데드락, 순환 참조, 정지(halting)라는 세 가지 개념이 어떻게 깊게 연결되는지 살펴본다.
데드락, 순환 참조, 정지(halting)
데드락, 순환 참조, 정지(halting)라는 3가지 개념은 서로 깊게 연결되어 있다.
데드락은 자원 할당 그래프(resource allocation graph) 로 이해할 수 있다.
그래프에는 두 종류의 노드가 있다.
간선은 의존성(dependency) 을 나타낸다. A가 B를 가리키면 A가 B에 의존한다는 뜻이다. 구체적으로는 두 종류의 간선이 있다.
그래프가 사이클(cycle) 을 형성하면 데드락이 발생한다.
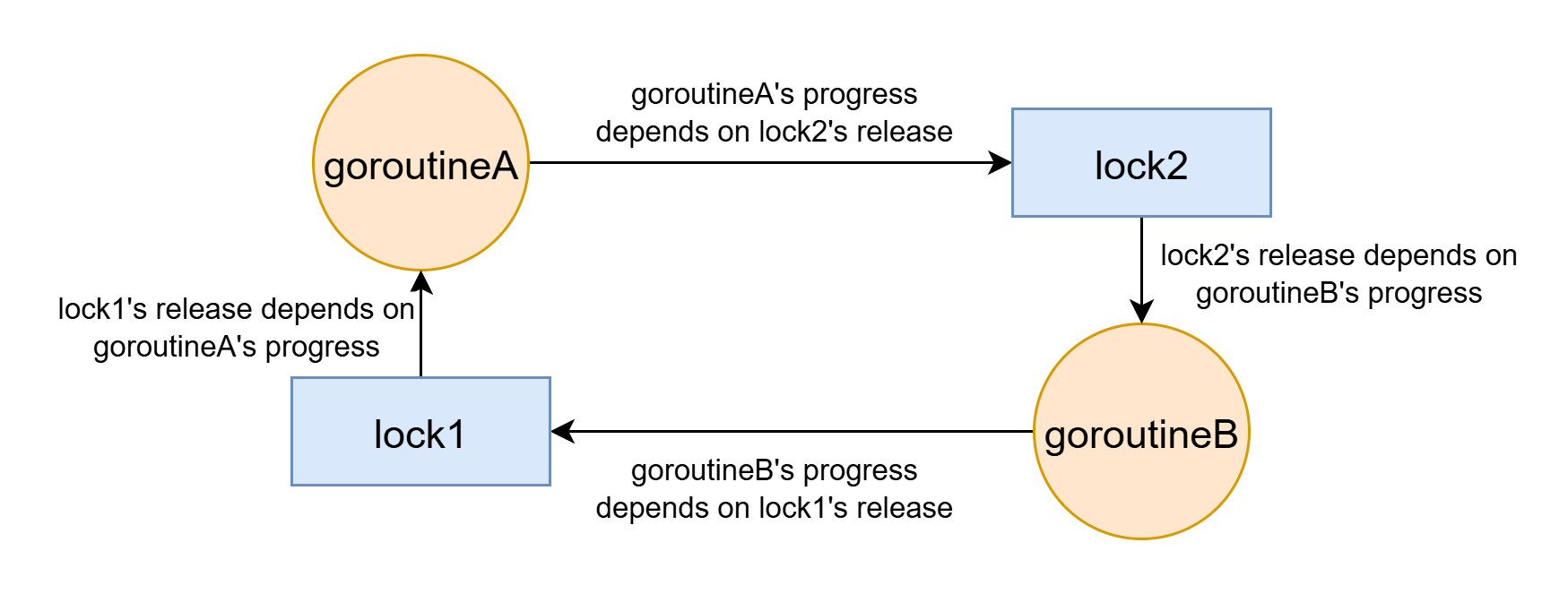
Golang에서의 간단한 2-락 데드락:
func goroutineA(lock1 *sync.Mutex, lock2 *sync.Mutex) { lock1.Lock() defer lock1.Unlock() // ... lock2.Lock() // 여기서 데드락 defer lock2.Unlock() } func goroutineB(lock2 *sync.Mutex, lock1 *sync.Mutex) { lock2.Lock() defer lock2.Unlock() // ... lock1.Lock() // 여기서 데드락 defer lock1.Unlock() }
데드락 상태에서의 자원 할당 그래프:
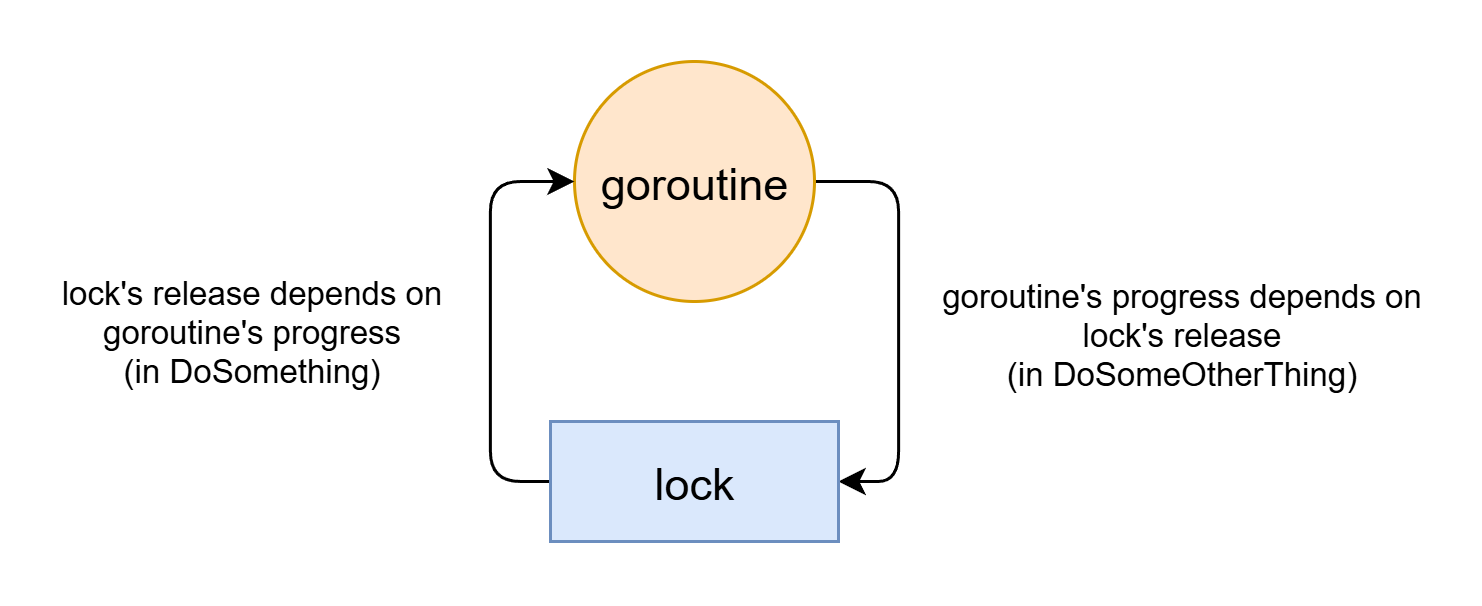
Golang의 락은 재진입(reentrant) 락이 아니다. 따라서 하나의 락과 하나의 스레드만으로도 데드락이 발생할 수 있다.
