베이지안 통계와 빈도주의 통계의 차이, 사전분포와 사후분포의 의미, 그리고 PyMC와 MCMC를 활용한 실전 적용을 데이터 과학자의 관점에서 설명합니다.
2026년 3월 17일 / 17분 읽기
내가 베이지안의 토끼굴에 빠진 것도 이번이 벌써 세 번째다. 매번 똑같다. 관련된 멋진 글을 하나 발견하고, 마치 마법처럼 느껴지고, 글을 쓰는 사람은 대개 이게 빈도주의보다 얼마나 더 멋진지에 대해 약간 우쭐해 보인다(솔직히 그럴 만도 하다). 그런데도 나는 결국 정확히 무슨 일이 일어나고 있는지는 여전히 헷갈린 채로 나오게 된다. 이 글은 지금까지 읽은 모든 것을 억지로라도 정리해서 이해해 보려는 일종의 카타르시스적 시도이고, 분명 나와 똑같이 느끼는 수많은 사람들에게도 도움이 되기를 바란다.1
빈도주의적 접근은 너무 지배적이어서 통계를 배울 때는 굳이 그런 이름으로 불리지도 않는다. 그냥 통계 그 자체다. 반면 베이지안 접근은 정말 소수만이 엄청나게 좋아하는 이상한 틈새 분야처럼 보인다. 통계의 Haskell 같은 존재다. 그리고 프로그래밍 쪽의 대응물과 마찬가지로, 이 작은 베이지안 부족은 실제로 그걸 그렇게까지 사랑할 만한 이유가 있다.
핵심적으로, 베이지안 통계와 빈도주의 통계의 차이는 확률이 이 틀 안에서 어떤 철학적 역할을 하느냐에 있다. 두 프레임워크 모두에 매개변수가 있고(보통은 어떤 현상이 어떻게 작동하는지를 결정하는 미지의 양들이다), 데이터(또는 관측값)가 있다. 이것은 당신이 측정한 것들이다.
간단한 예로 주사위를 여러 번 굴린다고 해 보자. 여기서 매개변수는 면의 개수 n n n이다(직관적으로 면이 많을수록 특정 면이 나올 확률이 낮아진다는 것을 우리는 안다). 데이터는 그저 주사위를 굴릴 때 관측한 면들의 모음이다. 그런데 이 예제가 조금이라도 말이 되게 하려면 상황을 약간 더 복잡하게 만들어야 한다. 그러니 당신이 DnD나 어떤 주사위 기반 게임을 하고 있는데, 게임 마스터가 커튼 뒤에서 주사위를 굴린다고 해 보자. 그러면 당신은 주사위에 면이 몇 개인지 모른다(게임 마스터가 당신에게 거짓말을 하고 있을 수도 있고 아닐 수도 있다). 당신이 아는 것은 그것이 주사위라는 점과, 굴려서 나온 값들뿐이다. 이 상황에서 빈도주의자는 매개변수 n n n은 고정되어 있고(비록 알 수는 없지만), 데이터는 균등분포 X∼U(n)X \sim \mathcal{U}(n)X∼U(n)에서 무작위로 추출된 것이라고 말할 것이다. 반면 베이지안은 매개변수 n n n 자체도 또 다른 분포 P P P에서 뽑힌 확률변수이며, 그 자체의 불확실성을 가지고 있고, 데이터는 그 분포가 실제로 무엇인지를 알려준다고 말할 것이다.
