코드 재사용을 위한 다양한 메커니즘(함수 추출, 고차 함수, OOP 서브타입/애드혹/매개변수 다형성, 타입 소거, 덕 타이핑, 매크로 등)을 비교하고, 정규화와 비정규화의 트레이드오프, 누수성 추상화, 단순 인터페이스가 가지는 한계, 그리고 데이터 모델·제약·데이터플로·책임 분리·트레이드오프 같은 핵심 아키텍처 결정의 중요성을 다룹니다. 또한 추상화가 깨지는 대표적 상황과 코너 케이스 폭발, 부분 정보 처리로의 전환 사례를 정리합니다.
코드 재사용, 다형성, 추상화에 대하여
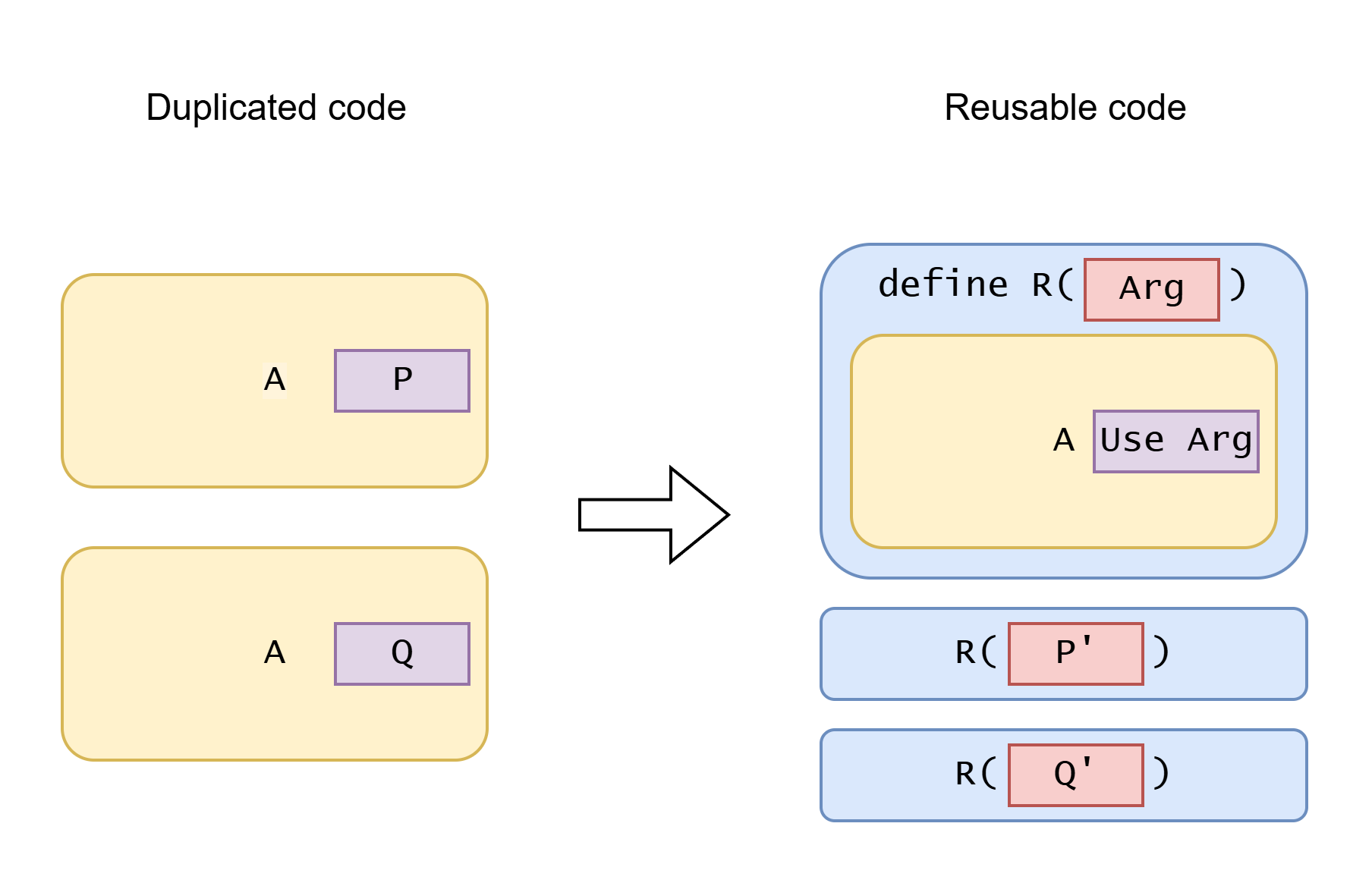
| 코드 재사용 메커니즘 | A | P와 Q | R | P'와 Q' | 인자 사용 |
|---|---|---|---|---|---|
| 함수 추출 | 실행 코드 블록 | 값 | 함수 | 값(인자 타입으로 변환됨) | 인자를 전달 |
| 고차 함수 추출(클로저, 람다 식) | 실행 코드 블록 | 실행 코드 블록(외부 인자를 받을 수 있음) | 함수를 인자로 받는 함수 | 클로저 함수(값을 캡처 가능) | 함수 인자를 호출 |
| OOP 상속, 인터페이스, 동적 트레이트(서브타입 다형성) | 실행 코드 블록 | 실행 코드 블록(외부 인자를 받을 수 있음) | 슈퍼타입 객체 참조를 사용하는 코드 | 다형적 메서드를 오버라이드한 서로 다른 서브타입의 객체들 | 다형적 메서드 호출 |
| 함수 오버로딩, 정적 트레이트, 타입클래스(애드혹 다형성) | 실행 코드 블록 | 실행 코드 블록(서로 다른 타입을 다룰 수 있음) | 제네릭 함수 | 타입 또는 타입클래스 | 오버로드된 함수 호출/트레이트 함수 호출/타입클래스 함수 호출 |
| 제네릭 타입(매개변수 다형성) | 타입 정의 | 타입들 | 제네릭 타입 | 타입 매개변수 | 타입 매개변수 사용 |
| 제네릭 함수(매개변수 다형성) | 실행 코드 블록 | 타입들 | 제네릭 함수 | 타입 매개변수(보통 추론됨) | 타입 매개변수 사용 |
