복잡한 시스템 엔지니어링과 장기 에이전틱 작업을 겨냥한 GLM-5를 공개한다. 확장형 사전학습과 비동기 RL 인프라 slime, DSA 통합을 통해 추론·코딩·에이전트 성능을 개선하고 다양한 사용/배포 방법을 소개한다.
복잡한 시스템 엔지니어링과 장기(롱 호라이즌) 에이전틱 작업을 목표로 GLM-5를 출시합니다. 스케일링은 여전히 인공 일반 지능(AGI)의 지능 효율을 향상시키는 가장 중요한 방법 중 하나입니다. GLM-4.5와 비교해 GLM-5는 **355B 파라미터(활성 32B)**에서 **744B 파라미터(활성 40B)**로 확장했으며, 사전학습 데이터도 23T에서 28.5T 토큰으로 증가했습니다. 또한 GLM-5는 DeepSeek Sparse Attention(DSA) 을 통합해, 긴 컨텍스트 처리 능력은 유지하면서 배포 비용을 크게 낮췄습니다.
강화학습(Reinforcement Learning, RL)은 사전학습 모델의 ‘유능함(competence)’과 ‘탁월함(excellence)’ 사이의 간극을 메우는 것을 목표로 합니다. 그러나 LLM에 RL을 대규모로 적용하는 것은 RL 학습의 비효율성 때문에 어렵습니다. 이를 위해 우리는 새로운 비동기 RL 인프라인 slime을 개발했습니다. slime은 학습 처리량과 효율을 크게 높여 보다 세밀한 사후학습 반복(iteration)을 가능하게 합니다. 사전학습과 사후학습 모두의 진전을 통해, GLM-5는 다양한 학술 벤치마크 전반에서 GLM-4.7 대비 유의미한 개선을 제공하며, 추론·코딩·에이전틱 작업에서 전 세계 오픈소스 모델 중 최고 수준의 성능을 달성해 프런티어 모델과의 격차를 좁혔습니다.
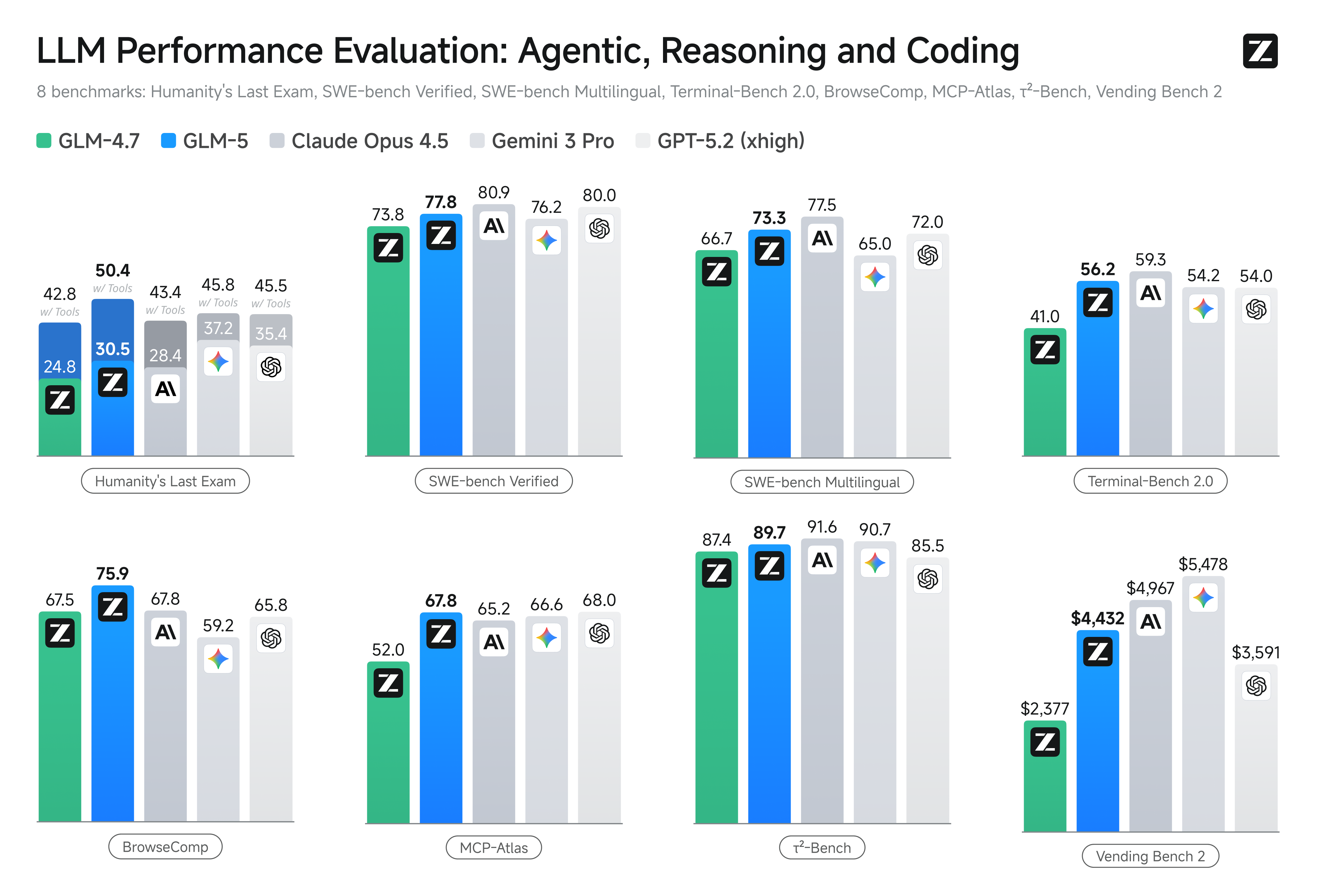
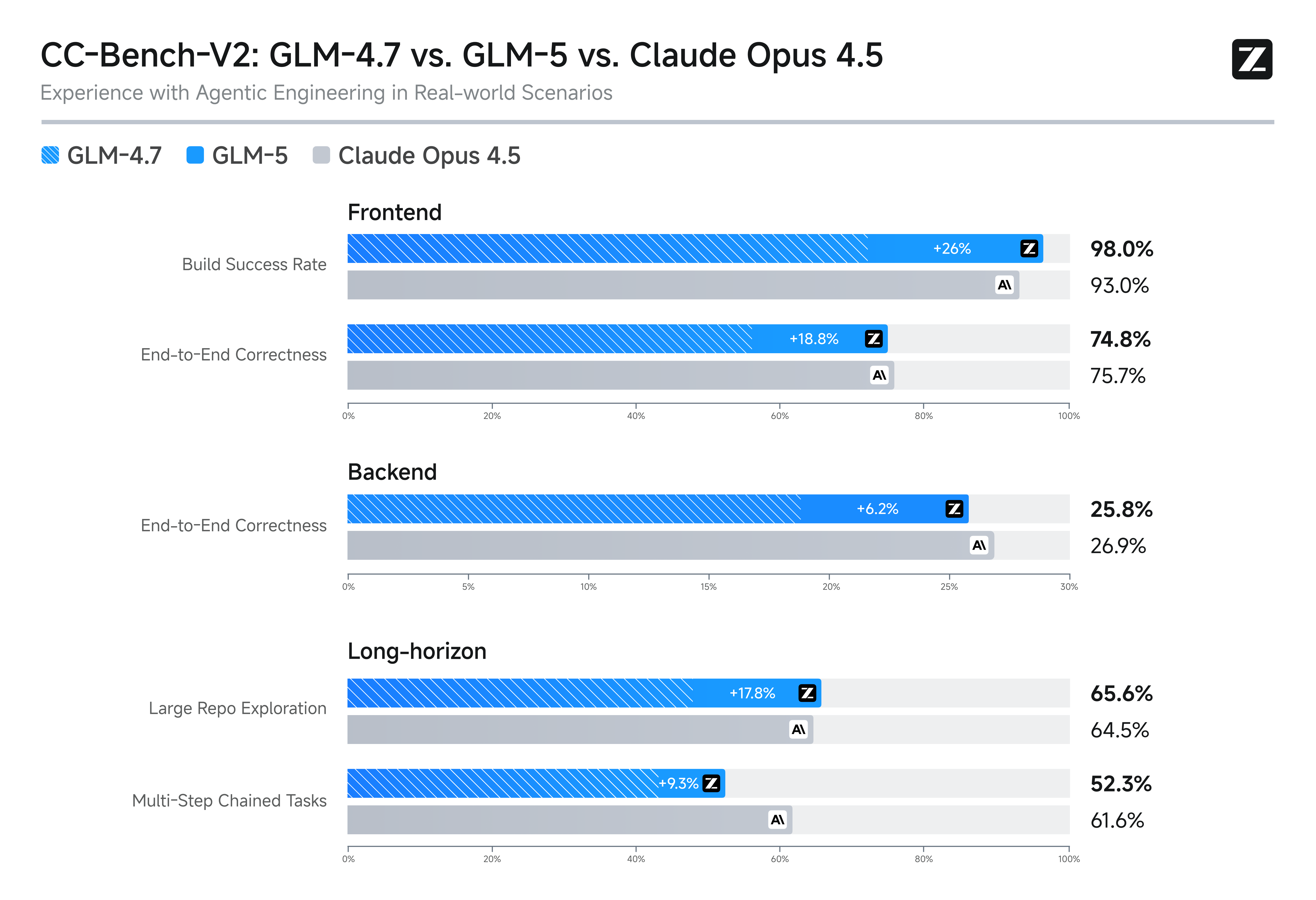
GLM-5는 복잡한 시스템 엔지니어링과 장기 에이전틱 작업을 위해 설계되었습니다. 내부 평가 스위트 CC-Bench-V2에서 GLM-5는 프론트엔드, 백엔드, 장기 작업 전반에 걸쳐 GLM-4.7을 크게 앞서며 Claude Opus 4.5와의 격차를 줄였습니다.
