가 기본적으로 활성화된 데 있다는 사실을 발견했습니다. 이를 알아내기 전까지 우리는 새로운 커널에서 libaio와 io_uring 모두에서 IOPS가 약 30% 떨어진 것을 보고 놀랐습니다.
이것은 이야기의 짧은 버전입니다. 자세한 내용은 아래에 있습니다.
다음 구성의 베어메탈 머신에서 실험을 수행했습니다.
intel_iommu=off 커널 부트 파라미터(결과 섹션에 제시한 최종 설정에서 사용)options nvme poll_queues=16으로 구성된 NVMe 드라이버(이 역시 최종 설정)Linux 커널 5.4.161c는 우리의 자체 사내 커널입니다. 배포판 패치를 포함하지만, 그중 어느 것도 비동기 I/O 성능에 영향을 줄 것으로는 예상하지 않습니다. 커널 5.15.0–164는 Ubuntu에서 제공됩니다. 나머지는 Ubuntu mainline kernels입니다.
NVMe 장치는 NUMA 노드 0에 연결되어 있습니다. 모든 벤치마크는 NUMA 노드 0의 CPU 코어 0–16에 고정된 cgroup에서 실행했으며, 메모리 할당도 같은 NUMA 노드에 바인딩했습니다. CPU governor는 performance로 설정했습니다.
libaio와 io_uring을 비교하기 위해 fio 벤치마킹 도구를 기반으로 한 script를 사용했습니다. 이 스크립트는 iodepth를 바꾸고 서로 다른 I/O 엔진으로 전환하면서 일련의 fio 명령을 실행합니다. 우리는 원시 블록 장치 성능을 측정합니다.
실험에 사용한 기본 fio 명령의 예는 아래와 같습니다.
sudo fio
다음 엔진과 엔진 인자를 사용했습니다.
--ioengine=libaio--ioengine=io_uring--ioengine=io_uring --hipri=1 (IOPOLL)--ioengine=io_uring --sqthread_poll (SQPOLL)--ioengine=io_uring --sqthread_poll --hipri=1 (IOPOLL + SQPOLL)추가적인 io_uring 최적화(예: 등록된 버퍼)는 의도적으로 범위에서 제외했습니다. 우리는 커널 간에 동등한 구성만 비교합니다.
이 벤치마크의 목표는 I/O 메커니즘을 비교하는 것이므로, 각 실행 전에 장치 상태를 새로고침합니다. 이는 blkdiscard를 사용해 수행하며, NVMe 장치를 리셋하여 가능한 최상의 성능 상태로 되돌립니다.
워크로드는 랜덤 4K 쓰기를 사용합니다. 이는 커널의 I/O 제출 경로에 부하를 주며, 비동기 I/O 성능 평가에 일반적으로 사용됩니다.
각 엔진 + 엔진 파라미터 + iodepth 조합에 대해:
열 영향과 장치 측 스로틀링을 피하기 위해:
각 실행은 10초의 램프업 후 1분 측정 구간으로 이어집니다. 이 길이는 일반적으로 I/O 엔진을 비교하기에 충분하면서도, 내부 가비지 컬렉션이나 백그라운드 유지보수로 인한 NVMe 성능 저하를 피할 수 있습니다.
각 실행마다 IOPS와 지연 시간 통계(백분위수 포함)를 모두 수집합니다. 최대 IOPS는 전체 그림의 일부일 뿐입니다. 낮은 I/O 깊이에서의 지연 시간도 살펴보는 것이 중요합니다.
이 작성자의 업데이트를 받기 위해 Medium에 무료로 가입하세요.
더 빠른 로그인을 위해 나를 기억하기
별도 언급이 없는 한, 모든 벤치마크는 같은 하드웨어와 같은 fio 버전 및 구성에서 실행했으며, 커널 버전과 I/O 엔진만 변경했습니다.
먼저 서로 다른 커널과 I/O 메커니즘에서 달성한 최대 IOPS를 다시 살펴보겠습니다.
