Spindle에 새로운 `microvm` 엔진이 추가되었습니다. 워크플로마다 독립적인 작은 가상 머신을 사용하며, NixOS 이미지 구성, Docker 빌드, 서비스 실행, 공격적인 캐시를 통한 빠른 재실행, 그리고 자체 호스팅까지 지원합니다.
Spindle에 두 번째 엔진인 microvm이 추가되었습니다. 각 워크플로는 자신만의 작은 가상 머신을 가지며, 그 안에서는 무엇이든 할 수 있는 완전한 실제 환경이 제공됩니다. 이것은 Nixery 엔진에서 한 단계 업그레이드된 것이면서도 완전히 호환되므로, 이미 동작하는 Nixery 워크플로가 있다면 nixery를 microvm으로 바꾸기만 해도 작동합니다!
흥미로운 부분은 NixOS 이미지입니다. 워크플로 파일에서 직접 머신을 구성할 수 있습니다. 예를 들어 다음과 같은 일을 할 수 있습니다.
서비스를 띄울 수 있습니다:
services:
postgresql:
enable: true
ensureDatabases: ["spindle-workflow"]
ensureUsers:
- name: spindle-workflow
ensureDBOwnership: true
Docker 컨테이너를 빌드할 수 있습니다:
virtualisation:
docker: true
steps:
- name: "do the thing!"
command: docker build ...
그리고 NixOS가 아닌 이미지도 사용할 수 있습니다:
image: alpine
steps:
- name: install golang
command: apk add go
두 번째 실행도 빠릅니다. 적극적으로 캐시하기 때문입니다. 의존성, 서비스, 그리고 microVM 내부에서 빌드된 다른 모든 Nix derivation은 spindle의 Nix 캐시에 푸시되므로, 다음에 그것들이 필요한 워크플로는 다시 빌드하지 않습니다. 이에 대해서는 아래에서 더 설명합니다.
그리고 tangled의 다른 모든 것처럼 전체 시스템을 자체 호스팅할 수 있으므로, 자신의 하드웨어에서 microVM 엔진과 함께 자체 spindle을 실행할 수 있습니다(자체 호스팅 가이드 참조). 더 풍부한 예시를 원한다면 문서의 레시피도 확인해 보세요.
microVM은 대부분의 지루한 부분을 제거한 VM일 뿐입니다. BIOS도 없고, 탐색할 PCI 버스도 없고, 에뮬레이션된 그래픽 카드도 없으며, 일반적인 QEMU 머신이 끌고 다니는 느린 레거시 요소도 없습니다. virtio 장치와 그 외의 아주 적은 것만 제공되므로 매우 빠르게 부팅되고 메모리도 거의 사용하지 않습니다. 현재 지원하는 러너는 QEMU뿐이지만, 엔진은 나중에 다른 러너(예를 들어 firecracker)도 끼워 넣을 수 있도록 작성되어 있습니다.
게스트 내부에는 우리가 agent라고 부르는 작은 소프트웨어가 있습니다. Spindle은 절대 SSH로 들어가거나 "바깥에서" 명령을 실행하지 않습니다. 대신 agent가 부팅되자마자 vsock을 통해 spindle로 다시 연결하고, 인사를 건넨 뒤부터는 워크플로의 모든 단계가 메시지로 전달됩니다. agent는 비특권 사용자로 명령을 실행하고, stdout과 stderr를 다시 스트리밍하며, 종료 코드를 보고합니다. 호스트 쪽 구현은 spindle에 있고, 게스트 쪽은 shuttle이라는 작은 Rust 바이너리입니다. (shuttle은 spindle이 사용하는 프로토콜인 agentproto를 구현합니다. 기술적으로 말하면 누구나 이것을 구현할 수 있고, 부작용 관련 조건만 맞는다면 자신만의 agent를 둘 수도 있습니다!)
부팅할 수 있는 이미지에는 두 가지 "종류"가 있으며, 꽤 다른 사용자층을 대상으로 합니다.
