지난 30년 동안 HPC 하드웨어와 프로그래밍 표기법이 어떻게 변했는지를 돌아보며, 왜 새로운 HPC 언어의 폭넓은 채택이 일어나지 않았는지와 앞으로 무엇을 해야 하는지를 논의합니다.
하드웨어 발전은 많았지만 새로운 언어의 채택은 너무 적었다
2026년 4월 9일 게시.
작성자: Brad Chamberlain
목차
지난여름, 나는 HIPS 2025—제30회 고수준 병렬 프로그래밍 모델 및 지원 환경 국제 워크숍—에서 기조연설을 할 기회를 얻었다. 이는 큰 영광이었다. 왜냐하면 HIPS는 그 역사 전반에 걸쳐 Chapel과 같이 확장 가능한 병렬 프로그래밍에 대해 생산적인 접근법을 만들고자 하는 프로젝트들에게 핵심적인 워크숍이었기 때문이다 - [x] [note:HIPS에 익숙하지 않은 독자를 위해 설명하자면, 이 워크숍의 출판물은 언어 설계, 컴파일러, 런타임 시스템, 프로그래밍 도구를 통해 다중프로세서, 컴퓨트 클러스터, 대규모 병렬 기계의 고수준 프로그래밍에 초점을 맞춘다. 오랫동안 논문 모집 안내문에는 “대규모 병렬 시스템과 many-core 아키텍처를 위한 새로운 프로그래밍 모델 분야의 혁신적 접근을 보여주는 논문을 특히 환영합니다.”라는 문구가 반복해서 등장해 왔다.].
HIPS의 30회를 기념하기 위해, 나는 이 강연을 통해 HPC, 즉 High-Performance Computing 분야에서 지난 30년의 프로그래밍을 되돌아보는 방식을 택했다. 이는 정신이 번쩍 드는 작업이었지만, 좋은 반응을 얻었다. 11월에는 CLSAC 2025에서 이 강연을 압축한 라이트닝 토크 형식으로 다시 발표했다. 이 블로그 글에서는 그 강연들의 핵심 요소 일부를 더 넓은 독자층을 위해 담아보려 한다.
수많은 “_n_년간의 HPC” 회고와 마찬가지로, 먼저 TOP500 목록을 살펴보자 - [x] [note:TOP500은 Linpack 벤치마크 성능을 기준으로 한 HPC 시스템 순위이다. 이 글의 모든 TOP500 결과와 이미지는 top500.org에서 가져왔으며 허가를 받아 사용했다. 또한 원래 강연 내용은 2025년 11월의 최신 결과를 반영하도록 갱신했다.] 이를 통해 HPC 시스템 자체가 지난 30년 동안 어떻게 변했는지 볼 수 있다. 단순화를 위해 각 목록의 상위 다섯 개 시스템만 보겠다.