 여기서 잠시 멈추고, 이게 말이 안 된다고 화면에 대고 소리칠 시간을 드리겠다. 당연히 면의 개수는 고정되어 있다. 주사위니까! 베이지안 통계가 분포 P P P로 정량화하는 것은 면의 개수가 얼마나 무작위적인지가 아니라, 그것에 대해 당신이 얼마나 불확실한지이다. 이것이 핵심적인 차이이며 베이지안 통계가 강력한 이유 전체이기도 하다. 빈도주의적 접근에서 불확실성은 종종 사후적으로 덧붙이는 것에 가깝다. 표본에서 모집단으로 가는 어떤 공식을 나중에 가져다 붙이는 식이다. 좀 있어 보이고 싶다면 부트스트래핑 같은 방법을 쓸 수도 있다. 그리고 그렇게 얻는 구간은 _신뢰구간_인데, 그것은 매개변수가 그 안에 있을 가능성을 말해 주는 것이 아니라, 그런 방식으로 구성한 구간들이 얼마나 자주 실제 매개변수를 포함하는지를 말해 준다. 이 지점은 자주 혼동되기 때문에 신뢰구간은 매우 오해받는 개념이 되곤 한다. 반면 베이지안 통계에서는 매개변수는 하나의 _점_이 아니라 하나의 _분포_다. 그 분포의 퍼짐 자체가 이미 매개변수에 대한 불확실성을 반영하고 있고, 거기서 얻는 _신용구간_은 실제로 매개변수가 그 안에 있을 가능성을 말해 준다.
여기서 잠시 멈추고, 이게 말이 안 된다고 화면에 대고 소리칠 시간을 드리겠다. 당연히 면의 개수는 고정되어 있다. 주사위니까! 베이지안 통계가 분포 P P P로 정량화하는 것은 면의 개수가 얼마나 무작위적인지가 아니라, 그것에 대해 당신이 얼마나 불확실한지이다. 이것이 핵심적인 차이이며 베이지안 통계가 강력한 이유 전체이기도 하다. 빈도주의적 접근에서 불확실성은 종종 사후적으로 덧붙이는 것에 가깝다. 표본에서 모집단으로 가는 어떤 공식을 나중에 가져다 붙이는 식이다. 좀 있어 보이고 싶다면 부트스트래핑 같은 방법을 쓸 수도 있다. 그리고 그렇게 얻는 구간은 _신뢰구간_인데, 그것은 매개변수가 그 안에 있을 가능성을 말해 주는 것이 아니라, 그런 방식으로 구성한 구간들이 얼마나 자주 실제 매개변수를 포함하는지를 말해 준다. 이 지점은 자주 혼동되기 때문에 신뢰구간은 매우 오해받는 개념이 되곤 한다. 반면 베이지안 통계에서는 매개변수는 하나의 _점_이 아니라 하나의 _분포_다. 그 분포의 퍼짐 자체가 이미 매개변수에 대한 불확실성을 반영하고 있고, 거기서 얻는 _신용구간_은 실제로 매개변수가 그 안에 있을 가능성을 말해 준다.
좀 더 수학적으로 말하면, 두 접근의 차이는 베이즈의 유명한 정리에서 드러난다. 이 정리는 조건부확률들이 서로 어떻게 연결되는지를 알려준다:
P(A∣B)P(B)=P(B∣A)P(A). P(A|B)P(B) = P(B|A)P(A)~.P(A∣B)P(B)=P(B∣A)P(A). 그게 전부다! 이 식에 매개변수 θ\theta θ와 데이터 X X X를 넣으면 , 즉 베이지안 추론의 초석이 되는 식을 얻는다. 이게 당장 유용해 보이지는 않을 수도 있지만, 정말로 유용하다. 기억하자. X X X는 단지 관측값들의 모음이고, θ\theta θ는 모델을 매개변수화하는 것이다. 그래서 P(X∣θ)P(X|\theta)P(X∣θ), 즉 _우도_는 어떤 매개변수 실현값이 주어졌을 때 지금 가지고 있는 데이터를 볼 가능성이 얼마나 되는지를 뜻한다. 한편 P(θ)P(\theta)P(θ), 즉 _사전분포_는 매개변수가 어떤 모습일 것이라는 직관이다. 이것에 대해서는 다시 돌아오겠지만, 보통은 당신이 선택하는 것이다. 마지막으로 P(X)P(X)P(X)는 정규화 상수라고 생각하면 되고, 베이지안 추론에서 사람들이 하는 주요한 일 중 하나는 문자 그대로 이걸 계산하지 않아도 되도록 가능한 모든 것을 하는 것이다! 목표는 물론 사후분포 P(θ∣X)P(\theta|X)P(θ∣X)를 추정하는 것이고, 이것은 매개변수가 어떤 _분포_를 취하는지를 알려준다. 사후분포가 유용한 이유는
