Intel 매뉴얼에 추가된 비휘발성 메모리용 새 명령어 CLWB와 PCOMMIT이 등장한 배경과, 캐시 계층 및 OS 오버헤드가 초고속 NVRAM에서 어떤 문제가 되는지, 그리고 이 명령어들이 이를 어떻게 완화하려 하는지 살펴본다.
최신 버전의 Intel 매뉴얼에는 SSD 같은 비휘발성 스토리지를 위한 새 명령어 몇 가지가 추가됐다. 이게 무슨 얘기일까?
명령어들을 자세히 보기 전에, 초고속 NVRAM에서 존재하는 이슈들을 먼저 보자. 한 가지 문제는 차세대 스토리지 기술(PCM, 3d XPoint 등)이 충분히 빨라져서, syscall과 기타 OS 오버헤드가 실제 디스크 접근 비용보다 더 비싸질 수 있다는 점이다1. 또 다른 문제는 x86 메모리 계층과 영속 메모리 사이의 임피던스 불일치다. 두 경우 모두, 한 구성 요소가 너무 크게 개선되어 다른 구성 요소들도 따라잡기 위해 개선되어야 하는, 기본적으로 Amdahl의 법칙 문제다.
첫 번째 이슈에 대해서는 Todor Mollov, Louis Eisner, Arup De, Joel Coburn, Steven Swanson의 좋은 논문이 있다. 아래에 그들의 그래프 중 하나를 제시한다.
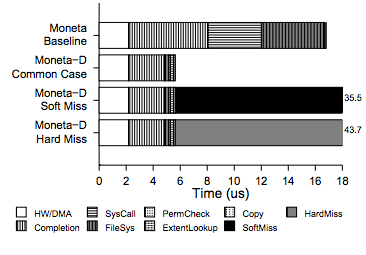
모든 곳에 “Moneta”라고 적혀 있는 건 그게 그들의 시스템 이름이기 때문이다(그런데 꽤 멋지다; 어떻게 했는지 보려면 논문을 읽어보길 권한다). 그들의 “baseline” 경우는 기본 시스템(stock system)에서 얻을 수 있는 것보다 훨씬 낫다. 여러 최적화를 했는데(예: Linux의 IO 스케줄러를 우회하고 가능한 경우 컨텍스트 스위치를 제거), 그 결과 평범한 linux 대비 지연 시간을 62% 줄였다. 그럼에도 트랜잭션의 하드웨어 + DMA 비용(막대의 흰 부분)은 오버헤드에 비해 훨씬 작다. DMA 비용을 하드웨어 오버헤드의 일부로 간주한다는 점에 유의하라.
그들은 OS를 완전히 우회해서 오버헤드의 상당 부분을 줄일 수 있지만, 쓰기 비용의 대부분이 오버헤드라는 사실은 여전히 맞다.
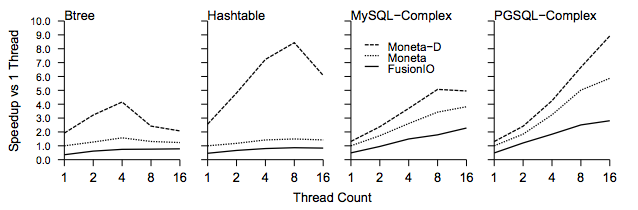
모든 오버헤드를 제거할 수는 없지만, 작은 마이크로벤치마크와 실제 코드 모두에서 꽤 큰 속도 향상을 얻는다. 이것이 한 가지 문제다. I/O 장치가 정말 빠를 때 OS는 I/O에 꽤 큰 세금을 부과한다.
아마도 NVRAM 장치를 메모리 영역에 매핑하고 필요할 때마다 그곳에 커밋하는 방식으로 이 문제의 상당 부분을 우회할 수 있을지도 모른다. 하지만 그러면 또 다른 문제에 부딪히는데, 트랜잭션 의미론 같은 것을 원할 때 캐시가 NVRAM 영역과 상호작용하는 방식과의 임피던스 불일치다.
이는 Kumud Bhandari, Dhruva R. Chakrabarti, Hans-J. Boehm의 이 보고서에 더 자세히 설명되어 있다. 여기에서도 그들의 그림 몇 개를 빌려오겠다.