type SomeObject struct { lock *sync.Mutex // ... } func (o *SomeObject) DoSomething() { o.lock.Lock() defer o.lock.Unlock() // ... o.DoSomeOtherThing() } func (o *SomeObject) DoSomeOtherThing() { o.lock.Lock() // 여기서 데드락 defer o.lock.Unlock() // ... }
(Rust의 락도 재진입이 아니다. 하지만 Java의 synchronized 와 C#의 lock 은 재진입 가능하다. 한 스레드가 같은 락을 여러 번 획득할 수 있다.)
이 예제들은 단순화되어 있다. 현실 세계의 데드락은 덜 명확하며 특정 조건에서만 트리거되는 경우가 많다. 어떤 데드락은 매우 드물게 발생하고 재현하기 어렵다.
때로는 재시도(retry)로 데드락이 해결되기도 한다. 재시도는 데드락이 의존하는 특정 조건을 회피할 수 있다. 하지만 재시도는 아래에서 설명하는 라이브락(livelock)을 유발할 수도 있다.
명시적인 락이 없어도 데드락이 발생할 수 있다. 나는 이를 락-프리 데드락(lock-free deadlock) 이라고 부른다. (명명 방식은 “serverless servers”, “constant variables”, “unnamed namespaces” 같은 표현과 비슷하다.)
락-프리 데드락을 보여주는 간단한 Golang 프로그램:
func goroutineA(aToB chan string, bToA chan string) { aToB <- "Hello from A" // 여기서 데드락 msg := <-bToA } func goroutineB(aToB chan string, bToA chan string) { bToA <- "Hello from B" // 여기서 데드락 msg := <-aToB }
Golang에서 채널은 기본적으로 버퍼가 없다(unbuffered). 그러면 생산자는 소비자를 기다린다. 두 채널이 버퍼가 없으면 데드락이 된다:
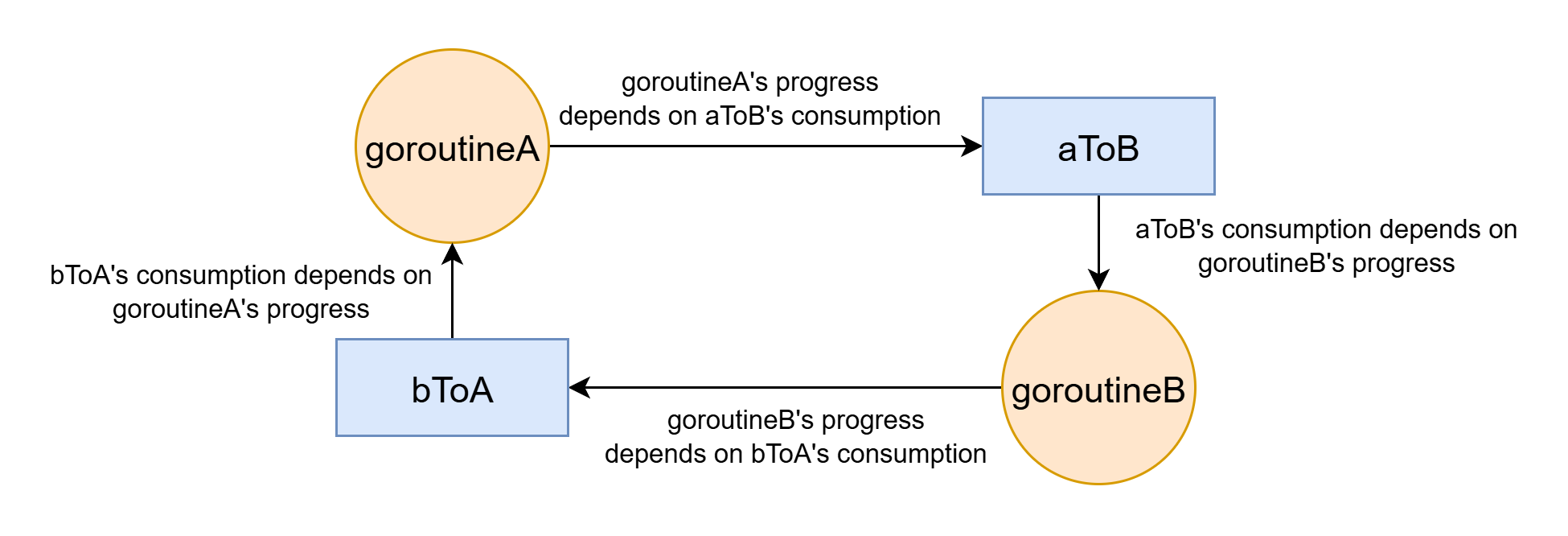
아무도 소비하지 않을 채널에 값을 넣으면 영원히 기다리게 된다. 하지만 채널을 버퍼 채널 make(chan string, 1) 로 바꾸면 버퍼가 가득 차지 않는 한 생산자가 소비자를 기다리지 않는다. 이 데드락은 채널을 버퍼링함으로써 해결할 수 있다.
Golang의 채널 버퍼는 반드시 상수 크기 제한을 가져야 한다. 무제한 채널을 위한 패키지도 있다(chanx). 다만 큰 버스트가 발생하면 메모리 부족(out-of-memory)이 날 수 있다.
