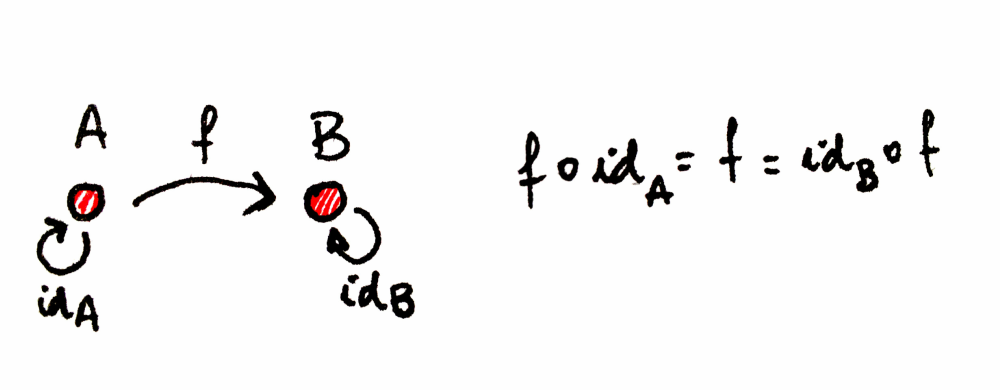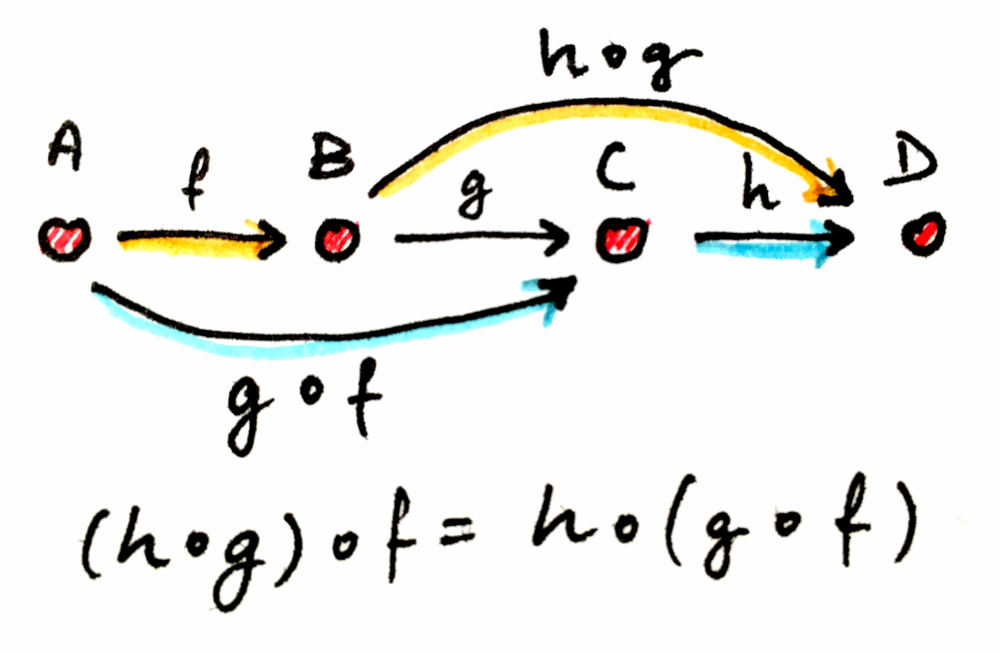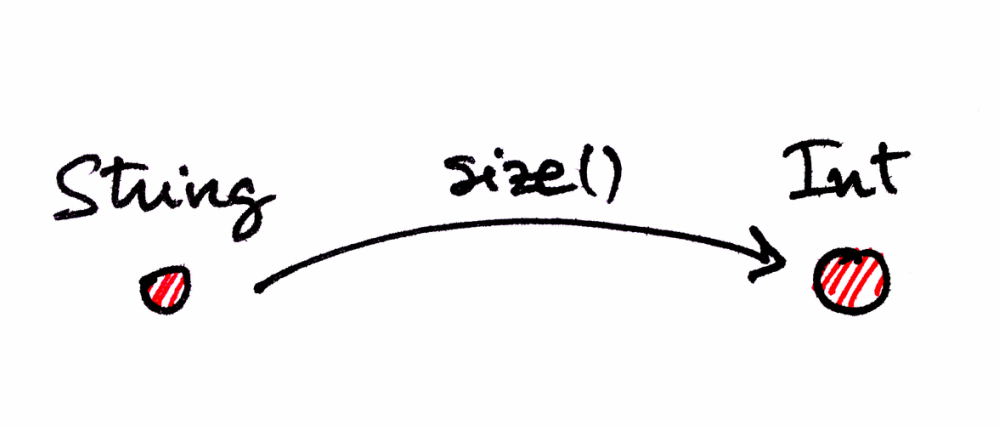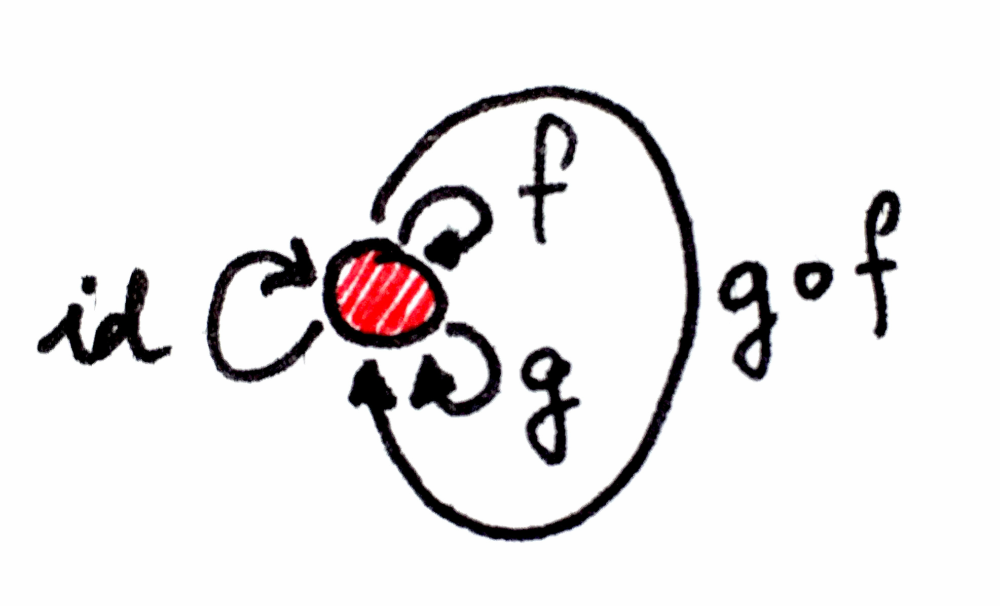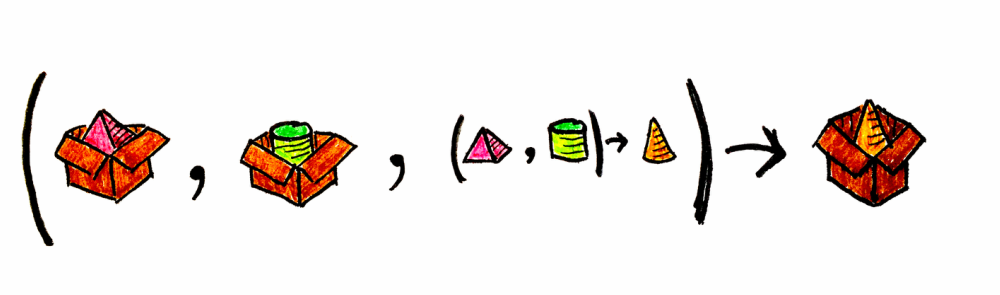개발자들이 함수형 프로그래밍에 점점 더 관심을 갖게 된 이유와, 범주론이 합성과 추상을 설명하는 방식, 그리고 Kotlin과 Arrow로 모노이드·펑터·어플리커티브·모나드를 살펴본다.
