GPU로 삼각형을 그리는 법을 익히고, Mesa3D, GLFW, OpenGL, Vulkan, Wayland, Linux DRM을 따라가며 리눅스 그래픽스 시스템이 어떻게 동작하는지 추적해 본다.
GPU로 삼각형을 그리는 법을 익히고, Mesa3D, GLFW, OpenGL, Vulkan, Wayland, Linux DRM을 따라가며 그래픽스 시스템이 어떻게 동작하는지(혹은 동작하지 않는지) 코드를 추적해 본다.
목차
( 이 글은 Lobsters에도 올라왔다 )
예전에는 Linux에서 그래픽 드라이버 문제를 피하려고 Intel 내장 그래픽만 사용해 왔다. 그런데 메인보드를 잘못 고르는 바람에 결국 별도의 그래픽 카드를 써야 하게 되었다. 이제 내 컴퓨터는 절전에서 복귀하는 데 14초가 걸리고, dmesg에는 이런 것들이 쏟아진다:
[59829.886009] [drm] Fence fallback timer expired on ring sdma0
[59830.390003] [drm] Fence fallback timer expired on ring sdma0
[59830.894002] [drm] Fence fallback timer expired on ring sdma0
[79622.739495] amdgpu 0000:01:00.0: [drm:amdgpu_ring_test_helper [amdgpu]] *ERROR* ring comp_1.0.1 test failed (-110)
[79622.909019] amdgpu 0000:01:00.0: [drm:amdgpu_ring_test_helper [amdgpu]] *ERROR* ring comp_1.0.2 test failed (-110)
[79623.075056] amdgpu 0000:01:00.0: [drm:amdgpu_ring_test_helper [amdgpu]] *ERROR* ring comp_1.0.3 test failed (-110)
[79623.241971] amdgpu 0000:01:00.0: [drm:amdgpu_ring_test_helper [amdgpu]] *ERROR* ring comp_1.0.4 test failed (-110)
[79623.408604] amdgpu 0000:01:00.0: [drm:amdgpu_ring_test_helper [amdgpu]] *ERROR* ring comp_1.0.6 test failed (-110)
[80202.893020] [drm] scheduler comp_1.0.1 is not ready, skipping
[80202.893023] [drm] scheduler comp_1.0.2 is not ready, skipping
[80202.893024] [drm] scheduler comp_1.0.3 is not ready, skipping
[80202.893025] [drm] scheduler comp_1.0.4 is not ready, skipping
[80202.893025] [drm] scheduler comp_1.0.6 is not ready, skipping
[80202.936910] [drm] scheduler comp_1.0.1 is not ready, skipping
그런데 "fence"나 "sdma0" ring은 대체 무엇일까? 이 comp_ 스케줄러들은 무엇이고, 왜 이들 중 충분히 많은 수가 준비되지 않으면 Linux는 Oops를 내는 걸까? 그리고 왜 NixOS를 업그레이드한 뒤로는 동영상을 재생할 때 Firefox가 멈추는 걸까? 이제는 Linux 그래픽스가 원래 어떻게 돌아가야 하는지 좀 배워야 할 때라고 생각했다...
화면에 무언가를 표시하려면, 각 픽셀의 색을 담을 메모리 덩어리(_framebuffer_라고 부른다)를 할당한다. (수백만 개에 이르는) 색 값을 모두 계산한 뒤에는 _디스플레이 하드웨어_에 framebuffer의 주소를 알려 주고, 하드웨어는 그 값을 모니터로 보내 화면에 표시한다. 이 동안 우리는 다음 프레임을 다른 framebuffer에 렌더링할 수 있다.
컴퓨터는 이런 종류의 작업에 그다지 잘 최적화되어 있지 않지만, _그래픽 카드_가 이를 가속해 준다. 그래픽 카드는 자체 메모리, 프로세서, 디스플레이 하드웨어를 가진 두 번째 컴퓨터와 비슷하지만 그래픽에 최적화되어 있다:
메인 컴퓨터(호스트)는 보통 적은 수의 매우 빠른 프로세서를 가진다. 그래픽 카드는 많은 수의 상대적으로 느린 프로세서를 가진다. 그래픽 카드 아키텍처가 유용한 이유는, 화면을 많은 작은 타일로 나눠 서로 다른 프로세서에서 병렬로 렌더링할 수 있기 때문이다. 프로세서를 비교적 느리게 돌리면 에너지(와 열)를 절약할 수 있고, 그 덕분에 더 많은 프로세서를 둘 수 있다.
참고: GPU(Graphics Processing Unit)는 반드시 별도의 카드에 있을 필요는 없다. 메인 컴퓨터의 일부일 수도 있고, 전용 RAM 대신 메인 메모리를 사용할 수도 있다.
보통은 여러 애플리케이션을 실행하고 화면을 공유하게 한다. 이상적으로는 각 애플리케이션(예: Firefox)이 GPU에서 코드를 실행해 자신의 창 내용을 GPU 메모리에 렌더링한 뒤 (1), 그 메모리에 대한 참조를 _디스플레이 서버_에 공유하고 (2), 디스플레이 서버(내 경우에는 Sway)가 다시 GPU에서 더 많은 코드를 실행해 (3) 이 창을 최종 이미지에 복사한 뒤 (4), 하드웨어가 이를 화면으로 보낸다 (5):
애플리케이션 프로세스는 Linux 커널 드라이버(내 경우에는 amdgpu)를 통해 GPU에 명령을 보낸다. 모든 GPU는 각자 고유한 API를 가지며, 이들은 매우 저수준이기 때문에 애플리케이션은 일반적으로 Mesa 라이브러리를 사용해 모든 장치에서 동작하는 API를 제공받는다. Mesa는 여러 GPU에 대한 백엔드를 갖고 있고, GPU가 없을 때를 위한 소프트웨어 렌더링 대체 수단도 제공한다.
The Linux graphics stack in a nutshell에 더 많은 설명이 있지만, 나는 직접 시험해 보고 싶었다...
Mesa는 그래픽을 위한 크로스플랫폼 표준 API인 OpenGL을 지원한다. 하지만 창을 열고 적절한 백엔드를 연결하려면 플랫폼별 코드도 필요하다. 조금 찾아본 끝에 GLFW (Graphics Library FrameWork)를 발견했는데, 창 안에 삼각형을 그리는 방법을 보여 주는 좋은 튜토리얼이 있었다.
그건 잘 동작했고, 나는 다채로운 색의 회전하는 삼각형이 들어 있는 창을 얻었다. 전체 화면에서도 부드럽게 애니메이션되었고, CPU 부하는 전혀 보이지 않았다(소프트웨어 렌더링과 비교하려면 LIBGL_ALWAYS_SOFTWARE=true를 사용하라):
이 예제는 먼저 모든 것을 설정하는 것부터 시작한다:
window = glfwCreateWindow(640, 480, ...))glfwMakeContextCurrent(window))GPU에서 실행되는 프로그램은 "shader"라고 부른다(실제로 셰이딩을 하든 아니든). 이들은 C와 비슷한 언어로 작성되며, 예제의 C 소스 코드 안에 문자열로 포함되어 있다.
정점 shader는 삼각형의 3개 정점 각각에 대해 실행되며, 입력 매개변수에 따라 이들을 회전시킨다. 그 다음 프래그먼트 shader는 회전된 삼각형이 덮는 각 화면 픽셀에 대해 실행되며, 그 색을 고른다. 이는 사실상 항등 함수에 가깝다. OpenGL이 세 정점의 색을 자동으로 보간해서 프래그먼트 shader에 입력으로 넘겨 주기 때문이다.
그 다음 예제는 메인 루프를 실행하며, 각 프레임을 렌더링한다:
glfwSwapBuffers(window)).Mesa는 OpenGL 외에도 여러 다른 API를 대안으로 제공한다. OpenGL ES(OpenGL for Embedded Systems)는 대체로 OpenGL의 부분집합이지만, 자체적인 소소한 개선점도 있다. 하지만 내가 특히 관심 있었던 것은 Vulkan이었다...
Vulkan은 자신을 "이전 세대 그래픽 API에서 발견되는 많은 추상화를 제거한 저수준 API"라고 설명한다. 예를 들어, 각 OpenGL 드라이버에는 shader 언어용 컴파일러가 들어 있지만, Vulkan에서는 shader 소스를 외부 도구로 SPIR-V 바이트코드로 컴파일한 뒤 그 바이트코드를 드라이버에 넘기기만 한다. 따라서 Vulkan 드라이버는 더 단순하고 이해하기 쉬워야 한다.
Vulkan tutorial은 "이런 이점을 위해 치르는 대가는 훨씬 더 장황한 API를 다뤄야 한다는 것"이라고 경고한다. 실제로 그렇다. OpenGL 삼각형 예제가 171줄의 C 코드인 반면, Vulkan의 삼각형 예제는 900줄의 C++ 코드다!
하지만 이것이야말로 내가 원하던 것이다. 각 단계가 어떻게 나뉘는지 자세한 분해 설명 말이다. 만들어야 할 객체가 많아서, 나는 결국 이들을 헷갈리지 않기 위해 도표까지 만들었다:
설정 단계는 다음과 같다:
AMD Radeon RX 550 Series와 llvmpipe(소프트웨어 렌더링). 이상하게도 내 Intel 내장 GPU는 여기 나타나지 않았다.[업데이트: BIOS 설정에서 "Internal Graphics"가 "Auto"로 되어 있었고, 그 때문에 비활성화되어 있었다]
이제 메인 루프를 돌릴 준비가 되었다:
_swap chain_에서 다음 _image_를 가져온다(그 image를 덮어쓸 준비가 되면 Vulkan이 _semaphore_로 알려 달라고 요청한다).
