Firecracker 공개 이후 7년간의 여정과 AWS 내부 활용 사례를 소개합니다. Bedrock AgentCore의 세션 단위 MicroVM 격리와 Aurora DSQL의 스냅샷/클론 기반 QP 설계를 통해 성능, 보안, 자원 효율의 균형을 어떻게 달성했는지 살펴봅니다.
시간은 화살처럼 날아간다. 과일 파리는 바나나를 좋아한다.
re:Invent 2018에서 우리는 Firecracker를 세상에 공개했다. Firecracker는 작은 가상 머신을 손쉽게 만들고 관리할 수 있게 해주는 오픈소스 소프트웨어다. 당시 우리는 Firecracker가 AWS Lambda를 뒷받침하는 핵심 기술 중 하나라고 이야기했고, 이를 통해 Lambda를 더 빠르고, 더 효율적이며, 더 안전하게 만들 수 있었다는 점을 설명했다.
몇 년 뒤 우리는 NSDI’20에서 Firecracker: Lightweight Virtualization for Serverless Applications 논문을 공개했다. 당시 내가 그 논문을 설명한 내용은 여기:
그 논문은 Lambda에서 Firecracker를 어떻게 사용하는지, 멀티테넌시의 경제학에 대한 우리의 생각(여기에서도 더 다룸), 그리고 Lambda에 대해 커널 수준 격리(컨테이너)나 언어 수준 격리가 아닌 가상화를 선택한 이유를 더 자세히 다뤘다.
이러한 과제에도 불구하고, 가상화는 많은 설득력 있는 이점을 제공한다. 격리 관점에서 가장 설득력 있는 이점은 보안상 중요한 인터페이스를 OS 경계에서 하드웨어와 상대적으로 단순한 소프트웨어가 지원하는 경계로 옮긴다는 점이다. 이는 커널 기능과 보안 사이에서 타협할 필요를 없애준다. 게스트 커널은 위협 모델을 변경하지 않고도 전체 기능을 제공할 수 있다. VMM은 범용 OS 커널보다 훨씬 작아서, 소프트웨어 호환성을 훼손하거나 소프트웨어 수정을 요구하지 않으면서 소수의 잘 이해된 추상화만을 노출한다.
Firecracker는 우리가 바라던 세 가지 방식 모두에서 정말 크게 성장했다. 첫째, AWS 내부의 더 많은 영역에서 사용되어 여러 서비스의 고객 인프라를 뒷받침한다. 둘째, 많은 분들이 오픈소스 버전을 직접 활용해 멋진 제품과 비즈니스를 만들고 있다. 셋째, VM 분야의 혁신을 촉발했다.
이 글에서는 논문에 담기지 않았던, AWS에서 Firecracker를 사용하는 두 가지 방식을 조금 소개하려 한다.
Bedrock AgentCore
지난 7월, 우리는 Amazon Bedrock AgentCore 프리뷰를 발표했다. AgentCore는 AI 에이전트를 실행하기 위해 설계되었다. 요즘 AI 세계에 깊게 발을 담그지 않았다면 ‘에이전트’라는 단어가 여러 정의로 쓰여 혼란스러울 수 있다. 나는 Simon Willison의 정의가 마음에 든다:
LLM 에이전트는 목표를 달성하기 위해 도구를 루프 안에서 실행한다.1
오늘날 프로덕션 에이전트 대부분은 프로그램(대개 Python)이며, 도구와 기반 AI 모델과 쉽게 상호작용할 수 있게 해주는 프레임워크를 사용한다. 내가 가장 좋아하는 프레임워크는 Strands로, 전통적인 명령형 코드와 프롬프트 기반의 모델 상호작용을 훌륭하게 결합한다. 나는 Strands로 작은 에이전트를 많이 만드는데, 대부분 30줄 미만의 Python 코드다(아이디어가 필요하다면 strands samples를 참고해 보라).
그렇다면 여기서 Firecracker는 어디에 쓰일까?
AgentCore Runtime은 AgentCore의 컴퓨트 구성 요소다. 여러분이 작성한 에이전트 코드가 클라우드에서 실제로 실행되는 장소다. 에이전트 격리 문제를 검토해 보니, Lambda의 함수 단위 모델은 에이전트에 충분히 풍부하지 않다는 걸 깨달았다. 특히 에이전트는 서로 다른 고객을 대신해 매우 다양한 종류의 작업을 수행하기 때문이다. 그래서 우리는 AgentCore Runtime을 세션 격리를 중심으로 설계했다.
