모델을 바꾸지 않고도 편집 도구(하네스)만 바꿔 여러 LLM의 실제 코드 수정 성공률을 크게 끌어올린 방법과, Hashline 편집 포맷의 아이디어 및 벤치마크 결과를 다룬다.
사실 바뀐 건 편집 도구뿐이었다. 그게 전부다.
Patch · Replace · Hashline · Hashline v2 — 16개 모델 전반의 정확도
정렬
모델
Δ Patch
Δ Repl.
토큰
1 Gemini 3 Flash
Patch 73.3%
Replace 70.0%
Hashline 78.3 81.3%
+8.0
+11.3
-21%
2 Claude Haiku 4.5
Patch 63.3%
Replace 65.0%
Hashline 68.3 76.3%
+13.0
+11.3
-22%
3 MiniMax M2.1
Patch 23.3%
Replace 55.0%
Hashline 55.0 65.0%
+41.7
+10.0
-42%
4 GLM-4.7
Patch 51.7%
Replace 66.7%
Hashline 71.7 75.0%
+23.3
+8.3
-32%
5 Kimi K2.5
Patch 66.7%
Replace 71.7%
Hashline 76.7%
+10.0
+5.0
-26%
6 Grok Code Fast 1
Patch 6.7%
Replace 66.7%
Hashline 68.3 71.3%
+64.6
+4.6
-49%
7 GPT-5.1 Codex Mini
Patch 57.2%
Replace 73.3%
Hashline 60.0 77.5%
+20.3
+4.2
—
8 Devstral Medium
Patch 18.3%
Replace 55.0%
Hashline 43.3 58.8%
+40.5
+3.8
—
9 Claude Sonnet 4.5
Patch 65.6%
Replace 76.7%
Hashline 78.3 80.0%
+14.4
+3.3
-24%
10 Grok-4.1 Fast
Patch 58.3%
Replace 75.0%
Hashline 73.3 77.5%
+19.2
+2.5
-20%
11 GLM-4.5 Air
Patch 36.7%
Replace 63.3%
Hashline 50.0 63.7%
+27.0
+0.4
-17%
12 Gemini 2.5 Flash Lite
Patch 26.7%
Replace 36.7%
Hashline 36.7%
+10.0
±0.0
—
13 GPT-5.2 Codex
Patch 76.7%
Replace 81.7%
Hashline 76.7 81.3%
+4.6
-0.4
–
14 Grok 4 Fast
Patch 28.9%
Replace 46.7%
Hashline 43.3 46.3%
+17.4
-0.4
-61%
15 Qwen Turbo
Patch 6.7%
Replace 25.0%
Hashline 23.3%
+16.6
-1.7
—
16 DeepSeek V3.2
Patch 76.7%
Replace 80.0%
Hashline 71.7%
-5.0
-8.3
–
Hashline은 16개 모델 중 14개에서 Patch를 능가한다. Hashline v2는 16개 모델 중 12개에서 추가로 개선된다 — 최대 향상: GPT-5.1 Codex Mini — 60.0% → 77.5% (+17.5pp).
지금 대화의 대부분은 어떤 모델이 코딩에 더 좋은지, GPT-5.3냐 Opus냐에 집중돼 있다. Gemini냐 이번 주에 떨어진 뭐든이냐. 하지만 이런 프레이밍은 점점 더 오해를 낳는다. 모델만이 중요한 변수인 것처럼 다루기 때문이다. 실제로 병목 중 하나는 훨씬 더 소소한 것, 즉 **하네스(harness)**다.
하네스는 사용자가 받는 첫인상을 포착하는 곳일 뿐 아니라(마구 스크롤이 튀는지, 버터처럼 부드러운지?), 모든 입력 토큰이 들어오는 근원이며, 모델 출력과 워크스페이스에 가해지는 모든 변경 사이의 인터페이스이기도 하다.
나는 작은 “취미 하네스”인 oh-my-pi를 관리한다. 이건 Mario Zechner가 만든 훌륭한 오픈소스 코딩 에이전트 Pi의 포크다. 지금까지 약 1,300개의 커밋을 작성했는데, 대부분은 고통 지점을 볼 때마다 이런저런 실험을 하고 소소한 개선을 쌓아 올린 것이다(혹은 자폐가 발동해서 “rg를 스폰하는 건 뭔가 잘못됐다”는 이유로 N-API를 통해 Rust를 더 심어 넣을 기회를 보면).
