AI 모델들이 본질적으로 동일한 방식으로 세계를 이해하고 표현하게 되는 이유와, 이는 대규모 모델의 발전에 따라 더욱 뚜렷해지고 있다는 이론을 다양한 연구와 예시를 통해 탐구합니다.

Project CETI는 고래의 언어를 해독하기 위한 대규모 프로젝트입니다. 만약 AI 모델이 보편적인 언어를 '학습'한다면, 언젠가 고래와도 말할 수 있게 될지도 모릅니다.
어렸을 적, 친구들과 "무솔리니 아니면 빵(Mussolini or Bread)"이라는 게임을 자주 했습니다.
이건 스무고개처럼 정답을 좁혀가는 추리게임입니다. 이름이 우스꽝스러운 이유는, 세상 모든 것 중에서 '무솔리니'와 '빵'만큼 먼 것도 드물기 때문이죠.
게임 한 판은 이런 식으로 진행됩니다:
이 게임의 요지는, 가능한 선택지의 공간을 계속 좁혀가면 거의 어떤 것도 맞출 수 있다는 점에 있습니다.
그런데 이 게임, 왜 가능한 걸까요? 우리가 '무솔리니와 베컴 중 누가 클로드 섀넌에 더 가깝냐'에 대해 미리 합의한 적도 없는데도, 다들 그냥 알아봅니다. 이게 가능한 이유 중 하나는 바로 _사물 간의 관계는 본질적으로 한 가지 방식밖에 없기 때문_이라는 직관에서 옵니다. 즉, 사람의 뇌는 사는 세계에 대한 복잡한 모델을 만들고, 내 머릿속 세계의 모델과 당신 머릿속 모델이 거의 비슷하다는 뜻입니다.
이를 압축(compression) 관점에서 설명해 봅시다. AI는 결국 세상의 모든 데이터를 '압축'하는 걸 배우는 것이라 할 수 있습니다. 실제로 언어모델이 하는 "다음 단어 예측"도 에너지-확률분포-압축의 관계를 밝힌 샤논의 정보이론 이후로 하나의 압축 문제로 볼 수 있게 되었습니다.
최근 몇 년간, 우리는 점점 더 정확한 세계의 확률분포를 가지게 되었습니다. 이는 더 큰 언어모델들이 더 나은 확률분포를 제공했기 때문입니다.

지능이란 곧 압축이고, 압축에는 스케일링 법칙이 따릅니다. 원래 스케일링 법칙 연구가 2017년 바이두에서 시작됨을 종종 상기하곤 합니다.
더 나은 확률분포를 가지면 더 나은 압축이 가능해집니다. 실제로, 데이터를 더 잘 압축하는 모델일수록 세상에 대해 더 잘 알고 있다는 뜻입니다. 따라서, 압축과 지능은 이중적 관계를 가집니다. 심지어 누군가는 압축이 AGI로 가는 길일지도 모른다고 말하기도 했죠. 일야(Ilya)는 지능과 압축의 관계에 대해 유명하지만 이해하기 어려운 강연을 하기도 했습니다.
작년 DeepMind는 Language Modeling Is Compression이라는 논문을 내놓아, 다양한 언어모델이 데이터 압축을 얼마나 잘하는지 테스트했습니다. 예측대로 더 강한 언어모델이 더 뛰어난 압축기를 보여주었습니다. (소스 코딩 정리에 따르면 당연한 결과죠.)
또, 압축을 배우는 것이 일반화(Generalization)로 나아가는 핵심 경로이기도 합니다. 최근 연구에서는 모델이 무한히 오래 훈련되는 경우의 압축 행동을 분석했습니다.
