Anthropic의 Claude Opus 4.5 출시와 모델 특성, 가격, 실제 코딩 작업에서의 체감, 그리고 최신 LLM들을 구분해 평가하기 점점 어려워지는 이유와 프롬프트 인젝션 취약성에 대한 논의.
2025년 11월 24일
Anthropic이 오늘 아침 Claude Opus 4.5를 출시했습니다. Anthropic은 이 모델을 “코딩, 에이전트, 컴퓨터 사용에 있어 세계 최고 모델”이라고 부릅니다. 이는 지난 일주일 안에 출시된 OpenAI의 GPT-5.1-Codex-Max와 Google의 Gemini 3가 가한 강력한 도전에 맞서, 다시금 최고 코딩 모델의 왕좌를 되찾으려는 시도입니다!
Opus 4.5의 핵심 특성은 200,000 토큰 컨텍스트(소넷과 동일), 64,000 토큰 출력 한도(이 역시 소넷과 동일), 그리고 2025년 3월의 “신뢰할 수 있는 지식 컷오프”입니다(소넷 4.5는 1월, 하이쿠 4.5는 2월 기준입니다).
가격은 상당한 안도감을 줍니다. 입력 100만 토큰당 5달러, 출력 100만 토큰당 25달러입니다. 이전 Opus의 15달러/75달러보다 훨씬 저렴하며, GPT-5.1 패밀리(1.25달러/10달러)와 Gemini 3 Pro(2달러/12달러, 혹은 200,000 토큰 초과 시 4달러/18달러)에 비해 어느 정도 경쟁력을 갖추게 해 줍니다. 비교를 위해, 소넷 4.5는 3달러/15달러, 하이쿠 4.5는 1달러/5달러입니다.
Opus 4.5가 Opus 4.1 대비 향상된 핵심 요소 문서를 보면 몇 가지 흥미로운 점이 더 나옵니다.
zoom 도구를 Opus 4.5에 제공해, 화면의 특정 영역을 확대해서 살펴보도록 요청하는 식의 사용이 가능합니다.저는 주말 동안 Anthropic의 새 모델 프리뷰에 접근할 수 있었습니다. Claude Code에서 상당 시간을 보냈고, 그 결과 여러 대규모 리팩터링이 포함된 sqlite-utils의 새로운 알파 릴리스가 나왔습니다. Opus 4.5는 이틀 동안 진행된 작업의 대부분을 담당했는데, 그 범위는 20개의 커밋, 39개 파일 변경, 2,022줄 추가 및 1,173줄 삭제에 달했습니다. 여기 제가 Opus 4.5와 함께 새로운 복잡한 기능 중 하나를 구현했던 Claude Code 대화 로그가 있습니다.
모델이 확실히 뛰어난 건 분명하지만, 한 가지 함정을 겪었습니다. 프리뷰 접근 권한이 일요일 오후 8시에 만료되었는데, 그 시점에 알파용 마일스톤에 아직 남아 있던 이슈들이 조금 있었습니다. 저는 Claude Sonnet 4.5로 다시 전환했고... 새 모델을 쓸 때와 마찬가지 속도로 그대로 작업을 이어갔습니다.
돌이켜보면, 이렇게 실제 프로덕션 코딩을 하는 방식은 제가 예상했던 것만큼 새 모델의 강점을 평가하는 데 효과적이지 않았습니다.
새 모델이 소넷 4.5보다 개선되지 않았다는 이야기를 하려는 건 아닙니다. 다만 제가 제시한 과제가 두 모델 간 의미 있는 능력 차이를 드러낼 만큼 충분히 적절했는지에 대해서는 자신 있게 말하기 어렵다는 겁니다.
이건 저에게 점점 커지는 문제를 의미합니다. 제가 AI에서 가장 좋아하는 순간은, 새로운 모델이 이전에는 아예 불가능했던 일을 할 수 있게 해 줄 때입니다. 예전에는 이런 순간이 훨씬 더 분명하게 느껴졌는데, 요즘에는 새로운 세대의 모델과 그 직전 세대를 구분해 주는 구체적인 예시를 찾기가 굉장히 어려운 경우가 많습니다.