| 타입 소거 | 코드 블록 | 서로 다른 타입의 값(혹은 여러 타입과 작동) | 함수(생성자일 수 있음) | 최상위 타입(any, Object)의 값, 런타임 타입 정보 포함 | 값 전달, 타입 검사, 캐스팅, 리플렉션 등 |
| 덕 타이핑(행 다형성), 구조적 타이핑 | 실행 코드 블록 | 객체 필드 접근, 메서드 호출 | 이름으로 필드 접근 또는 메서드 호출 | 공통 필드/메서드를 가진 서로 다른 값들 | 공통 필드/메서드를 이름으로 사용 |
| 매크로 | 코드 조각 | 코드 조각들 | 매크로 | 코드 조각들 | 매크로 인자 사용 |
함수를 추출하는 것은 정규화이고, 함수를 인라인하는 것은 비정규화입니다. 함수 추출은 중복 코드를 공유 함수로 바꾸고, 인라이닝은 공유 함수를 중복 코드로 되돌립니다.
| 정규화 | 비정규화 |
|---|---|
| 함수 추출 | 함수 인라인 |
| 제네릭 매개변수 추출 | 제네릭 인라이닝/타입 소거 |
| 캡슐화 | 캡슐화 제거 |
| 고차 함수 추출 | 동적 디스패치 인라인화 |
| 다형적 메서드 호출 추출 | 동적 디스패치 인라인화 |
| 크로스 플랫폼 프레임워크 사용 | 플랫폼별로 따로 개발 |
| 유연성 추가 | 유연성 제거 |
| 일반화 | 특수화 |
| 추상화된 "똑똑한" 코드 | 중복된 "단순한" 코드 |
| 정규성을 따르는 요구사항을 구현하기 쉬움. | 정규성을 따르는 요구사항 구현이 어려움. (변경이 중복됨) |
| 정규성을 깨는 요구사항 구현이 어려움. (복잡한 특수 케이스 처리를 추가) | 정규성을 깨는 요구사항 구현이 쉬움. |
우리가 때로 일반화 대신 특수화를 선택하는 이유:
누수성 추상화에 대하여: 추상화는 세부를 숨기고 단순하게 만들려는 시도입니다. 하지만 일부 추상화는 누수성이 있어, 올바로 사용하려면 오히려 숨기려던 세부를 이해해야 합니다. 누수성이 클수록 추상화의 유용성은 줄어듭니다.
