2025년 한 해 동안 작성자가 LLVM과 Rust 생태계에서 수행한 주요 작업(Ptradd/Ptrtoaddr, 라이프타임 인트린식, 캡처 추적, ABI, 컴파일 시간, 최적화, 패키징, 거버넌스 등)을 정리한 연례 보고서.
지난 3년 동안 ptradd 마이그레이션을 느리게 진행해 왔습니다. 이 변경의 목표는 타입 기반
getelementptr(GEP) 표현에서 벗어나, 포인터에 정수 오프셋을 더하기만 하는
ptradd인스트럭션으로 옮겨가는 것입니다.
올해 초의 상태는, 상수 오프셋 GEP 인스트럭션이 다음 형태로 정규화(canonicalize)되어 있었던 것입니다.
getelementptr i8, ptr %p, i64 OFFSET이는
ptradd와 동등합니다.
올해의 진전은, 모든 GEP 인스트럭션이 단일 오프셋을 갖도록 정규화한 것입니다. 예를 들어,
getelementptr [10 x i32], ptr %p, i64 %a, i64 %b는 이제 두 개의 인스트럭션으로 분할됩니다. 이는 단일 오프셋 인자만 허용하는
ptradd에 더 가까워지게 합니다. 하지만 이 변경은 독립적으로도 유용합니다. 공통 GEP 접두(prefix)에 대한 CSE(공통 부분식 제거)를 가능하게 해주기 때문입니다.
이 작업은 여러 단계로 진행되었습니다. 먼저 여러 개의 변수 인덱스를 분할했고, 다음으로 상수 인덱스도 분리했으며, 마지막으로 선행 0 인덱스 제거까지 했습니다.
늘 그렇듯, 작업의 대부분은 변경 자체가 아니라 그로 인해 발생한 회귀(regression)를 완화하는 데 있었습니다. 많은 변환(transform)을, 단일 GEP가 아니라 GEP 체인에 대해 동작하도록 확장했습니다. 이는 ptradd 마이그레이션과 별개로도 유용한데, 체인 형태의 GEP는 이전부터 이미 매우 흔했기 때문입니다.
이 마이그레이션을 완료하려면 아직 큰 과제들이 남아 있습니다. 첫 번째는
ptradd가 상수 스케일링 팩터를 지원해야 하는지, 아니면 별도의 곱셈으로 표현하도록 강제해야 하는지 결정하는 것입니다. 양쪽 모두에 타당한 논거가 있습니다.
두 번째는 단순한 정규화에서 벗어나 새 형태를 요구하도록 전환하는 것입니다. 아마도 먼저 IRBuilder가 이를 생성하도록 한 뒤, 타입 기반 형태의 구성을 실제로 막는 식이 될 것입니다. 그 시점이
ptradd인스트럭션을 실제로 도입하는 시점이 될 것입니다.
LLVM 22는 새로운
ptrtoaddr인스트럭션을 도입합니다. 이는
ptrtoint와 CHERI 아키텍처에서의 포인터 비교의 의미론에 대한 긴 논의의 결과입니다.
ptrtoaddr의 의미론은
ptrtoint와 비슷하지만, 두 가지 점에서 다릅니다:
addr()에 해당하며,
expose_provenance()가 아닙니다.
포인터를 정수로 변환하는 “노출하지 않는” 방법은 LLVM의 프로버넌스 스토리를 정리하는 데 중요한 단계입니다. LLVM은 현재
ptrtoint가 (노출) 부작용을 갖는다는 사실을 무시하고 있는데, 부작용 없는 대안이 있어야 이를 진지하게 다루기 위한 전제 조건 중 하나가 됩니다. (다른 하나는 byte 타입입니다.)
비슷하지만 완전히 같지는 않은 두 인스트럭션을 갖는 단점은, 가능한 경우 기존 최적화들이 두 형태 모두에서 동작하도록 세심한 조정이 필요하다는 점입니다. 이에 대해 작업해 왔고,
ptrtoaddr는 이제 대부분의 중요한 최적화에서 지원되어야 합니다.
LLVM은 스택 할당을
alloca인스트럭션으로 표현합니다. 이것들은 일반적으로 항상 엔트리 블록 안에 배치되며, 실제 할당의 라이프타임은 plaintext lifetime.start 와 plaintext lifetime.end 인트린식으로 표시합니다. 이 인트린식의 주요 목적은 스택 컬러링(stack coloring)을 가능하게 하는 것입니다. 스택 컬러링은 동시에 라이브(live)하지 않은 스택 할당들을 같은 주소에 배치할 수 있어 스택 사용량을 크게 줄입니다.
