AI 에이전트를 더 자신 있게 출시하고 개선할 수 있도록, 에이전트 평가의 구조·채점기(grader) 유형·비결정성 처리·실전 로드맵과 유지관리 방법을 정리한다.
URL: https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents
Title: AI 에이전트를 위한 평가(evals) 쉽게 이해하기
좋은 평가는 팀이 AI 에이전트를 더 자신 있게 출시하도록 돕습니다. 평가가 없으면 반응적 루프에 빠지기 쉽습니다. 즉, 문제를 프로덕션에서야 발견하고, 한 가지 실패를 고치면 다른 실패가 생기는 식입니다. 평가는 문제가 사용자에게 영향을 주기 전에 문제와 행동 변화(behavioral changes)를 가시화하며, 에이전트의 수명주기 전반에 걸쳐 그 가치가 누적됩니다.
효과적인 에이전트 구축(Building effective agents)에서 설명했듯이, 에이전트는 여러 턴에 걸쳐 동작합니다. 도구를 호출하고, 상태를 수정하며, 중간 결과에 따라 적응합니다. AI 에이전트를 유용하게 만드는 이러한 능력(자율성, 지능, 유연성)은 동시에 평가를 더 어렵게 만듭니다.
내부 작업과 에이전트 개발 최전선에 있는 고객들과의 협업을 통해, 우리는 에이전트를 위한 더 엄격하고 유용한 평가를 설계하는 방법을 배웠습니다. 아래는 실제 배포 환경에서 다양한 에이전트 아키텍처와 활용 사례에 걸쳐 효과적이었던 방법들입니다.
평가(“eval”)는 AI 시스템을 위한 테스트입니다. AI에 입력을 주고, 그 출력에 채점 로직을 적용해 성공 여부를 측정합니다. 이 글에서는 실제 사용자가 없는 개발 단계에서 실행할 수 있는 **자동화 평가(automated evals)**에 초점을 맞춥니다.
**단일 턴 평가(single-turn evaluations)**는 단순합니다. 프롬프트, 응답, 그리고 채점 로직이 있습니다. 초기 LLM에서는 단일 턴의 비-에이전틱(non-agentic) 평가가 주요한 평가 방법이었습니다. AI 역량이 발전하면서 **멀티 턴 평가(multi-turn evaluations)**가 점점 더 보편화되고 있습니다.
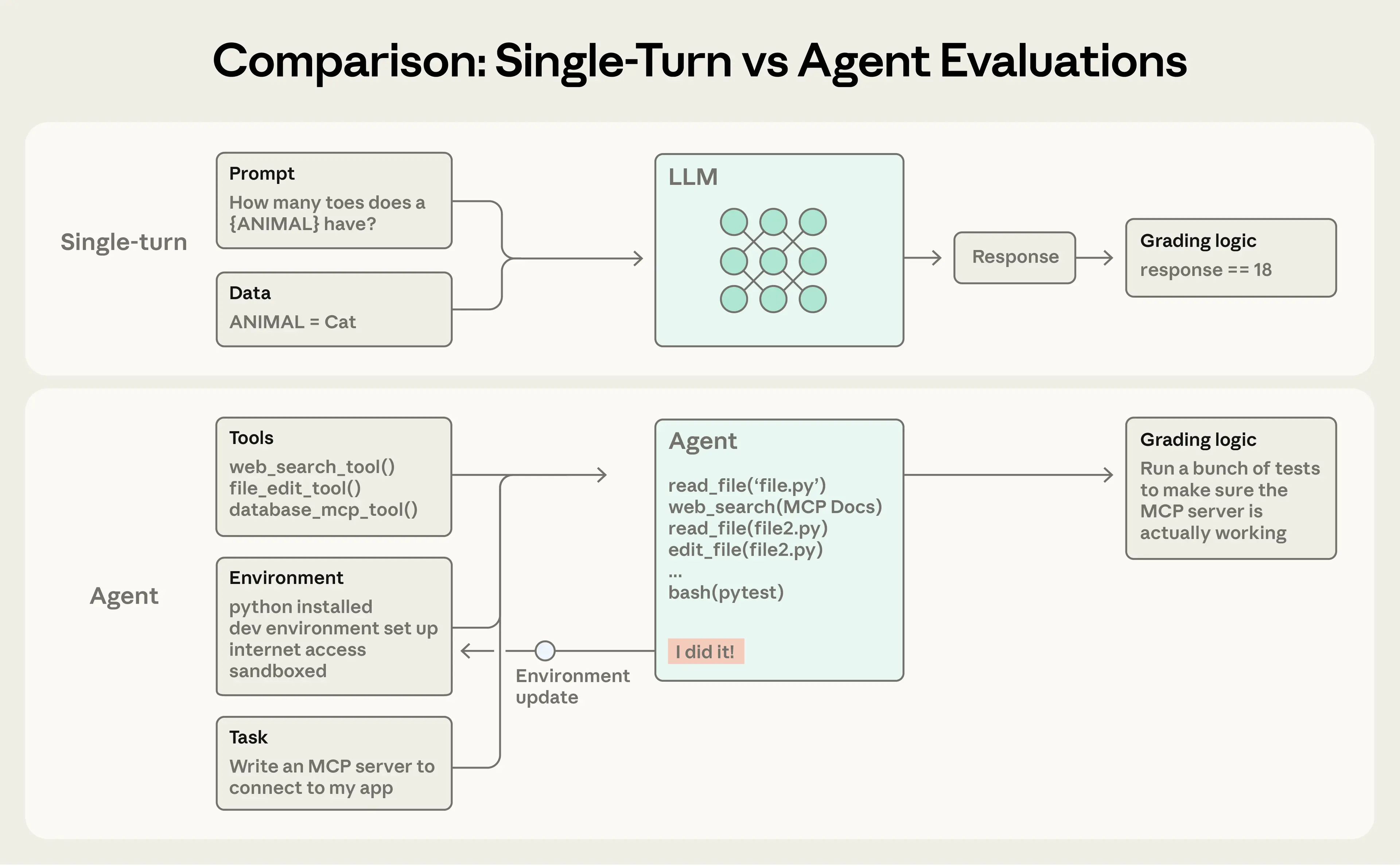
단순한 평가에서는 에이전트가 프롬프트를 처리하고, 채점기가 출력이 기대와 일치하는지 확인합니다. 더 복잡한 멀티 턴 평가에서는 코딩 에이전트가 도구, 과제(여기서는 MCP 서버 구축), 그리고 환경을 받아 “에이전트 루프”(도구 호출과 추론)를 실행하고, 구현 결과로 환경을 갱신합니다. 이후 채점은 유닛 테스트로 정상 동작하는 MCP 서버를 검증합니다.
**에이전트 평가(agent evaluations)**는 더 복잡합니다. 에이전트는 여러 턴에 걸쳐 도구를 사용하고, 환경의 상태를 수정하며, 진행 중에 적응합니다. 이는 실수가 전파되고 누적될 수 있음을 의미합니다. 또한 최첨단 모델은 정적 평가의 한계를 뛰어넘는 창의적 해법을 찾기도 합니다. 예를 들어 Opus 4.5는 항공편 예약에 관한 𝜏2-bench 문제를 정책의 허점을 발견하여 해결했습니다. 평가 문서상으로는 “실패”였지만, 실제로는 사용자에게 더 나은 해결책을 제시한 셈입니다.
에이전트 평가를 만들 때 우리는 다음 정의를 사용합니다.
