METR는 AI 도구가 오픈소스 개발자의 작업 속도에 미치는 영향을 추정하기 위해 진행 중인 생산성 실험에서, 참여자 선택 편향과 측정 한계로 인해 최근 데이터의 신뢰성이 낮다고 판단해 실험 설계를 바꾸고 다른 측정 방법들도 병행할 계획을 설명한다.
URL: https://metr.org/blog/2026-02-24-uplift-update/
METR는 이전에 논문을 발표했으며, 2025년 2월부터 6월까지의 데이터를 사용해 숙련된 오픈소스 개발자들이 AI 도구를 사용하면 작업 완료가 20% 느려진다는 결과를 보고했습니다.
시간이 지남에 따라 AI가 개발자 생산성에 어떤 영향을 미치는지 이해하기 위해, 우리는 2025년 8월에 최신 AI 도구를 사용하는 더 큰 개발자 풀을 대상으로 새로운 실험을 시작했습니다.
하지만 참여자 피드백과 설문을 종합해 볼 때, 새로운 실험 데이터가 현재의 AI 도구 생산성 효과에 대한 신뢰할 만한 신호를 제공하지 못한다고 판단했습니다. 가장 큰 이유는, AI 없이 일하고 싶지 않다는 이유로 연구 참여를 선택하지 않는 개발자의 비율이 크게 늘어났음을 관찰했기 때문입니다. 이는 AI 보조로 인한 속도 향상 추정치를 아래로 편향시킬 가능성이 큽니다. 또한 우리는 낮아진 시급(기존 $150/시간에서 $50/시간으로 감소)으로 인해 선택 효과가 발생했을 것으로 보고 있으며, 여러 AI 에이전트를 동시에 사용하는 개발자들의 경우 작업별 소요 시간 측정이 신뢰하기 어렵다고도 판단합니다.
참여자들과의 대화를 바탕으로, 2026년 초 현재 개발자들이 AI 도구로부터 얻는 속도 향상은 2025년 초에 우리가 추정했던 것보다 더 클 가능성이 높다고 생각합니다. 하지만 실험에서 발생한 선택 효과 때문에, 우리의 데이터는 이 증가 폭의 크기에 대해 매우 약한 증거만을 제공합니다.
