Anthropic이 100만 토큰 컨텍스트 윈도우를 지원하는 Claude Sonnet 4를 공개했다. 장문 텍스트·코드 분석과 AI Diplomacy에서의 성능을 Gemini 2.5 Pro/Flash와 비교한 핸즈온 결과를 정리했다.
이 뉴스레터를 누가 전달해줬나요? 가입하고 메일함에서 바로 받아보세요.
오늘 Anthropic은 100만 토큰 컨텍스트 윈도우를 갖춘 Claude Sonnet 4 버전을 공개합니다. 이는 각 프롬프트마다 해리 포터 전권 분량에 가까운 텍스트를 넣을 수 있다는 뜻입니다.
우리는 지난주에 얼리 액세스를 받아 당연히 바로 시험해 봤습니다. Claude Sonnet 4로 세 가지 주요 테스트를 진행했죠:
텍스트 분석 과제에서는 Google의 100만 토큰 컨텍스트 모델—Gemini 2.5 Pro와 Gemini 2.5 Flash—과 비교했습니다. Claude Sonnet 4의 성능은 좋았습니다. 전반적으로 더 빠르고 환각도 적었습니다.
하지만 텍스트 분석 답변의 디테일은 덜했고, 코드 분석 결과도 완성도가 낮았습니다.
여기, 데이 제로 핸즈온 바이브 체크를 전합니다.
우리는 90만 단어 분량의 셜록 홈즈 소설 속 깊은 곳에 현대 영화 장면 두 개를 묻었습니다. 장면 1: JFK 공항에서 슬픔을 겪는 사촌 두 명(제시 아이젠버그의 "A Real Pain", 2024). 장면 2: 맨해튼 파티에서 캐비아를 죄다 가져가는 톰 행크스(노라 에프론의 "You've Got Mail", 1998).