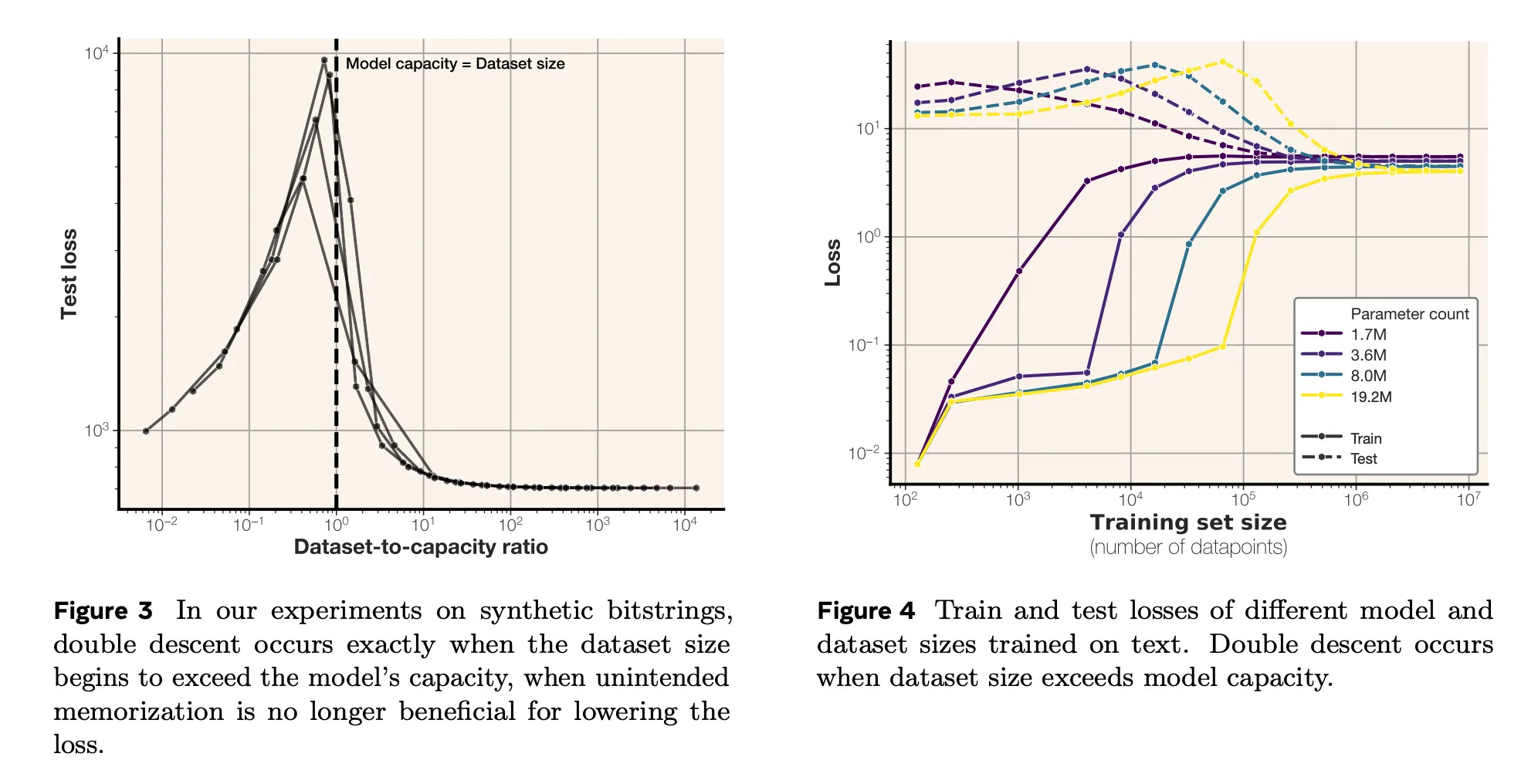
_How much can language models memorize?_의 결과. 압축이 더 이상 불가능해질 때 비로소 일반화가 시작됩니다. 그 전에 모델은 각 데이터 포인트를 전부 따로 저장해버릴 수 있기 때문입니다.
모델이 학습 데이터를 완벽하게 외울 수 있을 때(그래프 좌측), 모델은 기억은 잘하지만 일반화는 못합니다. 그런데 데이터셋이 커져, 모델이 모든 데이터를 파라미터에 담지 못하면 여러 데이터에서 정보를 "결합"해야만 훈련 손실을 최소화할 수 있습니다. 바로 이 때 일반화가 등장합니다.
