Yelp는 파티션 수준 액세스 패턴을 시각화해 데이터 소비 방식을 파악하고, Apache Iceberg 마이그레이션 우선순위를 정하며, 데이터 레이크의 S3 스토리지 비용을 33% 절감했습니다.
대규모 분석 환경에서 데이터 팀은 누가 이해관계자인지, 그리고 데이터가 어떻게 사용되고 있는지와 같은 겉보기에 단순한 질문에 답하는 데 종종 어려움을 겪습니다. Yelp에서는 시간 기반 파티션 키 값을 액세스 이벤트 타임스탬프에 대응시켜 시각화함으로써 이 문제를 해결합니다. 이러한 시각화는 애드혹 쿼리, 일별 배치 작업, 주기적인 백필과 같은 뚜렷한 사용 시그니처를 드러내며, 데이터 소유자가 자신의 이해관계자와 사용 사례를 이해할 수 있게 해줍니다. 데이터 사용에 대한 이러한 더 깊은 통찰은 수천 개의 테이블을 Apache Iceberg 형식으로 마이그레이션하고, 페타바이트 규모 데이터 레이크 비용을 33% 절감한 스토리지 효율화 지점을 식별하는 등 영향력 높은 플랫폼 이니셔티브를 가능하게 했습니다.
데이터 기반 사용 귀속이 없으면 팀은 이해관계자와의 대화, 문서, 구전 정보에 의존하게 되는데, 이러한 정보원은 금세 오래됩니다. 이로 인해 데이터 소유자는 자신의 데이터를 효과적으로 관리하기 어려워지고, 플랫폼 팀이 자율적으로 제공할 수 있는 지원도 제한됩니다. 세분화된 사용 귀속은 데이터가 어떻게 소비되는지에 대한 명확한 통찰을 제공하여 이 문제를 해결하고, 상당한 비용 효율화 기회를 열어줍니다.
