TCP의 동작에 대한 오해를 바로잡고, 슬로 스타트·흐름 제어·혼잡 제어의 차이를 설명합니다. Linux 기본인 CUBIC의 원리와 영향, QUIC의 특징, 지연 기반 접근인 BBR의 가능성과 공존 이슈를 통해 대용량 전송 성능에 무엇이 실제로 영향을 주는지 정리합니다.
TCP 혼란 해소: 혼잡 제어, CUBIC, QUIC, BBR
2017-06-30
개발자와 네트워크 엔지니어들에게서 가끔 TCP 혼잡 윈도(cwnd) 크기에 대한 이야기를 듣습니다. 사람들은 sliding window 알고리즘, ACK 기반 윈도 증가(slow start), 그리고 RTT가 크면 대용량 다운로드 성능이 나빠질 운명이라는 잡담을 하곤 합니다. 맞아요, 폰에서 설치 버튼을 눌러 빠른 다운로드를 기대했는데, 빙하처럼 느린 다운로드를 마주하면 TCP 매개변수에 뭔가 문제가 있어 보이고, TCP를 열어 튜닝해야 할 때처럼 느껴지죠. 하지만 그 유혹은 잘못된 것이고, 평균적인 엔지니어가 가할 수정들을 들으면 오히려 겁이 날 겁니다.
놀랍게도 대부분의 엔지니어가 TCP가 실제로 어떻게 동작하는지에 대해 제대로 아는 바가 별로 없다는 걸 알게 됐습니다. 많은 엔지니어가 sliding window와 ack-pacing에 대해 조금 알고 있고, 나머지는 오해와 혼란입니다. 그러니 준비하세요. 저는 혼란을 줄이고 대용량 TCP 다운로드 전송률에 실제로 영향을 주는 것, 즉 CUBIC에 대해 이야기하려 합니다. 그리고 TCP의 밝은 미래에 대한 희망으로, 지연(레이턴시) 기반 혼잡 탐지 진영에서 나온 CUBIC의 대안 BBR, 그리고 웹을 위한 새로운 전송 프로토콜 QUIC도 함께 이야기하겠습니다.
먼저 튜닝에 대한 질문부터. 운영체제의 TCP 매개변수를 건드릴 일이 있을 확률은 낮습니다. 흔한 시나리오로 튜닝이 필요할 수 있는 경우는 두 가지뿐입니다. 1. 데이터센터에서 저지연 환경을 위해 Data Center TCP를 도입하려는 경우. 2. 10Gig+ 링크를 사용하며 운영체제의 고용량 링크 자동 튜닝을 신뢰하지 못하는 경우. 이 둘을 제외하면, 시스템이 기본 제공하는 튜닝이 탄탄하다고 믿는 게 좋습니다. 왜냐하면 TCP는 ARPA/인터넷의 역사 전체에 걸쳐 엔지니어들이 꾸준히 다듬어 왔고, 모두가 TCP의 올바른 동작이 정말 중요하다는 데 동의하기 때문입니다.
1986년, 인터넷이 아직 정부가 운영하던 시절 TCP가 어렸을 때, 엔지니어들은 나쁜 TCP 동작과 네트워크에 대해 배워가고 있었습니다. 그때 TCP에는 congestion control(:-!)이 없어, 때때로 인터넷의 큰 구간이 "붕괴"하곤 했습니다. 클라이언트는 상대 단말의 처리 용량(flow control)은 존중하도록 프로그래밍되어 있었지만, 네트워크의 용량은 고려하지 않았습니다. 마치 심판에게 화가 난 농구팀처럼, 클라이언트는 과부하가 걸린 로컬 라우터에 계속해서 재전송을 퍼부었고, 극소수의 패킷만 통과하는데도 전혀 자제하지 않았습니다. 1986년 특히 심각했던 사건에서는, 엄청난 혼잡 아래 NSFNET 백본 링크들이 정격 32kbps 용량의 1/1000에 불과한 40bps만 전달했습니다. 인터넷은 혼잡 붕괴를 겪고 있었습니다. 혼잡 붕괴의 해법은 TCP에 congestion control과 Jacobson과 Karels의 slow start 알고리즘을 주입하는 것이었습니다1.