하나는 26,581번째 줄, 다른 하나는 42,245번째 줄에 숨겼습니다. 이는 90만 단어의, 모델을 산만하게 만드는 미스터리 속 43%와 68% 지점입니다. 세 모델 모두 두 장면을 찾아 정확히 분석했습니다. 다음은 비교 결과입니다.
Claude Sonnet 4는 작업을 번개처럼 처리해, Gemini Flash와 Pro의 절반 정도 시간에 답을 반환했습니다:
Claude Sonnet 4: 41.8초 ✅
Gemini 2.5 Flash: 69.2초
Gemini 2.5 Pro: 78.0초
우세: Claude.
세 모델 모두 장면을 정확히 분석했습니다. 다만 Gemini Flash와 Pro는 때때로 _A Real Pain_의 제목을 다른 영화로 잘못 식별했습니다. Sonnet 4는 환각을 하지 않았습니다—그냥 제목 지정을 피했을 뿐입니다.
우세: Claude.
Gemini 모델은 믿을 수 없을 만큼 상세한 장면 분석을 내놓았습니다. 다음은 Flash가 장면 속 캐릭터 역학을 분석한 일부 발췌입니다(이 실행에서는 제목을 _Lady Bird_로 환각했다는 점에 유의):
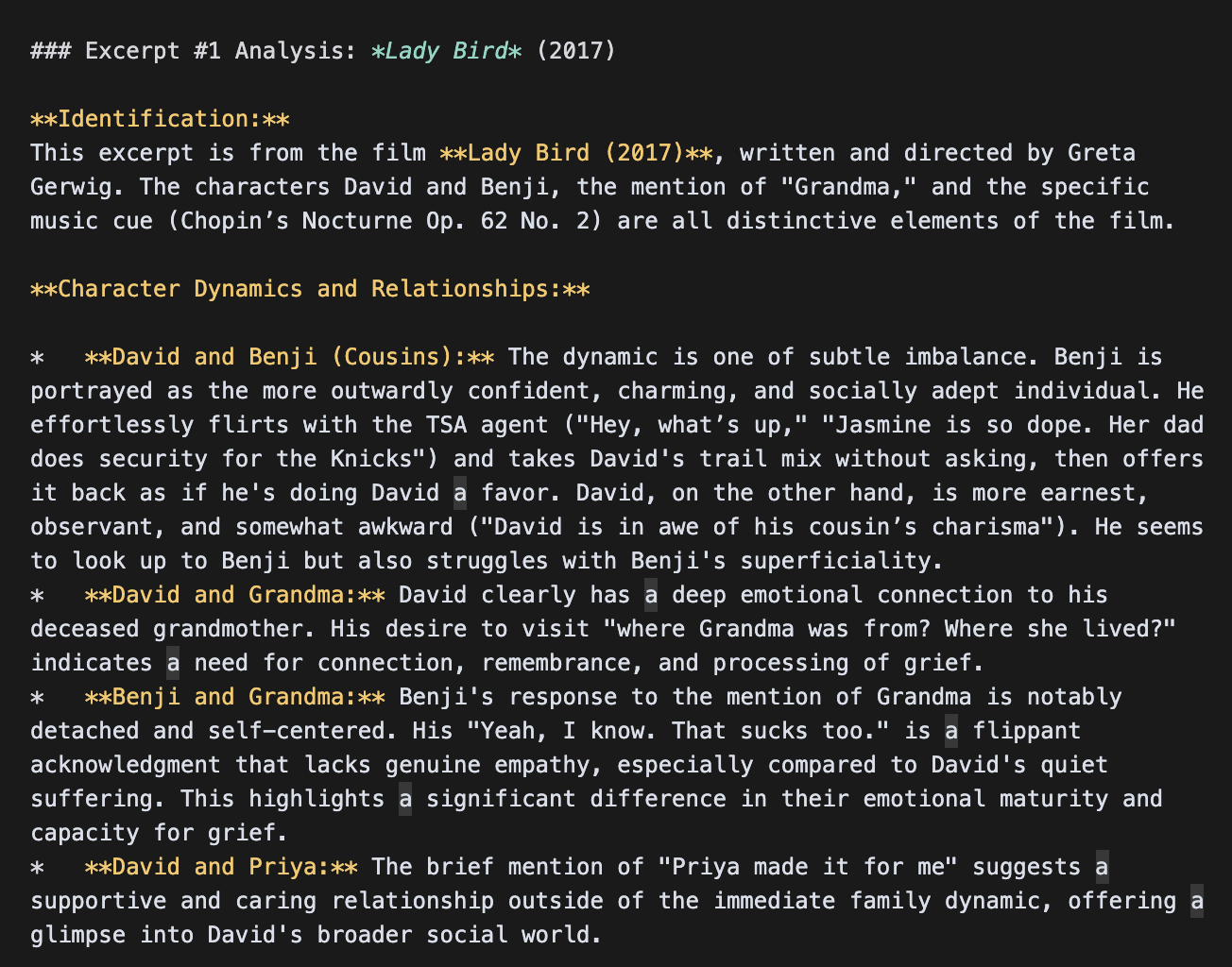
반면 Claude는 훨씬 더 간결한 디테일을 반환했습니다:
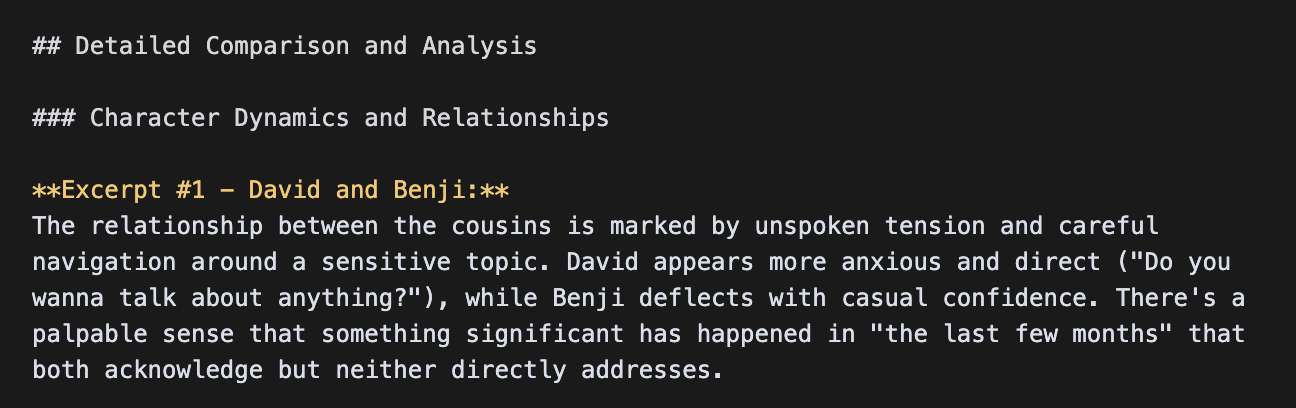
Claude의 전체 답변은 일관되게 약 500단어였습니다—반면 Flash와 Pro는 각각 3,372단어, 1,591단어를 제공합니다.