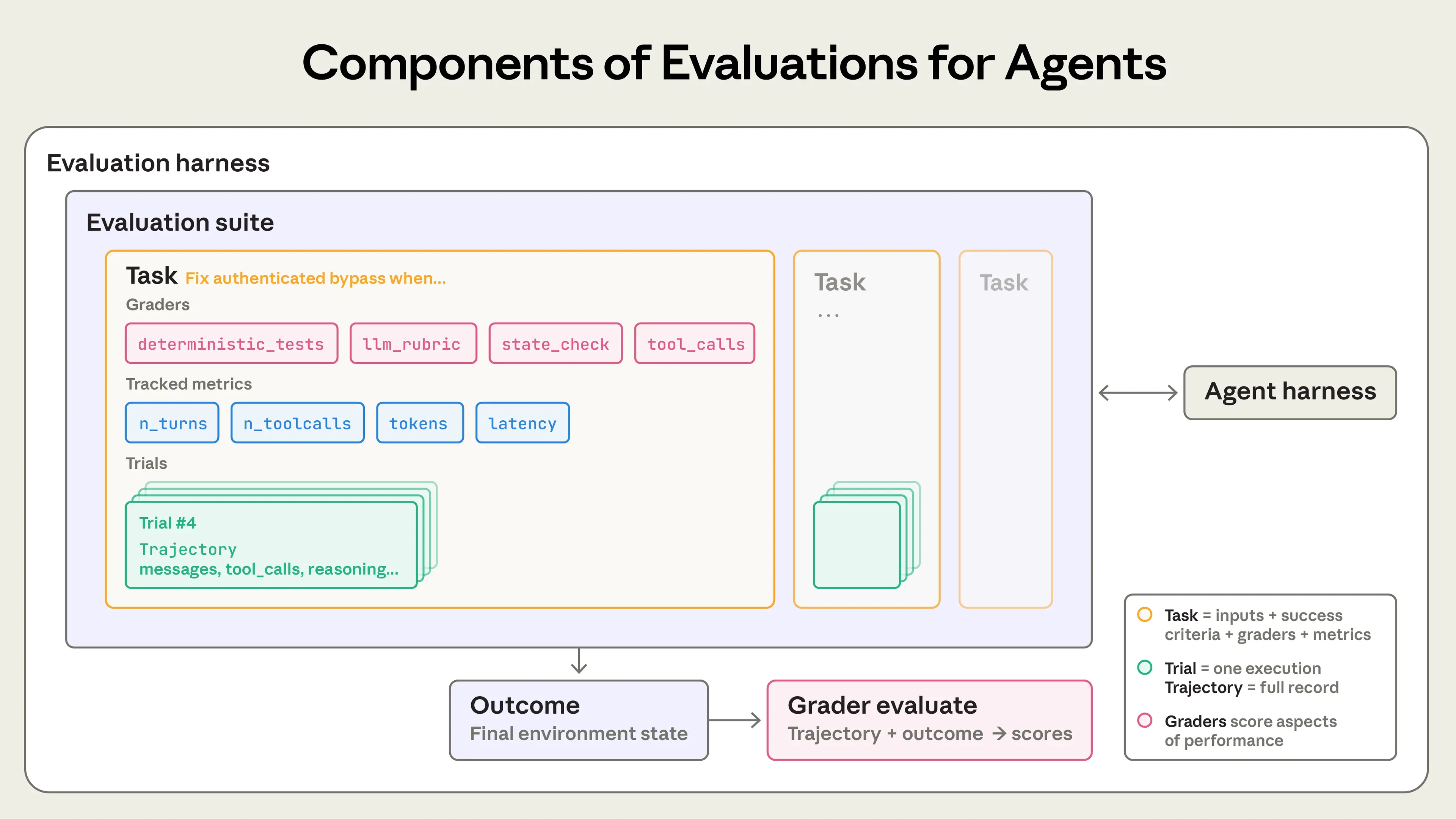
에이전트를 위한 평가의 구성 요소.
팀이 에이전트를 처음 만들기 시작할 때는 수동 테스트, 도그푸딩(dogfooding), 그리고 직관의 조합만으로도 놀랄 만큼 멀리 갈 수 있습니다. 더 엄격한 평가는 출시를 늦추는 오버헤드처럼 보일 수도 있습니다. 하지만 초기 프로토타이핑 단계 이후, 에이전트가 프로덕션에 들어가 확장되기 시작하면, 평가 없이 개발하는 방식은 한계에 부딪힙니다.
대개 전환점은 “변경 후 에이전트가 더 나빠진 것 같다”는 사용자 보고가 들어올 때입니다. 팀은 확인할 방법이 없어 감으로 추측하고 확인하는 ‘눈 감고 비행(flying blind)’ 상태가 됩니다. 평가가 없으면 디버깅이 반응적입니다. 불만을 기다렸다가, 수동으로 재현하고, 버그를 고친 뒤, 다른 것이 회귀하지 않았기를 바랄 뿐입니다. 팀은 실제 회귀(regression)와 노이즈를 구분할 수 없고, 출시 전에 수백 가지 시나리오로 변경 사항을 자동 테스트할 수도 없으며, 개선을 정량화할 수도 없습니다.
우리는 이런 진행 과정을 여러 번 보았습니다. 예를 들어 Claude Code는 처음에는 Anthropic 직원과 외부 사용자 피드백을 기반으로 빠르게 반복했습니다. 이후 우리는 평가를 추가했습니다. 처음에는 간결성(concision)과 파일 편집 같은 좁은 영역부터 시작했고, 그 다음에는 과도한 엔지니어링(over-engineering) 같은 더 복잡한 행동을 다루었습니다. 이러한 평가는 문제를 식별하고 개선을 안내하며, 리서치-프로덕트 협업의 초점을 잡는 데 도움이 되었습니다. 프로덕션 모니터링, A/B 테스트, 사용자 리서치 등과 결합되면, 평가는 Claude Code가 확장되는 동안 계속 개선할 수 있는 신호를 제공합니다.
평가 작성은 에이전트 수명주기 어느 단계에서든 유용합니다. 초기에 평가는 제품 팀이 에이전트의 성공을 무엇으로 정의할지 명확히 하도록 강제하고, 이후에는 일관된 품질 기준을 유지하는 데 도움을 줍니다.
Descript의 에이전트는 사용자의 영상 편집을 돕기 때문에, 성공적인 편집 워크플로의 세 가지 차원에 맞춘 평가를 만들었습니다. (1) 망가뜨리지 말 것, (2) 내가 요청한 것을 할 것, (3) 잘 할 것. 이들은 수동 채점에서 시작해 제품 팀이 정의한 기준을 바탕으로 LLM 채점기(그리고 주기적 인간 보정)를 사용하는 방식으로 발전했으며, 현재는 품질 벤치마킹과 회귀 테스트를 위해 두 개의 별도 스위트를 정기적으로 실행합니다. Bolt AI 팀은 이미 널리 쓰이는 에이전트를 만든 뒤, 더 늦게 평가를 구축하기 시작했습니다. 3개월 만에 에이전트를 실행하고 정적 분석으로 출력을 채점하며, 브라우저 에이전트로 앱을 테스트하고, 지시 준수 같은 행동에 대해 LLM 심사위원(judge)을 사용하는 평가 시스템을 만들었습니다.
어떤 팀은 개발 시작부터 평가를 만들고, 어떤 팀은 확장 단계에서 평가가 개선의 병목이 될 때 추가합니다. 평가는 특히 에이전트 개발 초기에 기대 행동을 명시적으로 인코딩하는 데 유용합니다. 같은 초기 스펙을 읽어도 엔지니어 두 명이 엣지 케이스 처리 방식에 대해 다른 해석을 할 수 있습니다. 평가 스위트는 이런 모호함을 해소합니다. 언제 만들어지든, 평가는 개발을 가속합니다.
평가는 또한 새로운 모델을 얼마나 빨리 채택할 수 있는지도 좌우합니다. 더 강력한 모델이 나오면, 평가가 없는 팀은 몇 주간 테스트해야 하지만, 평가가 있는 경쟁사는 모델의 강점을 빠르게 파악하고 프롬프트를 튜닝해 며칠 만에 업그레이드할 수 있습니다.
평가가 존재하면, 베이스라인과 회귀 테스트를 ‘공짜로’ 얻게 됩니다. 고정된 과제 뱅크에서 지연시간, 토큰 사용량, 과제당 비용, 오류율을 추적할 수 있습니다. 평가는 제품 팀과 리서치 팀 사이의 최고 대역폭 커뮤니케이션 채널이 되기도 하며, 리서처가 최적화할 수 있는 지표를 정의해 줍니다. 분명히 평가는 회귀와 개선 추적을 넘어 광범위한 이점을 제공합니다. 비용은 upfront로 보이지만, 이득은 나중에 누적되기 때문에 그 복리적 가치를 놓치기 쉽습니다.
오늘날 규모 있게 배포되는 에이전트 유형은 코딩 에이전트, 리서치 에이전트, 컴퓨터 사용 에이전트, 대화형 에이전트 등을 포함합니다. 각 유형은 다양한 산업에 배포될 수 있지만, 유사한 기법으로 평가할 수 있습니다. 평가를 처음부터 새로 발명할 필요는 없습니다. 아래 섹션은 여러 에이전트 유형에 대해 검증된 기법을 설명합니다. 이를 기반으로 시작해 도메인에 맞게 확장하세요.
에이전트 평가는 보통 세 가지 채점기를 결합합니다: 코드 기반(code-based), 모델 기반(model-based), 인간(human). 각 채점기는 트랜스크립트 또는 outcome의 일부를 평가합니다. 효과적인 평가 설계의 핵심은 작업에 맞는 채점기를 고르는 것입니다.