왜 굳이 하느냐고? Opus가 훌륭한 모델일 수는 있지만, Claude Code는 지금도 서브에이전트 출력에서 원시 JSONL을 새어 내보내며 수십만 토큰을 낭비한다. 나는 “씨발, 이제 서브에이전트는 구조화된 데이터를 출력하게 하자”라고 말할 수 있다.
도구 스키마, 에러 메시지, 상태 관리, “모델이 무엇을 바꿔야 하는지 앎”과 “이슈가 해결됨” 사이의 모든 것. 실전에서 실패의 대부분은 여기에서 발생한다.
모델 비종속(model agnostic)이라는 점에서, 모델은 그저 파라미터일 뿐이니 훌륭한 테스트베드다. 진짜 변수는 하네스이며, 여기서는 상상도 못 할 정도로 많은 제어권을 갖는다.
어쨌든, 어제 내가 바꾼 이 한 _변수_에 대해 이야기해 보자.
내가 무엇을 만들었는지 설명하기 전에, 현 시점의 최첨단이 어떤 상태인지 이해할 가치가 있다.
Codex는 apply_patch를 쓴다: 입력으로 문자열을 받는데, 본질적으로 OpenAI 풍의 diff다. 구조화된 스키마에 의존하는 대신, 하네스는 이 덩어리(blob)가 엄격한 규칙 집합을 따르길 기대한다. OpenAI 사람들이 분명 똑똑하다는 점을 감안하면, GPT의 Codex 변형을 위한 LLM 게이트웨이에서 토큰 선택 과정이 이 구조에 맞도록 편향되어 있을 거라 확신한다. 다른 제약(예: JSON 스키마나 필수 tool call)이 작동하는 방식과 비슷하게 말이다.
하지만 이걸 전혀 모르는 다른 모델에게 주면? 패치 실패가 폭증한다. 내 벤치마크에서 Grok 4의 패치 실패율은 50.7%, GLM-4.7은 **46.2%**였다. 이들은 나쁜 모델이 아니다 — 그저 그 언어를 하지 못할 뿐이다.
Claude Code(그리고 대부분)는 str_replace를 쓴다: 정확히 기존 텍스트를 찾아 새 텍스트로 바꾼다. 생각하기엔 매우 단순하다. 하지만 모델은 공백과 들여쓰기를 포함해 모든 문자를 완벽히 재현해야 한다. 여러 곳이 매칭되면? 거절된다. “파일에서 바꿀 문자열을 찾을 수 없음(String to replace not found in file)” 에러는 너무 흔해서 자기만의 GitHub 이슈 메가스레드(+ 다른 27개 이슈)가 있을 정도다. 최적이라고 하긴 어렵다. Gemini도 본질적으로 같은 일을 하되, 여기에 약간의 퍼지 공백 매칭을 더한다.
Cursor는 별도의 신경망을 훈련했다: 드래프트 편집을 받아 파일에 올바르게 병합하는 일만 하는 파인튜닝된 70B 모델이다. 하네스 문제가 너무 어려워서, 가장 자금력이 좋은 AI 회사 중 하나가 이 문제에 또 다른 모델을 던지기로 결정했을 정도다. 그리고 그들조차 자신들의 블로그 글에서 “400줄 미만 파일에서는 전체 파일을 완전히 다시 쓰는 것이 aider 같은 diff보다 성능이 좋다”고 말한다.
**Aider의 자체 벤치마크**는 포맷 선택만으로도 GPT-4 Turbo가 26%에서 59%로 요동쳤음을 보여준다. 하지만 같은 포맷에서도 GPT-3.5는 유효한 diff를 안정적으로 생성하지 못해 19%에 그쳤다. 포맷은 모델만큼이나 중요하다.
JetBrains의 Diff-XYZ 벤치마크는 이를 체계적으로 확인해 줬다. 단일 편집 포맷이 모든 모델과 사용 사례를 지배하지는 않는다. EDIT-Bench는 현실적인 편집 작업에서 pass@1이 60%를 넘는 모델이 단 하나뿐이라는 사실을 발견했다.
보면 알겠지만, 단순한 “어떻게 바꾸는가” 문제에 대해 “최선의 해법”에 대한 진짜 합의는 없다. 내 5센트 의견: 이 도구들 중 어느 것도, 엄청난 컨텍스트를 낭비하고 완벽한 회상에 의존하지 않으면서, 모델이 바꾸고 싶은 줄에 대해 안정적이고 검증 가능한 식별자를 제공하지 못한다. 모두 모델이 이미 봤던 내용을 다시 재현하는 데 의존한다. 그게 안 되면 — 그리고 자주 안 된다 — 사용자는 모델을 탓한다.
