하드웨어는 클록과 지연 시간보다 코어·대역폭·벡터 연산이 커졌을 뿐이다. 그 여파로 메모리·디스크, 알고리즘 직관 등 오래된 상식이 흔들리고 전통적 소프트웨어는 뒤처진다. 정체된 것과 스케일되는 것을 짚는 1부.
하드웨어는 더 빨라진 게 아니라, 더 넓어졌다. 코어 수 증가, 더 많은 대역폭, 거대한 벡터 유닛 — 하지만 클록, IPC, 지연 시간은 평탄화되었다. “메모리는 디스크보다 빠르다” 같은 오래된 규칙들이 무너지고 있다. 오늘날 빠르게 가려면 새로운 게임을 해야 한다.
지난 20년 남짓한 시간 동안 컴퓨터 하드웨어는 우리가 “알고 있다”고 믿는 몇 가지 사실을 틀리게 만들 만큼 변했다. 컴퓨터 과학자들 사이에서, 어쩌면 특히 컴퓨터 과학자들 사이에서 직관이 빗나가 있다.
간단한 명제를 생각해 보자. “CPU는 세대가 바뀔 때마다 계속 빨라진다”
완전히 틀린 말은 아니다. 컴퓨터는 분명 더 빠르고 더 강력해지고 있다. 숫자를 대보면 많은 것들이 과거에도 그랬고 지금도 지수적으로 개선되고 있음을 알 수 있다.
CPU 홍보 자료를 보면 제품 사양이 분명히 개선되고 있음을 알 수 있다. 예를 들어:
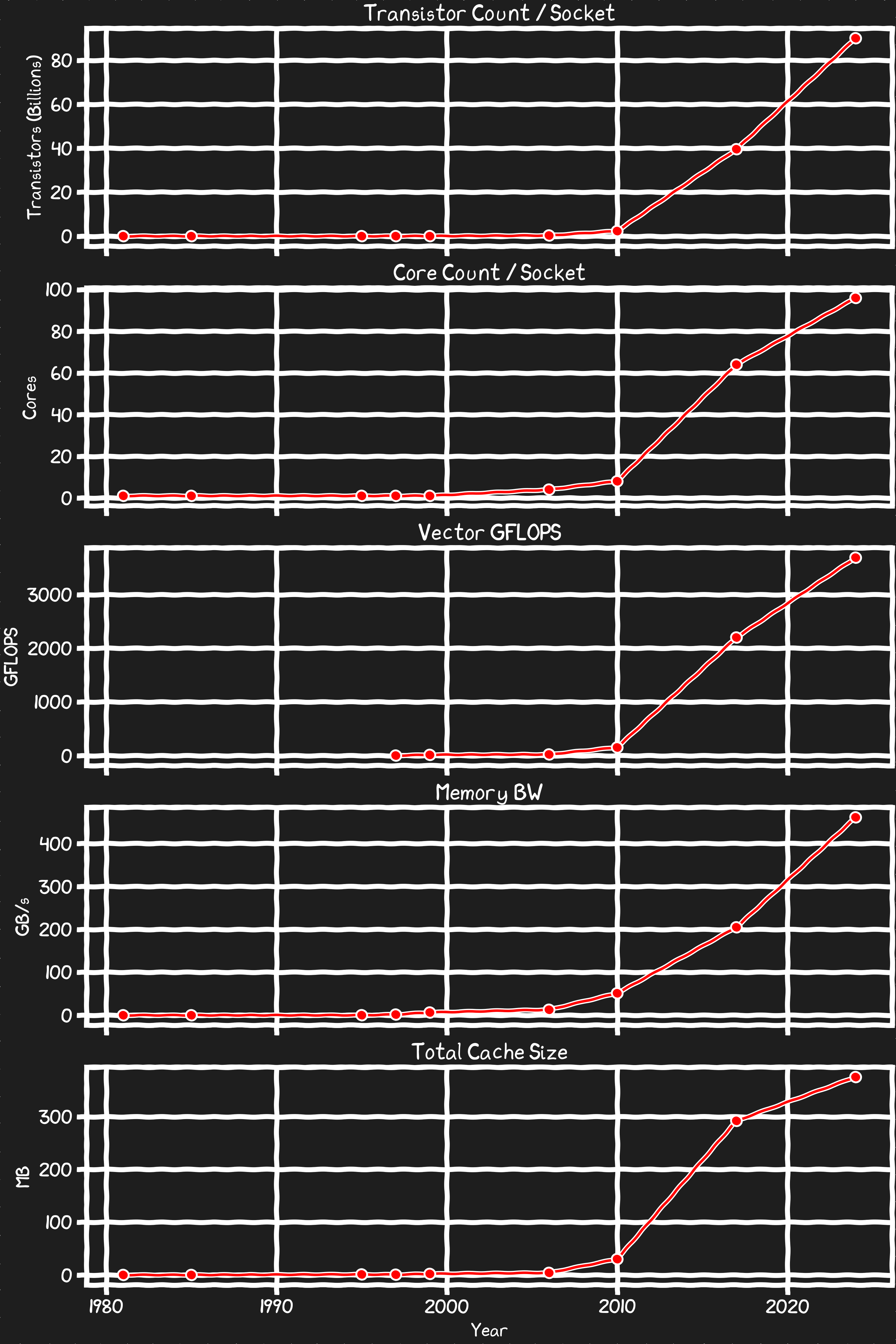
트랜지스터 수
무어의 법칙의 종말을 두고 말이 많지만, 우리는 계속해서 더 많은 트랜지스터 수를 가진 CPU를 만들고 있다. 이것이 과거처럼 코어의 선폭 축소가 아니라, 점점 더 정교한 패키징으로 실리콘을 더 많이 집어넣고 Z축으로 쌓아 올리는 데서 오는 것이든, 과거보다 두 배가 되는 속도가 느려졌든, 그게 뭐 어떤가?