전체 크기로 이미지를 보려면 엔터를 누르거나 클릭하세요
눈에 띄는 관찰 결과는 몇 가지가 있습니다.
전체 그림을 완성하기 위해, 우리가 사용하는 최신 안정 커널인 Linux 6.18.18에서 io_uring과 libaio 비교에 초점을 맞춰 보겠습니다. 먼저 6.18.18 결과만 표시한 최대 IOPS 그림입니다.
전체 크기로 이미지를 보려면 엔터를 누르거나 클릭하세요
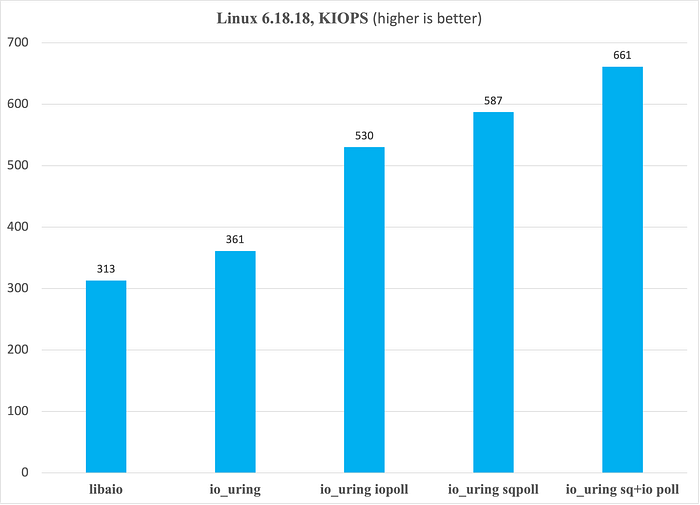
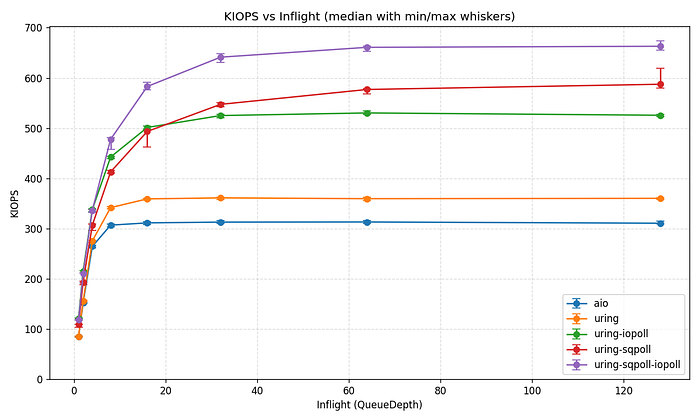
다음으로 iodepth 증가에 따라 IOPS가 어떻게 확장되는지 살펴보겠습니다. 아래 그림에서 수염은 최소값과 최대값을, 점은 중앙값을 나타냅니다.
전체 크기로 이미지를 보려면 엔터를 누르거나 클릭하세요
아래는 iodepth 1–8 범위를 확대해서 본 것입니다.
전체 크기로 이미지를 보려면 엔터를 누르거나 클릭하세요
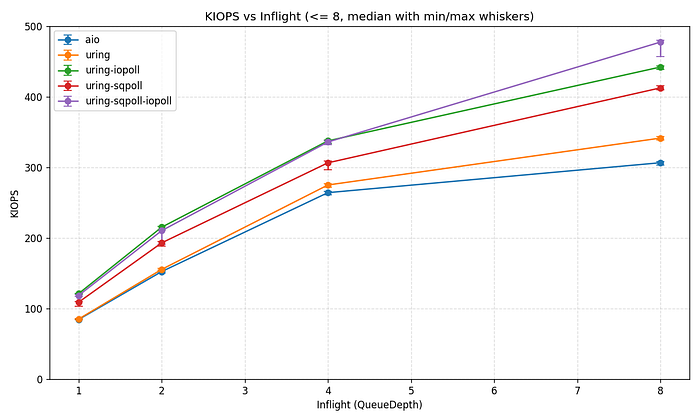
io_uring은 전체 iodepth 범위에서 일관되게 libaio보다 뛰어난 성능을 보입니다.