수행할 작업을 _command buffer_에 기록한다:
_command buffer_를 device의 _graphics queue_에 넣는다. 이때 기다려야 할 semaphore(_render pass_가 요구함), 끝났을 때 알릴 또 다른 semaphore, 그리고 호스트에 command buffer를 재사용해도 된다고 알릴 _fence_를 함께 넘긴다. 알고 보니 "fence"는 호스트와 공유되는 semaphore일 뿐이다(Vulkan에서 "semaphore"는 GPU 내부에서 신호를 주고받는 데 쓰이는 것을 뜻한다).
_image_의 표시 작업을 device의 _present queue_에 넣고, 렌더링 semaphore에 신호가 오면(디스플레이 서버를 통해) image를 표시하라고 요청한다.
정말 일이 훨씬 많아졌다! 게다가 삼각형을 애니메이션시키는 데도 그 위에 상당한 추가 작업이 필요했다. 그래도 OpenGL보다 동작 방식을 더 잘 이해하게 된 것 같고, 추적하기도 더 쉬울 것 같다.
vulkaninfo 명령은 감지된 GPU에 대한 페이지 수의 정보를 쏟아낸다. 내 출력에서 눈에 띄는 부분은 다음과 같다:
Instance Extensions: count = 24
VK_KHR_wayland_surface : extension revision 6
VK_KHR_xcb_surface : extension revision 6
VK_KHR_xlib_surface : extension revision 6
GPU id : 0 (AMD Radeon RX 550 Series (RADV POLARIS11)) [VK_KHR_wayland_surface]:
VkSurfaceCapabilitiesKHR:
minImageCount = 4
VkQueueFamilyProperties:
queueProperties[0]:
queueFlags = QUEUE_GRAPHICS_BIT | QUEUE_COMPUTE_BIT | QUEUE_TRANSFER_BIT
queueProperties[1]:
queueFlags = QUEUE_COMPUTE_BIT | QUEUE_TRANSFER_BIT
queueProperties[2]:
queueFlags = QUEUE_SPARSE_BINDING_BIT
GPU id : 1 (llvmpipe (LLVM 19.1.7, 256 bits)) [VK_KHR_wayland_surface]:
Vulkan의 흥미로운 기능 중 하나는 "validation layer"를 켤 수 있다는 점이다. 이것은 개발 중에 API를 올바르게 사용하고 있는지 검사해 주고, 실제 배포에서는 성능을 위해 끌 수 있다. 예를 들어 이것 덕분에 튜토리얼의 동기화가 완전히 맞는 것은 아니라는 점을 알 수 있었다(자세한 내용은 Swapchain Semaphore Reuse를 보라. 튜토리얼은 framebuffer마다 하나씩이 아니라 renderFinishedSemaphore 하나만 사용한다).
여기서 흥미로운 점 하나는, swap chain이 렌더링이 끝나기를 기다리지 않고 이미지를 compositor(디스플레이 서버)로 보낸다는 것이다. 그건 어떻게 가능할까?
compositor가 렌더링이 끝나기 전에 이미지를 사용하려 들지 않게 만드는 방법은 두 가지가 있다: 암묵적 동기화와 명시적 동기화다. 암묵적 동기화에서는 Linux 커널이 어떤 GPU 작업이 어떤 버퍼에 접근하는지 추적한다. 그래서 우리가 삼각형을 렌더링하는 작업을 제출하면, 커널은 그 작업의 완료 fence를 출력 버퍼에 붙인다. compositor(내 경우 Sway)가 이미지를 복사하는 GPU 작업을 제출하면, 커널은 먼저 그 fence를 기다린다.
이 방식에는 여러 문제가 있다고 한다. 예를 들어 compositor는 이번 프레임을 기다리기보다는 이미 완료된 이전 프레임을 쓰는 편을 선호할 수 있다. 이를 해결하기 위한 명시적 동기화 Wayland 프로토콜이 있지만, 내가 사용하는 Sway 버전은 그것을 지원하지 않는다.
자세한 내용은 Bridging the synchronization gap on Linux와 Explicit sync를 보라.
렌더링된 이미지는 테스트 애플리케이션에서 Wayland compositor(디스플레이 서버)로 어떻게 전달될까? 튜토리얼 애플리케이션이 주고받는 모든 메시지를 기록하기 위해 WAYLAND_DEBUG=1로 실행해 보았다:
$ WAYLAND_DEBUG=1 ./vulkan-test
{Default Queue} -> wl_display#1.get_registry(new id wl_registry#2)
{Default Queue} -> wl_display#1.sync(new id wl_callback#3)
{Display Queue} wl_display#1.delete_id(3)
...
하지만 출력은 혼란스러웠고, strace를 보니 테스트 애플리케이션이 디스플레이 서버에 4번 연결하고 있었다:
$ strace -e connect ./vulkan-test 2>&1 | grep /wayland
connect(3, {sa_family=AF_UNIX, sun_path="/run/user/1000/wayland-1"}, 27) = 0
connect(5, {sa_family=AF_UNIX, sun_path="/run/user/1000/wayland-1"}, 27) = 0
connect(23, {sa_family=AF_UNIX, sun_path="/run/user/1000/wayland-1"}, 27) = 0
connect(23, {sa_family=AF_UNIX, sun_path="/run/user/1000/wayland-1"}, 27) = 0
더 복잡한 점은, 예제가 6개의 Wayland queue를 사용하고 있다는 것이다:
$ WAYLAND_DEBUG=1 ./vulkan-test 2>&1 | sed -n 's/.*\({[^}]*}\).*/\1/p' | sort | uniq -c
618 {Default Queue}
135 {Display Queue}
288 {mesa formats query}
72 {mesa image count query}
144 {mesa present modes query}
385 {mesa vk display queue}
전체적으로 테스트 애플리케이션은 Sway에 지원되는 확장(프로토콜) 목록을 14번이나 요청한다! 같은 확장을 반복해서 bind하고 (zwp_linux_dmabuf_v1.get_default_feedback도 반복 호출한다):
$ WAYLAND_DEBUG=1 ./vulkan-test 2>&1 | grep get_registry
{Default Queue} -> wl_display#1.get_registry(new id wl_registry#2)
{Default Queue} -> wl_display#1.get_registry(new id wl_registry#3)
{Default Queue} -> wl_display#1.get_registry(new id wl_registry#21)
{Default Queue} -> wl_display#1.get_registry(new id wl_registry#2)
{Default Queue} -> wl_display#1.get_registry(new id wl_registry#2)
{Default Queue} -> wl_display#1.get_registry(new id wl_registry#2)
{mesa image count query} -> wl_display#1.get_registry(new id wl_registry#52)
{mesa formats query} -> wl_display#1.get_registry(new id wl_registry#51)
{mesa formats query} -> wl_display#1.get_registry(new id wl_registry#50)
{mesa present modes query} -> wl_display#1.get_registry(new id wl_registry#43)
{mesa present modes query} -> wl_display#1.get_registry(new id wl_registry#44)
{mesa formats query} -> wl_display#1.get_registry(new id wl_registry#46)
{mesa formats query} -> wl_display#1.get_registry(new id wl_registry#48)
{mesa vk display queue} -> wl_display#1.get_registry(new id wl_registry#42)
정말 엉망이다!
여기서는 너무 많은 일이 일어나고 있다. GLFW는 Wayland와 X11, OpenGL과 Vulkan, 그리고 키보드와 포인터 지원까지 한꺼번에 끌어오고 있다. 게다가 CPU 스레드도 11개나 사용한다!
나는 GLFW 라이브러리를 제거하고, 대신 wayland-book.com의 최소한의 Wayland 골격 코드를 넣었다. Wayland와 Vulkan 사이의 주요 통합 지점은 VkSurfaceKHR인데, 이전에는 이것을 GLFW가 만들어 주고 있었다. 나는 glfwCreateWindowSurface를 vkCreateWaylandSurfaceKHR로 바꾸기만 하면 되었다. 이것은 libwayland의 wl_display와 wl_surface 객체를 받아 Vulkan surface 구조체에 저장한다.
strace에 따르면 이제는 Wayland 연결이 4번이 아니라 3번, 스레드는 11개가 아니라 5개, get_registry 호출은 14번이 아니라 11번이다. 그래도 여전히 너무 많다!
잡음이 심한 이유 중 하나는 Vulkan API가 열거 함수를 두 번 호출해야 한다는 점이다. 한 번은 결과 배열에 얼마나 큰 공간이 필요한지 알아내기 위해, 두 번째는 실제로 메모리를 할당한 뒤 다시 호출하기 위해서다. 예를 들어 튜토리얼은 장치를 이렇게 가져오라고 한다:
1 2 3 4``` uint32_t deviceCount = 0; vkEnumeratePhysicalDevices(instance, &deviceCount, nullptr); std::vector<VkPhysicalDevice> devices(deviceCount); vkEnumeratePhysicalDevices(instance, &deviceCount, devices.data());
Mesa는 두 번 모두 Wayland에 새 연결을 만든다. 우리가 그걸 신경 쓰지 않는데도, compositor의 기본 장치를 목록 맨 앞에 두기 위해 그렇게 한다(우리가 원하는 것은 일반적인 대체 장치가 아니라, 특정 Wayland surface와 맞는 장치를 고르는 것이다). 이것은 항상 첫 번째로 반환된 장치를 선택하는 애플리케이션을 위한 해킹처럼 보인다.
## Vulkan의 Wayland 확장 제거하기
더 단순하게 만들기 위해, instance 확장에서 Wayland 통합을 담당하는 `VK_KHR_wayland_surface`를 제거하고, swapchain도 내 코드로 바꿨다. 이건 사실 꽤 어려웠고, Mesa가 어떻게 하는지 보려고 gdb로 여러 곳을 따라가며 확인해야 했다.
