expect test가 어떻게 테스트 작성을 더 빠르고 탐색적이며 문서화에도 유용한 작업으로 바꾸는지 살펴봅니다.
Jane Street에서는 테스트 작성을 REPL 세션처럼, 또는 Jupyter 노트북에서 탐색적으로 프로그래밍하는 것처럼 느끼게 해 주는 “expect test”라는 패턴/라이브러리를 사용합니다. 피드백 순환이 너무 빠르고 즐거워서 거의 손으로 만지는 듯한 느낌이 듭니다. 한동안 이것을 사용해 본 지금, 제가 테스트를 작성하고 싶은 방식은 이것뿐입니다.
다른 언어에서는 이것을 “snapshot” 테스트라고 부릅니다. 예를 들어 Rust의 expect-test가 있고, 이것은 우리 라이브러리에서 영감을 받은 듯합니다. 또는 Javascript의 Jest도 있습니다. 우리도 처음에는 Mercurial의 unified testing format과 셸 세션을 테스트하기 위한 이른바 “cram” 테스트를 통해 이 아이디어를 접했습니다.
제가 사용해 본 대부분의 테스트 프레임워크에서는 가장 단순한 단언조차 놀랄 만큼 많은 수고를 요구합니다. fibonacci 함수에 대한 테스트를 작성한다고 해 봅시다. 다음과 같이 쓰기 시작합니다.
assert fibonacci(15) ==
...
그런데 이미 여기서 생각을 해야 합니다. fibonacci(15)는 도대체 얼마일까요? 이미 알고 있다면 훌륭합니다. 하지만 모른다면 어떻게 해야 할까요?
아마도 다음과 같은 말도 안 되는 코드를 써야 하는 것 같습니다.
assert
fibonacci(15) == 8
그러면 테스트가 “틀렸습니다! 8을 기대했지만 610을 받았습니다”라고 말하고, 터미널 버퍼에 있는 610을 에디터로 복사해 붙여넣어야 하겠지요.
이건 정말 터무니없습니다!
expect test에서는 이렇게 합니다.
printf "%d" (fibonacci 15);
[%expect {||}]
%expect 블록이 처음에는 비어 있는 이유는 바로 무엇을 기대해야 하는지 모르기 때문입니다. 컴퓨터가 그것을 대신 알아내게 두는 것입니다. 우리 환경에서는 단지 빈 문자열 대신 610을 원한다는 빌드 실패 메시지만 받는 것이 아닙니다. 테스트를 통과시키기 위해 파일에 정확히 어떤 변경을 해야 하는지 보여 주는 diff를 받게 됩니다. 그리고 단축키 하나로 그 diff를 “수락”할 수 있습니다. 그러면 여러분이 보고 있는 Emacs 버퍼의 내용이 실제로 그 자리에서 새 내용으로 덮어써집니다 [1].
