GHCi로 시작해 산술과 불리언, 함수 호출과 우선순위, if 표현식, 리스트와 문자열, 기본 리스트 연산, 범위와 무한 리스트, 리스트 내포, 튜플, zip, 피타고라스 삼각형 예제까지 하스켈 기초를 차근히 다룹니다.
 좋아요, 시작해 봅시다! 소개 따위는 안 읽고 건너뛰는 못 말릴 분이라면, 그래도 소개의 마지막 섹션만큼은 읽어 두세요. 이 튜토리얼을 따라가며 필요한 것들과 함수를 어떻게 로드할지 설명해 두었거든요. 우리가 가장 먼저 할 일은 GHC의 대화형 모드를 실행해서 몇 가지 함수를 불러 보며 하스켈의 아주 기본적인 감각을 익히는 것입니다. 터미널을 열고 ghci를 입력하세요. 그러면 대략 이런 화면이 보일 겁니다.
좋아요, 시작해 봅시다! 소개 따위는 안 읽고 건너뛰는 못 말릴 분이라면, 그래도 소개의 마지막 섹션만큼은 읽어 두세요. 이 튜토리얼을 따라가며 필요한 것들과 함수를 어떻게 로드할지 설명해 두었거든요. 우리가 가장 먼저 할 일은 GHC의 대화형 모드를 실행해서 몇 가지 함수를 불러 보며 하스켈의 아주 기본적인 감각을 익히는 것입니다. 터미널을 열고 ghci를 입력하세요. 그러면 대략 이런 화면이 보일 겁니다.
축하합니다, GHCI에 들어왔어요!
간단한 산술부터 해봅시다.
설명이 굳이 필요 없죠. 한 줄에서 여러 연산자를 함께 쓸 수 있고, 익숙한 우선순위 규칙이 그대로 적용됩니다. 괄호로 우선순위를 명시하거나 바꿀 수도 있어요.
멋지죠? 음, 아직은 안 멋질 수 있지만 좀만 참으세요. 여기서 조심할 작은 함정 하나는 음수 표기입니다. 음수를 쓰고 싶다면 항상 괄호로 감싸는 게 좋아요. 5 * -3을 하면 GHCI가 호통치지만, 5 * (-3)은 잘 동작합니다.
불 대수도 상당히 직관적입니다. 아시다시피 &&는 불리언 and, ||는 불리언 _or_를 뜻합니다. not은 True나 False를 부정합니다.
동등성 검사는 이렇게 합니다.
그렇다면 5 + "llama"나 5 == True는 어떨까요? 첫 번째를 시도하면 무시무시한 오류 메시지가 튀어나옵니다!
으악! GHCI가 말해 주는 건 "llama"는 숫자가 아니라서 5에 더하는 법을 모른다는 겁니다. "llama" 대신 "four"나 "4"여도 하스켈은 그것을 숫자로 보지 않습니다. +는 좌우가 숫자이길 기대하죠. True == 5를 하려고 하면, GHCI는 타입이 맞지 않는다고 알려줍니다. +는 숫자에만 동작하지만, ==는 비교 가능한 어떤 두 것에도 동작합니다. 단, 둘은 같은 타입이어야 한다는 함정이 있습니다. 사과와 오렌지는 비교할 수 없죠. 타입은 조금 뒤에 자세히 다룹니다. 참고: 5 + 4.0은 가능합니다. 5가 영리해서 정수처럼도, 부동소수처럼도 행동할 수 있거든요. 4.0은 정수처럼 행동할 수 없으니 5가 맞춰 줍니다.
사실 우리는 지금까지 내내 함수를 사용해 왔습니다. 예를 들어 *는 두 숫자를 받아 곱하는 함수입니다. 보신 것처럼 그 사이에 끼워서 호출하죠. 이것을 중위(infix) 함수라고 합니다. 숫자와 함께 쓰이지 않는 대부분의 함수는 전위(prefix) 함수입니다. 살펴봅시다.
 함수는 보통 전위 형태이므로, 이제부터는 굳이 전위라고 밝히지 않고 그냥 함수라고 하겠습니다. 대부분의 명령형 언어에서는 함수 이름 뒤에 괄호로 인자를 감싸서 호출합니다. 예: foo(), bar(1), baz(3, "haha"). 하스켈에서는 함수 이름 뒤에 공백을 두고, 그 다음에 공백으로 구분한 인자들을 적어 호출합니다. 가장 심심한 함수 하나를 불러 보죠.
