Quickwit 0.1 첫 릴리스를 발표하며, 오브젝트 스토리지 기반 세그먼트 복제와 스토리지·컴퓨트 분리를 통해 프라이빗 검색의 비용 효율을 높이는 접근과 주요 기능, 향후 로드맵을 소개한다.
Quickwit 0.1 릴리스를 발표하게 되어 기쁩니다. Quickwit에서 조용히 무엇을 만들어 왔는지 설명하는, 오래 미뤄진 블로그 글을 올릴 때가 됐습니다.
저희는 다음과 같은 관찰에서 Quickwit을 시작했습니다. Elasticsearch는 검색을 위한 만능 솔루션입니다... 하지만 비용 관점에서 보면, 검색 엔진에는 사실 크게 두 가지 유형이 있고, 각기 다른 해법을 요구합니다.
이 검색 엔진들을 산점도로 그려봅시다. X축은 검색 대상 코퍼스의 크기, Y축은 평균 QPS(query per second)입니다. 두 범주는 서로 잘 분리된 두 개의 선을 따라 흩어져 있는 것으로 관찰됩니다.
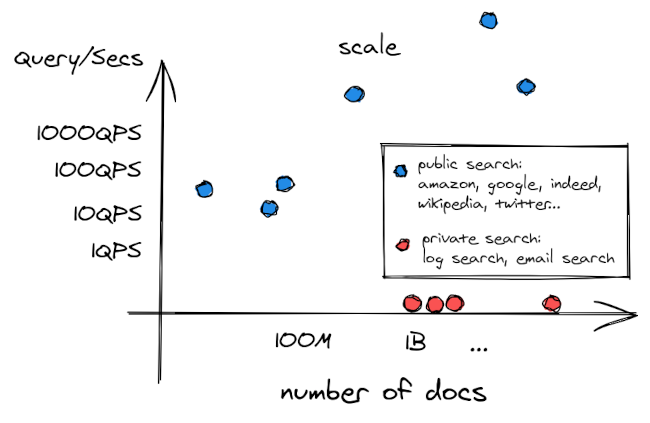
문서 수 / QPS의 비율이 근본적으로 다릅니다. 물론 Google은 엄청나게 많은 웹 페이지를 검색합니다... 하지만 비례해서 트래픽은 더 큽니다! 반면, 중간 규모로 성공한 스타트업은 검색해야 할 로그가 수백 GB에 달할 수 있지만, 하루 쿼리는 100건도 안 될 수 있습니다.
예상하셨겠지만, 이 두 유형의 검색 엔진 비용 모델은 극적으로 다릅니다!
예를 들어 성공적인 이커머스 웹사이트를 운영한다면, 가장 비싼 하드웨어 비용은 검색에 쓰이는 연산(CPU+RAM) 시간일 가능성이 큽니다. 또한 검색 엔진의 투자 대비 수익률이 충분히 높아서 비용 효율은 마지막 걱정거리일 수 있습니다. 황금알을 낳는 거위를 지나치게 아끼고 싶어 하는 사람은 없으니까요!
반면 전형적인 로그 검색 엔진을 생각해 보면, 방정식은 완전히 달라집니다... SSD가 갑자기 하드웨어 비용의 절반을 차지합니다. 나머지 비용은 컴퓨팅 파워인데, 서버 CPU는 대부분의 시간을 놀고 있습니다. 그다음으로 바쁜 일은 인덱싱입니다... 그리고 때때로 마법 같은 일이 일어납니다. 사용자가 와서 쿼리를 실행합니다. 그러면 CPU 코어들이 일제히 깨어나 최대한 빨리 결과를 반환하느라 바빠집니다... 그리고 다시 낮잠으로 돌아갑니다.
Elasticsearch는 공개 검색 문제를 염두에 두고 설계되었고, 이를 훌륭하게 해결합니다. Quickwit에서는 프라이빗 검색 엔진의 현상 유지를 깨기 위해, 그 아킬레스건인 비용 효율에 정확히 초점을 맞추기로 했습니다.
Quickwit 검색 엔진의 핵심은 tantivy를 기반으로 합니다. tantivy는 Lucene과 유사한 Rust 라이브러리로, 저희가 자랑스럽게 사용하고 유지보수하고 있습니다. 하지만 tantivy는 어디까지나 라이브러리입니다. 성능이 아무리 좋더라도, 인덱싱과 검색을 수평 확장할 메커니즘을 제공하지는 않습니다. 이것이 첫 번째 Quickwit 도전 과제였습니다.
가장 명확한 ‘쉽게 딸 수 있는 열매’는 인덱싱입니다.
저희의 해법은 단순합니다. 데이터를 한 번만 인덱싱하고, 오브젝트 스토리지에 업로드해 어떤 인스턴스에서든 사용할 수 있게 합니다. 복제는 오브젝트 스토리지가 처리합니다. 이렇게 인덱싱을 한 번만 하고 인덱스 세그먼트를 복제하는 접근은 일반적으로 세그먼트 복제(segment replication)라고 부릅니다. 반면 Elasticsearch는 문서 복제(document replication)에 의존합니다.