라이프타임 인트린식에 대해 두 가지 큰 변경을 했습니다. 첫 번째는 alloca에 대해서만 사용되도록 강제한 것입니다. 이전에는 함수 인자 같은 임의의 포인터에도 사용할 수 있었습니다. 이는 스택 컬러링과 양립할 수 없습니다. 스택 컬러링은 어떤 할당에 대한 모든 라이프타임 마커가 “보이도록” 요구하는데, 함수 호출 뒤에 숨겨질 수는 없기 때문입니다.
이를 IR 유효성(validity) 요구 사항으로 만든 것은, 최적화 패스의 결과로 실수로 non-alloca에 라이프타임을 적용하게 된 꽤 많은 사례를 찾아내는 데 도움이 됐습니다. 가장 흔한 경우는 alloca가 phi 노드에 의해 우연히 가려지는 경우였습니다.
두 번째 변경은 라이프타임 인트린식에서 size 인자를 제거한 것입니다. 이론상 이 인자는 할당의 일부(subset)에 대한 라이프타임을 제어할 수 있게 해 주었습니다. 하지만 실제로는 전혀 사용되지 않았고, 스택 컬러링은 그 인자를 그냥 무시했습니다. IR 의미론 측면에서는 비교적 작은 변화였지만, 라이프타임 인트린식이 들어간 모든 코드와 테스트를 업데이트해야 했기 때문에 영향은 훨씬 컸습니다.
이 변경들이 라이프타임 처리 관련 일부 문제를 해결했지만, (store speculation과 비교(comparison) 관련) 더 많은 문제들이 남아 있습니다. 핵심 문제는 현재 표현으로는 어떤 지점에서 alloca가 라이브인지, 또는 두 alloca의 라이프타임이 겹칠 수 있는지 효율적으로 판단할 수 없다는 점입니다. 이를 고치려면 더 침투적인 변경이 필요합니다.
전년도에서 이어진 또 다른 작업은 캡처 추적(capture tracking) 개선입니다. 작년에 이를 제안했지만, 구현 작업의 대부분은 올해 이루어졌습니다.
이 제안의 가장 중요한 부분은, 포인터의 주소를 캡처하는 것과 프로버넌스를 캡처하는 것을 구분하게 되었다는 점입니다. 많은 최적화는 후자만 신경 쓰면 됩니다. 프로버넌스 캡처만이 분석 불가능한 메모리 효과로 이어질 수 있기 때문입니다.
이를 가능하게 한 가장 큰 변경은 추론(inference) 지원과, 에일리어스 분석(alias analysis)이 프로버넌스 캡처만 검사하도록 업데이트하고 읽기 전용 캡처(read-only captures)를 활용하도록 한 것입니다.
또한 store에 plaintext !captures 메타데이터를 추가해 이 기능을 확장했습니다. 이는 Rust에서 non-mut 참조를 store하는 경우 읽기 프로버넌스(read provenance)만 캡처한다는 것을 인코딩하기 위한 것입니다. 이는
println!()처럼 함수 인자가 아니라 메모리를 통해 캡처하는 구성 요소 주변을 최적화하는 데 도움이 됩니다. 실제로 이것이 가능한지 여부는 Rust 에일리어싱 모델의 열린 질문에 달려 있습니다.
서로 다른 타겟 아키텍처에 대한 추상화로서 LLVM의 가장 큰 실패 중 하나는, 플랫폼 ABI(호출 규약, CC)의 처리입니다. ABI 처리의 큰 부분이 프런트엔드에서 수행되어야 하며, 이는 현재 C FFI 지원이 있는 모든 프런트엔드가 자신이 지원하는 모든 타겟에 대해 복잡하고 미묘한 ABI 규칙을 재구현해야 함을 의미합니다.
이를 완화하기 위해, 저는 ABI 로어링 라이브러리를 제안했습니다. 이 라이브러리는 별도의 ABI 타입 시스템(LLVM IR 타입보다 풍부하지만 Clang QualType보다는 훨씬 단순한)을 사용해 주어진 함수 시그니처를 어떻게 올바르게 로어링해야 하는지 프런트엔드에 알려줍니다.