30년 전인 1995년 11월의 결과를 살펴보면, Fujitsu, Intel, Cray의 시스템이 상위 다섯 자리를 차지하고 있었고, 이들의 네트워크 인터커넥트는 각각 crossbar, 2D mesh, 3D torus 토폴로지를 사용했다. 코어 수는 80개에서 3,680개까지였고, Rmax 값으로 측정한 성능은 98.9에서 170 GFlop/s 범위였다. 다음은 TOP500 웹사이트에서 이 시스템들과 결과를 요약한 스크린샷이다:
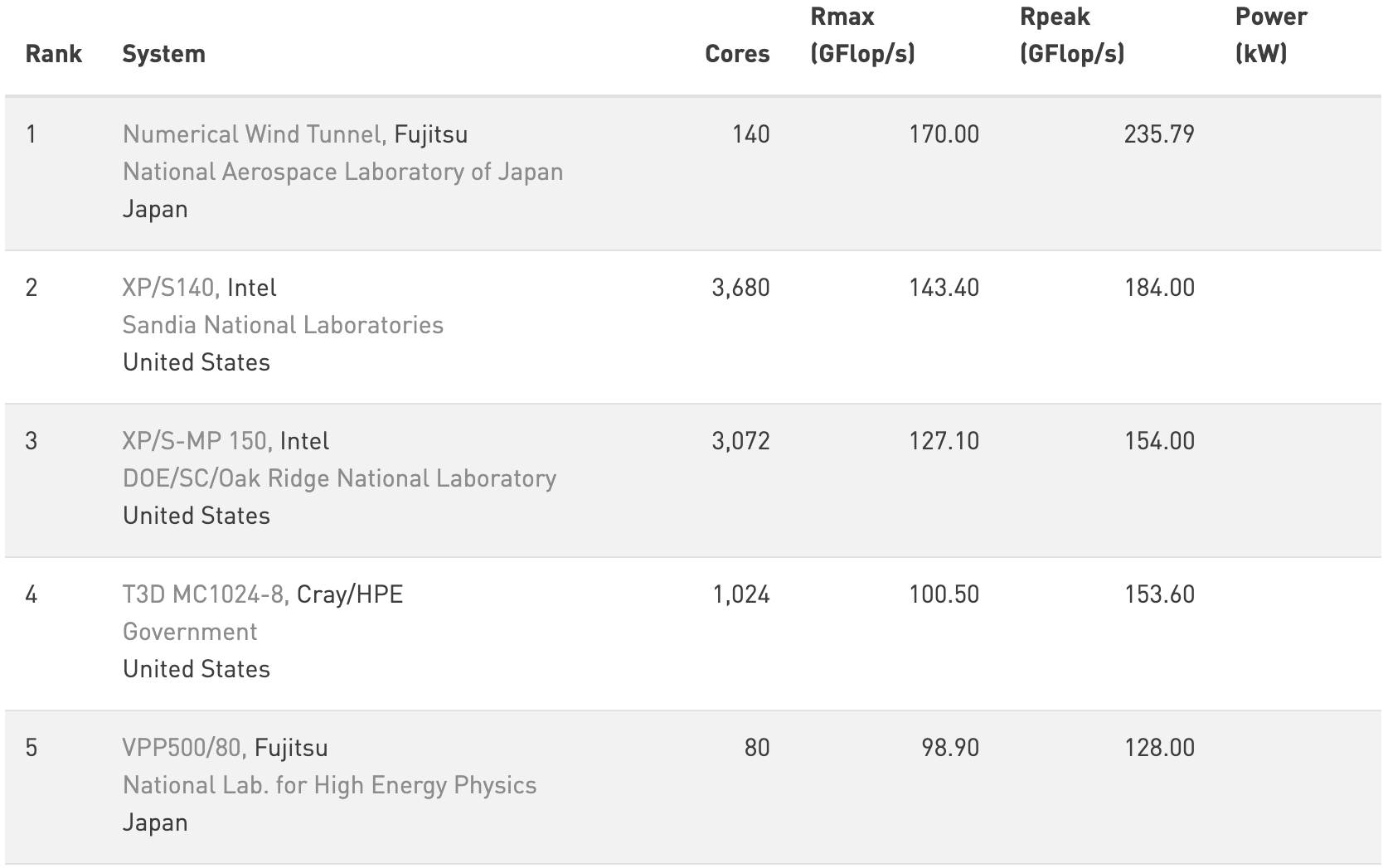
시간을 건너뛰어 2025년 11월에 발표된 최신 TOP500 목록을 보면, HPE Cray, Eviden/Bull, Microsoft의 시스템이 보인다. 이들은 dragonfly[+] 및/또는 fat-tree 기반 토폴로지를 사용하는 Slingshot-11 및 InfiniBand NDR 인터커넥트 위에서 동작한다. 코어 수는 수백만 단위(2,073,600–11,340,000코어)로 뛰어올랐고, Rmax 값은 561에서 1809 PFlop/s에 이른다:
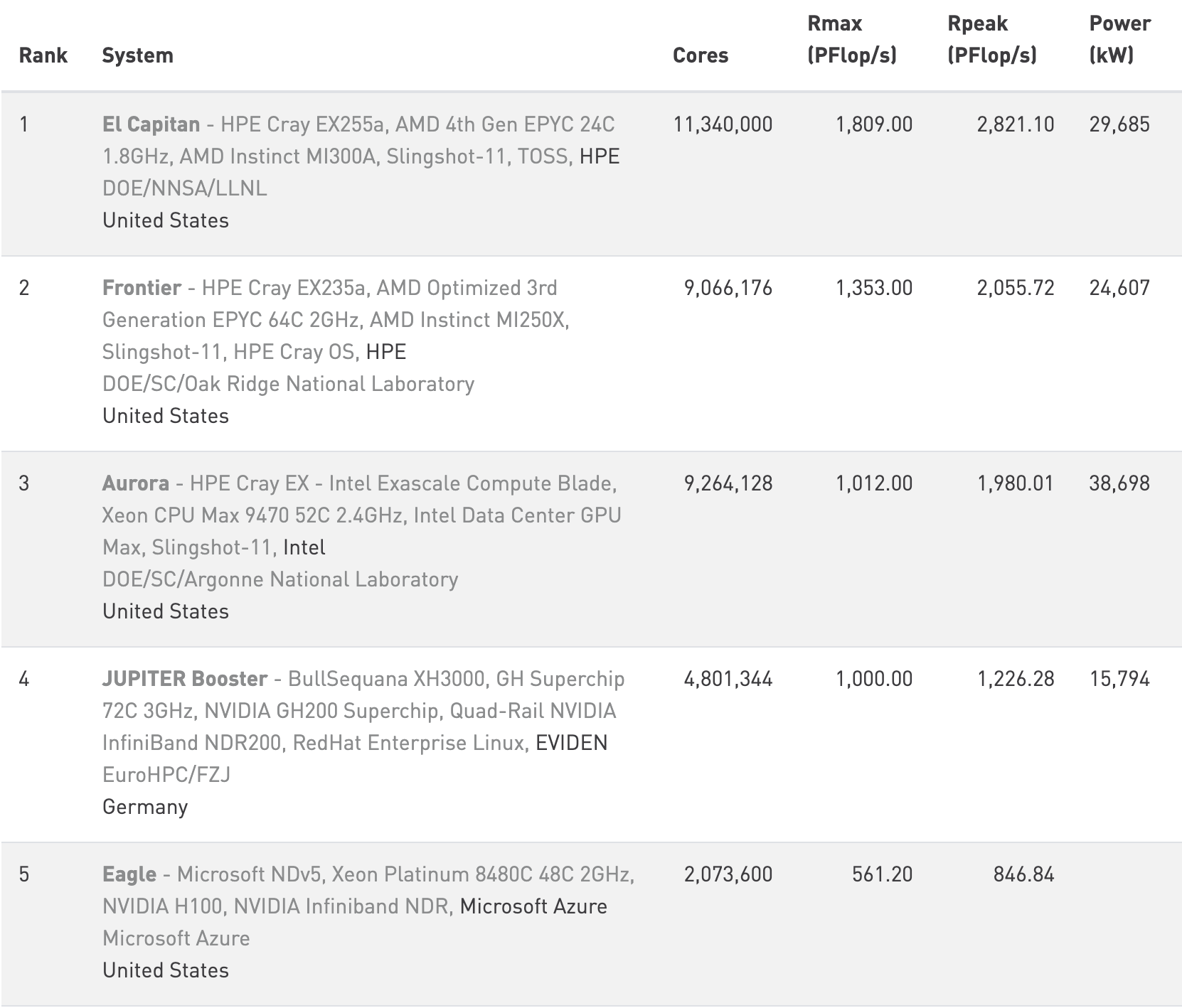
이 30년의 변화를 요약하면, 코어 수는 수백 배에서 수십만 배까지 증가했고, 성능은 수백만 배에서 수천만 배까지 향상되었다. 엄청난 발전이다!
| 1995년 상위 5개 | 2025년 상위 5개 | 변화량 | |
|---|---|---|---|
| 코어 수 | 80–3680 | 2,073,600–11,340,000 | ~563–141,750$\times$× |
| Rmax | 98.9–170 GFlop/s | 561.2–1809 PFlop/s | ~3,300,000–18,300,000$\times$× |
| 벤더 | Fujitsu, Intel, Cray | HPE, Eviden, Microsoft | — |
| 네트워크 | crossbar, mesh, torus | dragonfly[+], fat-trees | 더 높은 radix, 더 낮은 diameter |
이와 같은 백만 배 수준의 향상은, 수십 년의 시간이 흘렀다 하더라도, 상당한 노력 없이는 이루어지지 않는다. 따라서 이 기간 동안 하드웨어와 HPC 시스템 아키텍처에서 어떤 변화가 일어나 이런 거대한 향상을 만들어냈는지 돌아볼 가치가 있다. 나는 하드웨어 아키텍트는 아니지만, 내 관점에서는 주요 요인을 다음과 같이 생각하는 편이다:
이러한 변화로 인한 성능 향상을 넘어, 그것이 프로그래머에게 어떤 영향을 주었는지 생각해보는 것도 흥미롭다. 구체적으로 말해, 어떤 변화가 HPC 프로그래밍을 더 쉽게 만들었고, 어떤 변화가 더 어렵게 만들었을까? 잠시 스스로 답을 생각해 보시라. 곧 이 질문으로 돌아오겠다.