이전의 TCP에는 "윈도"가 하나뿐이었습니다. 각 클라이언트는 상대가 선로에서 읽어갈 준비가 된 바이트 수(receive window)를 추적했습니다. 클라이언트가 데이터를 받을 준비가 되어 있지 않으면 송신자는 보내지 않았습니다(어차피 전송분이 폐기되고 재전송해야 하니까요). 1986년의 붕괴가 증명했듯 receive window만으로는 충분하지 않았습니다. 그때도 지금처럼 TCP 연결의 제약은 시스템의 메모리나 처리능력이 아니라 네트워크 용량이었습니다. 네트워크가 혼잡 붕괴로 들어가는 동안에도 receive window는 활짝 열려 있었죠! Jacobson과 동료들은 또 하나의 윈도, 즉 현재 혼잡(그리고 붕괴) 위험 없이 안전하게 전송할 수 있는 바이트 수를 규정하는 congestion window를 도입했습니다. 송신자는 receive window와 congestion window를 모두 참조해, 둘 중 더 제한적인 쪽이 허용하는 만큼의 패킷만 전송합니다.
새 TCP 스트림이 시작될 때, 그 링크가 얼마나 큰지 알 수 없습니다. 처리량이 1kbps일 수도, 10Gbps일 수도 있죠. 혼잡 제어는 링크 용량을 찾아내 붕괴를 막아야 하고, 동시에 빨리 찾아야 합니다(속도를 올리는 데 시간을 다 써버리고 싶지 않으니까요). Jacobson과 동료들은 ACK 하나를 받을 때마다 패킷 2개를 더 풀어주는, 지수적으로 성장하는 방식을 택했습니다. 모두를 혼란스럽게 하듯, Jacobson은 이 지수 성장을 slow start라고 명명했습니다. 고마워요, Jacobson2.
여기서 "튜닝파"를 변호하자면, initial_cwnd(초기 혼잡 윈도)를 조정하면 slow start가 속도를 올리는 데 걸리는 시간에 영향을 주는 건 사실입니다. 시작점을 2^(1+n) 대신 2^(4+n)로 점프시키면 큰 cwnd에 더 빨리 도달하죠. 그래도 튜닝할 가치가 크진 않습니다. 맞습니다, slow start는 RTT에 의해 페이싱되므로 RTT가 큰 사용자를 약간 불리하게 만듭니다. 하지만 현재(Linux) 기본값인 10개 패킷의 initial_cwnd로도, TCP는 14 사이클 안에 122Mbps까지 성장합니다. RTT가 100ms면 1.4초로, 대용량 다운로드 전체에서 보면 긴 시간이 아닙니다3. (10GigE 같은 고용량 링크의 경우, 대부분의 OS가 TCP 매개변수를 자동으로 조정합니다.)
대용량 다운로드에 튜닝이 소용없는 또 다른 이유: 다운링크의 initial_cwnd와 congestion control을 제어하는 건 서버의 TCP 인스턴스입니다. S3든 CDN이든 앱 스토어든, 대부분의 경우 서버를 당신이 튜닝할 위치에 있지 않죠. (또 잊지 마세요, CDN은 빠른 전송이 생업입니다. Akamai에 TCP 구현을 튜닝하는 성능 엔지니어가 없을 거라 생각했다면 큰 오산입니다.)
initial_cwnd를 만지게 부추기는 또 다른 오해는, slow start와 ACK 트리거 2^x 성장(ACK 페이싱)이 TCP 전송률의 주된 동인이라는 것입니다. 전혀 아닙니다. Slow start는 시작 공연일 뿐, 그보다도 덜합니다. 대부분의 시간 동안 TCP는 congestion avoidance 단계에 있으며, CUBIC 같은 알고리즘이 고삐를 잡고 있습니다. 대용량 다운로드의 변덕을 탓할 이름을 찾는다면, slow start나 ACK-pacing을 탓하지 말고, CUBIC을 탓하세요! (그리고 곧 칭찬도 하세요. 정말 정말 훌륭한 물건이니까요.)

그 오해들을 접어두고 TCP로 돌아갑시다. 파충류의 뇌가 포유류의 뇌 아래에 깔려 있다는 비유처럼, 위 그림의 우리의 TCP 스트림은 ACK 페이싱된 지수 성장(slow start)으로 시작해, 링크를 압도해 손실을 일으킬 때까지(그림의 첫 번째 봉우리) 진행됩니다. 그러면 Jacobson과 동료들의 포유류의 뇌, congestion control이 접수해 스트림을 관리합니다(연결의 남은 전부 동안!). Congestion control의 지침은 이렇습니다: 링크 용량 부근에서 동작할 것, 용량 변화에 반응할 것, 붕괴를 막을 것, 다른 스트림과 공평하게 공존할 것.