이제 작은 주사위 굴리기 예제로 돌아가 보자. 다음과 같은 값들을 해당 빈도와 함께 관측했다고 하자:
| Value | Count | Frequency |
|---|---|---|
| 1 | 2 | 0.250 |
| 2 | 1 | 0.125 |
| 3 | 2 | 0.250 |
| 4 | 3 | 0.375 |
당신이 빈도주의자라면, 면의 개수에 대한 _최대우도추정_을 찾으려 할 것이다. 이것은 본질적으로 위에서 소개한 항 P(X∣θ)P(X|\theta)P(X∣θ)를 최대화하는 것이다. 잠깐 이것을 따라가 보자. 주사위가 n n n개의 면을 가진다면 X∼U(n)X \sim \mathcal U(n)X∼U(n)이고, 정확히 이 데이터를 관측할 확률은
이다. 이것은 n n n이 가능한 한 가장 작은 값일 때 분명히 최대가 된다. 여기서는 4다(면이 3개인 주사위로는 4를 뽑을 수 없기 때문이다). 여기까지는 꽤 쉽지만, 신뢰구간은 또 다른 문제이고, “덧붙이기”라는 생각을 꽤 잘 보여 준다. 그것을 구하는 한 가지 방법은 P(X m a x≤4∣n)≥α/2 P(X_{\mathrm{max}} \leq 4 | n) \geq \alpha/2 P(X max≤4∣n)≥α/2를 만족하는 모든 n n n 값을 찾는 것이다. 여기서 α\alpha α는 신뢰수준이다(보통 5%로 잡는다). 주어진 n n n에 대해 이 확률은 (4 n)8\left(\frac{4}{n}\right)^8(n 4)8와 같고, 따라서 [4,6][4,6][4,6] 형태의 CI를 얻는다. 자, 이렇게 된다
이제 베이지안 모자를 쓰고 무엇을 할 수 있는지 보자. 우선, k k k개의 관측값이 있을 때 임을 이미 보았다(여기서는 k=8 k=8 k=8). 그러니 우도는 준비되었다. 내가 앞서 말했듯이 _사전분포_는 당신이 선택하는 것이다. 기본적으로는 매개변수가 따를 법하다고 생각하는 어떤 분포를 정해야 한다. 하지만 꼭 완벽할 필요는 없다. 합리적이기만 하면 된다! 사전분포가 하는 일은 대체로 초기 정보, 일종의 부스트를 베이지안 모델링에 제공하는 것이다. 유일하게 주의해야 할 점은 관련 있을 수 있다고 생각하는 모든 값에 지지를 주는 것이다(그러니 항상 비교적 넓은 분포를 고르는 편이 좋다). 예를 들어 여기서는 아주 비정보적인 사전분포를 고르겠다. 인 균등분포인데, n∈[4,N+3]n \in [4, N+3]n∈[4,N+3]이고 어떤 매우 큰 N N N(예를 들어 100)에 대해 정의된다. 그러면 베이즈 정리를 사용해 사후분포는 가 된다. 기호 ∝\propto∝는 정규화 상수를 제외하면 참이라는 뜻이므로, 전체 분포를 다음과 같이 다시 쓸 수 있다.
여기서 분모는 Hurwitz zeta function이라고 불리며, 빠르게 수렴하는 급수다. 이 단계에서 베이지안 통계학자는 분포의 최대값으로 주어지는 최대 사후확률 추정 (MAP)을 계산할 것이고(이는 n=4 n = 4 n=4에서 달성된다), 또는 평균 을 계산할 것이다. 이제 신용구간은 사후분포의 누적분포함수 를 보고, 전체 확률질량의 95%를 덮는 [4,n R][4, n_R][4,n R] 값을 찾으면 된다. 이 문제에서는 몇 개 값만 계산해 보고 어디서 멈추는지 보면 충분하고, 그 결과 [4,5] 구간이 나온다:
| n | F(n) |
|---|---|
| 4 | 0.816 |
| 5 | 0.953 |
| 6 | 0.985 |
따라서 이 결과는 빈도주의 접근과 꽤 잘 일치하며, 여기서의 불확실성은 다음의 결과로 해석할 수 있다.