여기서 중요한 점은, 일반화가 일어나는 방식이 _다른 모델에서도 거의 비슷하다_는 것입니다. 압축 관점에서 보면, 동일 아키텍처/파라미터 내에선 _데이터를 잘 압축하는 유일한 방식이 존재_한다는 말이죠. 미친 이야기 같지만, 다양한 도메인과 모델에서 그런 현상이 실제로 많이 발견됩니다.
서로 다른 모델이 왜 비슷한 표현을 학습하게 될까요? 모델이 정보를 표현하는 거의 무한에 가까운 방법이 있음에도 불구하고 말이죠.
이유는 모델이 세상에 존재하는 객체들의 관계를 학습하기 때문입니다. 어떤 의미에서 '진짜' 모델은 단 하나, 즉 현실을 가장 완벽하게 반영하는 모델뿐입니다. 아마 무한히 큰 모델에 무한한 데이터를 주면 세계 자체를 완벽하게 모사할 수 있을지도요.
모델의 규모가 커질수록 이들의 유사성은 더욱 뚜렷해집니다. 여러 MIT 연구자들은 이러한 현상에 대해 **플라톤적 표현 가설(Platonic Representation Hypothesis, PRH)**을 2024년 논문으로 공개했습니다.
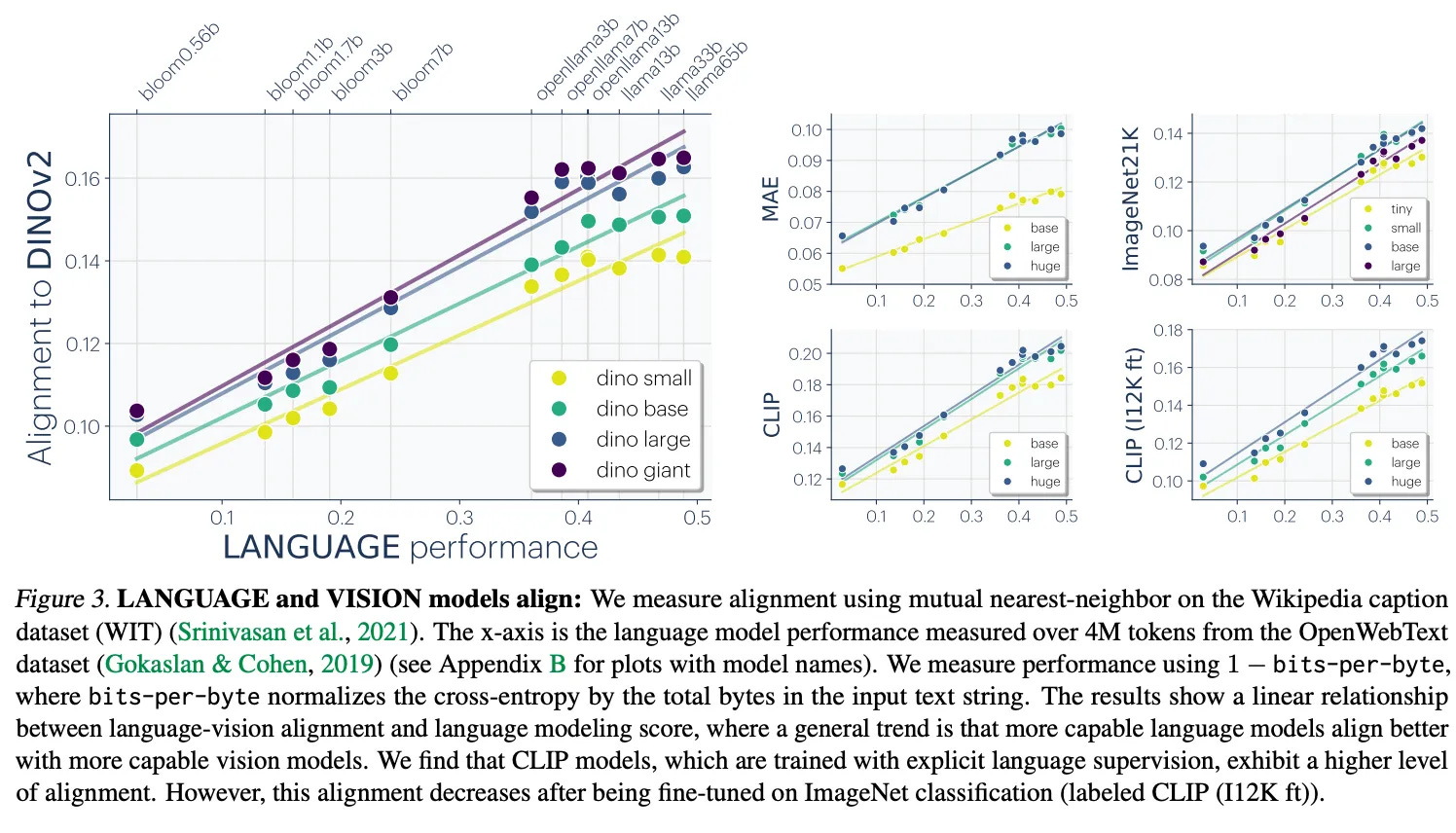
플라톤적 표현 가설은, 모델이 커질수록 같은 특성을 점점 더 많이 배우게 된다고 주장합니다. 이는 비전과 언어 영역 모두에서 증거가 발견되고 있습니다.
즉, 모델은 공통의 표현 공간으로 수렴하고 있으며, 크고 똑똑해질수록 이 현상은 심해집니다. 최소한 언어와 텍스트에서는 명확하죠.