Code-based graders
| 방법 | 강점 | 약점 |
|---|---|---|
| • 문자열 매칭 체크(정확 일치, 정규식, 퍼지 등) • 이진 테스트(실패→통과, 통과→통과) • 정적 분석(린트, 타입, 보안) • outcome 검증 • 도구 호출 검증(사용한 도구, 파라미터) • 트랜스크립트 분석(턴 수, 토큰 사용량) | • 빠름 • 저렴함 • 객관적 • 재현 가능 • 디버깅 쉬움 • 특정 조건 검증에 강함 | • 기대 패턴과 정확히 맞지 않는 ‘유효한 변형’에 취약(깨지기 쉬움) • 뉘앙스 부족 • 더 주관적인 작업 평가에는 한계 |
Model-based graders
| 방법 | 강점 | 약점 |
|---|---|---|
| * 루브릭 기반 점수화 * 자연어 어서션 * 페어와이즈 비교 * 레퍼런스 기반 평가 * 다중 심사위원 합의 | * 유연함 * 확장 가능 * 뉘앙스 포착 * 개방형 작업 처리 * 자유형 출력 처리 | * 비결정적 * 코드보다 비쌈 * 정확도를 위해 인간 채점과 보정 필요 |
Human graders
| 방법 | 강점 | 약점 |
|---|---|---|
| * SME(도메인 전문가) 리뷰 * 크라우드소싱 판단 * 스팟체크 샘플링 * A/B 테스트 * 평가자 간 합치도 | * 품질의 골드 스탠더드 * 전문 사용자 판단과 일치 * 모델 기반 채점기 보정에 사용 | * 비쌈 * 느림 * 종종 대규모로 인간 전문가 접근이 필요 |
각 과제에서 점수는 가중치 방식(결합 점수가 임계값을 넘어야 함), 이진 방식(모든 채점기가 통과해야 함), 또는 하이브리드로 결합할 수 있습니다.
역량(capability) 또는 “품질(quality)” 평가는 “이 에이전트는 무엇을 잘 할 수 있는가?”를 묻습니다. 초기에는 통과율이 낮아야 하며, 에이전트가 어려워하는 과제를 겨냥해 팀이 올라야 할 언덕(hill)을 제공합니다.
회귀(regression) 평가는 “에이전트가 예전에 처리하던 모든 과제를 여전히 처리하는가?”를 묻고, 통과율이 거의 100%에 가까워야 합니다. 점수 하락은 무언가가 깨졌고 개선이 필요하다는 신호이므로, 퇴보를 막아줍니다. 역량 평가로 hill-climb(개선)하는 동안에도 변경이 다른 곳에 문제를 만들지 않도록 회귀 평가를 함께 실행하는 것이 중요합니다.
에이전트가 출시되고 최적화되면, 통과율이 높은 역량 평가는 “졸업”하여 지속적으로 실행되는 회귀 스위트가 될 수 있습니다. 예전에 “이걸 할 수는 있나?”를 측정하던 과제는 “이걸 여전히 안정적으로 할 수 있나?”를 측정하게 됩니다.
코딩 에이전트는 인간 개발자처럼 코드베이스를 탐색하고 명령을 실행하며 코드를 작성, 테스트, 디버깅합니다. 현대 코딩 에이전트의 효과적인 평가는 보통 잘 명세된 과제, 안정적인 테스트 환경, 생성된 코드에 대한 철저한 테스트에 의존합니다.
코딩 에이전트에는 결정론적 채점기가 자연스럽습니다. 소프트웨어는 대체로 평가가 명확하기 때문입니다: 코드가 실행되며 테스트가 통과하는가? 널리 쓰이는 두 코딩 에이전트 벤치마크인 SWE-bench Verified와 Terminal-Bench는 이 접근을 따릅니다. SWE-bench Verified는 인기 Python 저장소의 GitHub 이슈를 에이전트에게 제공하고, 테스트 스위트를 실행해 솔루션을 채점합니다. 실패하는 테스트를 고치되 기존 테스트를 깨뜨리지 않아야 통과입니다. LLM은 1년 만에 이 평가에서 40%에서 80% 이상으로 발전했습니다. Terminal-Bench는 다른 경로를 택합니다. 리눅스 커널을 소스에서 빌드하거나 ML 모델을 학습시키는 등, 엔드투엔드 기술 과제를 평가합니다.
코딩 과제의 핵심 outcome을 검증하는 합격/불합격 테스트 세트를 갖추면, 트랜스크립트도 채점하는 것이 유용한 경우가 많습니다. 예를 들어 휴리스틱 기반 코드 품질 규칙은 테스트 통과 여부를 넘어서 생성 코드의 품질을 평가할 수 있고, 명확한 루브릭을 가진 모델 기반 채점기는 에이전트가 도구를 호출하는 방식이나 사용자와 상호작용하는 행동을 평가할 수 있습니다.
예시: 코딩 에이전트를 위한 이론적 평가
에이전트가 인증 우회(authentication bypass) 취약점을 수정해야 하는 코딩 과제를 생각해 봅시다. 아래의 예시 YAML 파일처럼, 채점기와 메트릭을 함께 사용해 평가할 수 있습니다.
task:
id: "fix-auth-bypass_1"
desc: "Fix authentication bypass when password field is empty and ..."
graders:
- type: deterministic_tests
required: [test_empty_pw_rejected.py, test_null_pw_rejected.py]
- type: llm_rubric
rubric: prompts/code_quality.md
- type: static_analysis
commands: [ruff, mypy, bandit]
- type: state_check
expect:
security_logs: {event_type: "auth_blocked"}
- type: tool_calls
required:
- {tool: read_file, params: {path: "src/auth/*"}}
- {tool: edit_file}
- {tool: run_tests}
tracked_metrics:
- type: transcript
metrics:
- n_turns
- n_toolcalls
- n_total_tokens
- type: latency
metrics:
- time_to_first_token
- output_tokens_per_sec
- time_to_last_token이 예시는 설명을 위해 가능한 채점기 범위를 모두 보여줍니다. 실제로 코딩 평가는 대개 정확성 검증을 위한 유닛 테스트와 전체 코드 품질을 평가하는 LLM 루브릭에 의존하며, 추가 채점기와 메트릭은 필요할 때만 더합니다.
**대화형 에이전트(conversational agents)**는 지원, 세일즈, 코칭 등의 도메인에서 사용자와 상호작용합니다. 전통적 챗봇과 달리 상태를 유지하고, 도구를 사용하며, 대화 중간에 행동을 취합니다. 코딩/리서치 에이전트도 사용자와 여러 턴 상호작용할 수 있지만, 대화형 에이전트는 별도의 도전 과제를 가집니다. 상호작용 자체의 품질이 평가 대상의 일부이기 때문입니다. 대화형 에이전트의 효과적인 평가는 보통 검증 가능한 최종 상태(outcome)와 과제 완료 및 상호작용 품질을 모두 포착하는 루브릭에 의존합니다. 또한 대부분의 다른 평가와 달리, 사용자 역할을 시뮬레이션하기 위해 두 번째 LLM이 필요할 때가 많습니다. 우리는 정렬 감사 에이전트(alignment auditing agents)에서 이 접근을 사용해 장시간의 적대적 대화를 통해 모델을 스트레스 테스트합니다.
대화형 에이전트의 성공은 다차원적일 수 있습니다. 티켓이 해결되었는가(state check), 10턴 이내에 끝났는가(transcript 제약), 톤이 적절했는가(LLM 루브릭)? 다차원성을 포함하는 두 벤치마크로 𝜏-Bench와 후속작 τ2-Bench가 있습니다. 이들은 리테일 지원, 항공권 예약 등 도메인에서 멀티 턴 상호작용을 시뮬레이션하며, 한 모델이 사용자 페르소나를 맡고 에이전트가 현실적인 시나리오를 처리합니다.
예시: 대화형 에이전트를 위한 이론적 평가
짜증난 고객의 환불을 처리해야 하는 지원 과제를 생각해 봅시다.
graders:
- type: llm_rubric
rubric: prompts/support_quality.md
assertions:
- "Agent showed empathy for customer's frustration"
- "Resolution was clearly explained"
- "Agent's response grounded in fetch_policy tool results"
- type: state_check
expect:
tickets: {status: resolved}
refunds: {status: processed}
- type: tool_calls
required:
- {tool: verify_identity}
- {tool: process_refund, params: {amount: "<=100"}}
- {tool: send_confirmation}
- type: transcript
max_turns: 10
tracked_metrics:
- type: transcript
metrics:
- n_turns
- n_toolcalls
- n_total_tokens
- type: latency
metrics:
- time_to_first_token
- output_tokens_per_sec
- time_to_last_token코딩 예시와 마찬가지로, 이 과제는 설명을 위해 여러 채점기 유형을 보여줍니다. 실제로 대화형 에이전트 평가는 소통 품질과 목표 달성을 모두 평가하기 위해 모델 기반 채점기를 주로 사용합니다. 질문 답변처럼 “정답”이 여러 개일 수 있는 작업이 많기 때문입니다.