함수는 보통 전위 형태이므로, 이제부터는 굳이 전위라고 밝히지 않고 그냥 함수라고 하겠습니다. 대부분의 명령형 언어에서는 함수 이름 뒤에 괄호로 인자를 감싸서 호출합니다. 예: foo(), bar(1), baz(3, "haha"). 하스켈에서는 함수 이름 뒤에 공백을 두고, 그 다음에 공백으로 구분한 인자들을 적어 호출합니다. 가장 심심한 함수 하나를 불러 보죠.
succ 함수는 후속 원소가 정의된 값을 받아 그 다음 값을 돌려줍니다. 보시다시피, 함수 이름과 인자는 공백으로만 구분합니다. 인자가 여러 개인 함수 호출도 간단합니다. min과 max는 순서를 매길 수 있는 두 값을 받습니다(예: 정수!). min은 더 작은 것을, max는 더 큰 것을 돌려줍니다. 직접 보세요:
함수 적용(함수 이름 뒤에 공백을 두고 인자를 적는 것)은 무엇보다 우선순위가 높습니다. 즉, 아래 두 표현은 같습니다.
하지만 9와 10의 곱의 다음 수를 얻고 싶다면 succ 9 * 10이라고 쓸 수 없습니다. 그건 9의 다음 수를 구한 뒤 10을 곱하겠다는 뜻이니까요. 그래서 100이 됩니다. succ (9 * 10)이라고 써야 91을 얻습니다.
인자가 두 개인 함수는 백틱으로 둘러싸서 중위로도 쓸 수 있습니다. 예컨대 div 함수는 두 정수를 받아 정수 나눗셈을 합니다. div 92 10은 9를 결과로 내죠. 하지만 이렇게 쓰면 어느 쪽이 나누는 수고 어느 쪽이 피제수인지 좀 헷갈릴 수 있습니다. 그래서 92 div 10처럼 중위로 쓰면 훨씬 명확합니다.
명령형 언어에서 온 많은 사람들이 괄호가 함수 호출을 의미해야 한다는 고정관념을 유지하곤 합니다. C에서는 foo(), bar(1), baz(3, "haha")처럼 괄호로 함수를 호출하죠. 하스켈에서는 공백이 함수 적용입니다. 따라서 Haskell에서 저 함수들은 foo, bar 1, baz 3 "haha"가 됩니다. bar (bar 3)를 보면, bar가 bar와 3을 인자로 받아 호출된다는 뜻이 아닙니다. 먼저 bar 3을 호출해서 어떤 숫자를 얻고, 그 숫자를 다시 bar에 넘긴다는 뜻입니다. C로 치면 bar(bar(3))이죠.
앞에서 함수 호출의 기본 감각을 익혔습니다. 이제 직접 만들어 봅시다! 좋아하는 텍스트 에디터를 열고 숫자를 받아 두 배로 만드는 함수를 적어 보세요.
함수 정의는 호출과 비슷합니다. 함수 이름 뒤에 공백으로 구분한 매개변수들이 오고, = 다음에 함수의 동작을 정의합니다. 이를 baby.hs 같은 이름으로 저장하세요. 저장한 곳으로 이동해 그 위치에서 ghci를 실행합니다. GHCI에 들어오면 :l baby를 실행하세요. 스크립트가 로드되면 우리가 정의한 함수를 가지고 놀 수 있습니다.
+는 정수와 부동소수(요컨대 숫자로 간주될 수 있는 모든 것)에 대해 동작하므로, 우리의 함수도 어떤 숫자에나 동작합니다. 이번엔 두 숫자를 받아 각각을 두 배로 만든 다음 더하는 함수를 만들어 봅시다.
간단하죠. doubleUs x y = x + x + y + y라고 정의해도 됩니다. 시험해 보면 예상 가능한 결과가 나옵니다(이 함수를 baby.hs 파일에 덧붙여 저장하고 GHCI에서 :l baby를 다시 하세요).
기대한 대로, 직접 만든 다른 함수에서 자신의 함수를 호출할 수 있습니다. 이를 염두에 두면, doubleUs를 이렇게 다시 정의할 수 있죠:
이건 하스켈 전반에서 자주 보게 될 일반적인 패턴의 아주 간단한 예입니다. 분명히 올바른 기초 함수들을 만들고, 그것들을 조합해 더 복잡한 함수를 만든다는 패턴이죠. 이렇게 하면 중복도 피할 수 있습니다. 만약 어떤 수학자들이 2가 사실은 3이라고 밝혀서 프로그램을 바꿔야 한다면 어떨까요? doubleMe만 x + x + x로 고쳐 쓰면 됩니다. doubleUs가 doubleMe를 호출하니, 2가 3인 이상한 새로운 세계에서도 자동으로 동작합니다.