첫 번째는 NixOS 이미지입니다. 이것이 흥미로운 쪽입니다. 전체 게스트가 Nix로 빌드되므로 워크플로 파일에서 직접 구성할 수 있습니다. dependencies, services, virtualisation(예: Docker), registry, caches 같은 것들을 YAML에 바로 적을 수 있고, 게스트 agent는 여러분의 단계가 실행되기 전에 그 구성을 빌드하고 활성화합니다. 정확히 같은 베이스와 구성을 이전에 빌드한 적이 있다면 spindle은 게스트에게 다시 빌드하는 대신 실현할 store path를 넘겨줄 수 있으므로(spindle에 구성된 캐시에서 가져옵니다), 두 번째 실행은 빠릅니다.
두 번째는 비-NixOS 이미지이며, 현재는 Alpine만을 의미하지만 무엇이든 될 수 있습니다. 여기서는 워크플로 수준의 NixOS 구성을 사용할 수 없습니다(구성할 NixOS가 없기 때문입니다). 하지만 이미지 내부에 Nix가 존재한다면, 우리 Alpine 이미지처럼 spindle Nix 캐시와는 여전히 문제없이 통신할 수 있습니다.
이전에 spindle을 사용해 본 적이 있다면 익숙하게 보일 것입니다. 이미 알고 있는 동일한 매니페스트에 NixOS 이미지가 이해하는 몇 개의 키만 추가된 형태입니다. 다음은 테스트를 위해 Postgres가 필요하고 이미지를 빌드하기 위해 Docker가 필요한 워크플로입니다:
# .tangled/workflows/test.yaml
engine: microvm
when:
- event: ["push", "pull_request"]
branch: ["master"]
image: nixos
dependencies:
- go
- github:nixos/nixpkgs#hello
registry:
nixpkgs: github:nixos/nixpkgs/nixos-unstable
caches:
https://nix-community.cachix.org: "nix-community.cachix.org-1:mB9FSh9qf2dCimDSUo8Zy7bkq5CX+/rkCWyvRCYg3Fs="
services:
postgresql:
enable: true
ensureDatabases: ["spindle-workflow"]
ensureUsers:
- name: spindle-workflow
ensureDBOwnership: true
virtualisation:
docker: true
steps:
- name: run tests
environment:
PGHOST: /run/postgresql
command: |
docker build -t app .
psql -c "select 1"
go test ./...
새 키들은 각각 하나의 역할을 합니다:
dependencies**는 단계에서 사용할 수 있는 패키지입니다. 이것들은 모든 단계가 실행되기 전에 source하는 mkShellNoCC devshell에 들어가므로, 단순한 바이너리만이 아니라 전체 stdenv 환경(pkg-config가 PKG_CONFIG_PATH를 연결하는 설정 훅 등 포함)을 얻게 됩니다. 즉 openssl 같은 의존성을 사용하면서 openssl-sys Rust crate를 무리 없이 컴파일할 수 있습니다! go처럼 이름만 있는 경우 nixpkgs에서 조회되며(Nixery와 동일), flakeref#attr 문법으로 어떤 flake든 가리킬 수도 있으므로 github:nixos/nixpkgs#hello는 그 flake에서 hello를 바로 가져옵니다.registry**는 전역 참조를 다시 매핑하는 방법입니다. 여기서는 nixpkgs를 nixos-unstable에 고정했기 때문에, 위의 go는 이제 unstable에서 해석됩니다. 같은 방식으로 여러분의 flake에 별칭을 붙일 수도 있습니다(myflake: github:me/x, 그리고 dependencies에서 myflake#tool).caches**는 바이너리 캐시 URL과 신뢰할 수 있는 공개 키를 매핑한 것입니다. 이것들은 읽기 프록시에 연결되므로(바로 아래에서 더 설명합니다), 게스트는 모든 것을 처음부터 빌드하는 대신 그것들로부터 미리 빌드된 경로를 대체 받아 사용할 수 있습니다.services와 virtualisation이 흥미로운 부분입니다. 이것들은 그대로 NixOS에 전달되므로, NixOS 설정에서 쓸 수 있는 것은 여기서도 쓸 수 있습니다. services.postgresql.enable은 여러분의 단계가 실행되기 전에 Postgres를 띄웁니다.