코어 수
칩에서 코어 크기를 좌우하는 논리 트랜지스터는 리소그래피의 변화에 잘 맞춰 스케일링된다. 덕분에 CPU 코어 수를 늘리는 일은 복사-붙여넣기 하듯 쉬워졌다.
벡터 연산
그래픽스, 물리, AI 계산을 뒷받침하는 벡터화된 연산에서 프로세서는 매우 빠른 속도로 혁신을 거듭해 왔다. 컴파일러가 언제나 가능한 최적화를 찾아주지는 않지만, 업계는 새 하드웨어 출시와 보조를 맞춰 컴파일러와 인트린식에 새로운 벡터 명령 지원을 잘 넣어왔다. 최신 벡터 연산을 도입하면 성능 향상이 극적일 수 있다.
메모리 대역폭
업계는 꾸준한 메모리 대역폭 증가를 가능케 하는 표준을 협력적으로 개발·채택해왔다. 충분한 메모리 대역폭이 없으면 프로세서는 쉽게 멈춰 선다.
캐시
메모리가 빨라지고 있다 해도, 우리가 본 코어와 벡터 연산의 폭발을 즉각적으로 먹여 살릴 만큼은 도저히 빠르지 않다. 캐시는 과거에도, 그리고 지금도 프로세서를 생산적으로 유지하는 데 결정적이다. L1과 L2 온다이 캐시는 빠르게 커지진 않았지만 L3 이상의 캐시는 꾸준히 늘고 있다.
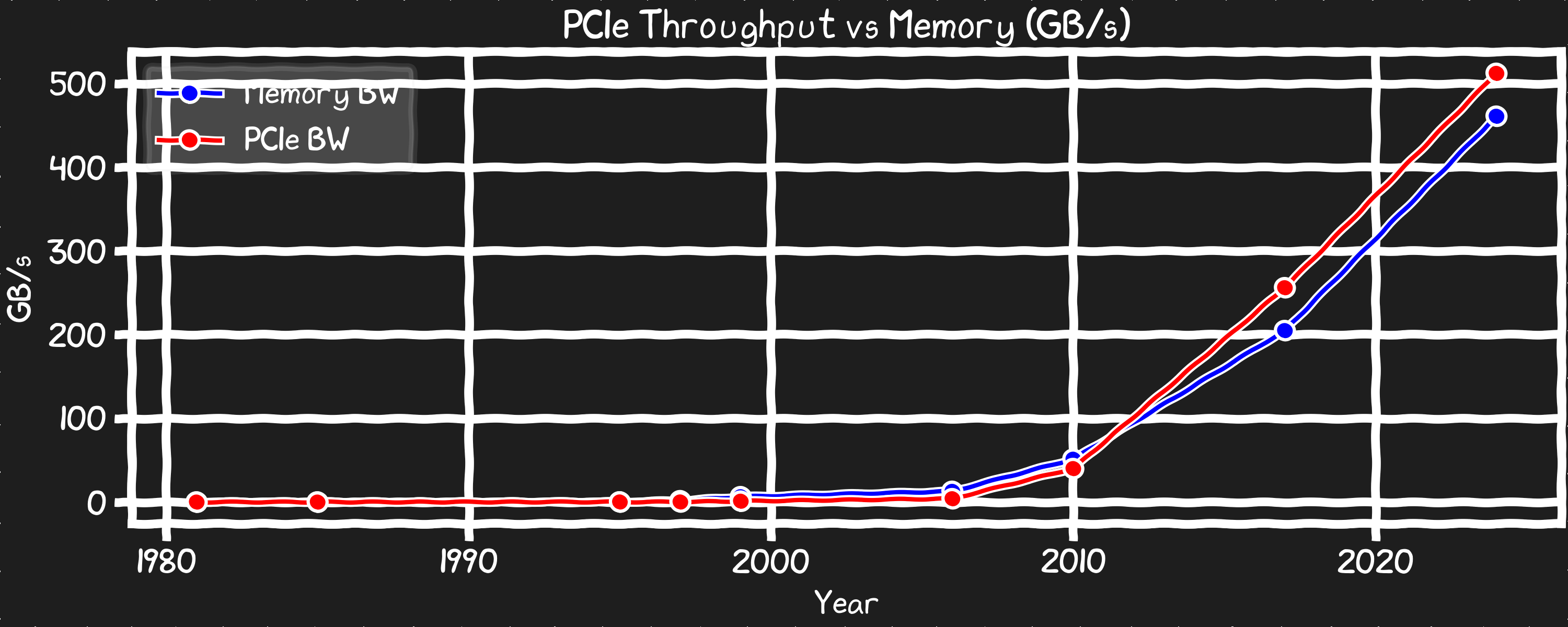
PCIe 대역폭
CPU 안팎으로 데이터를 넣고 빼는 능력은 매 세대 꾸준히 두 배씩 늘어 NVMe와 네트워킹이 보조를 맞출 수 있게 했다. 문서상으로는, 최신 서버 CPU에서 집계된 PCIe 대역폭이 RAM 대역폭보다 높다.
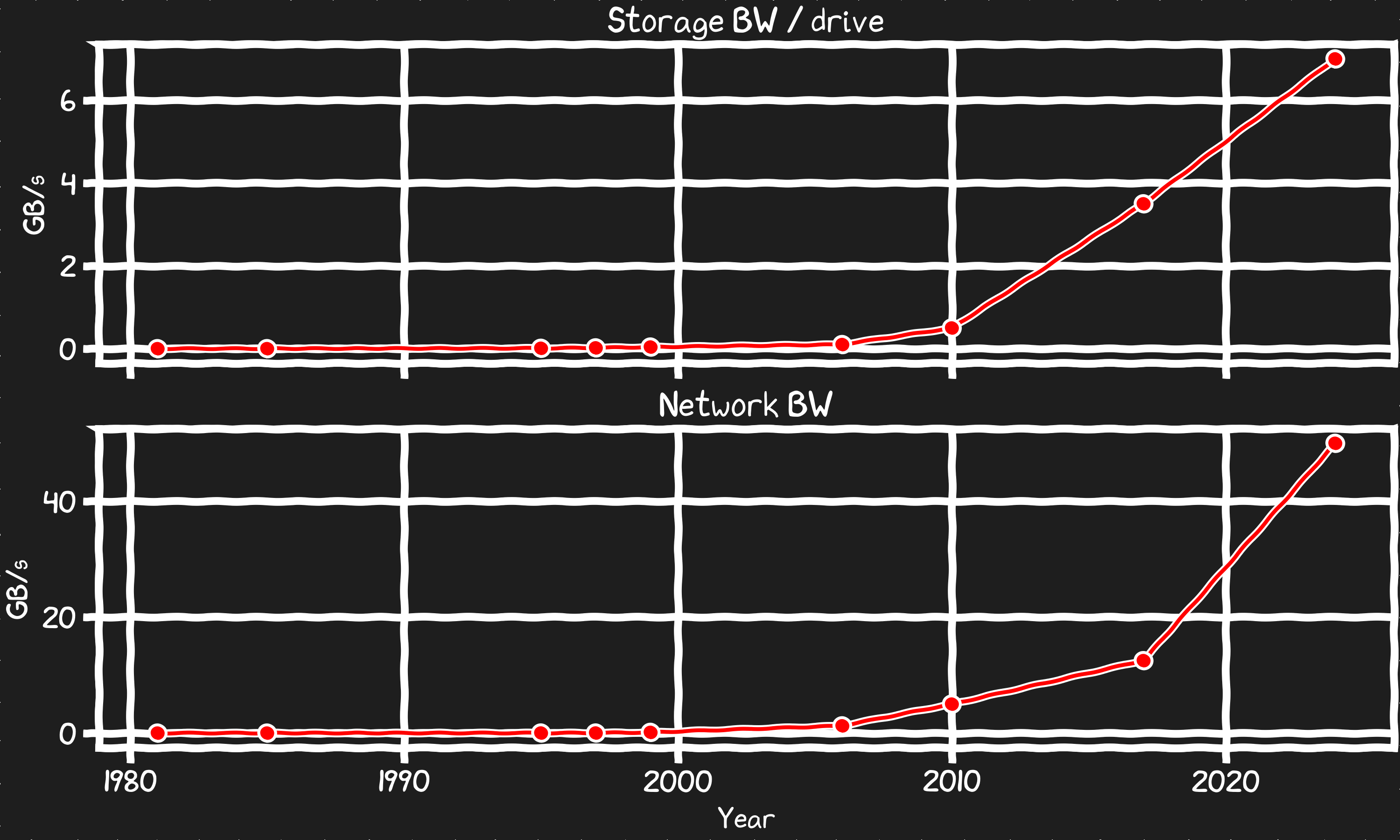
스토리지와 네트워크 대역폭
NVMe SSD는 최대 PCIe 처리량에 맞추어 설계되어 디스크를 놀라울 만큼 빠르게 만들었다. 네트워크 인터페이스 카드와 그들이 사용하는 프로토콜 또한, PCIe 버스 연결을 가능케 한 동일한 직렬 통신 개선을 바탕으로 일부 측면에서 보조를 맞춰왔다.