이상하게도 present queue는 전혀 필요하지 않은 것 같다. 어떤 코드 경로에서는 먼저 데이터를 blit해야 해서 queue를 그 대기 용도로 쓰는 듯한데, 내가 Wayland와 함께 쓰는 방식에서는 그게 필요 없었다.
validation layer 경고와도 조금 씨름해야 했다(삼각형은 잘 표시되고 있었지만). 예를 들어 Mesa는 이미지를 `VK_EXTERNAL_MEMORY_HANDLE_TYPE_DMA_BUF_BIT_EXT`로 생성하는데, 꽤 타당해 보이지만 그러면 `VUID-VkImageCreateInfo-pNext-00990`가 발생한다. 나는 الآن `VK_EXTERNAL_MEMORY_HANDLE_TYPE_OPAQUE_FD_BIT`를 사용하고 있는데, 뭔가 잘못된 것 같지만 동작하고 validation도 만족시킨다.
이 단순한 버전조차도 여전히 스레드 3개를 사용하고 있었다! `gdb`에서 `break __clone3`를 걸어 보니 Radeon 드라이버의 `radv_physical_device_try_create` 함수가 디스크 캐시 두 개(둘 다 `vulkan-:disk$0`라는 이름)를 만들고, 그 과정에서 스레드가 생성되었다. 추적 관점에서 캐시는 잡음과 혼란만 더하므로, 이를 끄기 위해 코드에서 `MESA_SHADER_CACHE_DISABLE=1`을 설정했다.
최종 버전은 단일 스레드를 사용하고, Wayland compositor에 한 번만 연결하며, `get_registry`도 한 번만 호출한다. 함께 따라 해 보고 싶다면 코드는 [vulkan-test](https://github.com/talex5/vulkan-test) 에 있고, 다음처럼 실행할 수 있다:
git clone https://github.com/talex5/vulkan-test.git -b blog cd vulkan-test nix develop make && ./vulkan-test 200
오른쪽으로 미끄러지는 삼각형이 보여야 한다. `200`은 종료되기 전에 표시할 프레임 수다.
## Wayland 따라가기
Wayland 로깅을 켠 상태로 테스트 애플리케이션을 실행하려면:
$ make trace > wayland.log
생성된 [wayland.log](https://roscidus.com/blog/data/graphics/wayland.log)에는 Sway(내 Wayland compositor)와 주고받은 모든 메시지뿐 아니라, 내가 코드에 추가한 몇몇 `printf` 메시지도 들어 있다.
[main](https://github.com/talex5/vulkan-test/blob/blog/main.c#L227) 함수는 몇 가지 확장을 사용해 새로운 Vulkan instance를 만드는 것으로 시작한다:
1
2
3
4
5
6
7
8
9```
const char* instanceExtensions[] = {
VK_KHR_GET_PHYSICAL_DEVICE_PROPERTIES_2_EXTENSION_NAME, // Get Unix device ID to compare with Wayland
VK_KHR_EXTERNAL_MEMORY_CAPABILITIES_EXTENSION_NAME, // Share images over Wayland
VK_KHR_EXTERNAL_SEMAPHORE_CAPABILITIES_EXTENSION_NAME, // Use Linux sync files
};
VkInstance instance;
...
LOG("Create instance with %d layers\n", createInfo.enabledLayerCount);
vkCreateInstance(&createInfo, NULL, &instance)
validation layer를 켜고 싶다면 //#define VALIDATION의 주석을 풀면 되지만, 추적을 위해 나는 꺼 두었다:
Create instance with 0 layers
다음으로 테스트 애플리케이션은 Wayland에 연결하고 지원되는 확장(프로토콜)의 registry를 요청한다:
1 2 3 4 5``` state->display = wl_display_connect(NULL);
struct wl_registry *registry = wl_display_get_registry(state->display); wl_registry_add_listener(registry, ®istry_listener, state); wl_display_roundtrip(state->display);
로그를 보면 Sway가 많은 확장으로 응답한다. 우리가 원하는 것을 보면, 그 특정 버전을 _bind_한다:
-> wl_display#1.get_registry(new id wl_registry#2) -> wl_display#1.sync(new id wl_callback#3) wl_display#1.delete_id(3) wl_registry#2.global(1, "wl_shm", 2) wl_registry#2.global(2, "zwp_linux_dmabuf_v1", 4) -> wl_registry#2.bind(2, "zwp_linux_dmabuf_v1", 4, new id [unknown]#4) wl_registry#2.global(3, "wl_compositor", 6) -> wl_registry#2.bind(3, "wl_compositor", 4, new id [unknown]#5) wl_registry#2.global(4, "wl_subcompositor", 1) wl_registry#2.global(5, "wl_data_device_manager", 3) wl_registry#2.global(6, "zwlr_gamma_control_manager_v1", 1) wl_registry#2.global(7, "zxdg_output_manager_v1", 3) wl_registry#2.global(8, "ext_idle_notifier_v1", 1) wl_registry#2.global(9, "zwp_idle_inhibit_manager_v1", 1) wl_registry#2.global(10, "zwlr_layer_shell_v1", 4) wl_registry#2.global(11, "xdg_wm_base", 5) -> wl_registry#2.bind(11, "xdg_wm_base", 1, new id [unknown]#6)
`->`로 시작하는 줄은 우리가 compositor에 보낸 메시지다. 예를 들어 `-> wl_display#1.get_registry(new id wl_registry#2)`는 [wl_display](https://wayland.app/protocols/wayland#wl_display) 타입의 객체 #1에 `get_registry` 요청을 보내, ID #2의 새 `wl_registry` 객체를 만들라고 한 뜻이다.
우리는 [zwp_linux_dmabuf_v1](https://wayland.app/protocols/linux-dmabuf-v1)(GPU 메모리 공유용), [wl_compositor](https://wayland.app/protocols/wayland#wl_compositor)(화면 표시의 기본 지원), 그리고 [xdg_wm_base](https://wayland.app/protocols/xdg-shell#xdg_wm_base)(데스크톱 창 생성용)를 bind한다.
확장은 더 많지만, 우리는 그것들엔 관심이 없다:
wl_registry#2.global(12, "zwp_tablet_manager_v2", 1) wl_registry#2.global(13, "org_kde_kwin_server_decoration_manager", 1) wl_registry#2.global(14, "zxdg_decoration_manager_v1", 1) wl_registry#2.global(15, "zwp_relative_pointer_manager_v1", 1) wl_registry#2.global(16, "zwp_pointer_constraints_v1", 1) wl_registry#2.global(17, "wp_presentation", 1) wl_registry#2.global(18, "wp_alpha_modifier_v1", 1) wl_registry#2.global(19, "zwlr_output_manager_v1", 4) wl_registry#2.global(20, "zwlr_output_power_manager_v1", 1) wl_registry#2.global(21, "zwp_input_method_manager_v2", 1) wl_registry#2.global(22, "zwp_text_input_manager_v3", 1) wl_registry#2.global(23, "ext_foreign_toplevel_list_v1", 1) wl_registry#2.global(24, "zwlr_foreign_toplevel_manager_v1", 3) wl_registry#2.global(25, "ext_session_lock_manager_v1", 1) wl_registry#2.global(26, "wp_drm_lease_device_v1", 1) wl_registry#2.global(27, "zwlr_export_dmabuf_manager_v1", 1) wl_registry#2.global(28, "zwlr_screencopy_manager_v1", 3) wl_registry#2.global(29, "zwlr_data_control_manager_v1", 2) wl_registry#2.global(30, "wp_security_context_manager_v1", 1) wl_registry#2.global(31, "wp_viewporter", 1) wl_registry#2.global(32, "wp_single_pixel_buffer_manager_v1", 1) wl_registry#2.global(33, "wp_content_type_manager_v1", 1) wl_registry#2.global(34, "wp_fractional_scale_manager_v1", 1) wl_registry#2.global(35, "wp_tearing_control_manager_v1", 1) wl_registry#2.global(36, "zxdg_exporter_v1", 1) wl_registry#2.global(37, "zxdg_importer_v1", 1) wl_registry#2.global(38, "zxdg_exporter_v2", 1) wl_registry#2.global(39, "zxdg_importer_v2", 1) wl_registry#2.global(40, "xdg_activation_v1", 1) wl_registry#2.global(41, "wp_cursor_shape_manager_v1", 1) wl_registry#2.global(42, "zwp_virtual_keyboard_manager_v1", 1) wl_registry#2.global(43, "zwlr_virtual_pointer_manager_v1", 2) wl_registry#2.global(44, "zwp_keyboard_shortcuts_inhibit_manager_v1", 1) wl_registry#2.global(45, "zwp_pointer_gestures_v1", 3) wl_registry#2.global(46, "ext_transient_seat_manager_v1", 1) wl_registry#2.global(47, "wl_seat", 9) wl_registry#2.global(48, "zwp_primary_selection_device_manager_v1", 1) wl_registry#2.global(50, "wl_output", 4) wl_callback#3.done(59067)
Mesa 자체의 Wayland 지원은 [wp_presentation](https://wayland.app/protocols/presentation-time)("부드러운 동영상 재생을 보장하기 위한 정확한 표시 타이밍 피드백")과 [wp_tearing_control_manager_v1](https://wayland.app/protocols/tearing-control-v1)("티어링을 허용해 지연 감소")도 bind하지만, 나는 어느 쪽도 구현하지 않았다. 또한 Sway가 지원했다면 Mesa는 [wp_linux_drm_syncobj_manager_v1](https://wayland.app/protocols/linux-drm-syncobj-v1), [wp_fifo_manager_v1](https://wayland.app/protocols/fifo-v1), [wp_commit_timing_manager_v1](https://wayland.app/protocols/commit-timing-v1)도 bind했을 것이다.