단계는 spindle-workflow 사용자로 실행되므로, ensureDBOwnership과 함께 그 사용자 이름으로 데이터베이스 이름을 지정하는 것이 동작하는 DB를 만드는 가장 쉬운 길입니다. Postgres의 peer 인증은 유닉스 사용자를 일치하는 역할에 바로 매핑하므로 psql은 비밀번호나 추가 설정 없이 소켓을 통해 연결됩니다(이 이름 일치는 ensureDBOwnership에 대한 NixOS 요구사항입니다. 다른 이름의 DB를 원한다면 직접 권한을 부여하면 됩니다).
virtualisation.docker: true는 virtualisation.docker.enable = true의 축약형이며, VM 내부에서 실제 Docker 데몬을 사용할 수 있게 해줍니다. 첫 번째 단계가 실행될 때쯤이면 Postgres는 리스닝 중이고 Docker 소켓도 준비되어 있습니다. 사이드카를 맞춰 붙이는 과정 없이 머신의 일부일 뿐입니다.
(enable 옵션이 존재하는 곳에서는 어디서나 true를 .enable = true의 축약형으로 사용할 수 있으므로, 대부분의 "그냥 켜기" 서비스는 한 줄이면 됩니다!)
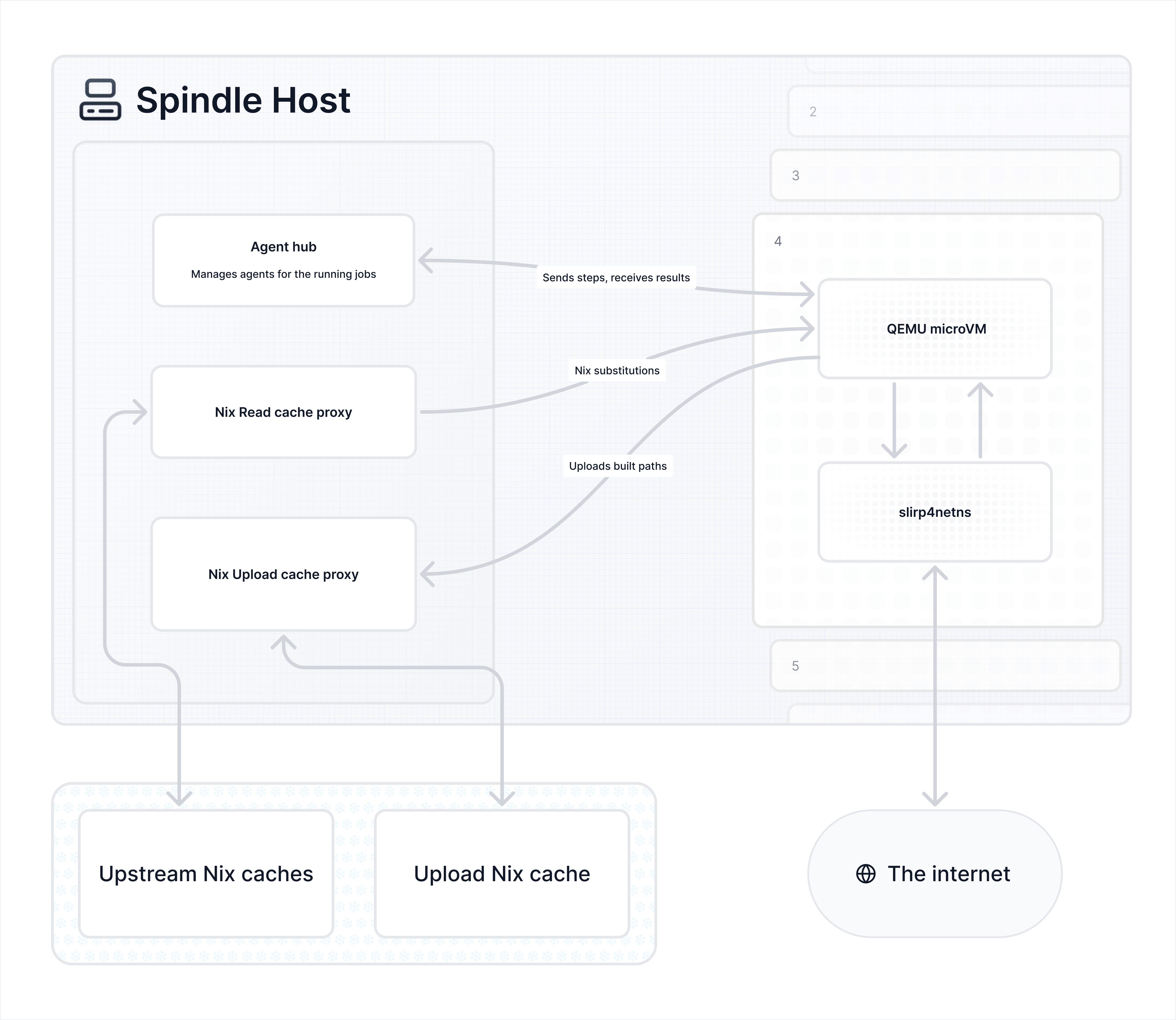
Spindle은 호스트에서 실행되는 두 개의 프록시를 통해 Nix 캐시와 통신하므로, 게스트는 여기에 접근하기 위해 자격 증명이나 직접적인 네트워크 접근 권한이 필요하지 않습니다. agent와 마찬가지로 이들도 spindle과 통신할 때 vsock을 사용합니다.