Title: The Science Behind Functional Programming
3개월에 걸쳐 저는 운 좋게도 멋진 컨퍼런스 세 곳에 참석할 수 있었습니다. 10월의 Lambda World, 11월의 ScalaIO, 그리고 12월의 Scala eXchange입니다. 거의 20개의 발표와 여러 워크숍에 참석하고 나니, 이야기해볼 만한 주제가 여럿 있다는 걸 알게 됐습니다. 하지만 저는 경험을 되돌아보며 얻은 가장 큰 두 가지 결론을 여러분과 나누고자 합니다.
객관적으로 말해, 이런 흐름을 보여주는 사실은 많습니다. 예를 들어 새로운 함수형 언어(혹은 함수형 기법을 장려하는 언어)의 확산이 그렇죠. 저는 Google Trends를 가지고 이것저것 살펴봤는데, 4년 사이 “higher order functions(고차 함수)” 검색이 250% 이상 증가했고, “js functional programming”은 750% 이상, “java functional programming”은 1,050% 이상 늘었다고 합니다.
또 이 말은 제 체감에도 근거합니다. 요즘은 점점 더 많은 개발자들이 예전에는 함수형 프로그래밍에서만 쓰이던 기법과 패턴에 관심을 보입니다. 그리고 제 관점에서 또 하나 놀라운 사실은, 인구 10만 명 남짓한 스페인 남부의 작은 도시가 국제 함수형 프로그래밍 컨퍼런스를 개최한다는 점입니다. Lambda World가 2년 만에 참석자 수가 두 배가 되었다면, 이는 한 가지를 의미합니다. 사람들은 FP를 배우고 싶어 한다는 것이죠.
흥미로운 이야기 하나를 해볼게요. 이 행사들에는 100명 이상의 연사가 있었지만, 세 행사 모두에서 발표한 사람은 단 두 명뿐이었습니다. Bartosz Milewski와 Daniela Sfregola가 카디스(Cádiz), 리옹(Lyon), 런던(London)에서 모두 발표했죠. 그리고 네, 두 사람 모두 **범주론(Category Theory)**을 이야기했습니다.
사람들은 Milewski의 키노트를 좋아하고, 주최 측도 그걸 알고 있습니다. 또한 Phillip Wadler가 폐회 키노트를 하거나, Eugenia Cheng이 개회 키노트를 하는 식으로 연사들과 함께 범주론을 배우는 것을 좋아합니다. 이런 수학자들은 흔히 회의적인 반응을 보이곤 했습니다. “와, 내가 수십 년간 연구해 온 이 과학에 이렇게 많은 사람들이 관심을 갖게 되다니!!” 같은 말이죠. 이 정도면 제 생각을 충분히 뒷받침하는 근거가 되길 바랍니다. 개발자들이 점점 더 한 가지 현실을 자각하게 되었다는 건 분명해 보입니다. Daniela가 아주 멋지게 표현했죠. “범주론을 조금 배우고 나니, 왜 우리가 일을 그런 방식으로 하는지 이해할 수 있었고, 해결하려는 문제에 맞는 올바른 패턴을 선택함으로써 코드를 개선할 수 있었어요.”
이 글에서 제가 이야기하고 싶은 것이 바로 이것입니다. 저는 몇 가지 계산(컴퓨테이션) 패턴 뒤에 있는 범주들을 간단히 개관해 보겠습니다. 범주론에 대한 대부분의 글과는 달리, 코드 예시로 Haskell을 쓰지도 않고, Scala도 쓰지 않겠습니다(그럼에도 저는 이런 개념들을 Scala로 배웠습니다). 대신 Arrow가 제공하는 멋진 기능을 활용해 Kotlin으로 이 글을 써볼 수 있어 정말 기대됩니다.
제가 가장 좋아하는 정의 중 하나는 Eugenia Cheng 박사의 말입니다. 범주론은 수학의 수학이다(Category Theory is the mathematics of mathematics). 그녀는 또한 수학을 논리적인 것들이 어떻게 작동하는지에 대한 논리적 연구라고 확장해 설명합니다. 전반적으로 이 설명은 범주론이 무엇인지, 거시적인 관점에서 감을 줍니다.
하지만 이 글의 접근 방식에는 Sfregola의 정의인 범주론은 사물들이 어떻게 합성되는지에 관한 것이다와 Milewski의 정의인 범주론은 합성과 추상의 과학이다가 더 잘 맞습니다.
개발자라면, 의식하든 못하든 하루(어쩌면 그 이상)의 대부분을 주로 두 가지 일을 하며 보낼 겁니다. 합성(composition)과 추상화(abstraction) 말이죠.
합성(Composition): 소프트웨어 개발은 소스 파일, 클래스, 함수, 자료구조 등을 계속 분해하고, 다시 합쳐 더 큰 프로그램을 만드는 일입니다. 합치고/분해하는 능력이 없다면 우리는 프로그래밍을 할 수 없습니다. 우리는 합성의 과학이 필요합니다.
추상화(Abstraction): 개발자로서 구현의 세부 사항을 모두 머릿속에 담아두기는 어렵습니다. 대신 도움이 되는 것은, 함수가 무엇을 하는지, 데이터 타입이 무엇을 위한 것인지에 대한 짧은 설명을 머릿속에 유지하는 일입니다(어떻게 구현되었는지는 상관없이요). 우리는 레벨을 오가며 지속적으로 세부 사항을 생략합니다. 결국 여러 함수 내부가 어떻게 되어 있는지 잊고, 서로 어떻게 합성되는지를 알기 위해 시그니처만 기억하기도 하죠.
친애하는 여러분, 합성과 추상을 설명하는 데 범주론만큼 좋은 과학은 없습니다.
