상태 기반 생성, 결정적 시뮬레이션 테스트, 그리고 시간축에서의 결함 국소화를 통해 축소를 다시 바라보는 글입니다.
무작위 테스트는, 고립해서 보면, 멍청한 아이디어다. 가능한 입력이 사실상 무한한 프로그램을 가져다 놓고, 그 무한한 가능성들 중 하나를 무작위로 골라 프로그램이나 프로그램에 대한 어떤 단언을 깨뜨리기를 기대한다. 그런데 이것이 실제로, 가장 순진한 형태에서도, 즉 본질적으로 다음과 같은 루프만으로도 작동한다(버그를 발견한다):
while True:
input = generate_random_input()
if not property(input):
report_bug(input)
세월이 흐르면서 사람들은 내가 설명한 이 순진한 형태에 대해 여러 가지 개선책을 만들어 냈다. 가장 유명한 예는 커버리지 가이드이며, 이것은 지난 10년 동안 퍼즈 테스트의 부상을 이끌었고, 시스템 전반에 걸쳐 수천, 어쩌면 수백만 개의 서로 다른 버그를 찾아냈다. 커버리지 가이드에서는 무작위 입력이 테스트 대상 시스템의 코드 커버리지를 늘리는 입력 쪽으로 편향되며, 그 결과 입력 공간을 더 잘 탐색하게 된다. 수정된 루프는 다음과 같다:
pool = initialize_pool()
while True:
input = mutate(select_from_pool(pool))
if not property(input):
report_bug(input)
if increases_coverage(input, pool):
pool.add(input)
우리가 점점 더 많은 버그를 발견하면서, 버그를 찾는 것만으로는 충분하지 않다는 점이 점점 더 분명해졌다. 누군가는 그 버그들을 검증하고 수정해야 한다. 따라서 “반례”, 즉 주장된 버그를 유발하는 입력은 읽기 쉽고, 살펴보기 쉬우며, 다루기 쉬워야 한다. 이상적으로는 테스터가 가능한 한 가장 단순한 형태의 입력을 받아야 하며, 잡음은 제거되고, 버그를 재현하고 결국 수정하는 데 필요한 최소한의 구조만 제공해야 한다. 이 해법은 서로 다른 이름으로 등장했지만 형태는 비슷했는데, minimization, delta-debugging, 혹은 shrinking이 그것이다.
축소는 한 번 듣는 즉시 납득이 되는 아이디어들 가운데 하나다. 예를 들어 어떤 프로그램에 대한 무작위 입력을 생성했다고 하자. 이미지 처리기를 위한 무작위 PNG 이미지일 수도 있다. 시스템의 어떤 부분에서 버그가 유발되면, 우리는 그 입력을 다시 유발하는 가능한 한 가장 단순한 PNG를 얻고 싶다. 이를 위해 몇 가지 단순화 절차를 정할 수 있다. 각 픽셀을 독립적으로 흐리게 만들어 그림을 더 어둡게 하고, 가능한 한 많은 픽셀을 #000000으로 만들 수 있다. 이미지를 잘라내어 이미지의 일부를 완전히 제거할 수도 있다. 알고 보면 이런 단순화는 많은 경우 값을 더 작게 만드는 것과 같다. 예를 들어 이미지 크기를 줄이거나, 픽셀을 가장 작은 16진 색 표현인 흰색으로 수렴시키는 식이다. 그래서 이름이 _shrinking_이다. 축소에서는 버그를 유발하는 입력 사례에서 시작해서, 더 작은 입력이 여전히 버그를 다시 유발하는 한 입력의 더 작은(축소된) 버전을 반복해서 만들어 낸다. 더 작은 사례를 찾지 못하면 원래 입력을 사용자에게 보고한다.
