이 문서는 RPython 프로그램을 분석하고 다양한 대상 플랫폼용으로 “컴파일”하기 위해 개발한 툴체인을 설명합니다.
목차
이 문서는 RPython 프로그램(예: PyPy 자체)을 분석하고 다양한 대상 플랫폼용으로 “컴파일”하기 위해 우리가 개발한 툴체인을 설명합니다.
이 문서는 크게 세 부분으로 이루어져 있습니다. 약간 단순화한 개요, 툴체인의 주요 구성 요소 각각에 대한 간단한 소개, 그리고 각 부분이 어떻게 함께 맞물리는지를 보다 포괄적으로 설명하는 부분입니다. 이 문서를 처음 읽는다면 개요가 가장 유용할 가능성이 높고, PyPy에 대한 기억을 다시 떠올리려는 목적이라면 전체 구성 방식이 아마 원하는 내용일 것입니다.
번역 툴체인의 역할은 RPython 프로그램을 여러 대상 플랫폼 중 하나를 위한 효율적인 버전으로 변환하는 것입니다. 일반적으로 그 대상은 Python보다 훨씬 저수준인 플랫폼입니다. 이 작업은 여러 단계로 나뉘며, 이 문서의 목적은 그 단계들을 소개하는 것입니다.
우선 RPython 프로그램을 C로 변환하는 과정을 설명하겠습니다. 이것이 기본이자 원래의 대상입니다.
RPython 번역 툴체인은 Python 소스 코드나 구문 트리를 직접 보지 않습니다. 대신 입력으로 주어진 함수 객체의 동작을 정의하는 code objects 에서 시작합니다. 플로우 그래프 빌더는 추상 해석을 사용해 이 코드 객체들을 처리하여 제어 흐름 그래프를 생성합니다(함수당 하나). 이것 역시 소스 프로그램의 또 다른 표현이지만, 타입 추론과 번역 기법을 적용하기에 적합하며, 번역 단계 대부분이 작동하는 근본적인 자료 구조입니다.
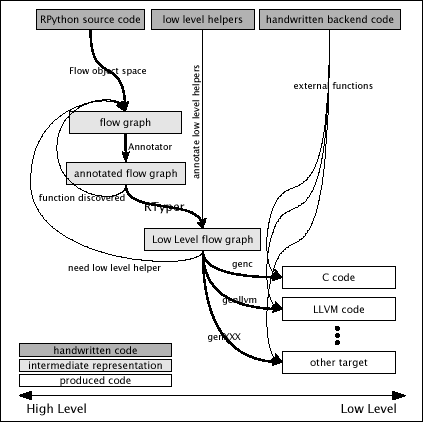
번역은 다음과 같은 단계들로 이루어진다고 생각하면 도움이 됩니다(아래 그림도 참고하십시오).
(다만 이 단계들이 이 설명에서 보이는 것만큼 완전히 분리되어 있는 것은 아닙니다.)
번역 과정에는 rpython/bin/translatorshell.py라는 대화형 인터페이스가 있어서, 이 단계들을 대화식으로 살펴볼 수 있습니다.
다음 그림은 단순화된 개요를 보여줍니다(PDF 컬러 버전).
플로우 그래프 빌더의 역할(소스는 rpython/flowspace/에 있음)은 함수로부터 제어 흐름 그래프를 생성하는 것입니다. 이 그래프에는 개별 연산의 추적도 포함되므로, 실제로는 함수의 또 다른 표현이라고 할 수 있습니다.
기본 아이디어는 인터프리터가 예를 들어 다음과 같은 함수를 받으면:
def f(n): return 3*n+2
이를 바이트코드로 컴파일한 뒤 자신의 VM에서 실행한다는 것입니다. 대신 플로우 그래프 빌더에는 추상 인터프리터가 들어 있어, 바이트코드를 받아 필요한 스택 재배치와 변수 조작을 수행하되, Python 객체에 대해 실제로 수행되는 모든 연산을 basic block이라는 구조에 기록만 합니다. 연산의 결과는 이후 연산에 다시 등장할 수 있는 플레이스홀더 값으로 표현됩니다.
예를 들어 위 함수의 인수로 플레이스홀더 v1이 주어지면, 바이트코드 인터프리터는 다음을 호출합니다.
v2 = space.mul(space.wrap(3),
v1)
그리고 이어서 v3 = space.add(v2, space.wrap(2))를 호출하고 결과로 v3를 반환합니다. 이 호출들 동안 다음 블록이 기록됩니다.