다음으로 창을 만들고, 그 창에 대한 "feedback"을 Sway에 요청한다:
-> wl_compositor#5.create_surface(new id wl_surface#3) -> xdg_wm_base#6.get_xdg_surface(new id xdg_surface#7, wl_surface#3) -> xdg_surface#7.get_toplevel(new id xdg_toplevel#8) -> xdg_toplevel#8.set_title("Example client") -> wl_surface#3.commit() -> zwp_linux_dmabuf_v1#4.get_surface_feedback(new id zwp_linux_dmabuf_feedback_v1#9, wl_surface#3) -> wl_display#1.sync(new id wl_callback#10) wl_display#1.delete_id(10)
Sway는 우리가 아직 살아 있는지 확인하고, 우리는 응답한다:
xdg_wm_base#6.ping(59068) -> xdg_wm_base#6.pong(59068)
그 다음 feedback이 도착한다:
zwp_linux_dmabuf_feedback_v1#9.main_device(array[8]) zwp_linux_dmabuf_feedback_v1#9.format_table(fd 4, 1600) zwp_linux_dmabuf_feedback_v1#9.tranche_target_device(array[8]) zwp_linux_dmabuf_feedback_v1#9.tranche_flags(0) zwp_linux_dmabuf_feedback_v1#9.tranche_formats(array[200]) Wayland compositor supports DRM_FORMAT_XRGB8888 with modifier 0xffffffffffffff zwp_linux_dmabuf_feedback_v1#9.tranche_done() zwp_linux_dmabuf_feedback_v1#9.done() wl_callback#10.done(59069)
`main_device`는 "서버가 사용하길 선호하는 주 장치"를 알려 준다. 이것은 단지 숫자(`dev_t` 타입)이며, Wayland는 이를 바이트 배열로 보낸다. 우리는 나중을 위해 이것을 저장한다.
format table에는 Linux 포맷이 나열되어 있고, 여기서 Vulkan도 지원하는 적절한 것을 찾아야 한다. 테스트 애플리케이션은 `DRM_FORMAT_XRGB8888`만 지원하며, 그것을 찾으면 로그를 남긴다.
포맷 외에도 이미지에는 픽셀이 어떻게 배치되는지 나타내는 _modifier_가 있다([Tiling](https://docs.mesa3d.org/isl/tiling.html) 참조). 내 카드는 이를 지원하지 않는 것 같아서, 나는 예전 방식의 `DRM_FORMAT_RESERVED` (`0xffffffffffffff`)를 사용하고 있다.
discarded xdg_toplevel#8.configure(0, 0, array[0]) xdg_surface#7.configure(59069) -> xdg_surface#7.ack_configure(59069) -> zwp_linux_dmabuf_feedback_v1#9.destroy()
Sway의 특이한 점 하나는, 처음에 크기 0x0인 `configure`를 보내면서 우리가 크기를 선택하라고 한다는 것이다(그리고 나중에 그 값을 무시한다). 로그 메시지에 `discarded`라고 나온 것은, 내가 이 메시지에 대한 핸들러를 등록하지 않았기 때문이다.
창이 열려 있는 동안 compositor는 추가 feedback을 보낼 수도 있다. 아마 창을 다른 GPU에 연결된 다른 화면으로 끌어다 놓으면, 이제는 그 장치를 선호한다고 알려 줄 수도 있을 것이다. 하지만 Sway는 그냥 업데이트를 보내므로, 로그가 지저분해지는 것을 피하려고 나는 feedback 객체를 파괴해 버렸다.
이제 `main.c`로 돌아가서, 위 Wayland의 "main device"와 일치하는 Vulkan device를 찾기 위해 [find_wayland_device](https://github.com/talex5/vulkan-test/blob/blog/main.c#L186)를 호출한다:
Wayland compositor main device is 226,128
이것은 이 장치의 major와 minor 부분이다:
$ stat --format="%Hr,%Lr" /dev/dri/renderD128 226,128
Vulkan에 특정 device를 요청하는 방법은 없는 것 같다. 대신 `vkEnumeratePhysicalDevices`를 호출해 모두 가져오고 목록을 뒤진다. 테스트 애플리케이션은 반환된 두 장치를 나열한다. 그리고 첫 번째 장치의 ID가 Wayland에서 받은 것과 일치함을 보고 그것을 선택한다.
Vulkan found 2 physical devices 0: AMD Radeon RX 550 Series (RADV POLARIS11) 1: llvmpipe (LLVM 19.1.7, 256 bits) Using device 0 (matches Wayland rendering node)
우리는 `vkGetPhysicalDeviceQueueFamilyProperties`를 사용해 그래픽 연산을 지원하는 queue를 찾고, 그런 queue 하나를 가진 논리 device를 만든다:
Device has 3 queue families Found graphics queue family (0) Create logical device
다음으로 command pool을 만들고, 미리 컴파일된 shader 바이트코드를 읽어 와 렌더링 pipeline을 설정한다:
Create command pool Loaded shaders/vert.spv (1856 bytes) Loaded shaders/frag.spv (572 bytes) vkCreateDescriptorSetLayout vkCreatePipelineLayout vkCreateRenderPass vkCreateDescriptorPool vkAllocateDescriptorSets Create uniform buffer 0 createBuffer vkMapMemory vkUpdateDescriptorSets Create uniform buffer 1 createBuffer vkMapMemory vkUpdateDescriptorSets Create uniform buffer 2 createBuffer vkMapMemory vkUpdateDescriptorSets Create uniform buffer 3 createBuffer vkMapMemory vkUpdateDescriptorSets vkCreateGraphicsPipeline
uniform buffer는 렌더링 코드에 입력 매개변수를 전달하는 데 사용된다. 우리는 각 프레임마다 숫자 하나를 전달해서, [shader.vert](https://github.com/talex5/vulkan-test/blob/blog/shaders/shader.vert#L3-L5)에 삼각형을 오른쪽으로 얼마나 움직일지 알려 줄 것이다.
버퍼를 할당하려면 어떤 종류의 메모리를 쓸지 골라야 한다. 어떤 메모리 타입은 접근이 빠르지만 그래픽 카드 위에 있어야 하고, 다른 것들은 더 느리지만 CPU에서도 접근할 수 있다. `vkGetBufferMemoryRequirements`는 그 버퍼에 적합한 메모리 타입을 알려 주고, 우리는 거기서 우리가 원하는 속성도 갖춘 것을 찾는다([findMemoryType](https://github.com/talex5/vulkan-test/blob/blog/helpers.c#L63) 사용). 예제 코드는 호스트에서도 보이고, 호스트와 coherent해서(수동 동기화가 필요 없는) 메모리를 할당한다.
다음으로 첫 번째 framebuffer를 위한 `VkImage`를 만들고, 그에 대한 device 메모리를 할당한 뒤, 그 메모리를 이미지에 bind한다:
Create framebuffer 0 vkCreateImage vkAllocateMemory vkBindImageMemory
이미지용 메모리는 빠른 것(호스트에서 접근 가능한 것이 아니라 GPU 로컬 메모리)을 선택한다.
이제 Wayland compositor에 framebuffer의 메모리를 알려 줘야 한다. GPU 메모리에 대한 참조를 Unix 파일 디스크립터로 내보내고, `zwp_linux_dmabuf_feedback_v1` 프로토콜을 사용해 Vulkan이 그것을 어떻게 배치할 계획인지에 대한 정보와 함께 compositor에 보낸다:
vkGetMemoryFdKHR -> zwp_linux_dmabuf_v1#4.create_params(new id zwp_linux_buffer_params_v1#10) -> zwp_linux_buffer_params_v1#10.add(fd 12, 0, 0, 2560, 16777215, 4294967295) -> zwp_linux_buffer_params_v1#10.create_immed(new id wl_buffer#11, 640, 480, 875713112, 0) -> zwp_linux_buffer_params_v1#10.destroy()
다른 framebuffer들에 대해서도 같은 일을 한다:
Create framebuffer 1 vkCreateImage vkAllocateMemory vkBindImageMemory vkGetMemoryFdKHR -> zwp_linux_dmabuf_v1#4.create_params(new id zwp_linux_buffer_params_v1#12) -> zwp_linux_buffer_params_v1#12.add(fd 14, 0, 0, 2560, 16777215, 4294967295) -> zwp_linux_buffer_params_v1#12.create_immed(new id wl_buffer#13, 640, 480, 875713112, 0) -> zwp_linux_buffer_params_v1#12.destroy() Create framebuffer 2 vkCreateImage vkAllocateMemory vkBindImageMemory vkGetMemoryFdKHR -> zwp_linux_dmabuf_v1#4.create_params(new id zwp_linux_buffer_params_v1#14) -> zwp_linux_buffer_params_v1#14.add(fd 16, 0, 0, 2560, 16777215, 4294967295) -> zwp_linux_buffer_params_v1#14.create_immed(new id wl_buffer#15, 640, 480, 875713112, 0) -> zwp_linux_buffer_params_v1#14.destroy() Create framebuffer 3 vkCreateImage vkAllocateMemory vkBindImageMemory vkGetMemoryFdKHR -> zwp_linux_dmabuf_v1#4.create_params(new id zwp_linux_buffer_params_v1#16) -> zwp_linux_buffer_params_v1#16.add(fd 18, 0, 0, 2560, 16777215, 4294967295) -> zwp_linux_buffer_params_v1#16.create_immed(new id wl_buffer#17, 640, 480, 875713112, 0) -> zwp_linux_buffer_params_v1#16.destroy() Start main loop
이제 프레임을 표시하는 메인 루프를 돌릴 준비가 되었다. 각 프레임은 compositor에게 그 다음다음 프레임을 원할 때 알려 달라고 요청하는 것으로 시작한다:
-> wl_surface#3.frame(new id wl_callback#18)
이전 프레임이 아직 렌더링 중이라면 기다려야 한다. 모든 프레임에 같은 command buffer를 재사용하고 있기 때문이다(물론 첫 프레임에서는 이게 중요하지 않다):
Wait for inFlightFence Rendering frame 0 with framebuffer 0
이제 암묵적 동기화 지원 부분이다. 현재 framebuffer를 사용 중인 작업이 있다면 그것들에 대한 _sync file_을 Linux에 요청해서 받아오고, 그것을 `imageAvailableSemaphore`에 붙인다. 첫 번째 프레임에서는 아무것도 없겠지만, 일반적으로는 compositor의 렌더링 작업이 아직 사용 중인 framebuffer를 우리가 재사용할 수도 있다. 그런 다음 command buffer에 렌더링 명령과 `imageAvailableSemaphore`에 대한 의존성을 채워 넣고 GPU에 제출한다:
Import imageAvailableSemaphore Submit to graphicsQueue
GPU가 프레임을 렌더링하는 동안, 우리는 Vulkan의 `renderFinishedSemaphore`를 Linux sync file로 내보내고 그것을 이미지에 붙이게 한다. 이렇게 하면 compositor는 렌더링이 끝날 때까지 그 이미지를 사용하려 하지 않는다. 마지막으로 진행 중인 framebuffer(framebuffer 0에 대한 `wl_buffer#11`)를 surface에 붙이고, compositor에 다음 프레임에 이것을 쓰라고 알린다:
Export renderFinishedSemaphore -> wl_surface#3.attach(wl_buffer#11, 0, 0) -> wl_surface#3.damage(0, 0, 2147483647, 2147483647) -> wl_surface#3.commit()
2147483647은 32비트 부호 있는 정수의 최댓값으로, 창 전체를 무효화한다는 뜻이다.