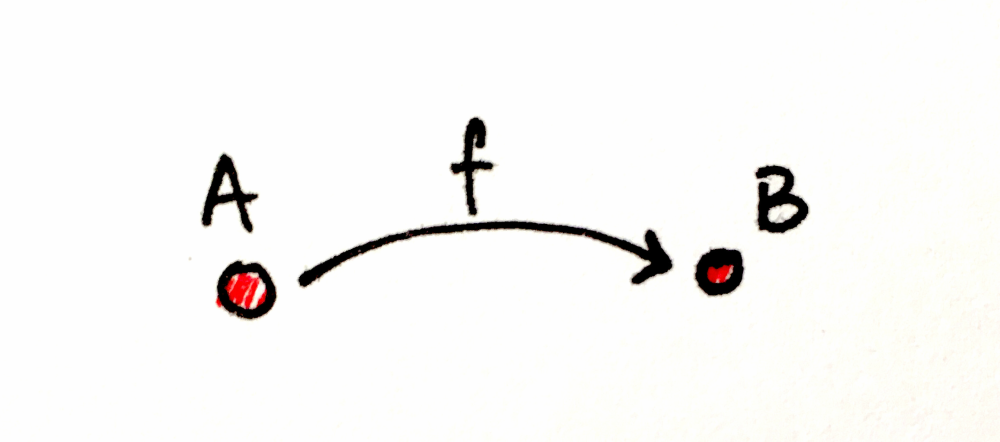
수학적 관점에서 범주는 화살표(arrow)로 연결된 일련의 객체(object)로 이루어집니다.
객체가 무엇인지는 중요하지 않습니다. 의자, 꽃 등 상상할 수 있는 무엇이든 될 수 있죠. 범주를 정의하는 것은 화살표가 어떻게 합성되는지입니다. 즉 화살표들(보통 사상(morphism)이라고도 부릅니다) 사이의 관계 말이죠.
합성(Composition):
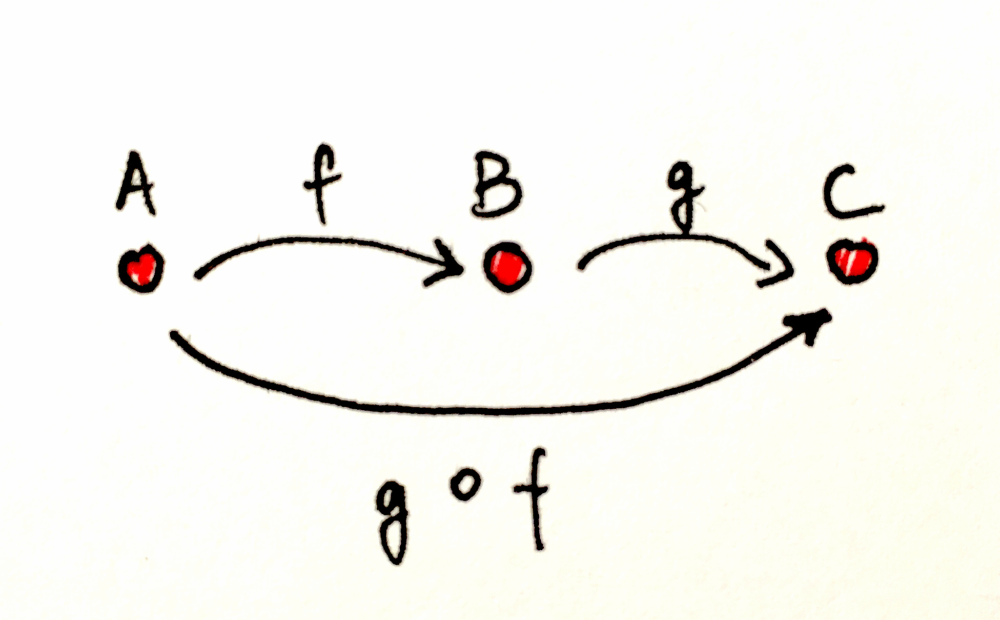
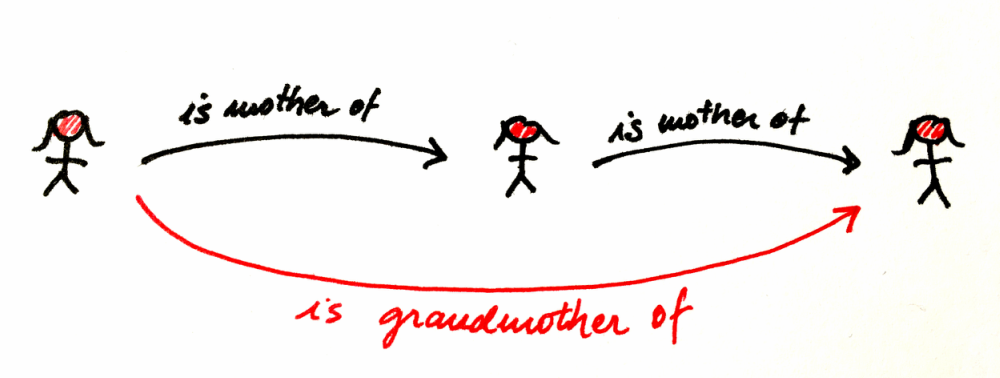
사상 f를 사용해 A에서 B로 갈 수 있고, g를 사용해 B에서 C로 갈 수 있다면, 암묵적으로 두 화살표의 합성인 g ∘ f(“f 다음 g”, g after f)를 통해 A에서 C로 갈 수 있습니다.
우리는 암묵적으로 추론할 수 있는 관계를 생략하기 위해, 머릿속에서 계속 합성을 수행합니다.
사상의 합성은 범주가 성립하기 위해 몇 가지 법칙을 만족해야 합니다.
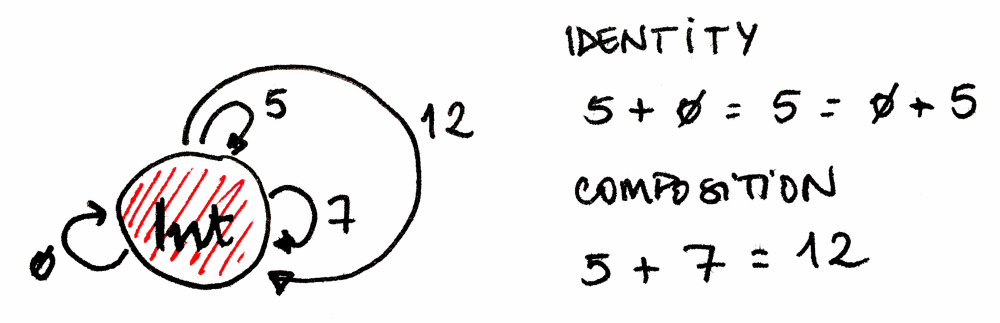
합성의 항등원(Identity for composition): 모든 객체 A에 대해 합성의 단위원(unit)인 화살표가 하나 존재합니다. 이 화살표는 객체에서 자기 자신으로 되돌아오는 루프 형태입니다. 합성의 단위원이라는 것은, 각각 A에서 시작하거나 A에서 끝나는 어떤 화살표와 합성하더라도 그 화살표 자체를 그대로 돌려준다는 뜻입니다. 객체 A의 단위원 화살표를 idA(A 위의 항등, identity on A)라고 부릅니다. 항등 합성은 사상 f가 f ∘ idA 및 idB ∘ f와 동일한 시작점과 끝점을 갖도록 보장합니다.
합성의 결합법칙(Associativity of Composition): 합성할 수 있는(즉 끝과 끝이 맞닿는) 세 사상 f, g, h가 있다면, 괄호 없이도 합성할 수 있습니다. 수식으로는 (h∘g)∘f = h∘(g∘f) = h∘g∘f라고 표현합니다.