우도와 사전분포가 모두 거의 정보를 주지 못한다면, 사후분포는 매우 불확실해질 것이다. 이것은 문제에 대한 어떤 지식을 포함한 다른 사전분포를 사용하면 도움이 될 수 있음을 보여 주는 완벽한 예다. n n n은 4에 가까울 법한 정수이므로, 나는 기하분포를 사전분포로 사용하겠다. 즉 n∼3+G e o m(q)n \sim 3 + \mathrm{Geom}(q)n∼3+Geom(q), 여기서 q=0.5 q = 0.5 q=0.5이다. 아래 코드 조각에서는 pymc를 사용해 이것을 수치적으로 계산하고, 과 신용구간 [4,5][4, 5][4,5]를 얻는다. 구간은 같지만 중요한 것은 분포가 4에 더 가까워지고 있다는 점이다(평균을 보라). 이는 우리의 불확실성이 줄어들고 있음을 보여 준다.
import pymc as pmimport numpy as npimport arviz as azimport matplotlib.pyplot as plt
# Observationsobservations = np.array([1, 1, 2, 3, 3, 4, 4, 4])k = len(observations)x_max = int(observations.max())
with pm.Model() as model: # Geometric prior on excess faces beyond x_max excess = pm.Geometric("excess", p=0.5) - 1 # 0, 1, 2, ... n = pm.Deterministic("n", excess + x_max)
# Likelihood: (1/n)^k, valid by construction since n >= x_max pm.Potential("likelihood", -k * pm.math.log(n))
# Use NUTS sampler with target_accept=0.9 for discrete variables trace = pm.sample(10000, tune=2000, chains=4)
posterior_n = trace.posterior["n"].values.flatten()hdi = az.hdi(trace, var_names=["n"], hdi_prob=0.95)
print(f"Posterior mean: {posterior_n.mean():.2f}")print(f"95% HDI: {hdi['n'].values}")
그런데 아까는 사전분포가 중요하지 않다고 했잖아. 분명 중요하잖아!
맞다. 이것은 베이지안 통계의 아주 중요한 측면이다. 사후분포는 사전분포에 직접 의존하므로, 당연히 어느 정도 영향을 받는다. 하지만 데이터가 많아질수록 사후분포는 우도 항에 의해 더 크게 결정된다. 이는 특히 “넓은” 사전분포(넓은 Gaussian, 균등분포 등)를 택했을 때 그렇다. 이유는 데이터가 많아질수록 우도가 더 많은 구조, 즉 국소적인 봉우리를 갖게 되기 때문이다. 이것을 사전분포와 곱하면, 사전분포의 평평한 부분은 이 봉우리들을 거의 교란하지 못하고, 그 구조가 사후분포에도 그대로 남는다. 하지만 데이터가 적으면 반대 일이 일어나고, 사전분포의 모습이 사후 데이터에 더 많이 반영된다. 이것이 베이지안 통계의 강점 중 하나다. 사전분포는 데이터 부족을 보완하기 위해 존재하고, 충분한 데이터가 있으면 조용히 뒤로 물러난다.3
요약: 빈도주의 통계는 매개변수는 고정되어 있고 데이터는 무작위라고 보는 반면, 베이지안 통계는 그 반대로 본다. 이것은 대체로 해석의 차이지만, 프레임워크 자체에도 실제로 영향을 준다. 베이지안 통계는 표본 데이터에 내재된 불확실성을 모델링하는 데 특히 잘 맞는다.