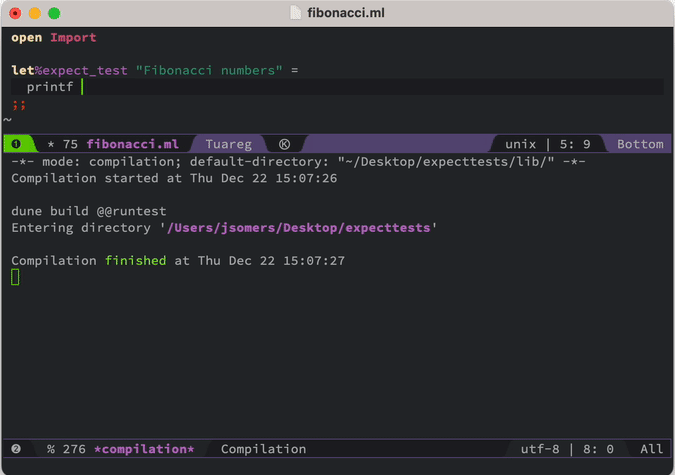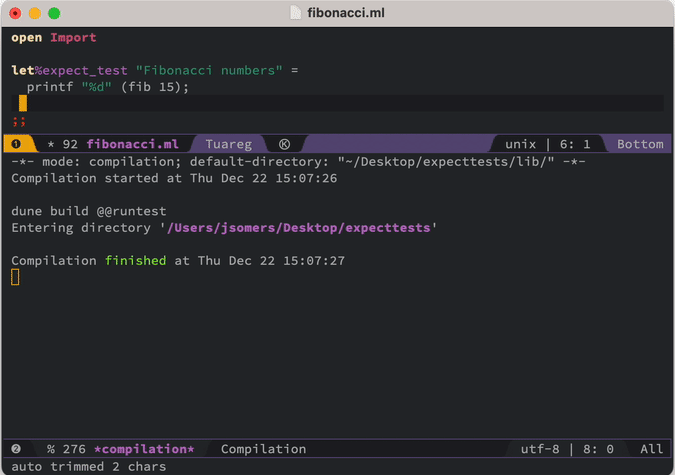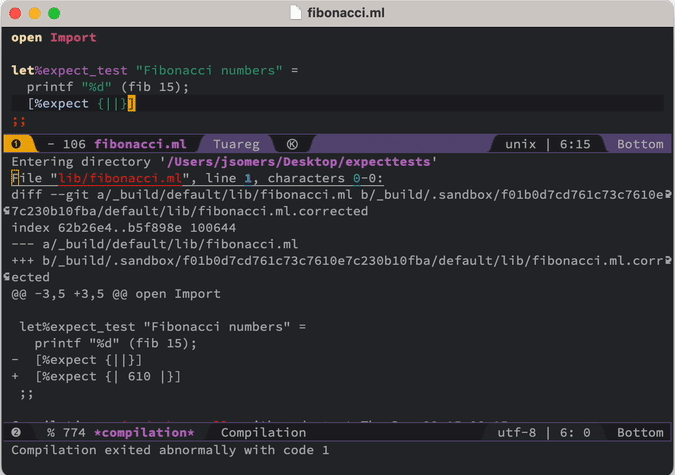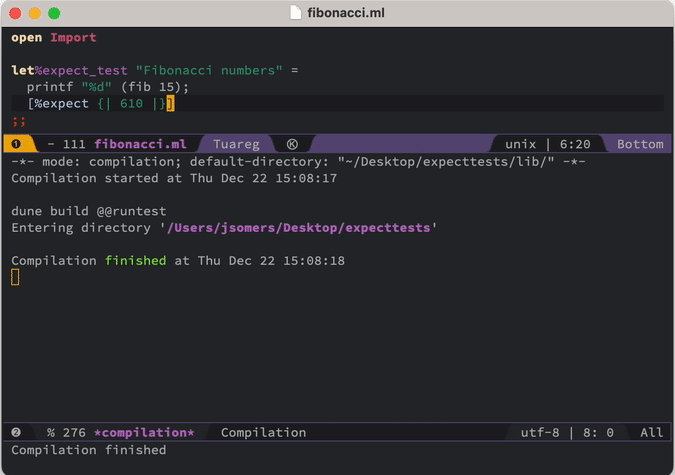
이 워크플로의 강력함은 아무리 강조해도 지나치지 않습니다. “테스트를 작성한다”는 것은 그냥 어떤 코드 아래에 [%expect] 블록을 하나 떨어뜨려 놓는 것이고, 그러면 그 코드가 출력한 내용으로 채워집니다.
바로 얼마 전 저는 다소 특이한 제약 조건 아래에서 숫자를 반올림하는 까다로운 작은 함수를 작성하고 있었습니다. 이런 종류의 작업은 빠르게 많은 예제를 돌려 보며 반복하기 위해 REPL이나 Jupyter 노트북에서 작성하고 싶어지는 전형적인 예입니다. 제가 해야 했던 일은 함수 바로 아래에 다음을 쓰는 것뿐이었습니다.
let%expect_test "Test the [round] function on [examples]" =
Ascii_table.simple_list_table
[ "n"; "f(n)" ]
(List.map examples ~f:(fun n -> [ n; round n ] |> List.map ~f:string_of_float));
[%expect {||}]
그러자 짠, 에디터가 결과의 작은 표를 만들어 주었습니다. 당연히 제 첫 구현에는 온갖 버그가 있었고, 표의 몇몇 항목은 틀려 보였습니다. 함수를 개선하는 일은 조금 고치고, 그 결과 생긴 diff를 보고, 또 조금 고치고, 이런 일을 반복하는 문제로 바뀌었습니다. 마침내 표가 제가 원하는 모습이 될 때까지 말입니다. (원했다면 그 시점에 Quickcheck 같은 것을 사용해 철저한 퍼즈 테스트를 할 수도 있었겠지요.) 그동안 그 표는 문서로도 살아남았습니다. 실제로 많은 함수에서는 예시 입력과 출력 몇 개를 보는 것이 장황한 설명보다 훨씬 더 분명합니다.
