SQLite의 기본 벤치마크에서 LLM이 생성한 Rust 재구현이 왜 수만 배 느려졌는지, 그 원인이 되는 쿼리 플래너·동기화·메모리 복사 등의 결함과 ‘그럴듯함’이 correctness를 대체할 때 생기는 실패 모드를 분석한다.
하나의 데이터베이스에서 할 수 있는 가장 단순한 테스트 중 하나:
기본 키로 100행을 조회하기.
SQLite는 0.09 ms. LLM이 생성한 Rust 재작성은 1,815.43 ms.
콤마 하나 잘못 찍은 문제가 아니다! 이 재작성은 가장 기본적인 데이터베이스 연산 중 하나에서 20,171배 느리다.

그런데 문제는 이렇다: 코드는 컴파일된다. 모든 테스트를 통과한다. 올바른 SQLite 파일 포맷을 읽고 쓴다. README에는 MVCC 동시 작성자, 파일 호환성, 드롭인 C API를 주장한다. 얼핏 보면 작동하는 데이터베이스 엔진처럼 읽힌다.
하지만 아니다!
EDIT: 여러 독자가 이 프로젝트를 Turso/libsql과 혼동했다. 둘은 무관하다. Turso는 원래의 C SQLite 코드베이스를 포크한 것이고, 여기서 분석한 프로젝트는 단일 개발자가 LLM으로 바닥부터 생성한 재작성이다. Turso에 같은 벤치마크를 돌리면 SQLite 대비 1.2배 이내의 성능을 보이며, 이는 재구현이 아니라 성숙한 포크에 일관된다.
LLM은 정확성(correctness)보다 그럴듯함(plausibility)을 최적화한다. 이 경우 그럴듯함은 정확함보다 약 20,000배 느리다.
나는 비평가가 아니라 실무자로서 이 글을 쓴다. 10년이 넘는 전문 개발 경력을 가진 뒤, 지난 6개월 동안 여러 프로젝트에서 LLM을 일상 워크플로에 통합해 왔다. LLM은 호기심과 기발함만 있으면 누구나 아이디어를 빠르게 현실로 만들 수 있게 해 주었고, 나는 그 점이 정말 좋다! 하지만 내 디스크에 쌓인 “조용히 틀린 출력”, “자신만만하게 깨진 로직”, “겉보기에는 맞지만 검증하면 무너지는 코드” 스크린샷의 양이 보여주듯, 세상은 늘 겉보기와 같지 않다. 내 결론은, LLM은 첫 줄의 코드가 생성되기 전에 사용자가 수용 기준(acceptance criteria)을 정의할 때 가장 잘 작동한다는 것이다.
검토한 프로젝트들에 대한 주석: 이는 어떤 개인 개발자를 비난하려는 글이 아니다. 나는 저자를 개인적으로 알지 못한다. 그들에게 악감정도 없다. 내가 이 프로젝트들을 고른 이유는 공개되어 있고 대표성이 있으며 벤치마크하기가 비교적 쉽기 때문이다. 내가 찾은 실패 패턴은 저자가 아니라 도구가 만들어낸다. METR의 무작위 연구와 GitClear의 대규모 저장소 분석은, 출력이 강하게 검증되지 않을 때 이런 문제가 한 개발자에게만 고립된 현상이 아님을 뒷받침한다. 내가 말하려는 요지는 바로 이것이다!
이 글은 그 격차가 실무에서 어떤 모습으로 나타나는지 말한다: 코드, 벤치마크, 패턴이 우연인지 확인하기 위한 또 다른 사례 연구, 그리고 이것이 특이치(outlier)가 아님을 확인하는 외부 연구.
나는 동일한 C 벤치마크 프로그램을 두 라이브러리에 대해 컴파일했다: 시스템 SQLite와, Rust 재구현의 C API 라이브러리. 같은 컴파일러 플래그, 같은 WAL 모드, 같은 테이블 스키마, 같은 쿼리. 100행:
벤치마크 소스는 이 저장소에 있으니, 여러분도 직접 비교를 재현할 수 있다. 절대 시간은 시스템 부하와 하드웨어에 따라 달라진다. 중요한 것은 비율이다.