다음으로, 같은 기간 동안 지배적이었던 HPC 프로그래밍 표기법을 생각해 보자. 안타깝게도 HPC 프로그래밍에 대해 TOP500에 해당하는 명확한 지표는 없으므로, 이 글에서는 내 경험과 연구, 기억을 바탕으로 한 내 견해를 제시하겠다.
1995년 11월 당시 내 관점에서, 지배적이면서 가장 널리 채택된 HPC 프로그래밍 언어는 Fortran, C, C++였다. 스크립팅의 경우 지배적 기술은 Perl, sh/csh/tcsh, 또는 Tcl/TK로 보였다.
당시 분산 메모리 시스템을 프로그래밍하는 지배적인 방식은 MPI, PVM, SHMEM이었다 - [x] [note:여기서 내 특성화에 후견지명이 어느 정도 영향을 주는지 궁금해하는 것은 타당하다. 1995년에 MPI나 SHMEM이 정말로 “지배적”이었을까? 아니면 오늘날 그들의 장수성을 확인할 수 있기 때문에 내가 그렇게 여기는 것일까?]. High Performance Fortran (HPF)은 많은 관심과 자금을 받고 있었지만, 내 인식으로는 그것을 연구하고 개발하던 팀 밖에서 만들어진 실제 응용에서는 그리 많이 사용되지 않았다.
공유 메모리 병렬성에 대해서는, 이 시점에 OpenMP가 아직 몇 년 뒤의 일이며 1997년에 Architecture Review Board를 구성하고 1.0 명세를 발표했다는 사실을 다시 떠올리고 조금 놀랐다. 1995년에는 루프 수준 또는 스레드 수준 병렬성이 필요했다면 POSIX threads나 벤더별 컴파일러 pragma 및 마크업(예: Cray Microtasking)을 사용했을 것이다. 다만 당시 프로세서는 보통 단일 코어였기 때문에, 벡터 명령어를 지원하지 않는 한 굳이 신경 쓰지 않았을 수도 있다.
오늘날 HPC에서 널리 채택된 것을 생각해 보면, 그 목록은 실망스러울 정도로 1995년과 비슷하다. 프로그래밍 언어 측면에서는 Fortran, C, C++가 여전히 HPC 환경을 지배한다. PVM은 사라졌고 HPF는 자리잡지 못했지만, MPI와 SHMEM은 여전히 건재하며 분산 메모리 HPC 프로그래밍을 지배하고 있다. 1997년 출범 이후 OpenMP는 공유 메모리 프로그래밍에서 빠르게 지배적인 위치를 차지했고 오늘날까지 그 지위를 유지하고 있어, 지난 30년의 대부분 동안 핵심 기술로 자리해 왔다. C++ 라이브러리 기반 표기법인 Kokkos는 지난 10년가량 동안 HPC 채택 측면에서 의미 있는 진전을 이룬 몇 안 되는 프로그래밍 모델 중 하나이며, 공유 메모리 병렬성에서 OpenMP의 대안 역할을 한다.
1995년 이후 HPC 프로그래밍 표기법에서 가장 큰 변화는 HPC 시스템에 GPU가 도입되고, 그 결과 GPU를 프로그래밍해야 할 필요가 생기면서 일어났다. 불행히도 1995년대의 어떤 기술도 GPU를 대상으로 삼기에 충분하지 않았고, 그 공백을 메우기 위해 수많은 새로운 기술이 만들어졌다. 이들은 CUDA, HIP, SYCL, OpenACC, OpenCL, Kokkos와 같은 언어 확장과 라이브러리의 형태로 등장했다. OpenMP 같은 다른 기술도 GPU를 지원하기 위해 크게 진화했으며, 그 과정에서 본질적으로 조금 더 명령형이 되었다.
스크립팅 영역에서는 Python이 Perl과 Tcl/TK를 크게 대체했고, bash는 일반적으로 sh, csh, tcsh를 대신해 지배적인 셸 스크립트 언어가 되었다.
“
지난 30년 동안 HPC 하드웨어는 훨씬 더 강력해졌지만, 실제로 사용되는 HPC 표기법은 대체로 그대로 머물렀다. 특히 우리는 새로운 컴파일형 프로그래밍 언어를 폭넓게 채택하는 데 실패했다.
”
요약하자면, 30년 전과 오늘날 널리 채택된 HPC 프로그래밍 표기법은 다음과 같다고 보겠다:
| Category | 1995 Notations | 2025 Notations |
|---|---|---|
| Languages | Fortran, C, C++ | Fortran, C, C++ |
| Inter-node | MPI, PVM, SHMEM | MPI, SHMEM |
| Intra-node | Pthreads, vendor extensions (with OpenMP on the horizon) | Pthreads, OpenMP, Kokkos |
| GPUs | N/A | CUDA, HIP, SYCL, OpenMP, OpenACC, OpenCL, Kokkos |
| Scripting | Perl, sh/csh/tcsh, Tcl/TK | Python, bash |
따라서 지난 30년 동안 HPC 하드웨어는 훨씬 더 강력해졌고, 그 결과 시스템 성능, 효율성, 확장성 면에서 놀라운 도약이 있었지만, 실제로 사용되는 HPC 표기법은 GPU 컴퓨팅의 도입을 제외하면 대체로 그대로였다 - [x] [note:Fortran, C++, MPI 또는 이 목록의 다른 항목을 옹호하는 사람들은 이름은 같아도 기술 자체는 지난 30년 동안 크게 진화하고 개선되었다고 주장할 수 있다. 예를 들어 Fortran 2008은 분산 프로그래밍을 지원하도록 발전했고, C++는 공유 메모리 병렬성을 위한 기능을 추가했다. 이런 발전은 중요하고 주목할 만하지만, 내가 보기에는 이러한 모델이 사용자에게 제시하는 전반적 패러다임은 여전히 매우 비슷하며, 보다 현대적인 대안에 비해 SPMD 프로그래밍 모델, 명시적 통신, 상대적으로 저수준의 기반 언어에 의존하고 있다.]. 아마 가장 눈에 띄는 점은, 공동체로서 우리는 HPC를 위한 어떤 새로운 컴파일형 프로그래밍 언어도 폭넓게 채택하지 못했다는 사실일 것이다.
