테이블 크기가 변할 때 재계산해야 하는 키의 비율을 최소화하도록 해시 테이블을 설계하는 알고리즘인 일관 해싱(consistent hashing)을 소개한다.
내비게이션 토글 Eli Bendersky's website
Eli Bendersky's website
September 27, 2025 at 05:54 TagsGo , Programming
이 글은 일관 해싱을 소개한다. 일관 해싱은 해시 테이블의 크기가 바뀔 때 테이블의 크기 변화로 인해 재계산해야 하는 키의 일부만 작게 유지하도록 해시 테이블을 설계하는 알고리즘이다.
캐싱 웹 프록시를 설계한다고 하자. 그런데 예상되는 저장소 요구량이 단일 머신이 감당할 수 있는 수준을 넘어선다. 그래서 캐시를 여러 머신에 분산한다. 어떻게 해야 할까? 어떤 URL이 주어졌을 때, 잠재적으로 캐시된 버전을 얻기 위해 어느 서버에 접근해야 하는지 [1] 쉽게 알아낼 수 있게 하려면 어떻게 해야 할까?
즉시 떠오르는 접근은 _해싱_이다. URL의 숫자 해시를 계산하고 이를 N개의 노드(이 글에서는 서버를 이렇게 부른다)에 고르게 분배한다:
hash := calculateHashFunction(url) nodeId := hash % N
이 과정은 동작하지만, 실제 애플리케이션에서는 심각한 단점이 있다.
캐싱 사용 사례를 다시 생각해 보자. “인터넷 규모”의 현실적인 애플리케이션에서는 우리가 암묵적으로 둔 가정 하나가 성립하지 않는다. 캐시 노드는 정적이지 않다. 부하가 높으면(혹은 새 머신이 투입되면) 시스템에 새 노드가 추가되고, 기존 노드는 크래시하거나 유지보수를 위해 오프라인으로 내려갈 수 있다. 즉, 애플리케이션의 N은 상수가 아니다.
문제는 이제 명확해질 것이다. 이를 직접 보여주기 위해 Go의 md5 패키지를 사용해 hashItem을 실제로 구현해 보자 [2]:
// hashItem computes the slot an item hashes to, given a total number of slots.
func hashItem(item string, nslots uint64) uint64 {
digest := md5.Sum([]byte(item))
digestHigh := binary.BigEndian.Uint64(digest[8:16])
digestLow := binary.BigEndian.Uint64(digest[:8])
return (digestHigh ^ digestLow) % nslots
}용어를 약간 조정하자:
처음에 32개의 슬롯으로 시작했고, 문자열 "hello", "consistent", "marmot"를 해싱했다고 하자. 다음과 같은 슬롯이 나온다:
hello (n=32): 4
consistent (n=32): 14
marmot (n=32): 5
이제 다른 노드가 추가되어 총 nslots가 33으로 늘었다고 하자. 아이템을 다시 해싱하면:
hello (n=33): 23
consistent (n=33): 18
marmot (n=33): 31
모든 슬롯이 바뀌었다!
이것이 순진한 해싱 접근의 중대한 문제다. nslots가 바뀔 때마다 거의 모든 item에 대해 완전히 다른 슬롯이 나온다. 현실의 애플리케이션에서는, 새 노드가 캐싱 클러스터에 합류하거나 떠날 때마다 클러스터가 새 상태에 안정화되기 전까지 모든 질의에서 캐시 미스가 쏟아진다는 뜻이다. 그리고 노드 변화는 가장 불편한 순간에 일어나기도 한다. 예를 들어 부하가 급증하는(어떤 사이트가 영향력 있는 언론에 언급되었거나, 라이브 이벤트 스트리밍이 있는) 상황에서 이를 처리하려고 새 노드를 추가한다면, 캐시를 잠시라도 전부 잃는 건 좋은 타이밍이 아니다!