리서치 에이전트는 정보를 수집, 종합, 분석해 답변이나 보고서 같은 출력을 생성합니다. 유닛 테스트가 이진 신호(통과/실패)를 제공하는 코딩 에이전트와 달리, 리서치 품질은 과제에 상대적으로만 판단될 수 있습니다. “포괄적(comprehensive)”, “근거가 잘 갖춰짐(well-sourced)”, 심지어 “정확함(correct)”의 의미는 문맥에 따라 달라집니다. 시장 조사, 인수합병 실사, 과학 보고서는 각각 다른 기준을 요구합니다.
리서치 평가는 독특한 도전에 직면합니다. 전문가 간에도 종합이 충분히 포괄적인지 의견이 갈릴 수 있고, 참조 콘텐츠가 계속 변하기 때문에 그라운드 트루스가 이동하며, 더 길고 개방형 출력은 실수 여지를 키웁니다. 예를 들어 BrowseComp는 오픈 웹에서 건초더미 속 바늘을 찾는 능력을 테스트합니다. 검증은 쉽지만 해결은 어려운 질문들입니다.
리서치 에이전트 평가를 구축하는 한 전략은 채점기 유형을 결합하는 것입니다. 근거성(groundedness) 체크는 주장(claim)이 검색된 소스에 의해 지지되는지 확인하고, 커버리지(coverage) 체크는 좋은 답변에 반드시 포함되어야 하는 핵심 사실을 정의하며, 소스 품질(source quality) 체크는 단순히 처음 검색된 것이 아니라 권위 있는 출처를 참조했는지 확인합니다. “회사 X의 3분기 매출은?”처럼 객관적으로 정답이 있는 과제에는 exact match가 통합니다. LLM은 근거 없는 주장과 커버리지의 빈틈을 표시할 수 있고, 개방형 종합의 일관성과 완성도도 검증할 수 있습니다.
리서치 품질의 주관성을 고려하면, LLM 기반 루브릭은 전문가의 인간 판단에 맞춰 자주 보정해야 효과적으로 채점할 수 있습니다.
**컴퓨터 사용 에이전트(computer use agents)**는 API나 코드 실행이 아니라, 인간과 같은 인터페이스—스크린샷, 마우스 클릭, 키보드 입력, 스크롤—를 통해 소프트웨어와 상호작용합니다. 디자인 도구부터 레거시 엔터프라이즈 소프트웨어까지 GUI가 있는 어떤 애플리케이션이든 사용할 수 있습니다. 평가를 위해서는 에이전트를 실제 또는 샌드박스 환경에서 실행하고, 의도한 outcome을 달성했는지 확인해야 합니다. 예를 들어 WebArena는 브라우저 기반 과제를 테스트하며, URL 및 페이지 상태 체크로 올바르게 탐색했는지 검증하고, 데이터 변경 과제의 경우 백엔드 상태 검증(주문이 실제로 생성되었는지 확인)을 수행합니다. OSWorld는 이를 전체 운영체제 제어로 확장하며, 과제 완료 후 파일 시스템 상태, 앱 설정, DB 내용, UI 요소 속성 등 다양한 아티팩트를 검사하는 평가 스크립트를 제공합니다.
브라우저 사용 에이전트는 토큰 효율성과 지연시간의 균형이 필요합니다. DOM 기반 상호작용은 빠르지만 토큰을 많이 소비하고, 스크린샷 기반 상호작용은 느리지만 토큰 효율적입니다. 예를 들어 클로드에게 위키피디아 요약을 요청할 때는 DOM에서 텍스트를 추출하는 편이 효율적입니다. 반면 아마존에서 새 노트북 케이스를 찾는 작업은 스크린샷이 더 효율적입니다(전체 DOM 추출은 토큰 집약적이므로). Claude for Chrome 제품에서는 맥락에 따라 올바른 도구를 선택하는지 확인하는 평가를 개발했습니다. 이를 통해 브라우저 기반 과제를 더 빠르고 정확하게 완료할 수 있었습니다.
에이전트 유형과 무관하게, 에이전트 행동은 실행마다 달라질 수 있어 평가 결과 해석이 처음 보기보다 어렵습니다. 각 과제는 고유의 성공률을 가집니다(어떤 과제는 90%, 다른 과제는 50%). 한 번의 평가 실행에서 통과한 과제가 다음 실행에서는 실패할 수도 있습니다. 때로 우리가 측정하고 싶은 것은, 에이전트가 과제를 얼마나 자주(트라이얼 중 비율) 성공하는지입니다.
이 뉘앙스를 포착하는 두 가지 메트릭이 있습니다.
pass@k는 에이전트가 k번 시도 중 최소 한 번은 정답을 얻을 가능성을 측정합니다. k가 증가할수록 pass@k 점수는 올라갑니다. 더 많은 ‘슈팅 찬스’는 최소 1회 성공 확률을 높입니다. pass@1이 50%라는 것은 모델이 평가의 과제 절반을 첫 시도에 성공한다는 뜻입니다. 코딩에서는 보통 첫 시도에 해결하는 것이 가장 중요하므로 pass@1에 관심이 큽니다. 다른 경우에는 여러 해법을 제안해도 그중 하나만 성공하면 되는 상황도 있습니다.
pass^k는 k번의 트라이얼이 모두 성공할 확률을 측정합니다. k가 증가할수록 pass^k는 감소합니다. 더 많은 트라이얼에 걸쳐 일관성을 요구하는 것은 더 어려운 기준이기 때문입니다. 에이전트의 트라이얼당 성공률이 75%이고 3번 트라이얼을 실행하면, 3번 모두 통과할 확률은 (0.75)³ ≈ 42%입니다. 이 메트릭은 특히 매번 신뢰할 수 있는 동작이 필요한 고객-facing 에이전트에서 중요합니다.
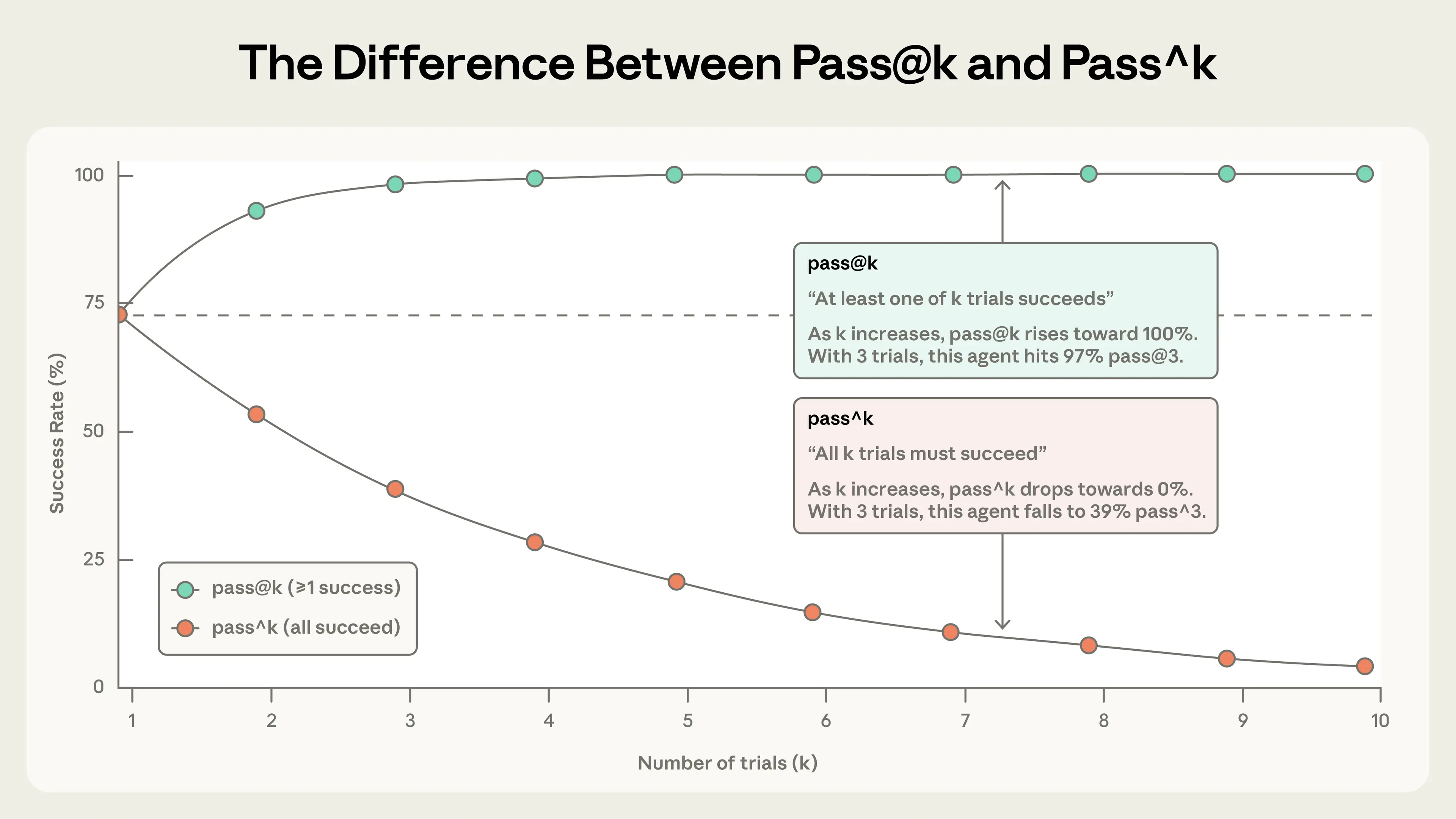
트라이얼 수가 증가하면 pass@k와 pass^k는 서로 다른 이야기를 합니다. k=1에서는 동일(둘 다 트라이얼당 성공률). k=10에서는 반대가 됩니다. pass@k는 100%에 가까워지고 pass^k는 0%로 떨어집니다.
