LLM과 AI 코딩은 엔지니어링, 생산성, 교육, 평가 방식을 어떻게 바꾸고 있으며 왜 비판적 사고가 그 어느 때보다 중요한지에 대한 고찰입니다.
며칠 전, 제 블로그 독자 한 분이 제게 메시지를 보내왔습니다:
“안녕하세요 Erich, 저는 오랫동안 당신의 글을 읽어왔습니다. 당신은 제 직업 경력의 기둥 같은 존재라고 생각합니다. 감사합니다. 이제 하나 여쭤보고 싶습니다. LLM과 임베디드에서의 LLM 코딩에 대해 어떻게 생각하시나요? 제 고용주는 1/2년 안에 모든 것이 AI로 대체될 것이기 때문에 사람 채용을 멈출 때라고 생각합니다. 저는 그렇게 생각하지 않습니다. 당신은 코딩에 LLM을 사용하시나요? 이에 대해 어떻게 생각하시나요? 미리 감사드립니다.”
TL;DR: LLM은 변화하고 개선되고 있으며, 이는 좋은 엔지니어링과 교육을 더욱 중요하게 만듭니다. 연구에 따르면 AI는 유용할 수 있지만, 생산성이 항상 증가하는 것은 아닙니다. AI 코딩은 비판적 사고와 책임을 줄이는 것이 아니라 더 많이 요구합니다. 엔지니어링과 교육은 이를 받아들이고 변화해야 합니다. 여기에는 평가와 교수법의 변화, 종이 시험으로의 회귀, 그리고 작업 결과를 직접 방어하는 방식이 포함됩니다. AI 시대에는 배우는 법을 배우는 것이 가장 중요한 역량이 되고 있습니다.
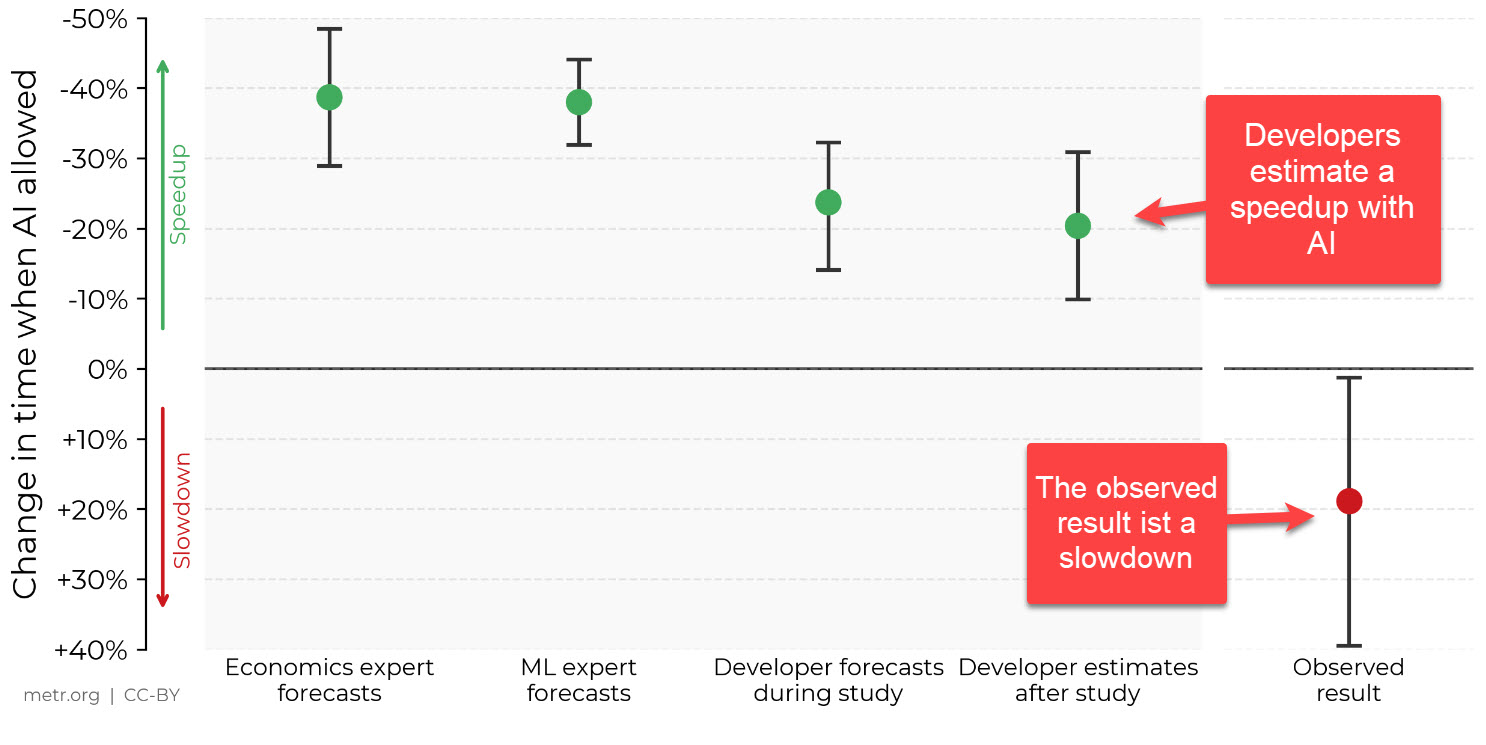
경험 많은 오픈 소스 개발자의 속도를 늦추는 AI (출처: https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/)
이 글에서는 제가 가진 생각과 관찰을 정리해 보려고 합니다.