GSoC의 일환으로 vortex73가 이런 라이브러리의 프로토타입을 구현했습니다. 이는 x86-64 SystemV ABI(더 복잡한 편에 속합니다)에 대해 큰 오버헤드 없이 일반적인 접근이 작동함을 보여줍니다. 자세한 내용은 동반된 블로그 글을 참고하세요. 이 라이브러리를 업스트림에 포함시키는 작업이 진행 중입니다.
또 다른 고통 지점은 타입 정렬(alignment) 정보가 (레이어링 이유로) Clang과 LLVM에 중복되어 있고, 이 정보가 서로 어긋날 수 있다는 점입니다. 이는 LLVM 정보를 사용하는 Rust 같은 프런트엔드에 문제를 일으킵니다. 저는 향후 이런 문제를 더 많이 방지하기 위해 일관성 체크를 구현했습니다. 또한 Clang과 LLVM 사이에 중복된 데이터 레이아웃 정의를 제거했습니다.
백엔드 측도 개선하기 위해, CC 로어링에 원래의(legalize 되지 않은) 인자 타입을 노출했습니다. 이를 통해 MIPS의 하드코딩된 fp128 libcall 목록 같은 타겟별 해킹을 많이 정리할 수 있었습니다.
전년도에, 임의 정밀도 정수(APInt)를
uint64_t로부터 구성할 때 값이 실제로 N비트 signed/unsigned 정수인지 확인하는 assert를 도입했습니다. 이 assert의 목적은 부호(signedness)가 잘못 지정되어 생기는 오컴파일을 피하는 것입니다. 이런 문제는 큰 정수(64비트 초과)에서만 드러납니다.
당시에는 (이미 매우 컸던) 작업 범위를 줄이기 위해
ConstantInt::get()생성자는 이 assert에서 제외했습니다. 하지만 이후 바로 이 assert가 막아야 하는 정확한 문제 때문에 발생한 SelectOptimize 오컴파일을 만나고는, 그 결정을 후회하게 됐습니다.
이것이 충분한 동기가 되어, assert를
ConstantInt::get()에도 적용하도록 확장했습니다. 다시 한 번, 기존 문제들을 고치기 위한 상당한 작업이 필요했습니다(대부분은 무해했지만, 그 과정에서 최소 두 건의 추가 오컴파일을 잡아냈습니다).
올해는 컴파일 시간 관련 작업을 거의 하지 않았고, 다른 사람들의 활동도 많지 않았습니다. 2025년 동안 컴파일 시간이 어떻게 변했는지 아래에 정리했습니다:
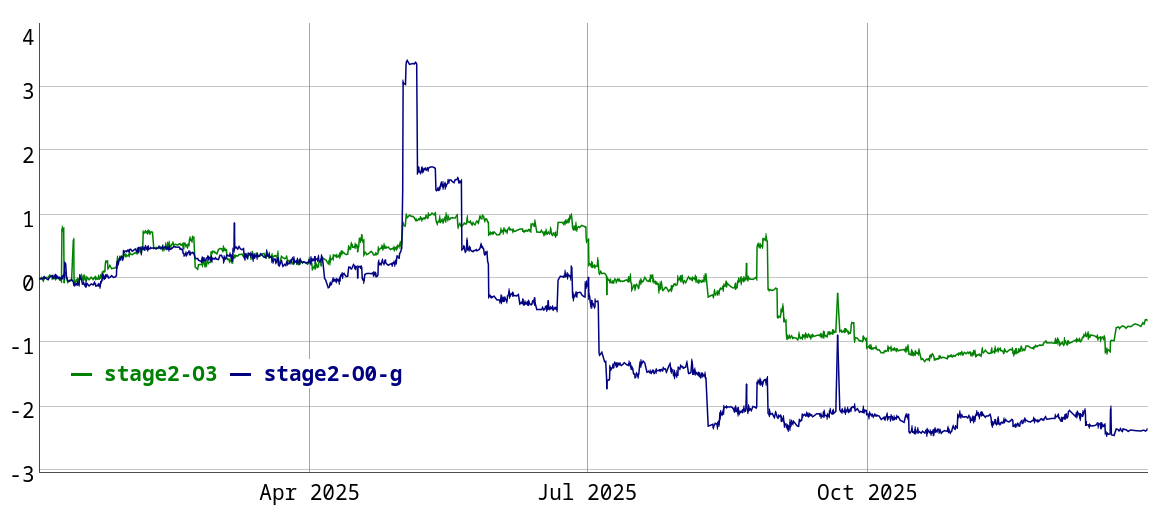
그래프가 너무 복잡해져서 구성(config) 두 개만 포함했습니다. 역사적으로는 x86에서만 컴파일 시간을 추적해 왔지만, 올해는 AArch64 구성 두 개를 추가했습니다. 여기서 흥미로운 요점은, 구성에 따라 AArch64 컴파일이 약 10~20% 더 느리다는 것입니다. 최적화되지 않은 빌드에서는 FastISel 대신 GlobalISel을 사용하기 때문이고, 최적화 빌드에서는 코드 생성(codegen) 중 에일리어스 분석을 사용하는 것이 중요한 요인입니다.
