Superluminal의 Linux 버전에서 발생한 주기적 시스템 프리즈를 추적하며 eBPF 링버퍼와 rqspinlock의 NMI 재진입·타임아웃·기아 문제를 찾아 커널 패치로 해결한 과정.
17 Mar, 2026
|
우리는 CPU 프로파일러인 Superluminal의 Linux 버전을 한동안 개발해 왔고, 소수 테스터 그룹과 함께 비공개 알파를 진행하고 있었습니다. 모든 것이 순조로웠는데, 테스터 중 한 명인 Aras가 Superluminal로 캡처를 수행하는 동안 주기적으로 시스템 전체가 멈추는 현상을 겪기 전까지는 그랬습니다.
우리는 Superluminal이 “그냥 잘 동작(Just Working)”하는 것을 항상 자랑스럽게 생각해 왔고, 이건 분명히 그렇지 않았습니다. 그래서 당연히 우리는 커리어에서 마주한 버그 중 가장 까다로운 것 중 하나가 되어버린 문제를 추적하기 시작했습니다.
추적은 우리를 Linux 커널 내부 깊숙한 곳으로 이끌었고(다시), 커널의 스핀락에 대해 우리가 원했던 예상했던 것보다 훨씬 더 많이 알게 되었으며, 그 과정에서 여러 문제를 찾아 수정하는 데 도움을 줄 수 있었습니다.
그가 겪고 있던 문제는 Fedora 42 머신(커널 6.17.4-200)에서 Superluminal 캡처가 실행 중일 때 시스템이 주기적으로 짧은 시간 동안 멈춘다는 것이었습니다:
이런 이슈를 원격으로 디버깅하는 건 정말 어렵기 때문에, 우리는 먼저 VM에서 재현을 시도했습니다. 하지만 여러 Fedora 버전/커널로 여러 번 시도해도 재현할 수 없었습니다. 결국 물리 머신에 Fedora를 설치해 보았고, 그제서야 재현할 수 있었습니다.
이제 재현이 되니, 본격적으로 문제를 파고들 수 있습니다.
머신이 Superluminal로 캡처 중일 때 주기적으로 멈추고 있으니, 먼저 캡처를 열었을 때 어떤 모습인지부터 볼 수 있습니다. 이런 캡처를 열어보면 다음과 같습니다:
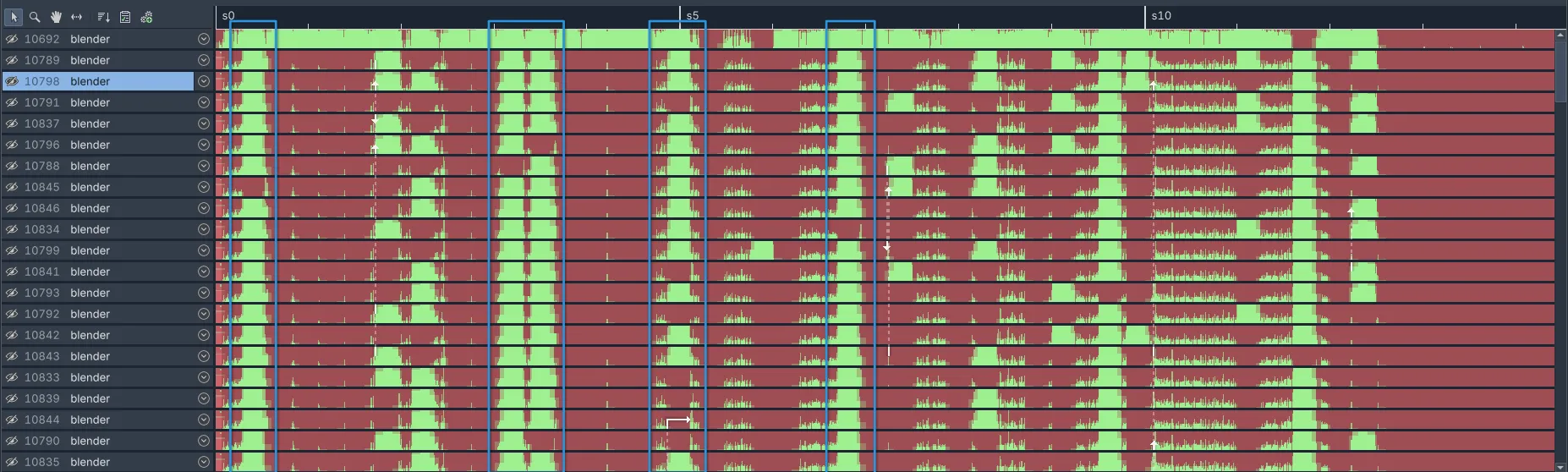 이건 프로세스 내 각 스레드의 타임라인을 보여줍니다. 녹색은 CPU가 실제로 일을 실행 중(즉, 스레드가 스케줄 인됨)임을 의미하고, 다른 색은 스레드가 스케줄 아웃되어 무언가를 기다리고 있음을 의미합니다. 캡처에서 (파란색으로 표시된) 의심스러운 구간을 즉시 발견할 수 있는데, 프로파일링 중인 워크로드와는 맞지 않게 프로세스의 모든 스레드가 거의 같은 시간 동안 바쁘게 보입니다.
이건 프로세스 내 각 스레드의 타임라인을 보여줍니다. 녹색은 CPU가 실제로 일을 실행 중(즉, 스레드가 스케줄 인됨)임을 의미하고, 다른 색은 스레드가 스케줄 아웃되어 무언가를 기다리고 있음을 의미합니다. 캡처에서 (파란색으로 표시된) 의심스러운 구간을 즉시 발견할 수 있는데, 프로파일링 중인 워크로드와는 맞지 않게 프로세스의 모든 스레드가 거의 같은 시간 동안 바쁘게 보입니다.