Block(v1): # 입력 인수 v2 = mul(Constant(3), v1) v3 = add(v2, Constant(2))
build_flow()는 바이트코드 인터프리터가 발생시키는 모든 연산을 basic block에 기록하는 방식으로 동작합니다. basic block은 두 경우 중 하나에서 끝납니다. 바이트코드 인터프리터가 is_true()를 호출할 때, 또는 joinpoint에 도달했을 때입니다.
is_true()를 호출하면, 추상 인터프리터는 일반적으로 그 답이 True인지 False인지 알지 못하므로, 조건 분기를 두고 현재 basic block에 대해 두 개의 후속 블록을 생성합니다. 여기에는 약간의 기교가 필요해서, 바이트코드 인터프리터가 is_true()가 먼저 False를 반환한다고 믿게 만들고(이후 연산은 첫 번째 후속 블록에 기록됨), 나중에는 같은 is_true() 호출이 True도 반환한다고 믿게 만들어(이후 연산은 이번에는 다른 후속 블록으로 감) 처리합니다.(이 절은 추후 확장 예정…)
여기서는 build_flow()가 생성하는 자료 구조를 설명합니다. 이것들은 번역 과정의 기본 자료 구조입니다.
이 모든 타입은 rpython/flowspace/model.py에 정의되어 있습니다(요점을 다시 강조하자면, PyPy 소스 기반에서 꽤 중요한 모듈입니다).
함수의 플로우 그래프는 FunctionGraph 클래스에 의해 표현됩니다. 여기에는 Link들로 연결된 Block 모음에 대한 참조가 들어 있습니다.
Block은 SpaceOperation들의 목록을 담고 있습니다. 각 SpaceOperation은 opname, args, result를 가지며, 이들은 Variable 또는 Constant입니다.
우리는 매우 유용한 PyGame 뷰어를 가지고 있어서, 번역 과정의 여러 단계에서 그래프를 시각적으로 검사할 수 있습니다(무엇이 왜 망가지는지 알아내려 할 때 매우 유용합니다). 모습은 다음과 같습니다.
플로우 그래프의 구조를 감 잡기 위해 몇 가지 예제로 python bin/translatorshell.py를 가지고 놀아 보기를 권장합니다. 아래에서는 타입들과 그 속성을 조금 더 자세히 설명합니다.
FunctionGraph
하나의 그래프를 담는 컨테이너입니다(하나의 함수에 대응).
| startblock: | 첫 번째 블록입니다. 함수가 호출될 때 제어가 여기로 들어옵니다. startblock의 입력 인수는 함수의 인수입니다. 함수가 *args 인수를 받는 경우, args 튜플은 startblock의 마지막 입력 인수로 주어집니다. |
| --- |
| returnblock: | 함수 반환을 수행하는 (유일한) 블록입니다. 비어 있으며 실제로 return 연산을 담고 있지 않습니다. 반환은 암묵적입니다. 반환되는 값은 returnblock의 유일한 입력 변수입니다. |
| exceptblock: | 함수 바깥으로 예외를 발생시키는 (유일한) 블록입니다. 두 입력 변수는 각각 예외 클래스와 예외 값입니다. (함수가 예외를 명시적으로 발생시키지 않으면 실제로 다른 어떤 블록도 exceptblock으로 링크하지 않습니다.) |
Block
기본 블록으로, 연산 목록을 포함하고 다른 basic block으로 점프하는 것으로 끝납니다. 블록 실행 중 “살아 있는” 모든 값은 Variable에 저장됩니다. 각 basic block은 자신만의 서로 다른 Variable들을 사용합니다.
| inputargs: | 이전 블록들 중 어느 곳에서든 이 블록으로 들어올 수 있는 모든 값을 나타내는 새롭고 서로 다른 Variable들의 목록입니다. | | --- | | operations: | SpaceOperation의 목록입니다. | | exitswitch: | 아래 참조 | | exits: | 이 basic block의 끝에서 다른 basic block의 시작으로 가능한 점프를 나타내는 Link들의 목록입니다. |
각 Block은 다음 중 하나의 방식으로 끝납니다.