최적화 측면에서는, 희소 조건부 상수 전파(SCCP) 동안 인스트럭션이 방문되는 횟수를 줄이기 위해 SCCP 워크리스트 관리를 개선했습니다(약 0.25% 개선). 필요하지 않은 곳에서 비싼
__builtin_object_size메커니즘 사용을 피하기 위해 getBaseObjectSize() 함수를 도입했습니다(약 0.35% 개선). 또한 중복 연산을 줄이기 위해 타입 할당 크기 계산을 특수화했습니다(약 0.25% 개선).
다른 기여자들의 변경 두 가지도 강조하고 싶습니다. 하나는 불필요한 fragment 생성을 피함으로써 디버그 라인테이블 방출을 최적화한 것입니다. 이 변경은 디버그 빌드를 약 1% 개선했습니다. 다른 하나는 Clang AST에서 중첩 이름 지정자(nested name specifiers)의 표현을 바꾼 것입니다. 이게 정확히 뭘 하는지는 모르겠지만, Clang 빌드 시간을 약 2.6% 개선했기 때문에 C++ 비중이 큰 프로젝트에 큰 영향을 줍니다.
저는 특히 이 Clang 변경이 마음에 듭니다. Clang이야말로 완화되지 않은 컴파일 시간 회귀의 주요 원인이기 때문입니다.
저는 보통 직접적인 최적화 작업을 많이 하지는 않습니다. 최적화가 큰 IR 또는 인프라 변경을 필요로 하지 않는다면, 이를 할 수 있는 다른 사람이 충분히 많기 때문입니다. 하지만 가끔은 참을 수가 없어서, 올해 제가 작업한 흥미로운 최적화 몇 가지를 소개합니다.
여러 개의 store를 하나의 더 큰 store로 합치는 store merge 최적화를 구현했습니다. LLVM은 이미 백엔드에서 이와 유사한 지원이 조금 있었지만, 제대로 동작하느냐는 꽤 들쭉날쭉했습니다. 제가 이 작업을 한 이유는, 누군가 Reddit에 Rust의 GCC 백엔드가 LLVM 백엔드보다 더 좋은 코드를 생성하는 예시를 공유했기 때문입니다. 그런 부당함은 도저히 두고 볼 수 없었습니다.
비절차간(inter-procedural)이 아닌 SCCP(희소 조건부 상수 전파)에서 PredicateInfo 사용1을 활성화했습니다. 이를 통해 분기와 assume이 암시하는 상수 범위를 기반으로 신뢰할 수 있는 최적화가 가능해집니다. 이전에는 매우 이르게 실행되는 비절차간 SCCP와, LVI(lazy value info)에 기반한 CVP(correlated value propagation)에서만 이를 처리했는데, CVP는 루프를 다루는 데 문제가 있습니다2. 여기서 주요 작업은 PredicateInfo를 빠르게 만드는 것이었지만, 결국 약 0.1%의 컴파일 시간 회귀를 감수해야 했습니다.
마지막으로, 더 이상 유용할 가능성이 낮은 assume을 제거(drop)하는 패스를 구현했습니다. 이는 assume을 더 추가하면 최적화 품질이 떨어지는 반복적인 문제를 부분적으로 다룹니다. 이것은 시작점일 뿐이며, 파이프라인의 여러 위치에서 다양한 공격성 수준으로 assume을 더 많이 제거해야 할 가능성이 큽니다.
예년처럼 Rust를 LLVM 20으로, 그 다음 LLVM 21로 업데이트했습니다. 최근 업데이트들과 마찬가지로, 이는 컴파일 시간 개선을 동반했습니다(LLVM 20, LLVM 21).
