LoRA-GA는 초기 그라디언트를 SVD로 분해해 LoRA의 첫 스텝 업데이트를 전량 미세튜닝과 최대한 가깝게 맞추는 방법을 제안한다. 이 아이디어는 직관적 이론 근거와 함께 GLUE, LLaMA2-7B 등 다양한 벤치마크에서 전량 미세튜닝에 근접한 성능을 보여주며, 특히 적은 데이터/스텝에서 효율을 높인다.
서문
잘 알려져 있듯이, LoRA는 매개변수 효율적인 미세튜닝 방법의 하나이며, 우리는 《기울기 관점의 LoRA: 소개, 분석, 추측 및 확장》에서 간단히 소개한 바 있다. LoRA는 업데이트를 저랭크 분해로 표현하여 학습해야 할 파라미터 수를 줄이고, 미세튜닝 시의 메모리 사용량을 절약한다. 또한 학습된 가중치는 원래 가중치에 합칠 수 있어 추론 아키텍처를 바꿀 필요가 없으니, 학습과 추론 모두 친화적인 방식이다. 아울러 우리는 《서로 다른 학습률을 주면 LoRA가 더 오를까?》에서 LoRA의 비대칭성을 논의하며 A, B에 서로 다른 학습률을 주는 것이 더 좋은 효과를 낸다는 점을 지적했고, 이 결론은 "LoRA+"라 불린다.
효과를 더 끌어올리기 위해 연구자들은 AdaLoRA, rsLoRA, DoRA, PiSSA 등 여러 변형을 제안해 왔다. 각각 나름의 타당성이 있지만, 특별히 각인될 만큼 인상적이진 않았다. 그런데 엊그제 공개된 《LoRA-GA: Low-Rank Adaptation with Gradient Approximation》은 초록만 훑어도 “이건 반드시 통하겠다”는 느낌이 들었고, 꼼꼼히 읽어보니 지금까지 본 LoRA 개선 중 가장 빼어난 작품이라 여겨졌다.
어떤 점이 그렇게 뛰어날까? LoRA-GA의 실제 가치는 어떨까? 함께 살펴보자.
기초 복습#
먼저 LoRA를 다시 복습해 보자. 사전학습 가중치가 W 0∈R n×m 라고 하자. 전량 미세튜닝(full fine-tuning)의 업데이트도 당연히 n×m 행렬이다. LoRA는 이 업데이트를 저랭크 행렬로 제한해 학습 파라미터 수를 줄인다. 즉 W = W 0 + A B 로 두고, 여기서 A∈R n×r, B∈R r×m, 그리고 r≪min(n,m)이다. 새 가중치 W로 모델의 원 가중치를 대체하고, W 0 는 고정한 채 A, B만 학습한다. 그림으로 쓰면 대략 다음과 같다:
W 0∈R n×m + A∈R n×r × B∈R r×m
LoRA의 초기 상태를 사전학습 모델과 일치시키기 위해 보통 A, B 중 하나를 영(0)으로 초기화하여 A 0 B 0=0이 되게 한다. 그러면 초기 W는 W 0 와 동일하다. 하지만 이것은 필수는 아니다. 만약 A, B 모두를 영이 아닌 값으로 초기화한다면, W를 다음과 같이 두기만 하면 된다.
W = (W 0 − A 0 B 0) + A B (1)
즉 고정 불변의 가중치를 W 0 대신 W 0 − A 0 B 0 로 바꾸면, 역시 “초기 W가 W 0 와 같다”는 조건을 만족할 수 있다.
덧붙이면, LoRA는 대개 메모리가 부족할 때의 차선책이다. 일반적으로 전량 미세튜닝이 LoRA보다 성능이 더 좋기 때문에, 연산/메모리가 충분하고 최상의 성능을 추구한다면 전량 미세튜닝을 우선 선택하는 것이 바람직하다. LoRA-GA도 이러한 가정을 전제로 한다. LoRA-GA의 개선 방향이 바로 전량 미세튜닝과의 정렬(alignment)이기 때문이다. LoRA의 또 다른 사용 시나리오는 소규모 맞춤 모델을 대량으로 만들어 저장해야 할 때다. 이때 LoRA는 저장 비용을 줄여 준다.