스케일링 트렌드를 볼 때, 모델들은 해마다 크고, 똑똑해지고, 효율적으로 변합니다. 즉, 앞으로는 점점 모델이 _서로 더 유사해질_수밖에 없습니다.
플라톤적 표현 가설의 증거는 강력하지만, 실용적일까요? PRH를 실제 활용하기 전에 먼저 임베딩 역변환(embedding inversion) 문제에 대해 배경을 설명해야겠습니다.
박사과정의 1년을, 신경망의 임베딩 벡터에서 입력 텍스트를 역추론할 수 있을까에 매달렸습니다.
ImageNet 결과에서, 단지 모델의 1000 클래스 확률값만으로도 이미지를 신기할 정도로 잘 복원할 수 있음을 보였습니다. 즉, "이 이미지는 앵무새 0.0001%, 바분 0.0017% 같다"는 식의 정보로도 진짜 정답은 물론, 얼굴 구조, 자세, 배경 등 부수적인 정보까지 추론이 가능하다는 겁니다.
텍스트 쪽은 더 쉬울 거라 생각했습니다. 임베딩 벡터는 거의 1000개의 플로트 값, 즉 16KB 정도나 되니, 긴 텍스트도 잘 복원 가능할 것 같았죠.
하지만 실제로는 매우 어려웠습니다. 임베딩이 매우 압축되어 있기 때문입니다. 유사한 텍스트들은 유사한 임베딩을 가지므로, 미묘하게 다른 둘을 구분하기가 매우 힘듭니다. 예측 벡터는 실제 값과 아주 비슷하지만, 정확히 일치하는 텍스트를 내기는 거의 불가능했습니다.
그래서 우리는 일종의 테스트시간 연산을 도입해 문제를 우회했습니다. 임베딩 공간에 여러 번 쿼리를 날려, 텍스트 기반 "스텝"을 통해 진짜 텍스트를 점차 좁히는 학습 최적화기를 만들어냈죠.