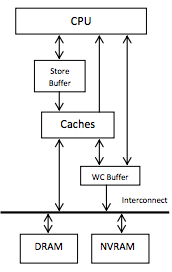
안전하고 영속적인 NVRAM 영역이 있지만, CPU가 거기에 도달하기 전에 서로 다른 순서 보장(ordering guarantee)을 가진 여러 계층을 거쳐야 한다. 그들은 다음 예를 든다:
예를 들어, 영속 메모리 위치 N을 할당하고 초기화한 다음, 할당된 주소를 전역 영속 포인터 p에 대입하여 공개(publish)하는 흔한 프로그래밍 관용구를 생각해 보자. 전역 포인터에 대한 대입이 초기화보다 먼저 NVRAM에서 가시화된다면(아마도 초기화는 캐시되어 NVRAM까지 아직 도달하지 않았기 때문일 것이다), 그리고 바로 그 지점에서 프로그램이 크래시한다면, 재시작 후 영속 포인터를 역참조할 때 초기화되지 않은 데이터를 읽게 된다. writeback (WB) 캐싱 모드를 가정하면, 전역 영속 포인터 p에 대입하기 전에 새로 할당된 영속 위치 N에 대해 캐시 라인 플러시를 삽입함으로써 이를 피할 수 있다.
여기저기 CLFLUSH 명령어를 넣는 방식은 동작하긴 하지만, 그 오버헤드는 어느 정도일까?
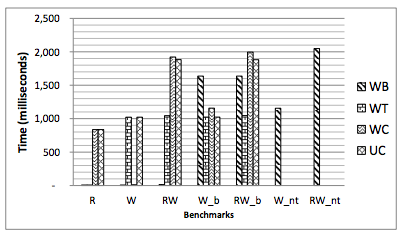
그들이 살펴본 네 가지 메모리 타입(그리고 x86이 지원하는 네 가지)은 writeback (WB), writethrough (WT), write combine (WC), uncacheable (UC)이다. WB는 보통 상황에서 다루는 그것이다. 메모리는 캐시될 수 있고, 강제될 때마다 writeback된다. WT는 메모리가 캐시될 수는 있지만 쓰기는 곧바로 메모리에 써야 한다. 즉, 메모리는 캐시와 함께 최신 상태로 유지된다. UC는 아예 캐시될 수 없다. WC는 UC와 비슷하지만, 쓰기가 메모리로 나가기 전에 병합(coalesce)될 수 있다.
R, W, RW 벤치마크는 그저 메모리를 읽고 쓰는 벤치마크다. WB가 압도적으로 최고임이 분명하다(낮을수록 좋다). WB가 다른 정책들보다 얼마나 나은지 직관을 얻고 싶다면, WB 메모리가 아닌 것으로 OS를 부팅해보면 된다.
나는 예전에 칩 회사에서 일했기 때문에 가끔 그렇게 해야 했다. 처음 칩이 돌아왔을 때는 버그를 우회하기 위해 어떤 비트를 꺼야 하는지 모르는 경우가 흔했다. 진행을 위해 가장 단순한 방법은 캐시를 아예 꺼버리는 것인 경우가 많다. 그렇게 하면 “동작”은 하지만, DOS 같은 최소한의 OS조차도 WB 메모리 없이 부팅하면 눈에 띄게 느리다. 내 기억으로는 Win 3.1은 대부분 한 시간이 걸렸고, Win 95는 여러 시간이 걸리는 과정이었다.
_b 벤치마크는 쓰기가 메모리에 가시화되도록 강제한다. WB의 경우 이는 MFENCE 다음 CLFLUSH를 포함한다. 가시성 제약이 있는 WB는 다른 대안들보다 확연히 느리다. 쓰기를 정렬하고 플러시할 필요가 없는 WB에 비해 여러 자릿수(orders of magnitude)의 성능 저하가 발생한다.
그들은 또한 데이터가 영속적으로 가시적이어야 한다는 제약 하에, 몇몇 실제 데이터 구조에 대한 벤치마크도 수행한다.