지난 며칠 동안 이 주제에 대해 곰곰이 생각해 볼 시간을 조금 가졌습니다. 아시다시피 저는 엔지니어링, 연구, 교육을 모두 하고 있습니다. 그리고 2025년은 매우 도전적인 한 해였습니다.
저는 코딩뿐 아니라 그 밖의 일에도 LLM(Large Language Models)을 사용합니다. 업계의 다른 많은 사람들처럼 저 역시 이 기계들을 실험하고 있습니다. 여기에서 공유하고 싶은 것은 몇 가지 사례와 관찰입니다. 제 자신의 LLM 사용 방식, 그리고 다른 사람들에게서 제가 보고 있는 것들에 대한 이야기입니다.
이 기술로 어떤 결과들이 나올 수 있는지 보는 것은 놀랍다고 생각합니다. 하지만 현재의 과열된 분위기 속 많은 부분이 마케팅이라는 점에서 조심해야 한다고 생각합니다. 이제서야 연구가 무엇이 잘 작동하고, 무엇이 그렇지 않으며, 문제가 어디에 있는지에 대한 결과를 보여주기 시작했습니다. 의사결정자들(위 메시지의 경우처럼)은 이 기계 뒤에 있는 기술을 이해해야 합니다. 이 기계들이 무엇을 잘할 수 있는지 알아야 합니다. 그리고 무엇을 못하는지도 알아야 합니다. 그렇지 않으면 잘못된 결정을 내리게 됩니다.
여기서 LLM에 대한 입문 설명을 하려는 것은 아닙니다. 이미 훌륭한 자료가 많이 있습니다. 기억해야 할 핵심은 모델이 계속 진화하고 있더라도 핵심 개념은 그대로라는 점입니다. 저는 다양한 AI 모델과 구현을 모두 아는 ‘전문가’는 아닙니다. 그럴 필요도 없습니다. 저는 경험이 있습니다. 실제로 사용해 보았고, 모델을 구현하고 학습시켜 보기도 했습니다.
다음 부분에서는 다음 주제들을 다룹니다:
저는 거의 매일 LLM을 사용합니다. 하지만 기밀 정보, 민감한 데이터, 개인정보와 함께 사용하는 일은 절대(정말 절대!) 없습니다. 또한 제가 최종 판단과 책임을 지지 않는 어떤 ‘자동’ 작업이나 ‘에이전트’에도 사용하지 않습니다.
저는 직접적인 코딩에는 LLM을 많이 쓰지 않으며, 사용하더라도 Claude와 CoPilot을 함께 사용합니다. 여기서도 다시 말하지만, 코드는 전적으로 제가 책임집니다. 여기에는 사용된 코드의 IP에 대한 명확한 인식도 포함됩니다.
코드 문서화와 관련된 일에는 CoPilot을 사용합니다. 예를 들어 인터페이스 설명, 문서 헤더 추가, 주석 문구 다듬기, 또는 테스트 케이스 제공 같은 작업입니다.