이 구간 각각은 250ms+ 동안 CPU가 완전히 바쁜 것처럼 보입니다. 이 중 하나를 확대하고 스레드를 펼치면 다음과 같습니다:
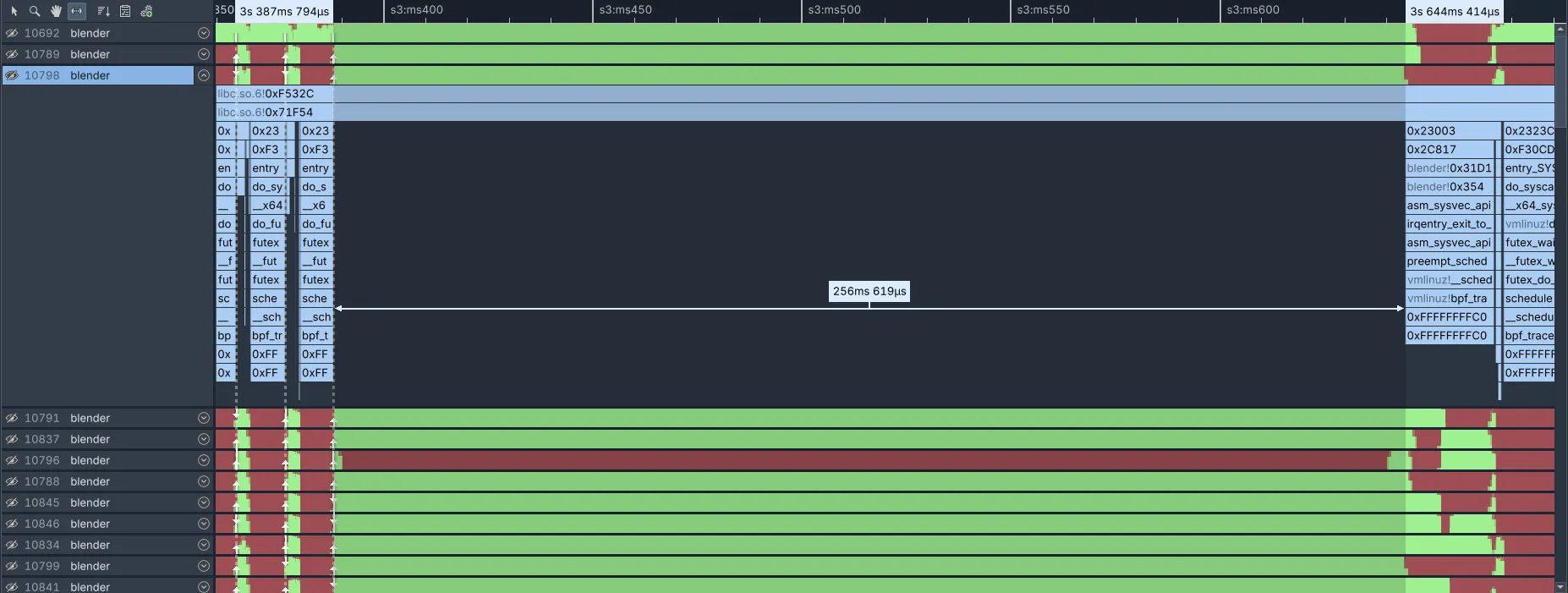 이는 이 스레드가 ‘바쁨’으로 보고되는 동안에도, 해당 기간에는 샘플이 전혀 수집되지 않았음을 나타냅니다. 이 패턴은 모든 스레드에서 동일하게 나타납니다.
이는 이 스레드가 ‘바쁨’으로 보고되는 동안에도, 해당 기간에는 샘플이 전혀 수집되지 않았음을 나타냅니다. 이 패턴은 모든 스레드에서 동일하게 나타납니다.
문제를 재현하면서 dmesg 출력을 보면, Superluminal 자체에서 보고 있던 250ms+와 매우 잘 맞는 다음과 같은 메시지도 얻을 수 있습니다:
[ +0.014286] INFO: NMI handler (perf_event_nmi_handler) took too long to run: 1.723 msecs
[ +0.232451] INFO: NMI handler (perf_event_nmi_handler) took too long to run: 250.424 msecs
[ +0.000001] INFO: NMI handler (perf_event_nmi_handler) took too long to run: 250.424 msecs
[ +0.250938] INFO: NMI handler (perf_event_nmi_handler) took too long to run: 250.936 msecs
즉, 이 모든 것은 CPU가 왜 바쁜지를 알려주진 못합니다(이를 위해서는 콜스택/샘플이 필요합니다). 하지만 커널에서 250ms+ 걸리는 _무언가_가 발생하고 있다는 점은 보여줍니다.
우리는 그게 무엇인지 “그냥” 알아내면 됩니다.
보통 애플리케이션에서 이런 멈춤이 발생하면 원인을 찾기는 비교적 간단합니다. 디버거를 붙이고, 멈춤이 발생할 때 브레이크한 다음, 스레드/스택을 확인하면 됩니다. 하지만 이번에는 커널 프리즈라서 그렇게 간단하지 않습니다.
그런데 이전 변경 작업을 하며 이미 커널을 컴파일하는 법을 배웠습니다. 커스텀 커널이 있으면 커널 디버깅을 켜는 건 꽤 쉽습니다. 커널을 디버깅할 별도의 머신이 필요하긴 하지만, 그건 큰 문제는 아닙니다.
진짜 문제는 우리 머신들에 이런 게 없었다는 점이었습니다:
 특정 세대라면 이걸 보자마자 알아볼 겁니다. TX와 RX 라인을 납땜으로 서로 연결해서 Doom을 멀티플레이로 하던 추억이 있을지도 모르겠네요…
특정 세대라면 이걸 보자마자 알아볼 겁니다. TX와 RX 라인을 납땜으로 서로 연결해서 Doom을 멀티플레이로 하던 추억이 있을지도 모르겠네요…
그렇게 나이가 많지 않다면 (흠): 이건 COM, 즉 시리얼 포트입니다.
예전에는 메인보드에 기본으로 달려 있었지만, 현대 머신에는 보통 더 이상 없습니다. Linux 커널 디버거는 디버거와 디버깅 대상 머신 간 통신에 이를 사용하기 때문에, 두 머신 모두 이런 포트가 필요합니다. 그래서 우리는 위 사진처럼 시리얼 포트 PCIe 카드를 구해야 했습니다.
이제 gdb로 문제 머신에 붙어, 커널로 브레이크인하고 커널 상태를 확인하는 등 기본적인 디버거 명령을 수행할 수 있습니다. 여기서부터 버그를 찾는 건 간단합니다. 프리즈를 재현한 다음, 원격 머신에서 커널로 브레이크인해 무슨 일이 벌어지는지 보면 됩니다.
… 또는 그래야 했습니다. 불행히도 커널이 이 프리즈 상태에 들어가면 디버거조차 더 이상 응답하지 않는 것처럼 보였습니다. 프리즈 중에 브레이크를 걸려던 시도는 모두 gdb가 크래시 나거나 타임아웃 되었고, 이를 동작하게 만들 수 없었습니다.
즉 디버깅은 물 건너갔습니다. 좋네요. 이제 뭘 해야 할까요?
이처럼 어떤 코드가 문제를 일으키는지 전혀 알 수 없을 때는, 가능한 한 최소한의 재현 케이스로 좁혀보는 것이 도움이 됩니다. 그래야 지금처럼 “시스템 전체”가 아니라 (바라건대) 비교적 적은 코드만을 대상으로 추론할 수 있습니다.
Linux에서 우리의 캡처 백엔드는 복잡한 코드 덩어리입니다: eBPF 코드 약 2000라인, 유저스페이스 제어 코드 약 6000라인. 이 거대한 건초더미에서 바늘을 찾는 셈입니다.
이슈의 성격(커널 프리즈)과, 커널에서 실행되는 코드가 eBPF 코드뿐이라는 사실을 고려하면, 문제는 eBPF 코드 어딘가에 있다고 가정하겠습니다. 그러면 조사할 코드는 약 2000라인으로 줄어들어 낫긴 하지만, 여전히 많습니다.
이전 글들에서 설명했듯이 eBPF 코드는 성능 데이터를 수집하기 위해 커널의 여러 트레이스포인트에 붙습니다. 낮은 빈도의 bookkeeping 이벤트 몇 개를 제외하면, eBPF에서 캡처하는 주요 성능 이벤트는 세 가지입니다:
더 좁히기 위해, 우리는 이 이벤트 타입들을 각각 개별적으로 비활성화할 수 있는 디버그 옵션을 만들었습니다. 그리고 이벤트를 켜고 끄는 다양한 조합으로 재현을 시도했습니다. 그 결과 다음 관찰을 얻었습니다:
이는 샘플 이벤트에서 실행되는 eBPF 코드와 컨텍스트 스위치에서 실행되는 eBPF 코드 사이의 어떤 상호작용이 문제임을 강하게 시사합니다. 또한 샘플링 주파수를 기본 8 kHz에서 1 Hz로 낮추면 프리즈 빈도는 줄어들지만 여전히 발생합니다.