1988년에 우리의 포유류 뇌 congestion control은 Jacobson의 새 알고리즘 Tahoe였을 것입니다. Tahoe는 큰 진전이었지만, 여기서는 Tahoe 대신 현대의 congestion control 알고리즘이자 Linux 커널의 기본인 CUBIC을 설명하겠습니다.
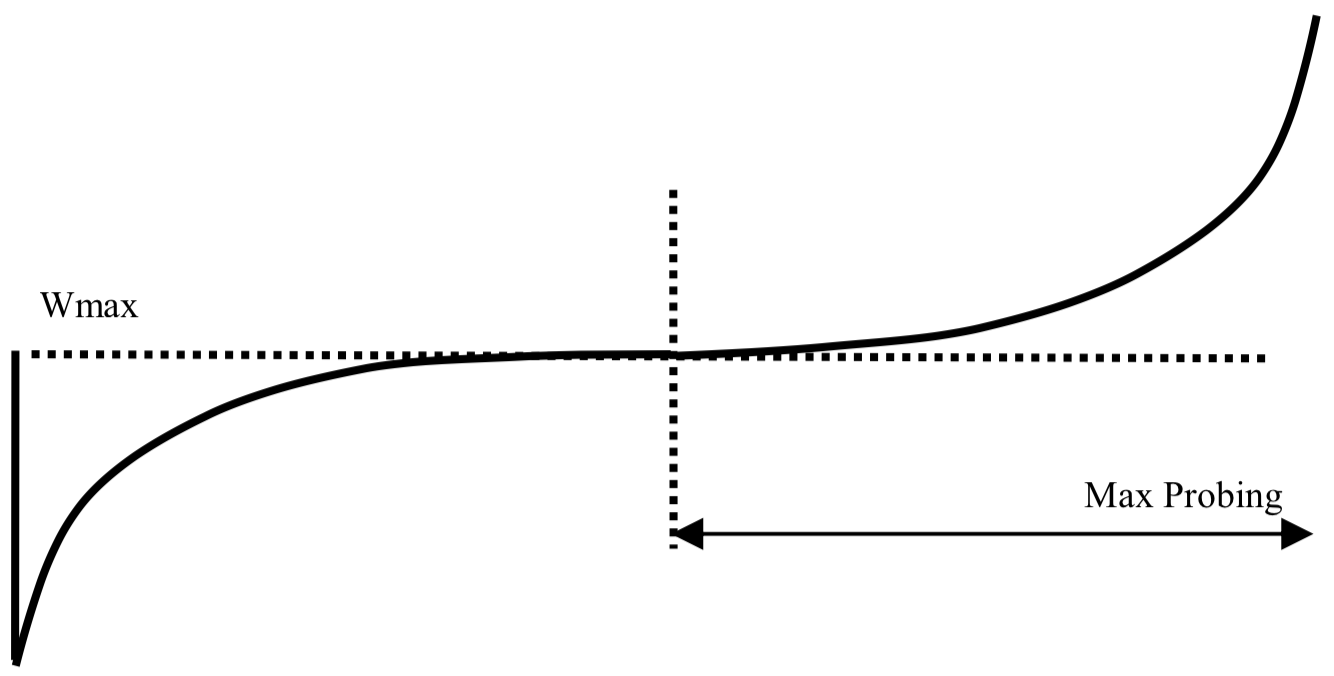
TCP-포유류-브레인 CUBIC이 지휘를 잡으면, TCP가 링크를 압도했던 시점의 cwnd 값인 W_max를 알고 있습니다. CUBIC은 실제 링크 용량이 W_max 근처 어딘가에 있다고 가정할 수 있습니다. 더 큰 관점에서 CUBIC은 알려진 링크 용량을 최대한 활용하고, 가끔은 이 "안전한" 처리량을 넘어 링크 용량이 증가했는지 탐색하고 싶어합니다. 그 "공식"이 아래에 보이는 3차(cubic) 함수입니다. CUBIC은 손실이 나면 0.8*W_max로 후퇴한 다음, 변곡점(평평한 부분)을 W_max에 두고 이 3차 곡선을 그립니다. 위 그림을 보면, 처음 세 봉우리는 변곡점 근처에서 중단된 3차 함수입니다. 상어 지느러미처럼 보이죠. 마침내 네 번째 사이클에서 용량이 증가해 스트림이 변곡점(W_max)을 지나 3차 함수의 "최대 탐색(max probing)" 영역으로 들어갑니다. 선명한 3차 곡선 형태가 나타납니다. 몇 번의 상어 지느러미 사이클을 더 거친 뒤, 이런 성장이 반복됩니다.