버그를 유발하는 어떤 입력 I가 주어졌을 때, 축소 함수 shrink(I) -> [I_1, I_2...I_n]를 정의할 수 있고, 축소 알고리즘의 한 버전을 다음과 같이 쓸 수 있다:
def shrink_input(input):
for smaller_input in shrink(input):
if triggers_bug(smaller_input):
return shrink_input(smaller_input)
return input
여기서 시간성이 등장한다. 무작위 테스트를 바라보는 기본 관점은 이것이 처음부터 많은 입력을 만들어 낸다는 것이다. 허공에서 PNG를 만들어 낼 수도 있고, 균형 잡힌 이진 트리를 생성할 수도 있고, 네트워크 토폴로지를 만들 수도 있고, 가상 물리 환경을 구성하거나 문법 오류가 있는 텍스트를 쓸 수도 있다. 모두 도메인에 따라 달라진다. 하지만 처음부터 입력을 생성하는 것이 선택지가 아닌 시스템도 많다. 예를 들어 완전히 올바른 형식의 SQLite 데이터베이스 전체를 처음부터 생성한 뒤, 그 데이터베이스에 대한 SQL 질의를 또 생성해서, 단순한 질의 하나의 결과만 테스트할 수는 없다. 그래서 이런 복잡한 구조를 처음부터 생성하려 하기보다, 무작위 테스트는 대체로 _상태 기반 생성_을 사용하는 쪽으로 수렴해 왔다. 상태 기반 생성에서는 무작위 테스트에 시간의 개념을 추가한다. 우리는 시간 t=0에서 초기 상태 S_0로 시작하고, 시스템의 API를 바탕으로 상호작용을 생성한다. SQL 데이터베이스라면 SQL 문이 될 수 있고, 키-값 저장소라면 insert, delete, get 같은 것들이다.
각 상호작용이 끝날 때마다 시스템의 상태는 바뀔 수도 있고, 이는 우리가 다음에 생성할 입력에 영향을 준다. 운이 좋다면(시스템 자체가 물리적 시간의 영향을 받지 않는다면), 모든 행동은 또 하나의 틱이 되어 t=0,1,2...n으로 진행하다가 버그를 발견하게 된다. 논리적인 다음 단계가 축소라는 것은 이미 알고 있다. 하지만 이런 행동들은 서로 선형적인 의존성을 가질 수 있고, 모든 행동이 유효하기 위해 앞선 모든 행동에 의존할 수도 있는데, 이런 행동들을 어떻게 축소할까? 아래는 그런 의존성 사슬의 예시다:
CREATE TABLE t0 (c0, c1);
INSERT INTO t0 VALUES (0, 0), (1, 1), (2, 2);
SELECT FROM t0 WHERE c0 >= 1; -- @bind r
-- @assert r = (1, 1), (2, 2)
여기서 묘사된 언어는 SQL에 중간 질의 결과를 바인딩하고 그에 대한 사실을 단언하는 기능을 조금 덧붙인 것이다. 이 특정 예시는 포함 단언을 보여 준다. 검색했을 때 우리가 삽입한 값들이 발견되기를 기대한다. 상태 비저장 경우의 PNG에서 했던 것과 비슷하게 이 구조의 일부를 제거하려고 하면, 테스트를 무효로 만들어 버릴 수 있다. 첫 줄(CREATE TABLE...)을 제거하면, 그 뒤의 모든 상호작용이 실패할 것이라 예상하게 되고, 따라서 단언도 실패하겠지만, 테스트 자체가 무효가 된다.