전량과의 정렬#
LoRA-GA는 매우 깊이 있는 최적화 포인트를 제시한다. W = (W 0 − A 0 B 0) + A B 라는 구성으로 W의 초기값이 W 0 와 같아지므로, 초기 상태에서 LoRA와 전량 미세튜닝은 동치다. 그렇다면 A 0, B 0 를 더 조정하여 이후 학습 과정에서도 LoRA가 전량 미세튜닝을 최대한 가깝게 따르게 만들 수 없을까? 예컨대 가장 단순하게는, 첫 한 스텝 업데이트 후의 W 1 이 서로 최대한 같아지게 할 수 없을까?
곱씹을수록 이 포인트가 “본질을 정확히 겨냥”하고 있음을 느끼게 된다. LoRA의 목적이란 바로 “작은 것으로 큰 효과를” 내어 전량 미세튜닝의 성능에 근접하는 것이다. 그렇다면 이후의 업데이트 결과를 전량 미세튜닝과 최대한 정렬시키는 것이야말로 가장 옳은 개선 방향이다. 근사 관점에서 보면 “초기 W가 W 0 와 같다”는 것은 전량 미세튜닝에 대한 0차 근사이고, 뒤이은 W 1, W 2, …를 가깝게 유지한다는 것은 더 고차의 근사에 해당한다. 이 선택은 매우 합리적이며, 필자가 초록만 보고도 “바로 이거야”라는 강한 확신을 갖게 된 이유다.
구체적으로, 최적화기가 SGD라고 하자. 전량 미세튜닝에서는
W 1 = W 0 − η ∂L/∂W 0 (2)
여기서 L은 손실함수, η는 학습률이다. LoRA의 경우는 다음과 같다.
A 1 = A 0 − η ∂L/∂A 0 = A 0 − η ∂L/∂W 0 B⊤0
B 1 = B 0 − η ∂L/∂B 0 = B 0 − η A⊤0 ∂L/∂W 0
W 1 = W 0 − A 0 B 0 + A 1 B 1 ≈ W 0 − η (A 0 A⊤0 ∂L/∂W 0 + ∂L/∂W 0 B⊤0 B 0) (3)
마지막 근사는 η의 2차 항을 생략한 것이다. 이제 두 W 1 이 유사한 꼴을 갖췄다. 둘을 최대한 가깝게 만들기 위해 다음을 최소화해 보자.
argmin A 0,B 0 ‖ A 0 A⊤0 ∂L/∂W 0 + ∂L/∂W 0 B⊤0 B 0 − ∂L/∂W 0 ‖^2_F (4)
여기서 ‖·‖_F는 행렬의 Frobenius 노름의 제곱, 즉 모든 원소 제곱의 합이다.
해법 유도#
간단히 G 0=∂L/∂W 0 로 두면, (4)식의 목표는 다음과 같이 쓸 수 있다.
argmin A 0,B 0 ‖ A 0 A⊤0 G 0 + G 0 B⊤0 B 0 − G 0 ‖^2_F (5)
여기서 A 0 A⊤0 G 0 와 G 0 B⊤0 B 0 의 랭크는 많아야 r이고, 그 합의 랭크도 많아야 2r이다. 2r < min(n, m)이라 가정하자. 그러면 위 목표는 곧 G 0 를 랭크 ≤ 2r로 최적으로 근사하는 문제와 같다.
먼저 G 0 가 음이 아닌 대각행렬이고, 대각 원소가 큰 순서대로 정렬돼 있다고 하자. 이 경우는 간단하다. 랭크 ≤ 2r의 최적 근사는 대각선의 앞 2r개 원소만 남긴 새 대각행렬이다. 이는 “Eckart-Young-Mirsky 정리”로 알려져 있다. 그리고 A 0, B 0 를 적절히 잡아 A 0 A⊤0 G 0 + G 0 B⊤0 B 0 가 G 0 의 앞 2r개 대각 원소만 남기게 만들 수 있다. 한 가지 선택(분할 행렬 표기)은 다음과 같다.
A 0 = (I n)[:,:r], B 0 = (I m)[r:2r,:] (6)
여기서 I n, I m 은 각각 n, m 차원의 단위행렬이고, [:,:r]과 [r:2r,:]은 파이썬 슬라이싱처럼 앞 r개 열과 r+1∼2r번째 행을 뜻한다. “그럴 수 있다”라고 한 것은 해가 유일하지 않음을 의미한다. 요지는 G 0 의 앞 2r개 대각 원소를 골라오되, A 0 A⊤0 G 0 와 G 0 B⊤0 B 0 가 절반씩 나눠 갖게 하면 된다는 것이다. 위 선택은 A 0 A⊤0 G 0 이 앞 r개를, G 0 B⊤0 B 0 이 r+1∼2r개를 담당하는 경우다.