읽기 프록시는 구성된 substituter들과 워크플로에 나열한 캐시들로 요청을 분산합니다. 그래서 게스트가 store path를 실현해야 할 때 프록시에 요청하면 프록시가 그것을 가져옵니다. 요청은 읽기 캐시들에 동시에 전송되며, 가장 먼저 응답하는 쪽이 이깁니다.
업로드 프록시는 반대 방향으로 동작합니다. 게스트 내부에서 빌드된 모든 경로는 spindle의 Nix 캐시로 다시 푸시되므로(구성되어 있다면), 다음에 그것이 필요한 워크플로는 다시 빌드할 필요가 없습니다. 구성된 읽기 캐시들 중 어느 곳에든 이미 존재하는 경로는 업로드되지 않습니다. agent가 빌드된 경로를 보고하면 그것들은 큐에 들어가고, 워크플로의 나머지 부분이 계속 실행되는 동안 백그라운드에서 업로드되므로 업로드가 작업을 막지 않고 겹쳐서 진행됩니다. VM 정리 단계에 도달했을 때 아직 전송 중인 것이 있다면, 모든 작업이 끝날 때까지 워크플로가 기다립니다.
Spindle은 업로드 대상 바이너리 캐시로 http, ssh-ng, ssh URL을 사용하도록 구성할 수 있습니다. 예를 들어 ssh-ng://localhost는 spindle이 실행 중인 머신의 로컬 Nix store에 바로 업로드합니다! ssh-ng와 ssh는 spindle이 nix copy를 사용해 업로드할 수 있도록 PATH에 Nix가 있어야 하지만, http를 지원하는 바이너리 캐시(예: ncps)를 사용한다면 Nix가 없어도 됩니다.
이미지 빌드는 Nix로 수행됩니다. NixOS의 경우 microvm.nix를 기반으로 하고 그 위에 자체 요소를 얹습니다(커널 모듈 축소, 사용자 구성 등). Alpine의 경우에는 커널, initrd, 커널 모듈을 가져오고, 부팅 시 머신을 구성하는 init 스크립트를 설정하고, 원하는 의존성(nix, git 등)을 복사해 넣은 뒤, 전체 rootfs를 squashfs로 압축하는 비교적 작은 Nix 정의가 있습니다.
하지만 이 모든 것이 반드시 Nix일 필요는 없습니다. spindle의 관점에서 이미지는 몇 가지 조건만 만족하면 유효합니다. agentproto를 구현한 게스트 agent가 존재하고 부팅 시 시작되어야 하며, spindle-workflow 사용자가 존재해야 하고, 작업 디렉터리가 /workspace에 설정되어 있어야 합니다. 이것은 원하는 어떤 방식으로든 빌드할 수 있습니다.