이제 첫 번째 프레임이 끝났으니, 계속 들어오는 Wayland 메시지를 처리한다. compositor는 여러 객체(feedback 객체와 4개 framebuffer의 buffer params)에 대한 삭제를 확인해 준다:
wl_display#1.delete_id(9) wl_display#1.delete_id(10) wl_display#1.delete_id(12) wl_display#1.delete_id(14) wl_display#1.delete_id(16)
compositor는 다음 프레임 callback이 더 이상 존재하지 않는다고 알린 뒤, 그 callback이 완료되었다고 알린다. 순서가 반대인 것 같지만 어쨌든 동작한다!
wl_display#1.delete_id(18) wl_callback#18.done(40055490)
그래서 이제 이전과 똑같이 두 번째 프레임을 처리한다:
-> wl_surface#3.frame(new id wl_callback#18) Wait for inFlightFence Rendering frame 1 with framebuffer 1 Import imageAvailableSemaphore Submit to graphicsQueue Export renderFinishedSemaphore -> wl_surface#3.attach(wl_buffer#13, 0, 0) -> wl_surface#3.damage(0, 0, 2147483647, 2147483647) -> wl_surface#3.commit()
두 번째 프레임이 끝난 뒤에야, Sway는 마침내 창 크기가 얼마인지 알려 준다:
discarded xdg_toplevel#8.configure(962, 341, array[8]) xdg_surface#7.configure(59070) -> xdg_surface#7.ack_configure(59070)
이 시점에서 모든 framebuffer를 다시 만들어야 하지만, 나는 귀찮아서 그냥 640x480으로 계속 렌더링한다:
wl_display#1.delete_id(18) wl_callback#18.done(40055491) -> wl_surface#3.frame(new id wl_callback#18) Wait for inFlightFence Rendering frame 2 with framebuffer 2 Import imageAvailableSemaphore Submit to graphicsQueue Export renderFinishedSemaphore -> wl_surface#3.attach(wl_buffer#15, 0, 0) -> wl_surface#3.damage(0, 0, 2147483647, 2147483647) -> wl_surface#3.commit()
프레임 2(세 번째 프레임)를 보낸 뒤, Sway는 프레임 0과 1을 다 썼다고 알려 주고 프레임 3을 요청한다(`delete_id`와 `done`의 순서는 더더욱 수상하다!):
discarded wl_buffer#11.release() wl_display#1.delete_id(18) discarded wl_buffer#13.release() wl_callback#18.done(40055493)
이론적으로는 framebuffer를 재사용하기 전에 `release`를 기다려야 한다. 그래야 Sway가 그것을 표시하기 시작했고, 따라서 거기서 sync file을 안전하게 꺼낼 수 있다는 것을 알 수 있기 때문이다. 하지만 framebuffer가 4개나 있고, Sway가 프레임 0 렌더링을 시작하기도 전에 프레임 4를 요청할 가능성은 아주 낮아 보였기 때문에, 이 테스트에서는 그 부분을 구현하지 않았다.
-> wl_surface#3.frame(new id wl_callback#18) Wait for inFlightFence Rendering frame 3 with framebuffer 3 Import imageAvailableSemaphore Submit to graphicsQueue Export renderFinishedSemaphore -> wl_surface#3.attach(wl_buffer#17, 0, 0) -> wl_surface#3.damage(0, 0, 2147483647, 2147483647) -> wl_surface#3.commit() discarded wl_buffer#15.release()
그리고 프레임 4에서는 첫 번째 framebuffer(`#11`)를 재사용한다:
wl_display#1.delete_id(18) wl_callback#18.done(40055497) -> wl_surface#3.frame(new id wl_callback#18) Wait for inFlightFence Rendering frame 4 with framebuffer 0 Import imageAvailableSemaphore Submit to graphicsQueue Export renderFinishedSemaphore -> wl_surface#3.attach(wl_buffer#11, 0, 0) -> wl_surface#3.damage(0, 0, 2147483647, 2147483647) -> wl_surface#3.commit() discarded wl_buffer#17.release() wl_display#1.delete_id(18)
## bpftrace로 보는 커널 세부사항
커널 안에서 무슨 일이 일어나는지 보기 위해, 나는 bpftrace 스크립트([trace.bt](https://github.com/talex5/vulkan-test/blob/blog/trace.bt))를 만들었다. 이 스크립트는 애플리케이션이 stdout과 stderr에 쓰는 내용도 가로채서 자기 출력에 포함하므로, 모든 것이 순서대로 한곳에 나타난다.
$ sudo bpftrace trace.bt > bpftrace.log
그런 다음 다른 창에서 예전처럼 애플리케이션을 실행했다. 이 스크립트는 amdgpu 전용 함수 여러 개를 추적하므로, 직접 시도해 보려면 GPU와 커널 버전에 맞게 약간 수정해야 할 것이다.
참고로, 내 시스템의 전체 로그는 여기 있다: [bpftrace.log](https://roscidus.com/blog/data/graphics/bpftrace.log)
### 시작과 라이브러리 로딩
bpftrace 로그를 보면 몇몇 라이브러리가 열리는 것이 보인다:
Attaching 25 probes... open(.../wayland-1.23.1/lib/libwayland-client.so.0) => 3 open(.../vulkan-loader-1.4.313.0/lib/libvulkan.so.1) => 3 open(.../libdrm-2.4.124/lib/libdrm.so.2) => 3 open(.../glibc-2.40-66/lib/libm.so.6) => 3 open(.../glibc-2.40-66/lib/libc.so.6) => 3 open(.../libffi-3.4.8/lib/libffi.so.8) => 3 open(.../glibc-2.40-66/lib/libdl.so.2) => 3
(공간을 아끼기 위해 `/nix/store/HASH-` 접두사는 제거했다. 3은 FD이고, close는 추적하지 않았기 때문에 이것이 재사용되고 있다.)
이 라이브러리들은 모두 예상 가능한 것들이다. 우리는 Wayland 프로토콜을 말하기 위해 `libwayland-client`를, 그래픽 카드와 대화하기 위해 `libvulkan`과 `libdrm`을 사용한다. `libc`와 `libm`은 표준 라이브러리(C와 수학)이고, `ffi`와 `dl`은 더 많은 라이브러리를 동적으로 로드하기 위한 것이다.