물론 그 표는 단지 탐색 보조 도구이자 문서의 일부일 뿐만 아니라, 말 그대로 테스트이기도 합니다. 누군가 제 함수나 그 의존성 중 하나를 수정하면 [%expect] 블록 안에 얼려 둔 출력이 예상치 못한 동작을 막아 줍니다. expect test에서 회귀는 곧 diff입니다.
(일반적으로 코드를 작성한 바로 그 자리에 테스트를 인라인으로 넣는 것도 가능하지만, Jane Street에서는 테스트 코드와 실제 코드를 명확히 분리하는 편입니다. 테스트는 별도의 디렉터리에 두고 공개 인터페이스를 대상으로 작성하거나, 비공개 구현을 테스트할 때는 오직 그 목적만을 위해 내보낸 For_testing 모듈을 대상으로 작성합니다.)
예전에 제가 Ruby 웹 개발 회사에서 일할 때는 다음과 같은 테스트를 많이 작성하곤 했습니다. 이것은 인기 있는 Ruby 테스트 프레임워크인 RSpec에 관한 블로그 글에서 가져온 예입니다.
before do
@book = Book.new(:title => "RSpec Intro", :price => 20)
@customer = Customer.new
@order = Order.new(@customer, @book)
@order.submit
end
describe "customer" do
it "puts the ordered book in customer's order history" do
expect(@customer.orders).to include(@order)
expect(@customer.ordered_books).to include(@book)
end
end
describe "order" do
it "is marked as complete" do
expect(@order).to be_complete
end
it "is not yet shipped" do
expect(@order).not_to be_shipped
end
end
이것은 완전히 훌륭한 테스트입니다. 하지만 생각해 봅시다. 저 describe 블록 안의 모든 것은 손으로 직접 써야 했습니다. 프로그래머는 먼저 어떤 속성들이 중요한지 결정해야 했습니다. 즉 customer.orders, customer.ordered_books, order.complete, order.shipped 같은 것들입니다. 그리고 각 필드가 어떤 상태일 것이라 기대하는지도 명시적으로 적어야 했습니다. 그러고 나서 그것을 전부 타이핑해야 했습니다.
제 핵심 주장은, 그러한 결정과 타이핑이 충분히 고통스럽기 때문에 실제로 테스트 작성을 방해한다는 것입니다. 테스트는 다음과 같은 일을 도와주는 멀티툴이 아니라 골칫거리가 되어 버립니다.
RSpec에 expect test가 있었다면 다음처럼 간단히 쓸 수 있었을 것입니다.
expect_test "#submit" do
@book = Book.new(:title => "RSpec Intro", :price => 20)
@customer = Customer.new
@order = Order.new(@customer, @book)
@order.submit
p @customer.orders
p @order
expect ""
end
그러면 같은 상태를 전부 눈에 보이게 만들 수 있었을 것입니다.
벌써 이런 반응이 들리는 것 같습니다. 테스트는 명시적이어야 합니다. 어떤 속성에 관심이 있는지, 어떤 출력을 기대하는지 등을 처음부터 정의하고 싶을 것입니다. (특히 TDD에서는 더 그렇습니다.) 상태를 한꺼번에 덤프해 놓고 독자가 무슨 일이 일어나는지 스스로 정리하게 두고 싶지는 않을 것입니다. 그리고 함수가 작성될 때까지 기다렸다가 테스트를 쓰고 싶지도 않을 것입니다.
맞습니다! 하지만 expect test도 전통적인 단위 테스트만큼 충분히 정밀할 수 있습니다. 저는 언제든 order.shipped?를 출력하고 expect 블록 안에 문자열 "false"를 직접 입력할 수 있습니다. 코드를 아직 쓰기 전에도 이렇게 할 수 있고, 그러면 RSpec으로 TDD를 하는 사람이 받는 것과 같은 종류의 오류를 얻게 됩니다.
차이는 제가 반드시 그렇게 할 필요는 없다는 점입니다. 또는 “일단 무슨 일이 일어나는지 보자”라는 빠르고 느슨한 단계를 거친 뒤에 그렇게 하는 일을 미뤄 둘 수도 있습니다. 빈 expect 블록의 아름다움은 바로 여기에 있습니다. 그것은 런타임에게 자기가 무엇을 생각하는지 말해 보라고 초대하는 것입니다.