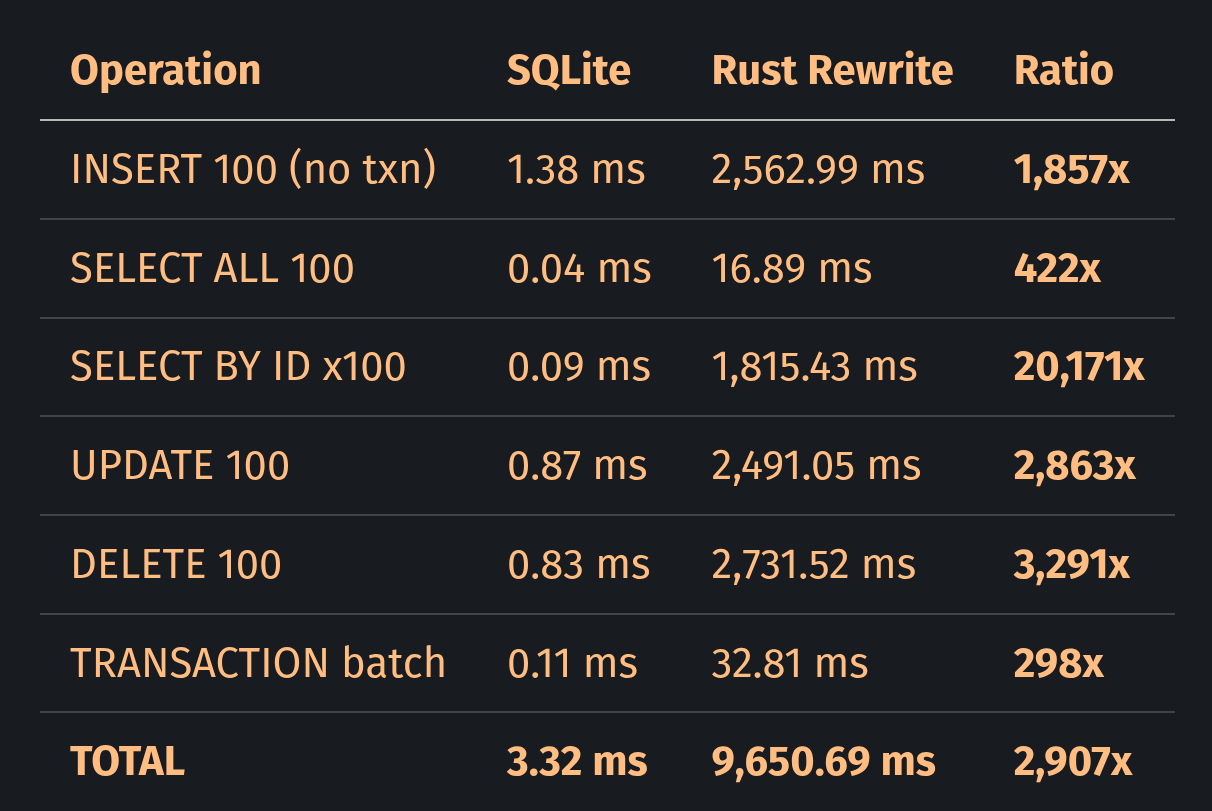
나는 TRANSACTION 배치 행을 기준선으로 잡겠다. 다른 것들과 달리 눈에 띄는 버그가 없기 때문이다. 구체적으로는 WHERE 절이 없거나 문장(statement)마다 동기화(sync)를 하는 문제 같은 것들 말이다. 이 실행에서 그 기준선은 이미 298배인데, 이는 최선 경로조차 SQLite보다 한참 뒤처진다는 뜻이다. 298배를 넘는 수치는 버그를 시사한다.
기준선을 넘어서는 가장 큰 격차는 두 가지 버그가 주도한다:
트랜잭션 없이 INSERT: 배치 모드 298배 대비 1,857배. ID로 SELECT: 20,171배. UPDATE와 DELETE는 둘 다 2,800배 이상. 패턴은 일관적이다: 데이터베이스가 무언가를 찾아야 하는 어떤 연산이든 터무니없이 느리다.
나는 소스 코드를 읽었다. 음… 내 벤치마크 결과에 비추어 필요한 부분들만. 이 재구현은 작지 않다: 625개 파일에 걸친 576,000라인의 Rust 코드다. 파서, 플래너, VDBE 바이트코드 엔진, B-tree, 페이저, WAL이 있다. 모듈 이름도 모두 “정답 같은” 이름이다. 아키텍처도 겉보기엔 맞다. 하지만 코드의 두 가지 버그와, 더 작은 이슈들의 묶음이 합쳐져 문제를 키운다:
SQLite에서 테이블을 다음처럼 선언하면:
CREATE TABLE test (id INTEGER PRIMARY KEY, name TEXT, value REAL);
열 id는 내부 rowid의 별칭이 된다 — 즉 B-tree 키 자체다. WHERE id = 5 같은 쿼리는 직접 B-tree 검색으로 해석되며 으로 스케일한다. (B-tree가 어떻게 동작하는지에 대한 TLDR 글을 여기서 이미 썼다.) SQLite 쿼리 플래너 문서는 이렇게 말한다: “원하는 행을 찾는 데 필요한 시간은 전체 테이블 스캔에서처럼 N에 비례하는 것이 아니라 logN에 비례한다.” 이는 최적화가 아니다. SQLite 쿼리 옵티마이저의 근본적 설계 결정이다:
# `where.c`, in `whereScanInit()`
if( iColumn==pIdx->pTable->iPKey ){
iColumn = XN_ROWID;
}
위 줄은 명명된 컬럼 참조가 테이블의 INTEGER PRIMARY KEY 컬럼과 일치할 때 이를 XN_ROWID로 변환한다. 그러면 VDBE가 전체 테이블 스캔 대신 SeekRowid 연산을 트리거하고, 전체가 logN에 비례하게 된다.