채널 버퍼 선택의 차이:
한 고루틴만으로 생기는 간단한 락-프리 데드락:
ctx, cancel := context.WithCancel(context.Background()) defer cancel() // ... <-ctx.Done()
앞의 데드락은 채널을 버퍼링하면 해결된다. 하지만 버퍼링이 모든 락-프리 데드락을 해결하는 것은 아니다.
간단한 예:
func goroutineA(aToB chan string, bToA chan string) { msg := <-bToA // 여기서 데드락 aToB <- "Hello from A" } func goroutineB(aToB chan string, bToA chan string) { msg := <-aToB // 여기서 데드락 bToA <- "Hello from B" }
또한 버퍼가 고정 크기라면, 버퍼가 꽉 찼을 때 여전히 데드락이 날 수 있다. 예:
results := make(chan int, 100) var wg sync.WaitGroup wg.Add(1) go func() { defer wg.Done() for i := 0; i < 200; i++ { results <- i } }() wg.Wait()
부모 프로세스가 자식 프로세스를 실행하고 자식의 stdin과 stdout을 파이프로 연결했다고 하자.
이 경우 데드락이 될 수 있다. 예:
(인자 없이 cat 을 실행하면 stdin에서 읽은 데이터를 그대로 stdout으로 출력한다. 아래 예제는 서브프로세스 cat 을 띄우고, stdout을 읽기 전에 stdin에 큰 데이터를 먼저 쓰기 때문에 데드락이 날 수 있다.)
cmd := exec.Command("cat") stdin, err := cmd.StdinPipe() if err != nil { panic(err) } defer stdin.Close() stdout, err := cmd.StdoutPipe() if err != nil { panic(err) } err = cmd.Start() if err != nil { panic(err) } largeData := []byte(strings.Repeat("X", 233333)) // 파이프 버퍼보다 큼 _, err = stdin.Write(largeData) // 여기서 데드락 if err != nil { panic(err) } // 큰 데이터를 쓴 뒤에 stdout 읽기 buf := make([]byte, len(largeData)) stdout.Read(buf)
서브프로세스에 대한 읽기와 쓰기는 서로 다른 고루틴에서 해야 한다.
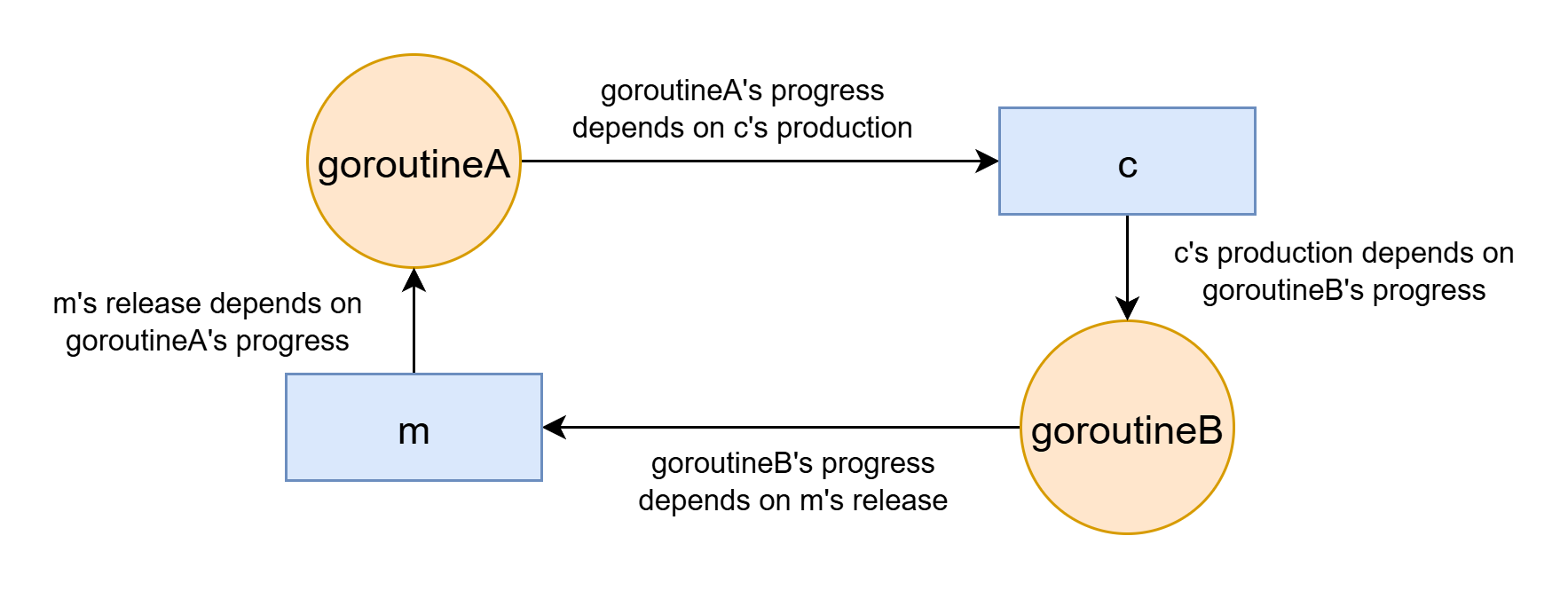
예:
func goroutineA(m *sync.Mutex, c chan string) { m.Lock() defer m.Unlock() value := <-c // 여기서 데드락(고루틴A가 먼저 실행된다고 가정) } func goroutineB(m *sync.Mutex, c chan string) { m.Lock() // 여기서 데드락(고루틴A가 먼저 실행된다고 가정) defer m.Unlock() c <- "some result" }
예를 들어 채널과 select를 이용해 타임아웃을 두고 작업을 수행한다고 하자:
func doWorkWithTimeout(timeout time.Duration) (string, error) { ch := make(chan string) // 버퍼 없는 채널 go func() { result := doWork() ch <- result // 여기서 블록됨 }() select { case result := <-ch: return result, nil case <-time.After(timeout): return "", errors.New("timeout") // 이 경로를 타면 ch는 다시는 소비되지 않음 } }
select 는 어느 한 케이스가 준비되면 종료된다. 타임아웃이 나면 두 번째 케이스로 종료되고 ch에서 더 이상 읽지 않는다. 그래서 ch <- result 가 영원히 멈춰 고루틴 누수(goroutine leak) 를 일으킨다. 이는 ch를 버퍼 채널로 바꾸면 해결할 수 있다.