Vulkan loader는 먼저 layer를 훑어본다:
Create instance with 0 layers open(/run/opengl-driver/share/vulkan/implicit_layer.d) => 3 open(/run/opengl-driver/share/vulkan/implicit_layer.d/VkLayer_MESA_device_select.json) => 3 open(.../vulkan-validation-layers-1.4.313.0/share/vulkan/explicit_layer.d) => 3 open(.../vulkan-validation-layers-1.4.313.0/share/vulkan/explicit_layer.d/VkLayer_khronos_validation.json) => 3
그 다음 Radeon 드라이버를 로드한다:
open(/run/opengl-driver/share/vulkan/icd.d/radeon_icd.x86_64.json) => 3 open(.../mesa-25.0.7/lib/libvulkan_radeon.so) => 3 open(.../llvm-19.1.7-lib/lib/libLLVM.so.19.1) => 3 open(.../elfutils-0.192/lib/libelf.so.1) => 3 open(.../libxcb-1.17.0/lib/libxcb-dri3.so.0) => 3 open(.../zlib-1.3.1/lib/libz.so.1) => 3 open(.../zstd-1.5.7/lib/libzstd.so.1) => 3 open(.../libxcb-1.17.0/lib/libxcb.so.1) => 3 open(.../libX11-1.8.12/lib/libX11-xcb.so.1) => 3 open(.../libxcb-1.17.0/lib/libxcb-present.so.0) => 3 open(.../libxcb-1.17.0/lib/libxcb-xfixes.so.0) => 3 open(.../libxcb-1.17.0/lib/libxcb-sync.so.1) => 3 open(.../libxcb-1.17.0/lib/libxcb-randr.so.0) => 3 open(.../libxcb-1.17.0/lib/libxcb-shm.so.0) => 3 open(.../libxshmfence-1.3.3/lib/libxshmfence.so.1) => 3 open(.../xcb-util-keysyms-0.4.1/lib/libxcb-keysyms.so.1) => 3 open(.../systemd-minimal-libs-257.5/lib/libudev.so.1) => 3 open(.../expat-2.7.1/lib/libexpat.so.1) => 3 open(.../libdrm-2.4.124/lib/libdrm_amdgpu.so.1) => 3 open(.../gcc-14.2.1.20250322-lib/lib/libstdc++.so.6) => 3 open(.../gcc-14.2.1.20250322-lib/lib/libgcc_s.so.1) => 3 open(.../glibc-2.40-66/lib/librt.so.1) => 3 open(.../libxml2-2.13.8/lib/libxml2.so.2) => 3 open(.../xz-5.8.1/lib/liblzma.so.5) => 3 open(.../bzip2-1.0.8/lib/libbz2.so.1) => 3 open(.../libXau-1.0.12/lib/libXau.so.6) => 3 open(.../libXdmcp-1.1.5/lib/libXdmcp.so.6) => 3 open(.../libcap-2.75-lib/lib/libcap.so.2) => 3 open(.../glibc-2.40-66/lib/libpthread.so.0) => 3
여기에는 AMD Radeon 드라이버 관련 것들(`libvulkan_radeon.so`와 `libdrm_amdgpu.so`)도 보이고, 압축 라이브러리 4개, XML 파서 2개, 컴파일러 관련 것들도 보인다.
그리고 오래된 X11 프로토콜용 라이브러리 12개(`libxcb` 등)도 보인다. 나는 X11을 전혀 쓰지 않는데도 이건 꽤 놀랍다.
이해하기 어려운 7ms 지연 후에, Vulkan은 대체용 소프트웨어 렌더러("lavapipe")를 로드한다:
[7 ms] open(/run/opengl-driver/share/vulkan/icd.d/lvp_icd.x86_64.json) => 3 open(.../mesa-25.0.7/lib/libvulkan_lvp.so) => 3
보통은 더 많은 드라이버를 로드하겠지만, 추적을 조금 짧게 만들기 위해 `VK_DRIVER_FILES`를 사용해 그것들을 비활성화했다.
그 다음 device 선택용 Vulkan layer를 로드한다:
open(.../mesa-25.0.7/lib/libVkLayer_MESA_device_select.so) => 3
이게 바로 드라이버 목록을 정렬하려고 원치 않는 Wayland 연결을 만들던 녀석이다. Wayland 확장을 제거한 뒤로는 더 이상 그러지 않는다.
그 다음 Mesa는 몇몇 설정 파일을 로드한다. 이것들은 버그가 있는 애플리케이션 목록과 그에 대한 우회책처럼 보인다:
open(.../mesa-25.0.7/share/drirc.d) => 3 open(.../mesa-25.0.7/share/drirc.d/00-mesa-defaults.conf) => 3 open(.../mesa-25.0.7/share/drirc.d/00-radv-defaults.conf) => 3
### 장치 열거
Wayland가 우리가 사용할 장치를 알려 준 뒤, 그것을 찾기 위해 `vkEnumeratePhysicalDevices`를 호출해야 한다. 이것은 Mesa가 알고 있는 모든 드라이버를 시도하면서, 사용 가능한 모든 GPU를 찾는다. lavapipe 소프트웨어 드라이버가 먼저 가서 sync file을 내보낼 수 있는지 검사한다:
Wayland compositor main device is 226,128 open(/sys/devices/system/cpu/possible) => 4 open(/dev/udmabuf) => 4 ioctl(/dev/udmabuf, UDMABUF_CREATE) => fd 6 ioctl(6, DMA_BUF_IOCTL_EXPORT_SYNC_FILE) => fd 7
그 다음 Mesa의 Radeon 드라이버가 `/dev/dri` 디렉터리를 나열하고, 각 장치의 `dev_t` ID를 얻고, `/sys`에서 그에 대한 정보를 조회한다:
stat(/dev/dri/card0) => rdev=226,0 readlink(/sys/dev/char/226:0) => ../../devices/pci0000:00/0000:00:01.0/0000:01:00.0/drm/card open(/sys/devices/pci0000:00/0000:00:01.0/0000:01:00.0/vendor) => 10 ... stat(/dev/dri/renderD128) => rdev=226,128 readlink(/sys/dev/char/226:128) => ../../devices/pci0000:00/0000:00:01.0/0000:01:00.0/drm/renderD12 open(/sys/devices/pci0000:00/0000:00:01.0/0000:01:00.0/vendor) => 10 ...
그 다음 Mesa는 `/dev/dri/renderD128`을 여는데, 이때 여러 흥미로운 일이 일어난다:
drm_sched_entity_init ([sdma0, sdma1]) drm_sched_entity_init ([sdma0, sdma1]) drm_sched_job (sched=918:1 finished=919:1) drm_sched_job (sched=918:2 finished=919:2) drm_sched_job (sched=918:3 finished=919:3) open(/dev/dri/renderD128) => 9
`open` 호출은 시작 시점이 아니라 반환 시점에 기록된다는 점에 유의하라. 나는 커널 내부에서 일어나는 일은 들여쓰기로 표시하고 있다.
메인 컴퓨터는 GPU에 명령을 보내기 위해 그것들을 _ring_에 쓴다. 각 장치는 여러 ring을 가질 수 있다. 내 장치의 경우 `/sys/kernel/debug/dri/0000:01:00.0/amdgpu_fence_info`에는 18개의 ring이 나열되며, 그 안에는 그래픽 ring 1개, compute ring 8개, SDMA ring 2개가 포함되어 있다(자세한 내용은 [https://docs.kernel.org/gpu/amdgpu/debugfs.html](https://docs.kernel.org/gpu/amdgpu/debugfs.html) 참조).
[Core Driver Infrastructure](https://docs.kernel.org/gpu/amdgpu/driver-core.html) 문서에 따르면 SDMA는 "System DMA"다. DMA는 [Direct Memory Access](https://en.wikipedia.org/wiki/Direct_memory_access)다. 따라서 SDMA ring은 GPU에 호스트 메모리와의 데이터 전송을 요청하는 방법인 것 같다.
GPU를 쓰고 싶어 하는 프로세스는 많을 수 있고, 각자 자신만의 "entity" queue를 받는다. _GPU scheduler_는 이 queue들에서 작업을 꺼내 ring에 올리며, 어느 프로세스가 우선순위를 갖는지 결정한다. 각 entity queue는 어떤 ring 집합을 사용할 수 있다.
장치를 여는 과정에서 `amdgpu_vm_init_entities`가 호출되었고, 그것이 두 개의 entity queue(`immediate`와 `delayed`)를 만들었는데, 둘 다 `sdma0`와 `sdma1` ring에 제출할 수 있다. 왜 queue를 두 개 쓰는지는 잘 모르겠다.
`drm_sched_job`은 어떤 작업이 entity queue에 추가되었음을 뜻한다(하지만 헷갈리게도, 실제로 스케줄링되었다는 뜻은 아니다). `sched=X`는 그 작업이 하드웨어 ring에 기록되면 fence X에 신호가 간다는 뜻이고, `finished=Y`는 GPU가 그 작업을 끝내면 fence Y에 신호가 간다는 뜻이다.
fence라고 불리는 것에는 여러 종류가 있는 것 같다:
* `dma_fence`는 내가 부르고 싶은 말로 하자면 "promise"와 비슷하다. 처음에는 신호가 오지 않은 상태이고, 신호가 오면 호출할 callback 목록을 갖고 있다. 이후 신호가 오면 callback에 알린다. 재사용은 불가능하다.
(나는 이 용어가 그다지 마음에 들지 않는다. "약속을 만들기", "약속을 이행하기", "약속이 이행되기를 기다리기"는 말이 된다. 하지만 "fence에 신호를 보낸다"나 "fence를 기다린다"는 말은 잘 와닿지 않는다.)
* `drm_sched_fence`는 3개의 fence 모음이다: 위에서 말한 `submitted`와 `finished`, 그리고 GPU의 fence인 `parent`다. `parent`는 `finished`와 비슷하지만, `parent`는 작업이 ring에 추가되기 전까지는 존재하지 않는다.
여기서도 용어는 좀 이상하다. 상식적으로라면 parent는 child보다 먼저 존재해야 할 것 같다.
* Vulkan의 `VkFence`도 있는데, 이것은 재사용 가능한 `dma_fence`의 가변 컨테이너에 더 가깝다.
DMA fence는 `CONTEXT:SEQNO` 형식의 고유 ID를 가진다. 각 entity queue는 전역 풀에서 두 개의 context ID를 할당받고(`sched`와 `finished` fence용), 그 context 안에서 요청 번호를 순서대로 매긴다.