Constant(last_exception)입니다. 첫 번째 Link는 exitcase가 None으로 설정되어 있으며 예외가 없는 경로를 나타냅니다. 다음 Link들은 exitcase가 Exception의 하위 클래스로 설정되며, basic block의 마지막 연산이 일치하는 예외를 발생시킬 때 선택됩니다. (따라서 basic block은 비어 있으면 안 되며, 핸들러로 보호되는 것은 마지막 연산뿐입니다.)Link
한 basic block에서 다른 basic block으로 가는 링크입니다.
| prevblock: | 이 Link가 출구로 속한 Block입니다. |
| --- |
| target: | 이 Link가 가리키는 대상 Block입니다. |
| args: | 대상 Block의 inputargs와 같은 크기의 Variable 및 Constant 목록으로, 다음 블록으로 전달되는 모든 값을 제공합니다. (prevblock에서 사용된 각 Variable은 args 목록에 0번, 1번 또는 여러 번 등장할 수 있다는 점에 유의하십시오.) |
| exitcase: | 위 참조 |
| last_exception: | None 또는 Variable; 아래 참조. |
| last_exc_value: | None 또는 Variable; 아래 참조. |
args는 prevblock의 Variable들을 사용하며, 이는 튜플 대입이나 함수 호출처럼 위치에 따라 대상 블록의 inputargs와 대응된다는 점에 유의하십시오.
링크가 예외 포착용이라면 last_exception과 last_exc_value는 링크에 진입할 때 생성된 것으로 간주되는 두 개의 새로운 Variable로 설정됩니다. 실행 시간에는 각각 예외 클래스와 예외 값을 담습니다. 이 두 새 변수는 같은 링크의 args 목록 안에서만 사용될 수 있으며, 다음 블록으로 전달됩니다(평소와 마찬가지로 실제로 전혀 나타나지 않거나, args에 여러 번 나타날 수도 있습니다).
SpaceOperation
기록된(또는 다른 방식으로 생성된) 기본 연산입니다.
| opname: | 연산의 이름입니다. build_flow()는 rpython.flowspace.operation의 목록에 있는 연산만 생성하지만, 이후에는 이름이 임의로 바뀔 수 있습니다. |
| --- |
| args: | 인수 목록입니다. 각 항목은 Constant이거나, 같은 basic block에서 이전에 본 Variable입니다. |
| result: | 결과를 저장할 새로운 Variable입니다. |
연산은 보통 실행 시간에 암묵적으로 예외를 발생시킬 수 없다는 점에 유의하십시오. 예를 들어 코드 생성기는 리스트에 대한 getitem 연산이 안전하며 범위 검사 없이 수행될 수 있다고 가정할 수 있습니다. 이 규칙의 예외는 다음과 같습니다. (1) 연산이 블록의 마지막에 있으며, 그 블록이 exitswitch == Constant(last_exception)로 끝나는 경우에는 암묵적 예외를 검사하고 생성하고 적절히 포착해야 합니다. (2) simple_call 또는 call_args 같은 다른 함수 호출은 항상 호출된 함수가 발생시킬 수 있는 어떤 예외든 발생시킬 수 있으며, 그러한 예외는 위와 같이 포착되지 않는 한 상위로 전달되어야 합니다.
Variable
실행 시간 값을 위한 플레이스홀더입니다. 여기에는 주로 디버깅 관련 내용이 들어 있습니다.
| name: | 값을 참조할 때 name 속성보다 Variable 객체 자체를 사용하는 것이 좋은 스타일이지만, name은 유일함이 보장됩니다. |
| --- |
Constant
SpaceOperation의 인수로 사용되거나, 대상 Block의 입력 Variable을 초기화하기 위해 Link를 통해 전달되는 값으로 사용되는 상수 값입니다.
| value: | 이 Constant가 나타내는 구체적인 값입니다. | | --- | | key: | 값을 나타내는 해시 가능한 객체입니다. |
Constant는 때때로 가변 Python 객체를 저장할 수 있습니다. 이는 그 객체의 정적이고, 사전 초기화되었으며, 읽기 전용인 버전을 나타냅니다. 플로우 그래프는 이러한 Constant를 실제로 변경하려고 해서는 안 됩니다.
아래에서는 객체의 타입을 발견하기 위해 제어 흐름 그래프를 어떻게 “어노테이션”할 수 있는지 간단히 설명합니다. 이 어노테이션 단계는 타입 추론의 한 형태입니다. 이는 Flow Object Space가 구축한 제어 흐름 그래프 위에서 작동합니다.