지난 30년 동안 큰 도약을 이루지 못했을 뿐 아니라, 하드웨어 복잡성이 증가하면서 HPC 프로그래밍은 오히려 뒤처졌다고도 볼 수 있다. 위에 나열한 하드웨어 변화들 중 대부분은 프로그래밍을 더 어렵게 만들었다. 벡터 명령어, 멀티코어 프로세서, GPU는 프로그래머가 프로세서를 효과적으로 사용하려면 표현해야 하는 새로운 병렬성 양식을 도입했다. 한편 CPU당 코어 수의 증가, chiplet 기반 설계, GPU는 NUMA(Non-Uniform Memory Access) 특성을 도입하여, 프로그래머가 데이터 배치와 affinity에 훨씬 더 민감해야 하도록 만들었다.
“
우리 하드웨어 발전의 대부분이 과거의 프로그래밍 표기법을 새로운 접근법으로 보완하도록 요구해 왔다는 사실은, 우리의 프로그래밍 모델이 목표 하드웨어로부터 충분히 추상화되지 않았음을 시사한다.
”
실제로 내 목록의 하드웨어 발전 중 프로그래밍 가능성 측면에서 분명한 이점이라고 할 수 있는 것은 고-radix, 저-diameter 네트워크뿐이라고 생각한다. 이는 1990년대에 비해 네트워크 토폴로지에 대한 민감성이 훨씬 덜 중요해졌기 때문이다. 당시 HPC 프로그래머들은 특정 네트워크 토폴로지—예를 들면 mesh, hypercube, 또는 ring-of-rings—에 맞춰 최적화하는 데 흔히 노력을 기울였다. 다행히 오늘날에는 이런 걱정이 훨씬 드물고, 어느 노드들이 통신하는지의 세부 사항보다는 “로컬 대 원격”이 주된 문제가 되는 경향이 있다.
우리 하드웨어 발전의 대부분이 과거의 프로그래밍 표기법에 새로운 기능이나 접근법을 추가하도록 요구해 왔다는 사실은, 우리의 프로그래밍 모델이 목표 하드웨어로부터 충분히 추상화되지 않았음을 시사한다. 논쟁의 여지는 있겠지만, 만약 이들이 더 범용적이고 하드웨어 중립적인 방식으로 병렬성과 locality를 표현할 수 있었다면 - [x] [note:내가 “locality를 표현한다”고 말할 때는 “이 데이터는 어디에 할당되어야 하는가?”, “이 태스크는 어디에서 실행되어야 하는가?”, “이 데이터는 어디에 할당되어 있는가 / 이 태스크는 어디에서 실행 중인가?”와 같은 것을 제어하고 추론할 수 있는 능력을 뜻한다. 이에 대한 답은 “컴퓨트 노드 X 위”, “GPU Y”, “메모리 Z”일 수 있다. 이런 제어는 분산 시스템에서 성능과 확장성을 위해 매우 중요한 경향이 있다.], 우리는 C++, MPI, OpenMP 및/또는 CUDA 같은 프로그래밍 표기법을 뒤섞어 프로그램을 작성할 필요가 없었을 것이다.
위 요약 표의 ‘Languages’ 행에 초점을 맞추면, 지난 30년 동안 왜 새로운 프로그래밍 언어가 HPC에서 폭넓게 채택되지 않았는지 추측해 보는 것은 흥미롭다. 여기 몇 가지 가능한 설명과, 내가 왜 그것들이 반드시 설득력 있다고 생각하지 않는지를 적어보겠다.
그 이유가 언어 설계가 죽었기 때문일까? 약 30년 전 우리 팀 논문 하나에 대한 익명의 리뷰어가 그렇게 주장했듯이 말이다.
“Programming language design ceased to be relevant in the 1980’s.”
— Anonymous reviewer, circa 1995 (paraphrased, from memory)
HPC 바깥의 프로그래밍을 보면, 답은 분명히 “아니오”인 듯하다. 구체적으로, 지난 30년 동안 수많은 새로운 언어가 등장하거나 주류에서 두드러진 위치로 올라섰다. 예를 들면 다음과 같다:
이런 언어들은 여러 분야의 많은 사용자들에게 일상적으로 선호되는 언어가 되었고, 이는 언어 설계가 결코 죽지 않았음을 시사한다.
더 나아가, 이런 언어 설계를 자극한 동기와 그것들이 자리잡은 이유를 살펴보면 생산성, 안전성 - [x] [note:여기서 “안전성”은 타입 안전성, 메모리 안전성, 병렬 안전성을 모두 포괄하는 넓은 의미로 사용한다.], 이식성, 성능 같은 주제가 반복해서 등장한다. 이것들은 HPC 프로그래머에게도 매우 중요하고 바람직한 요소들이다:
| Language | Productivity | Safety | Portability | Performance |
|---|---|---|---|---|
| Java | ✔ | ✔ | ||
| Javascript | ✔ | ✔ | ||
| Python | ✔ | |||
| C# | ✔ | ✔ | ||
| Go | ✔ | ✔ | ||
| Rust | ✔ | ✔ | ||
| Julia | ✔ | ✔ | ||
| Swift | ✔ | ✔ | ✔ |
“잠깐만… 언어 _____ 이 _____ 하지 않다고 주장하는 건가요?” (자세히 보려면 클릭)
일부 독자는 이 표를 보고, 어떤 언어에 체크 표시가 없으면 내가 그 언어를 비생산적이거나, 안전하지 않거나, 이식성이 없거나, 성능이 없다고 여긴다는 뜻으로 해석했다. 하지만 그것은 내 의도가 아니었다. 다만 표로 들어가는 문단에서 그 점을 충분히 분명하게 하지 못했을 수도 있다. 분명히 하자면, 체크 표시는 내가 이해하기로 그 언어가 설계되었거나 성공을 거둔 주된 이유를 나타내기 위한 것이다.
예를 들어, 나는 Julia를 Python 또는 Matlab 수준의 생산성을 제공하면서도 Fortran, C, C++ 수준의 성능을 제공하도록 설계된 언어라고 본다. 그리고 이 요소들이 Julia가 인기를 얻은 주된 이유이기도 하다고 생각한다. 그래서 그 두 열에 체크 표시를 했다. 그렇다고 해서 Julia가 안전성이나 이식성을 중시하지 않는다는 뜻도 아니고, 그런 우려를 고려하지 않고 설계되었다는 뜻도 아니다. 다만 내가 보기에는, 그것이 개발되고 자리잡게 된 주된 이유는 앞선 언어들의 안전성이나 이식성 결함을 해결하려는 데 있지는 않았다.
여기에는 분명 어느 정도 주관성이 있고, 내 지식에 공백이 있을 수도 있으며, 독자들이 동의하지 않는 경우 피드백을 환영한다.