이 정보를 바탕으로 코드에서 샘플링 & 컨텍스트 스위치 이벤트를 제외한 모든 것을 끄고, 두 쪽 eBPF 코드를 점점 더 깎아내어 프리즈가 발생하지 않을 때까지 단순화했습니다. 그 결과 마침내 다음과 같은 매우 최소한의 eBPF 재현 코드를 얻었습니다:
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 512 * 1024 * 1024);
} ringBuffer SEC(".maps");
SEC("tp_btf/sched_switch")
int cswitch(struct bpf_raw_tracepoint_args* inContext)
{
struct CSwitchEvent* event = bpf_ringbuf_reserve(&ringBuffer, sizeof(struct CSwitchEvent), 0);
if (event == NULL)
return 1;
bpf_ringbuf_discard(event, 0);
return 0;
}
SEC("perf_event")
int sample(struct bpf_perf_event_data* inContext)
{
struct SampleEvent* event = bpf_ringbuf_reserve(&ringBuffer, sizeof(struct SampleEvent), 0);
if (event == NULL)
return 1;
bpf_ringbuf_discard(event, 0);
return 0;
}
이는 두 개의 eBPF 프로그램을 설명합니다: 하나는 컨텍스트 스위치가 발생할 때 실행되고, 다른 하나는 샘플링 인터럽트에서 실행됩니다. 두 프로그램은 링 버퍼에서 공간을 예약(bpf_ringbuf_reserve)한 다음 즉시 그 예약을 폐기(bpf_ringbuf_discard)하는 것 외에는 아무 것도 하지 않습니다.
이 eBPF 프로그램들을 Superluminal과 독립적으로(즉, 우리의 다른 코드 없이) 커널에 붙이고, 충분히 높은 샘플링 주파수를 설정하면 주기적인 프리즈가 발생합니다.
이제 프로그램이 거의 아무 것도 하지 않으니, 남아 있는 작업의 대부분을 차지하는 bpf_ringbuf_reserve가 문제를 일으킬 가능성이 가장 높습니다. 그러니 고대의 예술인 “코드 그냥 읽기(Just Reading The Code)”로 무슨 일이 일어나는지 알아봅시다.
우리가 돌리던 커널에서의 전체 코드는 다음과 같습니다(원본 소스):
static void *__bpf_ringbuf_reserve(struct bpf_ringbuf *rb, u64 size)
{
unsigned long cons_pos, prod_pos, new_prod_pos, pend_pos, flags;
struct bpf_ringbuf_hdr *hdr;
u32 len, pg_off, tmp_size, hdr_len;
if (unlikely(size > RINGBUF_MAX_RECORD_SZ))
return NULL;
len = round_up(size + BPF_RINGBUF_HDR_SZ, 8);
if (len > ringbuf_total_data_sz(rb))
return NULL;
cons_pos = smp_load_acquire(&rb->consumer_pos);
if (raw_res_spin_lock_irqsave(&rb->spinlock, flags))
return NULL;
pend_pos = rb->pending_pos;
prod_pos = rb->producer_pos;
new_prod_pos = prod_pos + len;
while (pend_pos < prod_pos) {
hdr = (void *)rb->data + (pend_pos & rb->mask);
hdr_len = READ_ONCE(hdr->len);
if (hdr_len & BPF_RINGBUF_BUSY_BIT)
break;
tmp_size = hdr_len & ~BPF_RINGBUF_DISCARD_BIT;
tmp_size = round_up(tmp_size + BPF_RINGBUF_HDR_SZ, 8);
pend_pos += tmp_size;
}
rb->pending_pos = pend_pos;
/* check for out of ringbuf space:
* - by ensuring producer position doesn't advance more than
* (ringbuf_size - 1) ahead
* - by ensuring oldest not yet committed record until newest
* record does not span more than (ringbuf_size - 1)
*/
if (new_prod_pos - cons_pos > rb->mask ||
new_prod_pos - pend_pos > rb->mask) {
raw_res_spin_unlock_irqrestore(&rb->spinlock, flags);
return NULL;
}
hdr = (void *)rb->data + (prod_pos & rb->mask);
pg_off = bpf_ringbuf_rec_pg_off(rb, hdr);
hdr->len = size BPF_RINGBUF_BUSY_BIT;
hdr->pg_off = pg_off;
/* pairs with consumer's smp_load_acquire() */
smp_store_release(&rb->producer_pos, new_prod_pos);
raw_res_spin_unlock_irqrestore(&rb->spinlock, flags);
return (void *)hdr + BPF_RINGBUF_HDR_SZ;
}
대부분의 코드는 꽤 직관적입니다. 비교적 표준적인 다중 프로듀서 단일 컨슈머(MPSC) 링 버퍼의 프로듀서 측을 구현합니다.
이 코드에서 주목할 점 하나는, 스핀락으로 보호된다는 것입니다(16번째 줄의 raw_res_spin_lock_irqsave, 54번째 줄의 raw_res_spin_unlock_irqrestore). 또한 이 코드는 raw_res_spin_lock_irqsave가 실패하는 경우도 처리하도록 작성되어 있습니다. 그 경우 bpf_ringbuf_reserve가 실패하고 NULL을 반환합니다.
우리가 추적 중인 프리즈가 이 함수에서 발생하고, 게다가 락을 잡고 있으니 매우 수상합니다. 다음으로 스핀락 구현을 봅시다. 락/언락 함수는 몇 개의 매크로를 거치는데, 모두 접으면 본질적으로 다음과 같습니다:
static int raw_res_spin_lock_irqsave(lock, flags)
{
local_irq_save(flags);
preempt_disable();
return res_spin_lock(lock);
}
static void raw_res_spin_unlock_irqrestore(lock, flags)
{
res_spin_unlock(lock);
preempt_enable();
local_irq_restore(flags);
}
락 함수는 동일 CPU에서 인터럽트를 비활성화(local_irq_save)하고, 프리엠션을 비활성화(preempt_disable)한 뒤 락 획득을 시도합니다. 언락 함수는 그 반대입니다. 목적은 스핀락이 잡힌 동안 실행되는 코드가 다른 코드에 의해 인터럽트로 끊기지 않도록 보장하는 것입니다.
하지만 앞선 테스트에서 우리는 샘플링과 컨텍스트 스위치가 둘 다 켜져 있을 때만 프리즈를 재현할 수 있다는 것을 봤습니다. 흥미로운 점은 샘플링 인터럽트가 “NMI(non-maskable interrupt)”라는 특별한 종류의 인터럽트라는 것입니다. 여기서 maskable은 하드웨어 인터럽트가 소프트웨어(예: local_irq_save)로 비활성화될 수 있는지 여부를 뜻합니다. NMI는 아예 비활성화할 수 없고, 따라서 언제든지 발생할 수 있습니다.