물론 아무 필터링 없이 상태를 그냥 덤프하는 것의 단점 가운데 하나는 중요하지 않은 세부사항 속에서 길을 잃을 수 있다는 점입니다. 테스트를 처음 읽을 때도, 코드 변경으로 인해 테스트 출력이 바뀌었을 때도, 무엇이 중요한지 독자가 파악하기가 더 어려워집니다. 또 우연한 변경을 함께 끌어들일 가능성도 높아집니다.
그래서 expect test의 예술은 여러분이 신경 쓰는 상태를 포착하면서도 간결한 이야기를 들려주는 출력을 만들어 내는 데 있습니다. 최고의 테스트는 불필요한 세부사항을 생략하려고 애씁니다. 보통은 보조 함수와 사용자 정의 pretty-printer를 사용해 출력을 다듬습니다.
expect test가 Jane Street에 처음 도입되었을 때, 그것은 들불처럼 퍼져 나갔습니다. 이제 expect test는 우리 테스트 스위트의 대부분을 차지하고 있고, 일부 영역에서는 property-based testing이 그것을 보완합니다. 전통적인 assertion 스타일의 단위 테스트도 여전히 자리가 있기는 합니다. 다만 그 자리가 훨씬 작아졌을 뿐입니다.
기대 출력을 손으로 직접 작성하는 지루함은 실제 시스템이 복잡해질수록 더 커집니다. 숫자 표 하나도 일인데, 웹 애플리케이션의 DOM 상태나 금융 거래소의 주문서 상태를 설명하려 한다고 상상해 보십시오.
다음은 Jane Street의 오픈소스 OCaml 웹 프레임워크 Bonsai로 만든 장난감 웹 앱에서 가져온 실제 테스트의 일부입니다. (React나 Elm을 떠올리면 됩니다.) Bonsai의 가장 강력한 기능 가운데 하나는 UI 요소를 프로그래밍 방식으로 조작하고 DOM이 어떻게 변하는지 관찰하는 현실적인 테스트를 쉽게 작성할 수 있게 해 준다는 점입니다.
이 예에서는 사용자 선택기의 동작을 테스트합니다. 텍스트 상자에 입력하는 내용은 무엇이든 작은 “hello” 메시지 뒤에 붙습니다.
let%expect_test "shows hello to a specified user" =
let handle = Handle.create (Result_spec.vdom Fn.id) hello_textbox in
Handle.show handle;
[%expect
{|
<div>
<input oninput> </input>
<span> hello </span>
</div> |}];
Handle.input_text handle ~get_vdom:Fn.id ~selector:"input" ~text:"Bob";
Handle.show_diff handle;
[%expect
{|
<div>
<input oninput> </input>
- <span> hello </span>
+ <span> hello Bob </span>
</div> |}];
여기에는 expect 블록이 두 개 있다는 점에 주목하세요. (이렇게 하면 하나의 시나리오 안에서 여러 번 단언할 수 있고, 설정/보조 코드를 그 시나리오에만 국한시킬 수 있습니다.)
첫 번째 블록은 UI를 눈에 보이게 만들고, 두 번째 블록은 diff를 포함하여 텍스트를 프로그래밍 방식으로 입력한 뒤의 동작을 보여 줍니다. Bonsai는 사용자 입력에 반응해 html 속성이나 class 이름이 어떻게 바뀌는지도 보여 줍니다. 테스트에는 모의 서버 호출도 포함할 수 있고, UI뿐 아니라 그것을 구동하는 상태의 변화도 담을 수 있습니다. 이런 테스트가 있으면 브라우저를 열지 않고도 컴포넌트 전체를 작성할 수 있습니다.
고해상도 프로그램 실행 추적을 수집하고 표시하기 위해 Intel Processor Trace를 사용하는 인기 도구 magic-trace도 expect test를 많이 사용합니다. 일부는 단순합니다. 예를 들어 프로그램의 심볼 디맹글러를 테스트하는 다음 예가 있습니다.
let demangle_symbol_test symbol =
let demangle_symbol = Demangle_ocaml_symbols.demangle symbol in
print_s [%sexp (demangle_symbol : string option)]
;;
let%expect_test "real mangled symbol" =
demangle_symbol_test "camlAsync_unix__Unix_syscalls__to_string_57255";
[%expect {| (Async_unix.Unix_syscalls.to_string) |}]
;;
let%expect_test "proper hexcode" =
demangle_symbol_test "caml$3f";
[%expect {| (?) |}]
;;
let%expect_test "when the symbol is not a demangled ocaml symbol" =
demangle_symbol_test "dr__$3e$21_358";
[%expect {| () |}]
;;
다른 것들은 일종의 안정적인 문서 역할을 하며, 실행 중인 시스템 내부를 들여다볼 수 있게 해 줍니다. 예를 들어 다음 테스트는 OCaml 예외의 추적이 실제로 어떻게 보이는지를 보여 줍니다. (명확성을 위해 줄였습니다.)
