1997년 윈도우 매니저 Enlightenment E16에서 2006년부터 잠복해 있던 희귀한 멈춤 버그를 추적하고, Newton 방식 탐색의 진동 문제를 분석해 안전한 수정으로 해결한 과정을 다룹니다.
2026-04-15 :: Kamila Szewczyk
이 블로그의 편집장은 2004년에 태어났다. 그녀는 1997년의 윈도우 매니저인 _Enlightenment E16_을 매일 사용한다. 이 글에서는 코드베이스에 2006년부터 존재해 온, 작업을 완전히 멈추게 만드는 희귀한 버그를 고치는 과정을 설명한다. 놀랍게도 이 문제의 뿌리에는 Newton 알고리즘의 잘못된 구현이 있었다.
이상하게 느끼는 사람도 있겠지만, 나는 실제로 윈도우 매니저로 Enlightenment E16을 사용하는 것을 무척 좋아한다. 테마 적용이 가능하고, 손보기 쉽고, 가볍고(최대 RSS 24MB!), 나처럼 키보드를 많이 쓰는 사용자에게 잘 맞으며, 무엇보다도 정말 아름답다:
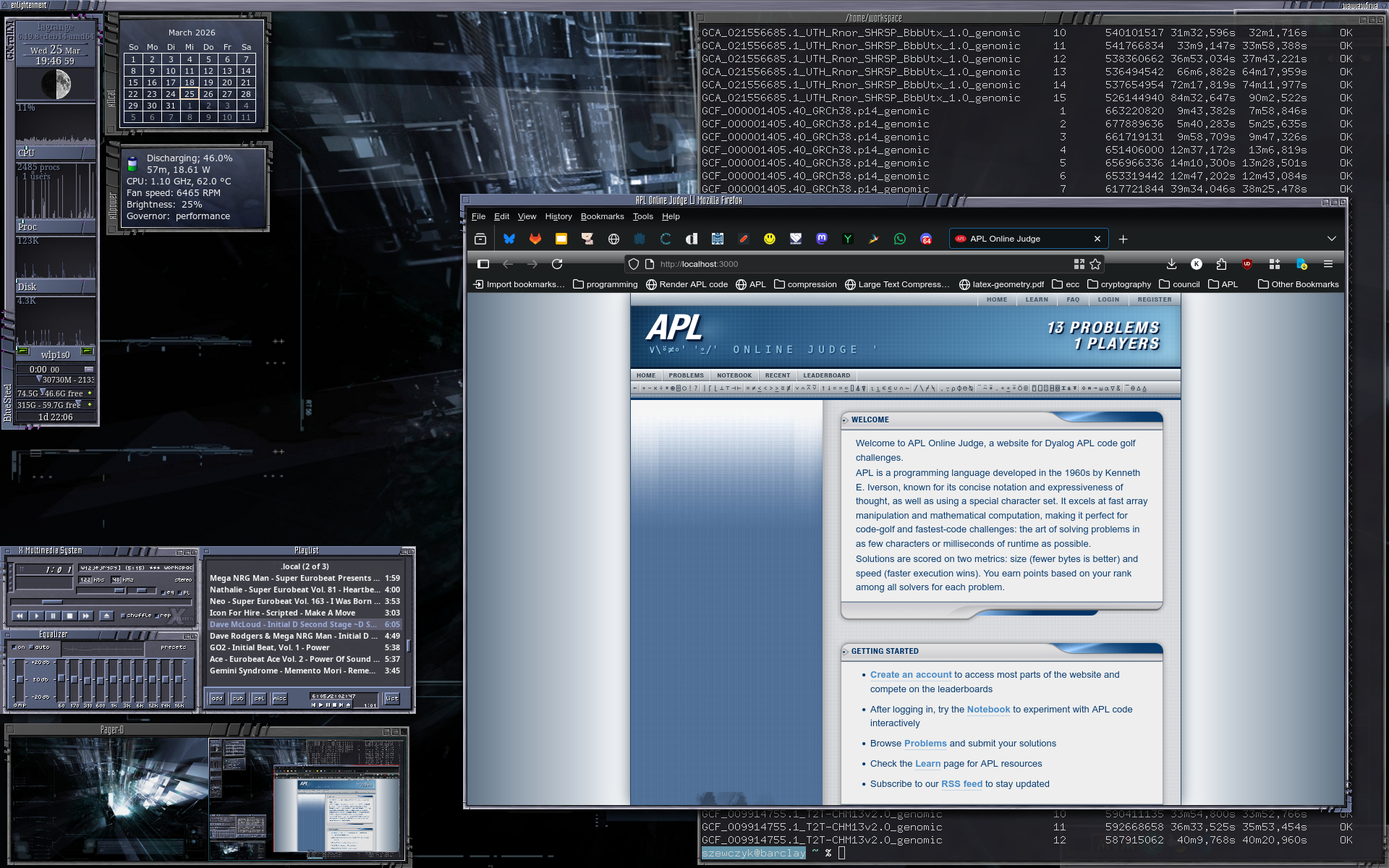
E16은 1997년에 Carsten Haitzler 덕분에 처음 등장했고, 그 이후로 계속 개발되어 왔다. 대부분은 E17과 그 밖의 더 새로운 버전으로 옮겨 갔지만, 소수의 열성 사용자 공동체는 아직도 E16을 사용하고 있고, 나도 그중 한 사람이다. 코드베이스는 꽤 오래되었고, 세월이 흐르며 기술 부채도 많이 쌓였다.