이제 잠깐만 따라와 달라. 모델이 파일을 읽거나 grep을 했을 때, 모든 줄이 2~3글자짜리 내용 해시로 태깅되어 돌아온다면 어떨까:
11:a3|function hello() {
22:f1| return "world";
33:0e|}
모델이 편집할 때는 그 태그를 참조한다 — “2:f1 줄을 바꿔라, 1:a3부터 3:0e까지 범위를 바꿔라, 3:0e 뒤에 삽입해라.” 마지막으로 읽은 뒤 파일이 바뀌었다면, (낙관적으로는) 해시가 맞지 않을 것이고, 무엇인가가 손상되기 전에 편집이 거부된다.
유사 랜덤 태그를 회상할 수 있다면, 편집 대상이 무엇인지 알고 있을 가능성이 크다. 그러면 모델은 신뢰할 수 있는 “앵커”를 보여 주기 위해 기존 내용을 재현하거나, 하물며 공백까지 정확히 재현할 필요가 없어진다.
내 주요 관심사가 실전 성능이었기 때문에, 픽스처는 다음과 같이 생성한다:
평균적인 작업 설명은 대략 이런 모습이다:
1# Fix the bug in `useCommitFilteringAndNavigation.js`
2
3A guard clause (early return) was removed.
4The issue is in the `useCommitFilteringAndNavigation` function.
5Restore the missing guard clause (if statement with early return).
물론 여기서 성공률 100%를 기대하진 않는다. 모델은 반드시 동일한 파일이 되도록 하는 유일한 해법이 아니라, 다른 해법을 떠올릴 수도 있기 때문이다. 하지만 버그는 충분히 기계적이라서, 대부분의 경우 수정은 우리가 넣어 둔 변이를 되돌리는 것이다.
작업당 3회 실행, 실행당 180개 작업. 매번 새로운 에이전트 세션, 도구 4개(read, edit, write). 우리는 임시 워크스페이스를 주고 프롬프트를 전달한 뒤, 에이전트가 멈추면 포맷팅 전후의 원본 파일과 비교한다.
16개 모델, 3개 편집 도구, 그리고 결과는 명확하다: patch는 거의 모든 모델에서 최악의 포맷이고, hashline은 대부분에서 replace와 맞먹거나 이기며, 약한 모델일수록 얻는 이득이 크다. Grok Code Fast 1은 6.7%에서 68.3%로 10배 향상됐다. patch가 너무 치명적으로 실패해서, 모델의 실제 코딩 능력이 기계적 편집 실패 뒤에 거의 완전히 가려져 있었기 때문이다. MiniMax는 두 배 이상으로 뛰었다. Grok 4 Fast는 재시도 루프에 토큰을 태우지 않게 되면서 출력 토큰이 61% 줄었다.
Gemini의 성공률이 +8% 개선되는 것은 대부분의 모델 업그레이드가 제공하는 것보다 크며, 학습 컴퓨트가 0으로 든다. 그저 약간의 실험(그리고 벤치마킹에 쓴 약 300달러)만으로.
많은 경우 모델은 과제를 이해하는 데서 불안정한 게 아니다. 자신을 표현하는 데서 불안정하다. 착륙장치 탓을 조종사에게 돌리고 있다.
Anthropic은 최근, 엄청나게 인기 있는 오픈소스 코딩 에이전트인 OpenCode가 Claude Code 구독을 통해 Claude에 접근하는 것을 차단했다.
Anthropic의 입장인 “OpenCode가 사설 API를 리버스 엔지니어링했다”는 표면적으로 타당하다. 그들의 인프라, 그들의 규칙. 하지만 그 조치가 시사하는 바를 보자:
하네스를 만들지 마라. 우리 걸 써라.