let%expect_test "A raise_notrace OCaml exception" =
let ocaml_exception_info =
Magic_trace_core.Ocaml_exception_info.create
~entertraps:[| 0x411030L |]
~pushtraps:[| 0x41100bL |]
~poptraps:[| 0x411026L |]
in
let%map () =
Perf_script.run ~ocaml_exception_info ~trace_scope:Userspace "ocaml_exceptions.perf"
in
[%expect
{|
23860/23860 426567.068172167: 1 branches:uH: call 411021 camlRaise_test__entry+0x71 (foo.so) => 410f70 camlRaise_test__raise_after_265+0x0 (foo.so)
-> 3ns BEGIN camlRaise_test__raise_after_265
-> 6ns BEGIN camlRaise_test__raise_after_265
-> 9ns BEGIN camlRaise_test__raise_after_265
-> 13ns BEGIN camlRaise_test__raise_after_265
-> 13ns BEGIN camlRaise_test__raise_after_265
-> 13ns BEGIN camlRaise_test__raise_after_265
-> 13ns BEGIN camlRaise_test__raise_after_265
-> 14ns BEGIN camlRaise_test__raise_after_265
...
|}%]
다음은 Jane Street의 장난감 시스템에서 가져온 테스트로, 시장 데이터를 처리합니다. (우리는 이 시스템을 내부 “dev teach-in”의 일부로 사용합니다. 이것은 개발자들에게 회사 전반의 다양한 시스템, 라이브러리, 아이디어, 관용구를 접하게 하려는 2주짜리 내부 수업입니다. 예를 들면 _고급 함수형 프로그래밍_이나 성능 엔지니어링 같은 것들입니다.) 이 특정 테스트의 목표는 “매수”와 “매도”가 있는 양면 주문서의 상태가 들어오는 주문에 어떻게 반응하는지를 보여 주는 것입니다.
이 테스트를 작성하려면 상황을 설정한 다음, 빈 [%expect] 블록을 하나 떨어뜨려 놓기만 하면 됩니다.
let d = create_marketdata_processor () in
(* Do some preprocessing to define the symbol with id=1 as "APPL" *)
process_next_event_in_queue d
{|
((timestamp (2019-05-03 12:00:00-04:00))
(payload (Add_order (
(symbol_id 1)
(order_id 1)
(dir Buy)
(price 10.00)
(size 1)
(is_active true)))))
|};
+ [%expect {||}];
그러면 컴파일러가 그 블록 안에 무엇이 들어가야 하는지 알아냅니다. 빈칸이어서는 안 된다는 빌드 오류를 보게 될 것입니다. 제안된 diff를 수락하면 다음과 같은 블록을 얻게 됩니다.
[%expect {|
process_next_event_in_queue d
{|
((timestamp (2019-05-03 12:00:00-04:00))
(payload (Add_order (
(symbol_id 1)
(order_id 1)
(dir Buy)
(price 10.00)
(size 1)
(is_active true)))))
|};
[%expect {|
+ ((book_event
+ (Order_added ((order_id 1) (dir Buy) (price 10.0000000) (size 1))))
+ (book
+ ((instrument_name AAPL)
+ (book ((buy (((price 10.0000000) (orders ((1 1)))))) (sell ()))))))
|}];
이것은 아름답습니다. 시스템 상태를 평문으로 표현한 모습입니다. expect 블록이 주문서를 보여 줍니다. 주문서를 작고 단순하게 유지하면 테스트를 읽기 쉬워집니다. 하지만 주문서에 대해 어떤 특정한 단언도 직접 만들 필요는 없습니다.
마지막 블록을 RSpec 세계에서 쓴다면 아마 이런 식일 것입니다.
expect @book["AAPL"].sell to_be empty
expect @book["AAPL"].buy[0].price to_equal 10
expect @book_events to.include(@order)
주문서 전체 상태의 모든 측면을 명시적으로 확인하는 것은 너무 지루하므로, 대신 가장 중요하다고 생각하는 몇 가지 단언만 작성하게 됩니다. 이것은 생각과 타이핑과 시간을 요구합니다.