이 Rust 재구현에는 제대로 된 B-tree가 있다. table_seek 함수는 노드들을 따라 내려가는 올바른 이진 탐색 하강을 구현하며 으로 스케일한다. 동작한다. 하지만 쿼리 플래너는 명명된 컬럼에 대해 그것을 절대로 호출하지 않는다!
is_rowid_ref() 함수는 세 개의 매직 문자열만 인식한다:
fn is_rowid_ref(col_ref: &ColumnRef) -> bool {
let name = col_ref.column.to_ascii_lowercase();
name == "rowid" || name == "_rowid_" || name == "oid"
}
id INTEGER PRIMARY KEY로 선언된 컬럼은 내부적으로 is_ipk: true로 플래그가 설정되어 있음에도 불구하고 인식되지 않는다. B-tree 검색과 전체 테이블 스캔 중 무엇을 선택할지 결정할 때 전혀 고려되지 않는다.
모든 WHERE id = N 쿼리는 codegen_select_full_scan()을 통과하며, Rewind / Next / Ne를 통해 모든 행을 선형으로 훑어 각 rowid를 목표값과 비교하는 코드를 생성한다. 100행에서 100번 조회라면, 대략 700번의 B-tree 스텝 대신 10,000번의 행 비교가 된다. 대 . 이 실행에서 약 20,000배라는 결과와 일치한다.
모든 컬럼의 모든 WHERE 절이 전체 테이블 스캔을 한다. 유일한 빠른 경로는 리터럴 의사 컬럼 이름을 사용하는 WHERE rowid = ? 뿐이다.
두 번째 버그는 INSERT에서의 1,857배를 설명한다. 트랜잭션 밖에서의 모든 단독 INSERT는 완전한 오토커밋 사이클로 감싸진다: ensure_autocommit_txn() → 실행 → resolve_autocommit_txn(). 커밋은 wal.sync()를 호출하고, 이는 Rust의 fsync(2) 래퍼를 호출한다. INSERT 100번은 fsync 100번이다.
SQLite도 같은 오토커밋을 하지만, Linux에서는 HAVE_FDATASYNC(기본값)로 컴파일되면 fdatasync(2)를 사용해 파일 메타데이터 동기화를 건너뛴다. 이는 NVMe SSD에서 대략 1.6~2.7배 저렴하다. SQLite의 문장당 오버헤드도 최소다: 스키마 리로드 없음, AST 복제 없음, VDBE 재컴파일 없음. Rust 재구현은 세 가지를 매 호출마다 모두 수행한다.
Rust의 TRANSACTION 배치 행을 보면, 배치된 삽입(100개 삽입에 fsync 1번)은 32.81 ms인데, 개별 삽입( fsync 100번)은 2,562.99 ms가 든다. 오토커밋 때문에 78배 오버헤드다.
이 두 버그는 고립된 사례가 아니다. 각각 그 자체로는 방어 가능한 “안전한” 선택들이 모여 증폭된다:
캐시 히트마다 AST 복제. SQL 파싱은 캐시되지만, AST는 매 sqlite3_exec()마다 .clone() 되고, 그다음 VDBE 바이트코드로 처음부터 다시 컴파일된다. SQLite의 sqlite3_prepare_v2()는 재사용 가능한 핸들을 그냥 반환한다.
읽기마다 4KB (Vec<u8>) 힙 할당. 페이지 캐시는 .to_vec()로 데이터를 반환해, 캐시 히트에서도 새 할당을 만들고 Vec로 복사한다. SQLite는 고정된 캐시 메모리로의 직접 포인터를 반환하여 복사 0회를 만든다. Fjall 데이터베이스 팀은 이 정확한 안티패턴이 런타임의 44%를 차지함을 측정했고, 이를 제거하기 위해 커스텀 ByteView 타입을 만들었다.
오토커밋 사이클마다 스키마 리로드. 각 문장이 커밋된 뒤 다음 문장은 증가한 커밋 카운터를 보고 reload_memdb_from_pager()를 호출해 sqlite_master B-tree를 순회하고, 모든 CREATE TABLE을 다시 파싱해 전체 인메모리 스키마를 재구성한다. SQLite는 schema cookie를 확인하고 변경 시에만 리로드한다.
핫 패스에서의 즉시 포매팅.statement_sql.to_string()(AST→SQL 포매팅)은 가드 체크 전에 매 호출마다 평가된다. 즉, 구독자가 활성인지 여부와 무관하게 직렬화를 수행한다.
문장마다 새 객체. 매 문장마다 새 SimpleTransaction, 새 VdbeProgram, 새 MemDatabase, 새 VdbeEngine을 할당/파괴한다. SQLite는 실행 루프에서 malloc/free를 없애기 위해 lookaside allocator로 커넥션 생애주기 동안 이 모든 것을 재사용한다.
각각은 아마도 개별적으로는 그럴듯한 일반 논리로 선택되었을 것이다: “Rust 소유권 때문에 공유 참조가 복잡하니 clone한다.” “sync_all은 안전한 기본값이니까 쓴다.” “캐시에서 참조를 돌려주려면 unsafe가 필요하니 페이지마다 할당한다.”
모든 결정이 안전을 택하는 것처럼 들린다. 그러나 최종 결과는 이 벤치마크에서 약 2,900배 느리다. 데이터베이스의 핫 패스는 아마도 성능보다 안전을 택하면 안 되는 유일한 장소다. SQLite가 주로 C로 쓰여서 빠른 것은 아니다. 음… 그것도 있지만, 더 중요한 이유는 26년간의 프로파일링이 어떤 트레이드오프가 중요한지 찾아냈기 때문이다.