이러한 주제적 공명에도 불구하고, 이 언어들은 적어도 MPI 같은 다른 기술을 계속 섞어 쓰지 않는 한 HPC에 특별히 준비되어 있지는 않다. 대부분이 동시성, 병렬성, 비동기성을 위한 내장 기능을 제공하긴 하지만, HPC에서 확장 가능한 성능에 결정적인 locality나 affinity 제어에 대해서는 거의 또는 전혀 도움을 주지 못한다. 그리고 바로 이 지점이 기존 HPC 표기법이 사용자에게 가장 큰 골칫거리를 주는 부분이라고 할 수 있다.
또 다른 설명은, 사실 HPC에는 새로운 언어가 필요 없고 Fortran, C, C++가 somehow HPC에 최적이라는 것일 수 있다. 하지만 이 언어들의 단점들을 생각해 보면, 그리고 주류 분야에서는 이들이 보다 현대적인 대안에 의해 대체되고 있거나 이미 대체되었다는 사실을 보면, 이는 진지하게 받아들이기 어렵다.
Fortran, C, C++가 HPC에 _충분하다_고 말하는 것은 분명 타당하다. 지난 30년 동안 주목할 만한 대부분의 HPC 계산이 실제로 이 언어들(라이브러리, 지시문, 확장과 함께)을 사용해 달성되었기 때문이다. 하지만 내게 그것은 1950년대의 어셈블리 프로그래머들이 사실 Fortran을 _필요로 하지 않았다_고 말하는 것과 조금 비슷하다. 어셈블리만으로도 충분했을 수는 있지만, 더 깔끔한 문법과 의미론적 검사, 그리고 컴파일러 최적화를 가능하게 하는 더 높은 수준의 추상화로 올라가는 것은 돌이켜보면 분명히 올바른 진화의 다음 단계였다.
“
오늘날의 프로그래머들은 레지스터로 값을 직접 옮겨 넣고 꺼내야 한다면 충격을 받을 것이다. 우리는 그와 비슷하게 노드 간, 혹은 GPU와 CPU 메모리 간 데이터 전송을 처리해 주는 언어와 컴파일러를 지향해야 한다.
”
Fortran 비유를 이어가면, 그 핵심에서 대부분의 HPC 표기법은 꽤 메커니즘 지향적이다:
“각 코어/노드/소켓에서 이 프로그램의 복사본을 실행하라”
“개념적으로 하나로 통합된 이 데이터 구조의 일부를 여기에 할당하라”
“이 메시지를 여기서 보내고 저기서 받아라”
“이 커널을 가속기에서 실행하라”
이 점이 바로 시스템 아키텍처가 진화할 때마다 새로운 표기법을 계속 추가해야 하는 큰 이유라고 볼 수 있다. HPC 프로그래밍이 문자 그대로 어셈블리는 아니지만, 시스템 기능의 사용을 수작업으로 지시하는 데 초점을 맞춘다는 점에서는 비슷하다. 또한 메모리 계층을 따라 데이터를 명시적으로 이동시킨다는 점에서도 유사하다. 다만 예전과는 다른 수준에서 그럴 뿐이다. 어셈블리 프로그래머가 메모리와 레지스터 사이로 값을 옮겼다면, HPC 프로그래머는 MPI_Send/Recv(), shmem_put(), cudaMemcpy() 같은 다양한 메커니즘을 사용해 서로 다른 메모리 사이의 복사를 표현한다.
좋은 언어는 Fortran이 어셈블리에 대해 제공했던 것과 비슷한 이점을 HPC 분야에 가져다줄 것이다. 즉, 생산성을 위한 더 나은 문법, 안전성을 위한 의미론적 검사, 성능을 위한 컴파일러 최적화다. 오늘날 대부분의 현대 프로그래머가 값을 레지스터에 직접 넣고 빼야 한다고 하면 놀라움을 금치 못하듯, 우리는 미래의 HPC 프로그래머들이 노드 간 또는 GPU와 CPU 메모리 간의 데이터 전송을 언어와 컴파일러가 처리해 준다는 사실에 자연스럽게 반응하게 만들 언어와 컴파일러를 지향해야 한다.
Fortran 비유는 프로그래머의 태도에도 이어진다. 어셈블리 프로그래머가 자신의 제어권을 포기하고 최적화 컴파일러를 믿는 데 주저했던 것처럼, HPC 프로그래머도 자신의 Fortran, C++, MPI를 포기하는 데 주저해 왔다. 그리고 그럴 만한 이유도 있다! HPC에서는 제어권이 중요하다. 왜냐하면 그것이 이론상 시스템의 날것의 기능에 아무 방해 없이 접근할 수 있게 해주기 때문이다. 하지만 Fortran이 필요할 때 어셈블리로 내려갈 수 있는 능력을 없애지 않았듯이, 좋은 HPC 언어도 마찬가지로 기존의 저수준 표기법을 호출하거나 직접 내장할 수 있도록 지원해야 한다.
새로운 HPC 언어가 자리잡지 못한 세 번째 설명은, 이를 만들려는 시도가 부족했기 때문이라는 것일 수 있다. 하지만 지난 30년의 HPC 연구를 지켜본 사람이라면 누구나 알듯, 이는 분명 사실이 아니다. 내가 보기에 지난 30년간 가장 주목할 만한 HPC 프로그래밍 언어 설계를 중심으로 보면 다음과 같은 것들이 있다:
90년대 중후반의 고전들:
PGAS의 창립 멤버들:
HPCS 시대의 언어들:
HPCS 이후의 언어들:
내장형 의사 언어들:
그리고 이 외에도 훨씬 더 많은 시도가 있었다.
이 목록을 만들면서, 이 모든 시도가 폭넓은 채택에 적합했다는 뜻을 전하려는 것은 아니다. 개인적 예를 들면, 나는 대학원 시절 우리 팀의 ZPL 작업이 중요한 기여를 한 훌륭한 학술 프로젝트였다고 생각하지만, 여러 이유로 폭넓게 채택될 위치에 있던 언어는 아니었다 - [x] [note:그 이유 중에는 일반성의 부족, 객체 지향 프로그래밍 같은 흔한 주류 기능의 부족, 당시 다가오던 아키텍처에 비해 충분히 풍부하지 않은 병렬성 형태, 그리고 더 낮은 수준에서 프로그래밍하거나 다른 언어와 상호운용할 능력의 부족 등이 있었다.].
지금까지 새로운 HPC 언어를 폭넓게 채택하는 데 실패했다고 해서, 우리가 시도 자체를 멈춰야 한다는 뜻은 아니다. 실패는 HPC 언어를 추구하는 일이 무의미하거나 가치 없다는 “증거”가 아니라, 배움과 영감을 위한 기회로 받아들여야 한다.