G 0 가 대각행렬이 아닐 때는 SVD로 G 0=U Σ V 로 분해하자. 여기서 U∈R n×n, V∈R m×m 은 직교행렬, Σ∈R n×m 는 비음수 대각 원소를 큰 순으로 갖는 대각행렬이다. 이를 (5)식에 대입하면
‖A 0 A⊤0 G 0 + G 0 B⊤0 B 0 − G 0 ‖^2_F = ‖A 0 A⊤0 U Σ V + U Σ V B⊤0 B 0 − U Σ V‖^2_F = ‖U[(U⊤A 0)(U⊤A 0)⊤Σ + Σ(B 0 V⊤)⊤(B 0 V⊤) − Σ]V‖^2_F = ‖(U⊤A 0)(U⊤A 0)⊤Σ + Σ(B 0 V⊤)⊤(B 0 V⊤) − Σ‖^2_F (7)
앞의 두 등호는 단순 치환이고, 세 번째 등호는 직교변환이 Frobenius 노름을 보존하기 때문이다. 이렇게 바꾸고 나면 근사 대상이 다시 대각행렬 Σ가 되고, 변수는 U⊤A 0 와 B 0 V⊤ 로 바뀐다. 그러면 대각행렬 경우의 해를 그대로 적용하여 다음을 얻는다.
A 0 = U (I n)[:,:r] = U[:,:r], B 0 = (I m)[r:2r,:] V = V[r:2r,:] (8)
일반적 결과#
이제 LoRA의 한 가지 초기화 방법을 얻었다.
이렇게 하면 LoRA + SGD로 얻는 W 1 이 전량 미세튜닝의 W 1 과 최대한 가깝다. 또한 그라디언트에서 중요한 것은 방향이며 크기는 상대적으로 중요하지 않다. 따라서 초기화 결과에 scale을 곱하거나, LoRA 자체에 scale(예: W = (W 0 − λ A 0 B 0) + λ A B)을 곱하는 것도 가능하다. 이런 항들은 LoRA에서 흔한 하이퍼파라미터이므로 여기서는 더 다루지 않겠다. 참고로 형식상 LoRA-GA와 비슷한 것으로 PiSSA가 있는데, 이는 W 0 를 SVD하여 A, B를 초기화한다. 이 방법은 이론적 뒷받침이 LoRA-GA만큼 견고하지 않아, 경험적 선택에 가깝다.
아마 독자 중에는 지금까지의 유도가 SGD 가정에 기반한다는 점을 눈치챘을 것이다. 우리가 더 자주 쓰는 Adam에 대해서는 결론이 달라져야 하지 않을까? 이론적으로는 그렇다. 《서로 다른 학습률을 주면 LoRA가 더 오를까?》에서 논의했듯 Adam의 첫 스텝 업데이트는 W 1 = W 0 − η sign(G 0)이지, W 1 = W 0 − η G 0 가 아니다. 이를 그대로 따라가면 최적화 목표는 아래가 된다.
argmin A 0,B 0 ‖ A 0 sign(A⊤0 G 0) + sign(G 0 B⊤0) B 0 − sign(G 0) ‖^2_F (9)
하지만 부호 함수 sign이 끼면서 해의 해석적 형태를 얻기 어렵다. 따라서 Adam에 대한 이론 분석은 여기까지다.
이 배경에서 Adam을 쓸 때 선택지는 셋이다.
원 논문은 1번을 택한 것으로 보이며, 실험 결과도 이를 뒷받침한다.
실험 결과#
논문의 실험 결과는 상당히 인상적이다. 특히 GLUE에서 전량 미세튜닝에 가장 근접한 성능을 달성했다.