그래서 이제 가설이 떠오릅니다: 다음 상황에서는 무슨 일이 벌어질까요…
raw_res_spin_lock_irqsave를 통해 링 버퍼 스핀락을 획득하려고 한다실제 스핀락 구현(코드)은 여기서 공유하기엔 너무 큽니다. 하지만 대충 훑어보면, 다음과 같은 것과 동등한 일이 일어나는 다양한 경로가 있습니다:
if (val & _Q_LOCKED_MASK) {
RES_RESET_TIMEOUT(ts, RES_DEF_TIMEOUT);
res_smp_cond_load_acquire(&lock->locked, !VAL || RES_CHECK_TIMEOUT(ts, ret, _Q_LOCKED_MASK));
}
여기서 호출되는 res_smp_cond_load_acquire 함수는 조건(두 번째 인자)이 참이 될 때까지 스핀-웨이트를 구현합니다. 위 스니펫은 본질적으로 다음과 같습니다:
if (val & _Q_LOCKED_MASK) {
RES_RESET_TIMEOUT(ts, RES_DEF_TIMEOUT);
while (true)
{
if (!lock->locked || RES_CHECK_TIMEOUT(ts, ret, _Q_LOCKED_MASK))
break;
}
}
즉, 두 조건을 기다립니다:
locked 플래그가 false가 되어, 락이 더 이상 잡혀 있지 않음을 나타내는 경우RES_CHECK_TIMEOUT이 true를 반환해, 대기 타임아웃이 만료된 경우다시 말해, 이는 locked 플래그가 false가 될 때까지 기다리되, 영원히 스핀하지 않도록 타임아웃을 둔 루프입니다. 이 코드가 다양한 경로에서 기다리는 타임아웃인 RES_DEF_TIMEOUT 정의를 보면:
/*
* Default timeout for waiting loops is 0.25 seconds
*/
#define RES_DEF_TIMEOUT (NSEC_PER_SEC / 4)
맨 처음 캡처에서 프리즈가 250ms+ (즉 0.25초)였던 것을 기억하시나요? 스핀락 코드의 기본 스핀-웨이트 타임아웃도 250ms라는 게 우연은 아닐 가능성이 큽니다. 아마 전문가들이 말하는 ‘확실한 단서(smoking gun)’일 겁니다.
이 시점에서 우리는 이 문제를 eBPF 커널 메일링 리스트에 보고했습니다. 그 결과 커널 메인테이너 Kumar Kartikeya Dwivedi와 Alexei Starovoitov와의 생산적인 논의가 이어졌고, 여러 문제점이 드러났습니다.
지금 메일링 리스트 토론을 읽어도 되지만, 그러면 재미가 반감됩니다. 대신 Linux 커널과 스핀락을 깊게 파고드는 여정에 함께해 주세요.
(이미 스핀락과 일반적인 문제점에 익숙하다면 다음 섹션으로 넘어가도 됩니다)
스핀락을 완전한 뮤텍스/락의 대안으로 접해본 적이 있을 겁니다. 가장 기본적인 형태는 대략 이렇게 생겼습니다:
typedef struct {
volatile int locked;
} spinlock_t;
static inline void spin_lock(spinlock_t *lock)
{
while (__sync_val_compare_and_swap(&lock->locked, 0, 1))
{
// Spin until we managed to take the lock
}
}
static inline void spin_unlock(spinlock_t *lock)
{
__sync_lock_release(&lock->locked);
}
그리고 이런 식으로 사용합니다:
spinlock_t lock;
spin_lock(&lock);
// Code guarded by the lock goes here; only one CPU can be executing this at a time
spin_unlock(&lock);
spin_lock 함수는 __sync_val_compare_and_swap를 통해 atomic compare-and-swap(CAS)을 수행하여 락을 획득합니다. 즉 locked 값을 원자적으로 1로 바꿉니다. 성공하면 이 스레드가 락을 보유하게 됩니다.
실패하는 경우는 locked 값이 현재 0이 아닐 때입니다. 그 경우 다른 스레드가 이미 락을 가지고 있거나, 이 스레드가 획득을 시도하는 동안 다른 스레드가 가져갔다는 뜻입니다. 그러면 성공할 때까지 루프에서 계속 재시도합니다.
이 기본 스핀락에는 여러 문제가 있습니다.
그중 하나는 스핀 자체가 아무 유용한 일도 하지 않으면서 CPU 사이클을 낭비한다는 점입니다. 다른 스레드가 락을 보유하고 있는 동안, 이 스레드가 실행 중인 CPU는 락이 풀릴 때까지 루프를 돌며 CPU 사이클을 태웁니다.
또 다른, 아마 더 심각한 문제는 스핀루프를 떠나서 CAS 자체가 매우 비쌀 수 있다는 점입니다. 그 이유는 캐시 라인 바운싱(cache line bouncing) 또는 핑퐁(ping-ponging) 문제 때문입니다.
CPU는 코어 간 메모리 캐시 일관성을 유지하기 위해 MESI 프로토콜을 사용합니다. CPU가 메모리 값을 쓰려고 할 때(여기서는 locked 플래그), 해당 값을 포함하는 캐시 라인을 먼저 Modified 상태로 획득해야 합니다. 이를 위해 CPU는 그 캐시 라인을 보유한 다른 모든 코어에게 무효화(invalidation)를 브로드캐스트하고, 각 CPU가 그 무효화에 대해 응답(acknowledgement)할 때까지 기다려야 합니다. 이런 코어 간 통신은 메모리 버스를 타기 때문에 비쌉니다.
이 문제는 스핀락에만 국한된 것은 아니지만, 스핀락은 공유된 locked 플래그 때문에 특히 크게 영향을 받습니다. 예를 들어 4개의 CPU에서 4개의 스레드가 위 기본 스핀락을 획득하려고 한다고 해봅시다. locked 플래그는 공유되며 하나의 캐시 라인에 있습니다.
__sync_val_compare_and_swap)로 락 획득을 계속 시도합니다. CAS는 쓰기 연산으로 취급되므로, 각 CPU는 캐시 라인을 Modified 상태로 획득해야 하며, 이는 다른 모든 코어에 무효화를 보내고 응답을 기다리는 것을 의미합니다.즉 이 시나리오에서는 캐시 라인이 높은 빈도로 코어들 사이를 튀어 다니게 됩니다. 또한 각 CPU가 서로의 무효화/응답을 처리해야 하므로, 경쟁자 수가 늘어날수록 비용이 제곱으로 악화됩니다. CPU 수가 많은 머신에서는 매우 문제가 될 수 있습니다.
마지막으로 이런 기본 스핀락은 “불공정(unfair)”합니다. 락이 풀리면 모든 대기자가 획득 경쟁을 하고, 누가 이길지는 사실상 임의입니다. 즉 어떤 스레드는 다른 CPU들이 계속 이기면 영원히 스핀할 수도 있어, 진행 보장(forward progress)이 없습니다. 예를 들어 위 캐시 라인 바운싱 문제와 결합되면, 락을 현재 보유한 CPU와 물리적으로 더 가까운 CPU가 메모리 버스 지연이 더 낮아서 반복적으로 CAS 경쟁에서 이길 수도 있습니다.