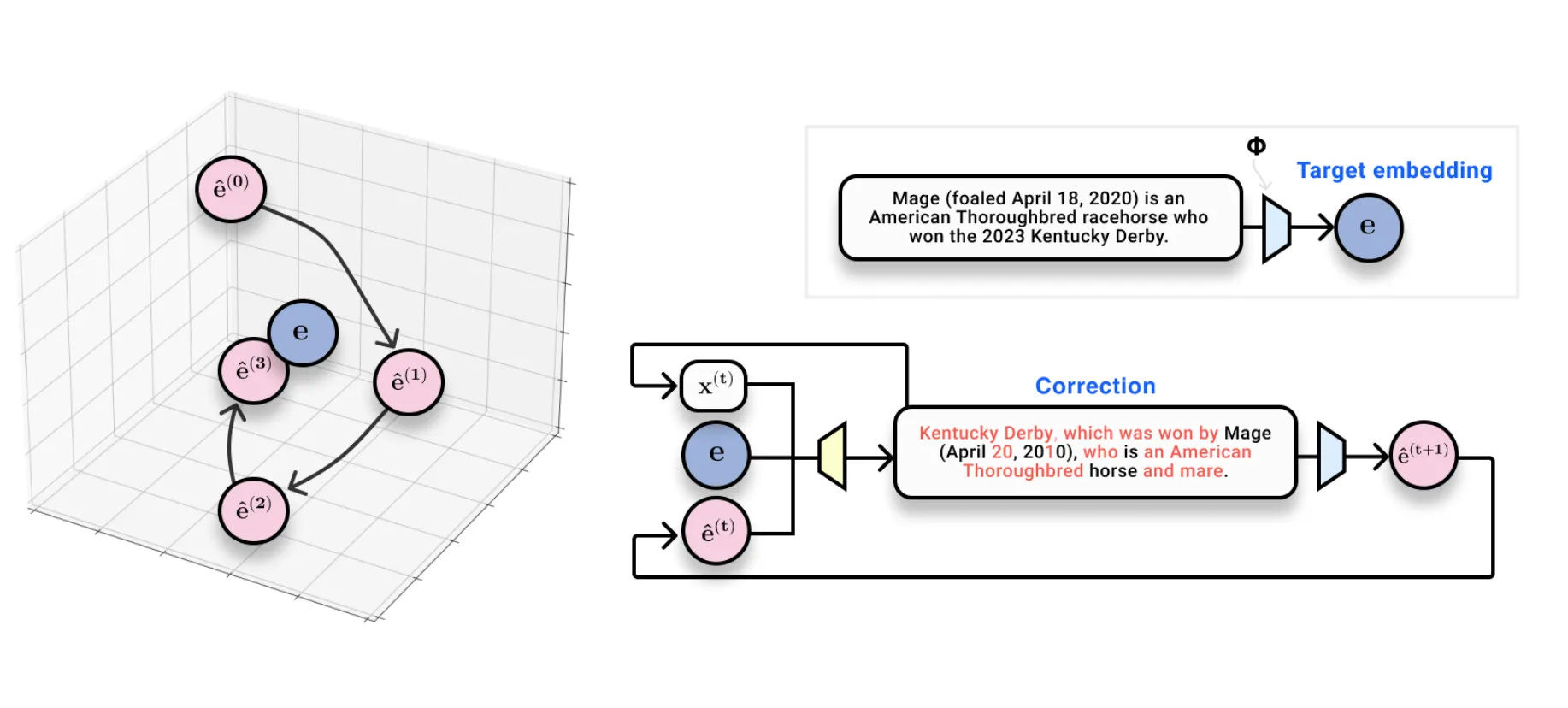
임베딩 역변환에 있어서 반복적 정제 방법은 매우 효과적입니다. (자세히 보기)
이 방법이 잘 작동한다는 걸 확인하고 매우 기뻤습니다. 그 결과, 임베딩 모델을 주면 거의 한 문장 길이 텍스트를 94% 정확도로 역변환할 수 있었습니다.
이는 벡터 데이터베이스 모델에도 큰 함의를 주었습니다. 벡터를 공유하는 것은 거의 그 벡터가 의미하는 텍스트를 공유하는 것과 다르지 않으니까요.