이 3차 형태는 최적화를 위한 것입니다. 최대 처리량(W_max 주변의 어느 지점) 아래에서 보내는 시간은 낭비니까요. CUBIC은 빠르게 성장해 W_max를 "바짝 붙어(hug)" 따라갑니다. 가까워질수록 성장이 완만해집니다. 비교하자면 예전 congestion control 알고리즘 Reno는 톱니파형(sawtooth)으로, CUBIC처럼 최대 처리량을 가까이서 붙들지 못합니다.
이제 위 cwnd 그래프의 오른쪽에서 이상한 일이 벌어집니다. 점선 빨간색으로 표시한 부분은 CUBIC이 변곡점(3차 함수의 평평한 부분)을 W_max보다 아래에 둔 곳입니다. CUBIC에는 Ha 등원 논문 이상의 내용이 있습니다. 수렴(여러 스트림이 네트워크 자원을 공평하게 나누는 상태에 도달하는 시간) 문제를 다루기 위해, Linux는 처리량이 감소하는 것으로 보일 때(W_max_prev > W_max) 변곡점을 0.9*W_max에 둡니다. 정상 상태에서는 Linux CUBIC이 W_max와 0.9*W_max 사이를 번갈아 오가는 사이클을 갖습니다.
아래에서 Linux CUBIC과 Ha의 원래 CUBIC을 볼 수 있습니다. Ha의 파형은 순수한 상어 지느러미입니다. 예상대로죠. 링크 용량은 오직 감소하므로, 3차 함수가 변곡점을 지나 탐색 단계에 들어갈 기회를 갖지 못합니다. Linux CUBIC의 수정은 매 다른 사이클마다 변곡점을 0.9*W_max에 두므로, 링크 용량이 증가하지 않아도 3차 형태가 나타납니다. 이 때문에 큰 플로우가 짧은 동안 인위적으로 낮게 머물며 작은 스트림이 대역폭을 더 확보하게 되는 상상이 가능할 겁니다. 또한 0.9*W_max 사이클에서는 스트림이 3차 함수의 선형 중심 영역을 지나 성장하기보다 최대 탐색 영역에서 W_max에 접근하므로, 가용 대역폭을 더 공격적으로 집어올릴 수도 있습니다.
TCP CUBIC에는 2008년 CUBIC 논문 이후의 또 다른 개선이 들어 있습니다4. 오늘날 TCP는 흔히 HyStart(Hybrid Slow Start)를 사용합니다. Slow start는 종종 링크 용량을 심하게 overshoot하여 불필요한 혼잡을 유발합니다. HyStart는 패킷 타이밍을 추적해 혼잡의 첫 조짐을 찾고, slow start가 링크를 심각하게 압도할 위험이 있는 수준 sshthresh를 설정합니다. sshthresh를 넘으면 스트림은 congestion control(여기서는 CUBIC)로 전환합니다.

RTT에 대한 중요한 메모. CUBIC의 트래픽 제어는 RTT와 독립적입니다. 엔지니어들이 TCP 전송 문제의 원인으로 RTT를 탓하는 것을 듣지만, CUBIC은 사실 ACK/RTT가 아닌 시간에 의해 페이싱됩니다. 시간만으로 cwnd를 조정하면 다양한 RTT에서 CUBIC이 더 좋은 성능을 냅니다5.
Next: QUIC
좋아요, slow start가 내 전송 문제의 주범은 아니고, flow control도, ACK 페이싱도 아니군요. 그래도 TCP가 CUBIC 같은 점진적 개선을 거쳤음에도, 대용량 전송에서 항상 일관되지는 않습니다. 희망 좀 줘보세요, 상황은 어떻게 개선되고 있나요?