하스켈에서는 함수의 순서가 중요하지 않습니다. doubleMe를 먼저 정의하고 doubleUs를 나중에 정의하든, 그 반대든 상관없습니다.
이제 숫자가 100보다 작거나 같을 때만 그 숫자를 두 배로 만드는 함수를 만들어 봅시다. 100보다 큰 숫자는 이미 충분히 크니까요!

바로 여기서 하스켈의 if 문을 소개했습니다. 아마 다른 언어의 if 문에 익숙하시겠죠. 하스켈의 if와 명령형 언어의 if의 차이는, 하스켈에서는 else가 필수라는 점입니다. 명령형 언어에서는 조건이 충족되지 않으면 몇 단계를 건너뛰면 되지만, 하스켈에서는 모든 표현식과 함수가 반드시 무언가를 반환해야 합니다. 이 if 문은 한 줄로도 쓸 수 있지만, 이렇게 쓰는 쪽이 더 읽기 좋다고 생각해요. 또 하나, 하스켈의 if는 표현식(expression) 입니다. 표현식은 값을 돌려주는 코드 조각을 말합니다. 5는 5를 돌려주므로 표현식이고, 4 + 8도 표현식, x + y도 x와 y의 합을 돌려주므로 표현식입니다. else가 필수이기 때문에 if 문은 항상 뭔가를 반환하며, 그래서 표현식인 셈이죠. 이전 함수에서 만들어지는 모든 숫자에 1을 더하고 싶다면, 본문을 이렇게 쓸 수 있습니다.
괄호를 생략했다면, x가 100보다 크지 않을 때에만 1을 더했을 겁니다. 함수 이름 끝의 '에 주목하세요. 그 아포스트로피는 하스켈 문법에서 특별한 의미가 없습니다. 함수 이름에 쓸 수 있는 유효한 문자예요. 보통 '는 엄격(지연이 아닌) 버전의 함수나, 기존 함수/변수의 약간 변형된 버전을 나타낼 때 씁니다. '가 함수 이름에 쓸 수 있는 문자이므로, 이런 함수도 만들 수 있습니다.
여기에는 주목할 점이 두 가지 있습니다. 첫째, 함수 이름에서 코난의 이름을 대문자로 시작하지 않았습니다. 함수는 대문자로 시작할 수 없기 때문이죠. 이유는 나중에 봅니다. 둘째, 이 함수는 매개변수를 받지 않습니다. 매개변수가 없는 함수를 보통 정의(혹은 이름) 라고 부릅니다. 한 번 정의하고 나면 그 이름(과 함수)의 의미를 바꿀 수 없기 때문에, conanO'Brien과 문자열 "It's a-me, Conan O'Brien!"은 서로 바꿔 쓸 수 있습니다.
 현실 세계의 장보기 목록처럼, 하스켈의 리스트는 아주 유용합니다. 가장 많이 쓰이는 자료구조이며, 수많은 문제를 모델링하고 해결하는 데 다양한 방식으로 활용됩니다. 리스트는 정말 멋집니다. 이 섹션에서는 리스트의 기초, 문자열(문자열은 리스트입니다), 그리고 리스트 내포를 살펴보겠습니다.
현실 세계의 장보기 목록처럼, 하스켈의 리스트는 아주 유용합니다. 가장 많이 쓰이는 자료구조이며, 수많은 문제를 모델링하고 해결하는 데 다양한 방식으로 활용됩니다. 리스트는 정말 멋집니다. 이 섹션에서는 리스트의 기초, 문자열(문자열은 리스트입니다), 그리고 리스트 내포를 살펴보겠습니다.
하스켈에서 리스트는 동종(homogenous) 자료구조입니다. 같은 타입의 여러 원소를 저장합니다. 즉, 정수의 리스트나 문자의 리스트는 가질 수 있지만, 몇 개의 정수와 몇 개의 문자가 섞인 리스트는 가질 수 없습니다. 자, 리스트!