Golang에서의 많은 메모리 누수는 고루틴 누수 때문에 생긴다. 고루틴 누수는 해당 작업이 영원히 끝나지 않게 만들고, 다른 버그를 유발할 수 있다. 누수된 고루틴을 누군가 기다리면 데드락이 된다.
Select는 async Rust에도 함정이 있지만 메커니즘(취소/cancellation)이 다르다.
때로는 락킹을 try-lock으로 바꾸고 재시도 메커니즘을 추가하면 일부 데드락을 해결할 수 있다. 데드락은 정확한 타이밍에 의존하는 경우가 많아서 다음 재시도에서는 데드락이 아닐 수도 있다.
하지만 재시도로도 데드락을 피할 수 없는 경우가 있다. 그러면 라이브락이 된다: 락을 성공적으로 획득하지 못한 채 계속 재시도만 한다.
func WithRetry[T any](attempts int, operation func() (T, error)) (T, error) { i := 0 for { result, err := operation() if err == nil { return result, nil } i++ if i >= attempts { return result, err } } } func goroutineA(lock1 *sync.Mutex, lock2 *sync.Mutex) (string, error) { return WithRetry(10, func() (string, error) { lock1.Lock() defer lock1.Unlock() // 어떤 작업 수행 if lock2.TryLock() { // 계속 실패할 수 있음 defer lock2.Unlock() // 다른 작업 수행 return "success", nil } else { return "", fmt.Errorf("failed to acquire lock2") } }) } func goroutineB(lock1 *sync.Mutex, lock2 *sync.Mutex) (string, error) { return WithRetry(10, func() (string, error) { lock2.Lock() defer lock2.Unlock() // 어떤 작업 수행 if lock1.TryLock() { // 계속 실패할 수 있음 defer lock1.Unlock() // 다른 작업 수행 return "success", nil } else { return "", fmt.Errorf("failed to acquire lock1") } }) }
일부 실시간(또는 준실시간) 시스템에서는 중요한 스레드가 다른 스레드보다 높은 우선순위를 가진다. 스케줄러는 높은 우선순위 스레드를 먼저 실행하려 한다.
우선순위 역전(priority inversion) 문제는 높은 우선순위 스레드가 계속 막혀 사실상 데드락과 비슷한 상태가 되게 만들 수 있다(엄밀히 말하면 데드락은 아니다).
전형적인 우선순위 역전은 낮음/중간/높음 우선순위의 3 스레드가 관련된다:
업데이트, 삭제, select ... for update 같은 명시적 락이 있다. 또한 암시적 락도 있다. 여기서는 암시적 락과 관련된 덜 자명한 데드락을 다룬다.
MySQL(InnoDB)은 외래 키 무결성을 보장하기 위해 외래 키가 참조하는 행을 암시적으로 락 건다. 하지만 이것이 데드락을 유발할 수 있다. 예:
create table parent ( id int primary key, update_time timestamp ) engine=innodb; create table child ( id int primary key, parent_id int, constraint fk_parent foreign key (parent_id) references parent(id) ) engine=innodb; insert into parent(id, update_time) values (2333, now());
그 뒤 두 트랜잭션이 동시에 실행된다. 각 트랜잭션은 child를 insert한 다음 parent의 update_time 을 업데이트한다:
| 트랜잭션 A | 트랜잭션 B |
|---|---|
insert into child(id, parent_id) values (1, 2333); | |
| parent 행에 암시적으로 읽기 락 | |
insert into child(id, parent_id) values (2, 2333); | |
| parent 행에 암시적으로 읽기 락 | |
update parent set update_time = now() where id = 2333; | |
| parent 행에 쓰기 락을 걸려 함. 트랜잭션 B가 읽기 락을 잡고 있어서 B를 기다림. | |
update parent set update_time = now() where id = 2333; | |
| parent 행에 쓰기 락을 걸려 함. 트랜잭션 A가 읽기 락을 잡고 있어서 A를 기다림. 데드락. |
이 데드락은 필요 이상으로 많은 것을 락킹 하기 때문에 생긴다. 외래 키 무결성을 위해서는 parent 행이 삭제되거나(또는 PK가 바뀌거나) 하지 않게만 하면 되지, parent 행 전체를 락할 필요는 없다.
이 데드락은 child를 insert하기 전에 timestamp를 변경하면 예방할 수 있다. 읽기 락을 쓰기 락으로 업그레이드하는 상황을 피하기 때문이다.
PostgreSQL에서는 child를 건드릴 때 parent에 대해 더 세밀한 for key share 락을 건다. for key share 는 참조된 키 외의 parent 필드 변경을 막지 않는다. 그래서 위 데드락은 PostgreSQL에서는 발생하지 않는다.
하지만 PostgreSQL에서도 for update 와 결합되면 외래 키로 데드락이 날 수 있다. for update 는 for key share 와 배타적이기 때문이다. 두 트랜잭션이 먼저 같은 parent 행에 for key share 를 건 다음, parent 행을 for update 하려고 하면서 데드락이 날 수 있다.
보통 존재하지 않는 행은 락킹할 수 없다. 하지만 MySQL은 인덱스의 “갭”에 락을 걸어 “아직 존재하지 않는 행을 락킹”할 수 있다. 이를 갭 락(gap lock)이라 하며, 반복 가능 읽기(repeatable read) 격리 수준에서 사용된다.1
갭 락은 데드락을 유발할 수 있다.