내 생각에 HPC 프로그래밍 언어의 상대적 정체는 여러 요인의 결과다:
내게 이것은 HPC 지향 프로그래밍 언어를 개발하지 말아야 할 이유라기보다, 오히려 그래야 할 이유에 더 가깝다. 하지만 동시에 현 상태를 설명하는 데도 도움이 된다고 생각한다. 우리가 분산 메모리 병렬성에 관심을 갖는 몇 안 되는 공동체 중 하나이기 때문에, 더 큰 다른 공동체가 우연히 우리의 문제를 해결해 주는 언어를 개발해 줄 가능성은 낮다. HPC는 지난 수년간 Java, Map-Reduce, Python, Javascript 같은 인기 있는 주류 기술을 활용해 자신의 요구를 충족하려고 시도해 왔지만, 이들 중 극소수만이 HPC가 요구하는 이식성, 성능, 확장성, 제어의 조합을 달성했다.
HPC의 삶의 현실은, Fortran, C, C++ 같은 언어로 작성된 크고 오래 살아남는 코드가 많고 여전히 중요하다는 점이다. 이런 코드는 사람들의 ذهن 속에 그 언어들을 계속 최전면에 두게 만들고, 때로는 우리가 새로운 언어를 채택할 수 없다는 믿음으로 이어진다. 하지만 이는 새로운 언어가 레거시 언어와 상호운용할 수 있고, 심지어 폴백으로 그것을 사용할 수도 있다는 점을 무시한다. 이는 Fortran이나 C 프로그래머가 핵심 커널에 어셈블리를 사용했던 것과 비슷하다. 또한 새로운 응용을 현대 기술로 작성하거나 오래된 응용을 다시 쓰는 이점도 간과한다.
내 인식이 편향되었을 수도 있지만, HPC 공동체의 예산과 초점(예: 연구비 공모, 상, 기조연설자 등)은 사용자 대면 소프트웨어보다 새로운 하드웨어, 시스템, 아키텍처에 훨씬 더 많은 비중을 두는 경향이 있다. 어느 정도는 이런 편향이 불가피할 수도 있다. 역사적으로 HPC를 독특하게 만든 것이 하드웨어였기 때문이다. 하지만 소프트웨어 없이는 하드웨어도 거의 사용할 수 없고, 소프트웨어에 더 투자하지 않음으로써 우리는 소프트웨어가 주된 관심사가 아니라 늘 뒷전으로 남는 악순환을 만든다. 게다가 HPC 소프트웨어에 대한 투자는 여러 세대의 하드웨어를 거치며 누적될 수 있는 반면, 하드웨어는 새로운 네트워크 토폴로지, 프로세서 아키텍처 등이 등장할 때마다 거의 다시 출발해야 하는 경우가 많았다는 점에서 더 안타깝다.
앞선 지점의 큰 영향 때문에, 우리의 프로그래밍 표기법은 대체로 상향식 접근을 취한다. “이 새로운 하드웨어는 무엇을 하며, 그것을 C/C++에서 프로그래머에게 어떻게 노출할 수 있을까?” 그 결과가 바로 오늘날 우리가 가진 C++, MPI, OpenMP, CUDA 같은 표기법의 뒤섞임이다. 이들은 시스템을 프로그래밍할 수 있게 해 주고, 그렇게 하기에는 충분하지만, 대상 하드웨어의 세부를 추상화해 주는 더 고수준 접근과 비교하면 여전히 아쉬움이 많다.
첫 번째 지점과 관련해, 우리가 원한다 하더라도 우리만의 언어를 유지할 수 없는 공동체라는 어떤 감각이 있다. 나는 그런 회의론을 어느 정도 이해하지만, 그것은 필연이라기보다 우리의 사고방식, 투자, 선택의 산물이라고 생각한다. 생각해 보라. 이 30년 동안 우리는 HPC와 병렬성이 극히 일부 프로그래머에게만 उपलब्ध하던 시대에서, 모든 프로세서가 병렬성을 지원하고 모든 클라우드 제공자가 기꺼이 HPC와 유사한 시스템 시간을 판매하는 시대로 옮겨왔다. 동시에 AI 데이터센터는 점점 전통적인 HPC 센터보다 더 거대해지고 있다. 역사적 의미에서 HPC가 “틈새”일 수는 있어도, 병렬 계산을 수행하는 능력은 어디에나 있으며 그 필요성도 커지기만 하는 듯하다. 그러므로 우리는 스스로를 언어를 가질 자격이 없거나 가질 수 없는 존재로 보지 말고, 유익한 방향으로 이끌 기회를 잡아야 한다.
이것은 아마 공동체가 직면한 가장 큰 도전 중 하나일 것이다. 위에서 언급한 하드웨어와 소프트웨어 사이의 자금 불균형을 믿는다 하더라도, HPC 소프트웨어 연구를 위한 기회 자체는 그럼에도 풍부했다. 하지만 더 부족하게 느껴지는 것은, 특히 연구에서 생산 단계로 넘어갈 때 시간이 지나도 HPC 소프트웨어를 지속할 경로를 제공하는 일이다. 내 경력 초기에, Argonne National Laboratory의 MPICH 그룹이 MPI가 이미 지배적이고 핵심적인 기술이었고 MPICH가 가장 중요한 구현이던 시기에 겪던 자금 문제를 알게 되었을 때 나는 충격을 받았다. 만약 우리가 HPC 소프트웨어를 오직 연구 활동으로만 취급한다면, 우리는 결코 최소한을 넘어설 수 없고, 점진적이거나 벤더별 해결책에 갇힐 가능성만 높인다.
이 모든 것에 더해, 모든 새로운 언어가 마주하는 일반적인 사회적 채택 문제도 있다. “이 언어가 자리잡아 대중화될까, 아니면 영원히 나만 쓰게 될까?” “초기의 새로움이 사라진 뒤에도 이 언어를 계속 살려 둘 회사나 기관의 충분한 지원이 있는가?” 이런 우려는 안타깝지만 현실이며, 완전히 이해할 수 있다. 그러나 주류 프로그래밍에서는 위에서 언급했듯, 매력적이고 충분한 자금 지원을 받는 언어가 이륙에 필요한 탈출 속도를 달성할 수 있음을 볼 수 있다. 그리고 HPC 공동체에는 그런 성공 사례를 만들 능력이 없다고 단정해서는 안 된다.