앞 절이 다소 지루하게 느껴졌다면 정상이다. 보통 위와 같은 단순한 예제에서는 베이지안 통계가 그다지 유용하게 느껴지지 않고, 프레임워크를 바꾸는 복잡성이 그만한 가치가 있어 보이지 않는다. 하지만 현실에서는 그런 상황이 거의 그대로 나타나지 않는다. 최근 나는 사전분포와 우도 모델링 사이의 절충이 매우 흥미로운 방식으로 드러나는 훨씬 더 재미있는 사용 사례를 접했다.
당신이 소매 회사라고 상상해 보자. 그리고 과거 데이터를 기반으로 판매 주문을 나타내는 합성 데이터를 생성하고 싶다. 이때 꽤 어려운 점 중 하나는 합성 데이터를 지리적으로 어떻게 분포시킬 것인가이다. 가장 단순한 접근은 각 주문에 대해 과거에 유사한 주문이 얼마나 자주 발생했는지를 바탕으로 무작위 위치(예를 들어 우편번호)를 뽑는 것이다. 지금은 유사하다는 말이 단순히 같은 카테고리이거나 같은 채널(오프라인 매장, 온라인 등)에서 판매되었다는 뜻일 수 있다. 이 문제에 대한 빈도주의적 접근은 보통 선택한 그룹핑에 따라 과거 데이터를 클러스터링한 뒤, 데이터 내 판매 횟수를 이용해 각 클러스터별 우편번호 분포를 추정하는 것에서 시작한다. 카테고리별로 카운트를 정규화하면 조건부확률분포 를 얻을 수 있고, 거기서 표본을 뽑으면 된다.
이것은 완전히 타당한 접근이지만 문제도 있다. 예를 들어 새로운 카테고리나 새로운 우편번호에는 그다지 강건하지 않다. 마찬가지로 데이터가 희소하면 추정된 분포는 꽤 잡음이 심할 수 있다. 데이터 과학에서는 이런 상황에 보통 특별한 정규화 기법이 필요하다. 베이지안 접근에서는 우편번호의 과거 분포가 우도를 제어한다(나는 이것을 Dirichlet-Multinomial 분포를 바탕으로 만들었다). 하지만 여전히 사전분포를 제공해야 한다. 앞서 말했듯이, 사전분포는 데이터가 강한 우도를 제공할 만큼 충분히 정확하지 않은 부분을 대신 채운다. 물론 이전 예제와는 달리, 여기서는 비정보적인 사전분포를 쓰고 싶지 않다. 대신 어떤 도메인 지식을 활용하고 싶다. 그렇지 않다면 그냥 빈도주의 접근을 쓰는 편이 낫다. 이 문제에 대한 좋은 사전분포는 인구 기반 분포(또는 판매와 어떤 식으로든 상관이 있는 무엇이든)일 것이다. 핵심은 데이터와 달리 인구 분포는 희소하지 않기 때문에 모든 우편번호가 표본으로 뽑힐 기회를 갖는다는 점이고, 이것이 더 강건한 모델로 이어진다는 것이다. 이렇게 하면 데이터를 최대한 활용하면서도 새로운 지역에 대해서는 사전분포를 일종의 폴백처럼 사용해 자연스럽게 처리하는 모델을 얻게 된다.
이쯤 되면 베이지안 통계가 얼마나 유용할 수 있는지 보이기를 바란다. 하지만 동시에 계산이 다소 까다로울 수 있다는 점도 눈치챘을 것이다. 앞에서는 모든 것이 잘 알려진 수학적 급수로 표현될 수 있어서 운이 좋았다. 일반적으로는 그렇지 않다. 다행히도 이런 작업을 전혀 하지 않고도 사후분포를 찾도록 도와주는 강력한 수치 알고리즘들이 있고, 사실 나는 위에서 Python 패키지 pymc를 이용한 예를 이미 보여 주었다.
이 아이디어는 Markov Chain Monte Carlo (MCMC) 방법에 뿌리를 두고 있다.