이 상황에 대한 몇 가지 해법이 있는데, 그 첫 번째는 현재 손에 쥔 입력을 슬라이싱해서 축소를 제한하는 것이다. 다음과 같은 대안적 상호작용 시퀀스를 보자:
CREATE TABLE t0 (c0, c1);
CREATE TABLE t1 (c0, c1, c2); -- (2)
INSERT INTO t0 VALUES (0, 0), (1, 1), (2, 2);
INSERT INTO t1 VALUES (NULL, 'why', 'not'); -- (4)
SELECT FROM t1 WHERE c0 != 1 OR c1 != 'how'; -- (5)
SELECT FROM t0 WHERE TRUE; -- (6)
SELECT FROM t0 WHERE c0 >= 1; -- @bind r
-- @assert r = (1, 1), (2, 2)
우리는 이 프로그램을 2개의 부분으로 나눌 수 있다. 실패와 관련 있는 부분과 관련 없는 부분이다. 물론 이 관련성은 휴리스틱이다. 관련 없어 보이는 것이 사실은 우리가 보는 실패의 원인일 수도 있으므로, 우리의 가정이 타당한지 반드시 확인해야 한다. 내가 여기서 사용할 슬라이싱 휴리스틱은 테이블 기반 슬라이싱으로, 실패한 단언과 관련된 테이블과의 상호작용만 신경 쓴다. r은 t0에 대한 질의로 계산되므로, 우리는 t0를 읽거나 쓰지 않는 모든 상호작용을 제거한다. 위 예시에서는 이 슬라이싱을 통해 t0가 아니라 t1만 언급하는 질의 (2), (4), (5)를 제거할 수 있다. 또 다른 휴리스틱은 가능한 한 많은 읽기 연산을 제거하는 것이다. 읽기 연산은 (바라건대) 데이터베이스 상태에 영향을 주지 않으므로, 질의 (6)도 제거할 수 있게 된다. 슬라이싱 후에는 훨씬 더 작은 원래 예시만 남게 된다.
하지만 우리는 또 다른 종류의 축소를 할 수도 있다. 시간적 생성을 그것이 강제하는 제약을 억지로 우회하려 하지 않고, 오히려 그것을 활용하는 방식이다. 무엇을 하느냐고? 시간 여행을 한다!
버그를 유발한 큰 구조에서 축소를 시작하는 대신, 애초에 그 구조를 만들어 낸 무작위 시드에서 시작한다. t=0에서 입력 생성을 시작하되, 시간의 어느 지점 t=j에서 우리의 결정을 조작해 더 작은 입력을 생성한다. 여기서 주의할 점은 t=j 이후 우리가 취하는 모든 행동이 이제 달라질 가능성이 있다는 것이다. 우리는 시간을 거슬러 올라가 과거를 바꾸었고, 그 지점 이후의 모든 미래 결정에 영향을 주었기 때문이다. 이 접근의 좋은 점은 생성기가 원래 지키던 불변조건을 보존한다는 것이다. 우리는 실제 축소를 수행한 것이 아니라, 생성 과정이 더 작은 구조를 만들어 내도록 조작했을 뿐이기 때문이다.
재현기를 사용해 결함이 계속 발생하는지를 감지하면서 큰 구조에서 더 작은 구조로 가는 첫 번째 접근은 보통 external 또는 type-based shrinking이라고 불리지만, 나는 이것을 structural shrinking이라고 부르는 편이 좋다. 두 번째 접근은 internal 또는 integrated shrinking이라고 부른다. Property-Based Testing 라이브러리들은 보통 어떤 축소 방법론을 택하느냐에 따라 나뉜다. Hypothesis는 유명하게도 uses integrated shrinking을 사용하고, 많은 QuickCheck 계열 라이브러리들은 structural shrinking을 사용한다.
DST로 넘어가 보자. integrated shrinking과 structural shrinking에 대한 논의는 길고도 긴 주제이며, 지금 여기서 어느 한쪽 편을 들 생각은 없다. 하지만 구조적 축소가 사실상 선택지가 아닌 무작위 테스트의 특별한 변종이 있다. 바로 _결정적 시뮬레이션 테스트_다. 이 글에서는 DST의 아주 구체적인 세부사항까지 들어가지는 않겠다. 이미 Phil의 블로그 글 같은 훌륭한 자료가 충분하다고 생각한다. 간단히 말해 DST는 시스템에서 시간의 개념을 제거할 수 없는 경우에 필요한 것이다. 즉, 앞 절의 가정을 어기는 경우다. 특히 분산 시스템이나 동시성 프로그램에서는 물리적 시간이 시스템 동작의 중요한 일부인 경우가 많고, 이를 추상화해 없앨 수 없다. 물리적 시간을 다뤄야 한다. 이런 경우에는 입력을 순진하게 축소할 수 없다. 대부분의 경우 애초에 그것들을 재현조차 할 수 없기 때문이다. 시간을 인지하는 시스템을 테스트할 때 동일한 상호작용 시퀀스를 두 번 실행한다고 해서 같은 출력이나 결과가 보장되지 않으며, 하물며 그것들을 바꿨을 때 오류가 유지되는 것은 더더욱 아니다.