그 다음 `open` 호출이 반환되었고, Mesa는 장치의 세부사항을 몇 가지 조회했다. 그리고 곧이어 커널은 미리 queue에 쌓여 있던 두 작업을 ring에 제출했다:
ioctl(/dev/dri/renderD128, VERSION) => 3.61 ioctl(/dev/dri/renderD128, VERSION) => amdgpu 3.61 amdgpu_job_run on sdma1 (finished=919:1) => parent=12:19449 dma_fence_signaled 918:1 amdgpu_job_run on sdma1 (finished=919:2) => parent=12:19450 dma_fence_signaled 918:2
`parent=Z`는 장치 fence Z가 생성되었음을 의미한다. `sched` fence는 작업이 장치에서 실행되도록 스케줄링되었음을 나타내기 위해 신호를 받는다.
`sched` fence가 필요한 이유는, 우리가 장치에 어떤 작업을 기다리라고 요청할 수 있는 것은 그 작업에 장치 fence가 있을 때뿐이기 때문이다. 그래서 작업 A가 아직 제출되지 않은 다른 작업 B에 의존한다면, 커널은 먼저 B의 `sched` fence를 기다려야 한다. 그래야 B의 `parent` fence를 알 수 있고, A를 GPU에 제출할 때 그것을 의존성으로 지정할 수 있다.
결국 `parent` fence에 신호가 오고, 그러면 `finished` fence에도 신호가 간다:
dma_fence_signaled 12:19449 dma_fence_signaled 919:1 dma_fence_signaled 12:19450 dma_fence_signaled 919:2
이것은 `amdgpu_irq_dispatch`에서 호출되는 `amdgpu_fence_process`에 의해 일어난다. 왜 어떤 함수가 호출되는지 알고 싶으면 bpftrace에 커널 스택(`kstack`)을 출력하라고 언제든 요청할 수 있다. 나는 이 인터럽트 핸들러들은 추적하지 않았는데, GPU의 모든 활동에 대해 호출되므로 내 테스트 애플리케이션과 무관한 것까지 추적을 어지럽히기 때문이다.
### 파이프라인 설정
Mesa가 결국 장치 목록을 반환하면, 우리는 원하는 것을 고르고 그것에 대한 `VkDevice`를 만든다. 이 과정에서 여러 작업이 장치에 제출된다:
Create logical device ioctl(/dev/dri/renderD128, AMDGPU_CTX) ioctl(/dev/dri/renderD128, AMDGPU_GEM_CREATE) => handle 1 drm_sched_job (sched=918:4 finished=919:4) drm_sched_job (sched=918:5 finished=919:5) drm_sched_job (sched=918:6 finished=919:6) ioctl(/dev/dri/renderD128, AMDGPU_GEM_VA, 1) ioctl(/dev/dri/renderD128, AMDGPU_GEM_CREATE) => handle 2 drm_sched_job (sched=918:7 finished=919:7) ioctl(/dev/dri/renderD128, AMDGPU_GEM_VA, 2) ioctl(/dev/dri/renderD128, AMDGPU_GEM_MMAP) amdgpu_job_run on sdma0 (finished=919:4) => parent=11:46118 dma_fence_signaled 918:4 amdgpu_job_run on sdma0 (finished=919:5) => parent=11:46119 dma_fence_signaled 918:5 ioctl(/dev/dri/renderD128, AMDGPU_GEM_CREATE) => handle 3 ...
다시 말하지만 `ioctl` 줄은 호출이 시작될 때가 아니라 반환될 때 기록된다.
command buffer를 만들 때도 device 메모리를 할당하고, descriptor set을 만들 때도, 각 uniform buffer(shader에 입력 데이터를 넘기기 위한 것)를 만들 때도, framebuffer를 만들 때도 메모리를 할당한다.
내게 가장 흥미로웠던 설정 단계는 `vkUpdateDescriptorSets`였다. 이것은 시스템 호출을 전혀 하지 않고, 위의 entity queue도 쓰지 않지만, 다른 entity queue에 작업을 제출한다. Mesa의 [ac_build_buffer_descriptor](https://gitlab.freedesktop.org/mesa/mesa/-/blob/35721f19866d07dc671d4a83d6f6b77240629cb6/src/amd/common/ac_descriptors.c#L807)를 보면 descriptor용 메모리에 그냥 쓰기를 시도하는 것 같고, 그러면 fault가 발생해서 먼저 GPU에서 호스트로 메모리를 옮기는 작업이 실행된다:
vkUpdateDescriptorSets (via amdgpu_bo_fault_reserve_notify) drm_sched_job (sched=789:865 finished=790:865) (via amdgpu_bo_fault_reserve_notify) drm_sched_job (sched=789:866 finished=790:866) amdgpu_job_run on sdma0 (finished=790:865) => parent=11:46127 dma_fence_signaled 789:865 amdgpu_job_run on sdma0 (finished=790:866) => parent=11:46129 dma_fence_signaled 789:866
나는 원래 모든 `dma_fence_init` 호출을 추적하고 있었기 때문에 이 사실을 눈치챘다. 최종 버전에서는 그렇게 하지 않았는데, 다른 프로세스를 위해 만들어진 fence까지 포함되기 때문이다.
### 프레임 하나 렌더링하기
마지막으로, 추가 추적을 붙인 상태에서 프레임 하나의 렌더링을 살펴보자.
우리는 먼저 `inFlightFence`를 기다린다(이것은 이전 프레임 렌더링이 끝났음을 알린다). 이것은 Linux의 [sync obj](https://docs.kernel.org/gpu/drm-mm.html#drm-sync-objects)로 구현되어 있다. sync obj는 _sync file_과 혼동하면 안 되며, `dma_fence`를 담는 컨테이너다. sync obj 안의 fence는 제거하거나 교체할 수 있기 때문에 재사용 가능하다.
Wait for inFlightFence ioctl(/dev/dri/renderD128, SYNCOBJ_WAIT, 6) ioctl(/dev/dri/renderD128, SYNCOBJ_RESET, 6) Rendering frame 0 with framebuffer 0
다음으로, Sway가 지난번에 이 framebuffer를 사용하기 위해 실행했던 렌더링 작업의 `dma_fence`를 내보낸다. 우리는 dmabuf(이미지)에서 [sync file](https://www.kernel.org/doc/html/latest/driver-api/sync_file.html#sync-file-api-guide)로 내보내고(이것은 하나의 고정된 `dma_fence`를 담는 불변 컨테이너다), 그다음 그것을 새 _sync obj_로 가져온다(Vulkan이 기존 것을 재사용하지 않는 이유는 모르겠다):
Import imageAvailableSemaphore dma_resv_get_fences => 0 fences ioctl(11, DMA_BUF_IOCTL_EXPORT_SYNC_FILE) => fd 19 ioctl(/dev/dri/renderD128, SYNCOBJ_CREATE) => handle 7 ioctl(/dev/dri/renderD128, SYNCOBJ_FD_TO_HANDLE, fd 19, handle 7)
첫 번째 프레임에서는 당연히 Sway가 이것을 아직 사용 중일 수 없으므로, fence가 없는 sync file을 받는다. 하지만 나중 프레임들(재사용되는 framebuffer를 쓰는 프레임들)에서도 나는 여기서 늘 `0 fences`만 본다. framebuffer가 4개나 있고(Mesa가 쓰는 개수다), Sway가 프레임을 요청할 때 렌더링하는 방식이라면, 실제로 뭔가를 기다려야 할 일은 거의 없을 것 같다.
렌더링 작업을 제출할 때, Mesa는 먼저 sync obj가 채워질 때까지 기다린다. 이건 멀티스레드 코드 지원과 관련된 것 같다:
Submit to graphicsQueue ioctl(/dev/dri/renderD128, SYNCOBJ_TIMELINE_WAIT, 7, ALL|FOR_SUBMIT|AVAILABLE)
Mesa는 `DRM_AMDGPU_CS`로 렌더링 작업을 제출한다(Command Submission? Command Stream?). 우리가 이 작업을 처음 수행할 때, 커널은 그래픽 ring에 제출하는 entity queue를 지연 생성한다:
drm_sched_entity_init ([gfx]) drm_sched_job (sched=918:28 finished=919:29) drm_sched_job (sched=918:29 finished=919:29) amdgpu_job_run on sdma1 (finished=919:28) => parent=12:19458 dma_fence_signaled 918:28 drm_sched_job (sched=921:1 finished=922:1) ioctl(/dev/dri/renderD128, AMDGPU_CS) => handle 1 ioctl(/dev/dri/renderD128, SYNCOBJ_DESTROY, 7)
렌더링이 완료될 때를 알려 주는 semaphore를 내보내고, 그것을 이미지에 붙인다(Sway가 거기서 그것을 찾게 된다):
Export renderFinishedSemaphore ioctl(/dev/dri/renderD128, SYNCOBJ_TIMELINE_WAIT, 1, ALL|FOR_SUBMIT|AVAILABLE) ioctl(/dev/dri/renderD128, SYNCOBJ_HANDLE_TO_FD, 1) => fd 19 ioctl(/dev/dri/renderD128, SYNCOBJ_RESET, 1) ioctl(11, DMA_BUF_IOCTL_IMPORT_SYNC_FILE)
마지막으로 새 프레임을 Sway에 알린다:
-> wl_surface#3.attach(wl_buffer#11, 0, 0) -> wl_surface#3.damage(0, 0, 2147483647, 2147483647) -> wl_surface#3.commit()
얼마 지나지 않아 커널은 그 작업을 장치의 그래픽 ring에 제출한다:
amdgpu_job_run on gfx (finished=922:1) => parent=1:1525895 dma_fence_signaled 921:1
## 오류 다시 살펴보기
좋다. 이제 처음의 오류 메시지들이 좀 더 이해되는지 보자. 먼저 "Fence fallback":
[59829.886009 < 0.504003>] [drm] Fence fallback timer expired on ring sdma0 [59830.390003 < 0.503994>] [drm] Fence fallback timer expired on ring sdma0 [59830.894002 < 0.503999>] [drm] Fence fallback timer expired on ring sdma0
Linux가 GPU에 요청을 보내면, 끝났을 때 GPU가 인터럽트를 발생시킬 것으로 기대한다. 하지만 혹시 그러지 않을 경우를 대비해 Linux는 0.5초 타이머도 설정해 두고 수동으로 확인한다. 인터럽트가 도착하면 타이머는 취소된다(혹은 아직 처리되지 않은 fence가 더 있으면 다음 0.5초를 위해 재설정된다). 이 로그 메시지는 타이머가 발사되었고 _동시에_ 완료된 fence가 발견되었을 때 기록된다. 즉, 진행은 되고 있지만 매우 느리다는 뜻이다. 내 로그에는 이런 것이 20개 연속으로 있었으니, 어떤 이유로 10초 동안 인터럽트가 전달되지 않았던 것처럼 보인다. Linux 6.6.89에서 6.12.28로 업그레이드하니 이 문제는 해결된 것 같다.