그리고 나중에 누군가 주문 엔진의 구현을 망가뜨렸을 때 취약해지기도 합니다. 예를 들어 이제는 주문을 주문서에 추가할 때 주문의 수량을 잘못 처리한다고 해 봅시다. 위의 손수 만든 단언들은 계속 통과할 것입니다. 주문서 위의 주문의 _수량_에 대해서는 아무 말도 하지 않았기 때문입니다. 하지만 expect test는 size 1이 의도치 않게 size 100으로 바뀌었다는 것을 보여 주는 깔끔한 diff와 함께 실패할 것입니다.
물론 expect test가 일반 단위 테스트보다 항상 더 많은 것을 잡아낸다고 말할 수는 없습니다. 둘 다 정확히 같은 수준의 유연성을 갖고 있기 때문입니다. 하지만 무엇을 단언하고 싶은지 정확히 떠올려야 하는 부담을 줄여 주기 때문에, expect test는 더 많은 것을 암묵적으로 단언하기 쉽게 만듭니다. 아이러니하게도, 그것들은 여러분이 결코 기대하지 않았던 것들까지 포착합니다.
이 스타일의 테스트는 출력 자체를 쉽게 만들도록 장려합니다. 대부분의 테스트가 데이터를 조금 설정한 다음 그것을 출력하는 것 이상의 일을 하지 않기 때문입니다. 실제로 Jane Street에서는 거의 모든 타입에 대해 문자열 표현을 아주 쉽게 만들 수 있게 해 주는 코드 생성기(ppx_sexp_conv 같은 것)를 사용합니다. (위에서 보셨겠지만, 우리는 S-expression을 많이 활용합니다.)
사람들은 expect test가 너무 편리하다고 느끼기 때문에, 예상하지 못할 것 같은 곳에서도 평문 출력을 생성하는 보조 도구를 만들기 위해 큰 노력을 기울이곤 합니다. 예를 들어 Jane Street가 현재 유지보수하는 FPGA 시뮬레이션 작성용 오픈소스 DSL인 Hardcaml에서는 많은 테스트가 사각형 형태의 평문 파형을 포함합니다. 이것은 예를 들어 clock과 clear 라인이 정확히 무엇을 하고 있는지 보여 줍니다.
let%expect_test "counter" =
let waves = testbench ()
Waveform.print ~display_height:12 waves
[%expect {|
+ ┌Signals────────┐┌Waves──────────────────────────────────────────────┐
+ │clock ││┌───┐ ┌───┐ ┌───┐ ┌───┐ ┌───┐ ┌───┐ ┌──│
+ │ ││ └───┘ └───┘ └───┘ └───┘ └───┘ └───┘ │
+ │clear ││ ┌───────┐ │
+ │ ││────────────────────────┘ └─────────────── │
+ │incr ││ ┌───────────────┐ │
+ │ ││────────┘ └─────────────────────── │
+ │ ││────────────────┬───────┬───────┬─────────────── │
+ │dout ││ 00 │01 │02 │00 │
+ │ ││────────────────┴───────┴───────┴─────────────── │
+ │ ││ │
+ └───────────────┘└───────────────────────────────────────────────────┘
|}]
이 글이 더 많은 사람들이 “snapshot” 스타일의 테스트를 시도해 보도록 격려하길 바랍니다. 제 개인적인 경험으로는, 이제 저는 컴퓨터가 제 테스트를 대신 완성해 주지 않는 워크플로로 돌아가고 싶지 않습니다. 다른 것은 몰라도, 기대 결과를 받아 적절한 위치의 단언 안에 넣어 주는 에디터 통합만으로도 큰 도움이 됩니다. 그런 단언을 손으로 직접 타이핑하는 일은, 마치 소스 코드의 포매팅을 손으로 직접 고치는 것처럼 느껴집니다. 저는 수년 동안 그것을 별문제 없이 해 왔지만, 이전의 관행이 어딘가 우스꽝스럽게 보이게 만드는 도구가 등장하고 나서는 이야기가 달라졌습니다.
보아하니 이 관용구는—다시 말하지만 우리가 발명한 것이 아니라 Mercurial에서 빌려 온 것이고, 다만 그것이 정말 최초의 근원인지 아니면 더 거슬러 올라가는지는 잘 모르겠습니다—점점 더 널리 퍼지고 있는 듯합니다. 언젠가는 정말 주류가 될지도 모릅니다.
[1] 예전에는 이것을 사실상 자신의 소스를 출력하는 방법을 아는 프로그램을 다루게 된다는 점에서 quine 테스트라고 부르곤 했습니다.