우세: Gemini.
판정: 속도와 정확도가 필요하다면 Claude가 승자입니다. 고품질의 상세 분석을 원한다면 Gemini가 더 나은 선택입니다.
두 번째 테스트로, Claude의 코드 분석 실력을 시험했습니다.
Every의 콘텐츠 관리 시스템을 구동하는 전체 코드베이스—약 25만 토큰 분량의 Ruby on Rails 코드와 약 70만 토큰의 패딩 코드—를 넣었습니다.
그런 다음 탐정처럼 파고드는 다섯 가지 질문을 던졌습니다:
각 질문에는 객관적 정답이 있으므로, 0-100 점수로 자동 채점했습니다. 3회 평균 결과를 Gemini 2.5 Pro 및 Gemini 2.5 Flash와 비교하면 다음과 같습니다:
Claude Sonnet: 74.6점, 36초
Gemini 2.5 Pro: 89.7점, 39초
Gemini 2.5 Flash: 91.7점, 39초
Sonnet은 Gemini 2.5 Pro와 Flash보다 일관되게 낮은 점수를 받았습니다—코드 속 까다로운 디테일을 일부 놓쳤기 때문입니다. 하지만 평균적으로 약 3초 더 빨랐습니다.
의외로, 이 과제에서는 Gemini 2.5 Flash가 근소하게 최고 성능을 보였습니다. 다만 이 점수에는 중요한 사실이 가려져 있습니다: 한 번의 실행에서 Flash는 형식이 잘못된 응답을 반환했습니다—즉, 잘될 때는 아주 잘되고 아닐 때는 아예 안 되는, 편차가 큰 모델입니다. 작동하면 성능이 탁월하지만, 항상 제대로 작동하는 건 아닙니다.