예를 들어 사용자 테이블이 있다. status=1 인 사용자에 대해서는 name이 중복되면 안 되지만, 다른 status에서는 중복이 허용된다고 하자. 이런 “조건부 유니크”는 단순 유니크 인덱스로는 강제하기 어렵기 때문에 애플리케이션에서 백엔드 코드로 강제한다고 하자.
create table users ( id int auto_increment primary key, name varchar(50), status int, index name_index (name) ) engine=innodb character set utf8mb4 collate utf8mb4_bin;
| 트랜잭션 A | 트랜잭션 B |
|---|---|
select id from users where name = 'xxx' and status = 1 for update; | |
name_index에 대해 암시적으로 read-gap-lock 수행 | |
select id from users where name = 'xxx' and status = 1 for update; | |
역시 name_index에 대해 암시적으로 read-gap-lock 수행 | |
insert into users(name,status) values ('xxx', 1); | |
| write-gap-lock을 시도. 같은 갭이 B에 의해 read-locked라서 B를 기다림 | |
insert into users(name,status) values ('xxx', 1); | |
| write-gap-lock을 시도. 같은 갭이 A에 의해 write-locked라서 A를 기다림. 데드락 |
PostgreSQL에는 갭 락이 없고 위 경우 데드락이 나지 않는다. 하지만 PostgreSQL은 그 설정(반복 가능 읽기, select ... for update)에서 name 중복을 막아주지 못한다. 반면 MySQL 갭 락은 그 설정에서 중복이 생기지 않게 보장할 수 있다. PostgreSQL에서 조건부 유니크를 보장하려면 부분 유니크 인덱스(partial unique index)를 쓰는 것이 권장된다.
앞의 두 데드락에서 공통점은 읽기 락을 바로 쓰기 락으로 업그레이드한다는 점이다.
두 트랜잭션(스레드)이 같은 읽기 락을 동시에 획득한 뒤, 둘 다 그 읽기 락을 쓰기 락으로 업그레이드하려고 하면 데드락이 된다.
읽기 락을 쓰기 락으로 업그레이드하는 것은 데드락에 취약하다. 그래서 대부분의 인메모리 RW락 구현(Golang RWMutex, Java ReentrantReadWriteLock, Rust RwLock 등)은 읽기→쓰기 업그레이드를 직접 지원하지 않는다. 읽기 락을 잡은 채 쓰기 락을 잡으려 하면 곧바로 데드락이 난다.
DB 내부 데드락은 대부분 데드락 감지를 켜고 트랜잭션 재시도를 하면 해결할 수 있다.
하지만 인메모리 데드락은 그렇게 간단히 해결되지 않는다. 언어가 롤백을 해주지 않는다. 데드락 감지도 한계가 있다(Golang의 데드락 감지는 모든 고루틴이 블록된 경우에만 트리거). 인메모리 데드락은 신중하게 예방해야 한다.
How to deadlock Tokio application in Rust with just a single mutex
레퍼런스 카운팅은 강한 참조(strong reference)의 사이클이 존재하면 메모리를 누수시킨다.
일반적인 해결책은 약한 참조(weak reference)를 써서 사이클을 끊는 것이다. 개발자는 참조 구조를 알고, 어디서 사이클이 생길지 알기 때문이다.
트레이싱 GC는 도달 불가능한 사이클을 처리할 수 있다. 하지만 사용하지 않는 데이터를 GC 루트로부터 도달 가능하게 유지함으로써 GC 환경에서도 메모리 누수가 발생할 수 있다. 예:
이런 메모리 누수는 종종 컨테이너와 비가시적인 참조와 관련된다. 람다 캡처도 비가시적 참조를 만들기 때문에 관련될 수 있다.
GC를 써도 파일 핸들, TCP 연결, 네이티브 코드가 관리하는 메모리 같은 비힙 자원은 여전히 누수될 수 있다.
Rice의 정리는 (자명한 경우를 제외하면) 어떤 프로그램이 어떤 데이터를 사용할지 여부를 신뢰성 있게 판단할 수 없다고 말한다. 객체가 GC 루트로부터 도달 불가능하면 분명히 사용되지 않는다. 그러나 어떤 데이터가 실제로는 사용되지 않더라도 참조는 남아 있을 수 있다. 이 경우는 트레이싱 GC가 처리할 수 없다.
옵저버 패턴은 GUI 애플리케이션에서 흔하다. 옵저버를 사용해 어떤 데이터의 업데이트가 다른 데이터로 전파되게 만드는 것은 흔한 패턴이다. 하지만 순환 의존이 생기면 끝없는 재귀에 빠질 수 있다.
type ObservedValue[T any] struct { Value T Observers []func(T) } func (o *ObservedValue[T]) AddObserver(observer func(T)) { o.Observers = append(o.Observers, observer) } func (o *ObservedValue[T]) SetValue(value T) { o.Value = value for _, observer := range o.Observers { observer(value) } } func main() { a := ObservedValue[int]{Value: 0} b := ObservedValue[int]{Value: 0} a.AddObserver(func(value int) { b.SetValue(value + 1) }) b.AddObserver(func(value int) { a.SetValue(value + 1) }) a.SetValue(1) // 무한 재귀에 빠짐 }
React에서도 비슷한 일이 생길 수 있다:
function SomeComponent() { const [countA, setCountA] = useState(0); const [countB, setCountB] = useState(0); useEffect(() => { setCountB(countA + 1); }, [countA]); useEffect(() => { setCountA(countB + 1); }, [countB]); ... }
React의 effect는 이벤트 루프의 다음 반복에서 트리거되므로 즉시 재귀가 되진 않지만, 계속 리렌더링을 발생시켜 성능 비용을 낳는다.
부분 순서(partial ordering)가 있고, 간선이 그 순서를 따라서만 형성될 수 있다면 사이클은 존재할 수 없다.
사이클은 전역 성질이지만, 순서(ordering)는 로컬 성질이면서 추이적으로 전역으로 전파될 수 있다(a<b∧b<c⇒a<c).
락 획득에 대한 전역적으로 일관된 순서가 있으면 데드락이 발생하지 않는다. 예를 들어 lock1 과 lock2 가 있을 때, lock2 를 락킹할 때는 반드시 이미 lock1 을 보유하고 있어야 한다고 보장하면, lock2 를 획득한 스레드가 lock1 을 획득하려는 경우가 생기지 않는다. 그러면 자원 할당 그래프에서 lock2 에서 lock1 으로 가는 경로가 만들어질 수 없고, 데드락을 예방할 수 있다.
(SQL 밖에서) “락 순서”는 단순히 lock() 호출 순서가 아니다. 동시에 최대 하나의 락만 보유한다면 어떤 순서로 락을 잡아도 데드락이 나지 않는다. A를 B보다 먼저 락킹한다는 것은 B를 락킹하려 할 때 반드시 A를 이미 보유해야 한다는 뜻이다. (SQL에서는 트랜잭션 안에서 락을 해제하는 방법이 없고, 트랜잭션 종료 후 자동 해제된다. 그래서 SQL에서 “락 순서”는 락킹 순서와 대응된다.)