버그는 늘 가장 정신없는 순간에 튀어나오는데, 이 버그도 절호의 기회를 감지했던 것 같다. 나는 곧 맡게 될 강의를 위해 슬라이드 몇 장을 마감 직전에 손보고 있었다. LaTeX로 조판한 강의 슬라이드 PDF 몇 개와 연습문제지가 있었는데, 어느 시점에 그중 하나를 Atril에서 여는 순간 데스크톱 전체가 멈췄다.
나는 TTY에서 X11 세션을 죽였다. 안타깝게도 멈춤은 결정적이었다. 그 특정 PDF를 열 때마다 항상 같은 일이 일어났다.
실행 중인 프로세스에 gdb를 붙여 보니, 모든 샘플이 imlib2의 폰트 캐시에 머물러 있었고, 호출자는 같은 e16 쪽 프레임이었다:
#0 __strcmp_evex ()
#1 __imlib_hash_find (hash=0x55bc9c111420, key="\001\001\001\001\001") object.c:172
#2 __imlib_font_cache_glyph_get (fn=..., index=0) font_draw.c:30
#3 __imlib_font_get_next_glyph (... utf8="Kickoff.pdf — Introduction...") font_main.c:218
#4 __imlib_font_query_advance (...) font_query.c:89
#5 imlib_get_text_advance (...) api_text.c:231
#6 Efont_extents (...) text_ift.c:87
#7 _ift_TextSize (...) text_ift.c:156
#8 TextstateTextFitMB (ts=..., textwidth_limit=291) text.c:350
#9 TextstateTextFit (...) text.c:559
#10 TextstateTextDraw (... text="Kickoff.pdf — Introduction...") text.c:638
#11 ITApply (...) iclass.c:930
#12 ITApply (...) iclass.c:884
#13 _BorderWinpartITclassApply (ewin=..., i=2, force=1) borders.c:179
#14 EwinBorderUpdateInfo (ewin=...) borders.c:300
#15 EwinChangesProcess (...) ewins.c:2141
#16 EwinEventPropertyNotify (ewin=..., ev=...) ewins.c:1438
...
#21 main (...) main.c:320
```
반복해서 다시 붙여 보니 프로그램이 _데드락_ 상태인 것은 아니었다. `__imlib_font_cache_glyph_get`는 매번 다른 글리프 인덱스(0, 20, 73, 81, 82, 87, 88, …)로 호출되고 있었다. 즉, 내부의 폰트 측정 루프는 진행되고 있었고, 바깥 어딘가의 루프가 문제였다.
이리저리 더듬어 본 끝에, Frame 8(`text.c:350`의 `TextstateTextFitMB`)이 항상 같다는 사실을 알아냈다. 문제의 호출은 중간 생략 부호 절단 루프 안의 `ts->ops->TextSize(ts, new_line, 0, pw, &hh, &ascent);`였다. 이 루프는 문자열을 `textwidth_limit = 291` 픽셀 안에 맞추기 위해 가운데의 문자를 도려내는데, PDF 제목을 렌더링할 때 사용되었고, 그 제목이 창 제목이기도 해서 장식 영역에 들어가기엔 너무 길었다.
여러 샘플에 걸쳐 프레임의 지역 변수를 덤프해 보니 깔끔한 두 상태 진동이 드러났다:
```
nuke_count = 8 nc2 = 36 wc_len = 81 len_n = 76
nuke_count = 11 nc2 = 35 wc_len = 81 len_n = 73
nuke_count = 8 nc2 = 36 wc_len = 81 len_n = 76
...