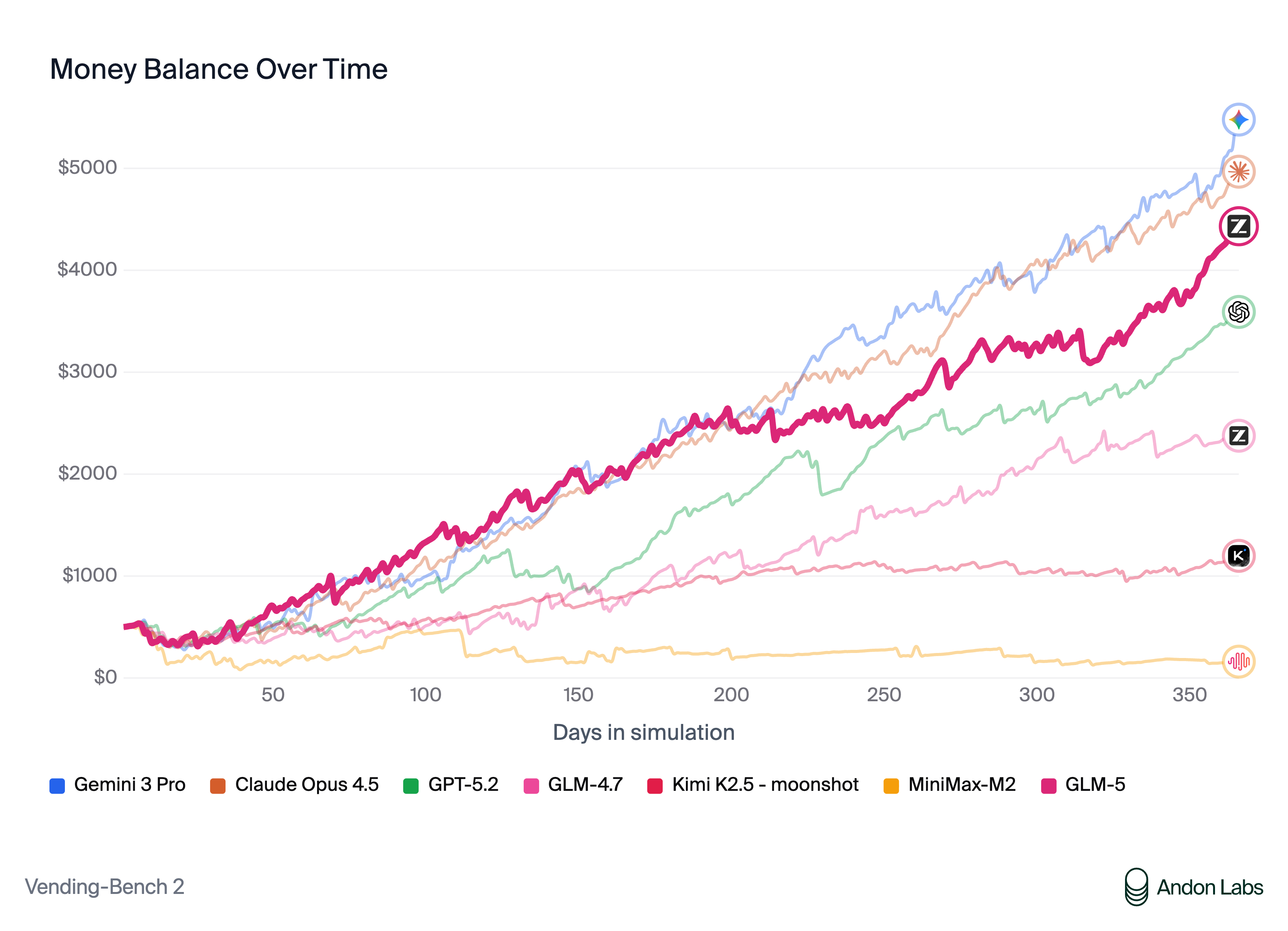
장기 운영 능력을 측정하는 벤치마크인 Vending Bench 2에서 GLM-5는 오픈소스 모델 중 1위를 기록했습니다. Vending Bench 2는 1년 기간 동안 시뮬레이션된 자판기 비즈니스를 운영하도록 요구합니다. GLM-5는 최종 계좌 잔액 $4,432로 마무리했으며, Claude Opus 4.5에 근접한 결과로 강력한 장기 계획 및 자원 관리 능력을 보여줍니다.