날짜로 파티셔닝된 분석 테이블(dt=yyyy-mm-dd)이 주어졌을 때, 액세스된 파티션과 이벤트 시간을 함께 도식화할 수 있습니다.
시각화에는 데이터에 액세스하는 엔터티도 포함합니다. Yelp는 AWS에서 운영되므로, 여기서 엔터티는 IAM 역할이며, 역할 이름은 서비스 또는 팀과 연결됩니다.
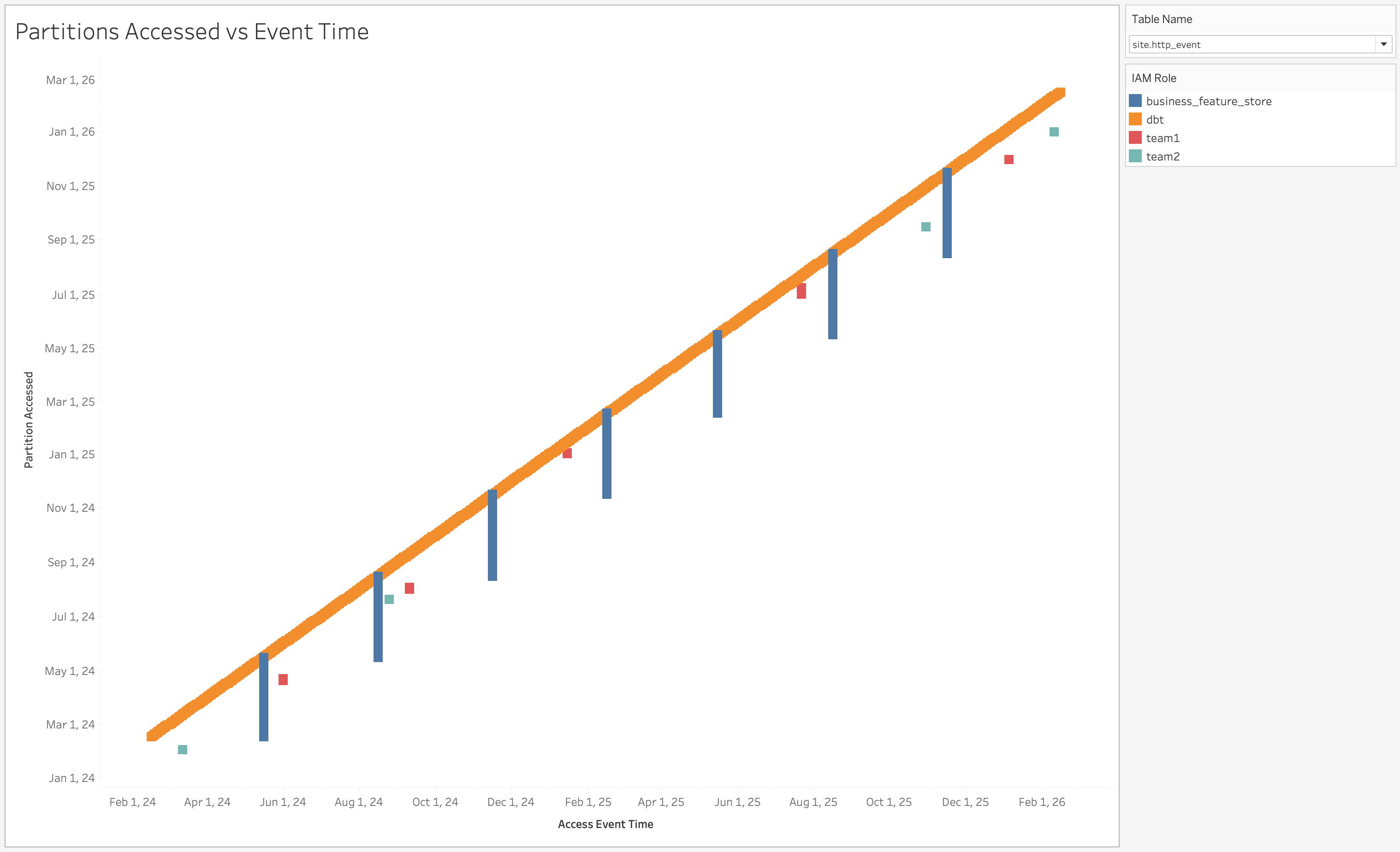
데이터 소유자는 또한 일반적으로 “지난 N개월 동안 테이블 X의 액세스 패턴은 어떠한가?”와 같은 시간 경과에 따른 액세스 패턴에도 관심이 있습니다. 두 번째 시각화는 이 질문에 답합니다.
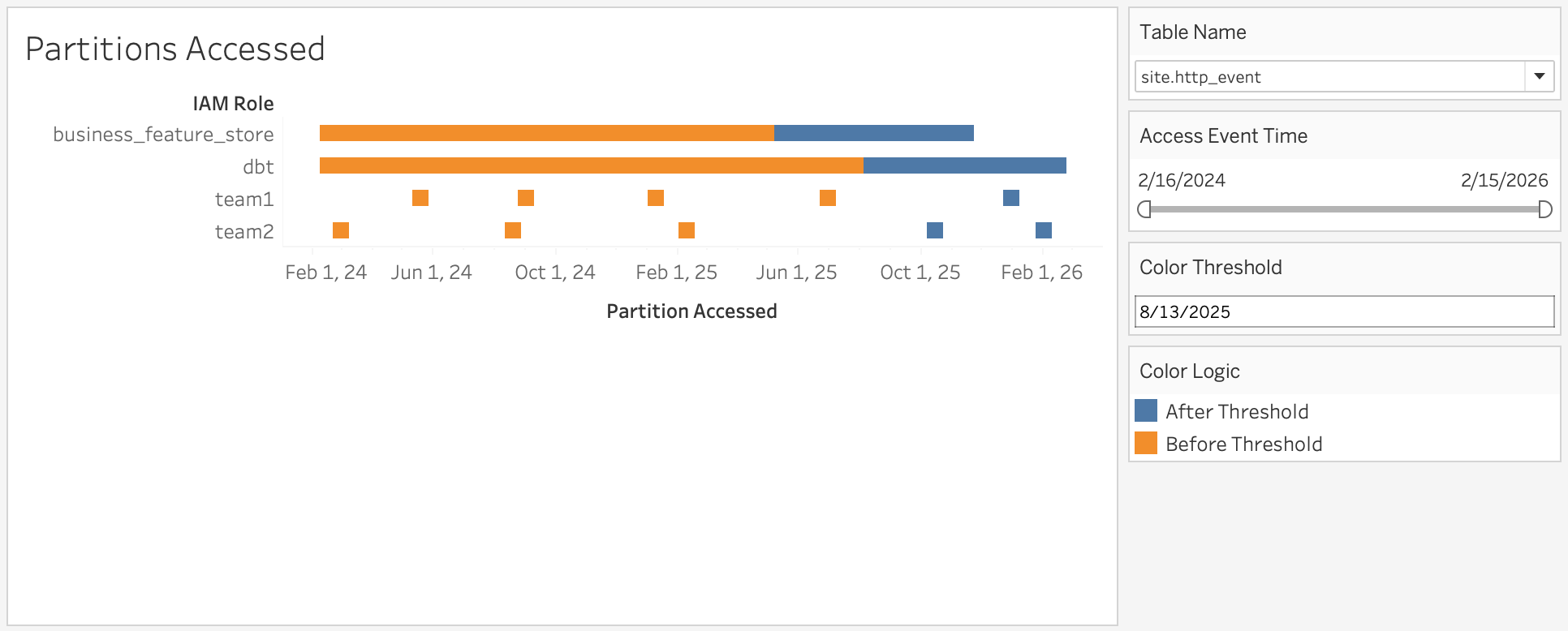
우리는 Apache Iceberg 도입의 우선순위를 정하기 위해 활성 테이블과 파티션을 식별하는 것에서 시작했지만, 곧 기회가 더 크다는 것을 깨달았습니다. 파티션 수준 사용 데이터는 플랫폼 팀의 세 가지 주요 축 전반에 걸쳐 의미 있는 개선을 제공할 수 있었습니다.
명확하게 정의된 액세스 패턴이 없으면, 요구사항이 바뀔 가능성 때문에 데이터 소유자가 삭제 기반 보존 기간을 더 늘리기 어려울 수 있습니다. 마찬가지로, 콜드 스토리지 제품에 최소 저장 기간과 액세스당 수수료가 있을 때는 콜드 스토리지 정책을 확정하기도 어렵습니다.