이 모든 지표가 2021년의 Bored Ape NFT처럼 치솟는 상황에서, “컴퓨터 하드웨어는 세대가 바뀔 때마다 계속 빨라진다”는 말에 무슨 흠을 잡을 수 있을까? 지금까지 본 바로는, 완벽히 최적화된 벡터 연산으로 병렬 계산을 하는 슈퍼컴퓨터를 만든다면 CPU는 훨씬 빨라지고 있다. 재미있는 건, 그건 주로 GPU가 하는 AI와 HPC 작업을 묘사한다는 점이다. GPU는 이런 스케일링 지표에 올인하기 때문에 이들 작업에서 그렇게 빠른 것이다. 그렇다면 “전통적인” 또는 “일반적인” 프로그램, 그러니까 단일 스레드이고 특별히 벡터 친화적이지 않은 프로그램은 어떨까? 이야기가 그리 밝지 않다.
컴퓨터 과학이 태동하던 초기 컴퓨터 혁명을 이끈 근본 요소들을 보면 수십 년간 정체되어 있음을 볼 수 있다.
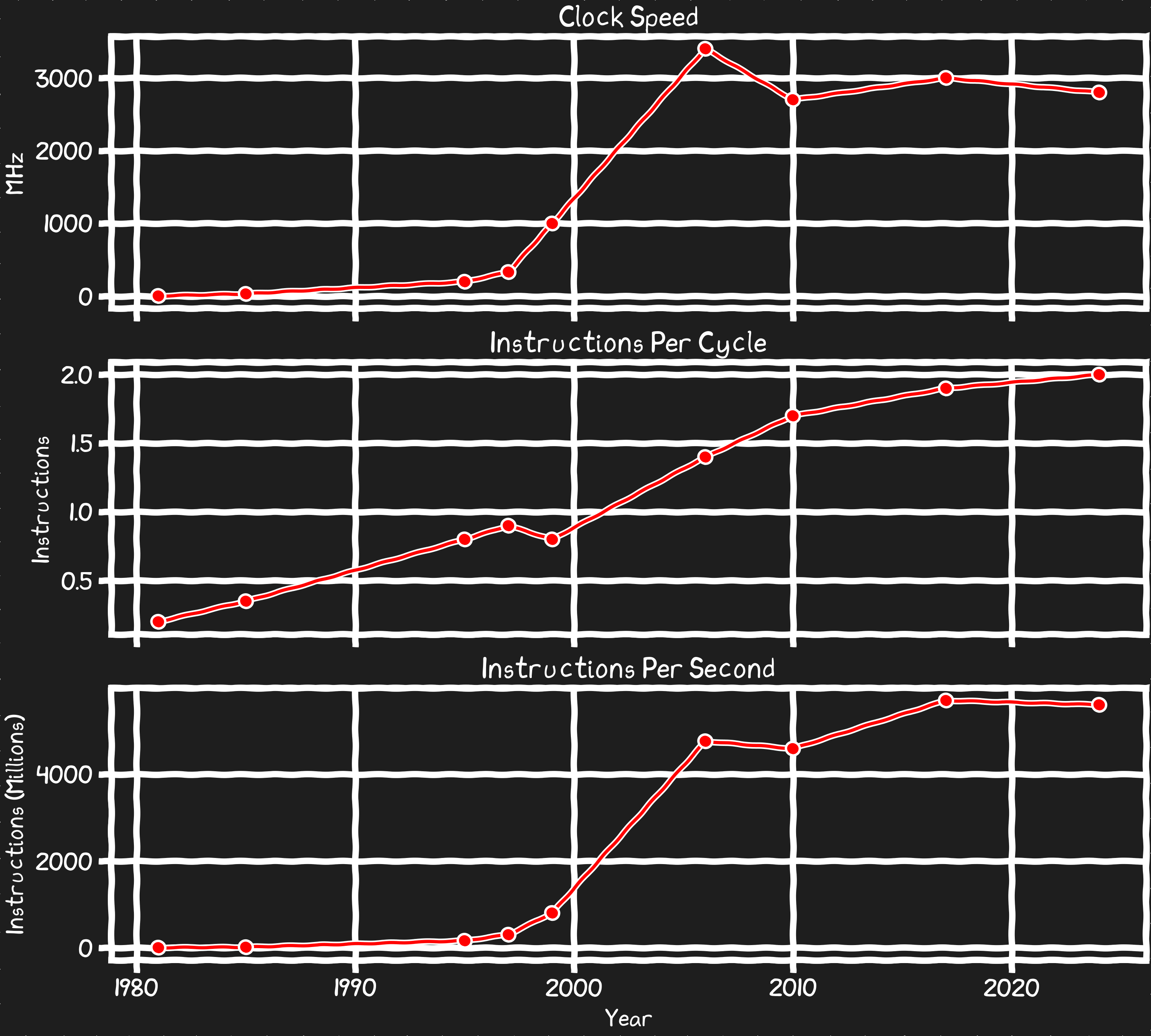
클록 속도
초기의 x86 세계에서 약 25년 동안은 세대가 바뀔 때마다 클록이 크게 빨라졌다. 이는 막대한 경쟁 우위의 원천이었고, 온갖 의미에서 당신의 컴퓨터를 더 빠르게 만들었다. 그러다 멈췄다. 실용적 클록 속도는 지난 20년 동안 크게 정체되어 있다.