Rust는 트리 형태의 소유권(ownership)을 선호한다. 소유자와 소유된 값 사이에 계층이 있어 순서를 만들고, 이는 사이클을 막는다. 공유(레퍼런스 카운팅)를 쓰더라도 가변성(mutability)이 없으면 새 값을 만들 때 이미 만들어진 값만 사용할 수 있으므로 순환 참조는 여전히 불가능하다. 공유와 가변성을 결합해야만 순환 참조를 만들 수 있다.
가변성과 지연 평가(lazy evaluation)가 없다면 순환 참조는 만들어질 수 없다. 새 값을 만들 때는 이미 존재하는 값만 포함할 수 있기 때문이다(평가 순서가 사이클을 막는다). 하지만 지연 평가가 있으면 아직 만들어지지 않은 값을 사용할 수 있어 순환 참조가 가능해진다.
Haskell은 가변 상태가 없는 순수 함수형 언어다. 또한 지연 평가를 한다.
Haskell은 지연 평가 덕분에 순환 참조를 허용한다. 예:
ones :: [Integer] ones = 1 : ones
이는 1의 무한 리스트가 된다.
이는 순환 참조 없이 무한히 확장되는 트리 구조로 볼 수도 있다.
비슷하게,
from :: Integer -> [Integer] from n = n : from (n + 1)
는 n부터 증가하는 정수의 무한 리스트를 만든다.
개념적으로 리스트는 무한히 크지만, 지연 평가 덕분에 필요한 부분만 계산되어 메모리에 저장된다. 계산이 리스트 전체를 필요로 하지 않는 한 사용할 수 있다.
일반 상태 모나드에서는 새 상태가 이전 상태로부터 계산된다. 하지만 역방향 상태 모나드(reverse state monad)에서는 상태가 “거꾸로” 흐른다. 이전 상태가 새 상태를 기반으로 계산될 수 있다. 이전 계산에서 사용된 이전 상태를 바꿀 수 있다. 이 “마법”은 지연 평가에 의존한다.
역방향 상태 모나드 정의:
newtype RState s a = RState { runRState :: s -> (a, s) } instance Monad (RState s) where ... RState sf >>= f = RState $ \state2 -> let (oldResult, state0) = sf state1 (newResult, state1) = runRState (f oldResult) state2 in (newResult, state0)
여기에는 순환 의존이 있다: (oldResult, state0) = sf state1 는 다음 줄에서 얻는 state1 을 사용한다. 다음 줄은 이전 줄에서 얻은 oldResult 를 사용한다.
사용 예:
{-# LANGUAGE GeneralizedNewtypeDeriving #-} import Control.Monad (ap) newtype RState s a = RState { runRState :: s -> (a, s) } instance Functor (RState s) where fmap f st = RState $ \s -> let (a, s') = runRState st s in (f a, s') instance Applicative (RState s) where pure x = RState $ \s -> (x, s) (<*>) = ap instance Monad (RState s) where return = pure RState sf >>= f = RState $ \state2 -> let (oldResult, state0) = sf state1 (newResult, state1) = runRState (f oldResult) state2 in (newResult, state0) get :: RState s s get = RState $ \s -> (s, s) put :: s -> RState s () put s = RState $ \_ -> ((), s) -- 새 상태에 기반해 이전 상태를 수정 modify :: (s -> s) -> RState s () modify f = RState $ \s -> ((), f s) example :: RState Int String example = do x <- get modify (* 2) y <- get return $ "Before: " ++ show x ++ ", After: " ++ show y main :: IO () main = do let result = runRState example 2333 putStrLn $ show result
출력:
("Before: 4666, After: 2333",4666)
역방향 상태 모나드는 여전히 정상적인 Haskell 프로그램 안에 있다. 시간의 흐름을 마법처럼 되돌릴 수는 없다. 또한 방정식을 풀어 새 상태로부터 이전 상태를 계산해낼 수 있는 것도 아니다. 새 상태가 이전 상태에 의존하면 그저 무한 루프에 빠질 뿐이다.
Haskell의 지연 평가는 평가 순서에 묶여 있다. a || b 에서 b 가 참인 것이 알려져 있어도 항상 a 를 먼저 평가하려 한다. Haskell의 지연 평가는 방정식을 푸는 데 쓰일 수 없다(방정식을 풀려면 Prolog 같은 것이 필요하다).
지연 평가는 메모리 누수를 유발하기도 한다. 예를 들어 큰 정수 리스트의 합을 계산해 놓고 그 합이 전혀 사용되지 않는다면, 리스트는 잠재적 평가를 위해 메모리에 남아 있을 수 있다.
정지 문제(Halting problem)는 순환 참조를 이용해 해결 불가능함이 증명되었다.
halts(program, input) 이라는 함수가 존재한다고 가정하자. 이 함수는 program과 input을 받아 program(input) 이 결국 정지하는지 여부를 불리언으로 반환한다.
그러면 다음과 같은 역설 프로그램 paradox 를 만들 수 있다:
fn paradox(program: Program) { if halts(program, program) { while true {} // 무한 루프 } else { return; // 정지 } }
그러면 halts(paradox, paradox) 는 모순을 낳는다. true를 반환하면 paradox(paradox) 가 정지한다고 말하는데, 정의에 따르면 무한 루프에 빠져야 한다.
Rice의 정리는 정지 문제의 확장이다: 모든 비자명한 프로그램 의미론적 성질은 결정 불가능하다(정지 여부 포함).
(정지 문제는 유한 시간 내 정지 여부만 다루며, 얼마나 오래 걸리는지는 중요하지 않다. 1000년 걸려도 완료되면 정지이다.)
튜링 머신에서 상태가 노드라면, 실행의 각 반복은 이전 상태에서 다음 상태로 점프하는 간선이 된다. 이는 그래프를 이룬다. 정지하지 않는다는 것은 시작 상태에서 도달 가능한 사이클이 존재한다는 뜻이다.
정지 문제와 Rice의 정리는 임의의 튜링 완전 프로그램을 신뢰성 있게 분석할 수 없다고 말한다.
하지만 그렇다고 아무것도 분석할 수 없다는 뜻은 아니다. 임의의 프로그램을 분석할 수 없다는 것뿐이다. 분석 가능한 프로그램은 많다. 프로그램이 충분히 단순하면 당연히 분석 가능하다. 적절한 캡슐화를 사용하면 프로그램의 한 부분만 집중하여 분석을 단순화할 수 있다.