이제 ring 테스트를 보자:
[79622.739495 < 0.001128>] amdgpu 0000:01:00.0: [drm:amdgpu_ring_test_helper [amdgpu]] ERROR ring comp_1.0.1 test failed (-110) [79622.909019 < 0.169524>] amdgpu 0000:01:00.0: [drm:amdgpu_ring_test_helper [amdgpu]] ERROR ring comp_1.0.2 test failed (-110) [79623.075056 < 0.166037>] amdgpu 0000:01:00.0: [drm:amdgpu_ring_test_helper [amdgpu]] ERROR ring comp_1.0.3 test failed (-110) [79623.241971 < 0.166915>] amdgpu 0000:01:00.0: [drm:amdgpu_ring_test_helper [amdgpu]] ERROR ring comp_1.0.4 test failed (-110) [79623.408604 < 0.166633>] amdgpu 0000:01:00.0: [drm:amdgpu_ring_test_helper [amdgpu]] ERROR ring comp_1.0.6 test failed (-110)
나는 `amdgpu_ring_test_helper`에 대해 `bpftrace`를 돌리고, 호출될 때 커널 스택 트레이스를 출력하게 했다. 보니 절전 진입 시(`amdgpu_device_ip_suspend_phase2` / `gfx_v8_0_hw_fini`)와 복귀 시(`amdgpu_device_ip_resume_phase2`, `gfx_v8_0_hw_init`) 각 ring마다 호출되는 것 같았다.
`gfx_v8_0_ring_test_ring`이 실행되어 `mmSCRATCH_REG0`(그게 무엇이든 간에)를 `0xCAFEDEAD`로 설정하고, ring에 작업을 제출해서 그것을 `0xDEADBEEF`로 바꾸게 한 뒤, `mmSCRATCH_REG0`가 바뀌는지 최대 100ms 동안 1μs마다 확인한다. 오류 코드 `-110`은 `-ETIMEDOUT`다.
ring을 덤프해 보니 명령은 거기에 있는 것처럼 보인다(`beef dead`가 보인다):
0000000 0100 0000 0100 0000 0100 0000 7900 c001 0000010 0040 0000 beef dead 1000 ffff 1000 ffff ...
물론 그게 이전 테스트의 흔적일 가능성도 있긴 하다.
시간 초과가 발생하면 이 ring들은 준비되지 않은 것으로 표시된다. 그리고 compute 작업을 스케줄링하려 할 때, `drm_sched_pick_best`가 다음과 같이 로그를 남긴다:
[80202.893020 < 576.587829>] [drm] scheduler comp_1.0.1 is not ready, skipping
그런데 애초에 왜 우리가 compute ring을 쓰고 있는 걸까? 다시 `bpftrace`로 추적해 보니, Sway에서 새 창을 열 때 스케일링이 적용되어 있으면 compute 작업이 제출되는 것 같았다.
나는 다음과 같은 [Linux kernel 메일링 리스트 글](https://lore.kernel.org/lkml/ede4dabb-d3e9-45bf-8e56-aebbb8a37ae5@amd.com/)을 찾았다:
> Either we need to tell Mesa to stop using the compute queues by default (what is that good for anyway?) or we need to get the compute queues reliable working after a resume.
나는 [RADV driver environment variables](https://docs.mesa3d.org/envvars.html)에 나오는 `RADV_DEBUG=nocompute`를 설정해 보았지만 도움이 되지 않았다. Sway는 여전히 somehow compute 작업이 제출되게 만들고 있었다. AMD 엔지니어들도 이게 동작하지 않는다는 것을 알고 있고, 어떻게 고쳐야 할지도 모르는 것처럼 보이므로, 나는 직접 고치려는 시도는 포기하기로 했다.
마지막으로 Firefox 문제를 살펴봤다. `WAYLAND_DEBUG=1`로 실행하고 YouTube 동영상을 재생하려 하자, 마지막으로 기록된 것은 이것이었다:
{mesa egl surface queue} -> wl_display#1.sync(new id wl_callback#78)
즉 Mesa는 Sway에 sync 요청(ping)을 보내고 응답을 기대하는데, 응답을 받지 못하고 있었다. `ss -x -p`를 보니 Firefox가 Sway의 응답을 읽고 있지 않았다:
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port Process u_str ESTAB 6480 0 * 519138 * 528576 users:((".firefox-wrappe",pid=70663,fd=9))
조금 `bpftrace`를 써 보니, Mesa 스레드는 이벤트를 보내는 동안 그것을 읽는 일은 Firefox의 메인 스레드에 의존하고 있었다. 그리고 gdb로 그것을 확인해 보니, 메인 스레드는 D-Bus 서비스를 기다리며 멈춰 있었다. 항상 발생하는 것은 아니고, `strace`나 `dbus-monitor`를 실행하면 문제가 자주 사라지는 것을 보아 일종의 경쟁 상태처럼 보인다. Firefox가 D-Bus를 사용하지 못하게 `DBUS_SESSION_BUS_ADDRESS= firefox`로 실행하니 문제가 해결된 것 같다. (사람들이 왜 D-Bus를 쓰는지 모르겠다. 단순한 소켓을 쓰는 것보다 나은 점이 없어 보인다)
## 결론
나는 오랫동안 그래픽이 어떻게 동작하는지 조금은 이해하고 싶었지만, 자세하면서도 초보자에게 친절한 설명을 찾지 못했다. 이 단순한 예제 프로그램을 만들고 추적하는 방식은 꽤 잘 먹혀든 것 같지만, 시간이 오래 걸리긴 했다. 이제 나는 Linux가 내는 오류들이 무슨 뜻인지는 이해하게 되었고, 비록 그것들을 어떻게 고칠지는 아직 모르지만 말이다.
`WAYLAND_DEBUG`와 `bpftrace`는 예전보다 Linux에서 무언가를 추적하는 일을 훨씬 쉽게 만들어 주고, Wayland 메시지, 애플리케이션 로그, 커널 내부를 하나의 추적 안에서 함께 볼 수 있다는 점이 정말 유용하다. Nix가 gdb가 필요로 할 때 [디버그 심볼을 주문형으로 내려받는 능력](https://github.com/symphorien/nixseparatedebuginfod)도 아주 잘 동작했다.
Vulkan은 좋은 저수준 API처럼 보이고, 덕분에 동작 방식을 훨씬 이해하기 쉬웠다. 다만 Vulkan의 Wayland 지원이 libwayland C 라이브러리를 반드시 쓰게 강제한다는 점은 아쉽다. 나는 아마 예를 들어 ocaml-wayland를 쓰고 싶을 텐데, 그러려면 swapchain을 사용하지 않는 다른 접근이 필요한 듯하다. Linux DRM 포맷을 Vulkan 포맷으로 매핑하는 것 같은 유용한 함수들은 Mesa의 공개 API에 노출되어 있지 않아서, 직접 중복 구현해야 한다.
또한 Mesa 드라이버가 너무 많은 라이브러리에 의존한다는 점도 아쉽다. 그중에는 더 이상 권장되지 않는 X11 프로토콜용 라이브러리 12개도 포함된다. 우리는 이미 [XZ Utils 백도어](https://en.wikipedia.org/wiki/XZ_Utils_backdoor) 같은 사례를 통해 이것이 공급망 공격을 더 쉽게 만든다는 것을 보았다(실제로 아무 데도 쓰지 않더라도 C 라이브러리를 링크하는 것만으로도 위험하다).
이렇게 추적을 한 줄씩 따라가는 접근이 누군가에게는 유용했기를 바란다. 소프트웨어가 어떻게 동작하는지 설명할 때는 지루하거나 어색한 부분을 건너뛰기 쉽고, 이런 방식은 그것을 막는 데 도움이 된다. 물론 이미 동작 방식을 잘 아는 사람이 쓴 설명을 읽는 편이 더 좋겠지만 말이다.
 그래픽 카드가 있는 Wayland 데스크톱
그래픽 카드가 있는 Wayland 데스크톱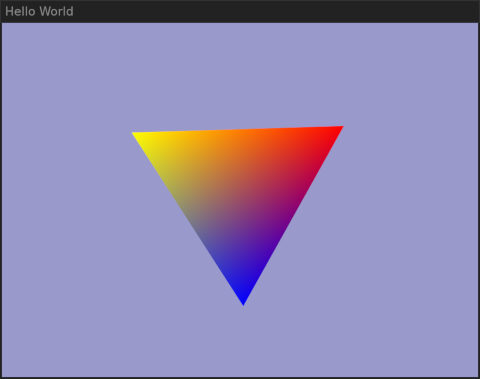 OpenGL 삼각형
OpenGL 삼각형 Vulkan 객체 의존성
Vulkan 객체 의존성