수평선 위로 유망한 새 프로토콜이 등장했습니다. 구글의 QUIC입니다. 하지만 QUIC이 모든 것을 바꿀 기막힌 새 프로토콜이라고 믿기 전에, 미안하지만 QUIC은 만병통치약이 아니고, 아마 대용량 전송에는 큰 도움이 되지 않을 겁니다.
뭐든 재설계해서 개선할 수 있음을 증명하려는 영원한 시도 속에서, 구글러들은 새로운 신뢰성 전송++ 프로토콜 QUIC을 만들었습니다. QUIC은 TCP+TLS+HTTP/SPDY의 대안으로, 더 빠른 핸드셰이크(특히 TLS), 헤드-오브-라인 블로킹 없는 스트림 멀티플렉싱, IP 주소 마이그레이션 중 지속성, 헤더 압축 등 많은 개선을 담고 있습니다. QUIC의 효과는 TCP+TLS+HTTP/SPDY의 여러 성능 문제를 해결해 웹 탐색을 빠르게 하는 것입니다. 어떤 이들은 QUIC이 TCP의 후계자라고 말하지만 사실이 아닙니다. QUIC은 TCP+TLS+SPDY를 하나로 통합하고 더 똑똑하게 만든 진화판입니다.
대용량 전송에서, QUIC이 TCP 대비 갖는 장점은 무엇일까요?
재전송된 패킷에 새 시퀀스 번호를 부여해,
QUIC이 재전송과 지연된 패킷을 구분할 수 있습니다.
QUIC은 RTT를 추적하고, TCP가 재전송 요청을 기다리는 대신, RTT 기반 시간 임계를 넘어선 패킷을 손실로 선언합니다.
QUIC은packet pacing을 사용할 것으로 예상됩니다(버스트 전송을 시간 간격으로 나눠 버퍼 과부하를 피함).성능에 반드시 도움이 되지는 않지만,
QUIC은 IP 주소가 바뀌어도 연결을 지속할 수 있습니다.
어떤 이들은 전진 오류 정정(FEC)을 QUIC의 장점으로 꼽기도 합니다. 안타깝게도 오픈소스 QUIC 구현은 FEC를 사용하지 않으며, QUIC의 초기 버전이 FEC를 포함할 가능성도 낮아 보입니다. 그래서 현재로서는 FEC가 장점이 아니며, 미래에는 그럴 수 있습니다. 또한 QUIC의 헤드-오브-라인 블로킹 개선은 다중 스트림 연결에만 해당하므로 여기서는 제외합니다.
그렇다면 대용량 전송에서 QUIC은 어떤 성적을 내나요? 엇갈립니다. RTT 160ms 환경의 비공식 테스트에서는, TCP가 손실률과 RTT 전반에서 QUIC보다 좋은 성능을 보였습니다. 반면 Carlucci 등은 패킷 손실이 증가할수록 QUIC이 TCP를 앞섰다고 보고했습니다. 다만 Carlucci 논문은 테스트베드의 RTT를 언급하지 않습니다. RTT가 1ms 같은 매우 작은 값이었다면, 그 결과는 현실 세계를 대표하지 못해 유효성이 떨어진다고 보겠습니다(QUIC은 RTT가 낮을수록 성능이 좋은 경향). 그래서 현재 테스트들만 보면 명확하지 않습니다. 그러나 앞서 경고했듯, 대용량 전송에 한해서 QUIC이 TCP를 압도적으로 개선한다는 인상은 받기 어렵습니다.
흥미롭게도, 현재 TCP 성능의 핵심 요소인 CUBIC 혼잡 제어 알고리즘이 QUIC에도 들어 있습니다. CUBIC은 현재 QUIC의 기본 congestion control 알고리즘입니다. 멋지긴 한데, 제 생각엔 QUIC이 packet pacing과 CUBIC을 동시에 잘 활용할 수 있을지 의문이 들기도 합니다.
CUBIC이 QUIC의 키를 잡고 있는 이상, 대용량 전송에서는 QUIC은 TCP의 혁명이라기보다 재구현에 가깝습니다. (공정하게 말하면, 웹/웹 애플리케이션 분야에서는 QUIC이 더 혁명적입니다.)
Next: BBR
다행히, QUIC과 TCP CUBIC을 모두 능가할 수 있는 또 다른 기술이 있습니다. 바로 BBR입니다.