각 에이전트 세션은 고유한 MicroVM을 부여받고, 세션이 끝나면 그 MicroVM은 종료된다. 세션(최대 8시간) 동안 사용자와 여러 번 상호작용하고, 수많은 도구와 LLM 호출이 일어날 수 있다. 하지만 끝나면 MicroVM이 파기되고 세션 컨텍스트는 안전하게 잊힌다. 이는 에이전트 세션 간 상호작용을(예: AgentCore Memory나 상태 저장 도구를 통해) 명시적으로 만들고, 코드 수준에서는 상호작용이 없게 하여 보안을 더 쉽게 사고할 수 있게 한다.
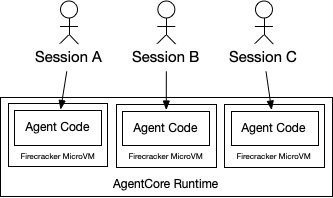
여기에서 Firecracker는 특히 유용하다. 에이전트 세션은 밀리초(작은 모델로의 단일 턴, 단일 샷 상호작용)부터 수시간(수천 번의 도구 호출과 LLM 상호작용이 있는 다중 턴 상호작용)에 이르기까지 매우 다양하다. 컨텍스트 크기도 0에서 기가바이트까지 달라진다. Firecracker의 유연성, 특히 VM의 CPU와 메모리 사용량을 실행 중에 늘리고 줄일 수 있는 능력은 이를 경제적으로 구현하는 데 핵심이었다.
Aurora DSQL
우리는 PostgreSQL 호환 서버리스 관계형 데이터베이스인 Aurora DSQL을 2014년 12월에 발표했다. 이전에 DSQL의 아키텍처에 대해 썼지만, 여기서는 Firecracker의 역할을 강조하고자 한다.
DSQL에서 활성 SQL 트랜잭션은 각자 고유한 Query Processor(QP) 안에서 실행되며, 각 QP는 PostgreSQL의 자체 사본을 포함한다. 이 QP들은(동일한 DSQL 데이터베이스에 대해) 여러 번 재사용되지만, 한 번에 하나의 트랜잭션만 처리한다.

데이터베이스 관점에서 왜 이것이 흥미로운지에 대해선 전에 쓴 글을 참고하자. 대신 페이지 수준까지 내려가 가상화 관점에서 살펴보자.
새로 들어오는 데이터베이스 연결을 위해 새로운 Firecracker 위에 새로운 DSQL QP를 만든다고 하자. 한 가지 방법은 Firecracker를 시작하고, Linux를 부팅하고, PostgreSQL을 시작하고, 관리 및 가시성 에이전트를 시작하고, 모든 메타데이터를 적재한 뒤 실행하는 것이다. 이건 그렇게 오래 걸리지는 않는다. 아마 몇백 밀리초 정도일 것이다. 하지만 우리는 훨씬 더 잘할 수 있다. 바로 ‘클론’이다. Firecracker는 스냅샷과 복원을 지원한다. VM의 메모리, 레지스터, 디바이스 상태를 파일로 기록해 두었다가 그 파일로 새 VM을 만들 수 있다. 클론이란 스냅샷을 한 번 만들면 원하는 만큼 복원해 쓸 수 있다는 단순한 아이디어다.
그래서 우리는 부팅하고, 데이터베이스를 시작하고, 약간의 커스터마이즈를 한 다음 스냅샷을 찍는다. 특정 데이터베이스에 새 QP가 필요할 때마다 그 스냅샷을 복원한다. 속도는 차원이 다르다.
이는 생성 시간을 크게 줄여, 부팅과 시작에 쓰일 CPU를 절약해 준다. 훌륭하다. 하지만 또 다른 이점이 있다. 클론된 MicroVM들이 변경되지 않은(클린) 메모리 페이지를 서로 공유할 수 있어 메모리 수요를 크게 줄일 수 있다는 점이다(무엇을 공유할지 세밀하게 제어할 수 있다).