```
나는 언제나 두 개의 시도된 절단 결과만 보았고, 똑같은 텍스트를 영원히 반복하고 있었다.
# 문제의 함수[⌗](https://iczelia.net/posts/e16-20-year-old-bug/#the-problematic-function)
가장 낮은 공통분모부터 시작하자. 아마 여기 논리 버그가 있을 것이다.
```c
static void
TextstateTextFitMB(TextState *ts, char **ptext, int *pw, int textwidth_limit)
{
char *text = *ptext;
int width, hh, ascent, cw;
char *new_line;
int nuke_count, nc2;
int len, len_mb;
wchar_t *wc_line = NULL;
int wc_len, len_n;
if (EwcOpen(ts->need_utf8 || Mode.locale.utf8_int))
return;
len = strlen(text);
wc_len = EwcStrToWcs(text, len, NULL, 0);
if (wc_len <= 1)
goto done;
wc_line = EMALLOC(wchar_t, wc_len + 1);
if (!wc_line)
goto done;
if (EwcStrToWcs(text, len, wc_line, wc_len) <= 0)
goto done;
new_line = EMALLOC(char, len + 10);
if (!new_line)
goto done;
width = *pw;
nuke_count = ((width - textwidth_limit) * wc_len) / width;
if (nuke_count < 2)
nuke_count = 2;
for (;;)
{
if (nuke_count >= wc_len - 1)
{
len_mb = EwcWcsToStr(wc_line, 1, new_line, MB_CUR_MAX);
if (len_mb < 0)
len_mb = 1;
strcpy(new_line + len_mb, "...");
break;
}
nc2 = (wc_len - nuke_count) / 2;
len_mb = EwcWcsToStr(wc_line, nc2, new_line, len + 10);
memcpy(new_line + len_mb, "...", 3);
len_mb += 3;
len_mb += EwcWcsToStr(wc_line + nc2 + nuke_count,
wc_len - nc2 - nuke_count,
new_line + len_mb, len + 10 - len_mb);
new_line[len_mb] = '\0';
len_n = wc_len - nuke_count + 3;
ts->ops->TextSize(ts, new_line, 0, pw, &hh, &ascent);
width = *pw;
nc2 = textwidth_limit - width;
cw = width / len_n;
if (nc2 >= 0 && nc2 < 3 * cw)
break;
if (nc2 > 0)
nuke_count -= (nc2 <= 2 * cw) ? 1 : (nc2 + cw / 2) / cw;
else
nuke_count += (-nc2 <= 2 * cw) ? 1 : (-nc2 + cw / 2) / cw;
}
Efree(text);
*ptext = new_line;
done:
Efree(wc_line);
EwcClose();
}
```
복사
우리에게 특히 흥미로운 부분은 이 루프다. 줄여 쓰면 다음과 같다:
```c
for (;;)
{
if (nuke_count >= wc_len - 1) { /* 퇴화한 경우: 단일 문자 + "..." */ break; }
nc2 = (wc_len - nuke_count) / 2;
/* new_line = 앞쪽 nc2개의 wchar + "..." + 뒤쪽 wchars 생성 */
len_n = wc_len - nuke_count + 3;
ts->ops->TextSize(ts, new_line, 0, pw, &hh, &ascent);
width = *pw;
nc2 = textwidth_limit - width;
cw = width / len_n;
if (nc2 >= 0 && nc2 < 3 * cw)
break; /* 맞음, 문자 3개 이내 */
if (nc2 > 0) /* 여유 공간이 있음 */
nuke_count -= (nc2 <= 2 * cw) ? 1 : (nc2 + cw / 2) / cw;
else /* 너무 넓음 */
nuke_count += (-nc2 <= 2 * cw) ? 1 : (-nc2 + cw / 2) / cw;
}
```
복사
이것은 `width`가 `textwidth_limit`에서 얼마나 벗어나는지에 따라, `cw = width / len_n`을 도함수(문자당 평균 픽셀 수)로 사용해 얼마나 더 많은 혹은 적은 wchar를 제거해야 하는지 추정하는 Newton 방식 탐색이다. 이런 영리하고 솜씨 좋은 해법을 보는 것은 즐겁다. 하지만 Newton 방법을 직접 구현해 본 사람이라면 누구나 이 코드를 보고 당장 한 가지를 외칠 것이다. _“반복 횟수 제한은 어디 있지?!”_ Newton 방법은 수렴에 실패할 수 있고, 시작점과 함수의 성질, 도함수 추정의 품질에 따라 지나치게 건너뛰며 발산할 수도 있다. 이 경우에는 방법이 두 점 사이를 영원히 오가며 진동하고 있었다.