90년대와 2000년대 초 HPCS 프로그램 시기에는, 확장 가능한 병렬 프로그래밍 언어에 대한 HPC 공동체의 수요가 상당했던 것으로 보인다. 그러나 시간이 지나면서 HPC 소프트웨어 엔지니어들의 성향은 프로그래밍 중심에서, 점점 기존 라이브러리에 의존하여 다른 사람이 쓴 코드를 이어 붙여 응용을 만드는 Python식 경험을 재현하는 쪽으로 이동한 듯하다. GenAI의 등장은 프로그래머와 프로그래밍이 필수적이라는 믿음을 더욱 약화시킨 것처럼 보인다. 그럼에도 나는 좋은 병렬 프로그래밍 언어 설계가 여전히 중요하다고 믿는다. 대부분의 프로그래머가 라이브러리나 AI의 사용자라 하더라도, 좋은 언어는 여전히 라이브러리를 만드는 프로그래머나 AI가 쓴 코드를 점검하고 진화시키고 유지하려는 프로그래머의 부담을 덜어 준다.
나처럼, 확장 가능한 병렬 프로그래밍을 위한 새로운 언어의 창조와 채택을 북돋우기 위해 우리가 더 많은 일을 할 수 있고 또 해야 한다고 믿는다면, 다음과 같은 일을 해보아야 한다:
HPC 공동체가 병렬 프로그래밍 언어를 뒷받침하기에는 너무 작고, 고립되어 있고, 틈새적이라고 생각하기보다는, 전통적 HPC 바깥—멀티코어 데스크톱부터 클라우드와 AI 데이터센터에 이르기까지—에서의 필요와 함께 병렬성의 편재성을 받아들여야 한다. 결국 더 작은 규모에서 병렬 컴퓨팅 공동체를 키우는 일은 더 많은 사용자에게 문호를 개방하고, HPC를 위한 새로운 사용 사례와 기회를 도입하며, 인류의 이익을 위한 더 많은 계산 과학을 가능하게 함으로써 HPC 공동체에도 도움이 될 수밖에 없다.
유망한 소프트웨어 개념이 연구에서 생산으로 전환되고 장기적으로 지속될 수 있도록 지원하는 자금 구조를 만들어야 한다. 소프트웨어에 기꺼이 돈을 지불하려는 의지는 사상 최저처럼 보이지만, 소프트웨어는 여전히 필수이며 그 자금은 어딘가에서 나와야 한다.
마찬가지로, 오픈소스 소프트웨어는 공짜로 생기지 않는다는 점을 사람들이 이해하도록 해야 한다. 오늘날 많은 HPC 소프트웨어 프로젝트가 오픈소스가 된 것은 정말 훌륭한 일이다. 이는 새로운 도구의 채택에 큰 도움이 되고, 공동체의 기여를 통해 지속적 개선도 가능하게 한다. 하지만 그것들을 유지하고, 개선하고, 다음 세대의 하드웨어(또는 시스템 수준 소프트웨어)에 이식하는 일이 많은 엔지니어링 시간을 요구하는 전일제 업무가 될 수 있다는 사실을 잊어서는 안 된다. 최근 Linux Foundation 내에 High Performance Software Foundation (HPSF)이 만들어진 것은 오픈소스 HPC 소프트웨어 프로젝트들 사이의 공동체를 만드는 데 있어 주목할 만한 진전이었다. 하지만 지속적인 재정 투자가 없다면 이런 프로젝트들을 장기적으로 어떻게 유지할지는 여전히 분명하지 않다.
응용 개발자와 소프트웨어 팀 간 상호작용을 위한 포럼을 지원하거나, 표기법 간 비교 프레임워크를 수립하는 등 HPC 소프트웨어 기술의 비교 또는 bake-off를 수행할 메커니즘을 마련해야 한다. 예를 들어 Computer Language Benchmarks Game의 HPC 버전, 갱신된 HPC Challenge 대회, 혹은 프로그래밍까지 고려하는 TOP500 스타일의 순위를 생각할 수 있다.
사용자로서 우리는 단지 통념이나 “전문가들”의 말을 이유로 기술을 너무 일찍 일축하지 않도록 스스로를 다잡아야 한다. 더 많은 것을 직접 시도해 보고, 우리 공동체가 무엇을 만들어야 하는지와 어떻게 개선되어야 하는지에 대해 스스로 의견을 형성해야 한다.
나를 알거나, 내 팀의 Chapel 언어 작업을 아는 사람들은 이 글에서 Chapel이 더 많이 언급되지 않은 것에 놀랄 수도 있고, 이것이 이 서사 속에 어떻게 들어맞는지 궁금해할 수도 있다. 이 글을 Chapel 중심으로 만들고 싶지는 않았지만, 마무리하기 전에 이 환경 속에서 Chapel의 위치를 짚고 넘어가고 싶다.
Chapel은 이 글에서 언급한, 확장 가능한 컴퓨팅에 언어가 가져다줄 수 있는 몇 가지 이점을 잘 보여주는 대표적 사례다:
보다 고수준의 언어가 더 메커니즘 지향적인 표기법보다 하드웨어 변화에 더 잘 견딜 수 있음을 보여준다. 범용 벡터 프로세서를 제외하면, Chapel은 위에 나열한 모든 하드웨어 발전, 범용 멀티코어 프로세서조차도 등장하기 전에 만들어졌다. 그러나 그 설계가 특정 하드웨어 메커니즘과 독립적으로 병렬성과 locality를 표현하는 데 초점을 두고 있기 때문에, Chapel은 그 생애 동안 일어난 HPC 컴퓨트 노드, 네트워킹, 아키텍처의 거대한 변화에 매우 잘 적응해 왔다. 이는 Chapel 자체와 그것으로 작성된 프로그램의 수명에 큰 역할을 했다.
Chapel은 Fortran이 어셈블리 프로그래머에게 그랬던 것처럼, 컴퓨트 노드와 메모리 사이의 데이터 이동을 성공적으로 추상화한다. 이를 위해 로컬 메모리에 있든 원격 메모리에 있든 관계없이 변수를 읽고 쓸 수 있게 하는 전역 네임스페이스를 사용한다. 덕분에 프로그래머는 명시적인 send, receive, put, get, mem-copy보다는 알고리즘에 집중할 수 있다.
사용자가 원할 경우 C로 내려가거나, 다른 언어 및 라이브러리와 상호운용하거나, 명시적 통신이나 복사를 수행할 수 있는 능력을 포함해 더 높은 수준 또는 더 낮은 수준의 프로그래밍을 지원한다.
알고리즘을 깔끔하게 표현하도록 돕는 기능은 컴파일러 주도 최적화도 지원한다. 이런 사례들에 대한 좋은 소개로는 Engin Kayraklioglu의 최근 HPSFCon 강연 The Case for Compiled Languages for HPC 또는 그 슬라이드를 보라.