반대로 공정한(fair) 스핀락은 도착 순서대로 락을 획득하도록 보장합니다. CPU 0이 락을 보유하고 있고 그 다음 CPU 3, 마지막으로 CPU 2가 락을 시도했다면, CPU 3이 CPU 2보다 먼저 락을 얻는 것이 보장됩니다.
유저스페이스에서는, 커널과 달리 시스템에 대한 제어가 더 적기 때문에(예: 프리엠션을 끌 수 없음) 적용되는 추가적인 문제가 많이 있습니다. 유저스페이스 스핀락의 잠재적 문제들을 훌륭하게 정리한 글로 이 글을 참고하세요.
앞 섹션에서 설명한 문제들 때문에 더 정교한 스핀락이 존재하는 건 놀랄 일이 아닙니다. Linux 커널은 스핀락을 광범위하게 사용하며, 커널에는 다양한 스핀락 변형이 있습니다. 주요 변형은 ‘queued spinlock’ 또는 qspinlock입니다(코드).
qspinlock은 MCS spinlock의 한 버전입니다. Linux 커널의 구현은 일반 MCS 락에 비해 여러 최적화가 적용돼 있지만, MCS 락의 기본 동작은 비교적 단순합니다.
MCS 락은 두 구조로 정의됩니다:
// Each CPU has its own node
struct mcs_node {
struct mcs_node* next; // Points to the next waiter in the lock queue
int locked; // Indicates whether this CPU is waiting for the lock (set to 1 while waiting; 0 when not waiting)
};
// The lock itself; essentially just a tail pointer
struct mcs_lock {
struct mcs_node* tail; // Points to the last waiter in the lock queue; null if currently unlocked
};
mcs_lock은 실제 락을 나타내고, mcs_node는 락 보유자 또는 대기자를 나타냅니다.
MCS 스핀락의 핵심 아이디어는 각 CPU가 보통 per-CPU 저장소를 통해 자신만의 mcs_node를 갖는다는 점입니다. mcs_node들은 대기자들의 연결 리스트를 형성합니다. 각 노드의 next 포인터는 (있다면) 다음으로 풀어줘야 할 대기자를 가리킵니다. 또한 모든 CPU가 경쟁해야 하는 공유 locked 플래그가 없습니다. locked 플래그는 per-CPU mcs_node 안에 있어 각 대기자는 자기 로컬 플래그만을 스핀합니다.
mcs_lock 자체는 tail 포인터 하나뿐입니다. 이는 락을 마지막으로 획득했거나 획득 중인 CPU의 mcs_node를 가리킵니다. 아무도 락을 보유하지 않으면 null입니다.
이렇게 락을 표현하면 앞서 설명한 기본 스핀락의 두 가지 주요 문제를 해결합니다:
locked 플래그가 없습니다. 대신 각 대기자(CPU)가 자신의 locked 플래그를 갖고 그것만을 스핀합니다. 공유 상태는 락의 tail 포인터뿐이며, 아무도 그것을 스핀하지 않습니다.next 포인터로 형성된 큐를 통해 대기자들은 도착한 순서대로 해제되므로, 락은 완전히 공정해집니다.추상적이니 예제로 더 구체적으로 보겠습니다. 다음 예제에서는 언락된 상태에서 시작해 CPU 0, 3, 2가 그 순서대로 락을 획득하려고 합니다.
락은 처음에 비어 있으므로 언락입니다. tail 포인터는 null입니다:
 CPU 0이 락을 획득하려고 하며, 락의
CPU 0이 락을 획득하려고 하며, 락의 tail 포인터를 자신의 노드로 원자적 교환합니다. 기존 tail이 null이었으므로 이전 보유자가 없었고, 이제 우리가 락 보유자입니다:
 이제 CPU 3도 락을 획득하려고 합니다. 다시 원자적으로
이제 CPU 3도 락을 획득하려고 합니다. 다시 원자적으로 tail을 자신의 노드로 교환합니다. 이전 tail이 null이 아니므로 이미 누군가 락을 보유하고 있음을 알 수 있습니다. 이전 tail 노드의 next 포인터를 설정해 큐에 자신을 추가하고, locked 플래그가 0이 될 때까지 스핀-웨이트를 시작합니다:
 CPU 2도 락을 시도하며 CPU 3과 같은 과정을 따릅니다. 역시 큐에 추가하고
CPU 2도 락을 시도하며 CPU 3과 같은 과정을 따릅니다. 역시 큐에 추가하고 locked를 스핀합니다:
 마침내 CPU 0이 락을 해제합니다. 자신의 노드에
마침내 CPU 0이 락을 해제합니다. 자신의 노드에 next 포인터가 설정되어 있으므로 큐 뒤에 대기자가 있다는 것을 알 수 있으며, 여기서는 CPU 3입니다. 다음 대기자의 locked 플래그를 0으로 설정해 다음 대기자를 새 락 보유자로 만들고, 그 대기자의 스핀루프를 빠져나오게 합니다:
 이 과정은 각 보유자가 순서대로 해제/소유권 이전을 하며 계속 진행되고, 마지막 대기자(CPU 2)가 해제하면 락은 다시 언락되어 빈 상태(
이 과정은 각 보유자가 순서대로 해제/소유권 이전을 하며 계속 진행되고, 마지막 대기자(CPU 2)가 해제하면 락은 다시 언락되어 빈 상태(tail == NULL)로 돌아갑니다:
위에서 설명한 qspinlock은 Linux 커널 전반에서 광범위하게 쓰입니다. 이는 사용이 올바르다는 가정 하에 작성되었고, 잠재적으로 잘못된 사용을 처리하려는 시도를 하지 않습니다. qspinlock이 잘못 사용되면, 다른 일반적인 (유저스페이스) 락과 마찬가지로 단순히 데드락으로 시스템이 멈춥니다.
이는 커널에서는 괜찮습니다. 커널 개발자라면 일반 유저스페이스 코드의 락 문제를 추적하듯이 이런 데드락을 비교적 쉽게 찾아낼 수 있기 때문입니다. 문제는 커널의 정상 실행 중 임의의 지점에서 “임의의(합리적 범위 내에서) C 코드”가 실행될 수 있는 시스템이 도입되면서 발생합니다.
그 시스템이 바로 ‘eBPF’이며, 그 임의 코드는 eBPF 프로그램 형태로 존재합니다.
eBPF 프로그램 작성자는 보통 커널 개발자가 아니며, 자신이 후킹하는 커널 시스템의 락 전략을 깊게 이해하길 기대하기 어렵습니다. 오랫동안 eBPF는(검증기 via verifier를 통해) 이를 간단히 처리했습니다:
단순한 경우엔 잘 동작했지만, eBPF의 범위/사용이 커지면서 이 제한은 너무 제약적이 되었습니다. 검증기가 eBPF 프로그램이 데드락이 없다는 것을 정적으로 증명할 수 있으면 이상적이겠지만, 조합 폭발 때문에 불가능합니다. eBPF 프로그램은 매우 다양한 커널 훅에 붙을 수 있고, 그 훅들은 이미 다른 락을 보유하고 있을 수도(없을 수도) 있습니다.
데드락 부재를 정적으로 증명하려면, 검증기는 본질적으로 다음 질문에 답해야 합니다: 로드된 모든 BPF 프로그램의 가능한 모든 인터리빙을, 모든 CPU에서, 모든 인터럽트 컨텍스트에서 고려하고, 각 attach point에서 커널이 보유하고 있을 수 있는 락까지 결합했을 때, 락 위반이 발생하는 경우가 있는가?