문제를 더 악화시키는 것은 종료 허용오차($$\epsilon$$ε)가 빡빡하다는 점이다. `nc2`가 `[0, 3*cw)` 안에 있을 때만 받아들인다. 이것은 왜 보통의 짧은 제목에서는 문제가 드러나지 않았는지도 설명해 준다. 더 짧은 문자열이거나 `cw`가 더 넓은 경우에는 `<= 2*cw` 분기가 작동하여 스텝이 1이 되므로 수렴한다.
# 수정[⌗](https://iczelia.net/posts/e16-20-year-old-bug/#the-fix)
나는 멀티바이트 루프와 ASCII 루프 양쪽에 대칭적으로 적용되는 세 가지 방어적 변경을 했다:
* 반복 횟수에 32의 상한을 두었다. 상한을 넘긴 뒤에는 현재 시도가 들어맞기만 하면 `nc2 >= 0` 그대로 받아들이고, 그렇지 않으면 `nuke_count`를 1 늘린 뒤 다시 시도한다. 이렇게 하면 제한된 시간 안에 반드시 종료되며, Newton 스텝이 진동한다는 것이 드러난 뒤에는 처음으로 들어맞는 시도를 선택하게 된다.
* 이제 루프 내부에서 `nuke_count`의 바닥값을 1로 둔다. 그래서 음수 보정 때문에 꼬리가 머리와 겹치는 퇴화한 문자열이 만들어질 수 없다.
* `cw` 역시 최소 1로 고정한다. 따라서 병적으로 폭이 0으로 측정되는 경우에도 스텝 계산식이 0으로 나누기로 바뀌지 않는다.
# 패치 (e16 1.0.30 기준)[⌗](https://iczelia.net/posts/e16-20-year-old-bug/#patch-against-e16-1030)
```diff
--- a/src/text.c
+++ b/src/text.c
@@ -255,7 +255,7 @@ TextstateTextFit1(TextState *ts, char **ptext, int *pw, int textwidth_limit)
if (nuke_count < 2)
nuke_count = 2;
- for (;;)
+ for (int iter = 0;; iter++)
{
if (nuke_count >= len - 1)
{
@@ -263,6 +263,8 @@ TextstateTextFit1(TextState *ts, char **ptext, int *pw, int textwidth_limit)
memcpy(new_line + 1, "...", 4);
break;
}
+ if (nuke_count < 1)
+ nuke_count = 1;
nc2 = (len - nuke_count) / 2;
@@ -276,9 +278,18 @@ TextstateTextFit1(TextState *ts, char **ptext, int *pw, int textwidth_limit)
width = *pw;
nc2 = textwidth_limit - width;
cw = width / len_n;
+ if (cw < 1)
+ cw = 1;
if (nc2 >= 0 && nc2 < 3 * cw)
break;
+ if (iter >= 32)
+ {
+ if (nc2 >= 0)
+ break;
+ nuke_count++;
+ continue;
+ }
if (nc2 > 0)
nuke_count -= (nc2 <= 2 * cw) ? 1 : (nc2 + cw / 2) / cw;
else
@@ -335,7 +346,7 @@ TextstateTextFitMB(TextState *ts, char **ptext, int *pw, int textwidth_limit)
if (nuke_count < 2)
nuke_count = 2;
- for (;;)
+ for (int iter = 0;; iter++)
{
if (nuke_count >= wc_len - 1)
{
@@ -346,6 +357,8 @@ TextstateTextFitMB(TextState *ts, char **ptext, int *pw, int textwidth_limit)
strcpy(new_line + len_mb, "...");
break;
}
+ if (nuke_count < 1)
+ nuke_count = 1;
nc2 = (wc_len - nuke_count) / 2;
@@ -362,9 +375,18 @@ TextstateTextFitMB(TextState *ts, char **ptext, int *pw, int textwidth_limit)
width = *pw;
nc2 = textwidth_limit - width;
cw = width / len_n;
+ if (cw < 1)
+ cw = 1;
if (nc2 >= 0 && nc2 < 3 * cw)
break;
+ if (iter >= 32)
+ {
+ if (nc2 >= 0)
+ break;
+ nuke_count++;
+ continue;
+ }
if (nc2 > 0)
nuke_count -= (nc2 <= 2 * cw) ? 1 : (nc2 + cw / 2) / cw;
else
```
복사
# 재현기[⌗](https://iczelia.net/posts/e16-20-year-old-bug/#reproducer)
WM_NAME이 충분히 길어서 중간 생략 부호 탐색이 과도한 건너뛰기 구간에 빠지는 모든 창에서 이 문제가 재현된다. 실제 사례는 다음과 같다:
```
Kickoff.pdf — Introduction to Information Theory Session 1: kickoff & first topic
```
(emdash를 포함해 폭 기준 81개의 문자, 약 291px의 테두리 제목 슬롯, 폰트는 문자당 평균 대략 3px.)