마지막으로 지연 시간 동작을 살펴보겠습니다. 아래 그림은 iodepth가 증가함에 따라 지연 시간 백분위수가 어떻게 변하는지 보여줍니다.
전체 크기로 이미지를 보려면 엔터를 누르거나 클릭하세요
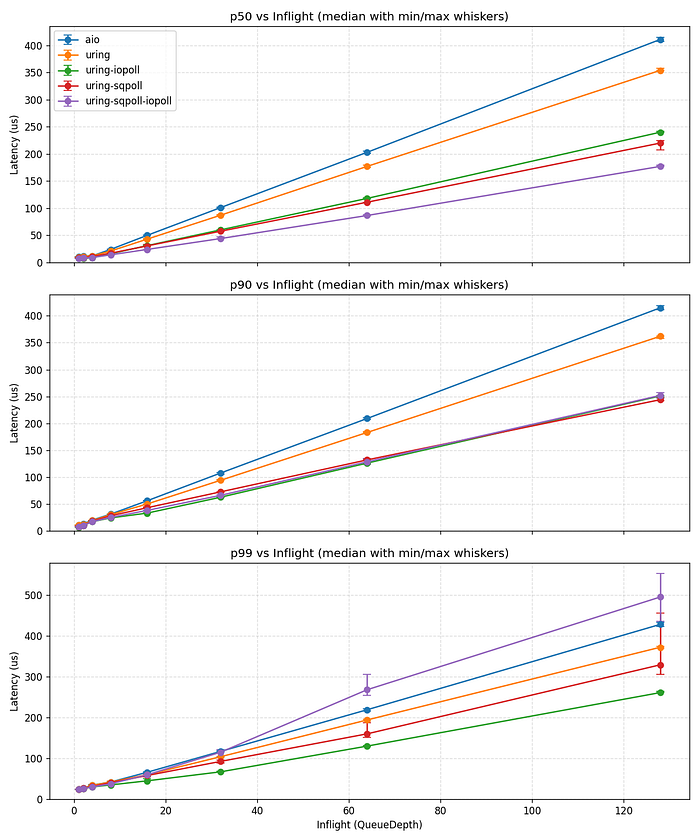
아래는 iodepth 1–16 범위를 확대해서 본 것입니다.
전체 크기로 이미지를 보려면 엔터를 누르거나 클릭하세요

그리고 다음은 큐 깊이 1, 4, 16에서의 지연 시간 분포입니다.
전체 크기로 이미지를 보려면 엔터를 누르거나 클릭하세요
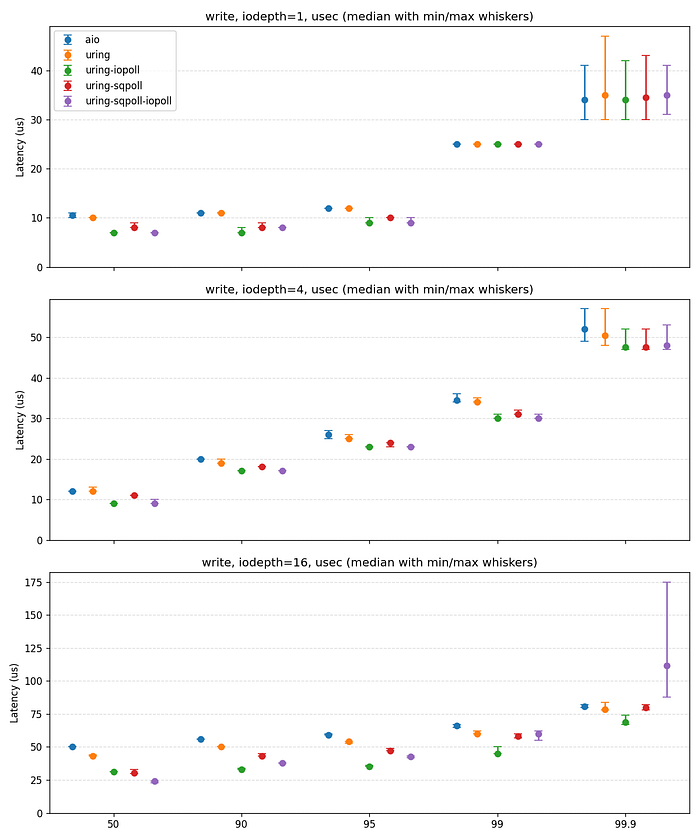
다시 말해, io_uring은 전체 범위에서 일관되게 libaio보다 더 낮은 지연 시간을 제공합니다.