일관 해싱 알고리즘은 이 문제를 우아하게 해결한다. 핵심 아이디어는 노드와 아이템을 모두 어떤 구간에 매핑하고, 한 아이템이 자신과 가장 가까운 노드에 속하도록 하는 것이다. 구체적으로는 단위원 [3]을 사용해, 노드와 아이템을 이 원 위의 각도로 매핑한다. 다음 예시가 이 방법이 어떻게 동작하는지 더 자세히 설명한다:
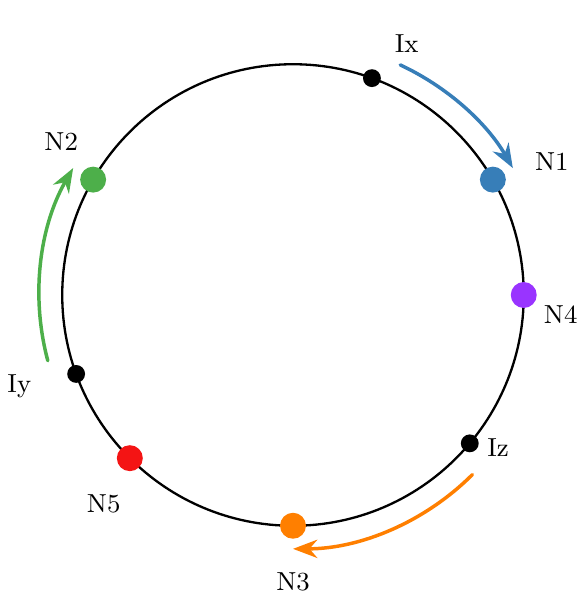 이 그림에는 다섯 노드 N1부터 N5, 그리고 세 아이템 Ix, Iy, Iz가 있다. 처음에는 노드를 추가한다. 해싱 연산을 통해 노드를 원 위에 매핑한다(자세한 내용은 뒤에서). 그런 다음 아이템이 들어올 때마다, 다음과 같이 어느 노드에 속하는지 결정한다:
이 그림에는 다섯 노드 N1부터 N5, 그리고 세 아이템 Ix, Iy, Iz가 있다. 처음에는 노드를 추가한다. 해싱 연산을 통해 노드를 원 위에 매핑한다(자세한 내용은 뒤에서). 그런 다음 아이템이 들어올 때마다, 다음과 같이 어느 노드에 속하는지 결정한다:
그림에서 Ix는 N1, Iy는 N2, Iz는 N3에 매핑된다. 여기까지는 괜찮다. 하지만 이 접근의 이점은 노드가 변할 때 드러난다. 그림에서 N3가 제거된다고 하자. 그러면 Iz는 N5에 매핑된다. 다른 아이템들의 매핑은 변하지 않는다!
노드를 추가할 때도 비슷한 결과가 나온다. 새 노드 N6를 추가했는데, 이 노드가 원 위에서 Iy와 N2 사이 위치로 해싱된다고 하자. 그 순간부터 Iy는 N6에 매핑되지만, 다른 아이템들은 계속 기존 매핑을 유지한다.
총 _M_개의 아이템을 _N_개의 노드에 분배해야 한다고 하자. 순진한 해싱 접근을 쓰면 노드를 추가하거나 제거할 때마다 _M_개 아이템 전부의 매핑이 바뀐다. 반면 일관 해싱에서는 대략 정도만 바뀐다. 이는 엄청난 차이다.
원래의 일관 해싱 논문( [1] 참고)은 이를 알고리즘의 _단조성(monotonicity) 속성_이라고 부른다:
If items are initially assigned to a set of buckets V_1, and then some new buckets are added to form V_2, then an item may move from an old bucket to a new bucket, but not from one old bucket to another.
위에서 설명한 대로 일관 해싱 알고리즘을 구현하는 것은 꽤 쉽다. 구현에서 가장 중요한 부분은 어떤 아이템이 어느 노드에 매핑되는지 찾는 것이다. 이는 어떤 형태로든 탐색을 포함한다. 원래의 일관 해싱 논문은 탐색에 균형 이진 트리를 사용할 것을 제안한다. 여기에서 보여주는 구현은 약간 다르지만 동등한 접근을 사용한다. 즉, 노드 위치(슬롯)의 선형 배열에서 이진 탐색을 하는 방식이다 [4].
먼저 몇 가지 실용적 고려 사항:
노드를 일관 해시에 추가할 때, nslots=ringSize로 두고 위에서 설명한 hashItem 같은 해시 함수를 적용해 노드의 위치를 찾는다. 노드는 다음과 같은 한 쌍의 자료구조로 저장한다. 아래 예시는 위 원 그림의 N1부터 N5까지 노드의 대략적인 위치를 사용한다(여기서는 ringSize=1024라고 가정):
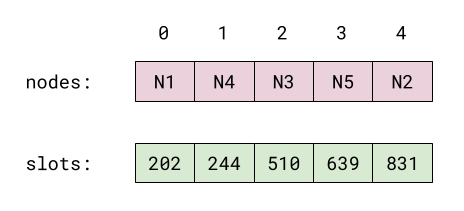 원 위에서의 노드 위치는 정렬된 slots에 저장된다. nodes에는 해당 노드 이름이 들어 있다. 각 i에 대해, nodes[i]는 원 위의 slots[i] 위치에 있다.
원 위에서의 노드 위치는 정렬된 slots에 저장된다. nodes에는 해당 노드 이름이 들어 있다. 각 i에 대해, nodes[i]는 원 위의 slots[i] 위치에 있다.