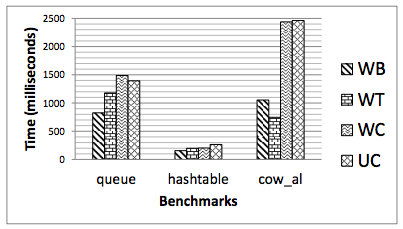
일반 WB 메모리의 성능은 끔찍할 정도로 느려질 수 있다. 캐시 없이 실행하는 성능과 2배 이내까지 느려진다. 그리고 이는 캐시 계층에서 빠져나오기 위한 오버헤드일 뿐이다. 영속 스토리지가 무한히 빠르더라도 마찬가지다.
이제 Intel이 이를 어떻게 해결하기로 했는지 보자. 새 명령어는 CLWB와 PCOMMIT 두 가지다.
CLWB는 CLFLUSH처럼 데이터가 메모리로 써지도록 강제한다. 하지만 캐시가 데이터를 버리도록 강제하지는 않기 때문에, 이후의 읽기/쓰기가 훨씬 빨라진다. 또한 CLFLUSH는 MFENCE에 대해서만 순서가 보장되지만, CLWB는 SFENCE에 대해서도 순서가 보장된다. 다음은 CLWB에 대한 그들의 설명이다:
메모리 피연산자로 지정된 선형 주소를 포함하는 캐시 라인을(더티라면) 캐시 일관성 도메인 내의 캐시 계층의 어느 레벨에서든 메모리로 write back한다. 라인은 수정되지 않은 상태로 캐시 계층에 유지될 수 있다. 캐시 계층에 라인을 유지하는 것은 이후 접근에서 캐시 미스를 줄이기 위한 성능 최적화(하드웨어가 힌트로 취급)이다. 하드웨어는 캐시 계층의 어느 레벨에서든 라인을 유지하기로 선택할 수 있으며, 경우에 따라 캐시 계층에서 라인을 무효화할 수도 있다. 소스 피연산자는 바이트 메모리 위치다.
프로세서는 추측적 읽기(speculative read)를 허용하는 메모리 타입(WB, WC, WT 같은)이 할당된 시스템 메모리 영역으로부터 데이터를 추측적으로 가져와(fetch) 캐시할 수 있음에 유의해야 한다. 이러한 추측적 가져오기는 언제든 발생할 수 있으며 명령어 실행에 묶여 있지 않기 때문에, CLWB 명령어는 PREFETCHh 명령어나 어떤 추측적 가져오기 메커니즘에 대해서도 순서가 보장되지 않는다(즉, 해당 캐시 라인을 참조하는 CLWB 명령어의 실행 직전/도중/직후에 데이터가 추측적으로 캐시 라인에 로드될 수 있다).
CLWB 명령어는 store-fencing 연산에 의해서만 순서가 정해진다. 예를 들어, 소프트웨어는 SFENCE, MFENCE, XCHG, 또는 LOCK 접두(prefix)가 붙은 명령어를 사용하여 이전 store들이 write-back에 포함되도록 보장할 수 있다. CLWB 명령어는 다른 CLWB 또는 CLFLUSHOPT 명령어에 의해 순서가 정해질 필요가 없다. CLWB는 동일 주소에 대해 논리 프로세서가 실행한 더 오래된 store들과 암묵적으로 순서가 정해진다.
CLWB의 실행은 PCOMMIT의 실행과 상호작용한다. PCOMMIT 명령어는 메모리에 accepted된 특정 store-to-memory 연산에 대해 동작한다. 더 오래된 store와 동일한 캐시 라인에 대해 CLWB가 실행되면, CLWB 실행이 전역적으로 가시화될 때 그 store는 메모리에 accepted된다.
PCOMMIT은 전체 메모리 범위에 적용되며, 그 메모리 범위의 모든 것이 영속 스토리지에 커밋되었음을 보장한다. 다음은 PCOMMIT에 대한 그들의 설명이다:
PCOMMIT 명령어는 영속 메모리 범위에 대한 특정 store-to-memory 연산을 영속적(전원 장애 보호)으로 만들도록 한다.1 구체적으로 PCOMMIT은 메모리에 accepted된 store들에 적용된다.