두 업데이트 모두 비교적 순조로웠습니다. LLVM 21에서는 로컬에서 재현되지 않는 BOLT 인스트루멘테이션 오컴파일을 만났지만, 다행히 호스트 툴체인을 업데이트하니 해결됐습니다.
이 업데이트들 덕분에 Rust에서 사용할 수 있는 여러 새로운 LLVM 기능을 활용할 수 있었고, 그중 일부는 Rust 사용을 위해 특별히 추가된 것들이었습니다.
가장 중요한 것은 non-mutable 참조에 대해 읽기 전용 캡처(read-only captures)를 사용하는 것입니다. 이를 통해 LLVM은 함수가 메모리를 수정할 수 없을 뿐만 아니라, 호출 이후 캡처된 포인터를 통해서도 수정될 수 없음을 알게 됩니다. 이는 C++에 비해 Rust에서 메모리 최적화의 신뢰성을 더욱 높입니다.
또 다른 것은 plaintext alloc-variant-zeroed 속성(attribute)을 사용하는 것입니다. 이는
__rust_alloc__rust_alloc_zeroed로 최적화할 수 있게 해 줍니다. 이 과정에서 LTO 관련 문제가 발생해, 할당자(allocator) 정의에 대한 속성 방출을 고치기 위한 후속 변경이 필요했습니다.
또한 값으로 전달(by value)되는 인자들을 plaintext dead_on_return 로 마킹하고 있으며, 포인터 산술에 getelementptr nuw를 사용하고 있습니다.
Red Hat의 LLVM 팀은 Fedora, CentOS Stream, RHEL에서 LLVM 패키징을 공동으로 담당하고 있습니다. 대부분의 작업은 매일3 돌아가며 유지보수하는 스냅샷 빌드 과정에서 발생합니다. 이론상 스냅샷 빌드는 새 메이저 버전을 출시하는 일을 버전 번호만 올리면 되게 해 줍니다. 하지만 실제로는 그렇게 간단하게 되지 않습니다.
전년도에 우리는 이미 핵심 llvm 패키지에 대해 모놀리식 빌드를 사용하기 시작했습니다. 올해는 mlir, polly, bolt, libcxx, flang 빌드도 모놀리식 빌드에 통합되어, 이제 libclc만 별도로 빌드합니다. 또한 이제 빌드는 PGO를 사용합니다. 이 개선들은 동료인 kwk가 수행했습니다.
제가 작업했고 결국 큰 실패로 끝난 변경 하나는, 메인 llvm 패키지와 구버전용으로 제공하는 llvmNN 호환 패키지 사이의 일관성을 높이려는 시도였습니다. 호환 패키지는 LLVM을
/usr/lib64/llvmNN같은 프리픽스 경로 아래에 설치하는 반면, 메인 패키지는 일반적인 시스템 경로에 설치됩니다. 아이디어는 항상 프리픽스 경로에 설치하고, 시스템 경로에서는 심볼릭 링크를 거는 것이었습니다. 그렇게 하면 메인 패키지를 호환 패키지처럼 사용할 수 있고, 서로 전환할 때 조정이 필요 없게 됩니다.
첫 번째로 부딪힌 문제는 RPM이 업그레이드 중 디렉터리를 심볼릭 링크로 바꾸는 것을 지원하지 않는다는 점입니다. 문서화된 우회 방법이 pretrans 스크립틀릿을 사용하라고 하지만, 이것도 완전히 동작하진 않습니다.4 결국 전체 디렉터리를 심볼릭 링크로 거는 대신 개별 파일들을 심볼릭 링크로 걸어야 했습니다.
두 번째 문제는 훨씬 나중에, 이 변경이 이미 배포된 이후에야 드러났습니다. 32비트와 64비트 LLVM 패키지를 동시에 설치(“multilib” 구성)할 수 없게 된 것입니다. 두 패키지의 프리픽스 경로는 다르지만, 둘 다 같은 시스템 경로에 심볼릭 링크를 설치했고, RPM은 또다시 이를 처리할 수 없었습니다. RPM에는 64비트 파일이 32비트 파일보다 우선하도록 해 주는 특별한 “file color” 지원이 있지만, 당연히 ELF 파일에만 동작하고 심볼릭 링크에는 동작하지 않습니다.