아쉬운 점은, 이 방법이 임베딩-특정(specific)이라는 것입니다. 미래 임베딩 모델이나 우리가 접근할 수 없는 사설 모델에도 똑같이 통할지는 불분명했고, 훈련에도 수백만 번의 임베딩 쿼리가 필요합니다.
우리는 PRH가 참이라면 모든 모델 간에 보편 인버터가 가능해야 한다고 생각했습니다. 그래서 우리는 _보편 임베딩 인버터(universal embedding inverter)_로 나아가는 긴 연구 여정을 시작했습니다.
수학적으로는 이렇습니다: A모델 임베딩과 B모델 임베딩 무더기가 있을 때, A→B(또는 반대) 사상(mapping)을 배울 수 있을까?
핵심은 "대응(코레스폰던스)", 즉 같은 텍스트가 두 모델 모두 임베딩된 쌍을 모른다는 점입니다. 그냥 임베딩 모음만 있을 때 각 모델의 공간을 어떻게든 정렬해 서로를 변환할 수 있게 해야 하는 어려운 문제죠.
이 문제는 CycleGAN에서 "사이클 일관성(cycle consistency)"이라는 아이디어로 이미지 도메인 간 변환에서 이미 한번 풀린 적이 있습니다:
(『말』과 『얼룩말』을 생각해봅시다. A모델 텍스트를 B모델 임베딩 공간으로, 또다시 되돌리는 거죠. 말-얼룩말이 된다면, 텍스트도 되지 않을 이유가 없습니다.)
적어도 1년 넘게 CycleGAN의 임베딩 버전을 만들어 시행착오 끝에, 비감독 정합(unsupervised matching) 과제에서 다음과 같은 GIF가 나왔습니다:
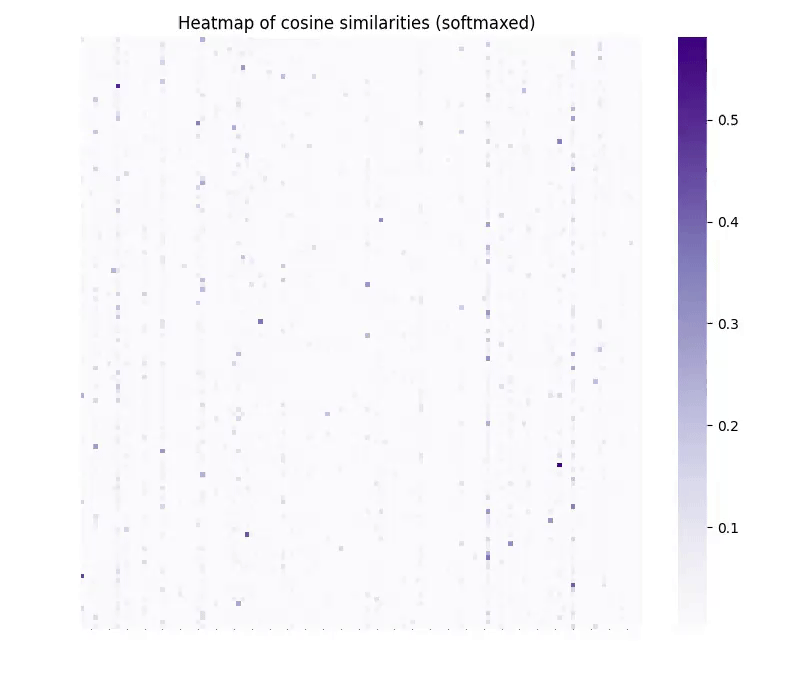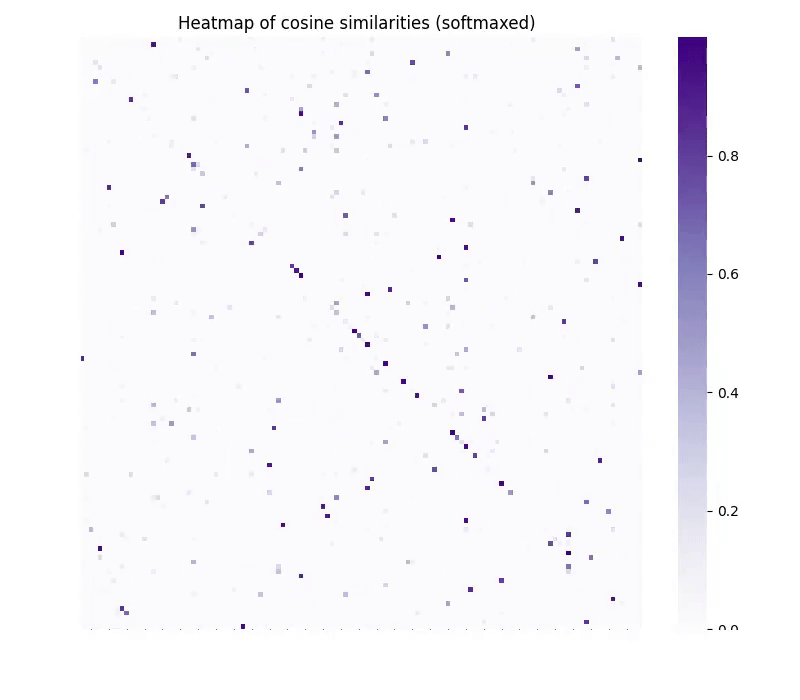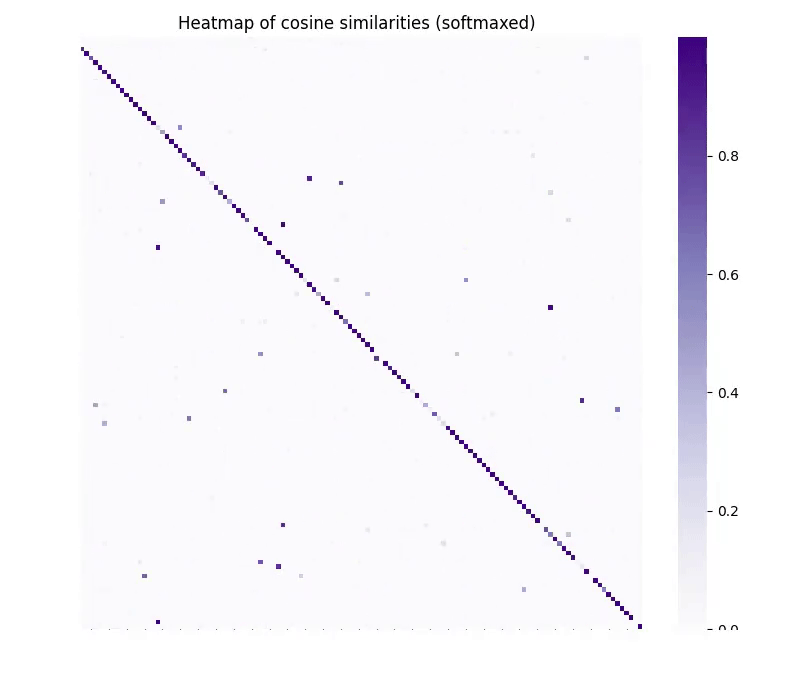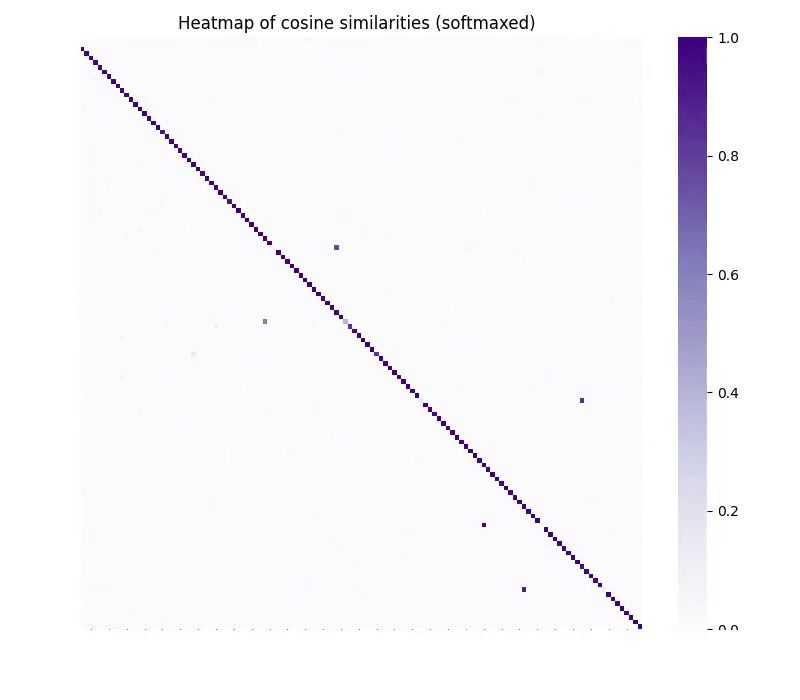
CycleGAN 방식에 가까운 모델을 임베딩 공간 간 매핑에 학습하면, vec2vec은 정말로 이 공간들을 '마법같이' 정렬합니다. 플라톤적 표현 가설 만세!