GLM-5는 Hugging Face와 ModelScope에 오픈소스로 공개되었으며, 모델 가중치는 MIT License로 배포됩니다. 또한 GLM-5는 개발자 플랫폼 api.z.ai 및 BigModel.cn에서 제공되며, Claude Code 및 OpenClaw와의 호환성을 지원합니다. Z.ai에서 무료로 체험할 수도 있습니다.
| 벤치마크 | GLM-5 (Thinking) | GLM-4.7 (Thinking) | DeepSeek-V3.2 (Thinking) | Kimi K2.5 (Thinking) | Claude Opus 4.5 (Extend Thinking) | Gemini 3.0 Pro (High Thinking Level) | GPT-5.2 (xhigh) |
|---|---|---|---|---|---|---|---|
| 추론 | |||||||
| Humanity's Last Exam | 30.5 | 24.8 | 25.1 | 31.5 | 28.4 | 37.2 | 35.4 |
| Humanity's Last Exam w/ Tools | 50.4 | 42.8 | 40.8 | 51.8 | 43.4* | 45.8* | 45.5* |
| AIME 2026 I | 92.7 | 92.9 | 92.7 | 92.5 | 93.3 | 90.6 | - |
| HMMT Nov. 2025 | 96.9 | 93.5 | 90.2 | 91.1 | 91.7 | 93.0 | 97.1 |
| IMOAnswerBench | 82.5 | 82.0 | 78.3 | 81.8 | 78.5 | 83.3 | 86.3 |
| GPQA-Diamond | 86.0 | 85.7 | 82.4 | 87.6 | 87.0 | 91.9 | 92.4 |
| 코딩 | |||||||
| SWE-bench Verified | 77.8 | 73.8 | 73.1 | 76.8 | 80.9 | 76.2 | 80.0 |
| SWE-bench Multilingual | 73.3 | 66.7 | 70.2 | 73.0 | 77.5 | 65.0 | 72.0 |
| Terminal-Bench 2.0 Terminus-2 | 56.2 / 60.7† | 41.0 | 39.3 | 50.8 | 59.3 | 54.2 | 54.0 |
| Terminal-Bench 2.0 Claude Code | 56.2 / 61.1† | 32.8 | 46.4 | - | 57.9 | - | - |
| CyberGym | 43.2 | 23.5 | 17.3 | 41.3 | 50.6 | 39.9 | - |
| 범용 에이전트 | |||||||
| BrowseComp | 62.0 | 52.0 | 51.4 | 60.6 | 37.0 | 37.8 | - |
| BrowseComp w/ Context Manage | 75.9 | 67.5 | 67.6 | 74.9 | 67.8 | 59.2 | 65.8 |
| BrowseComp-Zh | 72.7 | 66.6 | 65.0 | 62.3 | 62.4 | 66.8 | 76.1 |
| τ²-Bench | 89.7 | 87.4 | 85.3 | 80.2 | 91.6 | 90.7 | 85.5 |
| MCP-Atlas Public Set | 67.8 | 52.0 | 62.2 | 63.8 | 65.2 | 66.6 | 68.0 |
| Tool-Decathlon | 38.0 | 23.8 | 35.2 | 27.8 | 43.5 | 36.4 | 46.3 |
| Vending Bench 2 | $4,432.12 | $2,376.82 | $1,034.00 | $1,198.46 | $4,967.06 | $5,478.16 | $3,591.33 |
*: 전체 세트(full set) 점수를 의미합니다.
†: 일부 모호한 지시를 수정한 Terminal-Bench 2.0의 검증 버전입니다.