합성의 결합법칙을 이해하기 위해, 프로그래밍과 관련된 한 구체적인 범주에서 같은 개념을 보겠습니다. 객체가 데이터 타입(Int, String, Boolean 등)이고 사상이 함수인 범주를 생각해봅시다. 이 범주에서 size() 함수가 String과 Int 사이의 사상이 될 수 있을까요? 물론 가능합니다. String은 가능한 모든 문자열의 집합이고, Int는 (예를 들어) 자연수의 집합이니까요.
fun f(a: String): Int = a.length따라서 이 범주는, 집합의 모든 구성원에 대해 함수가 합성될 수 있고, 합성 법칙을 만족할 때에만 유효합니다. 여러분은 개발자이고, 함수 합성에 익숙하죠?
Kotlin에서는:
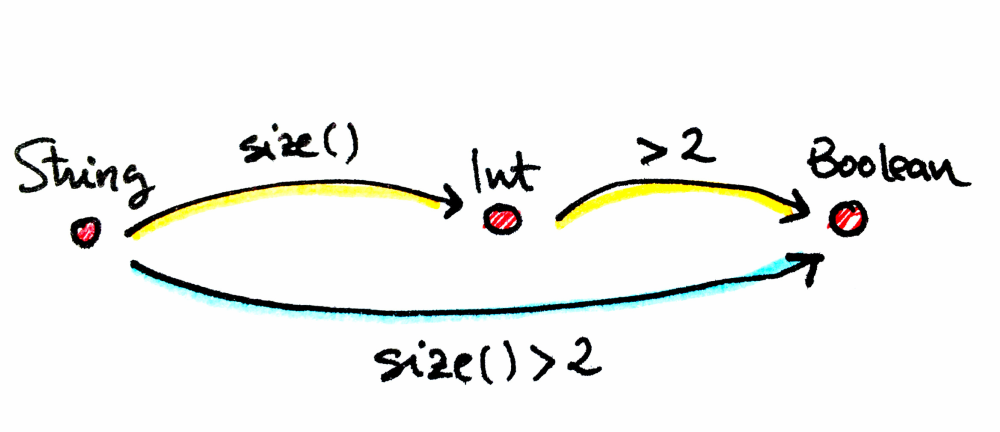
fun f(a: String): Int = a.length
fun g(b: Int): Boolean = b > 2
fun gAfterf(a: String): Boolean = g(f(a))모노이드(Monoid) 수학적으로 모노이드는 기본 산술의 배경이 되는 개념입니다. 모든 모노이드는 적절한 합성 규칙을 따르는 사상들의 집합을 가진 단일 객체 범주(single object category)로 설명할 수 있습니다.
전통적으로 모노이드는 이항 연산(binary operation)을 가진 집합으로 정의됩니다. 이 연산에 요구되는 것은 결합법칙을 만족하고, 단위원처럼 행동하는 특별한 원소가 하나 존재한다는 점뿐입니다.
모노이드는 프로그래밍에서도 어디에나 존재합니다. 문자열, 리스트, 폴더블(foldable) 자료구조, 동시성 프로그래밍에서의 future, 함수형 반응형 프로그래밍에서의 이벤트 등등에 나타납니다. 예를 들어 모든 자연수를 나타내는 객체 하나와 5를 더하는 연산인 함수 f 하나를 떠올려보세요. 이 함수는 0을 5로, 1을 6으로, 2를 7로 매핑하는 식입니다. 이제 7을 더하는 또 다른 함수 g를 상상해봅시다. 일반적으로 임의의 수 n에 대해 n을 더하는 함수, 즉 n의 “adder”가 존재합니다. adder는 어떻게 합성될까요? 5를 더하는 함수와 7을 더하는 함수의 합성은 12를 더하는 함수가 됩니다. 즉 adder의 합성은 덧셈의 규칙과 동등하게 만들 수 있습니다. 좋은 점은 덧셈을 함수 합성으로 대체할 수 있다는 것입니다. 또한 중립 원소인 zero에 대한 adder도 있습니다. zero를 더하는 것은 아무 변화가 없으므로, 자연수 집합에서 항등 함수가 됩니다.
이런 이유로 모노이드는 보통 데이터를 “접는(collapse)” 데 사용됩니다. 그럼 이런 합성 가능성(composability) 동작을 프로그래밍에서 어떻게 표현할 수 있을까요? 객체를 타입으로 취급하는 비유를 계속 이어간다면, 특정 타입과 연관된 동작(behavior)을 표현하기 위해 타입 클래스(type classes)를 사용할 수 있습니다. Kotlin은 이를 기본 제공하지 않지만, Arrow를 사용하면 우리만의 타입 클래스를 만들 수 있습니다. 합성 가능성을 표현하는 타입 클래스가 바로 Monoid가 될 수 있겠죠.
@typeclass
interface Monoid<A> : TC {
fun empty(): A
fun combine(a: A, b: A): A
}Monoid를 타입 클래스로 정의하면, 문자열, 리스트, 색상처럼 결합할 수 있는 모든 타입에 대해 Monoid 인스턴스를 만들 수 있습니다. 색상이라고요? 해봅시다.
data class Color(val red: Int = 0, val green: Int = 0, val blue: Int = 0)다시 한 번 Arrow 덕분에 타입 클래스 인스턴스를 쉽게 만들 수 있습니다.
Arrow는 타입 클래스의 [인스턴스](http://arrow-kt.io/docs/patterns/glossary# instances)를 정의하는 여러 방법을 제공합니다. @instance를 사용하면 Color에 대해 empty와 combine이 무엇을 의미하는지 구현할 수 있습니다.
@instance(Color::class)
interface ColorMonoidInstance: Monoid<Color> {
override fun empty(): Color = Color()
override fun combine(a: Color, b: Color): Color = Color(
red = min(a.red + b.red, 255),
green = min(a.green + b.green, 255),
blue = min(a.blue + b.blue, 255))
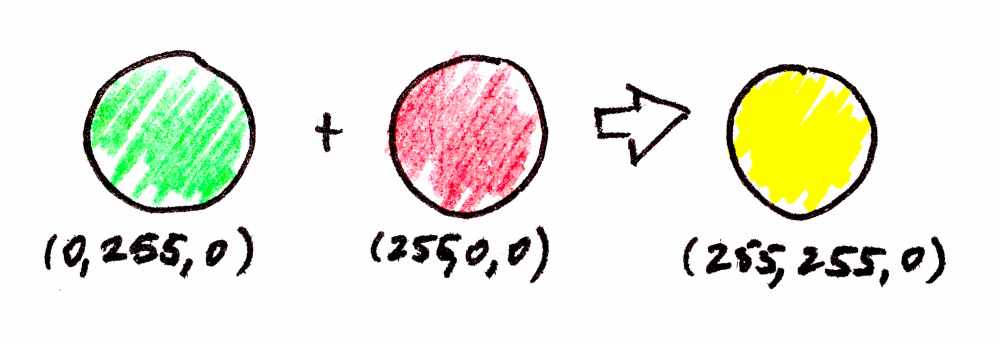
}인스턴스는 정의된 동작(behavior)을 충족시키기 위해 연산을 어떻게 계산할지에 대한 해석(interpretation)입니다. 예를 들어 여기서는 중립 원소(중립 색상)를 검정 rgb(0, 0, 0)으로 해석했고, 색상의 결합은 각 채널을 255까지 더하는 것으로 해석했습니다.