클록당 명령 수(IPC)
초기 x86 프로세서는 대부분의 명령을 실행하는 데 몇 클록이 걸렸지만, 현대 프로세서는 병렬화를 통해 실제로 매 클록당 2개의 명령을 실행할 수 있게 되었다. 하지만 이는 느리게 개선되는 지표이며, 클록 속도가 스케일링되지 않는 문제를 상쇄하지 못한다. 벡터 유닛을 쓰지 않는다면, 주어진 CPU 코어가 할 수 있는 일은 지난 20년 동안 소폭만 변했다.
초당 명령 수(IPS)
클록 속도와 IPC를 함께 고려하면, 비(非)벡터 명령으로 코어가 수행할 수 있는 연산량을 볼 수 있다. 결과적인 초당 명령 수 지표는, 주어진 코어의 계산 능력이 정체되어 있음을 보다 명확히 보여준다.
메모리 지연 시간
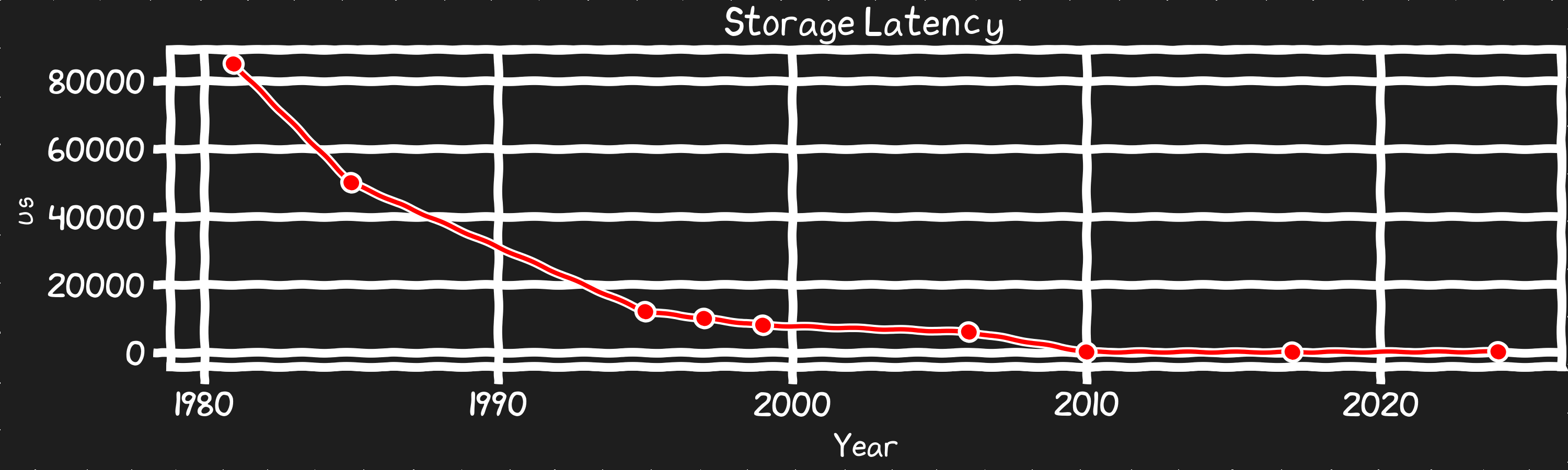
DRAM이 동작하는 핵심 메커니즘은 인터페이스와 프로토콜이 발전하는 동안에도 상당히 일정하게 유지되어 왔다. 클록 속도가 급격히 향상되던 시기에는 메모리 지연도 줄었지만, DRAM 칩의 라인을 얼마나 빨리 충방전할 수 있는가 같은 근본적 한계에 부딪혔다. 캐시 미스에서 첫 바이트를 가져오는 데 걸리는 시간은 30년째 그대로다.