지금까지 언급한 CUBIC과 congestion control은 혼잡의 신호로 패킷 손실을 사용합니다. 하지만 더 나은 방법이 있을 수 있습니다. 링크의 지연 변화를 모니터링하는 것입니다.
아래 그림을 보세요. 패킷 네트워크에서 처리량이 용량보다 낮으면 라우터 버퍼는 가볍게만 사용되고 지연이 낮습니다. 그러나 처리량이 용량에 가까워지면 버퍼가 차기 시작합니다. 버퍼는 트래픽 버스트를 완화하지만, 패킷이 대기열에 줄을 서야 하므로 지연이 증가합니다. 마침내 처리량이 용량을 넘어서면, 버퍼가 가득 차고 병목 라우터가 패킷을 드롭할 수밖에 없습니다.
사실 혼잡 지표로 손실에 의존하고 싶지는 않습니다. 버퍼를 채우고 손실을 유발하는 행위는 링크의 유효 처리량(goodput)을 감소시키는 비효율입니다. CUBIC과 다른 알고리즘은 아래 그림의 오른쪽 영역을 탐색하는 데 시간을 씁니다. 이는 손실, 재전송, 낭비를 일으킨다는 뜻이죠. 차라리 그래프의 중간에 머물며 오른쪽을 탐색하지 않는 편이 훨씬 낫습니다. 이것이 지연 기반 congestion control과 BBR의 근거입니다6.

그래서 BBR은 RTT를 모니터링하고, 타이밍에 기반해 패킷이 버퍼링되기 시작했는지 감지하려 합니다. RTT 증가폭이 클수록 패킷이 더 오래 버퍼링되고 있으며, 네트워크가 혼잡으로 들어갈 가능성이 높습니다. 이론적으로 이것은 BBR이 큐를 더 우수하게 활용하고, buffer bloat 문제를 아예 피할 수 있게 해줍니다(패킷 큐잉을 감지해 큐잉이 사라질 때까지 전송률을 낮추면, 깊은 버퍼블로트에 갇히지 않습니다).
이 접근에도 문제가 없지는 않습니다. 또 다른 지연 기반 알고리즘인 Vegas는 다른 알고리즘과 경쟁할 때 네트워크 용량에서 자신의 공정 지분을 주장하지 못합니다. CUBIC 같은 손실 기반 알고리즘이 용량 확장을 탐색할 때, Vegas는 네트워크 큐잉을 감지하고 CUBIC보다 먼저 물러나면서, CUBIC이 처리량의 일부를 빼앗아 가게 둡니다. BBR은 Vegas와 반대의 문제를 보이는 듯합니다. APNIC은 BBR이 15.2ms 링크에서는 CUBIC을 질식시켰고, 298ms RTT 인터넷 테스트에서는 공정 지분보다 약간 더 많이 가져갔다고 밝혔습니다.
사실 BBR은 RTT가 다른 다른 BBR 스트림과의 공존에도 문제가 있는 듯합니다. Shiyao 등은 100Mbps 링크에서, RTT 50ms의 BBR 스트림이 기존 RTT 10ms의 BBR 스트림으로부터 87.3Mbps의 처리량을 빼앗았다고 보고했습니다. 이 불균형은 10Mbps부터 1Gbps까지 다양한 네트워크 용량에서 지속되었고, RTT 50ms 스트림이 평균 88.4%의 용량을 가져갔습니다.
그럼에도 불구하고 구글은 BBR이 매우 성능이 좋다고 봅니다. 구글은 자사 백본 전체에 BBR을 사용하며 처리량 2~20배 향상을 보고합니다. 또한 BBR이 CUBIC 대비 1/2~1/5의 RTT에서 같은 처리량을 달성한다고 주장합니다. 버퍼블로트 환경에서는 RTT가 더 크게 감소한다고 주장합니다.
BBR은 분명 장점이 있습니다. 동시에 BBR은 공존 문제도 있어 보입니다. 구글은 BBR의 공존이 그리 나쁘지 않다고 주장하며, 유튜브에서 사용하는 인터넷 환경이 테스트베드보다 공존성 측면에서 더 유리할 수 있다고 말합니다. 그래도 BBR이 광범위한 도입에 앞서 더 많은 테스트와 개선이 필요해 보입니다.