전체 크기로 이미지를 보려면 엔터를 누르거나 클릭하세요

앞서 언급했듯이, 우리의 조사는 겉보기만큼 단순하지 않았습니다. 해피엔딩이 있는 그 이야기의 일부를 공유하고자 합니다.
우리는 Linux 커널 5.4, 5.15, 6.6으로 시작했습니다. 완전성을 위해 7.0-rc3도 테스트했습니다. 바로 여기에서 libaio와 io_uring 모두에서 30%의 IOPS 하락을 처음 발견했습니다. 처음에는 그다지 놀랍지 않았습니다. 결국 이것은 rc 커널이었기 때문입니다. 또한 7.0-rc2에 잘 알려진 regression이 있었고, 이것이 rc3까지 이어졌을 수도 있었습니다. 이를 확인하기 위해 6.18.18로 다시 돌아갔고, 같은 수준의 큰 성능 저하를 확인했습니다.
그 시점에서 우리의 결과는 다음과 같았습니다.
전체 크기로 이미지를 보려면 엔터를 누르거나 클릭하세요
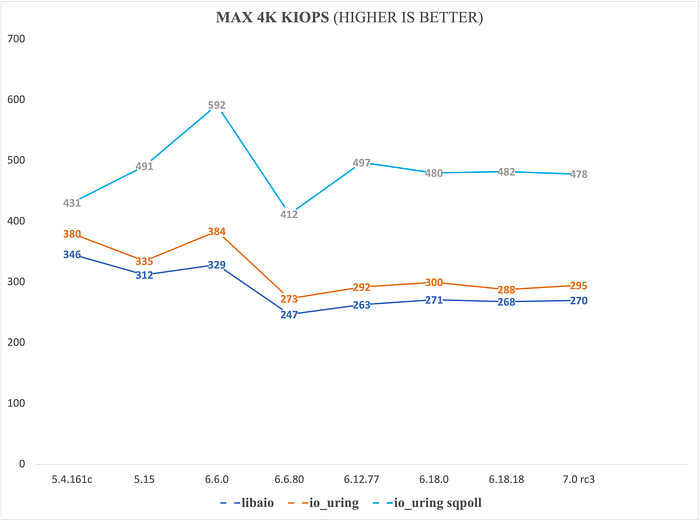
우리는 5.4와 5.15 사이에 작은 저하(libaio와 비폴링 io_uring만)를, 그리고 6.6.15와 6.6.20 사이 어딘가에서 더 심각한 하락을 관찰했습니다.
mainline 6.6.15와 6.6.20의 차이는 매우 작습니다. 작은 configuration 변경과 약간 다른 컴파일러 버전 정도입니다. 안타깝게도 우리는 처음에 구성 변경의 영향을 과소평가했고, 대신 더 오래된 GCC로 6.6.20을 다시 빌드해 보았습니다.
마지막의 다소 절박한 단계로 우리는 intel_iommu를 비활성화했고, 그것이 성능 저하의 근본 원인으로 드러났습니다. 추가 조사 결과 CONFIG_INTEL_IOMMU_DEFAULT_ON이 특정 5.15.x 커널부터 Ubuntu에서 enabled되었다는 사실을 확인했습니다. Ubuntu mainline 커널에서는 이것이 토글된 것으로 보였습니다. 어느 시점에 비활성화되었다가 6.6.15와 6.6.20 사이에서 다시 활성화되었습니다.