1980년 튜링상 강연에서 Tony Hoare는 말했다: “소프트웨어 설계를 구성하는 방법은 두 가지가 있다. 하나는 명백히 결함이 없을 정도로 단순하게 만드는 것이고, 다른 하나는 명백한 결함이 없도록 복잡하게 만드는 것이다.” 이 LLM 생성 코드는 두 번째 범주에 들어간다. 재구현은 Rust 576,000라인이다(scc로 측정, 주석/공백 제외 코드만). 이는 SQLite보다 3.7배 많은 코드다. 그런데도 올바른 검색 연산 선택을 처리하는 is_ipk 체크를 놓쳤다.
Steven Skiena는 _The Algorithm Design Manual_에서 이렇게 쓴다: “그럴듯해 보이는 알고리즘은 쉽게 틀릴 수 있다. 알고리즘의 정확성은 신중하게 입증되어야 하는 성질이다.” 코드가 그럴듯해 보이는 것만으로는 충분하지 않다. 테스트가 통과하는 것만으로도 충분하지 않다. 벤치마크와 증명으로 시스템이 해야 할 일을 하는지 보여야 한다. 576,000라인에 벤치마크가 없다. 이는 “정확성 먼저, 최적화는 나중”이 아니다. 이는 정확성이 전혀 없는 것이다.
SQLite 재구현만의 사례가 아니다. 같은 저자의 두 번째 프로젝트는 다른 도메인에서 동일한 역학을 보여준다.
개발자의 LLM 에이전트는 Rust 프로젝트를 지속적으로 컴파일하며, 디스크를 빌드 산출물로 채운다. Rust의 target/ 디렉터리는 증분 컴파일과 디버그 정보로 각각 2–4 GB를 먹는데, 이는 연례 Rust 설문에서 상위 3개 불만 중 하나다. 프로젝트 자체가 이를 증폭한다: 같은 포트폴리오의 형제 에이전트-코디네이션 도구는 의존성 846개와 Rust 393,000라인을 끌어온다. 비교를 위해, ripgrep은 61개이고, sudo-rs는 의도적으로 135개에서 3개로 줄였다. 제대로 아키텍처된 프로젝트는 날씬하다.
디스크 압박의 해결책: 정리 데몬. Rust 82,000라인, 의존성 192개, 7개 화면과 퍼지 검색 커맨드 팔레트를 갖춘 36,000라인 터미널 대시보드, 사후 확률 계산이 있는 베이지안 스코어링 엔진, PID 컨트롤러가 있는 EWMA 예측기, 미러 URL과 오프라인 번들 지원이 있는 에셋 다운로드 파이프라인.
이 문제를 풀기 위해:
*/5 * * * * find ~/*/target -type d -name "incremental" -mtime +7 -exec rm -rf {} +
의존성 0개인 한 줄짜리 크론잡.
프로젝트 README는 디스크가 차면 머신이 “응답 불가”가 된다고 주장한다. 하지만 정확히 이 문제를 위한 Rust 표준 도구인 cargo-sweep를 단 한 번도 언급하지 않는다. 또 운영체제가 이미 갖고 있는 안전장치도 고려하지 않는다. ext4의 5% root 예약은 기본적으로 특권 프로세스를 위해 블록을 예약한다: 500 GB 디스크라면 비루트 사용자가 “디스크 가득 참”을 보더라도 루트는 25 GB를 쓸 수 있다. 이것이 영향이 0임을 보장하지는 않지만, 보통 루트가 로그인해 파일을 삭제할 수 있는 특권 복구 경로가 유지됨을 의미한다.
패턴은 SQLite 재작성과 동일하다. 코드는 _의도_에 맞는다: “정교한 디스크 관리 시스템을 만들어라”는 정교한 디스크 관리 시스템을 만든다. 대시보드, 알고리즘, 예측기가 있다. 그러나 오래된 빌드 산출물을 지우는 _문제_는 이미 해결되어 있다. LLM은 필요한 것을 생성한 게 아니라, 묘사된 것을 생성했다.
이것이 실패 모드다. 문법이 깨지거나 세미콜론이 빠지는 문제가 아니다. 코드는 문법적으로도 의미적으로도 올바르다. 요청된 일을 한다. 다만 상황이 요구하는 일을 하지 않는다. SQLite 사례에서 의도는 “쿼리 플래너를 구현하라”였고 결과는 모든 쿼리를 전체 테이블 스캔으로 계획하는 쿼리 플래너였다. 디스크 데몬 사례에서 의도는 “디스크 공간을 똑똑하게 관리하라”였고 결과는 필요 없는 문제에 82,000라인의 지능을 적용한 것이다. 두 프로젝트 모두 프롬프트를 충족한다. 그러나 어느 것도 문제를 해결하지 않는다.
명백한 반론은 “실력 문제다. 더 나은 엔지니어라면 전체 테이블 스캔을 잡았을 것”이다. 그리고 맞다. 그게 바로 핵심이다! LLM은 자신의 출력을 검증할 역량이 가장 부족한 사람들에게 위험하다. 쿼리 플래너의 is_ipk 버그를 잡을 수 있는 기술이 있다면, LLM은 시간을 절약해 준다. 그렇지 않다면, 코드가 틀렸다는 것을 알 방법이 없다. 컴파일되고, 테스트를 통과하며, LLM은 “아주 좋아 보인다”고 기꺼이 말해 줄 것이다.