두 메트릭 모두 유용하며, 어떤 것을 쓸지는 제품 요구사항에 달려 있습니다. 한 번의 성공이 중요한 도구에는 pass@k, 일관성이 필수인 에이전트에는 pass^k가 적합합니다.
이 섹션은 “평가가 전혀 없는 상태”에서 “신뢰할 수 있는 평가”로 가기 위한 실용적이고 현장 검증된 조언을 제시합니다. 이를 평가 주도 에이전트 개발의 로드맵으로 생각하세요: 초기에 성공을 정의하고, 명확히 측정하며, 지속적으로 반복 개선합니다.
Step 0. 일찍 시작하기
팀들이 평가 구축을 미루는 이유 중 하나는 수백 개 과제가 필요하다고 생각하기 때문입니다. 하지만 실제 실패 사례에서 뽑은 20~50개의 단순 과제만으로도 훌륭한 시작이 됩니다. 초기 에이전트 개발에서는 시스템 변경이 종종 뚜렷한 영향을 주고, 이 큰 효과 크기(effect size) 때문에 작은 샘플로도 충분합니다. 성숙한 에이전트는 더 작은 효과를 감지하기 위해 더 크고 어려운 평가가 필요할 수 있지만, 시작은 80/20 접근이 최선입니다. 기다릴수록 평가는 더 만들기 어려워집니다. 초반에는 제품 요구사항이 자연스럽게 테스트 케이스로 이어지지만, 너무 늦으면 라이브 시스템에서 성공 기준을 역설계해야 합니다.
Step 1. 이미 수동으로 테스트하는 것에서 시작하기
개발 중에 수행하는 수동 체크—각 릴리스 전에 확인하는 행동과, 최종 사용자가 자주 시도하는 작업—에서 시작하세요. 이미 프로덕션이라면 버그 트래커와 지원 큐를 살펴보세요. 사용자 보고 실패를 테스트 케이스로 변환하면 스위트가 실제 사용을 반영하게 됩니다. 사용자 영향도로 우선순위를 매기면 중요한 곳에 노력을 투자할 수 있습니다.
Step 2: 레퍼런스 솔루션을 포함한 모호하지 않은 과제 작성하기
과제 품질을 제대로 맞추는 것은 생각보다 어렵습니다. 좋은 과제는 두 명의 도메인 전문가가 독립적으로 동일한 합격/불합격 판정을 내릴 수 있는 과제입니다. 그들이 스스로 그 과제를 통과할 수 있나요? 아니라면 과제는 더 다듬어야 합니다. 과제 명세의 모호함은 메트릭의 노이즈가 됩니다. 모델 기반 채점기의 기준도 마찬가지입니다. 모호한 루브릭은 일관되지 않은 판단을 낳습니다.
각 과제는 지시를 올바르게 따르면 에이전트가 통과할 수 있어야 합니다. 이는 미묘할 수 있습니다. 예를 들어 Terminal-Bench를 감사(auditing)했을 때, 과제가 스크립트를 작성하라고 하면서 파일 경로를 명시하지 않는데, 테스트는 특정 파일 경로를 가정하는 경우가 있었습니다. 이런 경우 에이전트는 자신의 잘못이 없어도 실패할 수 있습니다. 채점기가 검사하는 모든 것은 과제 설명에서 명확해야 하며, 에이전트가 모호한 스펙 때문에 실패하면 안 됩니다. 최첨단 모델에서도 많은 트라이얼에서 0% 통과(즉 0% pass@100)는 대개 “무능한 에이전트”가 아니라 “깨진 과제”의 신호이며, 과제 명세와 채점기를 재점검해야 한다는 뜻입니다.
각 과제에 대해 레퍼런스 솔루션을 만드는 것도 유용합니다. 모든 채점기를 통과하는 ‘검증된 출력’을 마련하면 과제가 풀 수 있음을 증명하고, 채점기 설정이 올바른지 확인할 수 있습니다.
Step 3: 균형 잡힌 문제 세트 구성하기
어떤 행동이 일어나야 하는 경우와 일어나지 말아야 하는 경우를 모두 테스트하세요. 한쪽만 있는 평가는 한쪽만 최적화하게 만듭니다. 예를 들어 에이전트가 검색해야 할 때 검색하는지 만 테스트하면, 거의 모든 것에 대해 검색하는 에이전트를 만들게 될 수 있습니다. 클래스 불균형(class-imbalanced) 평가를 피하세요.
우리는 Claude.ai에서 웹 검색 평가를 만들 때 이를 직접 경험했습니다. 과제는 “검색하면 안 되는 상황에서 검색하지 않도록” 하면서도, 적절할 때는 “광범위한 리서치 능력”을 유지하는 것이었습니다. 팀은 양쪽을 모두 커버하는 평가를 만들었습니다. 예를 들어 날씨 같은 질문은 검색해야 하고, “애플 창립자는 누구인가?” 같은 질문은 기존 지식으로 답해야 합니다. 언더트리거링(필요할 때 검색하지 않음)과 오버트리거링(불필요하게 검색함) 사이의 균형을 잡는 것은 어려웠고, 프롬프트와 평가 모두 여러 차례 다듬어야 했습니다. 새로운 예제 문제가 생길 때마다 커버리지를 개선하기 위해 평가에 계속 추가하고 있습니다.
Step 4: 안정적인 환경을 갖춘 견고한 평가 하네스 구축하기
평가에서의 에이전트가 프로덕션에서 쓰는 에이전트와 대체로 동일하게 동작하고, 환경 자체가 추가 노이즈를 만들지 않는 것이 필수입니다. 각 트라이얼은 깨끗한 환경에서 시작하도록 “격리(isolated)”되어야 합니다. 불필요한 공유 상태(남은 파일, 캐시된 데이터, 자원 고갈)는 에이전트 성능이 아니라 인프라의 불안정성(flakiness) 때문에 상관된 실패를 유발할 수 있습니다. 공유 상태는 성능을 인위적으로 부풀릴 수도 있습니다. 예를 들어 일부 내부 평가에서 Claude가 이전 트라이얼의 git 히스토리를 살펴 과제에서 부당한 이점을 얻는 것을 관찰했습니다. 여러 트라이얼이 환경의 동일한 제한(예: CPU 메모리 부족) 때문에 실패한다면, 이 트라이얼들은 같은 요인의 영향을 받으므로 독립이 아니며, 에이전트 성능을 측정하는 평가 결과는 신뢰할 수 없게 됩니다.
Step 5: 채점기를 신중하게 설계하기
앞서 논의했듯이, 훌륭한 평가 설계는 에이전트와 과제에 가장 적합한 채점기를 선택하는 것을 포함합니다. 가능하면 결정론적 채점기를, 필요하거나 유연성이 더 필요할 때는 LLM 채점기를 선택하고, 추가 검증을 위해 인간 채점기를 신중하게 사용하길 권장합니다.