이를 고치기 위해 여러 옵션을 탐색했지만, 결국 모두 어떤 RPM 기능의 부재에 부딪혔습니다. 최종적으로는 심볼릭 링크 방향을 반대로 했습니다(버전 프리픽스 경로가 시스템 경로를 가리키도록). 여기서 얻은 교훈은, RPM을 사용한다면 심볼릭 링크를 전염병처럼 피해야 한다는 것입니다.
올해 LLVM은 선출된 영역 팀(area teams)을 포함하는 새로운 거버넌스 프로세스를 채택했습니다. fhahn, arsenm와 함께 저는 LLVM 영역 팀에 선출되었습니다. LLVM 영역 팀은 2주에 한 번 미팅을 열어 대기 중인 RFC들을 논의합니다. (미팅은 공개지만, 보통 우리 셋만 참석합니다.)
우리의 접근은 대체로 방임(hands-off) 쪽이었습니다. 사람들이 확신이 없어 하는 RFC는 명시적으로 승인해 주기도 했지만, 대부분은 참여가 부족한 RFC에 추가 코멘트를 제공하는 정도로만 관여했습니다.
다른 영역들과 달리, 우리가 다룬 논쟁적인 제안/논의는 매우 적었다고 생각합니다. 하나는 부동소수점 min/max 의미론에 대한 광범위한 논의였고, 최근에야 해결되었습니다. 다른 하나는 디리니어라이제이션(delinearization) 과제 관련이었는데, 이는 구체적 제안이라기보다 일반적인 불만에 가까웠습니다.
LLVM 영역 팀의 의장으로서 저는 프로젝트 카운슬(project council)에도 참여합니다. 이는 영역 팀과는 반대에 가까운데, 프로젝트 카운슬까지 올라오는 주제들은 거의 모두 논쟁적입니다. 예를 들면 AI 정책, 필수 풀 리퀘스트 제안, sframe 업스트리밍 같은 것들입니다. 진전은 있었지만, 많은 주제에서 아직 최종 결론에 도달하지는 못했습니다. 다만 AI 정책은 이제 공개되어 있습니다.
연말에 우리는 정식 명세(formal specification) 워킹 그룹을 만들었습니다. 이 그룹은 LLVM의 오랫동안 존재해 온 정합성(correctness) 격차, 특히 프로버넌스 모델 관련 문제를 해소하는 것을 목표로 합니다. 저는 이 그룹의 초기 논의에 여러 번 참여했고, LLVM을 위한 프로버넌스 모델 초안을 작성했습니다. 현재 그룹의 초점은 byte 타입입니다.
LLVM C API의 흔한 함정인 글로벌 컨텍스트를 폐기(deprecate)했습니다. masked memory 인트린식에서 alignment 표현을 변경했습니다. 메모리 내 blockaddress 표현을 단순화했고, 향후를 위한 더 큰 변경도 제안했습니다.
마지막으로, 작년에 저는 약 2500개의 풀 리퀘스트를 리뷰했습니다. 아쉽게도 이는 제 리뷰 큐를 따라잡기에는 턱없이 부족합니다.
PredicateInfo는 분기 조건과 assume에 기반해 SSA 리네이밍을 수행합니다. 이는 SSI(static single information) 형태와 유사한 결과를 만들며, 표준 희소 데이터플로 전파가 이를 활용할 수 있게 합니다.↩
LVI는 JumpThreading과 CVP 사이에서 공유되는 분석입니다. JumpThreading은 제어 흐름을 광범위하게 변경하기 때문에 도미네이터 트리를 보존할 수 없습니다. 따라서 LVI 역시 도미네이터 트리를 사용할 수 없습니다. 그 결과 순수 재귀 분석이 되며, 공통으로 지배(dominating)하는 조건이 있더라도 사이클에서는 보수적으로 중단합니다.↩
실제로는 모든 아키텍처와 운영체제에서 성공적인 빌드를 “매일” 만들지는 못합니다. 항상 뭔가가 깨집니다.↩
업그레이드 문제는 해결하지만 다운그레이드 문제는 해결하지 못해 여전히 rpmdeplint에 걸립니다. 그리고 다운그레이드를 처리하려면 패키지의 이전 버전에 대한 변경이 필요합니다.↩
이 글이 마음에 들었다면 다른 글들도 둘러보시거나 Twitter 또는 Mastodon에서 저를 팔로우해 주세요.