보시다시피 리스트는 대괄호로 표기하며, 원소들은 쉼표로 구분합니다. [1,2,'a',3,'b','c',4] 같은 리스트를 시도하면, 하스켈은 문자(작은따옴표로 둘러싼 문자)가 숫자가 아니라고 불평할 겁니다. 문자 얘기가 나왔으니 말인데, 문자열은 문자들의 리스트일 뿐입니다. "hello"는 ['h','e','l','l','o']의 문법적 설탕이에요. 문자열이 리스트이므로 리스트 함수들을 문자열에도 쓸 수 있어 매우 편리합니다.
두 리스트를 이어 붙이는 것은 흔한 작업입니다. ++ 연산자로 합니다.
긴 문자열에 ++를 반복해서 쓰면 주의하세요. 두 리스트를 합칠 때(심지어 [1,2,3] ++ [4]처럼 단일 원소 리스트를 뒤에 붙일 때도), 내부적으로 하스켈은 ++의 왼쪽 리스트를 통째로 훑어야 합니다. 너무 크지 않은 리스트라면 문제가 없지만, 5천만 개짜리 리스트의 끝에 뭔가를 붙이는 일은 꽤 시간이 걸립니다. 반면 : 연산자(cons 연산자)를 써서 리스트의 앞에 무언가를 붙이는 건 즉각적입니다.
:는 숫자와 숫자 리스트, 혹은 문자와 문자 리스트를 받는 반면 ++는 두 리스트를 받는다는 점을 유의하세요. ++로 리스트의 끝에 원소 하나를 붙이더라도, 그 원소를 대괄호로 감싸 리스트로 만들어야 합니다.
[1,2,3]은 사실 1:2:3:[]의 문법적 설탕입니다. []는 빈 리스트입니다. 그 앞에 3을 붙이면 [3]이 되고, 그 앞에 2를 붙이면 [2,3]이 되고, 이런 식으로 이어집니다.
참고: [], [[]], [[],[],[]]는 서로 다른 것들입니다. 첫 번째는 빈 리스트, 두 번째는 빈 리스트 하나를 원소로 가진 리스트, 세 번째는 빈 리스트 세 개를 원소로 가진 리스트입니다.
리스트에서 인덱스로 원소를 꺼내려면 !!를 쓰세요. 인덱스는 0부터 시작합니다.
하지만 원소가 네 개인 리스트에서 여섯 번째 원소를 꺼내려 하면 오류가 납니다. 조심하세요!
리스트는 리스트를 원소로 가질 수 있습니다. 리스트를 원소로 가진 리스트의 리스트도 가능하고, 그 이상의 중첩도 가능합니다…
한 리스트 안의 리스트들은 길이가 달라도 되지만, 타입이 달라서는 안 됩니다. 문자와 숫자가 섞인 리스트를 만들 수 없는 것처럼, 문자 리스트와 숫자 리스트가 섞인 리스트도 만들 수 없습니다.
리스트의 원소들이 비교 가능하다면 리스트끼리도 비교할 수 있습니다. 리스트를 <, <=, >, >=로 비교할 때는 사전식(lexicographical) 순서로 비교합니다. 먼저 머리(head)를 비교하고, 같다면 두 번째 원소를 비교하는 식으로 이어집니다.
리스트로 무엇을 더 할 수 있을까요? 리스트에 동작하는 기본 함수 몇 가지를 봅시다.
head는 리스트를 받아 그 머리(첫 원소)를 돌려줍니다.
tail은 리스트를 받아 꼬리(첫 원소를 뺀 나머지)를 돌려줍니다.
last는 리스트의 마지막 원소를 돌려줍니다.
init은 리스트의 마지막 원소를 제외한 나머지를 돌려줍니다.
리스트를 괴물로 생각하면, 무엇이 무엇인지 한눈에 보입니다.
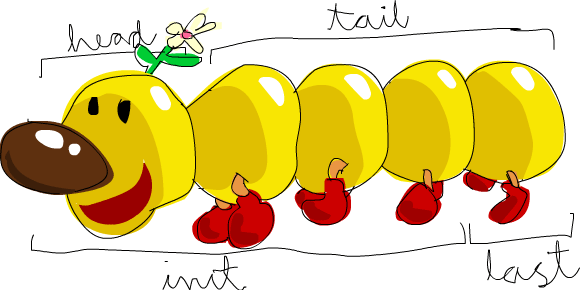
그런데 빈 리스트의 head를 얻으려 하면 어떻게 될까요?