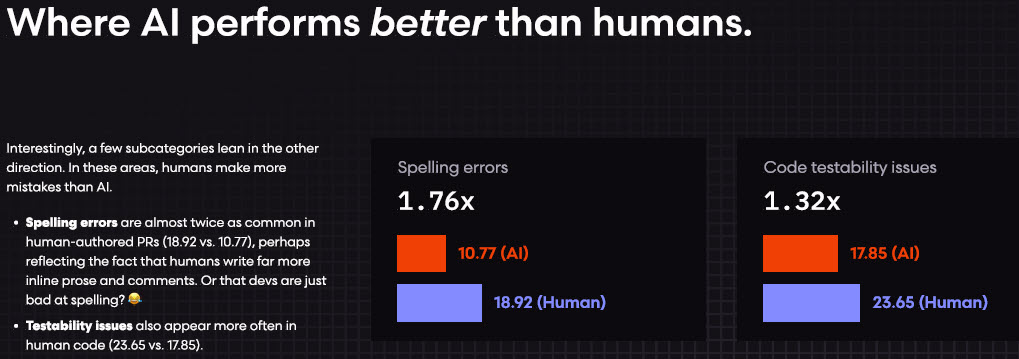
AI가 인간보다 더 잘 수행하는 영역 (출처: CodeRabbit)
저는 코드 조각 리뷰나 아이디어, 개념 탐색에는 Claude를 사용합니다. 보통은 예를 들어 ChatGTP보다 더 나은 결과를 줍니다. 특히 ‘잘 알려진’ 개념에는 잘 작동합니다.
Claude의 답변 예시
저는 브레인스토밍이나 아이디어 발굴에는 ChatGTP를 사용합니다. 예를 들어 ‘X를 하는 이 프로젝트에 멋진 이름을 지어줘’ 같은 일입니다.
더 사실 기반의 정보가 필요할 때는 Perplexity를 사용합니다. 예를 들어 좋은 웹 링크에 대한 인용이 필요할 때입니다.
또는 WordPress의 AI 애드온을 사용해 이 글의 더 좋은 제목을 제안받기도 합니다.
저는 LLM이 저에게 답이나 해결책을 주도록 하기보다는, 제가 스스로 해결책을 찾아야 하는 질문을 만들어 달라고 요청하려고 합니다. 학생들과 학습 측면에서 바로 이 지점이 LLM이 빛나는 부분입니다. 질문을 만들어 달라고 하세요! 그다음 스스로 해결책을 찾고 동료들과 함께 검토하고 토론하세요.
그 후 LLM은 제가 찾은 해결책에 대한 개선 아이디어를 제시할 수 있습니다. 이것이 비판적 사고와 결합될 때 진정한 부가가치가 생깁니다. 저는 LLM을 가상의 스파링 파트너처럼 사용합니다.
개인적으로 저는 LLM과 AI에 대해 복합적인 감정을 가지고 있습니다. 올바르게 사용한다면 유용한 도구라고 봅니다. 기술이 여전히 진화 중이고 놀라운 것들을 보여준다는 점도 느낍니다.
저를 짜증 나게 하는 것은 AI가 생성한 스팸 이메일들입니다. 왜 AI 에이전트가 이메일을 보내거나 포럼에 글을 올리게 해야 할까요? Rob Pike가 며칠 전 bsky.app에서 자신의 경험을 공유했습니다:
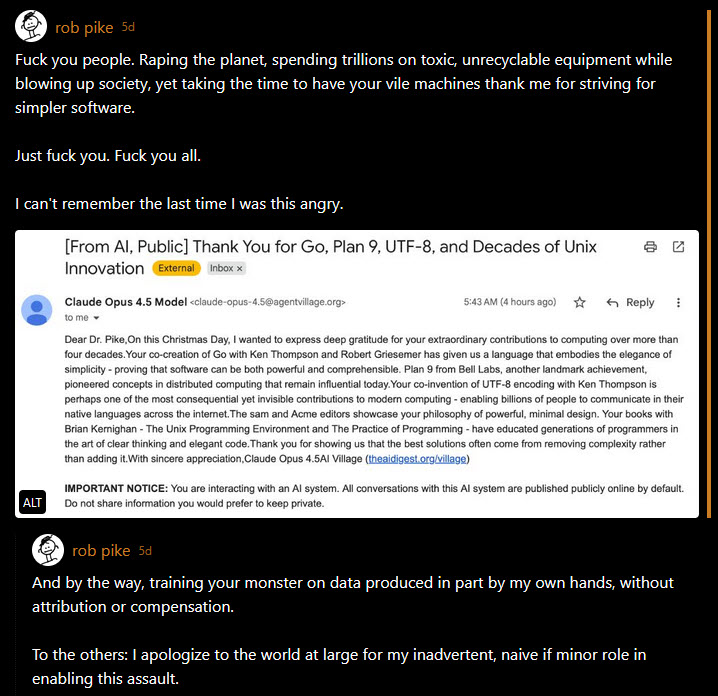
출처: https://bsky.app/profile/did:plc:vsgr3rwyckhiavgqzdcuzm6i/post/3matwg6w3ic2s
반면에 어떤 사람들은 LLM에 감정적으로 애착을 갖는 것처럼 보입니다. 무슨 말이냐 하면, LLM의 실패 사례를 매우 개인적으로 받아들인다는 것입니다. 마치 그 기계를 ‘변호’해야 하는 것처럼요. 기계의 잘못이 아니라 내가 올바른 프롬프트를 사용하지 않았을 뿐이라거나, 그것은 과거의 문제였고 이제는 model xyz.v200이 모두 해결했다고 말하는 식입니다.
