수만 개의 줄 기반 텍스트 파일에서 스캔 오류를 찾아 맥락 속에서 검토하고, 텍스트 편집기로 한꺼번에 수정할 수 있도록 `ripgrep` 위에 구축한 도구 Okapi를 소개합니다.
![]() 수만 개의 줄 기반 텍스트 파일에서 스캔 오류를 고쳐야 했기 때문에, 맥락 속에서 그것들을 찾고 텍스트 편집기를 사용해 한꺼번에 수정할 수 있도록
수만 개의 줄 기반 텍스트 파일에서 스캔 오류를 고쳐야 했기 때문에, 맥락 속에서 그것들을 찾고 텍스트 편집기를 사용해 한꺼번에 수정할 수 있도록 ripgrep 위에 Okapi라는 도구를 만들었습니다. homebrew로 설치할 수 있습니다.
이 프로젝트는 미국 정부 직원 데이터 수만 쪽을 디지털화하는 작업입니다. 이름은 Official Register이며, 150년에 걸쳐 100권이 넘는 책이 있습니다. 저는 olmOCR로 큰 성과를 거두었는데, 기본 Tesseract보다 훨씬 정확하기 때문입니다. 하지만 그래도 스캔 오류를 아주, 아주 많이 만들어 냅니다.
OCR이 만들어 내는 정말 흔한 문자 시퀀스 가운데, 거의 항상 틀린 것은 III입니다. 드문 경우에는 정말로 그 사람이 아버지와 할아버지와 같은 이름을 뜻하기도 합니다. 하지만 제가 작업하던 텍스트는 이런 모습이었습니다:
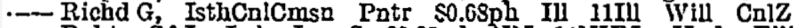 이것은 Richard가 Isthmian Canal Commission에서 시간당 68¢를 받는 Painter로 일했다는 뜻입니다. 그는 Illinois에서 태어났고, Illinois 제11 연방하원의원 선거구 Will 카운티에서 그 직위에 임명되었으며(채용되었으며), Panama Canal Zone에 배치되었습니다. (이 내용은 1909년판 1권의 144쪽에서 가져왔습니다.)
이것은 Richard가 Isthmian Canal Commission에서 시간당 68¢를 받는 Painter로 일했다는 뜻입니다. 그는 Illinois에서 태어났고, Illinois 제11 연방하원의원 선거구 Will 카운티에서 그 직위에 임명되었으며(채용되었으며), Panama Canal Zone에 배치되었습니다. (이 내용은 1909년판 1권의 144쪽에서 가져왔습니다.)
보시다시피 “수직선” 문자들이 엄청나게 많을 수 있습니다! 이것은 어떤 OCR에게도 일종의 스트레스 테스트이고, 이미지 품질도 상황에 도움이 되지 않았습니다. 제 데이터셋에서 III는 거의 항상 스캔 오류라고 해도 충분합니다. 다음은 몇 가지 예입니다:
| OCR text | Corrected text |
|---|---|
RosedaleIII | RosedaleIll |
Rock IslandArsnIllIII | RockIslandArsnlIll |
RockIsland ArsmllIII | RockIslandArsnlIll |
IIIllaSalle | IllLaSalle |
2IIIISangamon | 21IllSangamon |
IIIpr | Hlpr |
NIIIVS | NHDVS |
이 밖에도 훨씬 더 많은 변형이 있습니다. 사실 III는 텍스트 어딘가에 문제가 있다는 신호입니다. 이것을 무턱대고 Ill로 바꾸면 일부 경우는 고쳐지겠지만, 잘못된 텍스트를 만들어 내는 경우도 많고 근처에 숨어 있는 다른 스캔 오류들을 오히려 더 찾기 어렵게 만들기도 합니다.
ripgrep으로 정규식을 사용해 관심 있는 문자열을 찾는 것은 좋았지만, 그래도 훨씬 너무 느렸습니다. 때로는 일치 항목이 수백 개나 있어서, 맥락을 파악하고 한두 줄을 수정하고 저장하려고 파일을 하나씩 열 수는 없었습니다. 저는 정규식의 정밀함과 텍스트 편집기의 강력함이 결합된 것이 필요했습니다.
여기서 Okapi가 등장합니다:
$ okapi III
$ okapi "Dan[^l ]\b" # 아마도 약어 "Danl"이어야 함
$ okapi "Mich\wl" -e "Michel" # 제외 패턴 전달
$ okapi Fli -c ..15 # 일치 범위를 처음 15글자로 제한
이제 저는 대체 문자열이 정확히 무엇인지 몰라도 파일 전반에 걸쳐 비슷한 오류를 수정할 수 있습니다. 일치하는 항목들을 한 페이지에 펼쳐 한눈에 볼 수 있습니다. 또한 다중 선택의 모든 기능도 사용할 수 있습니다. Asciinema 데모와는 달리, 저는 Sublime의 다중 선택 기능을 사용해 일부 하위 패턴의 모든 인스턴스를 잡아 한 번에 바꾸고 있습니다. 그런 다음 다른 하위 집합을 정밀하게 찾아 바꿀 수 있습니다. 작업이 끝나면 모든 내용이 다시 디스크에 저장됩니다.
편집 버퍼는 이렇게 생겼습니다:
# --- Begin editable lines ---
A 76 ▓ — Richd G, IsthCnlCmsn Pntr $0.65ph Ill 11Ill Will CnlZ
B 22 ░ Richd G, IsthCnlCmsn Clk $125pm Eng 5GaFulton CnlZ
B 40 ░ Mrs Rosa J, Treas PrtnrsAsst Engrv&Prntg $1.50pd DC DC DC
# --- File Aliases ---
# A = /Users/nick/offreg/olmocr/1909/150-column_0.md
# B = /Users/nick/offreg/olmocr/1909/708-column_1.md
저는 git의 대화형 rebase 인터페이스에서 영감을 받았습니다. 첫 번째 열의 별칭 문자는 각 줄을 해당 파일과 연결합니다. 그다음에는 줄 번호와 구분 문자가 오는데, 이것은 파일별로 줄들을 시각적으로 나누는 역할도 합니다. 현재 별칭은 최대 3개의 대문자 알파벳으로 제한되지만, 그래도 18,000개가 넘는 파일을 표현할 수 있습니다. 이 정도면 누구에게나 충분할 겁니다!
모든 일치 줄을 하나의 버퍼에 모으는 것은 큰 진전이지만, 제 경우에는 그것만으로는 충분하지 않았습니다. 특정 줄의 바로 아래에 원본 이미지를 보여 주는 방법도 필요했습니다. 그러면 최고 효율로 실제 정답을 볼 수 있습니다. 예를 들어 Wrn은 분명히 Wm이어야 합니다. 하지만 Fli 같은 접두사는 모호합니다. 어떤 경우에는 이것이 Eli (Elizabeth)여야 합니다. 하지만 똑같이 Fli (Flin)나 Ell (Ella)도 맞을 수 있습니다. 맥락이 핵심입니다.
제가 사용한 전략은 다음과 같습니다:
그리고 어떨까요? 정말로 작동합니다!

더 많은 정보를 원하시면 연락해 주세요. Okapi 저장소의 Issues나 PRs도 기쁘게 받습니다. 이름 데이터베이스는 아직 온라인이 아니지만, 곧 공개할 예정입니다!