이는 제 해석일 뿐이며, 모노이드 법칙을 만족하기만 한다면 다른 어떤 해석도 똑같이 유효합니다. Arrow에서는 이러한 법칙을 단위 테스트로 작성해두었습니다.
또 Monoid 인스턴스를 후위 표기법으로 결합할 수 있도록 몇 가지 문법을 추가해보면 어떨까요?
inline fun <reified A> A.combine(b: A, FT: Monoid<A> = monoid()): A = FT.combine(this, b)약간의 “마법”으로 monoid()의 암묵적 인스턴스가 컨텍스트에 주입되고, 다음처럼 색상을 결합할 수 있습니다.
val green = Color(green = 255)
val red = Color(red = 255)
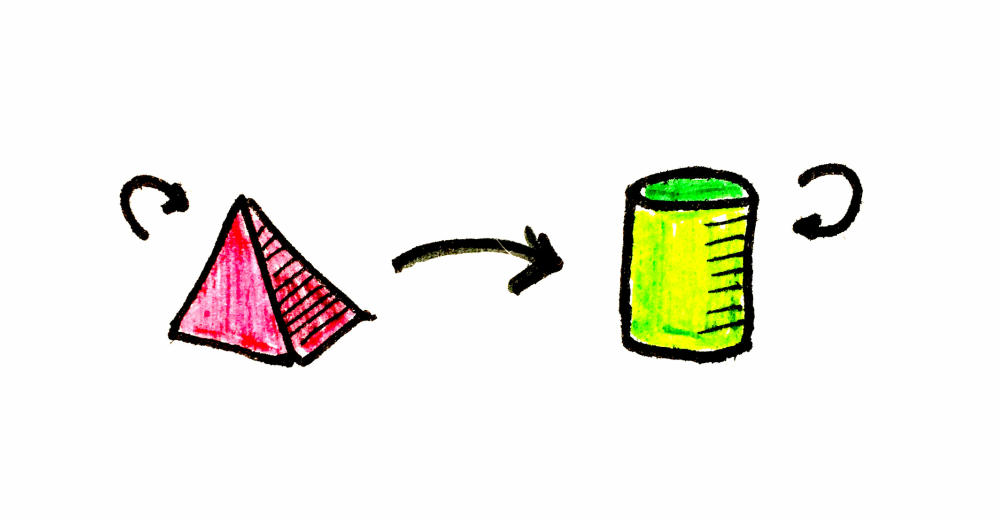
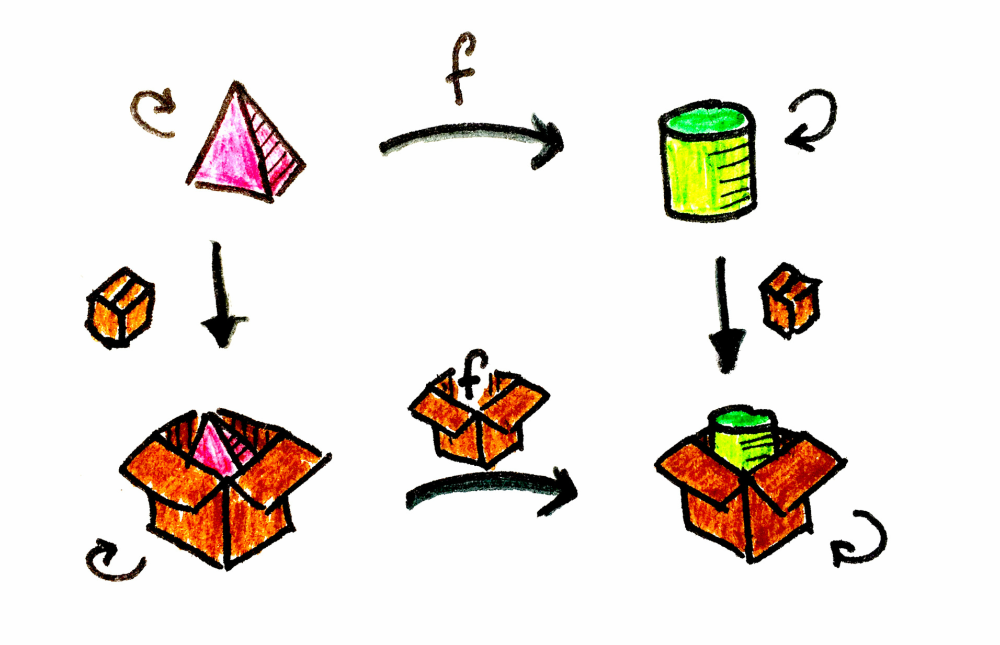
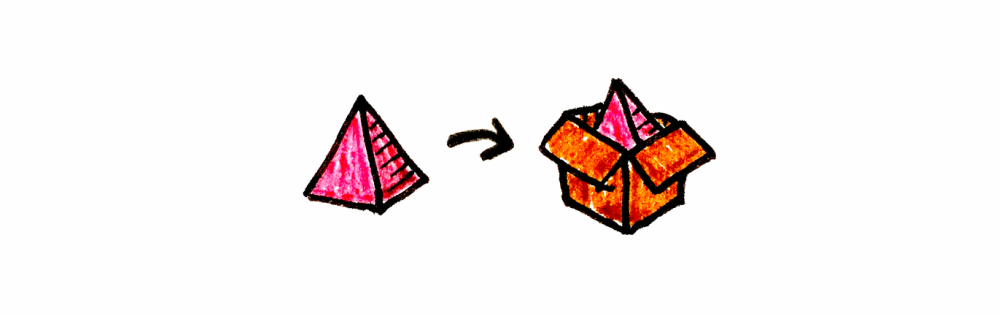
val yellow = green.combine(red) //Color(255, 255, 0)피라미드를 원통으로 바꾸는 방법을 아는, 가상의(정말 멋진) 범주를 가정해봅시다. 상상이 되나요? 이 범주를 C라고 부르겠습니다. 합성 법칙(항등성과 결합법칙)을 만족하는 한, C는 100% 유효한 범주입니다.