어노테이션 과정에 대한 더 포괄적인 설명은 번역에 관한 EU 보고서의 해당 절을 참고하십시오.
annotator의 주요 목표는 플로우 그래프에 등장하는 각 변수에 “어노테이션”을 부여하는 것입니다. “어노테이션”은 전체 프로그램 분석에 기반하여, 이 변수가 실행 시간에 담을 수 있는 모든 가능한 Python 객체를 설명합니다. 이 분석은 함수당 하나씩 있는 모든 플로우 그래프를 대상으로 수행됩니다.
“어노테이션”은 SomeObject의 하위 클래스 인스턴스입니다. 각 하위 클래스는 특정 객체 계열을 나타냅니다.
다음은 개요입니다(pypy/annotation/model/ 참조).
SomeObject는 기본 클래스입니다. SomeObject()의 인스턴스는 임의의 Python 객체를 나타내며, 따라서 대개 입력 프로그램이 완전한 RPython이 아니었음을 의미합니다.SomeInteger()는 임의의 정수를 나타냅니다. SomeInteger(nonneg=True)는 음이 아닌 정수(>=0)를 나타냅니다.SomeString()는 임의의 문자열을 나타내고, SomeChar()는 길이 1의 문자열을 나타냅니다.SomeTuple([s1,s2,..,sn])는 길이 n의 튜플을 나타냅니다. 이 튜플의 원소들은 주어진 어노테이션 목록에 의해 다시 제약됩니다. 예를 들어 SomeTuple([SomeInteger(), SomeString()])는 두 항목, 즉 정수와 문자열 하나씩을 가진 튜플을 나타냅니다.어노테이션 단계의 결과는 본질적으로 Variable을 어노테이션에 매핑하는 큰 딕셔너리입니다.
모든 SomeXxx 인스턴스는 불변입니다. annotator가 어떤 Variable이 담을 수 있는 것에 대한 판단을 수정해야 할 때는 기존 어노테이션을 변경하는 것이 아니라 새 어노테이션을 만듭니다.
가변 객체는 어노테이션 중 특별한 처리가 필요합니다. 포함된 값의 어노테이션이 변경 연산을 반영하도록 갱신되어야 할 수 있고, 그 결과 관련 플로우 그래프 부분을 통해 어노테이션 정보를 다시 흘려보내야 하기 때문입니다.
SomeList는 균질한 타입의 리스트를 뜻합니다(즉, 리스트의 모든 원소는 하나의 공통 SomeXxx 어노테이션으로 표현됩니다).SomeDict는 균질한 딕셔너리를 뜻합니다(즉, 모든 키가 같은 SomeXxx 어노테이션을 가지며, 모든 값도 마찬가지입니다).SomeInstance는 주어진 클래스 또는 그 하위 클래스의 인스턴스를 뜻합니다. annotator가 본 각 사용자 정의 클래스에 대해, 우리는 클래스 인스턴스의 속성을 설명하는 ClassDef (pypy.annotation.classdef)를 유지합니다. 본질적으로 ClassDef는 클래스 수준 및 인스턴스 수준 속성 전체의 집합과, 각 속성에 대응하는 SomeXxx 어노테이션을 제공합니다.
인스턴스 수준 속성은 어노테이션이 진행됨에 따라 점진적으로 발견됩니다. 다음과 같은 대입은:
inst.attr = value
주어진 인스턴스의 ClassDef를 갱신하여 해당 속성이 존재하며, 주어진 값만큼 일반적일 수 있음을 기록합니다.
각 속성에 대해 ClassDef는 또한 그 속성이 읽히는 모든 위치를 기록합니다. 이후 어느 시점에 해당 속성에 대한 어노테이션을 더 일반화해야 하는 대입을 발견하면, 지금까지 그 속성을 읽은 모든 위치가 무효로 표시되고 annotator는 그 지점부터 분석을 다시 시작합니다.
인스턴스 수준 속성과 클래스 수준 속성의 구별은 미묘합니다. 클래스 수준 속성은 본질적으로 인스턴스 수준 속성의 초기값으로 간주됩니다. 메서드는 이 점에서 특별하지 않지만, 인스턴스의 초기값으로 간주될 때 인스턴스에 바인딩된다는 점만 다릅니다(즉,
self =
SomeInstance(cls)
).