동기화된 각 레플리카 사본은 사본을 보유하기 위해 인덱싱 작업을 로컬에서 수행합니다. 인덱싱의 이 단계가 레플리카 단계입니다. Elasticsearch docs
바로 여기서 인덱싱에 쓰이는 CPU 시간을 3분의 1로 줄입니다.
다음 단계는 더 어렵습니다. CPU의 유휴 시간을 줄이고 싶습니다. 이를 위한 유일한 방법은 “컴퓨트 하드웨어”가 인덱스의 특정 조각에 묶이지 않도록 하는 것입니다. 사람들은 이 특성을 스토리지와 컴퓨트를 분리(separating storage and compute)라고 부릅니다...
도전 과제를 이해하기 위해, 이를 3개의 하위 문제로 나눠봅시다.

무상태(stateless) 검색은, 서서 출발하는 경주와 비슷합니다. 쿼리를 받는 순간이 старт용 총성이 울리는 첫 소리와 같습니다. 그 소리를 듣는다면, 즉시 준비되어 있어야 합니다.
큰 인덱스를 여는 작업은 보통 여러 파일 위치에서 각종 메타데이터를 로드해야 합니다. SSD에서는 1초가 걸릴 수 있습니다. S3에서는 몇 분이 걸릴 수도 있습니다.
이를 해결하기 위해, 작은 hot-start 번들을 사용해 S3에서 바로 70ms 만에 ‘터보 스타트’를 합니다.
S3는 처리량이 SSD보다 약 20배 낮아 좋지 않은 것으로 알려져 있습니다. 하지만 S3에 병렬 요청을 보낼 수 있다면 더 이상 그렇지 않습니다.
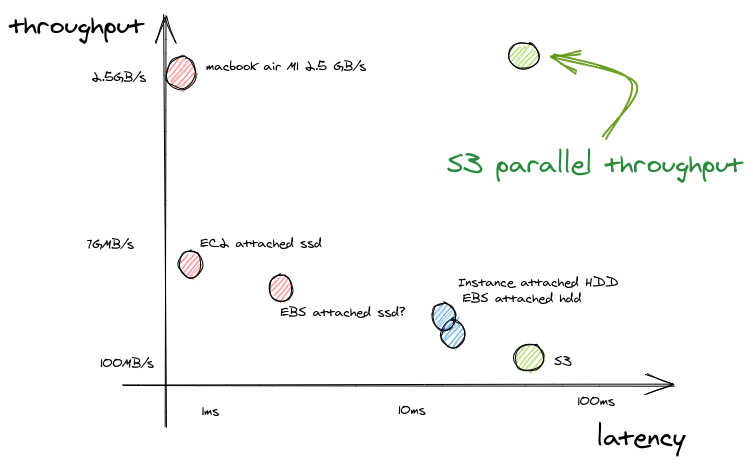
검색 엔진은 일반적으로 OS가 IO 스케줄링과 프리페치(prefetching)를 해주길 기대합니다. Quickwit은 자체적으로 IO를 스케줄링하고, 가능한 처리량을 극대화하기 위해 데이터를 동시에 다운로드합니다. 실제로는 쿼리 수행 구간 동안 1GB/s의 처리량을 관찰합니다. 이는 SSD에서 기대할 수 있는 대역폭 수준입니다.
S3로의 라운드 트립마다 고통스러운 60ms가 또 낭비됩니다. 마치 주방과 식탁이 200m 떨어진 식당을 운영하는 것과 같습니다. 웨이터라면 왕복 횟수를 최소화하고 싶을 겁니다.
Quickwit은 랜덤 시크(random seek)가 단 3번만 발생하는 크리티컬 패스로도 검색이 가능하도록 커스텀 인덱스 포맷을 사용합니다.
이 마지막 과제를 해결함으로써, 마침내 컴퓨트와 스토리지가 진정으로 분리된 검색 엔진을 제공할 수 있게 되었습니다. 그리고 이는 많은 이점을 열어줍니다.
그리고 이는 릴리스와 함께 이제 막 공개하기 시작한, 단순화된 고가용성 같은 다양한 가능성도 제공합니다.
이제 오늘 무엇을 배포하는지 이야기해 볼 시간입니다.
이번은 첫 번째 릴리스이며, 비용 효율적인 검색 엔진의 기반을 마련합니다.
구체적으로 Quickwit 0.1은 다음과 같은 주요 기능을 갖춘 검색 클러스터를 생성, 인덱싱, 서빙할 수 있는 커맨드라인 인터페이스 형태로 제공됩니다.
quickstart guide를 확인하고 docs를 읽어보세요. 그리고 가장 호기심 많은 분들을 위해, 깔끔하고 단순하게 만들기 위해 시간을 들였으니 code도 살펴보시길 권합니다.
단기적으로는 버그 수정과 피드백 반영에 집중할 예정입니다. 로드맵은 대리석에 새겨진 것이 아니지만, 향후 몇 달 동안 염두에 두고 있는 것들을 이미 공유할 수는 있습니다.
여러분의 사용 사례를 들려주시면 정말 좋겠습니다. 로드맵에서 기능 우선순위를 정하는 데 큰 도움이 됩니다.
즐거운 테스트 되세요!