코딩 에이전트 시대에 Zig와 Rust를 비교하며, allocator, packed struct, comptime, 타입 시스템, 메모리 안전성 관점에서 왜 Rust가 더 매력적으로 느껴지는지 설명합니다.
거의 3년 전, 코딩 에이전트가 등장하기 전, 저는 Zig와 unsafe Rust로 바이트코드 VM과 가비지 컬렉터를 작성했고, unsafe 코드를 작성하는 인간 관점의 사용성은 Zig 쪽이 더 낫다고 느꼈습니다.
안타깝게도, 요즘은 손으로 직접 코드를 쓰는 일이 점점 줄어들고 있어서, 이제 Zig를 써야 할 이유도 점점 줄어들고 있습니다. Zig 기능이 주는 인간 DX 생산성 향상 1.5-5배는 Rust에서의 코딩 에이전트가 주는 100배 향상에 가려집니다.
Zig의 최고의 기능들 중 많은 것들은 인간 중심의 사용성을 위해 설계되었지만, 에이전트에게는 이게 그렇게까지 중요하지 않습니다.
제가 좋아하는 Zig 기능들과, 왜 그것들이 이제는 그렇게 중요하지 않은지 이야기해보겠습니다.
이것은 제가 가장 좋아하는 Zig 기능입니다. 특정 코드 경로를 최적화하기 위해 특수한 allocator를 사용할 때 정말 엄청나게 똑똑해진 기분이 듭니다. 예를 들면 arena, stack fallback 같은 것들입니다.
// A real example:
// Reading a line of user input requires a heap allocator because
// in theory the input length is unbounded. In practice though,
// the input is almost always a short search query or path that
// fits in well under 1kb.
//
// stackFallback puts a fixed-size buffer on the stack and only
// hits the heap when the input overflows it. The common case
// costs zero heap allocations. The rare long input still works
// because the allocator silently upgrades to the heap.
var stack_fallback = std.heap.stackFallback(256, heap_allocator);
const alloc = stack_fallback.get();
const line = try reader.readUntilDelimiterAlloc(alloc, '\n', 4096);
defer alloc.free(line);
Rust에서의 문제는 예전에는 이에 해당하는 Allocator interface가 없었다는 점이었습니다. 그래서 커스텀 allocator를 사용하는 Vec<T>를 원하면, 정말로 std 버전을 복사해서 붙여넣고 allocator를 쓰도록 수정해야 했습니다. (Bumpalo가 바로 이렇게 했습니다. 소스를 보면, 그 컬렉션들은 bump allocator에 연결되도록 만든 std 버전의 포크입니다.)
이제는 꽤 오래전부터 nightly에 Allocator trait가 있었고, 지금은 꽤 괜찮아 보입니다. trait이기 때문에 Zig의 vtable 기반 방식과 달리 정적 디스패치입니다.
Zig와 달리 allocator에 대해 매개변수화된 데이터 구조를 설계하는 것이 커뮤니티 전체의 관례는 아니지만, AI는 판도를 바꿔 놓았고 코드를 복사해서 그렇게 바꾸는 일을 아주 쉽게 만들어줍니다. 제 사용 사례에서는 충분히 잘 작동한다고 느낍니다.
이것도 제가 아주 사랑하는 Zig 기능입니다. DOD 스타일의 CPU 캐시 최적화나 tagged pointer, NaN boxing 같은 것들을 매우 쉽게 할 수 있게 해주고, bitflags를 만드는 일조차 정말 쉬웠습니다.
여기 실제 예가 있습니다. Obj-C runtime C API를 통해 Metal 같은 Obj-C API를 사용할 때, id는 정렬된 힙 객체 포인터가 아니라 tagged pointer일 수 있습니다. 저는 정렬이 보장된다고 가정하는 코드에 tagged NSNumber를 넘겼다가 UB를 겪었습니다.