상속 규칙은 다음과 같습니다. 두 SomeInstance 어노테이션의 합집합은 가장 정확한 공통 기반 클래스의 SomeInstance입니다. 어떤 속성이 부모 클래스의 SomeInstance를 통해 고려된다면(즉, 읽히거나 쓰인다면), 우리는 모든 하위 클래스도 같은 속성을 가지며 같은 어노테이션이 모두에 적용된다고 가정합니다(따라서 부모 클래스의 메서드 안에 return self.x 같은 코드는 부모 클래스와 그 모든 하위 클래스가 x라는 속성을 갖도록 강제하며, 그 어노테이션은 모든 하위 클래스가 x에 저장하고자 할 수 있는 모든 값을 담을 만큼 충분히 일반적이어야 합니다). 하지만 서로 다른 하위 클래스들은, 부모 클래스를 통해 일반적인 방식으로 사용되지 않는다면, 같은 이름의 속성에 대해 서로 관련 없는 다른 어노테이션을 가질 수 있습니다.
백엔드 최적화의 목적은 컴파일된 프로그램을 더 빠르게 실행되게 만드는 것입니다. 전통적인 컴파일러와는 매우 다른 PyPy 번역기의 많은 부분과 비교하면, 이들 대부분은 컴파일러가 어떻게 동작하는지 아는 사람들에게 꽤 익숙할 것입니다.
PyPy 인터프리터 실행 중 발생하는 많은 함수 호출의 오버헤드를 줄이기 위해 우리는 함수 인라인화를 구현했습니다. 이것은 플로우 그래프와 호출 지점을 받아, 그 플로우 그래프의 복사본을 호출하는 함수의 그래프 안에 삽입하고, 등장하는 변수 이름을 적절히 바꾸는 최적화입니다. 원래 함수가 try: ... except: ... 가드로 둘러싸여 있었다면 문제가 생깁니다. 이 경우 인라인화는 항상 가능한 것이 아닙니다. 하지만 호출된 함수가 직접 예외를 발생시키지는 않고(단, 더 안쪽에서 호출된 함수가 잠재적으로 예외를 발생시킬 수는 있음) 있다면 인라인화는 안전합니다.
또한 어떤 함수를 어디에 인라인할지 결정하는 휴리스틱도 구현했습니다. 이를 위해 우리는 각 함수에 “크기”를 할당합니다. 이 크기는 함수가 어딘가에 인라인될 경우 예상되는 코드 크기 증가량에 대략 대응해야 합니다. 이 추정치는 두 수의 합입니다. 하나는 각 연산에 특정 가중치를 부여한 것으로, 기본값은 가중치 1입니다. 어떤 연산은 다른 연산보다 더 많은 비용이 드는 것으로 간주됩니다. 예를 들어 메모리 할당과 호출이 그렇습니다. 반면 어떤 연산은 전혀 비용이 들지 않는 것으로 간주됩니다(cast 등). 크기 추정의 한 부분은 그래프에 나타나는 모든 연산 가중치의 합입니다. 이를 “정적 명령 수”라고 부릅니다. 그래프 크기 추정의 다른 부분은 “중앙 실행 비용”입니다. 이것 역시 그래프 안의 모든 연산 가중치의 합이지만, 이번에는 그 연산이 얼마나 자주 실행될지에 대한 추정으로 가중됩니다. 이 추정에 도달하기 위해, 우리는 각 분기에서 두 경로가 동일한 빈도로 선택된다고 가정합니다. 단, 루프의 끝인 분기에서는 루프 끝으로 되돌아가는 점프가 더 가능성이 높다고 봅니다. 이로부터 방정식 시스템이 생기고, 이를 풀어 모든 연산의 근사 가중치를 얻을 수 있습니다.
모든 함수의 크기 추정이 결정되면, 가장 작은 함수부터 시작하여 호출 지점들에 인라인됩니다. 어떤 함수가 다른 함수에 인라인될 때마다 바깥 함수의 크기를 다시 계산합니다. 이 과정은 남은 함수들이 모두 미리 정의된 한계보다 큰 크기를 가질 때까지 계속됩니다.