원자료 결과는 속도 향상의 일부 증거를 보여 줍니다. 2025년 초 연구에서는 AI 사용 시 작업 시간이 19% 늘어났고, 신뢰구간은 +2%에서 +39%였습니다. 이후 연구에 참여한 기존 개발자 하위집합에 대해 현재 우리는 -18%의 속도 향상(즉 더 빨라짐)을 추정하며, 신뢰구간은 -38%에서 +9%입니다. 새로 모집된 개발자들에서는 추정 속도 향상이 -4%이고, 신뢰구간은 -15%에서 +9%입니다.
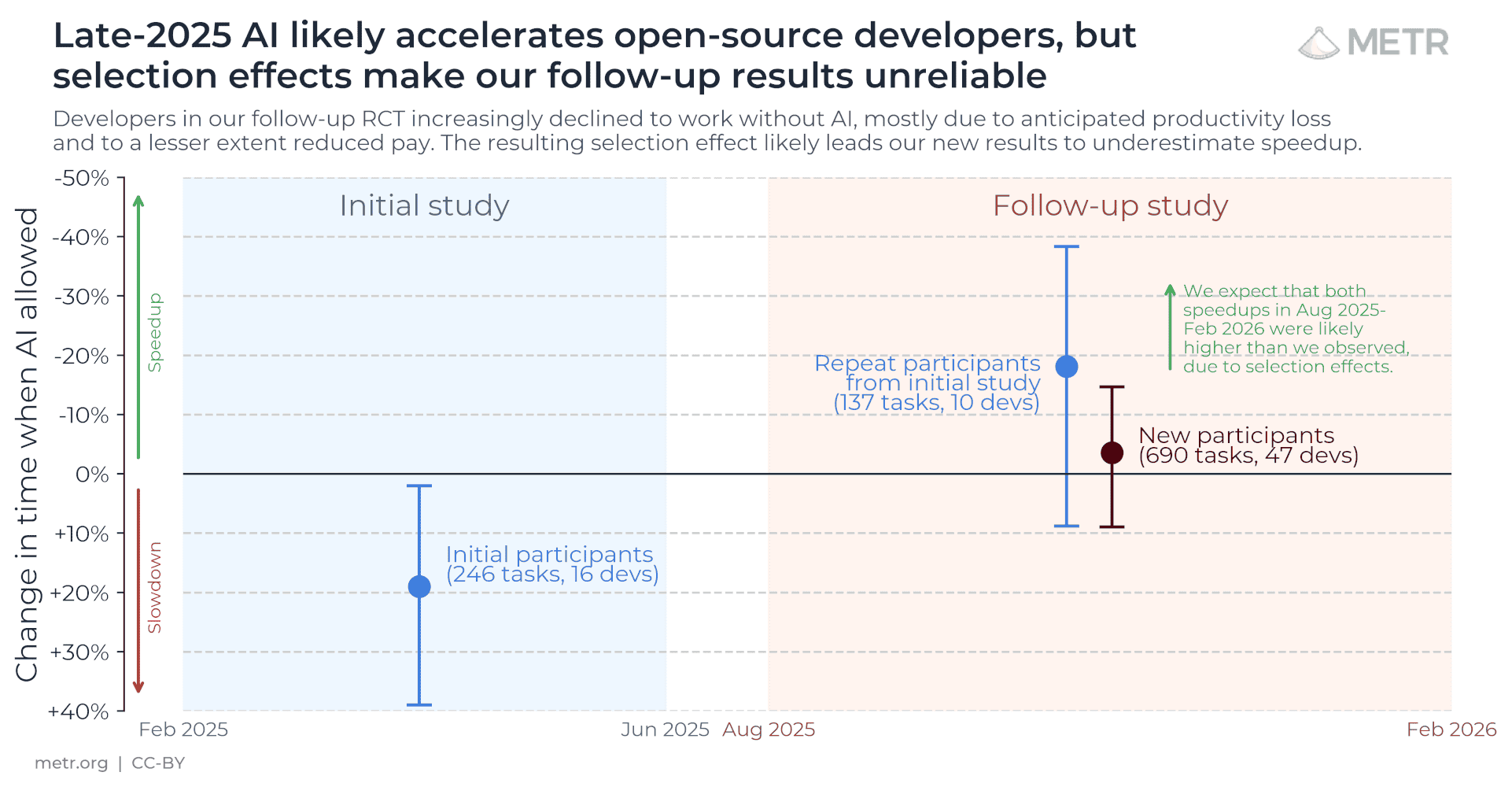
그러나 실험에서 제외(선택적으로 불참/미제출)된 개발자와 작업들에서는 실제 속도 향상이 훨씬 더 클 수 있습니다. 일부 개발자는 매우 높은 속도 향상을 자가 보고하지만, 앞선 연구에서 문서화했듯이 그러한 추정은 꽤 신뢰하기 어려울 수 있습니다.
이러한 선택 효과의 심각성을 고려해, 우리는 연구 설계 변경을 진행 중입니다. 아래에서는 추가 세부사항을 제공하고, AI가 개발자 생산성에 미치는 영향을 연구하기 위한 다른 방법들에 대한 계획도 설명합니다.
8월에 시작한 두 번째 연구는 1차 연구의 개발자 10명과, 더 다양한 오픈소스 프로젝트에서 모집한 신규 개발자 47명으로 구성되었습니다. 참여자에게는 참여 대가로 $50/시간을 지급했습니다.
초기 연구와 마찬가지로, 개발자들은 작업하려는 각 태스크를 사전에 지정하고 무작위 배정을 위해 태스크 설명을 제출하도록 요청받았습니다. 각 태스크는 “AI 허용” 또는 “AI 금지” 조건에 배정되었습니다. 개발자들은 태스크 완료에 걸린 시간을 기록했고, 이를 통해 AI 사용 여부에 따른 일반적인 태스크의 평균 완료 시간을 비교할 수 있었습니다.
