엔지니어 전원의 Claude Code 활용 현황을 가시화하기 위해, 플러그인으로 이용 데이터를 수집해 BigQuery에 적재하고 웹 대시보드로 분석·시각화한 사례를 소개한다.
📊
「모든 엔지니어가 Claude Code를 100% 활용한다」
이는 다이니의 이번 기수 목표 중 하나입니다.
솔직히 처음 떠오른 생각은 “무엇을 기준으로 100%라는 거지?”였습니다.
실마리를 찾기 위해 먼저 팀 전원에게 설문을 했습니다.
결과는 제각각이어서, “상당히 잘 활용하고 있다”는 사람도 있었고, “스킬이나 서브 에이전트는 거의 쓰지 못하고 있다”는 사람도 있었습니다.
그중에서도 가장 많았던 목소리는 “다른 사람들이 어떻게 활용하는지 모르겠다”였습니다.
실제로 자원자가 스킬이나 서브 에이전트를 만들어도, 그 존재 자체를 모르는 멤버가 있습니다. 알고 있어도 내용이 무엇인지 몰라서 못 씁니다. 결국 만든 본인만 쓰다가 그대로 묻혀 버립니다. 그런 상태였습니다.
이건 “활용도” 이전의 문제입니다.
애초에 무엇을 쓸 수 있는지, 누가 어떻게 쓰고 있는지가 보이지 않으면 활용도를 정의할 수 없습니다.
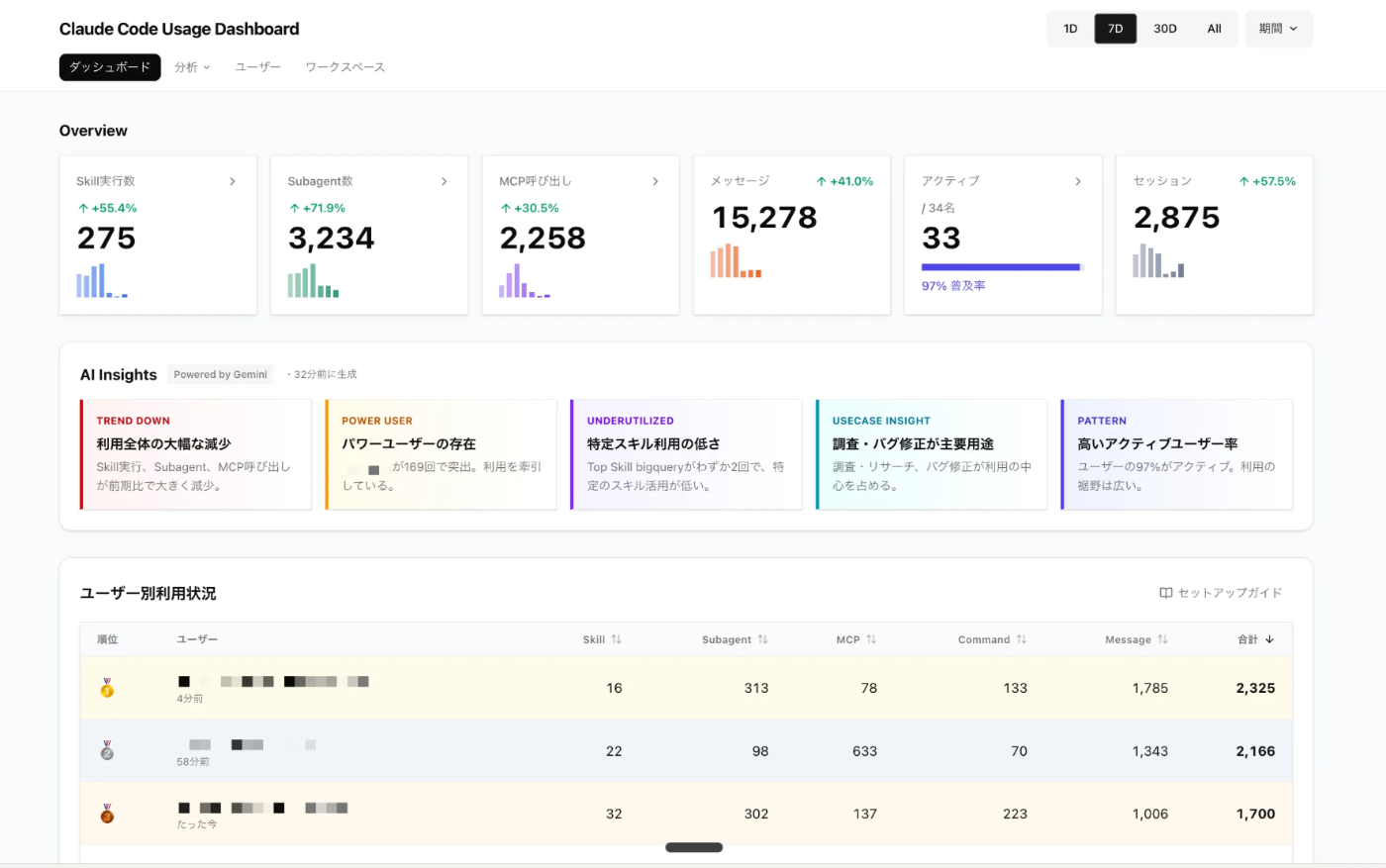
그래서 만든 것이, 엔지니어 전원의 Claude Code 활용 상황을 가시화하는 대시보드입니다.
이 구성을 Claude Code를 사용해 하루 조금 넘는 시간에 만들었습니다.
대시보드에서는 주로 이런 것들이 보이도록 했습니다.
대시보드를 운영하면서 특히 효과나 인사이트를 얻은 점을 소개합니다.