앗, 우리 얼굴에 터져버렸네요! 괴물이 없다면 머리도 없습니다. head, tail, last, init을 쓸 때는 빈 리스트에 쓰지 않도록 조심하세요. 이 오류는 컴파일 타임에 잡히지 않으므로, 빈 리스트에서 원소를 달라고 하스켈에 잘못 요청하는 일을 방지하는 습관을 들이는 게 좋습니다.
length는 리스트를 받아 그 길이를 돌려줍니다. 당연하죠.
null은 리스트가 비었는지 확인합니다. 비었으면 True, 아니면 False를 반환합니다. xs == [] 대신 이 함수를 쓰세요(xs라는 리스트가 있다면).
reverse는 리스트를 뒤집습니다.
take은 숫자와 리스트를 받아, 리스트 앞에서부터 그만큼의 원소를 뽑아 냅니다. 보세요.
리스트에 있는 것보다 더 많이 가져오라고 하면 그냥 리스트 전체를 돌려준다는 걸 보세요. 0개를 가져오면 빈 리스트가 됩니다.
drop은 비슷하지만, 리스트 앞에서부터 그만큼의 원소를 버립니다.
maximum은 어떤 순서로든 정렬 가능한 원소들의 리스트에서 가장 큰 원소를 돌려줍니다.
minimum은 가장 작은 원소를 돌려줍니다.
sum은 숫자 리스트의 합을 돌려줍니다.
product는 숫자 리스트의 곱을 돌려줍니다.
elem은 어떤 것 하나와 그 같은 것들의 리스트를 받아, 그게 리스트의 원소인지 알려줍니다. 보통 가독성을 위해 중위 함수로 호출합니다.
elem[3,4,5,6]elem[3,4,5,6]리스트에 동작하는 기본 함수 몇 가지를 살펴봤습니다. 더 많은 리스트 함수는 나중에 보겠습니다.
 1부터 20까지 모든 숫자의 리스트를 원하면 어떡할까요? 물론 전부 타이핑할 수도 있지만, 그건 프로그래밍 언어에서 탁월함을 요구하는 신사들의 해결책은 아니죠. 대신 범위(range)를 씁니다. 범위는 열거 가능한 원소들의 등차수열 리스트를 만드는 방법입니다. 숫자는 열거 가능합니다. 하나, 둘, 셋, 넷, … 문자도 열거 가능합니다. 알파벳은 A에서 Z까지의 문자 열거죠. 이름은 열거할 수 없습니다. "John" 다음엔 뭐가 오나요? 저도 몰라요.
1부터 20까지 모든 숫자의 리스트를 원하면 어떡할까요? 물론 전부 타이핑할 수도 있지만, 그건 프로그래밍 언어에서 탁월함을 요구하는 신사들의 해결책은 아니죠. 대신 범위(range)를 씁니다. 범위는 열거 가능한 원소들의 등차수열 리스트를 만드는 방법입니다. 숫자는 열거 가능합니다. 하나, 둘, 셋, 넷, … 문자도 열거 가능합니다. 알파벳은 A에서 Z까지의 문자 열거죠. 이름은 열거할 수 없습니다. "John" 다음엔 뭐가 오나요? 저도 몰라요.
1부터 20까지의 자연수를 담은 리스트를 만들려면 [1..20]이라고 쓰면 됩니다. [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20]을 쓰는 것과 동일하며, 길게 타이핑하는 건 어리석을 뿐입니다.
범위의 멋진 점은, 단계(step)도 지정할 수 있다는 것입니다. 1부터 20 사이의 모든 짝수를 원하나요? 혹은 1부터 20까지 세 번째마다 하나씩?
처음 두 원소를 쉼표로 구분하고 상한을 지정하면 됩니다. 꽤 똑똑하지만, 단계가 있는 범위는 사람들이 기대하는 만큼 영리하진 않습니다. [1,2,4,8,16..100]이라고 해서 2의 거듭제곱 전체를 얻을 수는 없습니다. 첫째, 한 가지 단계만 지정할 수 있고, 둘째, 등차가 아닌 수열은 처음 몇 항만으로는 모호하기 때문입니다.
20에서 1까지의 리스트를 만들려면 [20..1]이라고 쓸 수 없고 [20,19..1]이라고 써야 합니다.
부동소수점을 범위에 사용할 때는 조심하세요! 정의상 완전히 정밀하지 않기 때문에, 범위에서 쓰면 꽤 기묘한 결과가 나올 수 있습니다.
제 조언은, 범위에서는 부동소수를 쓰지 말라는 겁니다.