# 아무도 바라지 않았던 철학적 우회.[⌗](https://iczelia.net/posts/e16-20-year-old-bug/#a-philosophical-detour-that-nobody-asked-for)
더 새롭다고 해서 반드시 더 좋은 것은 아니다. 최신 소프트웨어는 새로운 버그도 함께 가져오고, 이제는 Large Language Models 덕분에 기여 장벽이 훨씬 낮아져 유지관리자와 사용자가 함께 그 버그를 즐기게 된다. 하지만 안정 브랜치 유지관리자들도 때로는 터무니없이 멍청한 짓을 한다:
[2026년 4월 3일, 나는](https://bsky.app/profile/did:plc:7k6gfbymauh2zke3n6y6cmxh/post/3mimhdzuzrc23) `fgetxattr(54321, NULL, NULL, 0);`가 어제의 6.6.y lts 커널을 겉보기에는 충돌시킨다고 언급했다. 경로가 잘못되었으니 그 호출은 그냥 `-1`을 반환하고 `errno`를 `EINVAL`로 설정해야 한다. 그런데 안정 브랜치 유지관리자가 그것을 [통째로 패치해 제거해 버렸다](https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/commit/?h=linux-6.6.y&id=5a1e865e51063d6c56f673ec8ad4b6604321b455).
그 뒤 그 끔찍한 커밋은 4월 8일에 [되돌려졌다](https://cdn.kernel.org/pub/linux/kernel/v6.x/ChangeLog-6.6.133). 명백한 서비스 거부 공격 벡터가 도입되었음에도 CVE는 아직 배정되지 않았다.
이런 일이 매일 실수로 벌어진다면[1](https://iczelia.net/posts/e16-20-year-old-bug/#fn:1), 공급망이 손상되어 악의적인 행위자가 의도적으로 버그를 집어넣을 때는 무슨 일이 벌어질까? 생각만 해도 아찔하다. [XZ backdoor](https://en.wikipedia.org/wiki/XZ_Utils_backdoor)가 들어갔을 때, 나는 Debian Sid 노트북으로 뉴스를 넘겨 보고 있었고 백그라운드에서는 코드가 컴파일되고 있었다. XZ Utils에 백도어가 있으며, 아마 국가 행위자가 버전 v5.6.0에 도입한 것 같다는 소식을 접했다. 나는 실제로 최전선 배포판을 쓰고 자주 업데이트하니, 곧바로 `apt list --upgradable | grep xz-utils`를 실행했다. 예상대로, 코로 뿜어낸 커피[2](https://iczelia.net/posts/e16-20-year-old-bug/#fn:2)로 노트북에 남은 얼룩은 꽤 처리하기 힘들었다.
반면, 유능한 개발자가 유지하는 낡고 오래된 소프트웨어의 개인 체크아웃에 존재하는 버그 수는 단조롭게 줄어들 것이다. 내가 기능이 필요하면 직접 구현하면 된다. 문제가 있다면 나 자신만 탓하면 된다. 손상될 공급망도 없고, 집요하고 표적화된 국가 행위자가 내 시스템에서 `sudo` 권한을 원한다면 결국 무슨 수를 써서든 얻어낼 것이다. 아, 그리고 내가 전에 쓰던 WM인 XFWM 업데이트가 가져올 기능들도 아마 딱히 쓰지 않았을 것이다.
* * *
1. Der Notfall ist der Normalfall.[↩︎](https://iczelia.net/posts/e16-20-year-old-bug/#fnref:1)
2. 오전 5시 30분은 내 문장가 기질이 가장 빛나는 시간이 아니다.[↩︎](https://iczelia.net/posts/e16-20-year-old-bug/#fnref:2)
© 2019 - 2025 by Kamila Szewczyk:: [Theme](https://github.com/panr/hugo-theme-terminal) made by [panr](https://github.com/panr)