Anthropic만 그런 것도 아니다. 이 글을 쓰는 동안 Google은 내 계정을 Gemini에서 완전히 밴했다:
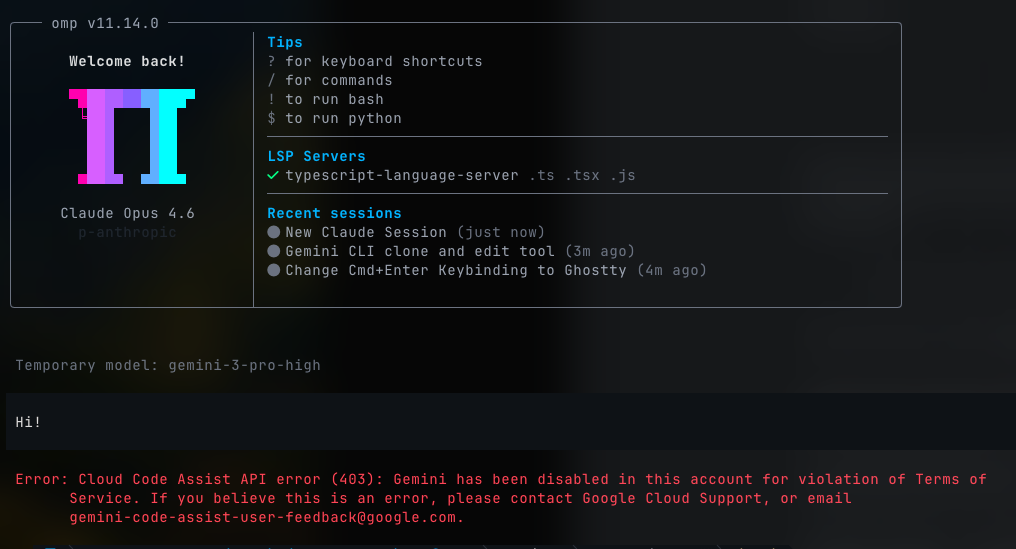
레이트리밋도 아니었고, 경고도 아니었다. 비활성화였다. 벤치마크를 돌렸다는 이유로 — 그리고 그 벤치마크는 Gemini 3 Flash가 새로운 기법으로 78.3%를 찍는 것을 보여 줬는데, 이는 그들이 시도한 최선보다 5.0pp나 낫다. 나는 도대체 뭐 때문인지조차 모르겠다.
왜 이게 거꾸로인지 말해 보자. 나는 방금, 다른 편집 포맷이 _그들의 모델_을 5~14포인트 개선하면서 출력 토큰을 약 20% 줄인다는 것을 보여 줬다. 그건 위협이 아니다. 공짜 R&D다.
어떤 벤더도 경쟁사 모델을 위해 하네스 최적화를 해 주지 않는다. Anthropic은 Grok을 위해 튜닝하지 않을 것이다. xAI는 Gemini를 위해 튜닝하지 않을 것이다. OpenAI는 Claude를 위해 튜닝하지 않을 것이다. 하지만 오픈소스 하네스는 모두를 위해 튜닝한다. 기여자들이 서로 다른 모델을 쓰고, 자신이 직접 겪는 실패를 고치기 때문이다.
모델은 해자(moat)다. 하네스는 다리(bridge)다. 다리를 불태운다는 건, 건너려는 사람이 줄어든다는 뜻일 뿐이다. 하네스를 해결된 문제로 취급하거나, 심지어 중요하지 않다고 여기는 것은 매우 근시안적이다.
나는 게임 보안 배경에서 왔다. 치터는 생태계를 크게 파괴한다. 물론 그들은 밴 당하고, 쫓기고, 소송도 당하지만, 널리 알려진 비밀이 하나 있다. 결국 보안팀은 “좋아! 그거 어떻게 우회했는지 우리에게 보여 줄래?”라고 묻고, 그들은 방어 팀에 합류한다.
누군가 네 API를 건드리고, 그 도구로 의미 있는 팔로잉을 모으는 데 성공했을 때 올바른 대응은 “더 말해줘”이지, “수천 명 단위로 일괄 밴하고; 풀고 싶으면 DM으로 빌어봐(근데 그건 또)ㅋㅋ”가 아니다.
하네스 문제는 실재하고, 측정 가능하며, 지금 당장 혁신 레버리지가 가장 큰 지점이다. “멋진 데모”와 “신뢰할 수 있는 도구”의 간극은 모델 마법이 아니다. 도구 경계에서의 세심하고, 꽤 지루한, 경험적 엔지니어링이다.
하네스 문제는 해결될 것이다. 질문은 그것이 한 회사에 의해, 비공개로, 한 모델만을 위해 해결되느냐, 아니면 커뮤니티에 의해, 공개로, 모두를 위해 해결되느냐다.
벤치마크 결과가 스스로 말해 준다.
All code, benchmarks, and per-run reports:oh-my-pi