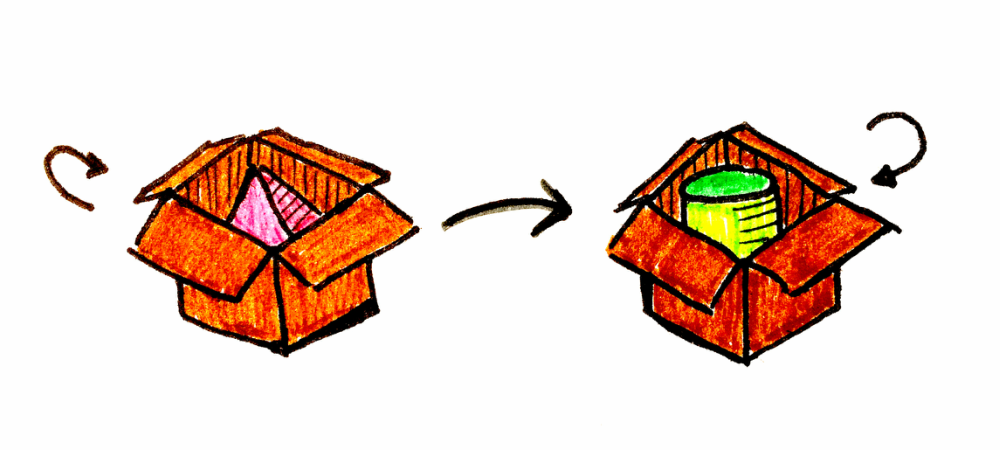
이제, 피라미드가 담긴 상자를 원통이 담긴 상자로 바꾸는 방법을 아는 또 다른 유사한 범주가 있다고 가정해봅시다. 이 범주는 D라고 합니다. 기본적으로 동일한 피라미드와 동일한 원통이지만, 서로 다른 컨텍스트 안에 있는 것이죠.
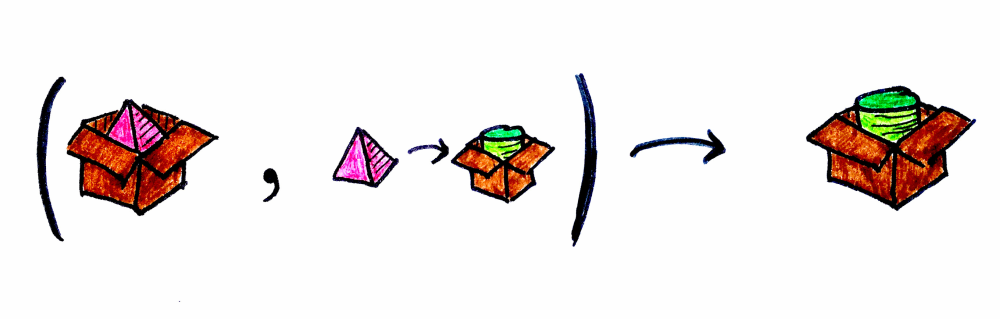
펑터(functor)는 범주 사이의 매핑입니다. 두 범주 C와 D가 주어졌을 때, 펑터 F는 C의 객체를 D의 객체로 매핑합니다. 즉 객체에 대한 함수(function of objects)입니다.
일반적으로 C의 객체 a에 대해, D에서의 대응을 Fa라고 쓰겠습니다. 하지만 범주는 단순히 객체만 있는 게 아니라, 객체와 그 사이를 연결하는 사상도 있습니다. 펑터는 사상도 매핑합니다. 즉 사상에 대한 함수(function of morphisms)이기도 합니다.
우리 예제에서 a는 피라미드, b는 원통, F는 상자입니다.
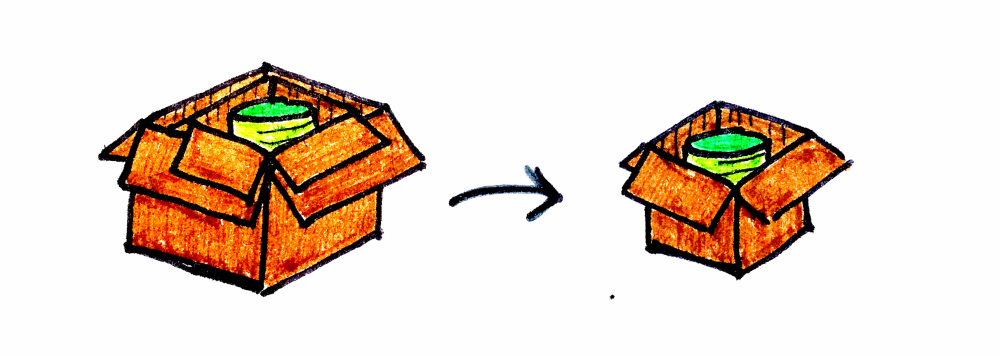
현실로 내려와 프로그래밍 이야기를 해봅시다. 타입과 함수의 범주가 있고, F는 타입 생성자(type constructor)로 표현되는 어떤 컨텍스트를 가집니다(한 타입을 다른 타입으로 매핑하므로). 우리는 종종 어떤 데이터 타입의 “내용물”을 변환해야 하는 상황에 처합니다. 펑터의 매핑 함수(map)를 사용하면, 값이 존재할 것이라는 가정하에 안전하게 값을 계산하고, 그 변환 결과를 동일한 컨텍스트에 캡슐화해 반환할 수 있습니다.
Arrow는 펑터처럼 동작할 수 있는 여러 higher-kinds를 제공합니다. 예를 들어 Option, NonEmptyList, Try 같은 것들이요. 우리도 새로운 데이터 타입과 펑터 인스턴스를 만들어볼까요? 타입 생성자를 만드는 것은 아주 간단합니다.
@higherkind
sealed class Box<out A> : BoxOf<A>
object Empty : Box<Nothing>()
data class Full<out T>(val t: T) : Box<T>()눈치채셨겠지만, Box<T>는 Scala의 Option이나 Haskell의 Maybe를 단순화해 복제한 것입니다. 이는 ADT(대수적 데이터 타입, Algebraic Data Type)로, 다른 코프로덕트(coproduct)와 마찬가지로 오직 하나의 값만 가질 수 있습니다. Empty 또는 Full<T> 중 하나죠. Box 컨텍스트에는 숫자 1, “hi”라는 단어, 심지어 파란색 같은 것도 넣을 수 있습니다.
val box1: Box<Int> = Full(1)
val boxHi: Box<String> = Full("Hi")
val boxBlue: Box<Color> = Full(Color(0, 0, 255))앞서와 같은 방식으로, 새로운 타입 클래스를 만들어 펑터의 동작을 코드로 표현해 보겠습니다. 여기서 말하는 펑터의 동작이란, 타입 생성자의 계산 컨텍스트 위에서 map 할 수 있는 능력을 뜻합니다.
@typeclass
interface Functor<F> : TC {
fun <A, B> map(fa: Kind<F, A>, f: (A) -> B): Kind<F, B>
}즉 포장된 피라미드 (Kind<F, A>)와 피라미드를 원통으로 바꾸는 함수 ((A) -> B)가 주어지면, 포장된 원통 (Kind<F, B>)을 반환합니다.
참고: Arrow에서 Kind는 제네릭 higher-kinds를 표현하기 위한 인터페이스입니다. 따라서 **Kind<F, A>**를 보면, A가 컨텍스트 F로 들어올려진(lifted) 것으로 이해하면 됩니다. **Kind<Box, Color>**는 **Box<Color>**이고, **Kind<Box, Pyramid>**는 ‘포장된 피라미드’입니다.
Box에 대한 Functor 인스턴스를 만들면 내용을 매핑할 수 있습니다. Arrow가 제공하는 또 다른 멋진 기능은 @deriving(Functor::class)로 인스턴스를 유도(derive)할 수 있다는 점입니다. 다만 map은 구현해야 합니다.