Google의 Nano Banana Pro 이미지 생성 모델은 쓸 만한 인포그래픽을 렌더링할 수 있다는 점에서 주목할 만합니다. 이전 모델들은 이 작업에서 사실상 웃음거리 수준으로 형편없었기 때문에, 이건 정말로 새로운 능력이라고 할 수 있습니다.
최전선 LLM들은 서로를 구분하기 훨씬 더 어렵습니다. SWE-bench Verified 같은 벤치마크에서는 모델들이 서로를 몇 퍼센트포인트 차이로 이기곤 하지만, 그게 제가 일상적으로 해결해야 하는 실제 문제에서는 구체적으로 무엇을 의미하는 걸까요?
솔직히 말해, 이건 주로 제 책임이기도 합니다. 저는 최전선 모델들의 현재 능력 바로 너머에 있는 과제들을 모아 놓는 제 컬렉션을 제대로 유지하지 못하고 있습니다. 예전에는 이런 과제가 꽤 많이 있었는데, 모델들이 하나씩 정복해 나가면서 지금은 새 모델 평가에 적합한 도전 과제가 민망할 정도로 부족한 상태가 되어 버렸습니다.
저는 종종 사람들에게, 모델이 실패한 과제들을 노트에 따로 모아 두었다가 나중에 더 새로운 모델들에 다시 시도해 보라고 조언합니다—Ethan Mollick에게서 배운 팁입니다. 저 역시 이 조언을 제 자신에게 훨씬 더 엄격하게 적용해야겠습니다!
Anthropic 같은 AI 연구소들이 이 문제를 직접적으로 해결하는 데 도움을 주었으면 합니다. 새 모델을 릴리스할 때, 이전 세대의 자사 모델로는 처리하지 못했던 과제들을 이제는 해결할 수 있게 되었다는 구체적인 예시를 함께 제공해 주기를 바랍니다.
“이건 소넷 4.5에서는 실패했지만 Opus 4.5에서는 성공한 프롬프트 예시입니다” 같은 사례는, MMLU나 GPQA Diamond처럼 이름 붙은 벤치마크에서 몇 퍼센트 개선되었다는 수치보다 훨씬 더 흥미를 끌 것입니다.