우리는 세분화된 사용 데이터가 팀이 이러한 결정을 자신 있게 내릴 수 있도록 해준다는 것을 발견했습니다. 이 세분화된 데이터는 삭제 기반 보존 확대와 더 비용 효율적인 S3 Storage Classes 적용을 가능하게 했고, 그 결과 S3 스토리지 비용을 33% 절감했습니다.
데이터세트의 액세스 패턴을 예측하기 어려운 경우 기본값으로 S3 Intelligent Tiering을 사용합니다. 이 방식의 핵심 장점은 액세스가 줄어들면 비용도 자동으로 낮아지고, 액세스 패턴이 바뀌더라도 불이익이 없다는 점입니다. 이는 최소 저장 기간과 검색 수수료가 부과되어 예상보다 더 자주 데이터에 액세스할 경우 절감 효과를 상쇄할 수 있는 콜드 스토리지 클래스(예: S3 Glacier)와는 대조적입니다.
S3 Intelligent Tiering을 통한 절감 효과는 상당할 수 있습니다. 30일 동안 액세스되지 않은 객체는 비용이 40% 감소하고, 90일 동안 액세스되지 않은 객체는 비용이 81% 감소합니다. 후자의 경우 S3 Glacier 비용 수준에 근접합니다!
실제 액세스 패턴을 보여주는 세분화된 사용 데이터 덕분에, 데이터 소유자는 자신의 분석 테이블에 더 비용 효율적인 스토리지 클래스를 자신 있게 할당할 수 있었습니다.