DST에서는 실행 계층이 완전히 결정적이므로, 물리적 시간과 효과가 시스템에서 추상화된다. 그래서 테스트는 완벽하게 재현 가능해진다. 이것은 엄청나게 좋은 일이다. 이전에는 디버그할 수 없었던 버그도 정확히 같은 상호작용 시퀀스를 재현할 수 있으므로 디버그할 수 있게 되고, 악명 높은 Heisenbug의 고통을 해결해 주기 때문이다. 하지만 정말 그럴까? 완벽한 재현 가능성의 핵심 문제는 시간성 때문에 시스템에서 아무것도 바꿀 수 없다는 점이다. 시간을 거슬러 올라갈 수는 있지만 아무것도 바꿀 수 없고, 오직 관찰만 할 수 있다. 무언가를 바꾸는 순간, 그 다음의 모든 결정은 통제 밖으로 벗어나므로, 그 변화가 정확히 어떤 영향을 주는지 알 수 없게 된다. 정말로 버그를 고친 것인가, 아니면 스케줄러가 그저 다른 선택을 해서 버그가 사라진 것인가?
현재 DST를 개척하고 있는 회사 Antithesis의 엔지니어들은 이 문제를 극복하기 위한 아주 멋진 방법을 찾아냈다. 나는 이것을 시간적 축소, 혹은 좀 더 정확히는 시간적 결함 국소화라고 부르고 싶다. 아이디어는 다음과 같다:
어떤 시간 길이에 걸쳐 이어지는 입력 시퀀스, 즉 시간적 테스트가 있다. 앞서 말했듯이, 시간의 어느 지점에서든 어떤 결정이든 바꿀 수 있고, 그러면 그 시점 이후의 거의 모든 것에 영향을 줄 수 있다. 시간의 임의의 지점 j_0, j_1...j_k에서의 몇몇 결정들이 버그의 유발 조건이라고 가정해 보자. 만약 t=j_k 이후의 어떤 것이든 바꿨을 때 버그 재현이 바뀌지 않는다면, j_k 이후의 결정 100%는 모두 무관해야 한다. 따라서 우리는 시간의 임의 지점을 골라 그 지점의 결정을 바꾸고, 그것이 이후에 발견되는 버그의 비율에 어떤 영향을 주는지 확인할 수 있다. 아주 희귀한 버그, 즉 j_0...j_k 조건에서만 재현되는 버그의 경우, j_0...j_k 중 어느 하나라도 바꾸면 재유발 비율은 0%가 될 것이다.
이 재유발 비율이라는 핵심 아이디어를 통해 Antithesis는 버그를 시간적으로 국소화할 수 있고, 버그가 다시 유발되는 데 결정적인 시간상의 핵심 조각들을 식별할 수 있다. 이는 궁극적으로 축소의 한 형태이므로 이 글의 제목이 그렇게 붙은 것이다. 또한 긍정 입력과 부정 입력의 차이를 식별하는 spectrum based fault localization 기법의 후손처럼 느껴지기도 하는데, 다만 그것을 시간의 영역으로 옮겨 놓은 셈이다.
이 능력 위에 구축할 수 있는 잠재적 분석은 아래에 보인 다음과 같은 버그 확률 그래프로 이어진다. 그래프를 생성하는 계산의 정확한 세부사항과 그래프 결과를 해석하는 방법은 Antithesis docs에서 확인할 수 있다.