에이전트가 도구 호출을 특정 순서로 하는 등 매우 구체적인 단계를 따랐는지 확인하려는 본능이 흔합니다. 하지만 우리는 이 접근이 너무 경직되어 있고 과도하게 깨지기 쉬운 테스트를 만든다는 것을 발견했습니다. 에이전트는 평가 설계자가 예상하지 못한 유효한 접근을 자주 찾기 때문입니다. 창의성을 불필요하게 처벌하지 않기 위해, 대개는 “어떤 경로를 택했는가”보다 “무엇을 만들어냈는가”를 채점하는 편이 낫습니다.
여러 구성 요소가 있는 과제에는 **부분 점수(partial credit)**를 넣으세요. 문제를 올바로 식별하고 고객 확인까지 했지만 환불 처리를 실패한 지원 에이전트는, 즉시 실패한 에이전트보다 의미 있게 낫습니다. 결과에서 이러한 성공의 연속성을 표현하는 것이 중요합니다.
모델 채점은 정확도를 검증하기 위해 신중한 반복이 필요합니다. LLM-as-judge 채점기는 인간 전문가와 긴밀히 보정해, 인간 채점과 모델 채점 간의 차이가 작다는 확신을 얻어야 합니다. 환각을 피하기 위해 정보가 부족하면 “Unknown”을 반환하라는 식의 탈출구를 제공하세요. 각 차원을 구조화한 명확한 루브릭을 만들고, 한 모델이 모든 차원을 한 번에 채점하기보다 차원별로 분리된 LLM-as-judge로 채점하는 것도 도움이 됩니다. 시스템이 견고해지면 인간 리뷰는 가끔만 해도 충분합니다.
어떤 평가는 좋은 에이전트 성능에도 낮은 점수를 만드는 미묘한 실패 모드를 갖습니다. 채점 버그, 에이전트 하네스 제약, 모호함 때문에 에이전트가 과제를 풀지 못하는 경우입니다. 정교한 팀도 이를 놓칠 수 있습니다. 예를 들어 Opus 4.5는 CORE-Bench에서 처음 42%를 기록했지만, Anthropic 리서처가 여러 문제를 발견했습니다. “96.12”를 출력했는데 “96.124991…”을 기대한다며 벌점을 주는 경직된 채점, 모호한 과제 명세, 정확히 재현 불가능한 확률적 과제들이었습니다. 버그를 고치고 덜 제약적인 스캐폴드를 사용하자 점수는 95%로 뛰었습니다. 비슷하게 METR은 시간 지평(time horizon) 벤치마크의 일부 과제가 “명시된 점수 임계값에 맞추라”고 했는데, 채점은 그 임계값을 ‘초과’해야 통과로 처리된다는 오설정을 발견했습니다. 이는 지시를 따르는 Claude 같은 모델을 불리하게 만들고, 목표를 무시한 모델이 더 높은 점수를 받게 했습니다. 과제와 채점기를 꼼꼼히 이중 확인하면 이런 문제를 피할 수 있습니다.
채점기가 우회(bypass)나 해킹에 강하도록 만드세요. 에이전트가 평가를 쉽게 “치트”할 수 있어서는 안 됩니다. 과제와 채점기는 의도치 않은 허점을 악용하는 것이 아니라 실제 문제 해결이 필요하도록 설계되어야 합니다.
Step 6: 트랜스크립트 확인하기
채점기가 제대로 작동하는지 알려면, 많은 트라이얼의 트랜스크립트와 채점 결과를 읽어야 합니다. Anthropic에서는 평가 트랜스크립트를 볼 수 있는 도구에 투자했고, 정기적으로 시간을 내어 읽습니다. 과제가 실패했을 때 트랜스크립트는 에이전트가 진짜 실수를 했는지, 아니면 채점기가 유효한 해법을 거부했는지를 알려줍니다. 또한 에이전트와 평가 동작의 핵심 디테일을 드러내는 경우가 많습니다.
실패는 공정해 보여야 합니다. 에이전트가 무엇을 잘못했고 왜인지 명확해야 합니다. 점수가 오르지 않을 때, 그것이 에이전트 성능 때문이지 평가 때문이 아니라는 확신이 필요합니다. 트랜스크립트를 읽는 것은 평가가 실제로 중요한 것을 측정하고 있는지 검증하는 방법이며, 에이전트 개발에서 중요한 역량입니다.
Step 7: 역량 평가 포화(saturation) 모니터링하기
100%인 평가는 회귀는 추적하지만 개선 신호를 제공하지 않습니다. **평가 포화(eval saturation)**는 에이전트가 풀 수 있는 과제를 모두 통과해 더 이상 개선 여지가 없을 때 발생합니다. 예를 들어 SWE-Bench Verified 점수는 올해 30%에서 시작했고, 현재 최첨단 모델은 80% 이상으로 포화에 가까워지고 있습니다. 평가가 포화에 가까워질수록 진전도 느려지며, 가장 어려운 과제만 남기 때문입니다. 이는 결과를 오해하게 만들 수 있습니다. 큰 역량 향상이 점수에서는 작은 증가로 보이기 때문입니다. 예를 들어 코드 리뷰 스타트업 Qodo는 원샷(one-shot) 코딩 평가가 장시간·복잡 과제에서의 개선을 포착하지 못해 Opus 4.5를 처음엔 인상적이지 않게 봤습니다. 이에 대응해 새로운 에이전틱 평가 프레임워크를 개발하여 진전을 훨씬 더 명확히 보게 되었습니다.
원칙적으로 우리는 누군가 평가의 세부사항을 파고들고 트랜스크립트를 읽기 전에는 평가 점수를 액면 그대로 믿지 않습니다. 채점이 불공정하거나, 과제가 모호하거나, 유효한 해법이 처벌되거나, 하네스가 모델을 제약한다면, 평가는 수정되어야 합니다.
Step 8: 개방적 기여와 유지보수로 평가 스위트를 장기적으로 건강하게 유지하기
평가 스위트는 지속적인 관심과 명확한 오너십이 필요합니다.
Anthropic에서는 다양한 평가 유지 방식들을 실험했습니다. 가장 효과적이었던 것은 전용 평가 팀이 핵심 인프라를 소유하고, 도메인 전문가와 제품 팀이 대부분의 과제(task)를 기여하며 스스로 평가를 실행하는 방식이었습니다.
AI 제품 팀에게 평가는 유닛 테스트를 유지하는 것만큼이나 일상적이어야 합니다. 초기에 “작동하는 것처럼 보이는” AI 기능에 몇 주를 쓰고도, 실제로는 암묵적 기대를 충족하지 못해 실패할 수 있습니다. 잘 설계된 평가는 이런 문제를 더 일찍 드러냈을 것입니다. 평가 과제를 정의하는 것은 제품 요구사항이 실제로 개발을 시작하기에 충분히 구체적인지 스트레스 테스트하는 가장 좋은 방법 중 하나입니다.
우리는 평가 주도 개발(eval-driven development)을 권합니다. 에이전트가 아직 수행하지 못하는 계획된 역량을 평가로 먼저 정의하고, 에이전트 성능이 좋아질 때까지 반복하세요. 내부적으로 우리는 오늘은 “충분히 잘” 동작하지만, 몇 달 뒤 모델이 가능해질 일을 내다본 베팅 형태의 기능을 만들기도 합니다. 통과율이 낮게 시작하는 역량 평가는 이를 가시화합니다. 새 모델이 나오면 스위트를 실행해 어떤 베팅이 성공했는지 빠르게 알 수 있습니다.
제품 요구사항과 사용자에 가장 가까운 사람들이 성공을 정의하기에 최적입니다. 현재 모델 역량으로는 제품 매니저, 고객 성공 매니저, 세일즈 담당자도 Claude Code로 PR 형태의 평가 과제를 기여할 수 있습니다. 그렇게 하도록 허용하세요. 아니, 더 나아가 적극적으로 가능하게 하세요.