상한을 지정하지 않으면 범위로 무한 리스트도 만들 수 있습니다. 나중에 무한 리스트를 자세히 다루겠습니다. 지금은 13의 처음 24개 배수를 어떻게 얻는지 보죠. [13,26..24*13]도 가능하겠지만, 더 나은 방법은 take 24 [13,26..]입니다. 하스켈은 게으르기 때문에 무한 리스트를 즉시 평가하려 들지 않습니다. 끝이 없으니 영원히 끝나지 않을 테니까요. 대신, 그 무한 리스트에서 무엇을 꺼내길 원하는지 기다립니다. 여기서는 처음 24개만 원하니 기꺼이 그렇게 해주죠.
무한 리스트를 만드는 유용한 함수 몇 가지:
cycle은 리스트를 받아 그것을 무한히 순환시키는 리스트를 만듭니다. 결과를 그대로 출력하려 하면 영원히 계속되므로, 적당히 잘라내야 합니다.
repeat은 원소 하나를 받아 그 원소로만 이루어진 무한 리스트를 만듭니다. 원소 하나짜리 리스트를 순환시키는 것과 같습니다.
같은 원소를 정해진 개수만큼 원한다면 replicate를 쓰는 게 더 간단합니다. replicate 3 10은 [10,10,10]을 돌려줍니다.
 수학 강의를 들어보셨다면 집합 내포(set comprehension) 를 보셨을 겁니다. 보통 일반적인 집합에서 더 구체적인 집합을 만들 때 사용하죠. 처음 10개의 짝수 자연수를 담는 기초적인 집합 내포는
수학 강의를 들어보셨다면 집합 내포(set comprehension) 를 보셨을 겁니다. 보통 일반적인 집합에서 더 구체적인 집합을 만들 때 사용하죠. 처음 10개의 짝수 자연수를 담는 기초적인 집합 내포는 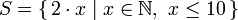 처럼 씁니다. 파이프(|) 앞 부분은 출력 함수, x는 변수, N은 입력 집합, x <= 10은 조건(프레디케이트)입니다. 즉, 그 집합은 조건을 만족하는 모든 자연수의 두 배를 담습니다.
처럼 씁니다. 파이프(|) 앞 부분은 출력 함수, x는 변수, N은 입력 집합, x <= 10은 조건(프레디케이트)입니다. 즉, 그 집합은 조건을 만족하는 모든 자연수의 두 배를 담습니다.
이를 하스켈로 쓰려면 take 10 [2,4..] 정도로 할 수 있겠죠. 하지만 처음 10개의 자연수에 두 배 대신 더 복잡한 함수를 적용하고 싶다면 어떨까요? 리스트 내포를 쓰면 됩니다. 리스트 내포는 집합 내포와 매우 비슷합니다. 당장은 처음 10개의 짝수를 구하는 것에 머물러 보죠. 우리가 쓸 수 있는 리스트 내포는 [x*2 | x <- [1..10]]입니다. x는 [1..10]에서 뽑아오고, [1..10]의 각 원소(우리가 x에 바인딩한)를 두 배로 바꿉니다. 실제로 해보면:
보시다시피 원하는 결과가 나옵니다. 이제 그 내포에 조건(프레디케이트)을 하나 추가해 봅시다. 조건은 바인딩 부분 뒤에 오며 쉼표로 구분합니다. 두 배 했을 때 12 이상인 원소만 원한다고 해 봅시다.
좋아요, 잘 됩니다. 그럼 50에서 100 사이의 수 중에서 7로 나누었을 때 나머지가 3인 수만 원한다면?
mod7==3]성공! 조건으로 리스트를 골라내는 것을 필터링(filtering) 이라고도 부릅니다. 우리는 숫자 리스트를 받아 조건으로 필터링했습니다. 다른 예를 봅시다. 10보다 큰 홀수는 "BANG!"으로, 10보다 작은 홀수는 "BOOM!"으로 바꾸고 싶다고 해 보죠. 홀수가 아니면 리스트에서 버립니다. 편의상, 그 내포를 함수로 감싸 재사용하기 쉽게 만들겠습니다.
내포의 마지막 부분이 조건입니다. odd 함수는 홀수이면 True를, 짝수이면 False를 돌려줍니다. 모든 조건이 True일 때만 그 원소가 리스트에 포함됩니다.