그럼에도 제한을 완화할 수 있도록, eBPF 시스템에서 사용하기 위한 새로운 resilient queued spinlock, 즉 rqspinlock이 도입되었습니다. 이름 그대로 이는 기존 qspinlock을 기반으로 합니다. 하지만 qspinlock이 올바른 사용을 전제하는 반면, rqspinlock은 더 방어적인 접근을 취합니다. 즉 잠재적 데드락을 허용하고, 동적으로 이를 복구합니다.
목표는 락 사용 오류가 있더라도 시스템이 (결국) 전진할 수 있도록 하는 것입니다. 이를 위해 몇 가지 방식으로 데드락을 감지/복구합니다:
능동 데드락 감지: 각 CPU는 현재 보유 중인 락들의 (고정 크기) 테이블을 유지합니다. 락 획득 시, 락이 이미 보유 중인 것으로 판명되면(즉 fast path가 실패하고 CPU가 스핀해야 하면), 그리고 스핀-웨이트 동안 주기적으로 rqspinlock은 다음 체크를 수행합니다. 체크가 실패하면 락 획득이 -EDEADLK로 실패합니다:
* AA 체크(재귀 락): 현재 CPU의 held lock 테이블에서 현재 락을 찾습니다. 이미 동일 CPU에서 그 락을 보유 중이면 재귀 락이며, rqspinlock 코드에서는 이를 ‘AA 데드락’이라 부릅니다.
* ABBA 체크(락 순서 역전): 다른 CPU들의 held lock 테이블에서 락 순서 역전을 찾습니다. 이 경우 CPU A가 락 X를 잡고 락 Y를 원하고, CPU B가 락 Y를 잡고 락 X를 원합니다.
타임아웃: 데드락 감지는 완전하지 않습니다. 저렴하게 감지 가능한 흔한 케이스만 다룹니다. 최후의 방어선으로, 감지되지 않는 데드락을 처리하기 위해 rqspinlock의 스핀루프에는 최대 지속 시간이 있습니다. 이를 초과하면 락 획득은 -ETIMEDOUT으로 실패합니다.
큐 타임아웃: 스핀루프가 타임아웃 되면, 그 타임아웃은 MCS 큐에서 타임아웃된 노드 뒤의 대기자들로 전파되어, 모든 대기자가 FIFO 순서로 -ETIMEDOUT과 함께 종료됩니다.
이 모든 것이 합쳐져 rqspinlock은 다양한 흔한 락 문제에 대해 탄력적으로 동작합니다. 개념적으로는 ‘단순’하지만, 상상할 수 있듯 이를 구현하기 위해 rqspinlock에는 꽤 복잡하고(그리고 레이스가 발생하기 쉬운) 장치들이 필요합니다.
그리고 그 장치들 속에 우리가 겪은 문제의 원인이 있습니다.
이제 우리가 기대했던 것보다 훨씬 더 많이 Linux 커널 스핀락 내부를 알게 되었으니, 추적 중인 프리즈에 대해 추론해 봅시다. 요약해 보면:
최소 재현 케이스에서 프리즈는 두 eBPF 프로그램 간의 상호작용에서 발생합니다. 하나는 컨텍스트 스위치에서 실행되고, 다른 하나는 샘플링 인터럽트에서 실행됩니다. 두 프로그램 모두 bpf_ringbuf_reserve로 링 버퍼 공간을 예약하는데, 그 함수는 링 버퍼 상태를 보호하기 위해 rqspinlock을 사용합니다.
앞서 말했듯 우리의 가설은 bpf_ringbuf_reserve의 스핀락이 재귀적으로 획득되는 상황에서 프리즈가 발생한다는 것입니다. 즉 컨텍스트 스위치 프로그램이 같은 CPU에서 락을 획득 중일 때, 샘플링 프로그램도 그 락을 획득하려고 한다는 의심입니다.
하지만 앞 섹션에서 설명했듯 rqspinlock은 이론적으로 재귀(AA) 락 감지로 이를 처리할 수 있어야 하는데, 우리는 여전히 250ms의 전체 rqspinlock 타임아웃에 도달하는 것으로 보였습니다. 따라서 선택지는 두 가지입니다: 가설이 틀렸거나, 혹은 rqspinlock에 버그가 있거나.
스포일러: 버그입니다. 파고들어 봅시다.
우리는 데드락 감지가 락 경쟁 시 스핀루프의 일부로 실행된다는 것을 알고 있으며, 앞서 rqspinlock의 스핀-웨이트가 사실상 이렇게 보인다는 것도 봤습니다:
while (true)
{
if (!lock->locked || RES_CHECK_TIMEOUT(ts, ret, _Q_LOCKED_MASK))
break;
}
이 루프는 locked 플래그가 더 이상 설정되어 있지 않거나(이전 보유자가 해제해 우리가 소유자가 됨), 타임아웃(RES_CHECK_TIMEOUT)에 도달할 때까지 스핀합니다.
이 루프 자체에서는 데드락 감지가 일어나지 않으므로, 합리적으로 RES_CHECK_TIMEOUT에서 데드락 감지가 수행된다고 추정할 수 있습니다. RES_CHECK_TIMEOUT의 코드를 따라가면, 타임아웃 체크의 일부로 1ms마다 check_deadlock_AA 함수가 호출되는 것을 확인할 수 있습니다.
코드는 다음과 같습니다:
static noinline int check_deadlock_AA(rqspinlock_t *lock, u32 mask,
struct rqspinlock_timeout *ts)
{
struct rqspinlock_held *rqh = this_cpu_ptr(&rqspinlock_held_locks);
int cnt = min(RES_NR_HELD, rqh->cnt);
/*
* Return an error if we hold the lock we are attempting to acquire.
* We'll iterate over max 32 locks; no need to do is_lock_released.
*/
for (int i = 0; i < cnt - 1; i++) {
if (rqh->locks[i] == lock)
return -EDEADLK;
}
return 0;
}
현재 CPU의 held lock 테이블(this_cpu_ptr(&rqspinlock_held_locks), 4번째 줄)을 가져온 뒤, 테이블의 락들을 순회하며 현재 획득하려는 락이 있는지 확인합니다. 있으면 재귀 락이므로 -EDEADLK를 반환합니다.
이 코드만 보면 문제될 게 많지 않습니다(테이블을 검사하기만 합니다). 그러면 테이블을 실제로 갱신하는 코드를 봐야 합니다.
테이블에 락을 추가하는 함수는 grab_held_lock_entry입니다. 여기서는 공유하지 않겠지만(코드), per-cpu 카운터를 단순 증가시키며 정적 per-cpu 배열에 락을 넣을 뿐입니다. 여기서도 문제가 생길 여지는 많지 않습니다.
다음은 이 함수가 사용되는 지점입니다. 호출되는 곳은 두 군데입니다. 첫 번째는 락 획득 fast path로, 락이 전혀 보유되지 않은 경우(즉 MCS 락의 tail == null 케이스)입니다.