Go에서의 ConsistentHasher 자료구조는 다음과 같다:
type ConsistentHasher struct {
// nodes is a list of nodes in the hash ring; it's sorted in the same order
// as slots: for each i, the node at index slots[i] is nodes[i].
nodes []string
// slots is a sorted slice of node indices.
slots []uint64
ringSize uint64
}
// NewConsistentHasher creates a new consistent hasher with a given maximal
// ring size.
func NewConsistentHasher(ringSize uint64) *ConsistentHasher {
return &ConsistentHasher{
ringSize: ringSize,
}
}그리고 주어진 아이템이 어느 노드에 매핑되는지 찾는 구현은 다음과 같다:
// FindNodeFor finds the node an item hashes to. It's an error to call this
// method if the hasher doesn't have any nodes.
func (ch *ConsistentHasher) FindNodeFor(item string) string {
if len(ch.nodes) == 0 {
panic("FindNodeFor called when ConsistentHasher has no nodes")
}
ih := hashItem(item, ch.ringSize)
// Since ch.slots is a sorted list of all the node indices for our nodes, a
// binary search is what we need here. ih is mapped to the node that has the
// same or the next larger node index. slices.BinarySearch does exactly this,
// by returning the index where the value would be inserted.
slotIndex, _ := slices.BinarySearch(ch.slots, ih)
// When the returned index is len(slots), it means the search wrapped
// around.
if slotIndex == len(ch.slots) {
slotIndex = 0
}
return ch.nodes[slotIndex]
}핵심은 이진 탐색 호출이다. 노드 추가/삭제도 마찬가지로 이진 탐색으로 수행한다. 전체 코드를 보라.
일관 해싱 구현에서 자주 발생하는 문제는 서로 다른 노드들에 아이템이 불균형하게 분배되는 것이다. _M_개의 아이템과 총 _N_개의 노드가 있으면, 노드당 평균 분배는 대략 이지만 실제로는 그리 균형적이지 않다. 어떤 노드에는 다른 노드보다 훨씬 많은 아이템이 할당될 수 있다(자세한 내용은 Appendix 참고).
실제 애플리케이션에서는 일부 캐시 서버가 다른 서버보다 훨씬 바빠질 수 있음을 뜻하며, 이는 용량 계획과 HW의 효율적 사용 측면에서 좋지 않다. 다행히 이 문제를 크게 완화하는 일관 해싱의 우아한 수정이 있다: 가상 노드(virtual nodes).
각 노드를 원 위의 단일 위치에 매핑하는 대신, _V_개의 위치에 매핑하자. 방법은 여러 가지가 있는데, 가장 단순한 방법은 노드 이름을 약간 변형하는 것이다. 예를 들어 AddNode가 node를 추가할 때 다음을 수행한다:
for i := range V {
vnodeName = fmt.Sprintf("%v@%v", node, i)
// ... now add vnodeName to the nodes/slots slices
}그런 다음 아이템을 조회할 때 가상 노드 중 하나를 만나게 되고, 그 이름에서 실제 노드 이름을 디코드(이 예시에서는 @<number> 접미사를 제거)하여 반환한다. 노드 제거도 비슷하게 간단하게 구현할 수 있다.
아이디어는 foo라는 노드가 있을 때, 가상 노드 이름 foo@0, foo@1, foo@2 등이 원 전체에 걸쳐 퍼지며 한 곳에 뭉치지 않는다는 것이다. 이것이 최종 분포에 어떤 영향을 주는지는 Appendix의 계산을 보라.
이 글의 소스 코드는 ConsistentHasher와 매우 비슷하지만 가상 노드 전략을 구현한 ConsistentHasherV 타입을 포함한다. 사용자 인터페이스는 완전히 동일하며, 내부 구현만 약간 달라진다.
이 글의 전체 소스 코드는 GitHub에 있다.
원 위에서 노드를 잘 섞기 위해 해시 함수의 품질은 매우 중요하지만, 균일 분포 값을 만들어 내는 완벽한 해시 함수를 사용하더라도 결과는 우리가 원하는 요구에 비해 최적이 아닐 수 있다.
단위원 위에서 [0, 1) 범위에 균일하게 N개의 점을 선택한다고 하자. 점들을 각도 순으로 정렬하면, 이웃한 각도 사이의 간격은 순서통계량(order statistics)이다. 이는 매개변수 (1, N-1)의 베타 분포(Beta distribution)를 따르며, 평균은 이고 분산은 이다.