사용자별 랭킹에서는 이용량에 큰 차이가 있었습니다.
더 나아가 대화량만 많은 사람도 있었고, 대화량 대비 스킬이나 서브 에이전트의 이용 비율이 높은 사람도 있었습니다.
“많이 쓰는 것” 과 “잘 쓰는 것” 은 별개라는 점을 알 수 있습니다.
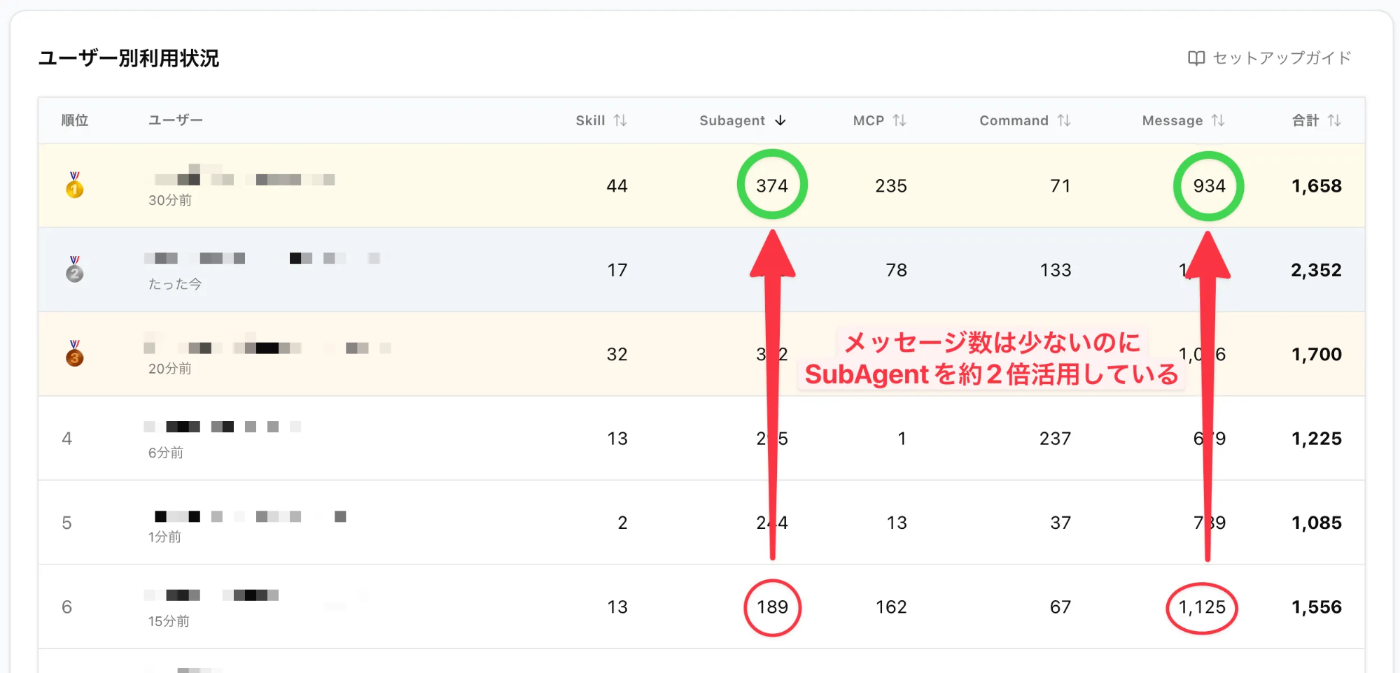
리뷰 계열, 커밋 계열 스킬은 개인 의존이 두드러졌습니다.
특히 커밋 계열은 여러 사람이 거의 같은 내용의 스킬을 각각 정의해서 사용하고 있었고, 통합의 여지가 보였습니다.

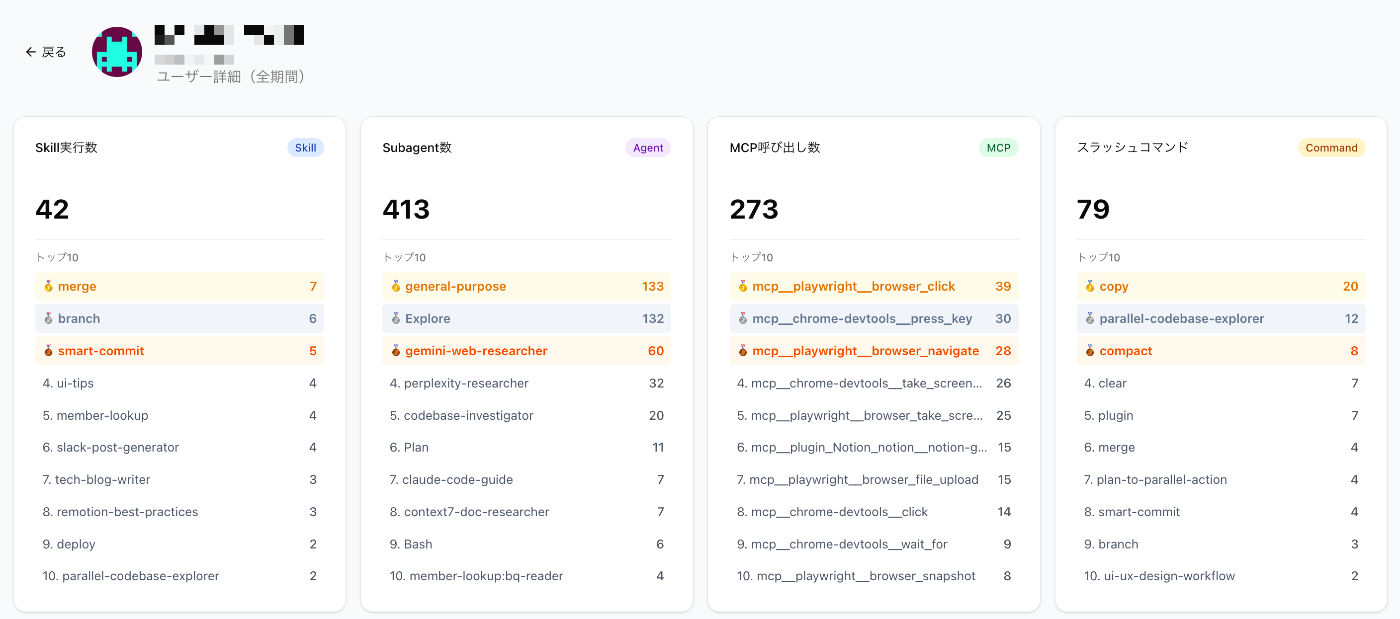
사용자별 페이지에서, 누가 어떤 스킬/서브 에이전트/MCP를 쓰는지 목록으로 볼 수 있습니다.