두 번째는 slow path로, 락이 이미 보유되어 스핀-웨이트가 필요한 경우입니다. 우리가 위에서 본 스핀루프 코드는 slow path에서 왔고, 아직 fast path는 보지 않았습니다. fast path는 이렇게 생겼습니다:
static __always_inline int res_spin_lock(rqspinlock_t *lock)
{
int val = 0;
if (likely(atomic_try_cmpxchg_acquire(&lock->val, &val, _Q_LOCKED_VAL))) {
grab_held_lock_entry(lock);
return 0;
}
return resilient_queued_spin_lock_slowpath(lock, val);
}
앞서 말했듯 Linux 커널의 MCS 락 버전은 기본 MCS 락보다 더 최적화되어 있지만, 5번째 줄의 atomic_try_cmpxchg_acquire(&lock->val, &val, _Q_LOCKED_VAL)을 기본 MCS 락의 tail 포인터 교환과 동등하다고 보면 됩니다. 성공하면 락이 아직 잡히지 않았음을 의미하고, 우리가 이제 락을 보유합니다. 그 다음 grab_held_lock_entry로 이 락을 현재 CPU의 held lock 테이블에 추가합니다.
바로 이 코드에 문제가 있으며, Alexei가 이를 발견했습니다.
문제는 이 코드가 동일 CPU에서 동시에 락을 획득하려는 누군가가 있을 수 없다고 가정한다는 점입니다. 이는 합리적인 가정입니다. 앞서 보았듯 rqspinlock의 락 함수는 락 획득을 시도하기 전에 이 CPU의 인터럽트와 프리엠션을 모두 비활성화하여, 코드가 중간에 인터럽트로 끊기지 않도록 보장하기 때문입니다.
하지만 우리는 샘플링 인터럽트가 NMI라는 것도 알고 있습니다. 즉 비활성화할 수 없습니다. NMI가 발생하면, CPU에서 실행 중이던 어떤 코드든 반드시 중단시키고 우선권을 가집니다.
그리고 여기서 문제가 발생합니다. atomic_try_cmpxchg_acquire로 락 획득이 성공한 후(5번째 줄), 하지만 grab_held_lock_entry가 호출되기 전(6번째 줄)에 NMI가 발생하면, 락은 (잠시) 일관되지 않은 상태가 됩니다. 락은 잠겨(획득되어) 있지만, held lock 테이블에는 아직 기록되지 않은 상태입니다.
즉 그 상태에서 수행되는 데드락 체크는 이 락이 포함된 데드락을 놓치게 됩니다. 단일 CPU에서 다음 순서를 생각해 봅시다:
res_spin_lock로 락을 획득하려고 하고, atomic_try_cmpxchg_acquire로 락을 획득해 이제 락을 보유합니다.grab_held_lock_entry로 갱신하기 전에, 동일 CPU에서 샘플링 NMI가 발생하여 컨텍스트 스위치 eBPF 프로그램을 인터럽트합니다.res_spin_lock로 락을 획득하려 하지만, 락이 이미 보유 중(컨텍스트 스위치 프로그램이 보유)이라 atomic_try_cmpxchg_acquire가 실패합니다.resilient_queued_spin_lock_slowpath)로 들어가 락 해제를 기다리며 스핀루프에 들어갑니다.grab_held_lock_entry로 held lock 테이블을 갱신하고 정상적으로 실행되어 시스템이 다시 움직입니다.이 문제의 수정은 Kumar가 했으며, 핵심은 순서를 바꾸는 것이었습니다. 즉 획득이 성공했을 때만 held lock 테이블을 갱신하는 것이 아니라, 이제는 compare-exchange로 실제 락 획득을 시도하기 전에 held lock 테이블을 항상 갱신합니다:
static __always_inline int res_spin_lock(rqspinlock_t *lock)
{
int val = 0;
/*
* Grab the deadlock detection entry before doing the cmpxchg, so that
* reentrancy due to NMIs between the succeeding cmpxchg and creation of
* held lock entry can correctly detect an acquisition attempt in the
* interrupted context.
*
* cmpxchg lock A
* <NMI>
* res_spin_lock(A) --> missed AA, leads to timeout
* </NMI>
* grab_held_lock_entry(A)
*/
grab_held_lock_entry(lock);
if (likely(atomic_try_cmpxchg_acquire(&lock->val, &val, _Q_LOCKED_VAL)))
return 0;
return resilient_queued_spin_lock_slowpath(lock, val);
}
우리는 Kumar의 패치를 가져와 커널을 컴파일해 이 문제가 해결되는지 확인했습니다. 다시 재현을 시도하니 문제가 사라졌고, 시스템은 더 이상 멈추지 않았습니다. 야호! 끝났네요.
… 정말 끝일까요?
이 패치로 시스템이 더 이상 눈에 띄게 멈추지는 않지만, dmesg에는 여전히 이런 메시지가 보였습니다:
[ +0.000002] INFO: NMI handler (perf_event_nmi_handler) took too long to run: 1.584 msecs
[ +0.014555] INFO: NMI handler (perf_event_nmi_handler) took too long to run: 1.701 msecs
[ +0.004845] INFO: NMI handler (perf_event_nmi_handler) took too long to run: 26.229 msecs
[ -0.000001] INFO: NMI handler (perf_event_nmi_handler) took too long to run: 15.120 msecs
[ +0.000000] INFO: NMI handler (perf_event_nmi_handler) took too long to run: 24.805 msecs
[ +0.000000] INFO: NMI handler (perf_event_nmi_handler) took too long to run: 6.855 msecs
[ +0.246851] INFO: NMI handler (perf_event_nmi_handler) took too long to run: 1.974 msecs
[ +0.163526] INFO: NMI handler (perf_event_nmi_handler) took too long to run: 1.981 msecs
[ +0.235492] INFO: NMI handler (perf_event_nmi_handler) took too long to run: 1.996 msecs
좋은 소식은 처음 보던 250ms 경고 메시지는 실제로 사라졌다는 것입니다(예상대로). 하지만 NMI가 너무 오래 걸리는 케이스가 여전히 있습니다.
NMI 핸들러에서 링 버퍼 공간을 예약하는 것 말고는 아무 것도 하지 않는데, 이 테스트 케이스에서 이런 메시지가 찍히는 건 기대하기 어렵습니다. 멈춤이 훨씬 짧아지긴 했지만, 여전히 멈춤입니다. 우리는 이제 이것들이 육안으로는 알아차리기 어려울 정도로 짧아진 시스템 프리즈일 것이라 의심했습니다.
뭔가가 여전히 일어나고 있으니, 다음으로 그것을 파고들어 봅시다.
이 경고 메시지에서 우선 알 수 있는 건, 타임아웃이 두 구간으로 나뉜다는 점입니다: 1-2ms, 그리고 6-26ms 정도의 더 큰 것들.
첫 번째 구간은 스핀-웨이트 동안 데드락 체크가 1ms 주기로 수행된다는 점과 꽤 가깝습니다(또는 그 배수). 그래서 데드락 체크 트리거 방식에 문제가 있지 않을까 의심했습니다. 타임아웃 체크 및 데드락 감지를 수행하는 함수를 봅시다:
static noinline int check_timeout(rqspinlock_t *lock, u32 mask,
struct rqspinlock_timeout *ts)
{
u64 time = ktime_get_mono_fast_ns();
u64 prev = ts->cur;
if (!ts->timeout_end) {
ts->cur = time;
ts->timeout_end = time + ts->duration;
return 0;
}
if (time > ts->timeout_end)
return -ETIMEDOUT;
/*
* A millisecond interval passed from last time? Trigger deadlock
* checks.