새 요구가 추상이 사용한 정규성을 따른다면, 그 추상화는 좋은 것이며 일을 단순하게 만듭니다.
하지만 새 요구 변화가 정규성을 깨뜨릴 때, 추상화는 개발자를 방해합니다. 개발자에게는 두 가지 선택지만 남습니다:
모든 추상화는 어떤 것을 쉽게 만드는 동시에 다른 것을 어렵게 만듭니다. 이는 트레이드오프입니다.
모든 게임 엔진은 쉽게 만드는 것들과 어렵게 만드는 것들이 있다. 한 도구만 오랫동안 쓰다 보면 그 도구의 범위를 벗어나는 설계를 아예 떠올리지 않게 된다. 그러면 도구에 한계가 없다고 느껴질 수도 있다.
- Tyler Glaiel, 링크
현실 세계는 복잡합니다. 소프트웨어를 만드는 일은 수많은 세부 사항에 대해 결정을 내려야 합니다.
어떤 도구의 인터페이스가 단순하다면, 내부에 많은 세부 결정이 하드코딩되어 있다는 뜻입니다. 인터페이스가 이런 세부 결정을 노출하기 시작하면 더 이상 단순하지 않게 됩니다.
이는 AI 코딩에도 적용됩니다. 모호한 프롬프트를 쓰고 LLM이 전체 애플리케이션/기능을 생성해 주면, 그 코드에는 당신이 내린 것이 아닌 LLM이 내린 수많은 주관적 세부 결정이 들어갑니다(물론 이후 프롬프트로 세부를 바꾸게 할 수는 있습니다).
이 결정들은 중요하며 초기에 내려야 합니다(AI 보조 코딩을 사용할 때는 특히 명확히 지정해야 합니다).
데이터 모델링:
제약:
데이터플로:
책임(관심사) 분리와 캡슐화:
트레이드오프:
복잡도를 줄이려면 가능한 한 것들 사이의 관련성을 줄여야 합니다. 하나의 것이 더 적은 것들과만 관계를 맺을수록 덜 복잡합니다. 개별 모듈의 책임을 축소하고, 관심사를 분리하십시오.
프로그래밍 맥락에서 직교성은 무관함을 의미합니다:
복잡한 작업을 여러 단계로 나누면 더 직교적으로 만들 때가 있습니다. 여러 단계를 하나로 합치면 복잡도가 올라갑니다.
현실은 이론보다 덜 완벽합니다. 흔히 두 대상은 대부분 직교적이지만 몇 가지 비직교적인 엣지 케이스가 존재합니다. 엣지 케이스가 적고 단순하다면 특수 처리를 추가해도 괜찮습니다. 그러나 특수 케이스가 많거나 일부가 복잡하다면, 두 모듈은 매우 비직교적이며 재설계가 필요합니다.
때로 인터페이스가 두 개의 직교적인 옵션을 전달하도록 허용하지만, 실제로는 어떤 옵션 조합은 지원하지 않는 경우가 있습니다. 이는 가짜 직교성입니다(인터페이스상으로는 직교적으로 보이지만 실제로는 아님).
합 타입(sum type)은 잘못된 데이터 조합을 방지하여 가짜 직교성을 줄이는 데 유용합니다. 유효하지 않은 데이터 조합이 만들어지는 것을 막아 정합성을 높일 수 있습니다.
또 다른 경우로, 소프트웨어가 인터페이스 차원에서는 직교성을 제공하고 실제로 모든 옵션 조합(무익한 조합까지)을 지원하지만 구현이 비직교적이라면, 구현이 조합 폭발에 직면하게 됩니다. 인터페이스에서 지원 조합을 제한하는 편이 낫습니다.