데이터 소유자가 미래 요구사항의 불확실성 때문에 삭제 기반 보존이나 콜드 스토리지를 더 확대할 수 없는 경우를 위해, 우리는 중간 지점을 도입했습니다. 즉, 예상 액세스 기간을 정의하고 액세스 기반 보존을 구현한 것입니다.
Default Access Retention 기간을 지난 데이터는 여전히 S3에 남아 있지만, 명시적인 절차를 거쳐야만 액세스할 수 있도록 제한적인 S3 버킷 IAM 정책 뒤에 놓입니다. 데이터 소비자는 제한된 파티션에 대한 임시 액세스를 요청하기 위해 Terraform PR을 올리고, S3 Inventory를 기반으로 구축된 대시보드를 사용해 관련 비용을 추정합니다. 이 대시보드는 범위에 포함된 데이터 양과 현재 S3 Storage Classes를 사용해 액세스 비용을 추정합니다. 비용 규모에 따라 특정 승인 수준이 요구됩니다. 이는 다음과 같은 이점을 제공합니다.
Yelp는 AWS에서 운영되므로, 사용 귀속 시스템은 Amazon S3 server access logging을 기반으로 구축되었습니다. 이를 대규모로 비용 효율적으로 활성화하는 방법은 S3 server access logs에 대한 Yelp Engineering Blog 게시물을 참고하세요. 서버 액세스 로그를 데이터 레이크 테이블에서 사용할 수 있으면, SQL 엔진을 사용해 테이블, 파티션, 엔터티(IAM 역할)별 사용 데이터를 집계할 수 있습니다.
배치 기반 아키텍처는 아래와 같습니다.

SQL 변환의 상위 수준 개요는 다음과 같습니다:
INSERT INTO table_usage_aggregated
SELECT
COUNT(1) AS ct,
requester AS iam_role,
"timestamp" AS event_time,
KEY_TO_TABLE_NAME(key) AS table_name, -- Change to function relevant to your data storage structure
KEY_TO_PARTITION_VALUE(key) AS partition_value -- Change to function relevant to your data storage structure
FROM
s3_server_access_logs_compacted
WHERE
bucket_name IN ('BUCKET1', 'BUCKET2') -- Change to your bucket names
AND "timestamp" = 'yyyy/mm/dd' -- Access event time
AND operation = 'REST.GET.OBJECT'
AND key LIKE 'prefix_to_include%'
GROUP BY
2, 3, 4, 5
KEY_TO_TABLE_NAME 및 KEY_TO_PARTITION_VALUE 함수 대신, 데이터베이스 이름, 테이블 이름, 테이블 위치, 파티션 스펙을 포함한 카탈로그 메타데이터와 조인할 수도 있습니다.
또한 분석 테이블에 정의된 스토리지 클래스와 사용량의 관계를 이해하기 위해 S3 Inventory와 조인하는 것도 유용할 수 있습니다.
데이터 플랫폼에 파티션 수준 액세스 가시성을 구축함으로써, Yelp의 데이터 플랫폼 팀은 활성 분석 데이터를 Iceberg로 더 빠르게 마이그레이션하고, Yelp의 데이터 관리 관행을 강화하며, 페타바이트 규모 데이터 레이크에 상당한 비용 효율화를 제공할 수 있었습니다. 대규모로 분석 데이터를 저장하고 있다면, 이 접근 방식은 여러분에게도 도움이 될 수 있습니다. 이 노력의 성공에 힘입어, 우리는 계보와 세분화된 사용 귀속을 더욱 강화하기 위해 데이터 인프라의 다른 영역에도 투자하고 있습니다.
이번 작업의 개발에 기여한 Rishi Madan, Yelp의 AWS 인프라 전반에서 S3 Server Access Logs를 활성화할 수 있도록 지원한 Yelp Infrastructure Security 팀(Vincent Thibault, Quentin Long, Nurdan Almazbekov), 그리고 이번 작업에 협력한 대규모 분석 테이블 소유 팀 모두에게 감사드립니다.
Yelp에서는 흥미로운 과제들을 해결하고 있습니다. 함께하고 싶으신가요? 지금 지원하세요!