연초를 맞아 DataHaskell 팀이 지난 분기에 배운 점과 출시한 것들, 그리고 다음에 집중할 방향(온보딩 개선, 기여 과제 정리, 실제 워크플로우 파일럿)을 정리한다.
URL: https://www.datahaskell.org/blog/2026/01/12/state-of-datahaskell-q1-2026.html
새해가 본격적으로 시작되고 연말연시의 늘어짐이 가실 즈음, 지금까지의 상황을 점검하기에 좋은 시기라고 생각했습니다. 우리가 배운 것, 우리가 출시한 것, 그리고 다음으로 무엇에 집중하는지를 공유합니다.
이 글은 월간 커뮤니티 미팅의 입력 자료로도 사용할 예정입니다: 2026년 1월 17일(토) 오전 9시 PST.
DataHaskell은 Haskell이 일상적인 데이터 업무에서 실용적인 선택지가 되도록 만들기 위한 노력입니다. Haskell이 유난히 잘하는 것들—조합성(composition), 정확성(correctness), 그리고 이해 가능한 도구 만들기—을 강조하고 싶습니다.
크게 보면 생태계는 두 방향으로 갈 수 있습니다:
우리는 둘 사이의 균형을 잡으려 하지만, 두 번째 쪽으로 더 기울어 있습니다.
우리가 말하는 심볼릭 AI 툴링이란, 불투명한 파라미터를 단순히 피팅하는 것이 아니라 프로그램 공간을 탐색(search over programs) 해서 해석 가능한 모델을 만들고 단순화하는 데 도움을 주는 도구를 뜻합니다.
구체적으로는 다음과 같은 것들을 포함합니다: 특징 합성(feature synthesis, 제약 조건을 두고 원시 컬럼에서 작고 의미 있는 특징을 자동 생성), 해석 가능한 모델 탐색(interpretable model search, 점검/비교(diff)/내보내기(export) 가능한 간결한 의사결정 규칙/트리/표현식 생성), 프로그램 최적화(program optimization, 예: 죽은 분기 제거, 표현식 정규화(canonicalize), 단조성(monotonicity) 같은 제약을 강제하는 안전한 단순화/재작성).
이 영역은, 전체 Python 생태계를 하룻밤 사이에 복제하려 하지 않으면서도 Haskell의 강점(타입드 DSL, 대수적 모델링, 조합성)이 빛날 수 있는 분야입니다.
지난 분기의 작업은 많은 인터뷰로 시작했습니다. 생태계가 어디까지 왔는지, 어디로 가야 한다고 생각하는지 맥락을 제공해 줄 수 있는 사람들의 이름을 가능한 한 많이 찾았습니다(그러면서도 팟캐스트로 변질시키고 싶은 유혹은 꾹 참았습니다). 먼저, 지난 몇 달 동안 시간을 내어 이야기해 주신 모든 분들께 특별히 감사드립니다. 특히 Sam Stites, Laurent P. René de Cotret, Ed Kmett, Michael Snoyman, Bryan O’Sullivan, Tom Nielsen, Aleksey Khudyakov 님께 감사드립니다.
커뮤니티와 생태계가 가장 어려운 문제입니다. DataHaskell이 성공하려면 여러 요소(그리고 사람들)가 한 몸처럼 움직여 단일하고 명확한 비전을 만들어야 합니다. 대부분의 사람들은 자신이 좋아하는 데이터 포맷을 읽을 수 없거나, 결과를 플로팅할 수 없거나, 머신러닝 모델을 쉽게 돌릴 수 없거나, Jupyter에서 모든 것이 잘 동작하지 않으면 생태계에 손을 대지 않습니다. 전체 로드맵을 이끌 기여자와 사용자 풀(pool)이 필요합니다.
자연스럽게, 첫 번째 관심사는 Haskell 커뮤니티 안의 잠재 사용자와 잠재 기여자에게 닿을 수 있는지 확인하는 것이었습니다. DataHaskell의 부활을 공개적으로 알린 뒤 Discord 서버 가입이 급증했습니다.
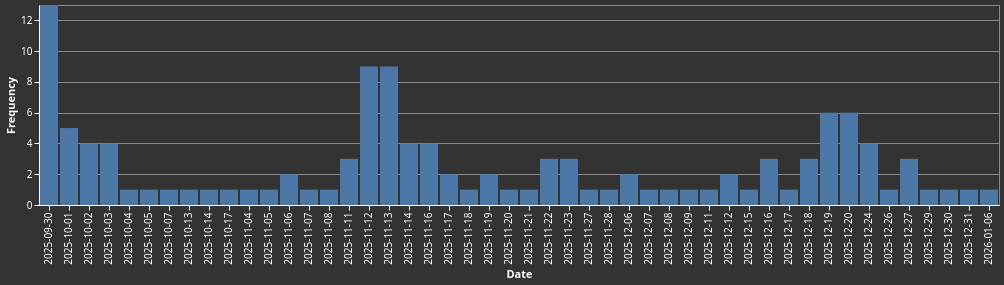
Discord에 들어온 뒤 가장 먼저 부탁드리는 것 중 하나가 소개 설문을 작성하는 것입니다. Discord 채널 멤버 110명 중 31명이 응답했습니다.