조건을 여러 개 포함할 수도 있습니다. 10에서 20 사이의 숫자 중 13, 15, 19를 뺀 값만 원한다면 이렇게 하죠:
리스트 내포에서는 조건을 여러 개 둘 수 있을 뿐 아니라(결과에 포함되려면 모든 조건을 만족해야 함), 여러 리스트에서 원소를 뽑아올 수도 있습니다. 여러 리스트에서 뽑아올 때, 내포는 주어진 리스트들의 모든 조합을 만들고 우리가 제공한 출력 함수로 그것들을 합칩니다. 길이가 4인 두 리스트에서 뽑는 내포가 필터링을 하지 않는다면, 결과 리스트의 길이는 16이 됩니다. 예를 들어, [2,5,10]과 [8,10,11]이 있고 이들 리스트의 모든 가능한 조합의 곱을 얻고 싶다면 이렇게 합니다.
예상대로 새 리스트의 길이는 9입니다. 50보다 큰 곱만 원한다면?
형용사 리스트와 명사 리스트를 조합하는 리스트 내포는 어떨까요… 장엄한 유머를 위해서요.
좋아요! length의 우리 버전을 만들어 봅시다! 이름은 length'로 하죠.
_는 리스트에서 무엇을 뽑아오든 신경 쓰지 않음을 뜻합니다. 어차피 변수 이름을 쓰지 않을 거라면 _로 쓰면 됩니다. 이 함수는 리스트의 각 원소를 1로 바꾸고 그것을 합칩니다. 결과 합은 리스트의 길이가 되겠죠.
친절한 알림: 문자열은 리스트이므로, 문자열을 처리하고 만들어내는 데도 리스트 내포를 쓸 수 있습니다. 문자열에서 대문자만 남기고 나머지는 모두 제거하는 함수를 보세요.
elem['A'..'Z']]시험해 봅시다:
여기서는 조건이 모든 일을 합니다. 그 문자는 ['A'..'Z']의 원소일 때만 새 리스트에 포함된다고 말하죠. 리스트를 원소로 담은 리스트를 다룰 때는 중첩 리스트 내포도 가능합니다. 리스트가 여러 숫자 리스트를 담고 있다고 해 봅시다. 리스트를 평탄화하지 않고 홀수는 모두 제거해 보겠습니다.
리스트 내포는 여러 줄로도 쓸 수 있습니다. GHCI 밖에서 코드를 작성할 때는, 특히 중첩된 내포라면 긴 내포를 여러 줄로 나누는 편이 더 좋습니다.

어떤 면에서 튜플은 리스트와 비슷합니다. 여러 값을 하나의 값에 담는 방법이죠. 하지만 근본적인 차이가 몇 가지 있습니다. 숫자의 리스트는 숫자의 리스트입니다. 그게 하나의 숫자만 담고 있어도, 무한히 많은 숫자를 담고 있어도 타입은 같습니다. 반면 튜플은 결합하려는 값의 개수를 정확히 알고 있을 때 쓰며, 튜플의 타입은 원소의 개수와 각 원소의 타입에 좌우됩니다. 튜플은 괄호로 표기하고 원소들은 쉼표로 구분합니다.
또 다른 중요한 차이는 동종일 필요가 없다는 것입니다. 리스트와 달리 튜플은 여러 타입을 조합할 수 있습니다.
하스켈에서 2차원 벡터를 어떻게 표현할지 생각해 봅시다. 리스트로 표현할 수도 있겠죠. 그럭저럭 됩니다. 그런데 2차원 평면 위의 도형의 점들을 리스트로 담고 싶다면요? [[1,2],[8,11],[4,5]]처럼 할 수 있습니다. 문제는 [[1,2],[8,11,5],[4,5]] 같은 것도 만들 수 있다는 겁니다. 하스켈은 여전히 숫자 리스트의 리스트이기 때문에 아무 문제 없다 보겠지만, 사실 별로 말이 안 되죠. 하지만 크기가 2인 튜플(쌍, pair)은 그 자체로 타입이므로, 쌍 몇 개와 3-튜플(triple) 하나를 같은 리스트에 담을 수 없습니다. 그러니 튜플을 씁시다. 벡터를 대괄호 대신 괄호로 감싸 [(1,2),(8,11),(4,5)]처럼요. [(1,2),(8,11,5),(4,5)]처럼 만들려 했다면 어떻게 될까요? 이런 오류가 납니다:
쌍과 3-튜플을 같은 리스트에 쓰려 했다고 알려줍니다. 그건 안 되죠. [(1,2),("One",2)] 같은 리스트도 만들 수 없습니다. 첫 원소는 숫자들의 쌍이고, 두 번째는 문자열과 숫자의 쌍이기 때문입니다. 튜플은 다양한 데이터를 표현하는 데도 쓰입니다. 예를 들어 누군가의 이름과 나이를 표현하려면 3-튜플 ("Christopher", "Walken", 55)을 쓸 수 있습니다. 이 예에서 보듯 튜플은 리스트를 원소로 가질 수도 있습니다.