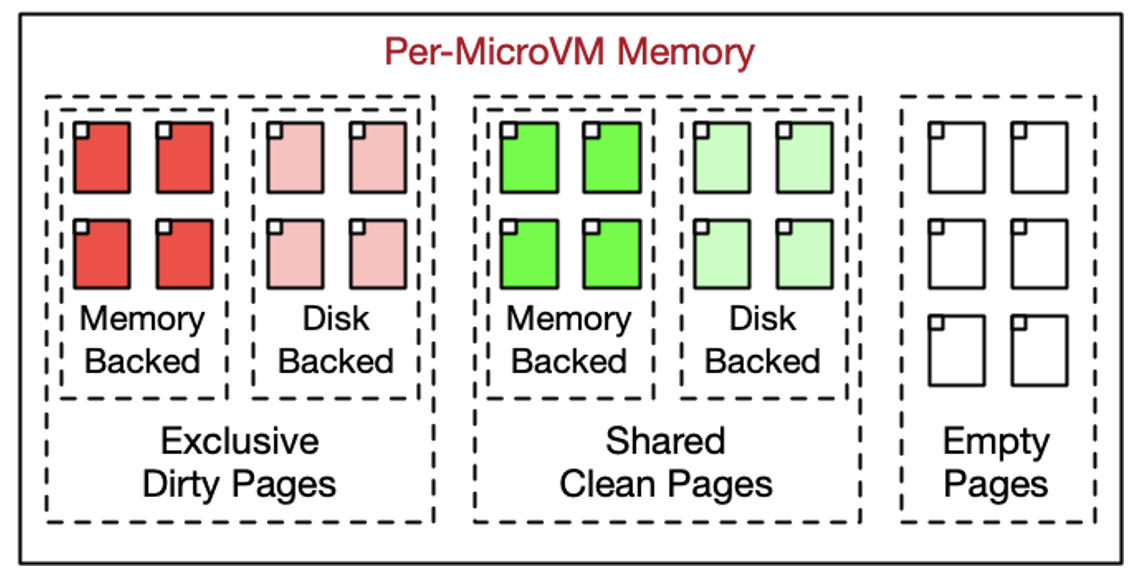
이는 큰 절감 효과를 낸다. Linux, PostgreSQL, 그리고 그 밖의 프로세스가 사용하는 메모리의 상당 부분은 시작 후 더 이상 수정되지 않기 때문이다. VM이 기록하는 페이지는 각자 고유한 사본을 갖는다(여기서 쓰기 가능한 메모리를 공유한다는 얘기는 아니다). 따라서 각 MicroVM 간 메모리는 여전히 강하게 격리된다. 또 다른 파급 효과로, 공유 페이지는 CPU 캐시 계층의 일부 수준에서 한 번만 존재해 성능을 더욱 높일 수 있다.
클론된 VM에서 난수 같은 것이 올바르게 동작하도록 하려면 약간의 추가 작업이 필요하다2.
작년에 나는 우리의 논문 Resource management in Aurora Serverless에 대해 글을 썼다. 이 시스템들을 더 깊이 이해하기 위해, 공통된 하나의 도전 과제—Linux의 메모리 관리 방식—에 대한 접근을 비교해 보자.
큰 그림에서, 기본 Linux의 관점에서는 빈 메모리 페이지는 낭비된 메모리 페이지다. 그래서 가능한 모든 기회를 잡아 사용 가능한 물리 메모리를 캐시, 버퍼, 페이지 캐시, 그리고 나중에 필요할 수도 있다고 생각하는 것들로 가득 채우려 한다.

이것은 일반적으로 훌륭한 아이디어다. 하지만 게스트 VM이 페이지를 붙들고 있을 때의 한계 비용이 0이 아닌 DSQL과 Aurora Serverless에서는, 시스템 전체 관점에서 옳지 않다. Aurora Serverless 논문에서 설명했듯, Aurora Serverless는 페이지 접근 빈도를 면밀히 추적해 이를 해결한다:
− Cold page identification: DARC [8]라는 커널 프로세스가 페이지를 지속적으로 모니터링하여 콜드 페이지를 식별한다. 콜드한 파일 기반 페이지는 free로 표시하고, 콜드한 anonymous 페이지는 스왑아웃한다.
이 방식은 잘 작동하지만, DSQL에 필요한 것보다는 무겁다. DSQL에서는 훨씬 단순한 접근을 택한다. 우리는 일정 시간이 지나면 VM을 종료한다. 그러면 추가 회계나 추적 없이 쌓인 찌꺼기가 자연스럽게 정리된다. DSQL이 이렇게 할 수 있는 이유는 연결 처리, 캐싱, 동시성 제어가 QP VM 바깥에서 처리되기 때문이다.
여러 면에서 이는 DSQL의 MVCC 가비지 컬렉션에 취한 접근과 비슷하다. 실행 중인 트랜잭션 집합에서 오래된 버전에 대한 참조를 꼼꼼히 추적해야 하는 PostgreSQL의 VACUUM 대신, 우리는 간단한 규칙(어떤 트랜잭션도 5분을 넘겨 실행될 수 없다)으로 실행 중인 트랜잭션 집합을 경계 지었다. 덕분에 DSQL은 그 기한보다 오래된 버전을 더 이상 참조되지 않는다는 확신 하에 간단히 버릴 수 있다. 늘 그렇듯, 단순함은 시스템의 속성이다.
각주