어떻게 저희를 알게 되셨나요? 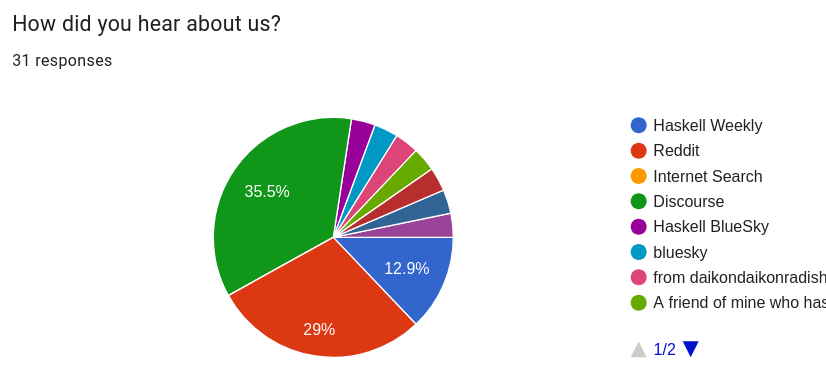
일상 업무에서 Haskell을 사용하시나요? 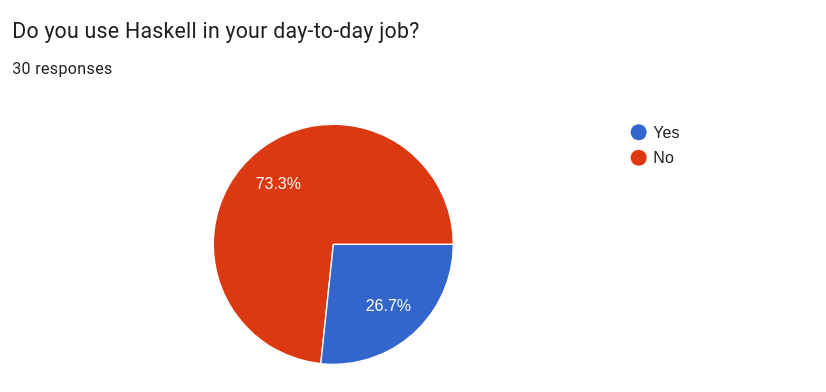
다음 중 본인의 역할을 가장 잘 설명하는 것은 무엇인가요? 
Haskell에서 어떤 데이터 도구를 사용해 보셨나요? 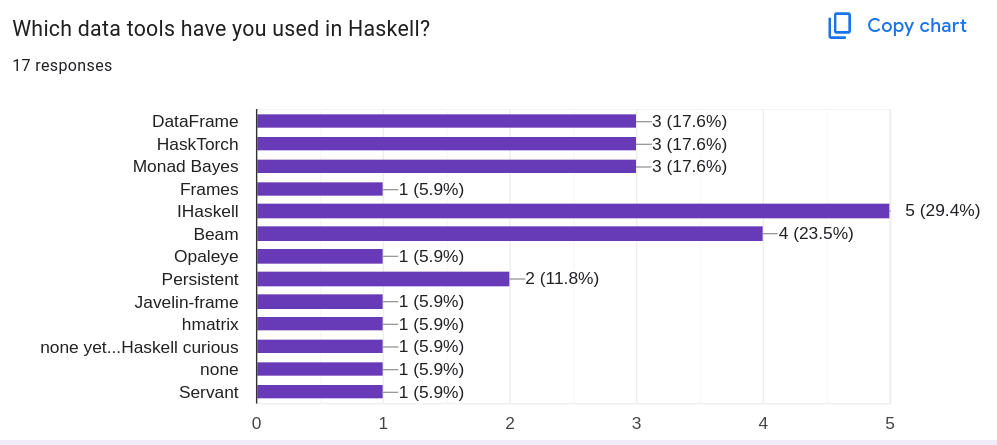
어떤 방식으로 기여하실 의향이 있나요? 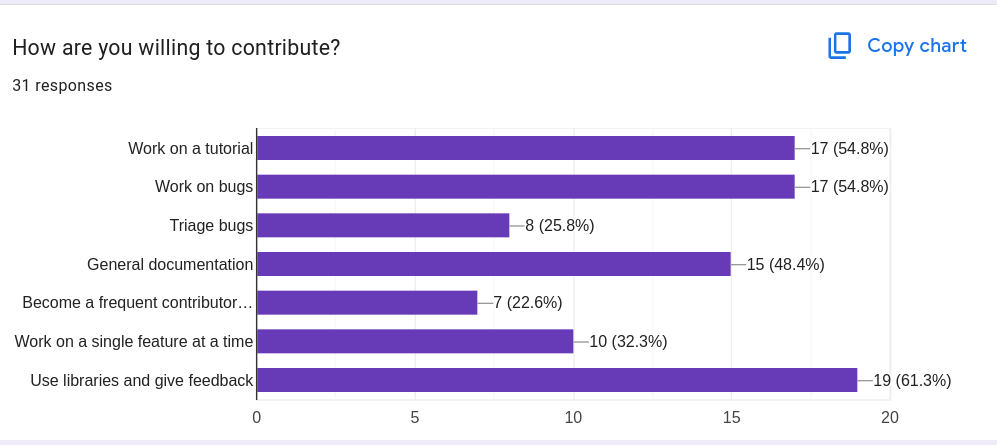
설문은 사람들이 압도적으로 마찰이 적고 한 입 크기의(bite-sized) 기여 방식을 원한다는 것을 시사합니다. 라이브러리를 써보고 피드백을 주는 것, 그리고 튜토리얼/문서/버그 수정처럼 구체적이고 자체 완결적인 기여가 선호됩니다. 반면 “장기적으로 지속되는 유지보수자가 되겠다”는 신호는 훨씬 적었습니다. 커뮤니티는 소수의 빈번한 기여자보다 많은 캐주얼/간헐적 기여자 쪽으로 기울어 있습니다.
우리가 관찰한 바를 토대로, 올해의 아웃리치는 다음을 최적화할 것입니다:
우리는 다음 영역의 메인터이너(또는 기여자)들과 적극적으로 협업하며 초보자 친화 과제를 스코핑하고 있습니다: IHaskell, Streamly, cassava, statistics/mwc-random, HVega.
동시에, 생태계가 성장하려면 더 많은 공동 소유(shared ownership)가 필요하기 때문에 이들 라이브러리에 대한 장기 기여자도 발굴하려 합니다.
또한 Haskell 커뮤니티 밖의 사람들에게도 연락했습니다. 데이터 사이언스를 위한 도구를 설계한다는 것은 데이터 사이언티스트의 문제를 푸는 것을 의미합니다. 우리는 Jonathan Carroll을 핵심 커뮤니티 멤버로 맞이했습니다. Jonathan은 데이터 사이언티스트이자 R 커뮤니티의 저명한 멤버입니다. 