랭킹 상위 페이지를 보기만 해도 그 사람의 활용 패턴을 파악할 수 있습니다.
OpenTelemetry도 검토했지만, 얻을 수 있는 것은 “Claude Code를 사용했다” 수준까지이며 어떤 스킬이나 어떤 서브 에이전트를 썼는지까지는 추적할 수 없습니다.
이번에는 “누가 어떤 기능을 어떻게 쓰고 있는지”를 가시화하고 싶었기 때문에, Claude Code가 출력하는 트랜스크립트를 직접 분석하는 방침으로 했습니다.
Claude Code는 세션 중의 주고받음을 JSONL로 기록합니다.
스킬 이용 시의 예는 아래와 같습니다.
{
"sessionId": "a1b2c3d4-e5f6-7890-abcd-ef1234567890",
"cwd": "/Users/username/Desktop/your-project",
"message": {
"model": "claude-opus-4-5-20251101",
"role": "assistant",
"content": [
{
"type": "tool_use",
"name": "Skill",
"input": { "skill": "frontend-design" }
}
]
},
"timestamp": "2026-02-04T11:22:07.768Z"
}이 로그에서 input.skill 을 추출해 스킬 이용을 특정합니다.
서브 에이전트, MCP, 슬래시 커맨드도 동일하게 식별할 수 있으므로, 필요한 이벤트를 추출해 BigQuery로 전송하고 있습니다.
플러그인은 설치 시 사용자 스코프에 배치해 달라고 요청했습니다.
저희는 모노레포 구성이라, 실행 디렉터리가 최상위인 사람도 있고 packages/product-a/ 인 사람도 있습니다.
프로젝트 레벨로 배치하면 후자에서는 동작하지 않기 때문에, 사용자 스코프로 해서 어떤 디렉터리에서도 계측할 수 있게 했습니다.
monorepo/
├── packages/
│ ├── product-a/
│ ├── product-b/
│ └── product-c/
!
보충: 디렉터리명 필터링
업무 위탁 등 여러 프로젝트에 관여하는 분들을 배려해, dinii- 를 포함하는 디렉터리에서만 계측하는 필터링도 구현했습니다.
프라이빗한 이용이나 타사 프로젝트에서의 이용은 계측되지 않습니다.
플러그인 배포에는 GitHub 경유 Plugin 공개를 채택했습니다.
/plugin marketplace add 에서 GitHub 리포지토리를 지정하기만 하면 됨최종적으로 팀 전원(100%)이 플러그인을 설치해 주었습니다.
도입 절차는 Claude Code에서 아래 커맨드를 실행하기만 하면 됩니다.
/plugin marketplace add [리포지토리URL.git]
/plugin install [플러그인]
설정 파일 편집이나 스크립트 실행이 불필요해서, 안내도 “이 커맨드를 입력해 주세요”로 끝낼 수 있었습니다.
대시보드 덕분에 AI 활용 시책이 효과가 있었는지 수치로 확인할 수 있게 되었습니다.