사후분포에서 표본을 뽑기 위해서는 몇 가지 MCMC 알고리즘이 있다(pyMC는 the NUTS algorithm을 사용한다). 하지만 여기서는 내가 전에 to solve the Ising spin model에서 사용했던 Metropolis 알고리즘에 초점을 맞추겠다. 알고리즘은 매개변수 공간의 어떤 점 θ 0\theta_0 θ 0에서 시작한다. 그리고 각 시간 단계 t t t마다 알고리즘은 새로운 점 θ t+1\theta_{t+1}θ t+1을 제안하고, 이것은 확률 로 수락된다. 이 확률은 사후분포의 비율에만 의존하므로 정규화 항 P(X)P(X)P(X)와는 무관하고, 대신 우도와 사전분포에만 의존한다. 이것은 두 분포 모두 보통 잘 알려져 있고 계산하기 쉽기 때문에 엄청난 장점이다. 알고리즘은 체인이 사후분포에 수렴할 때까지 얼마간 계속되고, 관측된 데이터 점들은 사후분포의 형태를 보여 준다.
pymc에서 이것을 하는 방법은 pm.Model()을 사용해 모델을 정의하는 것이다. pm.Uniform, pm.Normal, pm.Binomial 등으로 사전분포를 정의할 수 있다. 우도를 지정하려면, 닫힌 형태가 있다면 내가 위에서 했듯 pm.Potential로 직접 지정할 수 있고, 그렇지 않다면 분포 메서드들 가운데 하나를 사용해 매개변수 기반 모델을 정의하면서 observed 인수로 관측 데이터를 제공할 수 있다. 마지막으로 pm.sample()을 호출해 MCMC 알고리즘을 실행하고 사후분포에서 표본을 얻을 수 있다. 그런 다음 arviz를 사용해 결과를 분석하고 신용구간, 사후평균 같은 것들을 얻을 수 있다.
예를 들어, 데이터 (x i,y i)(x_i, y_i)(x i,y i)에 대해 선형회귀 모형 를 적합하고 싶다고 하자. 베이지안 접근에서는 먼저 매개변수 a a a, b b b에 대한 사전분포를 정의한다. 모든 매개변수가 연속적인 실수이므로 넓은 Normal 분포 사전분포가 좋은 선택이다. 우도에 대해서는 잔차 에 집중할 수 있고, 이것을 정규분포 로 모델링한다(σ\sigma σ에 대한 사전분포도 제공한다). pymc에서는 다음과 같이 구현할 수 있다:
import pymc as pm
with pm.Model() as model: # Priors a = pm.Normal("a", mu=0, sigma=10) b = pm.Normal("b", mu=0, sigma=10) sigma = pm.HalfNormal("sigma", sigma=10)
# Likelihood y_obs = pm.Normal("y_obs", mu=a * x + b, sigma=sigma, observed=y)
# Sample from the posterior trace = pm.sample(1000, tune=1000, chains=4)
체인이 수렴하면 arviz를 사용해 a a a, b b b, σ\sigma σ에 대한 사후분포를 추출할 수 있다(평균이나 CI를 구하기 위해서다):
import arviz as az
a_mean = trace.posterior["a"].values.mean()b_mean = trace.posterior["b"].values.mean()sigma_mean = trace.posterior["sigma"].values.mean()
이 접근의 멋진 장점 중 하나는 예를 들어 your data has outliers 같은 경우에도 아주 잘 작동한다는 점이다. 이 경우 각 데이터 점에 대해 잡음 매개변수 g i∈[0,1]g_i \in [0,1]g i∈[0,1]를 추가할 수 있다. 이것은 우리의 Gaussian 우도와 훨씬 더 큰 분산을 가진 또 다른 Gaussian 분포 사이를 보간하며, 배경 잡음을 모델링한다. 이렇게 하면 미지의 매개변수 수가 크게 늘어나지만, 그 대신 모든 매개변수에 가중치가 부여되고 모델은 이상치를 쉽게 식별할 수 있다. pymc에서는 다음과 같이 할 수 있다:
with pm.Model() as model: # Priors a = pm.Normal("a", mu=0, sigma=10) b = pm.Normal("b", mu=0, sigma=10)
# Variance of the two mixture Gaussians sigma = pm.HalfNormal("sigma", sigma=10) delta = pm.HalfNormal("delta", sigma=5) sigma_bgd = pm.Deterministic("sigma_bgd", sigma + delta) # For the background variance, ensure it's larger # than the inlier variance by adding a positive delta. # This helps breaking the symmetry between # the two components and allows the model to better identify outliers.