그는 설계와 우선순위 결정에 있어 큰 도움을 주었습니다. 우리는 Jonathan과 함께 Haskell IS a Great Language for Data Science라는 글을 작성했고, 여기서 Haskell의 특징이 데이터 사이언스의 일반적인 작업을 어떻게 더 쉽고 안전하게 만들 수 있는지를 보여주었습니다. 현재 Jonathan과 함께 Haskell for Data Science라는 책도 작업 중이며, 내년 중반~초반에 출간될 것으로 예상합니다.
지난 몇 달 동안 우리는 지속적으로 존재하던 기술적 문제 몇 가지를 해결하는 데 시간을 썼습니다. Haskell에서 작업할 때(신규/기존 사용자 모두) 가장 큰 허들 중 하나는 툴체인(컴파일러, 패키지 매니저, 라이브러리) 설치 및 관리입니다. GHCup이 이 이야기를 크게 개선했지만, 전체 생태계에는 여전히 거친 부분이 있습니다(누구나 IHaskell 설치 실패담 하나쯤은 있습니다). 우리는 특히 “첫 플롯까지 걸리는 시간(time to first plot)”을 줄이고 싶었습니다(이는 Julia 커뮤니티에서 자주 언급되는 지표입니다). 모든 사람을 Nix로 몰아넣는 유혹이 있었지만, 가능한 한 새로운 것을 최소로 요구하는 셋업을 제안하고 싶었습니다. 이를 위해 DataHaskell devcontainer를 만들고 이를 권장 경로(blessed path)로 정했습니다.
커뮤니티 전반에서 여러 페인 포인트를 해결했습니다. 예를 들어 Hasktorch 설치 경험 개선, 10년 묵은 포아송(poisson) 샘플러 기능 요청 해결, IHaskell 설치 안내 업데이트 등이 있습니다. 다시 말하지만, 어떤 단일 유스케이스가 성공하려면 생태계 전체가 함께 성공해야 합니다. Discord에서의 참여가 꽤 낮아, 이런 작업들을 위해 멤버들을 어떻게 동원할지 파악하기가 어려웠습니다. 올해는 기술적 기여를 촉진하기 위해 다양한 아웃리치 메커니즘을 시도할 예정입니다.