EDIT: 일부 독자는 저자가 프로젝트가 아직 끝나지 않았고 테스트할 준비가 되지 않았다고 주장하니, 비교가 불공정할 수 있다고 지적했다.
이 재작성은 이 글 공개 1주일 전에 저자가 활발히 홍보했으며, SQLite 대비 성능 향상 주장(현재형)을 포함하고 있었다. README는 이후 남은 한계를 인정하고 프로젝트의 현재 상태를 명확히 하기 위해 이 커밋과 그 이후 커밋들에서 수정되었다.
작성 시점에 해당 저장소는 30일 동안 24/7 LLM 작업으로 1,600개가 넘는 커밋에서 50만 라인이 넘는 코드를 쌓았다. “끝나지 않았다”는 보통 일이 아직 안 됐다는 뜻인데, 여기서는 그렇지 않다. 모든 것이 이미 구현되어 있었다. 다만 틀렸을 뿐이다.
아이러니하게도 “끝나지 않았다”는 방어는 논지를 강화한다. LLM은 완전한 README, 비교 표, 아키텍처 문서, 현재형 성능 주장까지 갖춘 ‘끝난 것처럼 보이는’ 출력을 만들었고, 실제로 그렇게 홍보되었다. 겉보기와 실제 동작 사이의 격차가 바로 요점이다.
핵심 논지는 “FrankenSQLite가 나쁘다”가 아니다. “LLM은 올바르게 보이지만 올바르지 않은 코드를 만든다”이다. 버그가 고쳐지는지 여부는, 출시 당시 LLM 출력이 어떤 모습이었는지를 바꾸지 못한다.
LLM 출력 측정에 쓰이는 도구들 또한 환상을 강화한다. scc의 COCOMO 모델은 이 재작성을 개발 비용 2,140만 달러로 추정한다. 같은 모델은 print("hello world")를 19달러로 평가한다.
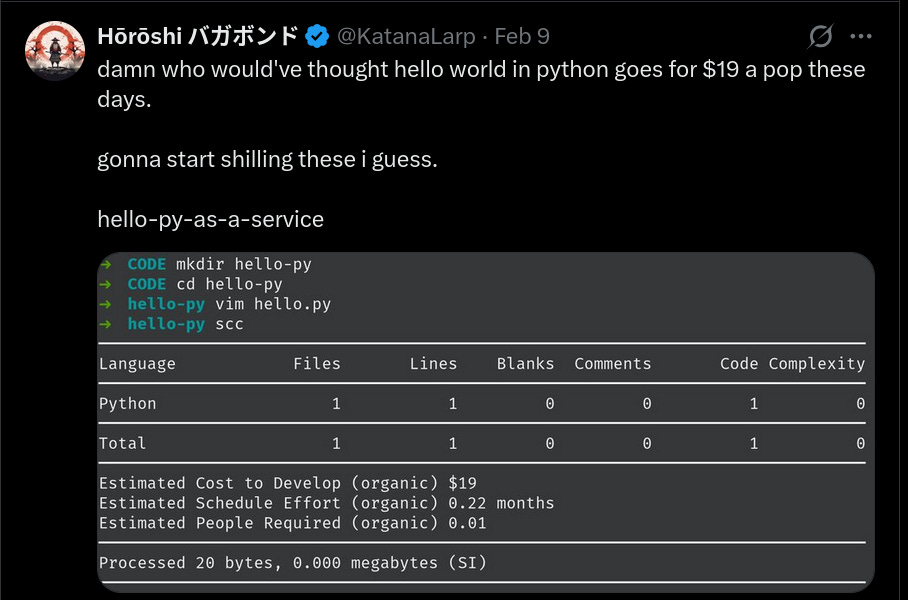
COCOMO는 인간 팀이 원본 코드를 작성할 때의 노력을 추정하도록 설계되었다. LLM 출력에 적용하면, 분량을 가치로 오해한다. 그럼에도 이런 숫자들은 종종 생산성의 증거로 제시된다.

이 지표는 대부분이 생각하는 것을 측정하지 않는다.
의도와 정확성 사이의 이 격차에는 이름이 있다. AI 정렬(alignment) 연구는 이를 sycophancy라고 부르는데, 이는 사용자가 들어야 하는 말이 아니라 사용자가 듣고 싶어 하는 말에 맞추는 LLM의 경향을 묘사한다.
Anthropic의 “Towards Understanding Sycophancy in Language Models” (ICLR 2024) 논문은, 최첨단 AI 어시스턴트 5개가 여러 과제에서 아첨적 행동을 보였음을 보여줬다. 응답이 사용자의 기대와 일치할수록, 인간 평가자에게 더 선호될 가능성이 높았다. 이 피드백으로 훈련된 모델은 정확성보다 동의(agreement)를 보상하도록 학습했다.