빌드된 모든 이미지는 아티팩트 옆에 spec.json을 함께 제공합니다. 이 스펙이 전체 계약입니다. 커널, initrd, 읽기 전용 store 디스크의 위치, 부팅 인자, 할당할 메모리와 vCPU 수, 단계를 실행할 셸, 쓰기 가능한 볼륨, 네트워크 인터페이스, 그리고 러너별 설정(머신 타입, CPU, 추가 QEMU 인자)까지 모두 포함됩니다. NixOS 이미지는 또한 내장된 베이스 구성을 식별하는 baseConfigHash도 포함합니다(이것은 nixosSystem.config.system.build.toplevel.outPath의 해시입니다).
워크플로는 최상위의 image 키로 이미지를 선택합니다. 이름은 디스크에 있는 것과 문자 그대로 매칭되며, 먼저 spec.json이 들어 있는 <name> 디렉터리를 찾고, 없으면 평평한 구조의 <name>.json으로 넘어갑니다. 여기서 좋은 점은 해석 결과가 오직 이름과 디스크 위의 내용에만 의존하고, 해석을 수행하는 호스트에는 전혀 의존하지 않는다는 것입니다. 그래서 같은 워크플로는 모든 spindle에서 같은 이미지로 해석됩니다. 운영자가 여러 아키텍처를 나란히 유지한다면 nixos-x86_64, alpine-aarch64 같은 이름을 붙일 수 있습니다(이 접미사는 단지 이름의 일부일 뿐이며 특별 취급되지 않습니다). 예를 들어 nixos가 동작하길 원한다면 nixos를 nixos-x86_64에 심볼릭 링크하면 됩니다.
실행 직전에는 참조된 파일들이 실제로 존재하는지, 그리고 호스트에 필요한 도구가 있는지를 다시 확인합니다. 볼륨용 mkfs.ext4, 스펙 아키텍처에 맞는 QEMU 바이너리, /dev/kvm, /dev/vhost-vsock, 그리고 이미지가 네트워킹을 원한다면 ip / mount / slirp4netns / unshare 도구 체인까지 확인합니다.
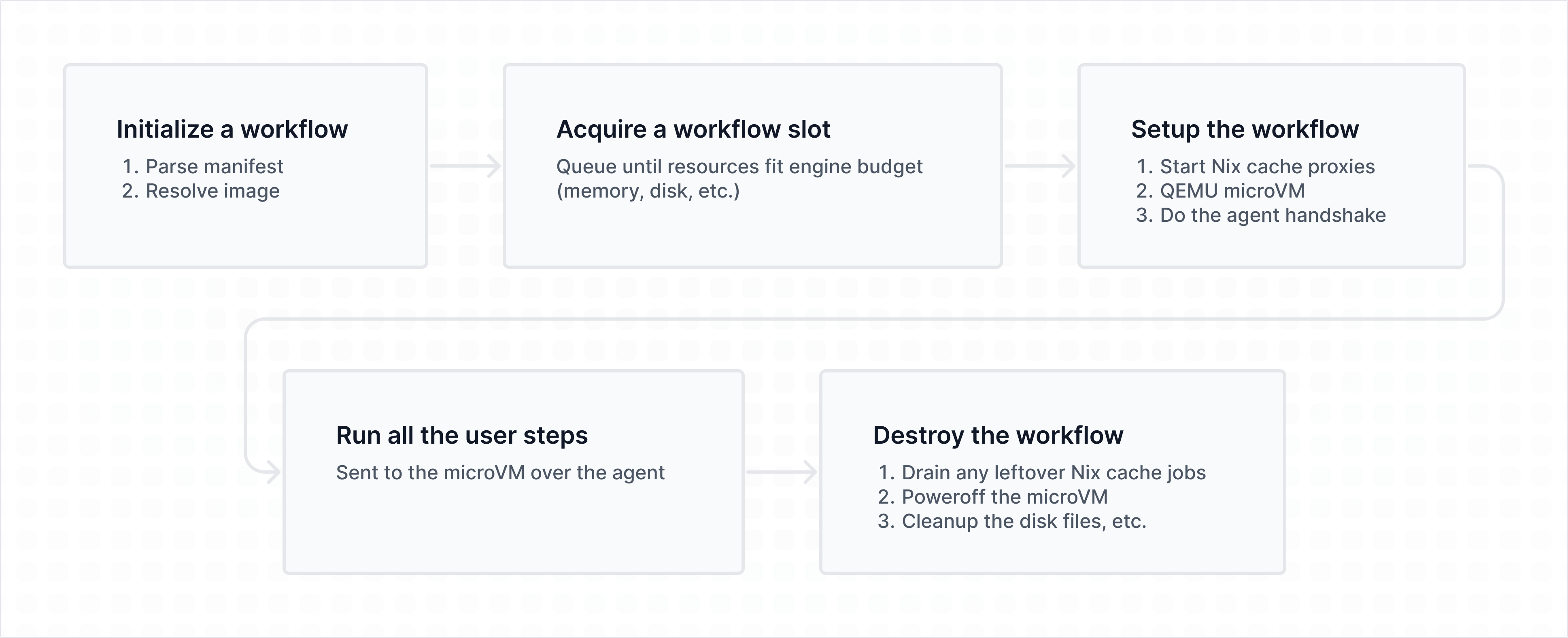
워크플로는 몇 가지 단계를 거칩니다. 파싱되고 이미지가 해석된 뒤, 슬롯을 기다리고, 설정이 이루어지고, 단계들이 실행되고, 마지막으로 모든 것이 정리됩니다.