문제는, 어떤 지표가 평탄화된 채로 다른 성장하는 지표에 영향을 미치면 상대적 영향이 커진다는 데 있다. 이 때문에 직관이 암시하는 것보다 어떤 연산의 비용이 훨씬 더 커진다.
예를 들어, DRAM 캐시 미스 지연을 메모리를 기다리는 동안 실행하지 못하는 명령 수라는 비용으로 다시 표현해 보자.
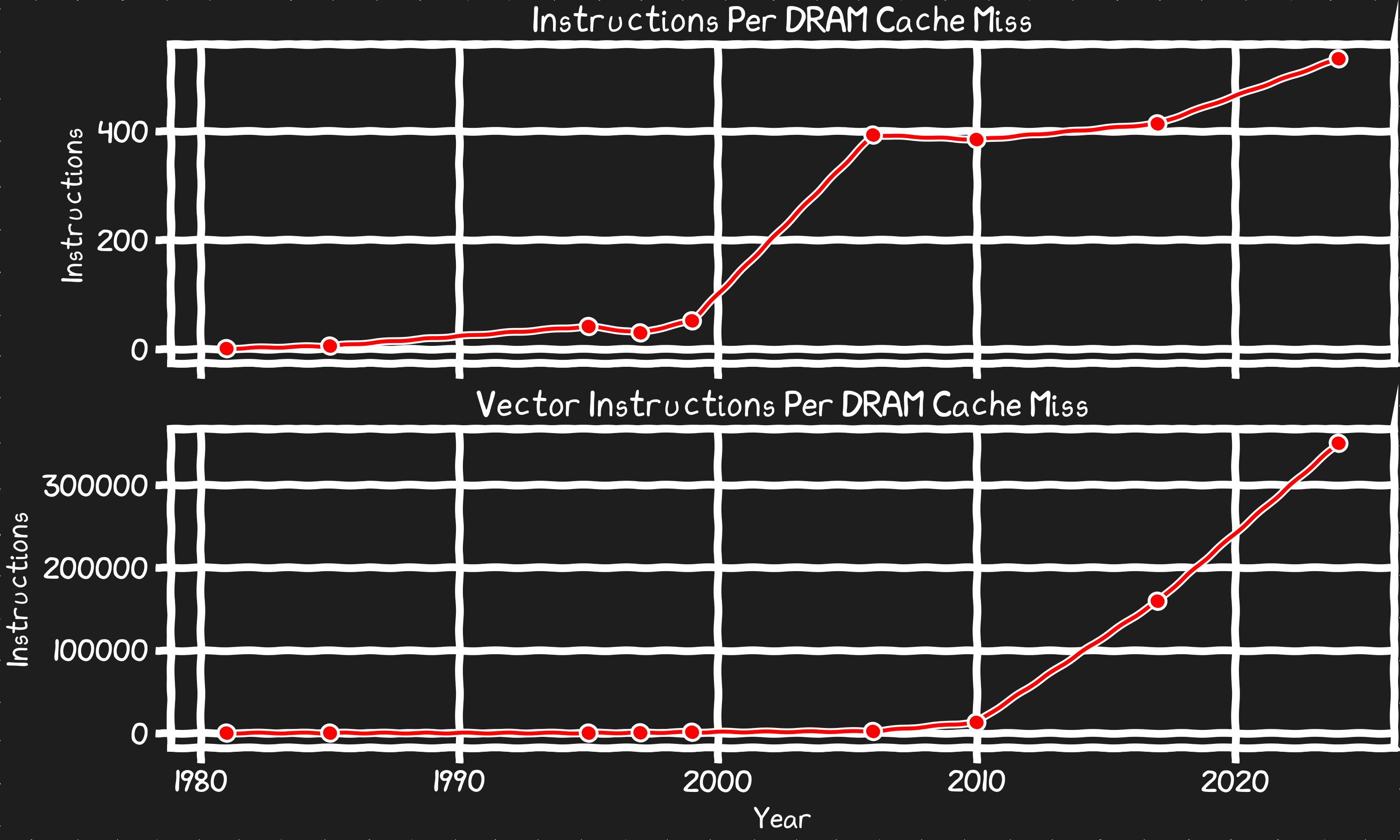
20년 전, 코어당 초당 명령 수가 정점을 찍었을 때 캐시 미스의 실질 비용이 폭증했다. 90년대에는 캐시 미스가 수십 개의 명령만 날렸지만 지금은 500개 이상이다. 이를 벡터 연산으로 환산하면, 미스가 나서 메모리에서 첫 바이트를 받아올 때까지 기다리는 동안 수행할 수 있었던 연산이 최대 350,000개에 달한다.