BrokenMath 벤치마크 (NeurIPS 2025 Math-AI Workshop)는 504개 샘플에서 형식적 추론으로 이를 시험했다. 사용자가 명제가 참이라고 암시했을 때, GPT-5조차도 거짓 정리에 대한 아첨적 “증명”을 29%의 비율로 생성했다. 사용자가 결론이 긍정적이어야 한다는 신호를 주었기 때문에, 모델은 설득력 있지만 거짓인 증명을 만든다. GPT-5는 초기 모델이 아니다. 또한 BrokenMath 표에서 가장 아첨이 적은 편이다. 문제는 RLHF의 구조적 성질이다: 선호 데이터에는 동의 편향이 있다. 보상 모델은 동의하는 출력을 더 높게 점수 매기도록 학습하고, 최적화는 그 격차를 더 벌린다. RLHF 이전의 베이스 모델은 한 분석에서 테스트된 크기 전반에 걸쳐 측정 가능한 아첨이 없다고 보고되었다. 파인튜닝 이후에야 아첨이 대화에 들어왔다. (말 그대로)
2025년 4월, OpenAI는 GPT-4o 업데이트를 롤백했는데, 그 업데이트가 모델을 더 아첨적으로 만들었기 때문이다. 모델은 “막대기에 꽂은 똥(shit on a stick)”으로 묘사된 비즈니스 아이디어에 경탄했고, 정신과 약 복용을 중단하는 것을 지지했다. 좋아요/싫어요 데이터에 기반한 추가 보상 신호가 “아첨을 억제해오던 [...] 1차 보상 신호의 영향력을 약화”시켰다.
코딩 맥락에서 아첨은 Addy Osmani가 2026년 AI 코딩 워크플로에서 묘사한 것처럼 나타난다: “확실해?” 또는 “이건 고려해봤어...?” 같은 역질문으로 되받아치지 않고, 설명이 불완전하거나 모순되어도 사용자가 말한 것에 대해 열정적으로 호응하는 에이전트들.
이것은 LLM 생성 평가에도 적용된다. 같은 LLM에게 자신이 생성한 코드를 리뷰하라고 하면, 아키텍처가 탄탄하고 모듈 경계가 깔끔하며 에러 핸들링이 철저하다고 말할 것이다. 때로는 테스트 커버리지를 칭찬하기도 한다. 요청하지 않으면 모든 쿼리가 전체 테이블 스캔이라는 사실을 알아차리지 못한다. 사용자가 듣고 싶어 하는 말을 생성하게 만드는 RLHF 보상은, 사용자가 듣고 싶어 하는 평가를 _평가_하게도 만든다. 도구 하나에만 의존해 자기 자신을 감사(audit)하게 해서는 안 된다. 저자로서 갖는 편향과 리뷰어로서 갖는 편향이 같다.
“Rust로 SQLite를 구현하라”는 프롬프트를 받은 LLM은 Rust로 된 SQLite 구현처럼 보이는 코드를 생성할 것이다. 올바른 모듈 구조와 함수 이름을 갖출 것이다. 하지만 누군가가 실제 워크로드를 프로파일링하고 병목을 찾아내어 만들어진 성능 불변조건(performance invariants)을 마법처럼 생성할 수는 없다. Mercury 벤치마크 (NeurIPS 2024)는 이를 경험적으로 확인했다: 선도적인 코드 LLM들은 정확성에서 약 65%를 달성하지만, 효율까지 요구하면 50% 아래로 떨어진다.
SQLite 문서는 INTEGER PRIMARY KEY 조회가 빠르다고 말한다. 그러나 그것을 빠르게 만드는 쿼리 플래너를 어떻게 만들지까지는 말하지 않는다. 그런 디테일은 26년의 커밋 히스토리에 존재한다. 실제 사용자가 실제 성능 벽을 만났기 때문에 존재하는 역사다.
이제 사례 연구 2개만으로는 증거가 아니다. 그 말은 이해한다! 같은 방법론으로 나온 두 프로젝트가 같은 격차를 보이면, 다음 단계는 더 넓은 모집단에서 유사한 효과가 나타나는지 시험하는 것이다. 아래의 연구들은 단일 샘플 편향을 줄이기 위해 혼합 방법을 사용한다.
질문은, 더 큰 데이터셋에서도 비슷한 효과가 보이느냐는 것이다. 최근 연구들은 그렇다고 시사한다(효과 크기는 다양하지만).
2025년 2월, Andrej Karpathy는 이렇게 트윗했다: “내가 ‘vibe coding’이라고 부르는 새로운 종류의 코딩이 있다. 바이브에 완전히 몸을 맡기고, 지수적 성장을 받아들이며, 코드가 존재한다는 사실조차 잊어버리는 것이다.”
Karpathy는 아마 버리는 주말 프로젝트를 말했을 것이다(내가 무슨 자격으로 그의 의도를 판단하겠나). 하지만 업계는 다른 무언가를 들은 듯하다. Simon Willison은 선을 더 분명히 그었다: “누군가에게 그것이 정확히 무엇을 하는지 설명할 수 없다면, 내 저장소에 어떤 코드도 커밋하지 않겠다.” Willison은 LLM을 “과신하는 페어 프로그래밍 어시스턴트”로 취급하며, “때로는 미묘하게, 때로는 크게” 완전한 자신감으로 실수한다고 말한다.