Fin
그러니 이렇게 정리할 수 있습니다. 앱 스토어 다운로드가 기어갈 때, 부두 인형에 이름을 적어 넣어야 한다면 그 이름은 ack-pacing도, sliding window도, flow control도, slow start도 아닙니다. 그 이름은 CUBIC입니다. 공정하게 말하자면 CUBIC은 훌륭한 일을 합니다. 아마 가장 널리 쓰이는, 가장 견고한 congestion control 알고리즘일 겁니다. 하지만 인터넷 대역폭이 커지고 무선이 더 큰 비중을 차지할수록 TCP는 기대만큼의 성능을 내지 못합니다. TCP는 1980년대의 인터넷 혼잡 붕괴 이후 크게 진화해 왔고, 지금도 진화 중입니다. BBR은 TCP를 더 버퍼-최적에 가까운 처리량으로 운영(그리고 전반적으로 더 나은 성능 제공)하는 데 성공할 수 있습니다. 그리고 대용량 전송을 직접 개선하는 기능은 부족하지만, QUIC도 개선을 거쳐 대용량 전송에서 TCP를 앞지를 수 있습니다.
대용량 다운로드에 관해서는, 미안하지만 앞으로 몇 년은 그냥 감수해야 할 듯합니다(가능하다면 분할하고 병렬로 내려받으세요). 하지만 지평선 위에 유망한 기술들이 보입니다.
흥미진진한 시간이 기다립니다!
Edit: PS4에서의 대용량 다운로드 문제에 대한 재미있는 예. TCP 이슈이고, RTT 이슈이며, 중간에 프록시를 두면 해결된다고요... 아, 사실 RTT 이슈가 아니었네요... 소니가 의도적으로 속도 제한을 걸어둔 겁니다. (이 경우에는 CUBIC을 탓하지 않아도 되겠군요!)
좋습니다, 내용이 많았으니 요약합니다:
flow control, sliding window 알고리즘, slow start, congestion control은 서로 다른 개념이며 TCP에서 다른 역할을 합니다.
flow control은 수신자가 받을 준비가 된 양을 넘겨 보내지 않도록 송신자를 막습니다.
flow control은 수신자로부터 시스템 상태(receive window 공간)에 대한 직접 정보를 받습니다.
네트워크 처리량(용량)이 병목이고 버퍼 공간이 병목이 아닌 경우가 대부분이므로, flow control은 TCP 성능에서 드물게 핵심 역할을 합니다.
TCP의 slow start는 TCP 연결의 부트스트랩에 불과합니다.
대용량 다운로드는 주로 TCP의 congestion control 알고리즘이 좌우합니다.
대부분의 TCP 구현은 hybrid slow start를 사용해, 80~90년대 TCP보다 연결 초기에 더 일찍 congestion control에 지휘권을 넘깁니다.
1980년대 인터넷이 반복적으로 혼잡 붕괴를 겪은 뒤, TCP에 congestion control과 slow start가 추가되었습니다.
congestion control은 네트워크가 감당할 수 있는 양을 넘는 트래픽으로 네트워크를 과부하시키지 않도록 합니다.
congestion control은(ECN을 쓰지 않는 한) 패킷 손실, 지연, 네트워크 변동성 같은 간접적 정보만을 받습니다. 이를 바탕으로 congestion window(cwnd)의 안전한 값을 추론해야 합니다.
congestion control은 다른 네트워크 스트림과 공정하게 공존하도록 설계되어야 합니다.
CUBIC은 가장 널리 사용되는 congestion control 알고리즘이며 Linux의 기본입니다.
CUBIC은 마지막으로 알려진 용량으로 빠르게(x^3) 복귀해 사용 가능한 용량을 활용하며, 상어 지느러미 같은 패턴을 만듭니다(Reno는 톱니 모양).
CUBIC은 ACK 페이싱이 아니라 시간 기반으로 cwnd를 증가시킵니다. 다양한 RTT에서 무난한 성능을 냅니다.
CUBIC은 수렴성을 높이기 위해 용량이 감소하는 듯 보일 때 3차 곡선을 ``0.9*W_max` 중심에 두는 등의 수정을 포함합니다.
내 시스템에서 TCP를 튜닝해도 대용량 다운로드에는 도움이 되지 않습니다. 하행에서는 송신자(서버)가 혼잡 제어를 책임지기 때문입니다.