이는 "강한 플라톤적 표현 가설(Strong PRH)"의 가능성을 실증하는 중대한 성과였습니다. 즉, 서로 다른 모델의 표현공간은 너무나도 구조가 흡사해서, 한 쪽을 알지 못해도 변환이 가능 하다는 뜻입니다. 따라서 아무 정보도 모르는 곳에서 임베딩을 역전환하거나, 모델간 비감독 변환이 가능합니다.
추가적인 PRH 증거로 메커니즘 해석(mechanistic interpretability) 분야를 들 수 있습니다. 여긴 모델의 내부 작동 원리 해석을 목표로 합니다. Circuits 연구(2020)에서는 서로 다른 모델에서 매우 비슷한 기능성을 발견했습니다:

_Circuits(2020)_에서 찾은 보편적 특징 탐지기들. 완전히 다른 네트워크가 놀랄만큼 유사한 동작을 보였습니다.
최근에는 희소 오토인코더(Sparse Autoencoders, SAEs)를 활용한 "특징 이산화(feature discretization)" 방식이 등장했습니다. SAE는 여러 임베딩에서 최대한 해석이 쉬운 특징 사전을 배웁니다. 두 모델에 각각 SAE를 학습시키면, 실제로 많은 특징을 공유한다는 관측이 잇따랐습니다. 더 나아가 '비감독 개념 발견(unsupervised concept discovery)' 방법론도 나오고 있습니다.

_Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment (2025)_에서 찾은 공통 개념 특징들. 두 SAE를 비교해 얼마나 특징이 겹치는지 보여줍니다.
PRH가 맞다면, 모델의 성능이 올라갈수록 이런 공통 회로 발견도 점점 더 흔해질 것입니다.
철학적으로도 깊지만, 플라톤적 표현 가설은 실제로도 매우 유용한 시사점을 던집니다. 메커니즘 해석 분야가 진보하면서 더 효율적인 모델 역공학 도구가 나오고, 모델이 커질수록 상호유사성 발현은 더 심해질 것입니다.

Linear A는 인간이 아직 해독하지 못한 고대 그리스 문자입니다. 플라톤적 표현 가설이 언젠가 그 해독의 길을 열어줄지도 모릅니다.
우리의 vec2vec 연구에서는 강력한 증거들이 나왔으나, 아직도 깨지기 쉬운 부분이 많습니다. 인터넷 기반 텍스트 모델 간이나 CLIP형 이미지-텍스트 임베딩간의 비감독적 매핑은 꽤 잘 이뤄집니다.
하지만 언어 간 고정밀 매핑이 될지는 아직 확실하지 않습니다. 만약 가능하다면, Linear A같은 고대 문자 해독이나, 고래의 언어를 인간 언어로 변환 가능성까지 열릴 것입니다. 정답은 시간이 말해줄 것입니다.