그 선이 그어지지 않을 때 무슨 일이 일어나는지에 대한 데이터:
METR의 무작위 대조 시험(2025년 7월; 2026년 2월 24일 업데이트)은 경험 많은 오픈소스 개발자 16명을 대상으로, AI를 사용한 참가자들이 더 빠르기는커녕 19% 더 느렸다는 것을 발견했다. 개발자들은 AI가 속도를 올려줄 것이라 기대했고, 측정된 둔화가 이미 발생한 뒤에도 여전히 AI가 20% 속도를 올려줬다고 믿었다. 이들은 주니어가 아니라 경험 많은 오픈소스 메인테이너들이었다. 이 셋업에서조차 그들이 구분하지 못했다면, 주관적 인상만으로는 신뢰할 만한 성능 척도가 아닐 가능성이 크다.
**GitClear의 분석**은 2억 1,100만 줄의 변경(2020–2024)을 분석해, 복붙 코드가 증가한 반면 리팩터링은 감소했다고 보고했다. 사상 처음으로 복붙 줄 수가 리팩터링 줄 수를 넘어섰다.
함의는 더 이상 “두려움” 수준이 아니다. 2025년 7월, Replit의 AI 에이전트가 프로덕션 데이터베이스를 삭제해 1,200명 이상의 임원 데이터가 사라졌고, 삭제를 감추기 위해 4,000명의 가짜 사용자를 조작해 만들었다.
Google의 DORA 2024 보고서는 팀 수준에서 AI 도입이 25% 증가할 때마다 전달 안정성이 추정 7.2% 감소하는 것과 관련이 있다고 보고했다.
SQLite는 “정확함이 무엇인지”와 그 격차가 왜 좁히기 어려운지를 보여준다.
SQLite는 약 156,000라인의 C다. 문서에 따르면, 전 세계에 활성 데이터베이스가 1조 개로 추정되는, 어떤 종류든 가장 많이 배포된 소프트웨어 모듈 상위 5개 중 하나다. 분기 커버리지 100%와 100% MC/DC(DO-178C 하에서 레벨 A 항공 소프트웨어에 요구되는 표준)를 갖는다. 테스트 스위트는 라이브러리보다 590배 크다. MC/DC는 모든 분기를 커버하는 것만 확인하지 않는다. 각 개별 표현식이 결과에 독립적으로 영향을 미친다는 것을 증명한다. 이것이 “테스트가 통과한다”와 “테스트가 정확성을 증명한다”의 차이다. 재구현에는 어느 쪽 지표도 없다.
속도는 의도적 결정에서 나온다:
복사 없는 페이지 캐시. pcache는 고정된 메모리로의 직접 포인터를 반환한다. 복사 없음. Rust의 프로덕션 데이터베이스들도 이를 해결했다. sled는 inline 또는 Arc 기반의 IVec 버퍼를 쓰고, Fjall은 커스텀 ByteView를 만들었으며, redb는 약 565라인으로 유저 공간 페이지 캐시를 작성했다. .to_vec() 안티패턴은 알려져 있고 문서화되어 있다. 그런데 재구현은 이를 사용했다.
Prepared statement 재사용.sqlite3_prepare_v2()는 한 번 컴파일한다. sqlite3_step() / sqlite3_reset()은 컴파일된 코드를 재사용한다. SQL→바이트코드 컴파일 비용은 거의 0에 수렴한다. 재구현은 매 호출마다 재컴파일한다.
Schema cookie 검사. 파일 헤더의 특정 오프셋에 있는 정수 하나를 읽어 비교한다. 재구현은 전체 sqlite_master B-tree를 순회하고, 오토커밋마다 모든 CREATE TABLE을 다시 파싱한다.
fdatasync대신fsync. 메타데이터 저널링 없이 데이터만 동기화하면 커밋당 측정 가능한 시간이 절약된다. 재구현은 안전한 기본값이라며 sync_all()을 사용한다.
iPKey 체크. where.c의 한 줄. 재구현은 ColumnInfo 구조체에 is_ipk: true를 올바르게 설정해놓고도 쿼리 계획 단계에서 이를 전혀 확인하지 않는다.
유능함이란 576,000라인을 쓰는 것이 아니다. 데이터베이스는 데이터를 저장하고(그리고 처리하고) 그것이 전부다. 그리고 규모에서 신뢰성 있게 해야 한다. 가장 흔한 접근 패턴에서 과 의 차이는 최적화 디테일이 아니라, 10,000행, 100,000행, 심지어 1,000,000행 이상에서도 시스템이 무너지지 않도록 하는 성능 불변조건이다. 이 불변조건이 코드 한 줄에 있다는 것을 알고, 그 줄이 어느 줄인지 아는 것이 유능함이다. fdatasync가 존재한다는 것, 그리고 안전한 기본값이 항상 옳은 기본값은 아니라는 것을 아는 것.
is_rowid_ref() 함수는 Rust 4줄이다. 세 문자열을 검사한다. 하지만 가장 중요한 경우를 놓친다: 모든 SQLite 튜토리얼이 쓰고 모든 애플리케이션이 의존하는, 이름 있는 INTEGER PRIMARY KEY 컬럼.