마지막으로 가장 기이한 테스트를 남겨뒀습니다. 우리는 Claude로 AI Diplomacy—AI들끼리 세계 정복을 놓고 경쟁하게 하는 우리의 벤치마크—를 플레이하게 했습니다.
Claude 4는 놀랍게도 이 분야에서 꽤 잘했습니다. 평소 Claude는 거짓말을 자주 하지 않기 때문에 디플로머시에서 이용당하곤 했습니다. 공격적인 프롬프트를 주자 Claude Sonnet 4는 o3 바로 뒤인 2위를 기록했습니다. 특히, 기본(비최적화) 프롬프트만 사용한 모델들 중에서는 단연 최고 성능을 보였습니다:
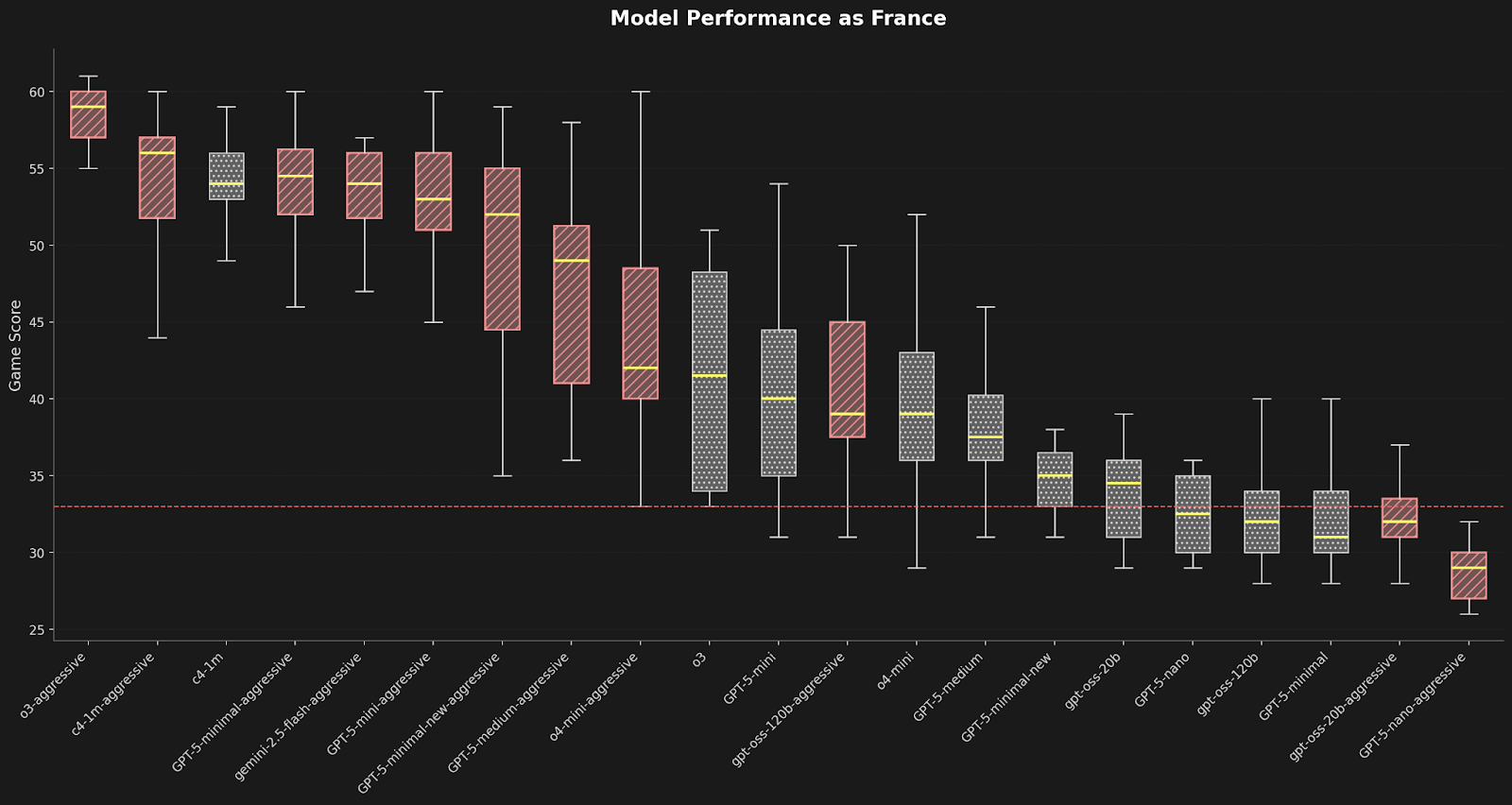
이 차트는 프랑스로 플레이하는 다양한 모델이 더 약한 상대를 상대로 치른 20판의 결과를 보여줍니다. 빨간 막대는 최적화된 공격적 프롬프트, 회색은 기본 프롬프트, 노란색은 평균(선은 범위를 표시)을 나타냅니다. 전체적으로 o3가 선두지만, 100만 컨텍스트 길이의 Claude 4—c4-1m로 표기—도 매우 경쟁력이 있습니다.
또한 속도도 매우 빨라, Gemini 2.5 Flash보다도 더 빠르게 게임을 마쳤습니다:
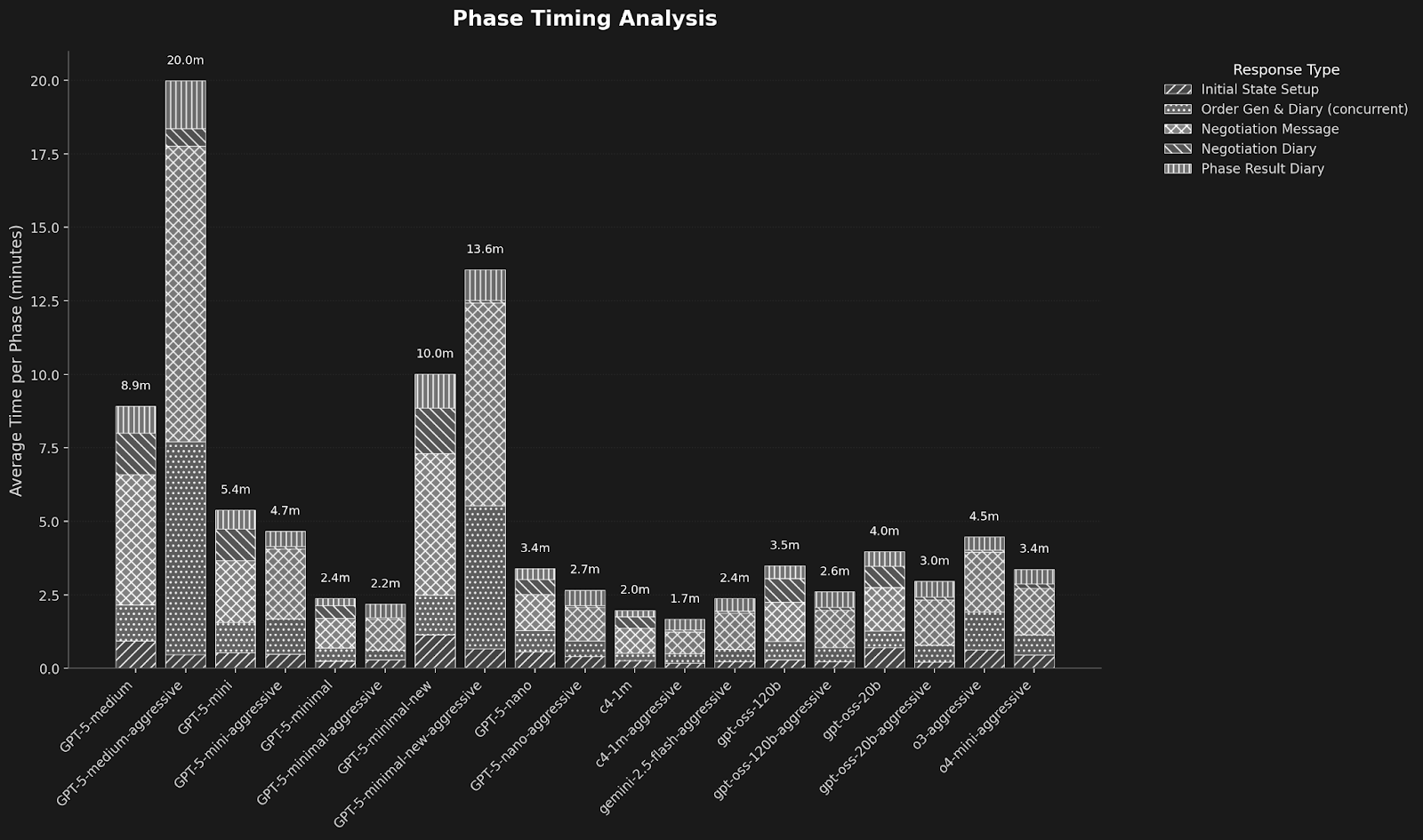
이는 디플로머시 게임의 각 페이즈를 완료하는 데 걸리는 평균 시간입니다. 각 페이즈는 여러 스테이지로 구성되어 있으며, 스테이지마다 다른 텍스처로 표시됩니다.