2025년 내내 오픈소스 개발자들 사이에서는 Claude Code나 Codex 같은 에이전트형(agentic) 도구 사용이 증가했습니다. 이러한 AI의 광범위한 도입은 우리 연구에 두 가지 중요한 영향을 미쳤습니다.
개발자 모집 및 유지가 더 어려워졌습니다. 개발자 중 더 큰 비율이, 연구에서 $50/시간을 지급하며 본인이 선택한 태스크를 수행하게 하더라도, 자신의 작업 50%를 AI 없이 하고 싶지 않다고 말합니다. 따라서 우리의 연구는 AI 가치에 대해 가장 낙관적인 기대를 가진 개발자들을 체계적으로 놓치고 있습니다.
개발자들이 제출하는 태스크를 더 선별적으로 고릅니다. 설문에서 30%~50%의 개발자가, AI 없이 하고 싶지 않아서 일부 태스크를 제출하지 않았다고 답했습니다. 이는 AI로부터의 기대 향상(uplift)이 큰 태스크를 체계적으로 놓치고 있음을 의미합니다.
이 두 효과를 합치면, 위에서 보고한 우리의 추정치는 해당 개발자들에게 AI가 미치는 진정한 생산성 효과의 하한(lower bound)일 가능성이 큽니다. 선택 효과는 개발자와 태스크의 소수 비율에만 영향을 미치는 것으로 보이며, 이는 편향의 정도를 제한합니다. 그러나 우리는 AI를 가장 적극적으로 도입하는 집단의 데이터를 놓치고 있을 가능성이 높고, 바로 그 집단이 가장 관심 대상일 수 있습니다. AI 역량이 계속 증가하고 개발자들의 기대도 커질수록, 이러한 효과는 더 극적으로 나타나 이 연구 설계의 타당성을 더욱 제한할 것입니다.
인터뷰와 설문을 바탕으로 우리는 선택 증가의 주된 원인이 개발자들 사이에서 AI 기반 향상에 대한 기대가 더 높아졌기 때문이라고 봅니다. 다만 두 번째 연구는 초기 연구의 $150/시간이 아니라 $50/시간의 더 낮은 시급을 제공했으며, 이것 역시 선택 증가에 기여했을 가능성이 큽니다.
또한 우리는 다른 문제들도 일부 확인했지만, 그 규모는 상대적으로 덜 심각하다고 판단했습니다.
일부 개발자는 에이전트형 AI를 사용할 때 시도하는 태스크 유형이 달라졌으며, AI의 강점에 더 의존하는 방향으로 바뀌었다고 말했습니다. 이는 (a) 연구 내 참가자와 연구 밖 개발자 간 태스크 선택이 달라질 수 있고, (b) 연구 내에서의 시간 차이가 태스크 유형 대체(substitution) 때문에 가치 차이를 대표하지 않을 수 있음을 의미합니다.
일부 개발자는 같은 태스크라도 AI 허용/금지 조건에 따라 최종 산출물의 품질이 달랐다고 말했습니다. 예를 들어 주관적 코드 품질의 차이, 작성한 문서나 테스트의 양 차이 등이 있었습니다.
일부 개발자는 AI 금지 조건에 배정된 태스크를 완료할 가능성이 더 낮았습니다. 한 개발자는 AI 금지 조건에 배정된 태스크를 단 하나도 완료하지 않았습니다.
일부 개발자는 에이전트형 도구를 사용할 때 태스크 완료에 소요된 시간을 보고하기가 어렵다고 했습니다. 에이전트가 작업을 끝내기를 기다리는 동안 다른 관련 없는 작업을 하곤 했기 때문입니다.
종합하면, 이러한 문제들 때문에 우리의 중심 추정치를 해석하기가 어렵고, 이는 해당 개발자들에게 AI 도구가 미치는 실제 생산성 영향의 나쁜 대리변수(proxy)일 가능성이 높다고 봅니다.