모든 store-to-memory 연산은 결국 메모리에 accepted되지만, 다음 항목들은 소프트웨어가 그것들이 accepted되도록 보장하기 위해 취할 수 있는 동작을 명시한다:
write-back(WB) 메모리에 대한 non-temporal store와 uncacheable(UC), write-combining(WC), write-through(WT) 메모리에 대한 모든 store는 전역적으로 가시화되는 즉시 메모리에 accepted된다. 일반적인 write-back(WB) 메모리에 대한 ordinary store가 전역적으로 가시화된 후, 그 store와 같은 캐시 라인에 대해 CLFLUSH, CLFLUSHOPT, 또는 CLWB가 실행되면, CLFLUSH, CLFLUSHOPT 또는 CLWB 실행 자체가 전역적으로 가시화될 때 그 store는 메모리에 accepted된다.
영속 메모리 범위에 대한 store가 메모리에 accepted된 후 PCOMMIT이 실행되면, PCOMMIT이 전역적으로 가시화될 때 그 store는 영속적이 된다. 이는 PCOMMIT의 실행이 전역적으로 가시화된 상태에서 그보다 나중의 영속 메모리 store가 실행된다면, 그 store가 PCOMMIT이 적용되는 store들보다 먼저 영속적이 될 수 없음을 의미한다.
다음 항목들은 PCOMMIT과 다른 연산들 사이의 순서를 자세히 설명한다:
논리 프로세서는 PCOMMIT 실행을 시작하기 전에, (그 논리 프로세서에 의한) 이전 store들과 CLFLUSHOPT 및 CLWB 실행이 전역적으로 가시화되었음을 보장하지 않는다. 이는 소프트웨어가 PCOMMIT을 실행하기 전에, 적절한 펜싱 명령어(예: SFENCE)를 사용하여 이전 store-to-memory 연산과 영속 메모리 범위에 대한 CLFLUSHOPT 및 CLWB 실행이 전역적으로 가시화되도록(그래서 메모리에 accepted되도록) 보장해야 함을 의미한다.
논리 프로세서는 이후 store들을 시작하기 전에 PCOMMIT 실행이 전역적으로 가시화되었음을 보장하지 않는다. 그러한 store들이 PCOMMIT보다 먼저 전역적으로 가시화되지 않아야 하는 소프트웨어(예: 더 젊은 store들이 PCOMMIT에 의해 커밋된 것들보다 먼저 영속적이 되면 안 되기 때문)는 PCOMMIT과 그 이후 store들 사이에 적절한 펜싱 명령어(예: SFENCE)를 사용하여 이를 보장할 수 있다.
PCOMMIT 실행은 SFENCE, MFENCE, XCHG 또는 LOCK 접두가 붙은 명령어, 그리고 직렬화(serializing) 명령어(예: CPUID)의 실행에 대해 순서가 정해진다.
PCOMMIT 실행은 load 연산에 대해서는 순서가 정해지지 않는다. 소프트웨어는 MFENCE를 사용하여 load를 PCOMMIT과 순서화할 수 있다.
PCOMMIT 실행은 명령어 스트림을 직렬화하지 않는다.
CLWB와 PCOMMIT이 실제로 성능을 얼마나 개선할지는 구현에 달려 있다. 이것들을 벤치마크해 보고 성능이 어떤지 보는 것은 흥미로울 것이다. 어쨌든 이는 WB/NVRAM 임피던스 불일치 문제를 해결하려는 시도다. OS 오버헤드 문제를 직접 해결하는 것은 아니지만, 그 문제는 추가 하드웨어 없이도 상당 부분 우회할 수 있다.
이 글이 마음에 들었다면, Broadwell 및 그 이후 Intel 서버 부품에서의 캐시 파티셔닝에 대한 글도 아마 즐길 것이다.
매뉴얼에서 이를 발견하고 알려준 Eric Bron에게, 그리고 오타를 찾아준 Leah Hanson, Nate Rowe, 'unwind'에게 감사를 전한다.
논문이 아직 부족하다면, Zvonimir Bandic이 특정 유형의 NVRAM에서 1.4 us 지연 시간과 700k IOPS를 달성하는 것에 관한 Dejan Vučinić, Qingbo Wang, Cyril Guyot, Robert Mateescu, Filip Blagojević, Luiz Franca-Neto, Damien Le Moal, Trevor Bunker, Jian Xu, Steven Swanson의 논문을 지적해 주었다.
이 글이 마음에 들었다면, “새로운” CPU 기능에 관한 관련 글도 좋아할지 모른다.