자세한 평가 정보는 각주(footnote)를 참고하세요.
파운데이션 모델은 ‘채팅(chat)’에서 ‘업무(work)’로 이동하고 있습니다. 이는 지식 노동자를 위한 오피스 도구, 엔지니어를 위한 프로그래밍 도구가 발전해 온 방식과 유사합니다.
GLM-4.5는 추론, 코딩, 에이전트를 위한 우리의 첫 단계로, 모델이 복잡한 작업을 완료할 수 있게 합니다. GLM-5에서는 복잡한 시스템 엔지니어링과 장기 에이전트 역량을 더 강화했습니다. GLM-5는 텍스트나 소스 자료를 .docx, .pdf, .xlsx 파일로 직접 변환할 수 있습니다. PRD, 수업 계획서, 시험지, 스프레드시트, 재무 보고서, 런시트(run sheet), 메뉴 등 다양한 문서를 엔드투엔드로 생성해, 즉시 사용할 수 있는 형태로 제공합니다.
공식 애플리케이션 Z.ai는 PDF / Word / Excel 생성 기능이 내장된 스킬을 갖춘 Agent 모드를 순차적으로 제공하고 있으며, 다중 턴 협업을 지원하고 출력물을 실제 납품물(deliverable)로 전환합니다.
GLM-5가 생성한 문서(.docx)
선호하는 코딩 에이전트에서 GLM-5를 사용해 보세요—Claude Code, OpenCode, Kilo Code, Roo Code, Cline, Droid 등. https://docs.z.ai/devpack/overview
GLM Coding Plan 구독자 안내: 컴퓨트 용량이 제한되어 있어, GLM-5는 Coding Plan 사용자에게 점진적으로 롤아웃하고 있습니다.
"GLM-5"로 업데이트하면 지금 바로 활성화할 수 있습니다(예: Claude Code의 ~/.claude/settings.json).GUI를 선호하시나요? 여러 에이전트를(원격으로도) 제어하고, 복잡한 작업에서 협업하도록 할 수 있는 에이전틱 개발 환경 Z Code를 제공합니다.
지금 시작하기: https://z.ai/subscribe
코딩 에이전트를 넘어, GLM-5는 OpenClaw도 지원합니다. OpenClaw는 GLM-5를 단순한 채팅을 넘어 앱과 디바이스 전반을 조작할 수 있는 개인 비서로 바꾸는 프레임워크입니다.
OpenClaw는 GLM Coding Plan에 포함되어 있습니다. 가이드를 참고하세요.
GLM-5는 Z.ai를 통해 사용할 수 있습니다. 시스템이 자동으로 변경하지 않는 경우, 모델 옵션을 수동으로 GLM-5로 바꾸세요. GLM-5에 대해 Chat 모드와 Agent 모드를 모두 제공합니다.
GLM-5 모델 가중치는 HuggingFace와 ModelScope에 공개되어 있습니다. 로컬 배포를 위해 GLM-5는 vLLM, SGLang 등 추론 프레임워크를 지원합니다. 종합적인 배포 안내는 공식 GitHub 저장소에서 확인할 수 있습니다.
또한 Huawei Ascend, Moore Threads, Cambricon, Kunlun Chip, MetaX, Enflame, Hygon 등 비(非) NVIDIA 칩에서도 GLM-5 배포를 지원합니다. 커널 최적화와 모델 양자화를 통해, 해당 칩에서도 합리적인 처리량(throughput)을 달성할 수 있습니다.
temperature=1.0, top_p=0.95, max_new_tokens=131072)으로 평가합니다. 기본적으로 텍스트 전용(text-only) 서브셋을 보고하며, * 표시는 전체 세트(full set) 결과입니다. 심사(judge) 모델로 GPT-5.2(medium)를 사용합니다. 도구 포함(HLE-with-tools) 평가에서는 최대 컨텍스트 길이 202,752 토큰을 사용합니다.temperature=0.7, top_p=0.95, max_new_tokens=16384, 컨텍스트 윈도우 200K.timeout=2h, temperature=0.7, top_p=1.0, max_new_tokens=8192, 컨텍스트 윈도우 128K로 Terminus 프레임워크에서 평가합니다. 리소스 제한은 CPU 16개, RAM 32GB로 상한을 둡니다.temperature=1.0, top_p=1.0, max_new_tokens=32000) 및 과제당 250분 타임아웃으로 평가합니다. 결과는 1,507개 과제에 대한 단일 실행(single-run) Pass@1입니다.