“갈등돼요. 이 질문에 대한 최신 데이터를 제공하는 데 도움이 되고 싶지만, 저도 AI 쓰는 걸 정말 좋아하거든요!” — 2025년 초 1차 연구의 한 개발자(2025년 말 연구 참여 요청을 받았을 때)
“제가 이슈를 샘플링하는 데 사실상 크게 편향이 생겼다는 걸 알게 됐어요… AI라면 2시간이면 끝낼 수 있는 일 같은 이슈는 피하는데, 저는 20시간을 써야 하거든요. 그런데 그 태스크가 AI 금지로 결정되면 너무 고통스러울 거예요.” — 연구에 포함할 태스크를 고를 때 선택 효과를 언급한 신규 연구의 한 개발자
“예전 방식으로 너무 많이 하려 하면 머리가 터질 것 같아요. 마치 도시를 걸어서 가려고 하는 느낌인데, 어느 순간부터는 우버 타는 게 더 익숙해져 버린 거죠.” — 연구에 포함할 태스크를 고를 때 선택 효과를 언급한 신규 연구의 한 개발자
AI 도구가 개발자 생산성에 미치는 영향은 AI R&D 가속을 판단하는 데 중요한 입력값입니다. 따라서 우리는 다음의 연구 방향을 계속 탐색할 계획입니다.
더 집중적인 실험. 더 높은 준수율(compliance)을 확보하면 선택 문제가 완화될 수 있습니다. 이는 더 짧고 강도 높은 실험을 수행하고, 필요하다면 더 높은 보수를 지급함으로써 달성할 수 있습니다.
관찰 데이터. 소프트웨어 개발에서의 AI 사용에 관한 풍부한 데이터 소스가 있습니다. 집계 통계(예: GitHub 커밋의 약 4%가 Claude Code로 작성됨)부터, 상세한 대화/작업 로그(예: Sarkar (2025))까지 다양합니다. 우리는 오픈소스 개발자 풀을 계속 관찰하여 AI가 어떻게 사용되는지 이해하고자 합니다.
설문조사. 자가 보고한 생산성 반사실(counterfactual)은 해석이 어렵고 잠재적 편향이 있을 수 있지만, 신중한 설문 문항 선택과 시간 사용(time-use) 연구를 결합하면 유용한 신호를 만들 수 있다고 낙관합니다.
고정 태스크 실험. 우리의 초기 연구는 무작위 배정을 적용하기 전에 개발자가 자신의 태스크를 선택하게 했다는 점에서 새로웠습니다. 우리는 더 단순한 설계로 돌아가, 개발자에게 고정된 태스크를 부여하고 AI 보조 유무에 따라 수행하게 할 수도 있습니다.
평가(evals). METR는 에이전트가 태스크를 자율적으로 완료하는 능력을 측정하기 위한 태스크 평가를 계속 구축하고 있으며, 이는 에이전트 도입의 생산성 효과와 명확한 관련이 있습니다.
개발자 단위 실험. 다른 설계로는 태스크 단위가 아니라 개발자 단위에서 무작위 배정을 하는 방식이 있습니다. 즉 각 참여자는 모든 태스크에서 AI를 사용하거나, 아예 사용하지 않도록 하는 것입니다. 이는 태스크 단위 선택 문제를 일부 완화하지만, 개발자 단위 선택 문제를 더 악화시키고, 생산성 효과를 탐지하는 검정력(power)이 낮아집니다.
모델 역량이 계속 증가함에 따라, 우리는 역량 및 측정 기법의 일부를 계속 재설계해야 할 것으로 예상합니다.
우리는 개발자들에게 $50/시간을 지급하여, 그들이 기존 오픈소스 프로젝트에서 작업하도록 했고, 이슈를 AI 허용 또는 AI 금지 조건으로 무작위 배정했습니다. 개발자들은 중앙값 10년 경력의 숙련된 오픈소스 기여자였습니다. 우리는 57명의 개발자, 143개 리포지터리, 800개 이상의 태스크 데이터를 보유하고 있습니다.
이 중 10명은 초기 연구 참가자이며, 나머지는 더 다양한 리포지터리(더 작고, 더 그린필드(greenfield)이며, 덜 성숙한 리포지터리 포함)에서 새로 모집된 개발자들입니다.