IOMMU(Input–Output Memory Management Unit)는 장치의 메모리 접근을 변환하고 격리를 강제하여 보안을 향상시키지만, 때로는 I/O 집약적 워크로드에서 추가 오버헤드를 유발할 수 있습니다. 이는 장치가 임의의 메모리에 접근하는 것을 막아 시스템을 보호하는 데 필요하며, 특히 가상화와 신뢰할 수 없는 주변장치에서 중요합니다.
우리의 경험상 대부분의 데이터베이스 관리 시스템은 IOMMU가 꼭 필요하지 않은 신뢰된 환경에서 실행됩니다. PCI 패스스루나 장치 격리가 필요하고 IOMMU를 끄는 것이 불가능하다면 iommu=pt 모드를 사용할 수 있습니다. 이 구성에서는 대부분의 장치에 대해 주소 변환이 사실상 우회되므로, 필요한 경우의 격리는 유지하면서도 오버헤드를 줄일 수 있습니다.
현대적인 환경에서 IOMMU 오버헤드를 최근에 체계적으로 평가한 자료는 찾지 못했습니다. 하지만 주목할 만한 관찰은 몇 가지 있습니다. 여기에서 저자들은 Ceph 클러스터에서 IOMMU가 “커널 수준 병목”이 되었다고 보고하며, 이를 비활성화하자 “상당한 성능 향상”이 있었다고 말합니다.
또 다른 예는 잘 알려진 VLDB paper “What Modern NVMe Storage Can Do, And How To Exploit It: High-Performance I/O for High-Performance Storage Engines”입니다. 여러 NVMe 장치를 완전히 활용하기 위해 저자들은 설정의 일부로 IOMMU를 비활성화했습니다.
우리가 이 문제를 직접 겪은 덕분에 얻은 한 가지 이점은 그 영향을 직접 측정할 수 있었다는 점입니다. 아래는 Linux 6.6.80에서 IOMMU 활성화와 비활성화를 비교한 결과입니다.
전체 크기로 이미지를 보려면 엔터를 누르거나 클릭하세요
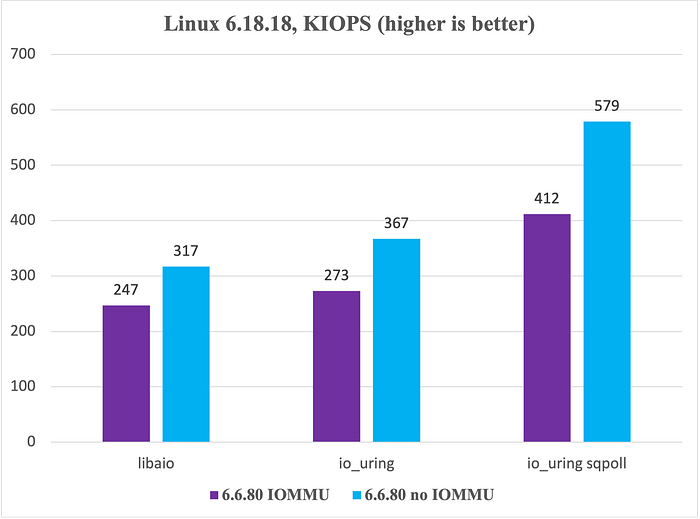
보안 관점에서 IOMMU를 기본 활성화하는 것은 합리적인 결정입니다. 하지만 대개 신뢰된 환경에서 DBMS를 실행하는 데이터베이스 개발자에게는 이것이 매우 회귀처럼 보일 수 있습니다. OS를 탓한다고요? 우리도 좋은 company에 있습니다 :)
전체 크기로 이미지를 보려면 엔터를 누르거나 클릭하세요

농담은 제쳐두고, 커널 개발자들에게 찬사를 보냅니다. 비동기 I/O, 특히 io_uring의 진전은 인상적입니다.