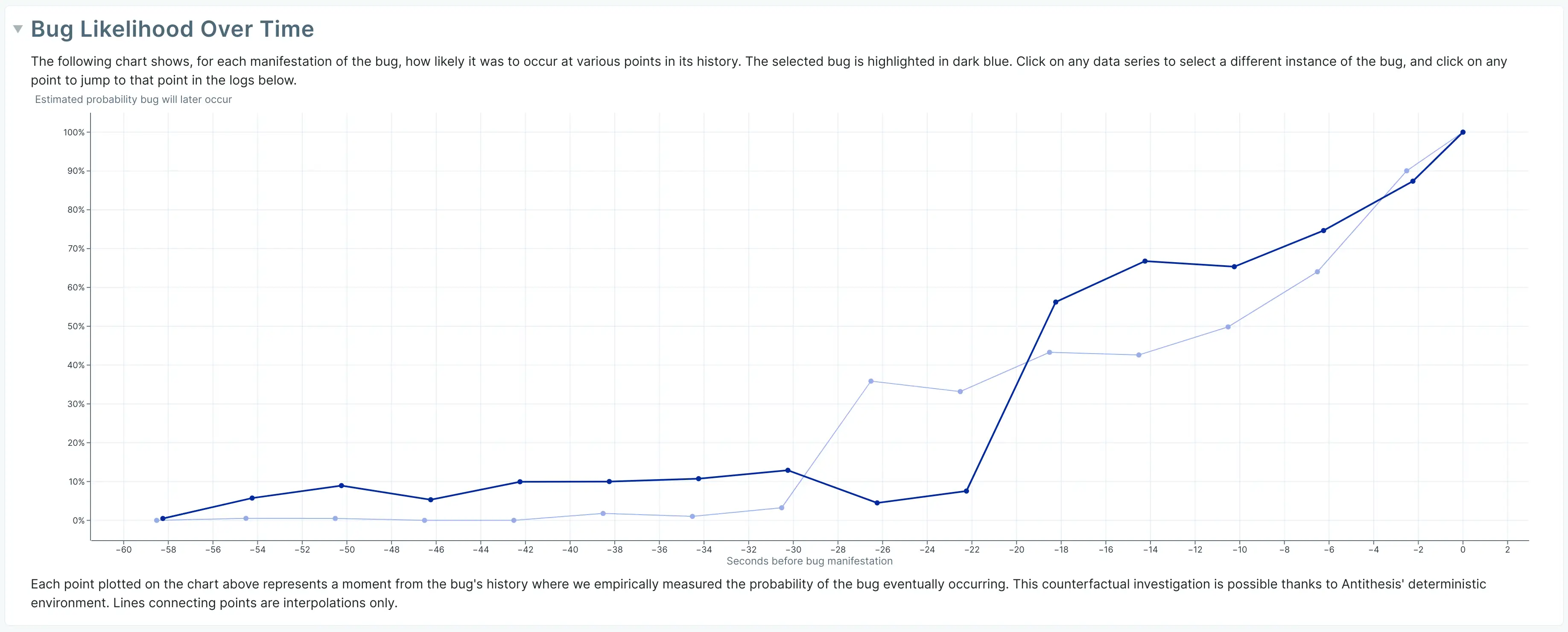
나는 Antithesis와 소속 관계가 있는 것은 아니라는 점을 밝혀 두고 싶다(다만 여러 주제에서 협업하고는 있다). 그리고 시간적 축소는 Antithesis에만 한정된 것이 아니라, 어떤 결정적 시뮬레이션 환경에도 적용 가능하다. 내 생각에 몇 년 안에 우리는 Shuttle이나 Fray 같은 동시성 테스트 라이브러리 위에 구축된 비슷한 도구들을 보게 될 가능성이 크다. 이들은 비슷한 설계 공간에 있고, 축소와 디버깅에 관한 동일한 과제를 안고 있기 때문이다.