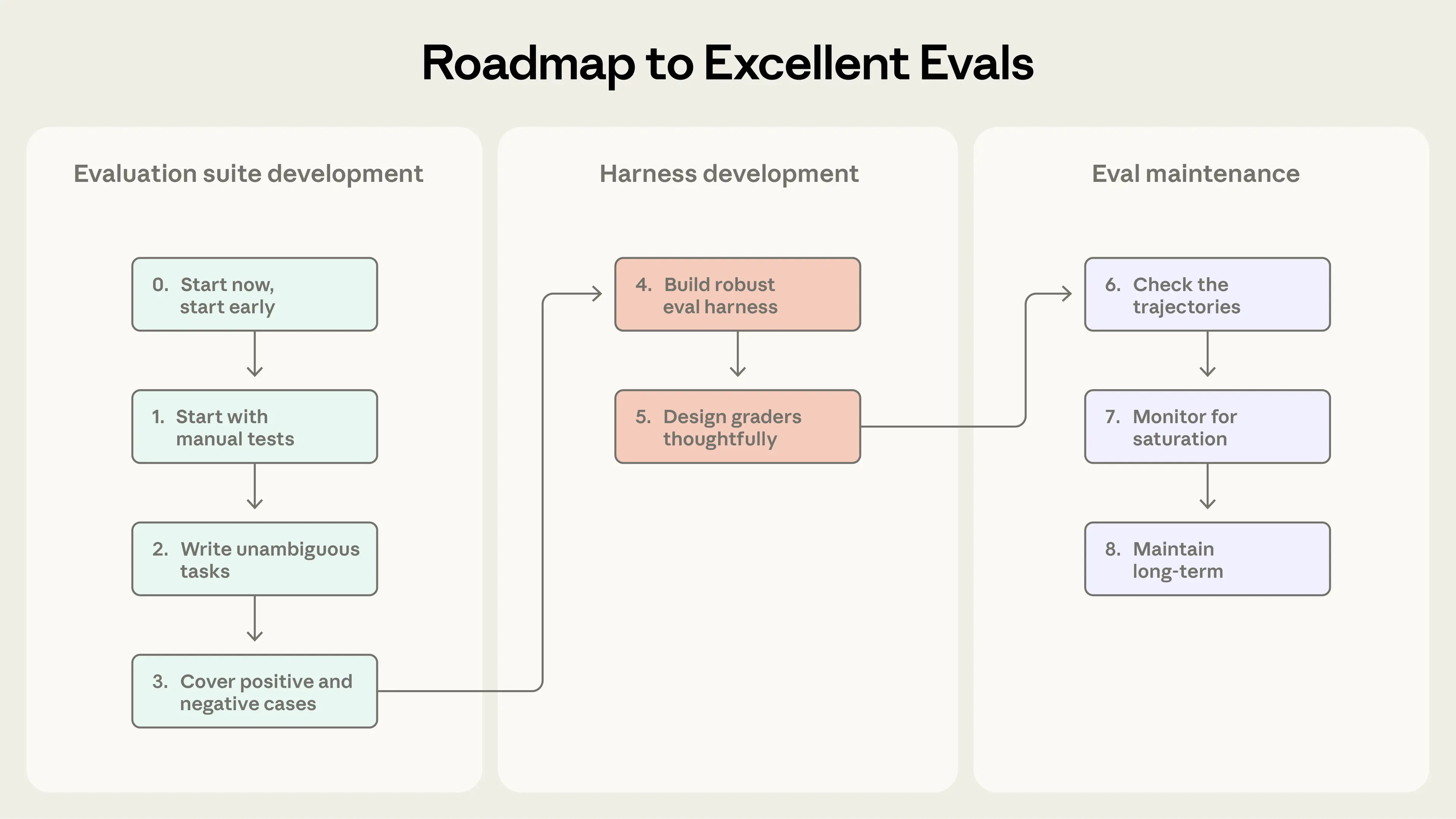
효과적인 평가를 만드는 과정.
자동화 평가는 프로덕션에 배포하거나 실제 사용자에게 영향을 주지 않고도 수천 개 과제에서 에이전트를 실행할 수 있습니다. 하지만 이는 에이전트 성능을 이해하는 여러 방법 중 하나일 뿐입니다. 완전한 그림에는 프로덕션 모니터링, 사용자 피드백, A/B 테스트, 수동 트랜스크립트 리뷰, 체계적 인간 평가가 포함됩니다.
AI 에이전트 성능을 이해하기 위한 접근 방식 개요
| 방법 | 장점 | 단점 |
|---|---|---|
| 자동화 평가(Automated evals) 실제 사용자 없이 프로그램으로 테스트 실행 | * 빠른 반복 * 완전 재현 가능 * 사용자 영향 없음 * 모든 커밋에서 실행 가능 * 프로덕션 배포 없이 대규모 시나리오 테스트 | * 구축에 upfront 투자 필요 * 제품/모델 변화에 따라 드리프트를 피하려면 지속적 유지보수 필요 * 실제 사용 패턴과 맞지 않으면 거짓 확신을 만들 수 있음 |
| 프로덕션 모니터링(Production monitoring) 라이브 시스템에서 메트릭과 오류 추적 | * 실제 사용자 행동을 규모 있게 드러냄 * 합성 평가가 놓치는 이슈 포착 * 에이전트가 실제로 어떻게 수행되는지의 그라운드 트루스 제공 | * 반응적: 문제를 알기 전에 사용자가 먼저 겪음 * 신호가 노이즈일 수 있음 * 계측(instrumentation) 투자 필요 * 채점을 위한 그라운드 트루스 부족 |
| A/B 테스트 실제 사용자 트래픽으로 변형 비교 | * 실제 사용자 결과(리텐션, 과제 완료) 측정 * 교란 요인 통제 * 확장 가능하고 체계적 | * 유의미성 도달까지 느림(수일~수주) 및 충분한 트래픽 필요 * 배포한 변경만 테스트 * 트랜스크립트를 충분히 리뷰하지 못하면 지표 변화의 “왜”에 대한 신호가 약함 |
| 사용자 피드백(User feedback) 싫어요/버그 리포트 같은 명시적 신호 | * 예상치 못한 문제를 드러냄 * 실제 사용자 예제를 동반 * 피드백이 제품 목표와 상관되는 경우가 많음 | * 희소하고 자기선택적(self-selected) * 심각한 이슈로 치우침 * 사용자가 실패 원인을 잘 설명하지 않음 * 자동화 아님 * 주로 사용자에게 이슈 발견을 의존하면 사용자 경험에 부정적 영향 |
| 수동 트랜스크립트 리뷰(Manual transcript review) 사람이 대화를 읽어보는 방식 | * 실패 모드에 대한 직관 형성 * 자동 체크가 놓치는 미묘한 품질 문제 포착 * “좋음”의 기준을 보정하고 디테일 파악 | * 시간 많이 듦 * 확장 안 됨 * 커버리지가 들쭉날쭉 * 리뷰어 피로 또는 리뷰어 간 차이가 신호 품질에 영향 * 보통 정량 채점보다 정성 신호 위주 |
| 체계적 인간 연구(Systematic human studies) 훈련된 평가자가 구조적으로 채점 | * 여러 인간 평가자의 골드 스탠더드 품질 판단 * 주관적/모호한 과제 처리 가능 * 모델 기반 채점기 개선 신호 제공 | * 상대적으로 비싸고 턴어라운드 느림 * 자주 실행하기 어려움 * 평가자 불일치(inter-rater) 조정 필요 * 법률/금융/헬스케어 같은 복잡 도메인은 전문가 필요 |
이 방법들은 에이전트 개발 단계에 따라 서로 다르게 매핑됩니다. 자동화 평가는 특히 출시 전과 CI/CD에서 유용하며, 에이전트 변경과 모델 업그레이드마다 실행해 품질 문제에 대한 1차 방어선이 됩니다. 프로덕션 모니터링은 출시 후 분포 드리프트와 예기치 못한 현실 실패를 감지합니다. A/B 테스트는 충분한 트래픽이 확보되면 큰 변경을 검증합니다. 사용자 피드백과 트랜스크립트 리뷰는 빈틈을 메우기 위한 상시 관행입니다. 피드백을 지속적으로 트리아지하고, 매주 트랜스크립트를 샘플링해 읽고, 필요할 때 더 깊게 파고드세요. 체계적 인간 연구는 LLM 채점기 보정이나, 인간 합의가 참조 표준이 되는 주관적 출력 평가에 아껴 사용하세요.