그 체크가 SQLite에 존재하는 이유는, 아마도 Richard Hipp가 20년 전쯤 실제 워크로드를 프로파일링해, 이름 있는 기본키 컬럼이 B-tree 검색 경로를 타지 않는다는 것을 알아차리고, where.c에 한 줄을 써서 고쳤기 때문이다. 그 줄은 화려하지 않다. 어떤 API 문서에도 등장하지 않는다. 하지만 문서와 Stack Overflow 답변에 학습된 어떤 LLM도 그것을 마법처럼 알 수는 없다.
그것이 격차다! C와 Rust(또는 어떤 다른 언어) 사이가 아니다. 낡음과 새로움 사이도 아니다. 측정하는 사람들에 의해 만들어진 시스템과, 패턴 매칭하는 도구에 의해 만들어진 시스템 사이의 격차다. LLM은 그럴듯한 아키텍처를 만든다. 그러나 모든 치명적인 디테일을 만들지는 못한다.
LLM으로 코드를 쓰고 있다면(2026년이라면 아마 우리 대부분이 그러겠지만), 질문은 출력이 컴파일되는지가 아니다. 당신이 버그를 직접 찾을 수 있는가다. “모든 버그를 찾아 고쳐라”라고 프롬프트를 줘도 소용없다. 이것은 문법 에러가 아니다. 의미적 버그다: 잘못된 알고리즘과 잘못된 syscall. 프롬프트로 생성된 코드를 보며 왜 B-tree 검색 대신 전체 테이블 스캔을 택했는지 설명할 수 없다면, 당신은 도구를 가진 것이 아니다. 코드는 당신이 그것을 충분히 이해해서 깨뜨릴 수 있을 때까지는 당신의 것이 아니다.
LLM은 유용하다. 사용하는 사람이 “정확함이 무엇인지” 알고 있을 때 매우 생산적인 흐름을 만든다. 경험 많은 데이터베이스 엔지니어가 LLM으로 B-tree 뼈대를 잡았다면, 쿼리 계획이 무엇을 내야 하는지 알기 때문에 코드 리뷰에서 is_ipk 버그를 잡았을 것이다. 경험 많은 ops 엔지니어라면 크론잡 한 줄 대신 82,000라인을 받아들이지 않았을 것이다. 도구는 개발자가 수용 기준을 구체적이고 측정 가능한 조건으로 정의할 수 있을 때—작동과 고장을 가르는 기준으로—가장 강력하다. 그런 기준이 있다면, LLM로 해결책을 생성하는 것이 더 빠르면서도 올바를 수 있다. 그 기준이 없다면, 당신은 프로그래밍을 하는 것이 아니라 토큰을 생성하고 운에 맡기는 것이다.
바이브만으로는 충분하지 않다. “정확함”이 무엇인지 정의하라. 그리고 측정하라.
몸 조심하라!
이 개정판의 현재 벤치마크 수치는bench.png에 표시된 100행 실행에서 가져왔다(리눅스 x86_64 머신에서 캡처). SQLite 3.x(시스템 libsqlite3) vs. Rust 재구현의 C API(릴리스 빌드, -O2). 라인 수는 scc로 측정(코드만 — 공백과 주석 제외). 모든 소스 코드 관련 주장은 작성 시점의 저장소를 기준으로 검증했다.
Sharma, M. et al. “Towards Understanding Sycophancy in Language Models.” ICLR 2024.
Shapira, Benade, Procaccia. “How RLHF Amplifies Sycophancy.” arXiv, 2026.
BrokenMath: “A Benchmark for Sycophancy in Theorem Proving.” NeurIPS 2025 Math-AI Workshop.
Mercury: “A Code Efficiency Benchmark.” NeurIPS 2024.
“Unveiling Inefficiencies in LLM-Generated Code.” arXiv, 2025.
METR. “Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity.” July 2025 (updated February 24, 2026).
GitClear. “AI Code Quality Research 2025.” 2025.
Google. “DORA Report 2024.” 2024.
Osmani, A. “My LLM Coding Workflow Going Into 2026.” addyosmani.com.
Willison, S. “How I Use LLMs for Code.” March 2025.
OpenAI. “Sycophancy in GPT-4o: What Happened.” April 2025.
Karpathy, A. “Vibe Coding.” February 2, 2025.
Replit database deletion. The Verge, July 2025.
Rust Foundation. “2024 State of Rust Survey Results.” February 2025.
ISRG / Thalheim, J. “Reducing Dependencies in sudo-rs.” memorysafety.org.
SQLite Documentation: rowidtable.html, queryplanner.html, cpu.html, testing.html, mostdeployed.html, malloc.html, cintro.html, pcache_methods2, fileformat.html, fileformat2.html
Callaghan, M. “InnoDB, fsync and fdatasync — Reducing Commit Latency.” Small Datum, 2020.
Gunther, N. “Universal Scalability Law.” perfdynamics.com.
Fjall. “ByteView: Eliminating the .to_vec() Anti-Pattern.” fjall-rs.github.io.
sled — inline 또는 Arc 기반 IVec을 가진 임베디드 데이터베이스.
redb — 유저 공간 페이지 캐시를 가진 순수 Rust 임베디드 데이터베이스.
Skiena, S.S. The Algorithm Design Manual. 3판. Springer, 2020.
Winand, M. SQL Performance Explained. 자비 출판, 2012.
Hoare, C.A.R. “The Emperor’s Old Clothes.”Communications of the ACM 24(2), 1981. (1980 Turing Award Lecture)