이를 라이브러리로 본다면, Windows 링커 기능 X와 Unix 링커 기능 Y를 조합해 사용할 수 있습니다. 하지만 그런 경우 링커가 어떻게 동작해야 하는지 선례가 없었습니다. 더 나쁜 점은, 많은 상황에서 무엇이 “올바른” 동작인지조차 자명하지 않았다는 것입니다. 우리는 모든 가능한 기능 조합에 대해 말이 되는 의미론을 정의하기 위해 많은 시간을 논의에 썼고, 모든 타깃을 동시에 지원하기 위해 주의 깊게 복잡한 코드를 작성했습니다. 그러나 돌이켜보면, 아무도 그런 가설적 기능 조합을 실제로 원하지 않았기 때문에, 그건 시간을 잘 쓰는 방법이 아니었습니다. lld v1에는 아마 실제 사용자가 거의 없었을 겁니다.
(이름을 ID로 쓰는 것은 보통 나쁜 설계입니다. 도구의 대상이 프로그래머인 경우를 제외하면.)
이를 구현하려면 실삭제를 소프트 삭제로 바꿔야 합니다. 예를 들어, 살아있는지 여부를 나타내는 불리언 플래그를 추가하고, 엔티티 동작의 모든 로직에서 그 플래그를 확인합니다.
이를 구현하려면 텍스트를 문자열로 그대로 저장할 수 없습니다. 로그는 관련 정보를 가진 데이터 구조로 저장하고, UI에 표시할 때 텍스트로 변환해야 합니다. (더 “단순한” 방법은 지원하는 모든 언어의 문자열을 함께 저장하는 것입니다.)
싱글플레이에서는 메모리 내 데이터가 진실의 원천이 될 수 있지만, 멀티플레이에서는 서버가 진실의 원천입니다. 이제 클라이언트가 아닌 모든 작업에는 패킷 송수신이 필요합니다.
게다가 가시적 지연을 줄이려면, 클라이언트 측 게임은 미래의 게임 상태를 추정하고 서버 패킷으로 추정을 보정해야 합니다(롤백 메커니즘 추가). 상당히 복잡해질 수 있습니다.
투두 리스트 앱에서 모든 데이터는 서버에서 로드되고, 모든 편집도 서버를 거친다. 그런데 새 요구사항: 인터넷이 끊겨도 동작하고, 연결되면 동기화해야 한다.
GUI에서 이전에는 GUI 상태를 변경하는 장기 실행 작업이 있을 때, 그 작업이 실행되는 동안 사용자가 GUI를 조작할 수 없었다. 이제 사용자 경험을 개선하려면, 작업이 실행되는 동안에도 GUI 조작을 허용해야 한다. 백그라운드 작업과 사용자가 이제 모두 변경 가능한 상태를 바꿀 수 있게 된다. User interfaces are hard - why?
이전에는 분리되어 있던 두 가지 UI 컴포넌트가 이제 변경 가능한 상태를 공유해야 한다. The complexity that lives in the GUI | RoyalSloth
이전 데이터 처리 과정에서 일부 정보가 제거되었다. 새 요구사항은 그 정보를 유지해야 한다. (예시 TODO)
(각 엔터프라이즈 고객을 위해 개별 개발을 하는 것이, 구성 가능한 유연한 “룰 엔진”을 만드는 것보다 실제로 더 쉬울 수 있습니다. 커스텀 “룰 엔진”은 단지 코드를 작성하는 것보다 더 복잡하고 디버깅이 어려워질 수 있습니다. 별도로 개발하더라도 공통 코드를 공유할 수 있습니다. The Configuration Complexity Clock)
권한 시스템의 특수 케이스. 비로그인 사용자에게 일부 기능 접근을 허용. 봇을 특수 권한을 가진 새로운 사용자 유형으로 추가. 특정 필드 수정 권한을 세분화.
두 시스템 A와 B가 함께 동작해야 하는데, A와 B의 API가 버전마다 모두 바뀐다. 그러나 A의 모든 버전은 B의 모든 버전과 동작해야 한다.
AB 테스트용 피처 플래그를 계속 추가한다. 많은 피처 플래그 조합이 생길 것이다. 어떤 조합은 버그를 유발할 수 있다.