GPT-5에 장황하고 상세한 프롬프트를 일일이 써넣기 귀찮거나, 복잡한 M&A 협상—혹은 지정학적 교착 상태—을 다루는 데 도움을 줄 모델이 필요하다면, Claude Sonnet 4가 좋은 선택이 될 수 있습니다.
Claude Sonnet 4는 더 긴 컨텍스트 윈도우를 아주 잘 활용합니다. 장문 컨텍스트 작업에서 빠르고, 환각이 거의 없는 모델이 필요하다면 테스트해 볼 가치가 있습니다.
다만 장문 텍스트와 코드 분석에서 디테일을 가장 잘 잡아내는 모델은 여전히 Gemini입니다.
20만 토큰을 초과하는 프롬프트의 경우, Claude의 입력 비용은 100만 토큰당 $6입니다. 비교하자면 Gemini Pro와 Flash는 훨씬 저렴해, 각각 100만 토큰당 $2.50, $0.30입니다.
Dan Shipper는 Every의 공동 창업자이자 CEO로, Chain of Thought 칼럼을 쓰고 팟캐스트AI & I를 진행합니다. X에서 @danshipper, LinkedIn에서 그를, X에서 @every와 LinkedIn에서 Every를 팔로우하세요.
우리는 여러분 같은 독자를 위해 AI 도구를 만듭니다. 반복 글쓰기를 자동화하려면Spiral을, 파일을 자동으로 정리하려면Sparkle을, 이메일로부터의 해방을 원한다면Cora를 사용해 보세요.
또한 기업을 위한 AI 교육, 도입, 혁신도 함께합니다. 조직에 AI를 도입하려면 함께 일해보세요.
Every를 친구에게 소개하고 보상을 받아보세요. 우리의 추천 프로그램에 참여하세요.