이는 꽤 의미가 크다. 20개의 노드가 있는 원을 생각해 보자. 분포의 표준편차는 분산의 제곱근이다. N=20을 대입하면:
20개의 노드가 원 둘레에 균일하게 분포한다면, 두 노드 사이의 평균 거리는 18도 정도일 것으로 기대할 수 있다. 표준편차 0.048은 17도에 해당하는데, 이는 평균과 비슷한 수준이다!
이를 보여주는 현실적인 예시도 만들 수 있다. 원 위에서 20개의 랜덤 각도를 생성하고 노드 분포가 어떻게 보이는지 확인해 보자:
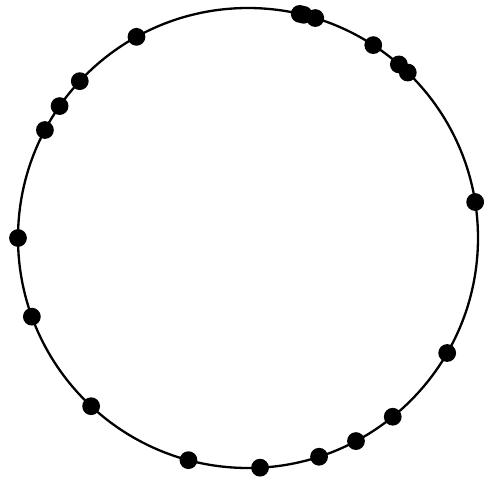 이 샘플에서는 인접 노드 사이 평균 각도는 18도(예상대로)다. 가장 작은 각도는 1.04도에 불과하고, 가장 큰 각도는 42도다. 이는 어떤 노드는 다른 노드보다 40배나 많은 아이템을 할당받을 수 있음을 뜻한다!
이 샘플에서는 인접 노드 사이 평균 각도는 18도(예상대로)다. 가장 작은 각도는 1.04도에 불과하고, 가장 큰 각도는 42도다. 이는 어떤 노드는 다른 노드보다 40배나 많은 아이템을 할당받을 수 있음을 뜻한다!
가상 노드가 어떻게 도움이 되는지는 쉽게 볼 수 있다. 각 서버가 원 위에 랜덤하게 분포한 여러 개의 노드에 매핑된다고 상상해 보자. 이들 중 일부는 가장 가까운 이웃과의 거리가 더 멀겠지만, 평균은 훨씬 변동이 작아진다. 수학적으로, 분산이 _v_인 균일 분포 랜덤 변수 _n_개의 평균의 분산은 이다.
구체적인 실험으로, 위와 비슷한 시뮬레이션을 노드당 10개의 가상 노드를 두고 수행해 보았다. 어떤 노드가 자신의 가상 노드 중 하나에 매핑될 때 그 노드가 담당하는 원의 전체 구간을 고려한다. 평균은 여전히 18도이지만, 분산은 크게 줄어든다. 가장 작은 값은 11도, 가장 큰 값은 26도다.
이 실험의 코드는 소스 코드 저장소의 demo.go 파일에서 찾을 수 있다.
[1]이는 MIT 연구자들이 일관 캐싱을 개발한 원래 동기와 가깝다. 그들의 연구는 "Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web" 논문에 설명되어 있으며, Akamai Technologies의 기반이 되었다.
분산 시스템에서 일관 해싱의 다른 사용 사례도 있다. AWS는 "Dynamo: Amazon’s Highly Available Key-value Store" 논문에서 흔한 응용을 대중화했는데, 여기서는 이 알고리즘을 서버들에 저장 키를 분산하는 데 사용한다.
[2]실제 애플리케이션에서는 아마 다른 해시 함수를 찾고 싶을 것이다. md5는 비교적 느리고, 이 사용 사례에서는 암호학적 보장도 필요 없다. 그렇다고 해도 선택한 해시 함수는 적합해야 하며, 약간만 다른 아이템(예: "node-1" vs. "node-2")에 대해서도 비트를 잘 섞어 주어야 한다. 예를 들어 Go 내장 hash/fnv 패키지는 이 목적에 그리 좋지 않다는 것을 확인했다.
[3]선형 구간 대신 원을 쓰는 이유는 경계 조건을 편리하게 다루기 위해서다. 이는 순진한 해싱 접근에서 모듈러 산술을 사용하는 것과 유사하다.
[4]성능 비교는 굳이 하지 않았지만, 배열 기반 접근이 상대적으로 캐시 친화적이어서 조회에서는 더 빠를 것이라고 추측한다. 삽입/삭제에서는 배열 접근이 O(n)이고 트리는 O()이지만, 조회 성능이 훨씬 더 중요하다고 가정해도 안전하다. 노드는 자주 바뀌지 않고, 조회는 그보다 훨씬 더 자주 일어난다.
댓글은 이메일로 보내 달라.
© 2003-2026 Eli Bendersky