나는 위에서 폭넓게 채택된 HPC 프로그래밍 표기법 목록에 Chapel을 넣지 않았다. 크게는 주제넘어 보이고 싶지 않았기 때문이다. 하지만 안타깝게도, 공동체 내에서 Chapel이 받는 지원이 내 목록의 다른 항목들만큼 견고하다고 보지 않기 때문이기도 하다. 그런 망설임에도 불구하고, 나는 Chapel이 여러 측면에서 그것들과 _경쟁력 있다_고 생각한다. 예를 들어 우리는 내 목록의 다른 표기법들 중 일부보다 더 큰 사용자 공동체를, 그리고 대형 기관의 마케팅에 덜 의존한 보다 자연스러운 방식으로 키워왔다고 믿는다. 안타깝게도 Chapel 사용자 대부분은 자신의 연구에서 떠오르는 언어를 시도해 볼 여유는 있지만, 그 개발 자체에 자금을 댈 위치에는 있지 않은 학술 그룹인 경향이 있다.
“
Chapel의 미래는 상당 부분 병렬 프로그래밍 공동체가 현상 유지의 대안에 대해 얼마나 의욕을 가지고 있는지, 그리고 그런 대안을 지원하려는 의지가 있는지에 달려 있다.
”
Chapel의 장기 지속성에 대한 가장 큰 위험을 생각해 보면, 그것들은 HPC 언어 설계의 정체와 관련된 위 요인들과 크게 겹친다. Chapel을 위한 연구 자금을 찾는 것은 그렇게 어렵지 않았지만, 장기적으로 사용자를 지원하고 구현을 개선하기 위한 자금을 찾는 일은 훨씬 더 어려웠다. Chapel은 비용이 많이 드는 소프트웨어 프로젝트로 여겨진다. 그리고 아마 많은 HPC 소프트웨어 팀에 비해 실제로 그랬을 수도 있다. 하지만 이는 대부분의 HPC 하드웨어 프로젝트에 비하면 미미한 수준이며, 게다가 우리는 새로운 하드웨어 세대마다 처음부터 다시 시작하는 대신 기존 투자를 계속 쌓아 왔다. 아이러니하게도, Chapel의 장수성은 다소 장애물이 되기도 했다. 우리는 더 이상 눈에 띄는 신인이 아니기 때문에, “지금쯤 세상을 뒤덮지 못했다면 뭔가 문제가 있을 것이다”라고 게으르게 생각하기 쉽고, 반대로 “꽤 오래 있었으니 아마 영원히 있을 것”이라고 생각하기도 쉽다.
한편, 정체의 일부 요인은 우리에게 이점이 되기도 한다. Chapel은 HPC의 고유한 요구를 충족하면서도 데스크톱, 클라우드, AI 컴퓨팅에서도 역할을 할 수 있다. 이제 범용 확장 가능 언어라는 타이틀을 두고 경쟁하는 다른 언어는 그리 많지 않다. 그리고 라이브러리를 위해 작성된 코드 및/또는 AI가 작성한 코드를 Chapel로 수정하거나 유지하는 것과 기존 언어로 하는 것 중에서 선택해야 한다면, Chapel에는 분명한 강점과 장점이 있다.
이 시점에서 Chapel의 미래는 주로 기여자, 이해관계자, 투자자 공동체를 얼마나 키울 수 있느냐에 달려 있으며, 이는 상당 부분 병렬 프로그래밍 공동체가 현상 유지의 대안에 대해 얼마나 의욕을 가지고 있고 그런 대안을 지원하려는 의지가 있는지에 달려 있다.
지난 30년 동안 HPC에서 새롭고 폭넓게 채택된 프로그래밍 언어가 없었다는 사실은 내게 낙담스러운 일이지만, 나는 여전히 희망을 가지고 있다. 나는 병렬성과 확장성을 위해 목적에 맞게 만들어진 언어를 사용하는 이점이 크다고 믿는다. 또한 대부분의 HPC 프로그래머가 그것을 직접 써볼 기회를 갖지 못했기 때문에, 그 이점이 대체로 알려지지 않았다고도 믿는다. 우리 프로젝트의 경험에서, 우리는 Chapel이 사용자들이 생산적이고 효율적으로 일을 해내는 능력에 미칠 수 있는 영향을 보아 왔고, 그 경험을 수십 개의 응용에서 수백, 수천 개로 확장하고 싶다.
“
나는 현재와 미래의 병렬 프로그래머가 Python, Rust, Swift, Julia 공동체만큼이나 현대적인 post-Fortran/C/C++ 언어를 누릴 자격이 있다고 생각한다.
”
마지막으로 이렇게 말하고 싶다. 새로운 HPC 언어가 채택되지 않은 모든 이유에도 불구하고, 나는 현재와 미래의 병렬 프로그래머가 Python, Rust, Swift, Julia 공동체만큼이나 현대적인 post-Fortran/C/C++ 언어를 누릴 자격이 있다고 생각한다. 또한 앞으로 30년이 더 지난 뒤에는—혹은 이상적으로는 그보다 훨씬 이전에—적어도 하나 이상의, 확장 가능한 병렬 프로그래밍을 지원하는 폭넓게 채택된 언어가 있기를 절실히 바란다. 지금 우리의 숫자는 0이기 때문이다.
Chapel 웹사이트에서는 이 글의 바탕이 된 HIPS와 CLSAC 강연의 슬라이드를 볼 수 있다. 왜 내가 모든 어려움에도 불구하고 Chapel이 폭넓게 채택되는 HPC 언어가 되기에 유리한 위치에 있다고 생각하는지 더 읽고 싶다면, 이 블로그의 10 Myths About Scalable Parallel Programming Languages (Redux) 시리즈를 보거나, 핵심 요점을 보고 흥미로운 진입점을 고르기 위해 마지막 글의 요약으로 바로 가 보라. 그리고 이 주제에 대해 더 이야기하고 싶다면, 나는 언제나 좋은 대화를 반긴다.
감사의 말: 이 글에 유익한 피드백과 조언을 준 Engin Kayraklioglu에게 감사드리고, 애초에 이 강연들을 블로그 글로 남기도록 격려해 준 점에도 감사드린다. 또한 Michael Gerndt, Amir Raoofy, 그리고 HIPS 2025 위원회에 이 강연을 원래 형태로 만들고 발표할 기회를 주신 데 대해 감사드린다.
| Date | Change |
|---|---|
| Apr 16,2026 | 초기 독자들의 질문에 응답하여 몇 가지를 더 분명히 하기 위해 새로운 details 섹션과 몇 개의 곁말을 추가함. |
![]()
![]()
![]()
![]()
![]()