@higherkind
@deriving(Functor::class)
sealed class Box<out A> : BoxOf<A> {
fun <B> map(f: (A) -> B): Box<B> = when (this) {
Empty -> Empty
is Full -> Full(f(this.t))
}
companion object
}
object Empty : Box<Nothing>()
data class Full<out T>(val t: T) : Box<T>()여기서 map 구현은 아주 단순합니다. 박스가 비어 있으면 빈 박스를 반환하고, 값이 있으면 함수 f를 내용물에 적용해 그 결과를 박스 안에 담아 반환합니다(Full(f(this.t))). 물론 모든 펑터 인스턴스는 펑터 법칙을 만족해야 합니다.
좋습니다! 이제 예를 들어 색상 박스를 정수 박스로 변환할 수 있습니다.
val boxInt: Box<Int> = Full(Color(0, 0, 255)).map{ it.blue } //Full(255)요약하자면, 우리는 객체가 하나뿐인 범주에서 시작했고, 이어서 펑터가 두 범주 사이에서 원소를 매핑하는 방법을 살펴봤습니다. 이제 한 단계 더 높은 추상화로 넘어가봅시다.
어플리커티브(Applicative)는 펑터 위에 쌓인 또 다른 구조로, 화살표가 보통처럼 객체를 연결하지만 한 가지 특별한 점이 있습니다. 객체가 사상(함수)일 수도 있다는 점입니다. BOOM!
우리는 객체가 무엇이든 될 수 있다고 했죠. 사상도 객체가 될 수 없을 이유가 있을까요? 프로그래밍 비유로 다시 옮기면, 객체는 타입이고 사상은 함수입니다. 함수도 하나의 타입이잖아요? 즉 이 범주에는 A를 받아 B를 반환하는 모든 함수들의 집합인 객체가 있을 수 있습니다.
범주 C에서 피라미드를 원통으로 바꾸는 화살표가 f였다면, 이 새로운 범주에서는 이 화살표 f를 컨텍스트 F 안으로도 올려(lift) 둡니다(여기서 F는 컨텍스트이며, 우리 예시에서는 박스입니다).
비유를 계속하자면, Functor는 map 조합자(combinator)를 가지며 이는 놀라운 능력입니다. 포장된 객체 (A)와 A를 B로 바꾸는 연산만 있으면, 컨텍스트로 들어올려진 결과 (B)를 얻을 수 있으니까요. 그런데 Applicative 범주는 위에서 말한 특별한 점을 고려해, 다른 능력들도 가집니다.
pure: 객체를 컨텍스트로 올리는 능력입니다. 즉 어떤 것을 박스에 넣는 것입니다. 다시 말해 (A) -> Kind<F, A>.ap: 타입 생성자 컨텍스트 안에 들어 있는 함수를 적용(apply)합니다. 시그니처를 보면 더 쉽습니다: (Kind<F, A>, Kind<F, (A) -> B>): Kind<F, B>. map과 비슷하지만, 앞서 말했듯이 f가 아니라 F[f]를 요구합니다.product: 두 개의 포장된 객체가 주어졌을 때, 둘의 데카르트 곱(cartesian product)을 포장된 형태로 제공합니다: (Kind<F, A>, Kind<F, B>): Kind<F, Tuple2<A, B>>.map2: 타입 생성자 컨텍스트 안에 있는 두 값을 매핑하고, 그들의 데카르트 곱에 함수를 적용합니다: (Kind<F, A>, Kind<F, B>, (Tuple2<A, B>) -> Z): Kind<F, Z>.다시 코드로 이 개념을 체화해봅시다.
@typeclass
interface Applicative<F> : Functor<F>, TC {
fun <A> pure(a: A): Kind<F, A>
fun <A, B> ap(fa: Kind<F, A>, ff: Kind<F, (A) -> B>): Kind<F, B>
override fun <A, B> map(fa: Kind<F, A>, f: (A) -> B): Kind<F, B> = ap(fa, pure(f))
fun <A, B> product(fa: Kind<F, A>, fb: Kind<F, B>): Kind<F, Tuple2<A, B>> = ap(fb, map(fa) { a: A -> { b: B -> Tuple2(a, b) } })
fun <A, B, Z> map2(fa: Kind<F, A>, fb: Kind<F, B>, f: (Tuple2<A, B>) -> Z): Kind<F, Z> = map(product(fa, fb), f)
}Applicative는 Functor를 구현하므로 map을 오버라이드해야 하며, map은 ap와 pure로 표현할 수 있습니다. Box에 대한 Applicative 인스턴스를 만들고 싶다면, 앞서와 같이 두 가지 선택지가 있습니다. 직접 구현하거나, Arrow가 Box에 대해(구현된 함수들에 따라) 모든 타입 클래스 인스턴스를 유도하도록 맡기는 방법입니다. 여기서는 두 번째를 선택해봅시다.
@higherkind
@deriving(Functor::class, Applicative::class)
sealed class Box<out A> : BoxOf<A> {
fun <B> map(f: (A) -> B): Box<B> = ???
fun <B> ap(ff: BoxOf<(A) -> B>): Box<B> = ???
fun <B> product(fb: BoxOf<B>): Box<Tuple2<A, B>> = ???
fun <B, Z> map2(fb: BoxOf<B>, f: (Tuple2<A, B>) -> Z): Box<Z> = ???
companion object {
fun <A> pure(a: A): Box<A> = Full(a)
}
}이 예제에서는 구현 자체가 그리 중요하진 않지만, 관심이 있다면 여기에서 볼 수 있습니다.
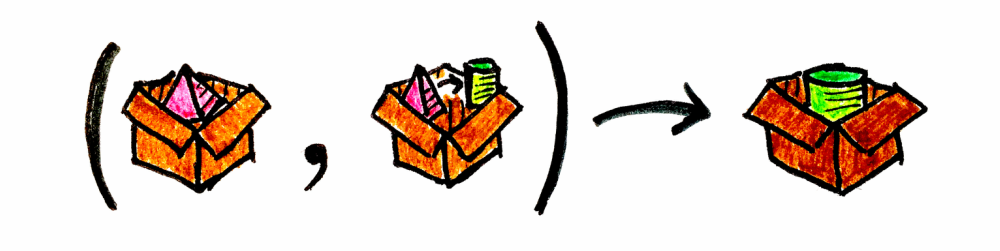
우리는 종종 서로 의존하지 않는 연산들로부터 여러 독립적인 값을 계산해야 하는 상황에 놓입니다. 아래 예제에서는, 원격 또는 로컬 서비스일 수도 있는 두 호출을 정의해 보겠습니다. 각각 Box라는 동일한 계산 컨텍스트에서 서로 다른 결과를 반환합니다.
fun getPyramidFromDB(name: String): Box<Pyramid>
fun getCylinderFromWS(name: String): Box<Cylinder>이는 서로 독립적인 여러 연산을 수행하고, 그 모든 결과를 함께 얻고 싶은 흔한 사용 사례를 대략적으로 보여줍니다.
val maybePyramid: Box<Pyramid> = getPyramidFromDB("MyPyramid")
val maybeCylinder: Box<Cylinder> = getCylinderFromWS("MyCylinder")
Box.applicative().map2(maybePyramid, maybeCylinder, { t -> Cone(t.b.name) }) //Box<Cone>핵심은, 레시피의 재료들이 서로 의존하지 않을 때 Applicative 구조를 사용한다는 점입니다. 이 경우 원통을 얻는 데 피라미드가 필요하지도 않고, 반대도 마찬가지입니다.