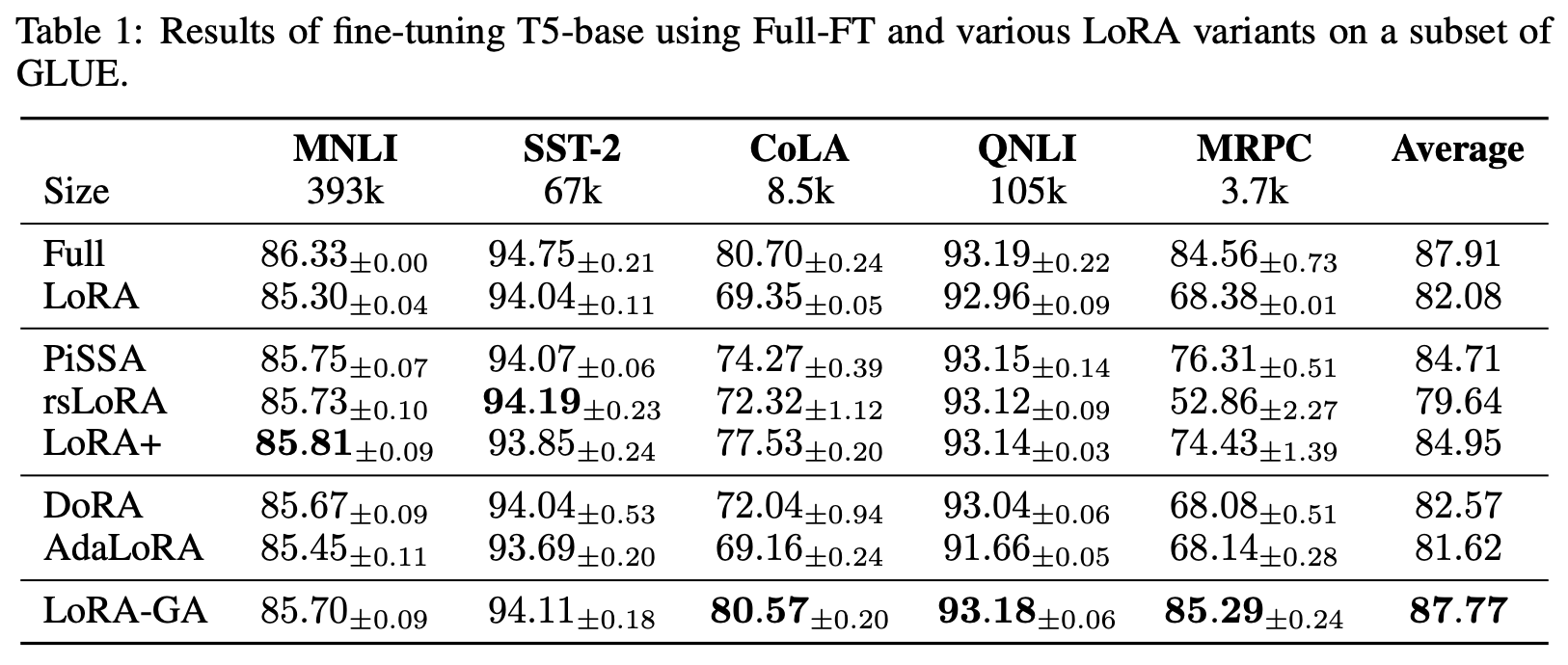
LoRA-GA + T5-Base의 GLUE 성능
평균적으로 학습 데이터가 적을수록 상대 향상이 더 크다. 이는 전량 미세튜닝과의 정렬 전략이 최종 성능을 높일 뿐 아니라 학습 효율도 높여, 더 적은 스텝으로 더 나은 성능에 도달할 수 있음을 시사한다.
LLAMA2-7b에서도 준수한 성능을 보였다.