# Mixture weights gs = pm.Beta("gs", alpha=2, beta=2, shape=len(x))
# Likelihood as a weighted mixture
mu = a * x + b w = pm.math.stack([gs, 1 - gs], axis=1) pm.Mixture( "likelihood", w=w, comp_dists=[ pm.Normal.dist(mu=mu, sigma=v), pm.Normal.dist(mu=mu, sigma=sigma_bgd), ], observed=y, )
# Sample from the posterior trace = pm.sample(1000, tune=1000, chains=4)
따라서 g i g_i g i가 1에 가까우면 우도는 회귀 Gaussian에 의해 지배되고, g i g_i g i가 0에 가까우면 혼합분포는 배경 Gaussian 쪽으로 기운다. 아래 그림에서 이 방법이 최소제곱 선형회귀와 어떻게 비교되는지 볼 수 있다.
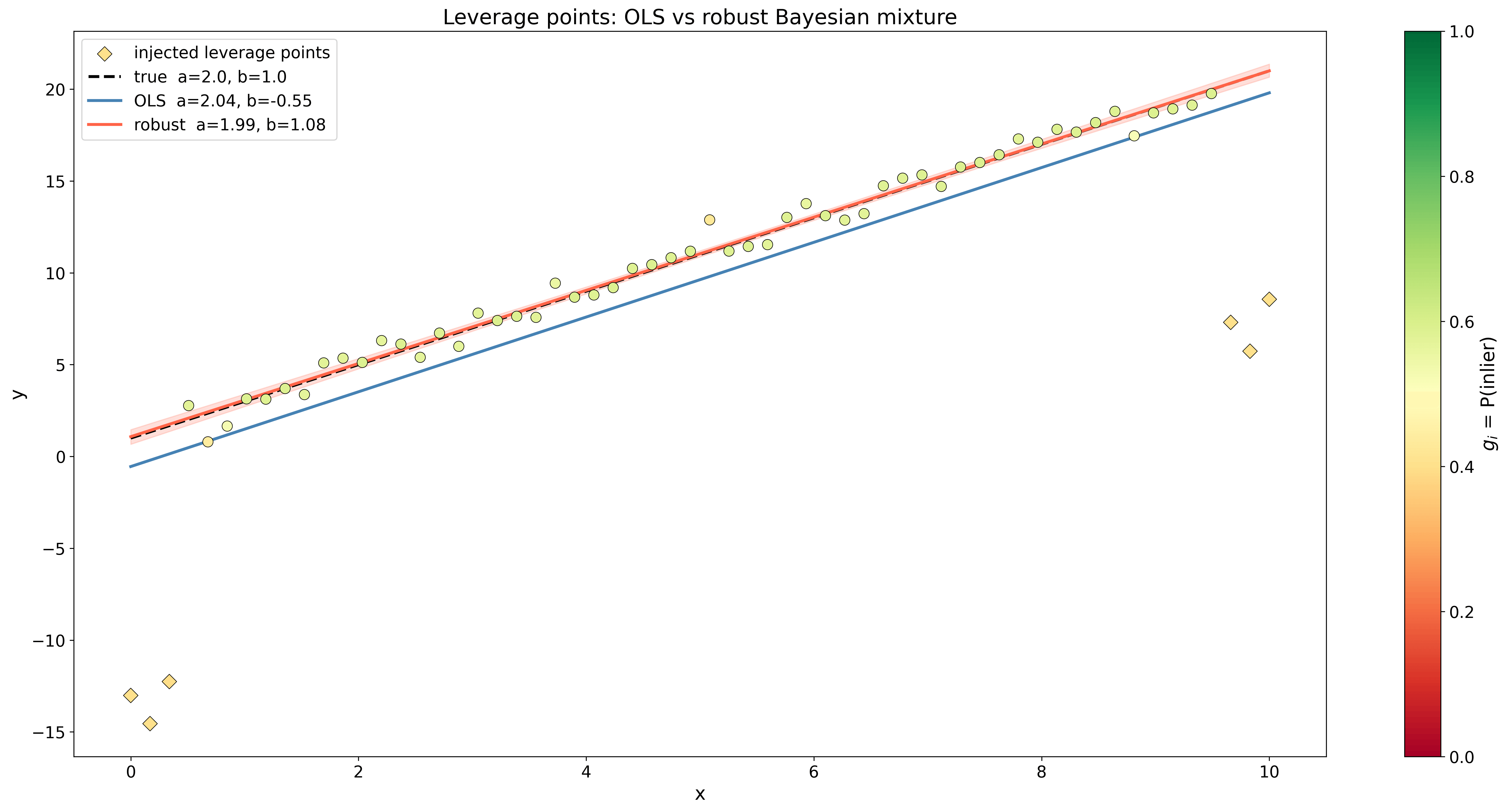 데이터 과학자로서 당신은 아마 Lasso (L1)나 Ridge (L2) 회귀 같은 정규화된 선형회귀로 이런 문제를 푸는 데 익숙할 것이다. 내부적으로 이것은 Laplace 또는 Gaussian 사전분포를 바탕으로 매개변수의 MAP를 찾는 것과 같다. 베이즈 정리의 로그 버전을 회귀 우도와 함께 사용하면, 사후분포를 최대화하는 것은 다음의 최소화 문제가 된다.