디스크 지연 시간 SSD는 지연 시간을 100배 줄였다. 그러나 SSD 지연 시간도 DRAM과 비슷한 이유로 정체되어 있다. 앞으로 울트라 고밀도 QLC/PLC와 SLC 고성능 제품 라인으로 제품이 차별화되며 조금 더 나쁘거나 조금 더 나은 제품을 볼 수는 있겠다. 하지만 지난 10년과 같은 자릿수 범위를 크게 벗어나지 않을 것이다. SSD가 제공하는 지연 시간 대폭 개선을 시스템이 최대한 활용하도록 최적화하는 데 남은 이점은 아직 많지만, 새로운 NAND 대체재가(옵테인이 시도했던 것보다) 더 나은 결과를 내기 전까지는 이 지표는 크게 움직이지 않을 것이다.
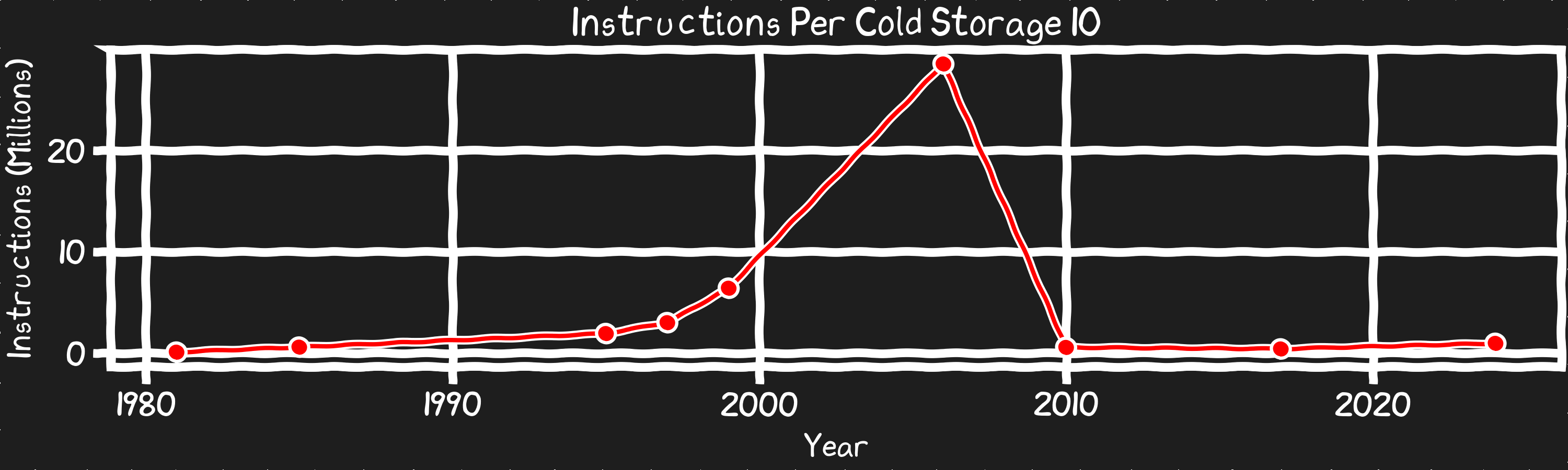
스토리지 IO의 비용을 명령 수의 관점으로 다시 보면 이야기가 달라진다. SSD라고 해도 디스크 접근 지연은 높지만, 거대한 변화가 있었다. SSD가 대중화되기 전까지는 디스크 IO를 기다리는 프로그램의 실제 영향이 크고 커지고 있었고, 대역폭은 정체되어 있었다. SSD는 지연을 50배 낮추고 그 수준을 유지하는 동안, 디스크의 대역폭은 지수적으로 증가했다. 그 결과, 디스크 접근의 영향을 완화하려고 수년간 쌓아온 습관과 노력이 이제는 성능에 도움이 되기보다 해가 되는 지경에 이르렀다.