그동안 저는 자전거 타는 펠리컨을 계속 그리게 할 수밖에 없을 것 같습니다. Opus 4.5가 (기본값인 “high” effort 레벨에서) 생성한 이미지는 다음과 같습니다.

보다 자세한 새로운 프롬프트를 사용했을 때는 확실히 더 잘했습니다.

같은 복잡한 프롬프트를 Gemini 3 Pro와 GPT-5.1-Codex-Max-xhigh에 줬을 때의 결과도 참고해 보세요.
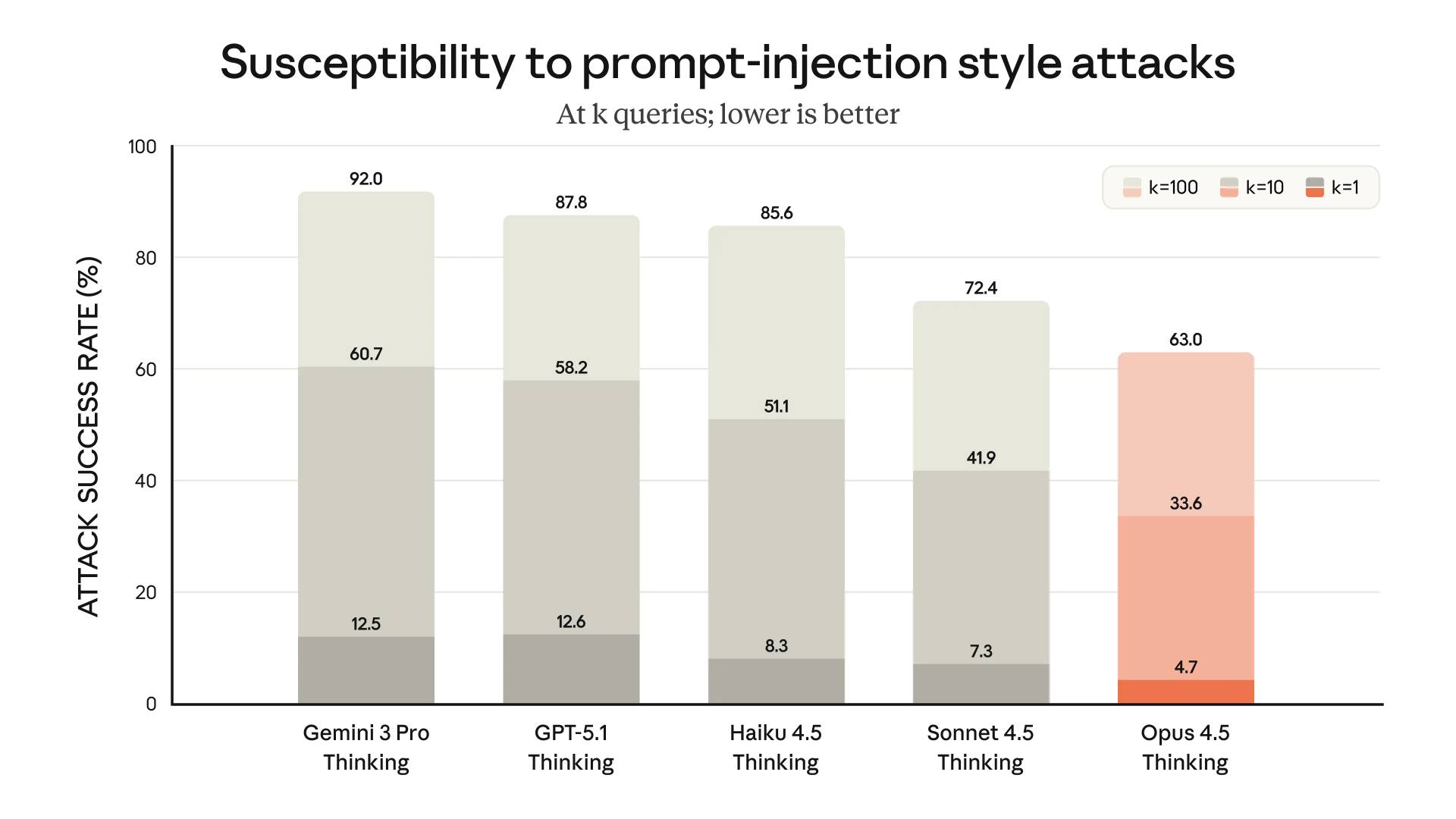
Anthropic 발표 글의 안전 섹션에서는 이렇게 말합니다.
Opus 4.5에서는, 모델을 속여 해로운 행동을 유도하는 기만적 지시를 몰래 심는 프롬프트 인젝션 공격에 대해 견고성을 상당히 끌어올렸습니다. Opus 4.5는 업계의 그 어떤 최전선 모델보다도 프롬프트 인젝션에 속아 넘어가기 더 어렵습니다.
한편으로는 이 결과가 상당히 좋아 보입니다. 이전 모델들과 경쟁 모델들보다 명확한 개선이 있죠.
하지만 이 차트가 실제로 말해 주는 바는 무엇일까요? 단일 시도만으로도 프롬프트 인젝션 공격이 20번에 1번 꼴로 여전히 성공한다는 뜻입니다. 그리고 공격자가 서로 다른 공격을 10번 시도할 수 있다면, 성공률은 3분의 1로 치솟습니다!
저는 여전히, 모델이 프롬프트 인젝션에 속지 않도록 훈련하는 방식이 이 문제의 정답이라고 생각하지 않습니다. 우리는 여전히, 충분히 동기 부여된 공격자라면 어떻게든 모델을 속이는 방법을 찾아낼 수 있다는 전제를 깔고 애플리케이션을 설계해야 한다고 봅니다.