기다리는 부분은 매우 중요합니다. 각 이미지는 필요한 메모리, vCPU 수, 디스크 용량을 선언하며, 워크플로는 무엇이든 부팅되기 전에 리소스 스케줄러로부터 슬롯을 획득해야 합니다. 이 스케줄러는 aging과 사용자별 공정성을 갖춘 work-conserving 방식이므로, 한 사람이 작업 100개를 제출해도 다른 사람들을 굶기지 않으며, 예산 안에 들어맞는 작업이 있다면 슬롯이 놀지 않습니다.
슬롯을 획득하면 설정을 진행합니다. Spindle은 게스트를 위한 무작위 vsock CID를 할당하고 agent 허브에 등록합니다. 워크플로별 작업 디렉터리를 만들고, 앞에서 설명한 두 개의 캐시 프록시와, 호스트를 통해 이름 해석을 수행하면서 private/special-use 주소를 걸러내는 DNS 프록시를 시작한 다음 VM을 생성합니다. 쓰기 가능한 볼륨은 ext4로 포맷된 sparse 파일이 되고, store 디스크는 읽기 전용으로 연결되며, QEMU는 -sandbox on, -nodefaults, 디스플레이 없음, 모니터 없음 등의 옵션과 함께 시작됩니다. 부팅 시 시리얼 / virtio_console 출력은 로그 파일로 보내고, 제어를 위한 QMP 소켓도 엽니다.
그다음 머신을 기다립니다. QEMU가 게스트가 실행 중이라고 말할 때까지 QMP를 폴링하고, 그런 뒤 우리가 기대하는 CID에서 vsock을 통해 agent의 핸드셰이크가 오기를 기다립니다. agent는 자신의 프로토콜과 버전을 알려주고, spindle은 작업 id, 신뢰할 수 있는 캐시 공개 키, 캐시와 DNS 프록시 포트를 되돌려 보냅니다. 이후 단계들은 한 번에 하나씩 $shell -lc <command> 형태로 실행되며, /workspace/repo에서 비특권 워크플로 사용자로, 올바른 환경과 잠금 해제된 시크릿을 포함한 상태로 수행됩니다. 워크플로가 NixOS 구성을 활성화하고, 우리가 정확히 같은 베이스와 구성을 이미 빌드해 둔 경우라면, 활성화 단계는 다시 빌드하는 대신 캐시된 toplevel store path를 실현할 수 있습니다. 어느 경우든, 구성을 새로 빌드하든 캐시된 toplevel을 내려받든, 그 출력은 발생하는 즉시 활성화 단계 로그로 바로 스트리밍되므로, 아무 일도 일어나지 않는 빈 화면을 보며 기다리는 대신 closure가 들어오는 모습을 지켜볼 수 있습니다.