우리의 로드맵은 야심차며, 끝까지 해내겠다는 의지가 있습니다. 하지만 고정불변은 아닙니다. 우리 자신의 흥분만이 아니라 실제 사용자 요구를 반영하길 원합니다.
첫째, 온보딩이 좋은 의미에서 지루하게(boring) 느껴지길 원합니다. 즉, 셋업 마찰을 줄이고 권장 경로를 더 탄탄히 하며, “첫 플롯까지 걸리는 시간”이 일관되게 짧고 신뢰 가능하도록 만들겠다는 뜻입니다.
둘째, 사람들이 실제로 데이터 도구를 사용하는 방식에 맞는 소수의 엔드투엔드 워크플로우를 공개하고자 합니다. 이런 “골든 패스(golden paths)”는 수집(ingestion), 변환(transformation), 시각화(visualisation), 모델링(modelling) 전반에 걸쳐 DataHaskell이 어떻게 맞물리는지 보여줘야 하며, 동시에 오늘 기준으로의 공백이 어디인지도 솔직하게 드러내야 합니다. 목표는 모든 것을 커버하는 것이 아니라, 몇 가지 워크플로우가 완결되고 반복 가능하게 느껴지도록 만드는 것입니다.
셋째, 실질적인 **기여 퍼널(contribution funnel)**을 만들고자 합니다. 방향 없는 도움 요청 대신, 한 입 크기 과제와 범위가 잘 정해진 문서/튜토리얼 바운티(bounty)를 담은 보드를 눈에 띄게 유지하고 정기적으로 업데이트할 것입니다. 의도는 누군가가 한 시간 안에 기여하고 즉시 유용하다고 느끼며, 계속하고 싶다면 다음에 무엇을 하면 되는지도 알 수 있게 만드는 것입니다.
넷째, **노트북 사용성(ergonomics)**이 눈에 띄게 개선되길 원합니다. 더 나은 기본값, 더 명확한 설치 및 트러블슈팅 문서, IHaskell이 조용히 실패하거나 혼란스러운 상태에 빠질 수 있는 경우의 수를 줄이는 것을 의미합니다. 많은 사람들에게 노트북은 ‘현관문’이므로, 그 문이 부드럽게 열리게 하고 싶습니다.
마지막으로, 프로덕션에서 Haskell을 사용하는 실제 1~2개 팀과 함께 DataHaskell을 파일럿으로 운영하고자 합니다. 목표는 구체적인 워크플로우를 선택하고, 빠르게 수정 사항을 배포하며, 실제 고통 지점이 우선순위를 형성하게 하는 것입니다. 소수의 실제 사용자가 엔드투엔드로 성공하도록 만들 수 있다면, 로드맵은 더 날카로워지고 생태계 작업 역시 정당화 및 조율이 훨씬 쉬워집니다. 여러분 회사가 프로덕션에서 Haskell을 사용하고 있다면(혹은 사용하려 한다면), 2026년에 파일럿 파트너로 함께하길 바랍니다. 우리는 1~2개 팀과 긴밀히 협업하며 빠르게 개선을 출시하고, 일상적인 사용에서 무엇이 실제로 중요한지를 배우고 싶습니다.
DataHaskell의 주요 리드는 Michael Chavinda(mchav)와 Jireh Tan(daikonradish)입니다. 커뮤니티에 정식으로 소개하기 위해 “Hello World” 바이오를 준비했습니다:
저는 Michael Chavinda입니다. 지난 10년 대부분을 사기 탐지 시스템을 만들고 표 형식 데이터로 머신러닝을 하는 데 보냈습니다(대부분 Google에서, 최근에는 FIS Global에서). 2015년부터 Haskell을 쓰다 말다 했지만, 산업 현장의 많은 문제들이 함수형 프로그래밍 아이디어와 잘 맞아떨어지기 때문에 계속 돌아오게 됩니다. MapReduce나 JAX 같은 것들에서 볼 수 있듯이, 그 아이디어들은 규모가 커져도 잘 작동합니다. DataHaskell을 통해 저는 Haskell이 일상적인 데이터 업무의 ‘진짜 선택지’가 되도록 돕고자 합니다. 멋진 아이디어로만 남는 게 아니라, 사람들이 실제로 손이 가는 툴킷이 되도록요.
저는 Jireh Tan이며 통계 및 수학적 프로그래밍에 초점을 둔 데이터 사이언티스트입니다. Facebook과 Gojek에서 일했습니다. 저는 어떤 환경에 들어가든 나올 때는 10% 더 나아지게 만들어야 한다고 믿기 때문에 DataHaskell에 기여합니다. 장인이 쓴 Haskell 코드는 정말 아름답고, DataHaskell과 연관된 라이브러리들에는 많은 장인들의 손길이 닿아 있습니다.
기여자: Michael Chavinda, Jireh Tan