QUIC은 유망한 TCP+TLS+HTTP/SPDY 대체 프로토콜입니다.
QUIC은 빠른 TLS 핸드셰이크, 헤드-오브-라인 블로킹 없는 스트림 멀티플렉싱, IP 주소 변경 중 지속성, 헤더 압축, 재전송에 대한 증가 식 패킷 번호, RTT 기반 손실 판정 같은 개선을 포함합니다.
초기 버전의 QUIC에는 대용량 전송에 이득이 될 수 있는 FEC, 패킷 페이싱, 고급 congestion control이 포함되지 않을 가능성이 높습니다.
QUIC은 TCP와 같은 CUBIC congestion control 알고리즘을 사용합니다!
당분간 QUIC이 TCP 대비 대용량 전송에서 더 나은 성능을 내기는 어려워 보입니다(현재 벤치마크도 이를 확인합니다).
BBR은 유망한 새 congestion control 알고리즘입니다.
CUBIC 및 대부분의 congestion control과 달리, BBR은 지연(레이턴시) 기반이며 패킷 페이싱을 사용합니다.
BBR은 네트워크 버퍼가 큐잉을 시작하기 직전 수준으로 전송률을 유지하려고 시도합니다.
BBR은 손실 기반 congestion control과 달리, 과대 버퍼/버퍼블로트 환경에서 잘 동작합니다.
구글은 BBR로 큰 성능 향상을 주장하지만, 외부 테스트에서는 이기종 네트워크와 CUBIC과의 공존에 문제가 관찰됩니다.
Note: "max probing" Cubic 그림은 Ha, Rhee, Xu의 원래 TCP CUBIC 논문에서 가져왔습니다.
각주
1
덧붙이자면, 이 혼잡 문제는 단순히 다중 사용자가 몰려서만 일어나는 붕괴가 아닙니다. Jacobson은 두 대의 컴퓨터가 게이트웨이 라우터의 처리량-버퍼보다 7% 더 많은 패킷을 전송하는 시나리오를 테스트했습니다. 게이트웨이 용량의 107%로 지속 전송했을 때, 전송은 177% 더 오래 걸렸고, 전체 시간의 65%를 재전송에 썼으며, 7%의 패킷은 무려 4번씩 재전송해야 했습니다. 그렇습니다, 집에서 Wi‑Fi로 음악을 스트리밍하는 것처럼 단일 사용자, 단순해 보이는 작업조차도 congestion control이 없으면 형편없는 성능을 피할 수 없습니다.
2 사실 Jacobson 등은 전력전자에서의 돌입 전류 제한기와 같은 이름을 따 "soft start"라고 알고리즘을 불렀습니다. John Nagle이 그 이름을 듣고는 "slow start"가 더 낫다며 IETF 메일링 리스트에서 그 이름을 제안했습니다. John Nagle의 말을 듣지 않을 수 없겠죠. 그러니 공정하게 말해, 이 이름의 책임은 Nagle과 Jacobson에게 있습니다.
3
기술적으로, 현대의 일반적인 TCP 구현은 약간 더 복잡한 slow start를 갖고 있습니다. 더 나은 링크 용량 감지를 위해, 대부분의 구현은 일종의 modified slow start를 사용해 특정 임계치에 도달하면 congestion control에 지휘권을 넘깁니다. 이 방식에서는 122Mbps까지의 램프 업이 약간 더 오래 걸릴 수 있습니다.
4
이 Hybrid Slow Start 개선은 CUBIC의 저자인 Ha와 Rhee의 작품입니다: Hybrid Slow Start for High-Bandwidth and Long-Distance Networks.
5
저는 CUBIC이 ACK 페이싱을 피하는 이유가 높은 RTT 네트워크에서의 성능을 돕기 위해서라고 가정했습니다. 아마 그런 효과도 있을 겁니다. 알려진 바에 따르면 CUBIC이 시간 기반인 이유는 RTT가 낮은 네트워크에서 지나치게 공격적이지 않게 하려는 것으로, 이는 CUBIC의 전신 BIC가 겪었던 결함입니다.
6
구글은 BBR을 지연/딜레이 기반 알고리즘으로 분류하지 않습니다. 이전 지연 기반 알고리즘인 Vegas보다 더 영리할지 몰라도, 제게는 여전히 꽤 지연 기반처럼 보입니다.