타임아웃은 협조적으로 처리됩니다. 워크플로 타임아웃으로부터 마감 시한을 계산해 게스트로 보내고, 게스트가 머신을 갑자기 빼앗기기 전에 스스로 타임아웃을 보고할 기회를 갖도록 호스트 쪽에 약간의 여유 시간을 둡니다. 그리고 VM이 단계 도중 크래시하면 시리얼 및 QEMU 로그를 그 단계의 stderr에 이어 붙입니다. 왜냐하면 "guest agent connection lost: EOF" 같은 메시지는 새벽 2시에 읽기에는 정말 쓸모가 없기 때문입니다...
정리 과정은 워크플로가 성공했든, 실패했든, 타임아웃되었든 동일합니다. 대기 중인 Nix 캐시 업로드를 모두 비우고, agent에게 전원을 끄라고 요청하고, QEMU 종료를 기다립니다(QMP system_powerdown으로 대체 시도하고, 그래도 고집을 부리면 마지막에는 kill합니다). 그런 다음 프록시들을 닫고 작업 디렉터리를 제거합니다.
호스트의 로컬 네트워크에 도달할 수 있는 VM은 도달해서는 안 되는 것들에도 도달할 수 있는 VM입니다. 그래서 QEMU는 아예 호스트의 네트워크 네임스페이스에서 실행되지 않습니다. 먼저 새로운 user, net, mount 네임스페이스로 unshare합니다. 그 네임스페이스 내부에서는 작은 래퍼가 127.0.0.1을 가리키는 resolv.conf를 bind-mount하여 QEMU의 내장 slirp DNS가 사용되지 않도록 하고, 그런 다음 QEMU를 exec하기 전에 모든 special-use IP 대역(RFC 6890, 즉 사설 네트워크, link-local, loopback 등)에 대해 블랙홀 라우트를 설치합니다. 이후 slirp4netns가 그 네임스페이스의 외부 인터넷 연결을 제공하며, --disable-host-loopback, sandbox, seccomp가 모두 활성화됩니다. QEMU는 그 네임스페이스 안에서 실행되고, 게스트의 네트워크 카드는 QEMU 자체의 내장 user-mode 네트워킹에 연결됩니다. 따라서 게스트에서 나가는 모든 패킷은 두 번을 거칩니다. guest → QEMU의 slirp → 네임스페이스의 slirp4netns → 인터넷. 게스트는 호스트의 네트워크를 절대 보지 못하고, 호스트의 네트워크도 게스트를 절대 보지 못합니다. 이 모든 것은 아무 권한 없이 수행됩니다!
게스트 DNS는 slirp 계층 어느 쪽도 사용하지 않습니다. 게스트의 /etc/resolv.conf는 127.0.0.1:53의 shuttle을 가리키고, shuttle은 DNS 패킷을 vsock을 통해 호스트 측 DNS 프록시로 전달합니다. 그 프록시는 호스트의 실제 리졸버를 통해 이름 해석을 수행하고, private 또는 special-use 주소를 가리키는 응답을 제거하므로 게스트 트래픽은 오직 외부 세계에만 도달할 수 있고, 호스트나 호스트의 로컬 네트워크에 있는 어떤 것에도 도달할 수 없습니다.
스케줄러의 예산은 자체적인 장부 관리입니다. 무엇을 할당했는지 추적하고, 러너(QEMU)는 워크플로가 그만큼만 사용하도록 보장합니다. 하지만 선택적으로 전체 구성요소(QEMU와 slirp4netns 모두)를 워크플로별 cgroup에 넣어 메모리, 스왑 등의 제한을 둘 수 있으며, 이는 QEMU와 slirp4netns 자체도 리소스를 사용한다는 점을 감안한 추가적인 강제 계층입니다. 좋은 부수 효과로, cgroup이 OOM으로 VM을 죽였을 때 그것이 OOM이었음을 확인하고 그렇게 보고할 수 있으므로, 일반적인 크래시처럼 보이게 하여 사용자가 추측하게 만들지 않습니다.
spindle 자체도 memory.min이 설정된 cgroup을 하나 갖습니다. 이는 호스트 OOM 상황에서 spindle 자체보다 워크플로가 먼저 죽도록 하기 위한 것입니다.
다음으로 예정된 몇 가지 사항입니다:
궁금한 점이 있다면 언제든지 https://chat.tangled.sh 에 와서 질문해 주세요!