(공개 후 서브 에이전트 이용 수가 1주일에 약 1.5배로 늘었습니다)
다른 멤버의 이용이 가시화되면서 “나도 써 볼까”라는 행동으로 이어졌다고 생각합니다.
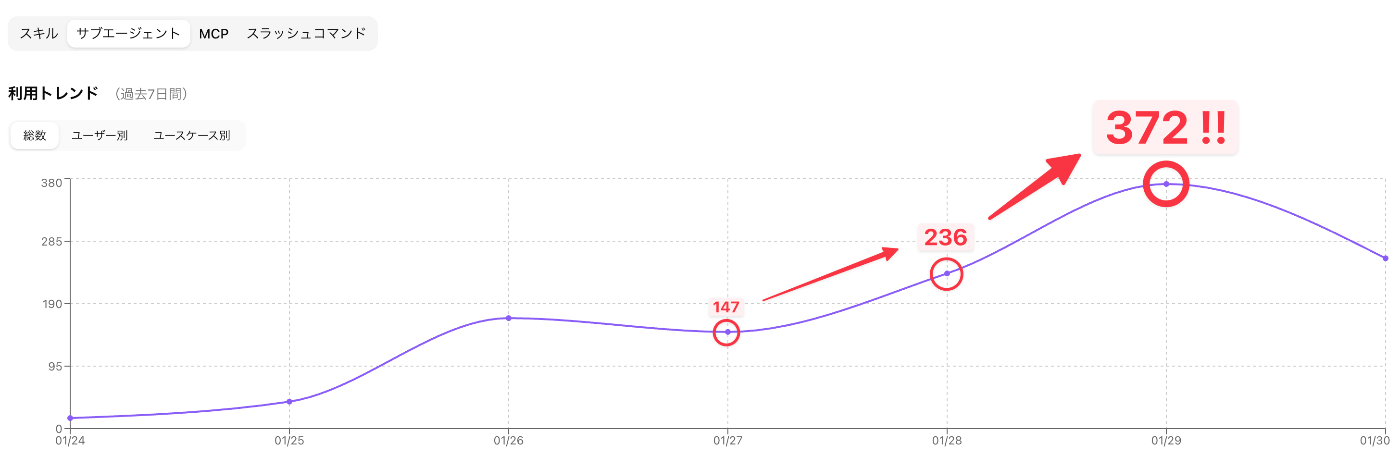
랭킹 상위 유저가 활용법을 공유할 때, 대시보드의 수치가 뒷받침이 됩니다.
“효율이 오른다”고 말하는 것보다 실제 이용 데이터가 보이는 편이 설득력이 더 높아, 활용 확산으로 이어졌습니다.
대시보드는 보고 싶은 지표가 떠오르는 타이밍에 지속적으로 개선하고 있습니다.
초기 데이터베이스 설계만 잡아두면 프론트엔드 구현은 AI에 맡길 수 있어, 변경을 빠르게 반영할 수 있습니다.
설문, 시스템 구축, 전원 도입까지를 단기간에 진행할 수 있었습니다.
돌이켜보면 포인트는 3가지입니다.
보이지 않는 것은 개선할 수 없다
누가 어떻게 쓰는지가 보이기만 해도 “저 사람도 커밋 스킬을 만들고 있었네” 같은 깨달음이 생겨, 서로 가르치고 배우는 일이 자연스럽게 시작됐다
숫자가 있으면 사람은 움직인다
구두 추천보다 상위권의 이용 데이터가 보이는 것만으로 납득감이 한꺼번에 높아졌다
떠올리면 그날 만든다
플러그인 + BigQuery + 대시보드라면 하루 만에 형태를 만들 수 있어 개선 사이클을 돌릴 수 있었다
AI 도구는 도입하고 끝이 아니라, 계측·가시화하고 팀 전체가 계속 개선해 나가는 단계까지 들어가는 것이 중요하다고 느낍니다.
이런 노력을 쌓아 올려, AI 네이티브 조직을 진지하게 실현해 나가겠습니다.