튜링 완전은 아니지만 여전히 표현력이 있는 제약을 가하면(예: Lean), 정지를 보장하면서도 충분히 유용할 수 있다.
Rust는 분석 가능한 프로그램 부분집합으로 제한하기 위한 많은 제약을 가지고 있어, 메모리 안전성과 스레드 안전성을 분석할 수 있다.2
재귀 CTE(with recursive ...)와 다른 절차적 확장(예: while)을 사용하지 않는다면 SQL은 튜링 완전이 아니다.
증명 언어는 커리-하워드 대응에 따라 프로그램과 증명을 함께 기술한다:
1 = 1, 1 + 1 = 2 같은 명제는 타입에 대응된다. 해당 타입의 값을 얻을 수 있으면 증명한 것이다(증명에 중요한 것은 값의 내부가 아니라 타입이다).(x: Integer) -> (x + 0) = x 같은 함수 타입은 x + 0 = x 라는 명제를 나타낸다. 인자 1 을 넣으면 (1 + 0) = 1 을 얻는다.((x + 1) + 1) + y = 1 + ((x + 1) + y) 는 (x + 1) + y = 1 + (x + y) 에 의존하며, 기본 케이스 (0 + 1) + y = 1 + (0 + 1) 까지 재귀적으로 “함수 호출”한다.X 에 대응하는 정리를 증명하려면 X 를 반환하는 프로그램을 “실행”한다. 프로그램이 정상 종료하고 X 타입 값을 출력하면 증명된다.X 타입의 값을 얻을 수 없다.Lean, Idris 같은 증명 언어는 튜링 완전이 아니다. 유효한 증명은 해당 프로그램이 정지해야 하기 때문이다. 이들은 프로그램이 결국 정지함을 보장하는 특별한 메커니즘(정지 검사기)을 갖고 있다.
엄밀히 말하면 튜링 완전은 무한한 메모리를 필요로 하므로, 현실의 컴퓨터/언어는 엄밀한 의미에서 튜링 완전이 아니다. 메모리 제약 외에도 블록체인 애플리케이션은 실행 단계마다 수수료(gas)를 소비하는 경우가 많은데, 튜링 완전은 무한 실행 단계를 요구하므로 이 역시 엄밀히는 튜링 완전이 아니다.
원시(raw) 이더넷에서는 스위치들이 서로 토폴로지 정보를 교환하지 않는다.
원시 이더넷 스위치의 라우팅 방식:
토폴로지에 사이클이 없을 때는 잘 동작한다. 하지만 사이클이 있으면 브로드캐스트가 다른 인터페이스를 통해 같은 스위치로 되돌아올 수 있다. 이는 MAC 테이블 self-learning을 망가뜨릴 뿐 아니라, 같은 패킷을 또 브로드캐스트하고 또 브로드캐스트해서 브로드캐스트 스톰을 일으킬 수 있다.
이는 스패닝 트리 프로토콜(spanning tree protocol)로 해결한다. 스위치들이 토폴로지 정보를 공유하고 루프를 끊는다.
서비스 A가 서비스 B를 호출한다고 하자. B가 거의 과부하 상태라 느리게 처리하면 A의 요청이 타임아웃되고 재시도한다. 그러면 B는 더 과부하가 된다. 이 피드백 루프는 “거의 과부하”를 “완전 다운”으로 만든다.
(대부분의 백엔드 서비스는 조기 취소(early cancellation)를 제대로 구현하지 못하므로, TCP 연결을 닫아도 요청의 자원이 즉시 해제되지 않는다3.)
또 다른 요인: A의 B에 대한 요청이 오래 걸리면, A도 대기 중인 스레드/코루틴을 누적한다. A는 더 많은 자원(메모리, 스레드, 코루틴 등)을 쓰게 되고, A도 과부하 또는 다운될 수 있다.
서킷 브레이커(circuit breaker)는 이 문제를 해결하려 한다. 대상 서비스가 과부하일 때 요청 전송 자체를 막는다.
OOM에 대해: GC 애플리케이션은 가용 메모리가 부족할 때 즉시 크래시하기보다 긴 GC 일시정지에 빠지는 경우가 많다. 그러면 TCP 연결이 닫히지 않고 호출자는 타임아웃까지 계속 기다린다. 이 문제는 비-GC 애플리케이션에서는 덜한데, 비-GC 애플리케이션은 메모리가 부족하면 대개 곧바로 크래시하기 때문이다.
DB와 캐시에 대해: 어떤 시스템에서는 DB가 모든 요청을 처리할 수 없다. DB 앞에 캐시(예: Redis)가 있어 90%를 처리해야 DB가 버틴다. 캐시 서비스가 재시작하면 너무 많은 요청이 DB로 몰려 DB가 과부하가 된다. DB는 캐시가 채워져야 정상 동작하지만, DB가 과부하라 캐시를 채울 수 없다. 해결책은 게이트웨이에서 소수의 요청만 허용하고 제한을 점진적으로 늘리는 것이다. Cache stampede.
장애가 장애 해결 도구를 망가뜨릴 수 있다:
In order to make that fix, we needed to access the Kubernetes control plane – which we could not do due to the increased load to the Kubernetes API servers.
All of this happened very fast. And as our engineers worked to figure out what was happening and why, they faced two large obstacles: first, it was not possible to access our data centers through our normal means because their networks were down, and second, the total loss of DNS broke many of the internal tools we’d normally use to investigate and resolve outages like this.
More details about the October 4 outage - Engineering at Meta
Many of our internal users and tools experienced similar errors, which added delays to our outage external communication.
Google Cloud services are experiencing issues and we have an other update at 5:30 PDT
방화벽 규칙을 바꾸다가 서버로의 SSH 연결을 막아버릴 수 있다. Windows에서는 도메인 컨트롤러가 하위 PC에 도메인 컨트롤러로의 연결을 차단하는 방화벽 규칙을 배포할 수도 있다.