*/
if (prev + NSEC_PER_MSEC < time) {
ts->cur = time;
return check_deadlock(lock, mask, ts);
}
return 0;
}
이 함수는 스핀-웨이트 중 호출되며, 앞서 보았던 RES_CHECK_TIMEOUT 매크로의 실체입니다. 전달되는 rqspinlock_timeout 객체는 타임아웃 상태를 나타냅니다.
이 함수가 특정 스핀-웨이트에 대해 처음 호출되면, 타임아웃을 초기화하고 즉시 반환합니다(7번째 줄의 if).
이후 호출(즉 이미 타임아웃이 초기화된 경우)에서는 두 가지 체크를 수행합니다:
ktime_get_mono_fast_ns)이 타임아웃 종료를 지났는지(13번째 줄의 if (time > ts->timeout_end)). 이 경우 대기는 타임아웃 되어 -ETIMEDOUT를 반환합니다.if (prev + NSEC_PER_MSEC < time)). 이 경우 데드락 체크를 수행합니다.기능적으로는 동작하지만, 데드락 체크가 최소 1ms가 지나야 수행된다는 점이 dmesg에서 보던 1-2ms NMI 타임아웃의 원인입니다.
이는 이전에 수정된 프리즈 이슈와 본질적으로 같은 상황이지만, 조금 다른 형태로 나타납니다:
check_timeout의 데드락 체크가 마침내 트리거되어 이미 알고 있던 데드락을 감지하고 -EDEADLK로 스핀-웨이트를 탈출합니다.이를 검증하기 위해 우리는 로컬에서 빠른 패치를 만들어 타임아웃 초기화 시점(7번째 줄의 if (!ts->timeout_end) 안)에서 check_deadlock을 트리거하도록 했고, 다시 재현을 시도했습니다. 이 수정이 적용되면 1-2ms 구간의 타임아웃은 더 이상 발생하지 않았고, 이제 dmesg에는 더 큰 타임아웃만 남았습니다.
이 문제 역시 보고했고, 정식 수정이 만들어졌습니다.
이제 남은 문제는, 이전 수정 후에도 dmesg를 통해 보고되는 6-26ms 타임아웃입니다. 이 원인은 Kumar가 발견했습니다.
여기서의 문제는, 재귀 락이 없더라도 NMI가 스핀락 보유자의 전진을 막아, 락 보유자가 CPU 시간을 충분히 얻지 못하게(기아, starvation) 만들 수 있다는 것입니다.
왜 그런지 이해하려면 다음 상황을 생각해 보세요:
이제 CPU 0이 락을 보유하고 CPU 3이 기다리는 상태입니다. 이런 상황에서 CPU 0에서 NMI가 발생해 링 버퍼 스핀락을 또 획득하려고 합니다. 이는 재귀 락 상황이며, 앞서 만든 수정들 덕분에 이제 올바르게 처리되어 NMI는 링 버퍼 스핀락 획득에 실패합니다. 그러나 이 NMI는 락을 얻지 못했더라도 그 동안 CPU 0의 진행을 막았습니다.
CPU 0이 링 버퍼 스핀락을 보유한 동안 NMI가 CPU 0에 계속 쏟아지면, 컨텍스트 스위치 프로그램이 진행하지 못해 링 버퍼 스핀락을 해제하지 못하게 됩니다. 그러면 CPU 3처럼 락을 필요로 하는 다른 CPU들도 진행하지 못합니다. 충분히 높은 샘플링 주파수에서는, 특히 데드락 체크가 최소 1ms 뒤에 트리거된다는 이전 문제와 결합되어, 더 긴 스톨로 이어질 수 있습니다.
이 문제의 수정도 Kumar가 했고, rqspinlock의 slow path(즉 이미 락이 잡혀 있는 상태에서 락을 획득하려 할 때)의 핵심에 상당히 미묘한 변경이 여러 개 포함되었습니다. 변경 자체는 비교적 작지만, 관련 레이스 컨디션의 미묘함 때문에 이 글 범위 밖입니다. 관심 있다면 패치 #3, #4 및 #5를 참고하세요.
어쨌든 우리는 이 수정과 다른 모든 수정을 함께 테스트했고, 마침내 재현을 실행해도 시스템에서 어떤 프리즈도 보지 못하는 상태가 되었고, dmesg에서도 타임아웃 경고가 사라졌습니다. 야호!
휴! 꽤 긴 여정이었지만, Linux 커널 락킹 내부에 대해 정말 많은 것을 배웠습니다.
남은 질문 하나는 이것입니다: 왜 이 문제는 로컬 개발 중이나 다른 사용자에게서는 이전에 발생하지 않았을까요? 이제 모든 과정을 거치고 나니 명확합니다. 우리의 커널이 그냥 너무 오래됐습니다.
eBPF 링 버퍼에서 rqspinlock을 사용하도록 한 변경은 2025년 4월에야 도입되었고(commit), 커널 6.15에 포함되었습니다. 그 이전에는 링 버퍼가 다른 스핀락을 사용했고, 그 락은 이런 특정 문제를 겪지 않았습니다.
우리는 Ubuntu에서 로컬 개발을 하는데, 당시 커널 6.14였습니다. Ubuntu는 6.17로 25.10에서야 전환했는데, 이는 작년 말에 릴리스되었습니다. 대부분의 사용자도 비슷한 상황이라 이 문제를 겪지 않았습니다. 우리는 앞으로 개발 머신을 보통 최신 커널을 쓰는 Arch로 바꿀 계획입니다. 그래야 이런 문제를 더 빨리 발견할 수 있으니까요. 교훈을 얻었습니다.
모든 이슈에 대한 수정은 Kumar가 만든 패치 시리즈에 포함되었고, 이는 6.19 커널에 들어갔습니다. 이슈가 충분히 중요하다고 판단되어 수정은 6.17과 6.18 커널에도 백포트되었습니다. 다양한 이슈를 추적하는 데 도움을 준 Kumar와 Alexei에게 다시 한 번 감사드립니다!
마지막으로, 이제 이 문제(들)를 철저히 이해했기 때문에, 아직 수정이 들어가지 않은 더 오래된 커널을 위한 워크어라운드를 우리 쪽에서 만들 수 있었습니다. 컨텍스트 스위치 eBPF 프로그램 실행 중 발생하는 재귀 NMI는 우리 쪽에서 그냥 버리도록 했습니다.
재미있는 여정이었지만, 앞으로는 더 이상 커널 문제를 보지 않길 바라며… 아, 우리 스스로도 그게 말이 안 된다는 걸 알죠.
맨 위로
이 글을 공유하기:
Twitter에 이 글 공유BlueSky에 이 글 공유이메일로 이 글 공유
다음 글 profiling에서 커널 패치까지: eBPF 성능 수정으로 가는 여정
Twitter의 RiteshMastodon의 RiteshBlueSky의 RiteshLinkedIn의 RiteshRitesh에게 이메일 보내기
Copyright © 2026|All rights reserved.