그래서 값싼 “힙 포인터 대 tagged immediate” 검사가 필요합니다. 여기 단순화한 Objective-C tagged pointer 레이아웃이 있습니다. 하위 1비트는 “힙 포인터가 아님”을 뜻하고, 그 다음 3비트는 클래스 슬롯을 식별하며, 나머지 60비트는 payload입니다:
pub const TaggedClass = enum(u3) {
ns_atom = 0,
ns_string = 1,
ns_number = 2,
ns_date = 3,
};
pub const ObjcTaggedPointer = packed struct {
is_tagged: bool = true,
class: TaggedClass,
payload: u60,
pub fn ns_number(n: u60) ObjcTaggedPointer {
return .{ .class = .ns_number, .payload = n };
}
pub fn from_raw(raw: u64) ObjcTaggedPointer {
return @bitCast(raw);
}
pub fn raw(self: ObjcTaggedPointer) u64 {
return @bitCast(self);
}
pub fn is_ns_number(self: ObjcTaggedPointer) bool {
return self.is_tagged and self.class == .ns_number;
}
};
이에 대응하는 Rust 버전은 생성 시 Objective-C 클래스 슬롯을 OR로 집어넣고, 접근할 때마다 마스킹으로 제거합니다. 그 슬롯은 실제 타입이 아니라 그냥 u64 상수일 뿐입니다:
pub struct ObjcTaggedPointer(u64);
impl ObjcTaggedPointer {
const TAG_MASK: u64 = 0b1;
const CLASS_MASK: u64 = 0b1110;
const CLASS_SHIFT: u64 = 1;
const PAYLOAD_SHIFT: u64 = 4;
const CLASS_NS_ATOM: u64 = 0;
const CLASS_NS_STRING: u64 = 1;
const CLASS_NS_NUMBER: u64 = 2;
const CLASS_NS_DATE: u64 = 3;
pub fn ns_number(n: u64) -> Self {
Self(
(n << Self::PAYLOAD_SHIFT)
| (Self::CLASS_NS_NUMBER << Self::CLASS_SHIFT)
| Self::TAG_MASK,
)
}
pub fn is_ns_number(self) -> bool {
self.0 & Self::TAG_MASK != 0
&& (self.0 & Self::CLASS_MASK) >> Self::CLASS_SHIFT == Self::CLASS_NS_NUMBER
}
}
보다시피 Rust의 기본 방식은 사용성이 떨어집니다. 사실 bitfield/bitflags 같은 crate를 쓰는 편이 더 낫습니다. 둘 다 proc macro 마법에 의존하며, 저는 Zig의 packed struct만큼 좋다고 느끼지 않습니다.
하지만 코딩 에이전트가 있으면, 손으로 코드를 쓰기 얼마나 귀찮은지는 정말 신경 쓰이지 않습니다.
이것은 Zig에서 가장 눈에 띄는 기능입니다. 아마 생소한 dependent types 계열 언어들을 제외하면, Zig만큼 컴파일 타임 평가가 훌륭한 프로그래밍 언어는 없습니다. 저는 이 기능이 많이 그리울 줄 알았지만, 실제로는 그렇지 않았습니다. 저에게 comptime 사용의 95%는 매개변수화된 타입을 가진 Zig식 제네릭 데이터 구조를 만드는 데 쓰입니다. 예를 들면:
fn ArrayList(comptime T: type) type {
return struct {
items: []T,
capacity: usize,
allocator: Allocator,
};
}
const IntList = ArrayList(i32);
제 생각에 Rust는 더 잘 설계된 타입 시스템을 가지고 있습니다. (다음 섹션 참고)
나머지 5%의 경우에는 comptime이 없는 것이 아쉽습니다. 이에 상응하는 것을 얻는 유일하게 믿을 만한 방법은 코드 생성입니다. 저는 지금 게임을 만들고 있는데, 툴에서 생성된 하드코딩된 히트박스 기하 데이터가 있고, 이것을 어떤 데이터 구조 안에 구워 넣고 싶습니다. comptime이 없으니 Claude에게 Rust 파일을 생성하는 스크립트를 쓰게 해야 합니다. 그래도 어쨌든 컴파일 타임 평가가 그렇게 자주 필요하다고 느끼지는 않습니다.
저는 comptime을 갖는 것보다 Rust의 더 잘 설계된 타입 시스템을 택하는 편이 낫다고 생각합니다. 특히 bounded polymorphism(traits/typeclasses)에서는 더 그렇습니다. Zig에서 그에 해당하는 것을 하려 하면 악몽입니다.
또한 Rust의 타입 시스템은 더 많은 불변 조건을 강제할 수 있고, 코딩 에이전트가 흔히 저지르는 실수를 막아준다고 생각합니다. 제 게임에서는 euclid crate를 쓰는데, 이것은 각 좌표 공간마다 특수한 타입을 만들어(예: Point<Screen> 또는 Point<World>) 좌표 공간을 서로 혼동하지 않게 해줍니다. 이는 그래픽스 프로그래밍에서 매우 흔한 문제입니다:
use euclid::{point2, vec2, Point2D, Translation2D, Vector2D};
struct WorldSpace;
struct ScreenSpace;
type WorldPoint = Point2D<f32, WorldSpace>;
type WorldVector = Vector2D<f32, WorldSpace>;
type ScreenPoint = Point2D<f32, ScreenSpace>;
fn main() {
let player: WorldPoint = point2(10.0, 20.0);
let movement: WorldVector = vec2(5.0, 0.0);
// Allowed: point + vector in the same space.