이제 이 글에서 가장 민망한 부분이 옵니다. 저는 수학자가 아니고, 이 설명은 그리 학술적이지 않습니다. 대신 수학적 의미보다, 모나드의 실용적 의미에 초점을 맞춥니다.
앞서 보았듯이 우리는 결과를 컨텍스트로 올리는 여러 도구를 이미 갖고 있습니다. 사실 Applicative 덕분에 서로 독립적인 여러 박스를 매핑해, 그 내용물로 어떤 연산을 수행하여 하나의 결과를 만들 수 있습니다.
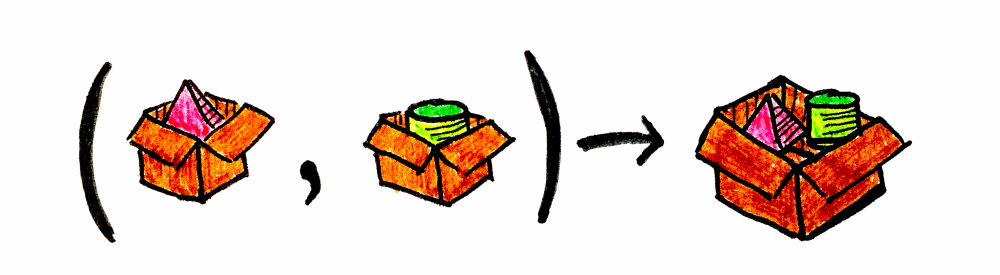
모나드(Monad)의 가장 큰 장점은, 박스 안에 박스가 생기는 것을 신경 쓰지 않고도 의존적인 중첩 연산을 다룰 수 있다는 점입니다. 모나드는 중첩된 컨텍스트를 평탄화(flatten)할 수 있고, 이는 강력한 능력입니다. 앞선 예제를 조금 바꾸면 문제가 보일 겁니다. 원통을 얻기 위해 피라미드가 필요하다고 상상해봅시다.
fun getPyramidFromDB(name: String): Box<Pyramid>
fun getCylinderFromWS(pyramid: Pyramid): Box<Cylinder>보시다시피 getPyramidFromDB는 피라미드를 주지만, 피라미드는 컨텍스트 안에 있습니다. 존재하지 않을 수도 있고(Option), 시간이 좀 걸릴 수도 있고(Future), 기타 등등 때문이죠. 하지만 getCylinderFromWS는 어떤 효과(effect)가 있는 피라미드를 기대하지 않고, 순수한 피라미드 자체를 요구합니다. “그럼 map을 써서 내용물을 조작하면 되지 않나?”라고 생각할 수도 있겠죠. 해봅시다.
val maybePyramid: Box<Pyramid> = getPyramidFromDB("MyPyramid")
maybePyramid.map { p -> getCylinderFromWS(p) } //Box<Box<Cylinder>>뭔가 이상합니다. Box<Box<Cylinder>>를 다루기 위한 추가 도구가 필요합니다. 여기서 flatten이 구세주로 등장합니다. 시그니처는 (Kind<F, Kind<F, A>>): Kind<F, A>입니다.
map과 flatten을 함께 쓰면 flatMap이라는 또 다른 조합자를 구현할 수 있습니다. 시그니처는 (Kind<F, A>, f: (A) -> Kind<F, B>): Kind<F, B>입니다.
이러한 능력을 표현하는 타입 클래스는 다음과 같을 수 있습니다.
@typeclass
interface Monad<F> : Applicative<F>, TC {
fun <A, B> flatMap(fa: Kind<F, A>, f: (A) -> Kind<F, B>): Kind<F, B>
fun <A> flatten(ffa: Kind<F, Kind<F, A>>): Kind<F, A> = flatMap(ffa, { it })
}Box에 대한 Monad 인스턴스 유도도 Arrow에 맡기겠습니다. 그러면 아래처럼 의존적인 연산들을 모나딕하게 체이닝할 수 있습니다.
val cone: Box<Cone> = getPyramidFromDB("MyPyramid").flatMap { pyramid ->
getCylinderFromWS(pyramid).map { cylinder ->
Cone(cylinder.name)
}
}모나드 컴프리헨션(Monad comprehension) 마지막으로 Arrow가 제공하는 또 하나의 멋진 기능을 보여주는 예제를 하나 들며 끝내고 싶습니다. 이런 시나리오를 상상해봅시다. 사용자 id가 주어지면, 그 사용자가 가장 좋아하는 아티스트 정보를 PDF 형식으로 제공하는 프로그램을 만들고 있습니다. 이를 위해 다음 서비스들이 있다고 해봅시다.
object UserRepository {
fun getUser(id: String): Option<User>
}
object Spotify {
fun getFavouriteArtist(artist: String): Option<Artist>
}
object Wikipedia {
fun getArticle(title: String): Option<Page>
}
object Converter {
fun toPDF(page: Page): Option<PDF>
}위 내용을 보면, 우리가 만들고 싶은 계산은 모나딕 구조에 잘 맞아 보이죠? 연산들이 서로 의존하고, 결과는 컨텍스트(여기서는 Option)로 들어올려진 상태로 오니까요. 그렇다면 “Option에 대한 Monad 인스턴스가 있나?”라고 저는 자문할 겁니다. 실제로 있습니다. Arrow가 만들어뒀죠. 그래서 우리는 이렇게 할 수 있습니다.
val pdf: Option<PDF> = UserRepository.getUser("123").flatMap { user ->
Spotify.getFavouriteArtist(user.spotifyUsername).flatMap { artist ->
Wikipedia.getArticle(artist.name).flatMap { page ->
Converter.toPDF(page)
}
}
}이렇게 하면 우리가 원하는 결과를 정확히 얻습니다. 하지만 다른 언어들은 종종 이런 모나딕 구조를 표현하기 위한 신택틱 슈가(syntactic sugar)를 제공합니다. 목적은, 서로 이어진 순차적 액션 체인을 다양한 배경의 프로그래머에게 자연스럽게 느껴지는 스타일로 합성할 수 있도록 하는 것입니다. Kotlin은 아직 이런 기능이 없지만, 앞서 말했듯 Arrow는 정말 멋진 관용구를 제공합니다: Monad Comprehensions
이제 같은 연산을 이렇게 쓸 수 있습니다.
val pdf: OptionOf<PDF> = Option.monad().binding {
val user = UserRepository.getUser("123").bind()
val artist = Spotify.getFavouriteArtist(user.spotifyUsername).bind()
val page = Wikipedia.getArticle(artist.name).bind()
Converter.toPDF(page).bind()
}이 글에서 사용한 모든 코드는 이 repo에서 찾을 수 있습니다. 제 생각에 Arrow를 가지고 놀아보고 싶다면 좋은 출발점이 될 겁니다.