데이터 과학자로서 당신은 아마 Lasso (L1)나 Ridge (L2) 회귀 같은 정규화된 선형회귀로 이런 문제를 푸는 데 익숙할 것이다. 내부적으로 이것은 Laplace 또는 Gaussian 사전분포를 바탕으로 매개변수의 MAP를 찾는 것과 같다. 베이즈 정리의 로그 버전을 회귀 우도와 함께 사용하면, 사후분포를 최대화하는 것은 다음의 최소화 문제가 된다.
Gaussian 사전분포 에 대해서는 이고, Laplace 사전분포 에 대해서는 이다. 그러니 결국 이 두 정규화 기법은 단지 서로 다른 베이지안 사전분포 선택이었던 셈이다!
이 글이 베이지안 통계가 어떻게 작동하고 어디에서 빛을 발하는지에 대해 좀 더 나은 감을 주었기를 바란다. 전반적으로 나는 이것이 불확실한 데이터를 적합하는 데 더 나은 프레임워크라고 느낀다. 조금 더 복잡하게 들릴 수는 있지만, 코드 예시에서 보았듯 MCMC 방법은 사전분포와 데이터만으로 복잡한 모델을 아주 쉽게 만들 수 있게 해 준다.
그렇지? 나만 그런 거 아니라고 말해 줘. ↩
사실 여기에는 분포가 이산적이지만 CI가 6과 7 사이에서 끝난다는 점 때문에 다소 성가신 미묘함이 있다. 그래서 반올림을 어떻게 하느냐에 따라 95% CI의 커버리지 문제가 생길 수도 있다. 하지만 여기서는 그냥 넘어가겠다. ↩
관심 있는 사람을 위해 말하자면, 이 진술의 배경에는 Bernstein-von Mises 정리가 있다. 이것은 본질적으로 어떤 극한에서 사후분포가 최대우도추정치(즉 빈도주의적 답) 주변을 중심으로 하고 폭은 줄어드는 정규분포로 수렴한다는 것을 말한다. 같은 극한에서 우도는 사전분포를 압도하고 사후분포를 완전히 지배하게 되어, 베이지안과 빈도주의 접근이 일치하게 된다. ↩
© 2025 Nicolas Chagnet. All rights reserved. Icon created by BZZRINCANTATION - Flaticon.