RPython은 가비지 컬렉션 언어이므로 힙 메모리 할당이 항상 매우 많이 일어납니다. 이는 더 전통적인 명시적 관리 언어에서는 아예 발생하지 않거나, 혹은 미리 알려진 시점에 죽는 객체를 만들어 명시적으로 해제할 수 있는 경우에 해당합니다. 예를 들어 다음과 같은 형태의 루프:
for i in range(n): ...
는 단순히 0부터 n - 1까지의 모든 숫자를 순회하는 것이지만, Python에서는 다음과 동등합니다.
l = range(n) iterator = iter(l) try: while 1: i = iterator.next() ... except StopIteration: pass
이는 세 번의 메모리 할당이 실행된다는 뜻입니다. range 객체, 그 range 객체용 iterator, 그리고 루프를 끝내는 StopIteration 인스턴스입니다.
약간의 인라인화 이후에는 이 세 객체 모두 다른 함수의 인수로 전달되지도 않고, 전역에서 도달 가능한 위치에 저장되지도 않습니다. 이런 상황에서는 그 객체를 제거할 수 있습니다(어차피 함수가 반환된 뒤 죽게 되기 때문입니다). 그리고 그 객체는 포함하고 있던 값들로 대체될 수 있습니다.
이 패턴(할당된 객체가 현재 함수를 결코 벗어나지 않으므로 함수 반환 후 죽는 패턴)은 매우 자주 발생하며, 특히 어느 정도 인라인화가 일어난 뒤에 더 그렇습니다. 따라서 우리는 객체를 “폭발시켜” 이런 단순하지만 꽤 흔한 상황에서 할당 하나를 아끼는 최적화를 구현했습니다.
메모리 할당 패널티를 줄이는 또 다른 기법은, 스택 프레임보다 오래 살지 않는다고 증명할 수 있는 객체에 대해 스택 할당을 사용하는 것입니다. 하지만 이것은 실제로 속도 향상에 별 도움이 되지 않았고, 그래서 시간이 지나며 다시 제거되었습니다.
이 단계는 이름이 다소 모호하게 느껴질 수 있지만, 별도의 단계로 등장한 것 중 가장 최근의 것입니다. 이 단계의 역할은 소스 생성을 하기 전에 최종 구현 결정을 내리는 것입니다. 경험상 실제 소스 코드를 생성하는 동시에 어떤 판단도 하고 싶지 않다는 사실이 드러났기 때문입니다. C 백엔드의 경우 이 단계는 세 가지 일을 합니다.
- 명시적인 예외 처리를 삽입합니다.
- 명시적인 메모리 관리 연산을 삽입합니다.
- 최종 소스에서 함수와 타입이 가질 이름을 결정합니다(이 객체-이름 매핑은 때때로 “저수준 데이터베이스”라고 불립니다).
RPython 코드는 제한 없는 Python과 거의 같은 방식으로 예외를 자유롭게 사용할 수 있지만, 최종 결과물은 C 프로그램이며 C에는 예외 개념이 없습니다. 예외 변환기는 CPython과 비슷한 방식으로 예외 처리를 구현합니다. 예외는 특별한 반환 값으로 표시되고, 현재 예외는 전역 자료 구조에 저장됩니다.
어떤 의미에서는 예외 변환기의 입력은 예외가 포함된 lltypesystem 기준의 프로그램이고, 출력은 순수한 lltypesystem 기준의 프로그램입니다.
RPython은 예외를 지원할 뿐 아니라 가비지 컬렉션 언어이기도 합니다. 다시 말해 C는 그렇지 않습니다. 이 간극을 메우기 위해 메모리 관리에 대한 결정을 내려야 합니다. 유연성을 중시하는 PyPy의 접근에 맞추어, 이를 어떻게 수행할지 변경할 자유가 있습니다. 현재 구현된 방식은 세 가지입니다.
- 참조 카운팅(폐기 예정, 너무 느림)
- Boehm-Demers-Weiser conservative garbage collector 사용
- RPython으로 구현된 우리의 정확한 GC들 중 하나 사용
거의 모든 애플리케이션 수준 Python 코드는 매우 빠른 속도로 객체를 할당합니다. 이는 메모리 관리 구현이 PyPy 인터프리터의 성능에 결정적이라는 뜻입니다.