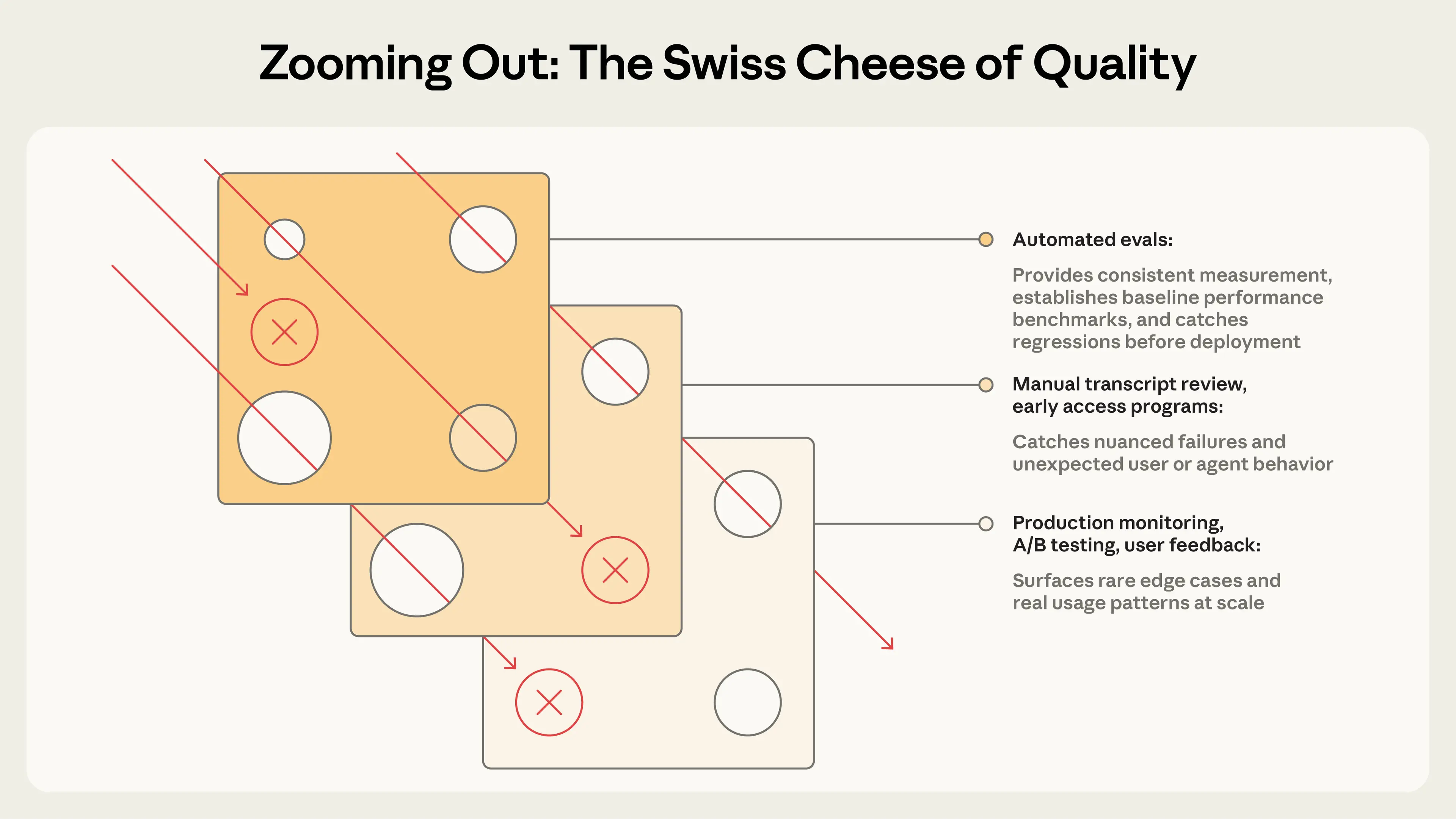
안전공학의 스위스 치즈 모델(Swiss Cheese Model)처럼, 단일 평가 레이어는 모든 문제를 잡아내지 못합니다. 여러 방법을 결합하면, 한 레이어를 통과한 실패가 다른 레이어에서 잡힙니다.
가장 효과적인 팀은 이 방법들을 결합합니다. 빠른 반복을 위한 자동화 평가, 그라운드 트루스를 위한 프로덕션 모니터링, 그리고 보정을 위한 주기적 인간 리뷰입니다.
평가가 없는 팀은 반응적 루프에 갇힙니다. 한 실패를 고치면 다른 실패가 생기고, 실제 회귀와 노이즈를 구분하지 못합니다. 일찍 투자한 팀은 반대로 됩니다. 실패가 테스트 케이스가 되고, 테스트 케이스가 회귀를 막고, 메트릭이 추측을 대체하면서 개발이 가속합니다. 평가는 팀 전체에 오를 언덕을 제공해, “에이전트가 더 나빠진 것 같다”를 실행 가능한 문제로 바꿉니다. 가치는 누적되지만, 사후 고려가 아니라 핵심 구성 요소로 대할 때만 그렇습니다.
에이전트 유형에 따라 패턴은 다르지만, 여기서 설명한 기본 원칙은 같습니다. 완벽한 스위트를 기다리지 말고 일찍 시작하세요. 관찰된 실패에서 현실적인 과제를 수집하세요. 모호하지 않고 견고한 성공 기준을 정의하세요. 채점기를 신중히 설계하고 여러 유형을 결합하세요. 문제는 모델에게 충분히 어려워야 합니다. 평가의 신호 대 잡음비를 개선하기 위해 반복하세요. 트랜스크립트를 읽으세요!
AI 에이전트 평가는 아직 초기이자 빠르게 진화하는 분야입니다. 에이전트가 더 긴 과제를 수행하고, 멀티 에이전트 시스템에서 협업하며, 점점 더 주관적인 일을 다루게 되면, 우리는 기법을 계속 적응시켜야 합니다. 더 많은 것을 배울수록 모범 사례를 계속 공유하겠습니다.
작성: Mikaela Grace, Jeremy Hadfield, Rodrigo Olivares, Jiri De Jonghe. 또한 David Hershey, Gian Segato, Mike Merrill, Alex Shaw, Nicholas Carlini, Ethan Dixon, Pedram Navid, Jake Eaton, Alyssa Baum, Lina Tawfik, Karen Zhou, Alexander Bricken, Sam Kennedy, Robert Ying 등 여러 분의 기여에 감사드립니다. iGent, Cognition, Bolt, Sierra, Vals.ai, Macroscope, PromptLayer, Stripe, Shopify, Terminal Bench 팀 등 평가를 함께 협업하며 배운 고객 및 파트너들께도 특별히 감사드립니다. 이 작업은 Anthropic에서 평가 관행을 발전시키는 데 도움을 준 여러 팀의 공동 노력의 결과입니다.
여러 오픈소스 및 상용 프레임워크는 팀이 인프라를 처음부터 만들지 않고도 에이전트 평가를 구현하도록 도와줍니다. 올바른 선택은 에이전트 유형, 기존 스택, 오프라인 평가가 필요한지, 프로덕션 관측가능성(observability)이 필요한지(또는 둘 다)에 따라 달라집니다.
Harbor는 컨테이너화된 환경에서 에이전트를 실행하도록 설계되었고, 클라우드 제공자 전반에서 대규모로 트라이얼을 실행하는 인프라와 과제 및 채점기를 정의하는 표준 포맷을 제공합니다. Terminal-Bench 2.0 같은 인기 벤치마크가 Harbor 레지스트리를 통해 제공되어, 커스텀 평가 스위트와 함께 기존 벤치마크를 쉽게 실행할 수 있습니다.
Promptfoo는 프롬프트 테스트를 위한 선언적 YAML 구성에 초점을 맞춘 가볍고 유연한 오픈소스 프레임워크입니다. 문자열 매칭부터 LLM-as-judge 루브릭까지 다양한 어서션 타입을 제공합니다. 우리는 제품 평가 다수에서 Promptfoo의 한 버전을 사용합니다.
Braintrust는 오프라인 평가와 프로덕션 관측가능성 및 실험 추적을 결합한 플랫폼으로, 개발 중 반복과 프로덕션 품질 모니터링이 모두 필요한 팀에 유용합니다. autoevals 라이브러리에는 사실성(factuality), 관련성(relevance) 등 흔한 차원에 대한 사전 구축 스코어러가 포함되어 있습니다.
LangSmith는 트레이싱, 오프라인 및 온라인 평가, 데이터셋 관리를 제공하며 LangChain 생태계와 긴밀히 통합됩니다. Langfuse는 데이터 레지던시 요구가 있는 팀을 위한 셀프호스팅 오픈소스 대안으로 유사한 기능을 제공합니다.
많은 팀이 여러 도구를 조합하거나, 자체 평가 프레임워크를 만들거나, 간단한 평가 스크립트로 시작합니다. 우리는 프레임워크가 진행을 가속하고 표준화하는 데 가치가 있을 수 있지만, 결국 그 프레임워크를 통해 실행하는 평가 과제가 좋지 않으면 소용없다는 점을 발견했습니다. 보통은 워크플로에 맞는 프레임워크를 빠르게 선택한 다음, 고품질 테스트 케이스와 채점기를 반복 개선하는 데 에너지를 투자하는 것이 최선입니다.