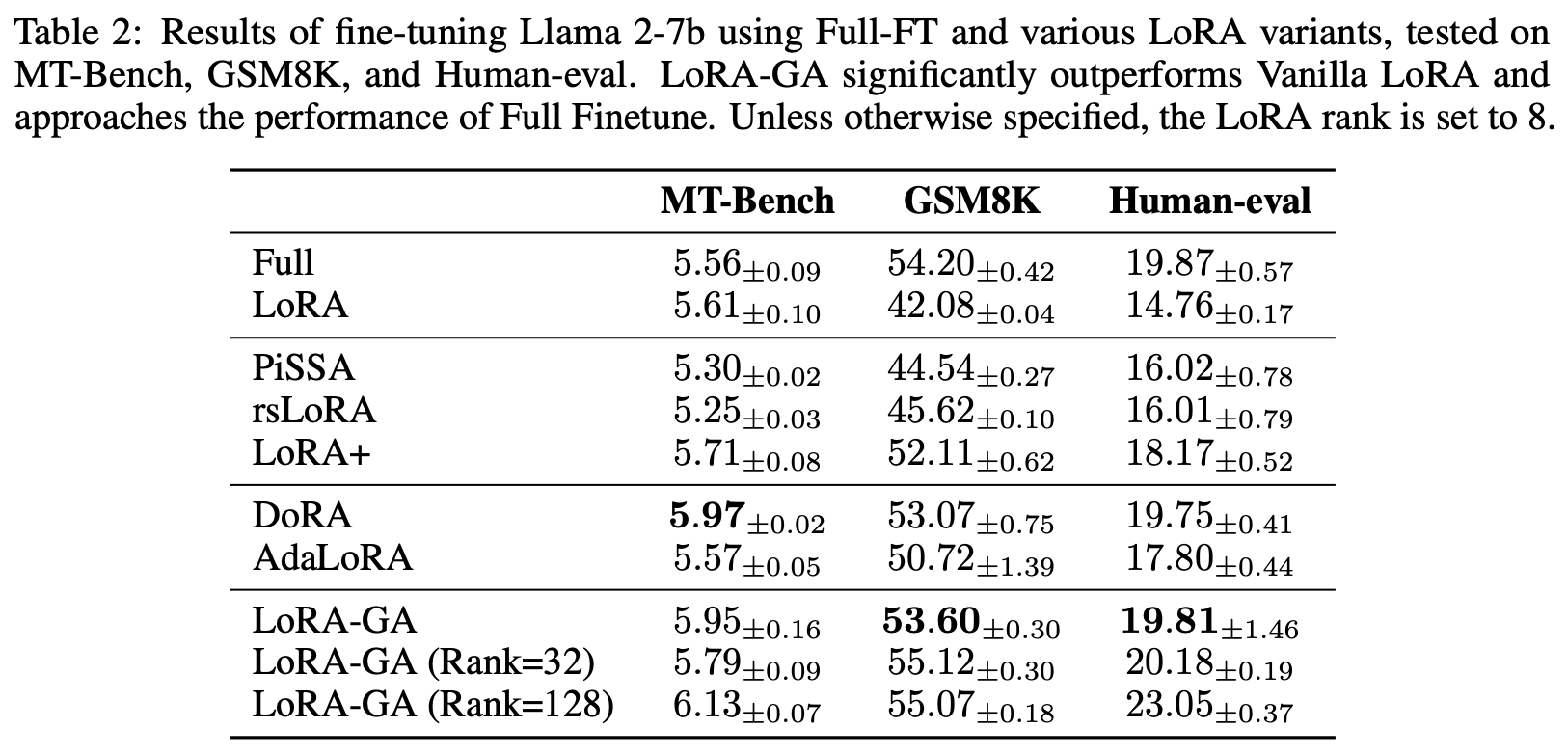
LoRA-GA + LLaMA2-7B의 여러 벤치마크 성능
유의할 점은 LoRA의 주요 사용처가 메모리 부족 상황이라는 것이다. 그런데 LoRA-GA 초기화에는 모든 학습 파라미터에 대한 완전한 그라디언트를 구해야 하므로, 메모리 부족으로 실행이 어려울 수 있다. 이를 위해 원 논문은 모든 파라미터의 그라디언트를 한 번에 동시에 계산하지 말고, 파라미터를 하나씩 직렬로 처리해 그라디언트를 구하는 요령을 제시한다. 이렇게 하면 단일 스텝의 메모리 사용량을 낮출 수 있다. 직렬 계산은 효율을 떨어뜨리지만, 초기화는 한 번만 수행하면 되므로 조금 느려도 무방하다. 구현 방법은 프레임워크마다 다르므로 여기서는 자세히 다루지 않는다.
글 마무리#
본 글은 LoRA의 새로운 개선인 LoRA-GA를 소개했다. LoRA 변형은 드물지 않지만, LoRA-GA는 매우 직관적인 이론적 지침으로 필자를 설득했다. 그 개선 아이디어는 “눈빛만 봐도 알 수 있다, 이건 맞는 논문이다”라는 느낌을 주었고, 여기에 준수한 실험 결과가 더해지니 처음부터 끝까지 군더더기 없이 시원하게 읽힌다.
재게시 시 본문 주소를 포함해 주세요: https://kexue.fm/archives/10226
더 자세한 재게시 안내는 다음을 참고: 《과학공간 FAQ》