문제는 setup.py였다. setup 스크립트를 실행하지 않고는 패키지의 의존성을 알 수 없었다. 하지만 빌드 의존성을 설치하지 않고는 setup 스크립트를 실행할 수 없었다. 2016년 PEP 518은 이를 명시적으로 지적했다: “setup.py 파일은 의존성을 알지 못하면 실행할 수 없지만, 현재로서는 setup.py를 실행하지 않고 자동화된 방식으로 그 의존성을 알 수 있는 표준 방법이 없다.”
이 닭-달걀 문제 때문에 pip는 패키지를 다운로드하고, 신뢰할 수 없는 코드를 실행하고, 실패하고, 누락된 빌드 도구를 설치하고, 다시 시도해야 했다. 모든 설치는 서브프로세스 생성과 임의 코드 실행의 연쇄가 될 수 있었다. 소스 배포판 설치는 사실상 추가 단계가 있는
curl | bash였다.
이 문제는 이후 새로운 표준에서 해결되었다.
순환 논증(Circular reasoning): A이면 B, B이면 A. 순환 논증은 잘못이며 A도 B도 증명하지 못한다.
통계에서의 예: 데이터를 수집하기 전에 데이터가 가우시안 분포를 따른다고 가정한다. 수집 후에는 이상치를 제거한다. 그리고 나서 데이터가 가우시안 분포를 따른다고 검증한다. 이 검증은 틀렸는데, 이상치 제거가 가우시안 가정에 의존하기 때문이다.
An error rate can be measured. The measurement, in turn, will have an error rate. The measurement of the error rate will have an error rate ...
We can use the same argument by replacing "measurement" by "estimation" (say estimating the future value of an economic variable, the rainfall in Brazil, or the risk of a nuclear accident).
What is called a regress argument by philosophers can be used to put some scrutiny on quantitative methods or risk and probability. The mere existence of such regress argument will lead to two different regimes, both leading to the necessity to raise the values of small probabilities, and one of them to the necessity to use power law distributions.
- N. N. Taleb, Link
자기 자신을 간접적으로 포함하는 집합은 러셀의 역설(Russel's paradox)을 일으킨다.
자기 자신을 원소로 갖지 않는 모든 집합들의 집합을 R이라고 하자. R이 R을 포함하면 정의상 포함하면 안 되고, 포함하지 않으면 정의상 포함해야 한다. 집합론은 순환 참조를 조심스럽게 피한다.
순수 람다 계산은 직접적인 자기 참조를 허용하지 않는다. 즉 “재귀 함수”를 직접 쓸 수 없다. 하지만 Y 조합자로 우회할 수 있다:
Y=λ f.(λ x.f(x x))(λ x.f(x x))
TypeScript로 쓰면:
type Func<Input, Output> = (input: Input) => Output; type SelfAcceptingFunc<Input, Output> = (s: SelfAcceptingFunc<Input, Output>) => Func<Input, Output>; function Y<Input, Output>( f: (s: Func<Input, Output>) => Func<Input, Output>): Func<Input, Output> { // temp = λ x . f (x x) let temp: SelfAcceptingFunc<Input, Output> = (x: SelfAcceptingFunc<Input, Output>) => f(input => x(x)(input)); // 참고: f(x(x))로 쓰면 무한 루프 return temp(temp); } const factorial = Y((f: (a: number) => number) => (n) => n > 1 ? n * f(n - 1) : 1); console.log(factorial(4));
Y 조합자의 타입은 자기 참조를 요구하지만, Y 조합자의 표현식 자체는 자기 참조를 직접 요구하지 않는다는 점에 주목하라.
Y 조합자는 람다 항의 고정점(fixed point)을 준다. Y f = f (Y f).
우선 기호, 명제, 증명을 데이터로 인코딩한다. 자유 변수를 포함하는 명제(예: “x는 짝수”에서 x)는 인코딩할 수 있고, 이는 “함수”나 “고차 함수”까지 나타낼 수 있다.
구체적으로 괴델은 기호/명제/증명을 정수(괴델 수)로 인코딩했다. 인코딩 방식은 다양하며 어떤 방식을 쓰는지는 중요하지 않다. 단순화를 위해 여기서는 모두 데이터를 다루고, 데이터와 기호/명제/증명 사이 변환은 무시한다.
정의:
is_proof(theory, proof): 어떤 proof가 theory를 성공적으로 증명하는지 판정. Lean 같은 형식 언어로 쓰인 증명은 결정적으로 검증 가능.provable(theory): is_proof(theory, proof) 를 만족하는 proof 가 존재하는지 여부를 불리언으로 반환unprovable(theory): provable(theory) 의 부정그 다음 Y 조합자와 같은 형태 (λ x.f(x x))(λ x.f(x x)) 를 사용한다:
H(x) = unprovable(x(x)) 를 정의. 이는 f 가 unprovable 인 λ x.f(x x) 에 해당G = H(H) 를 정의. 이는 (λ x.f(x x))(λ x.f(x x)) 에 해당그러면 G = H(H) = unprovable(H(H)) = unprovable(G) 가 된다. 즉 G 는 “G는 증명 불가능하다”라는 자기 지시적 명제가 된다. G 가 참이면 G 는 증명 불가능하고, 그러면 G 는 거짓이 되는 식의 역설이 생긴다.
여기서 x(x) 는 기호 치환(symbol substitution)이다. 자유 변수 x 를 x 로 치환하는데, 필요하면 변수 이름 충돌을 피하기 위해 리네이밍한다.
참고 링크:
갭 락 외에도 아직 존재하지 않는 행을 락킹하는 방법으로 predicate lock이 있다. 이는 어떤 술어(predicate)를 만족하는 모든 새 값을 막는다. PostgreSQL의 serializable 격리 수준에서 사용된다. ↩
Rust는(unsafe를 쓰지 않을 때) 메모리 안전성을 보장하면서도 튜링 완전이다. 이는 Rice의 정리와 모순되지 않는다. Rust의 제약 하에서는 메모리 안전성이 “자명한 성질(trivial property)”이기 때문이다. ↩
조기 취소를 구현하는 것은 어렵다. 클라이언트가 요청 처리 중 TCP 연결을 닫아도 백엔드는 보통 요청 처리 코드를 즉시 멈추고 메모리를 즉시 해제하지 못한다. 스레드를 강제로 죽이는 것은 위험한데, 정리(cleanup: 자원 해제, 뮤텍스 해제)가 실행되지 않거나 자료구조 불변식을 깨뜨릴 수 있기 때문이다. ↩