튜플은 어떤 데이터가 몇 개의 구성 요소를 가져야 하는지 미리 알고 있을 때 사용하세요. 튜플은 훨씬 더 엄격해서, 크기마다 타입이 달라집니다. 그러니 튜플에 원소를 덧붙이는 일반 함수를 쓸 수 없고, 쌍에 덧붙이는 함수, 3-튜플에 덧붙이는 함수, 4-튜플에 덧붙이는 함수…처럼 각각 따로 써야 합니다.
싱글톤 리스트는 있지만, 싱글톤 튜플은 없습니다. 곰곰이 생각해 보면 그리 말이 되지 않아요. 싱글톤 튜플은 담고 있는 값 그 자체일 뿐이고, 우리에게 이득이 없습니다.
리스트처럼, 튜플의 구성 요소들이 비교 가능하다면 튜플도 서로 비교할 수 있습니다. 단, 서로 다른 크기의 튜플은 비교할 수 없습니다. 리스트는 길이가 달라도 비교할 수 있는데 말이죠. 쌍에 동작하는 유용한 함수 두 가지:
fst는 쌍을 받아 첫 번째 구성 요소를 돌려줍니다.
snd는 쌍을 받아 두 번째 구성 요소를 돌려줍니다. 놀랍죠!
참고: 이 함수들은 오직 쌍에만 동작합니다. 3-튜플, 4-튜플, 5-튜플 등에는 동작하지 않습니다. 튜플에서 데이터를 꺼내는 다른 방법은 조금 뒤에 다룹니다.
리스트의 쌍들을 만들어 내는 멋진 함수: zip. 두 리스트를 받아 같은 위치의 원소들을 쌍으로 묶어 하나의 리스트로 만듭니다. 아주 단순하지만 활용도가 엄청납니다. 두 리스트를 결합하거나 동시에 순회하고 싶을 때 특히 유용합니다. 예시를 봅시다.
원소들을 짝지어 새 리스트를 만듭니다. 첫 번째는 첫 번째와, 두 번째는 두 번째와… 같이요. 쌍은 서로 다른 타입을 담을 수 있으므로, zip은 서로 다른 타입의 리스트 두 개를 받아 묶을 수 있습니다. 두 리스트의 길이가 맞지 않으면 어떻게 될까요?
긴 리스트는 짧은 리스트의 길이에 맞춰 잘려 나갑니다. 하스켈은 게으르기 때문에 유한 리스트와 무한 리스트도 함께 zip할 수 있습니다:
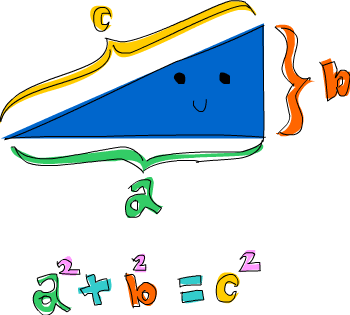
튜플과 리스트 내포를 결합한 문제를 하나 풀어 봅시다. 변의 길이가 모두 정수이고, 각 변이 10 이하인 직각삼각형 중 둘레가 24인 것은 무엇일까요? 먼저, 변이 10 이하인 모든 삼각형을 생성해 봅시다:
우리는 세 리스트에서 값을 뽑아오고 출력 함수로 그것들을 3-튜플로 합치고 있습니다. GHCI에서 triangles를 평가해 보면 변이 10 이하인 가능한 모든 삼각형의 리스트를 얻게 됩니다. 다음으로, 모두 직각삼각형이어야 한다는 조건을 추가합니다. 또한 빗변 c보다 b가 크지 않고, b보다 a가 크지 않다는 점을 반영해 수정합시다.
거의 다 됐습니다. 이제 둘레가 24인 것만 원한다고 조건을 추가하면 됩니다.
정답이 나왔습니다! 이는 함수형 프로그래밍의 일반적인 패턴입니다. 가능한 해의 시작 집합을 만들고, 그 해들에 변환을 적용하고 조건으로 걸러 가며 원하는 해를 얻는 패턴이죠.