이 문서가 보여주듯, 번역 단계는 처음 예상할 수 있는 것보다 더 많은 단계로 나뉘어 있습니다. 실제로 프로젝트가 시작될 때 우리가 예상했던 것보다도 더 많은 단계로 나뉘어 있습니다. 가장 초기의 GenC 버전은 고수준 플로우 그래프와 annotator의 출력 위에서 동작했으며, RTyper라는 개념조차 아직 존재하지 않았습니다. 더 최근에는 소스 생성을 위해 그래프를 준비하는 일(“databasing”)과 실제로 소스를 생성하는 일을 분리해서 생각하는 것이 최선이라는 점이 분명해졌습니다.
이제 분명하겠지만, PyPy의 번역 툴체인은 유연하면서도 복잡한 존재이며, 많은 개별 구성 요소들로 이루어져 있습니다.
digraph translation { graph [fontname = "Sans-Serif", size="6.00"] node [fontname = "Sans-Serif"] edge [fontname = "Sans-Serif"] subgraph legend { "Input or Output" [shape=ellipse, style=filled] "Transformation Step" [shape=box, style="rounded,filled"] // Invisible edge to make sure they are placed vertically "Input or Output" -> "Transformation Step" [style=invis] } "Input Program" [shape=ellipse] "Flow Analysis" [shape=box, style=rounded] "Annotator" [shape=box, style=rounded] "RTyper" [shape=box, style=rounded] "Backend Optimizations (optional)" [shape=box, style=rounded] "Exception Transformer" [shape=box, style=rounded] "GC Transformer" [shape=box, style=rounded] "GenC" [shape=box, style=rounded] "ANSI C code" [shape=ellipse] "Input Program" -> "Flow Analysis" -> "Annotator" -> "RTyper" -> "Backend Optimizations (optional)" -> "Exception Transformer" -> "GC Transformer" "RTyper" -> "Exception Transformer" [style=dotted] "GC Transformer" -> "GenC" -> "ANSI C code" // "GC Transformer" -> "GenLLVM" -> "LLVM IR" }
아직 강조하지 않은 세부 사항 하나는 다양한 구성 요소 사이의 상호작용입니다. annotator가 끝난 뒤 RTyper가 그래프를 처리하고, 그 다음에 예외 처리가 명시화되는 식으로 말하면 설명하기는 좋지만, 완전히 사실은 아닙니다. 예를 들어 RTyper는 많은 low-level helper 호출을 삽입하는데, 이것들은 먼저 어노테이션되어야 합니다. 또한 GC 변환기는 성능 향상을 위해 자신의 작은 helper 함수 일부에 대해 백엔드 최적화 중 하나인 인라인화를 사용할 수 있습니다. 다음 그림은 기본 번역 과정의 각 단계를 수행할 때 관련되는 구성 요소를 요약하려는 시도입니다.
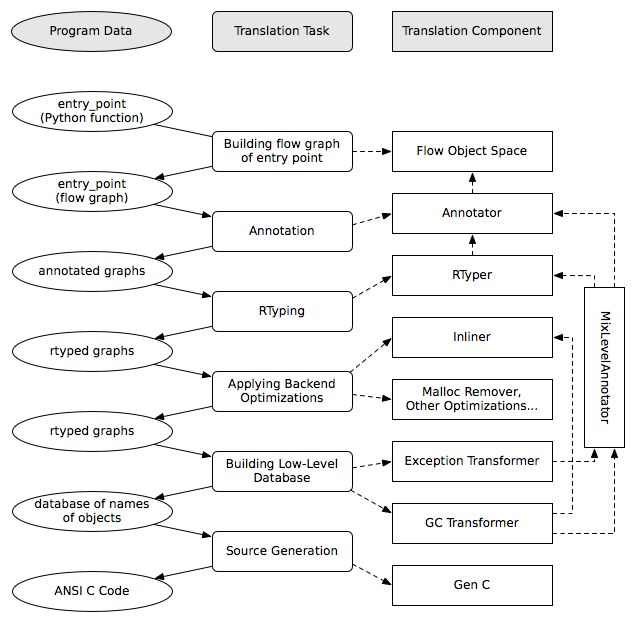
이전에 언급하지 않은 구성 요소로 “MixLevelAnnotator”가 있습니다. 이것은 “늦은” 번역 단계(RTyping 이후)가 서로를 상호 재귀적으로 참조할 수 있는 함수 집합 각각을 호출할 수 있어야 한다고 선언하고, 그것들을 한 번에 모두 annotate하고 rtype할 수 있도록 편리한 인터페이스를 제공합니다.