강조하고 싶은 흥미로운 주의사항이 하나 더 있습니다. Linux 6.8부터 IOPOLL(--hipri)과 함께 io_uring을 사용하도록 구성한 fio가 다음 오류와 함께 실패하기 시작했습니다.
fio: io_u error on file /dev/nvme0n1p2: Operation not supported: write offset=62033248256, buflen=4096
fio command failed for mode=uring-iopoll iodepth=8 rw=write run_index=4 특정 NVMe 드라이버 구성이 있어야 IOPOLL을 사용할 수 있다는 것이 밝혀졌습니다. 단계는 다음과 같습니다.
echo 'options nvme poll_queues=16' | sudo tee /etc/modprobe.d/nvme-poll.conf
sudo update-initramfs -u -k all
echo 1 | sudo tee /sys/block/nvme0n1/queue/io_poll
sudo shutdown -r now 이를 발견하기 전, 우리는 이미 이전 커널에서 여러 IOPOLL 실험을 수행한 상태였습니다. 실제로는 “일반” io_uring과 IOPOLL 사이의 차이는 작았고, SQPOLL과 IOPOLL을 결합했을 때도 이득은 크지 않았습니다.
Jens Axboe가 여기에서 설명했듯이, “If you don’t have any poll queues, preadv2 with IOCB_HIPRI will be IRQ based, not polled. io_uring just tells you this up front with -EOPNOTSUPP”. 이는 오래된 커널이나 기본 구성에서 IOPOLL을 사용할 때 염두에 둘 점입니다. 이 때문에 우리는 더 오래된 모든 커널에서 벤치마크를 다시 실행해야 했습니다.
이 글에서는 랜덤 4K 쓰기 워크로드를 사용해 여러 Linux 커널 버전에서 libaio와 io_uring의 성능을 비교했습니다. 실험을 통해 세 가지 주요 결론을 얻었습니다.
첫째, io_uring 성능은 새로운 커널에서 크게 향상됩니다. Linux 6.6에서 가장 빠른 io_uring 구성은 오래된 커널보다 약 1.4배 빠릅니다. 오래된 커널을 실행하는 시스템에서는 애플리케이션 변경이 없어도 커널 업그레이드만으로 저장소 성능이 상당히 향상될 수 있습니다.
둘째, io_uring은 일관되게 libaio를 능가합니다. 폴링도 배칭도 없는 io_uring조차 테스트한 모든 커널에서 IOPS와 지연 시간 모두에서 libaio보다 더 좋은 성능을 제공합니다. 최적의 구성에서는 io_uring이 libaio보다 최대 2배 높은 IOPS를 달성합니다. 우리의 실험에서 io_uring은 이미 테스트한 NVMe 장치를 한계에 가깝게 밀어붙였습니다. 더 빠른 스토리지 하드웨어에서는 libaio 대비 이점이 더욱 두드러질 수 있습니다.
셋째, 우리는 커널 5.4와 5.15 사이에서 libaio와 비폴링 io_uring 모두에 성능 회귀를 관찰했습니다. 이 효과가 여러 I/O 인터페이스에 걸쳐 나타나는 만큼, 원인은 I/O API 자체보다는 블록 계층이나 NVMe 드라이버에 있을 가능성이 높습니다. 폴링된 io_uring 모드의 개선이 이 회귀를 일부 가릴 수 있습니다.
동시에 구성은 중요합니다. 특히 IOMMU는 I/O 성능에 상당한 영향을 줄 수 있으므로, 커널 버전 간 결과를 비교할 때 이를 명시적으로 고려해야 합니다. 우리의 경우 Intel IOMMU가 커널 릴리스 사이에서 기본적으로 켜지면서, IOPS가 최대 30%까지 떨어지는 심각한 성능 회귀로 이어졌습니다.
마지막으로, fio 외에도 YDB의 한 컴포넌트를 사용해 이러한 결과를 검증했으며 매우 유사한 결과를 관찰했습니다. 이는 이 결론이 실제 워크로드에도 적용 가능함을 시사합니다. 이러한 통찰은 PostgreSQL처럼 io_uring 지원이 활발히 발전 중인 시스템을 포함해, 현대 Linux I/O 스택에 의존하는 다른 데이터베이스 시스템에도 관련이 있습니다.