let moved_player = player + movement;
// Allowed: explicitly convert from world space to screen space.
let world_to_screen = Translation2D::<f32, WorldSpace, ScreenSpace>::new(100.0, 50.0);
let player_on_screen: ScreenPoint = world_to_screen.transform_point(moved_player);
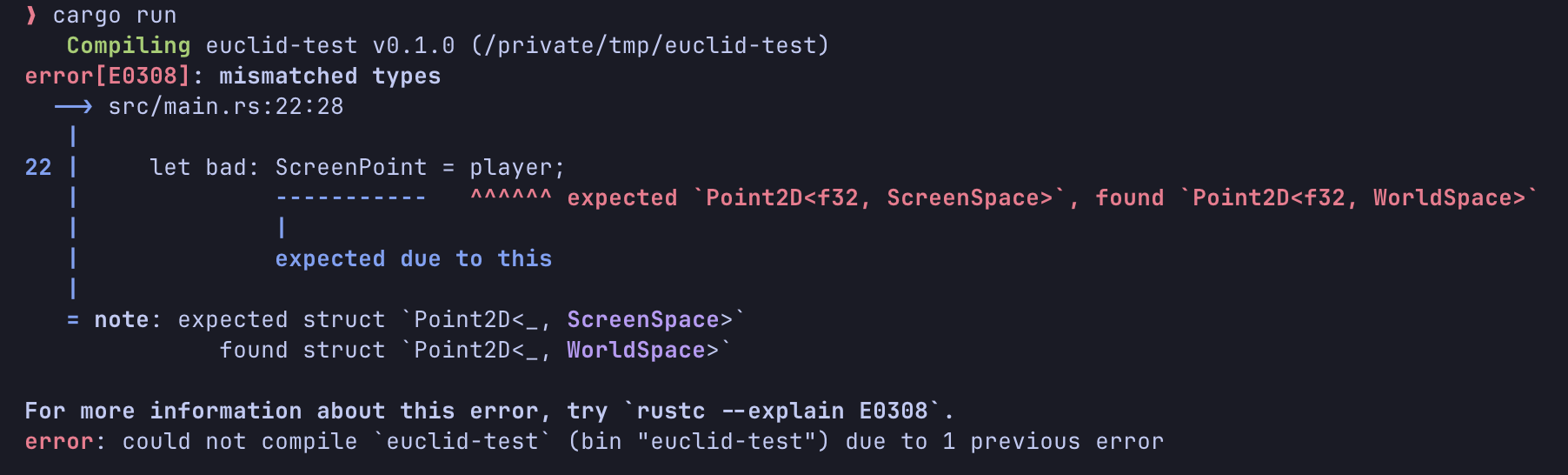
// Disallowed: can't mix coordinate spaces.
let bad: ScreenPoint = player;
}
이 덕분에 에이전트가 월드 공간 좌표와 스크린 공간 좌표를 섞어버리는 어처구니없는 실수를 하지 않게 됩니다:
코딩 에이전트 덕분에 작성되는 코드가 100배 많아진다는 것은, 메모리 문제를 찾기 위해 검토해야 할 Zig 코드도 100배 많아진다는 뜻이기도 합니다. 형식 검증이 없다면, 버그를 찾기 위해 살펴봐야 하는 탐색 공간의 표면적이 이제는 너무 커졌습니다. 지금처럼 생성되는 코드의 규모를 생각하면 Rust는 더더욱 매력적입니다. Rust의 트레이드오프는 특히 borrow checker에 익숙하지 않을 경우 개발자 생산성을 저해한다는 것이었지만, 코딩 에이전트가 있는 지금은 이것이 전혀 중요하지 않습니다.
그리고 Rust에서 unsafe를 사용하더라도 miri 같은 도구가 있어서, 코딩 에이전트에게 코드를 그것으로 실행하게 하여 UB를 일으키지 않는지, unsafe와 관련해 Rust의 aliasing 규칙을 위반하지 않는지 확인할 수 있습니다.
저는 여전히 Zig로 코드를 쓰는 것이 그립고, 훌륭한 언어라고 생각하지만, 저는 Rust를 더 좋아하고 코딩 에이전트도 Rust와 더 잘 맞습니다.
질문이 있으신가요? 제가 완전히 터무니없고 틀린 말을 했나요? Twitter로 연락 주세요.