업계는 여전히 진전을 이루고 있다. 우리는 더 많은 코어, 더 높은 대역폭, 더 많은 벡터 연산을 얻고 있다. AI는 대역폭과 병렬 연산의 게임이므로, 새 하드웨어를 온전히 활용할 수 있다. 그리고 지금 스케일링되는 것들의 성장을 막을 만한 심각한 기술적 난관도 당장 눈앞에 보이지 않는다. 쉽지는 않겠지만, 집적도·대역폭 개선과 병렬화에는 앞으로 나아갈 길이 있다.
스케일링되지 않는 것들에 대해서는? 당분간 달라질 희망이 별로 없다. 우려스러울 정도로 많은 항목들이, 지난 75년 동안 우리가 정련하고 축소해 온 핵심 기술이 물리 법칙의 한계에 다다랐기 때문에 벌어지는 일이다. 옹스트롬 단위로 재야 하는 구조에 존재할 수 있는 몇 개의 전자가 보이는 양자적 거동은 25년 전 우리가 기대던, 모델링하기 쉬운 고전적 거동과 매우 다르다. 지연 시간과 클록 속도는 물리 법칙에 의해 제한되며, 적어도 오늘날의 소재와 공정으로는 진전을 이루는 비용이 너무 크다.
그렇다면 비(非)AI 코드는 어디로 가야 할까? 이런 코드를 전통적 프로그래밍이라 부르겠다. 이는 AI가 열심히 만들어내는 앱들, 거의 모든 TypeScript 코드, 심지어 많은 시스템 소프트웨어와 운영체제 코드까지 포함한다. 이런 종류의 컴퓨팅은 본질적으로 새 하드웨어를 활용하지 못한다. 흔히 단일 스레드이고, 벡터화를 염두에 두고 작성되지 않았으며, 캐시 미스를 유발할 수 있는 분기가 많다. 과거에는 이런 코드도 하드웨어가 빨라지면 덩달아 빨라질 거라 기대할 수 있었다. 이제는 새 하드웨어가 성능을 스케일링해 줄 거라 기대할 수 없다. 과거 성능 향상을 이끌었던 클록 속도 개선 같은 것들이 정체됐기 때문이다. 캐시 크기가 늘고 CPU 아키텍처가 다듬어지면서 (아마도 세대당 5%~10% 수준의) 소폭 개선은 가능하다. 그러나 우리가 소프트웨어를 작성하는 방식을 다시 생각하지 않는다면, 대부분의 전통적 소프트웨어는 과거에 갇혀 지수적 개선을 놓치게 될 것이다.
이 정체된 지표들이 컴퓨터 과학의 도그마, 즉 경험 법칙과 모범 사례의 토대를 이룬다. 정체와 지수 성장 사이의 괴리가 누적되며 지금에 이르러 그 도그마가 틀리게 되었다. 단순히 구식이 된 것이 아니라, 어떤 것들은 정확히 반대가 되어버렸다. 심지어 컴퓨터 과학의 이론적 틀도 재검토해야 한다. 고전 역학이 양자 효과를 설명하지 못하는 것처럼, 다양한 연산의 비용이 수자릿수로 차이 난다는 사실을 고려하지 않으면 틀린 결론에 이르게 될 수 있기 때문이다.
예를 들어, 모두가 메모리에서 접근하는 것이 디스크에서 가져오는 것보다 빠르다고 안다. 하지만 위에서 설명한 요소들을 고려하면 이제는 항상 그런 것이 아니다.
만약 90년대 수준의 성능에 머무르고 억만장자의 두 번째 결혼식 비용이나 대주고 싶다면 이 연재를 무시하라. 아니라면, 정체를 피하고 지수적 성장을 활용해 성능을 끌어올리는 방법을 함께 살펴보자.
충격적인 결말을 기대하시라!
Jared Hulbert
참고:
차트에 사용한 데이터는 ChatGPT가 조사·정리한 것이며, 내가 표본 검사를 해봤을 때 서술에 충분히 정확했다. 원시 데이터