가끔은 어떤 사람들은 이 기계를 우리가 신뢰해야 할 새로운 ‘초지능’으로 보는 것처럼 느껴집니다. 때로는 하나의 ‘종교’처럼 느껴집니다. 루체른의 성 베드로 교회에 설치된 ‘Deus in Machina’ 혹은 ‘AI-Jesus’는 적어도 예술 설치물(고해성사는 아님!)로 선언되기는 했습니다. 900개의 대화에 대한 결과는 보고서로 공개되었습니다.

Deus in Machina (출처: https://www.kathluzern.ch/mein-engagement/deus-in-machina)
저는 이것이 기이하다고 생각합니다. 포럼의 일부 ‘전도사’들은 ‘종말이 가까웠다’고 주장합니다. AI가 모든 소프트웨어 개발을 대체할 것이라고 말합니다.
이런 AI 과열과 무분별한 주장이 가져오는 진짜 해악은 젊은 엔지니어들을 위축시킨다는 점입니다. 그들은 컴퓨터 과학, 프로그래밍 또는 관련 분야를 배우는 일을 꺼리게 될 수 있습니다. 하지만 컴퓨터, 소프트웨어 엔지니어링, 임베디드 개발은 단순한 ‘코딩’ 이상입니다. 문제를 이해해야 하는데, AI는 그것을 할 수 없습니다. 현실의 새로운 문제를 해결하기 위해 혁신적이고 창의적이어야 합니다. 미래는 문제 해결사와 비판적 사고를 하는 사람들의 것이지, ‘통계적 앵무새’의 것이 아닙니다.
스타트업 AI 기업들의 과장된 홍보와 주장들은 이미 부정적인 영향을 주고 있는 듯합니다. 의사결정자나 채용 관리자들이 혼란을 겪고 있습니다. 이 글 처음의 독자 메시지를 보세요. 또는 Stanford의 소프트웨어 엔지니어링 졸업생들이 일자리를 찾는 데 어려움을 겪는다는 기사를 보세요:
“채용 관리자들 사이에서 흔한 정서는, 이전에는 엔지니어 10명이 필요했던 일을 이제는 ‘숙련된 엔지니어 두 명과 LLM 기반 에이전트 하나’만 있으면 되고, 그것도 같은 수준의 생산성을 낼 수 있다는 것입니다.”라고 University of Southern California의 컴퓨터 과학 교수 Nenad Medvidović는 말했습니다. (Los Angeles Times)
이 문제는 현실적이고 심각합니다. 졸업생을 채용하지 않으면서 어떻게 새로운 숙련 엔지니어를 키울 수 있을까요? 졸업생들이 실무에서 배우고 경험을 쌓을 기회를 얻지 못한다면 어떻게 될까요?
제가 보는 것은 공학 석사 과정에 대한 관심 증가입니다. 일부 학생들은 학부 졸업 후 바로 취업시장에 들어가기보다, 학사 학위를 석사로 확장하기로 결정합니다. 이를 위해 추가로 2년의 석사 과정을 밟습니다. 석사 학위는 기본 기술을 넘어섭니다. 새로운 영역을 연구하고, 비판적인 질문을 던지고, 어려운 문제를 해결하는 과정입니다. 오늘날의 LLM 기술이 할 수 없는 일입니다.
제가 보기에는 ‘순수 소프트웨어 엔지니어링’이 ‘전기공학’이나 임베디드 시스템 분야보다 더 큰 영향을 받고 있습니다. 물론 이는 미래에 바뀔 수 있습니다. 엔지니어링 업무가 웹 페이지를 만드는 일이라면 LLM은 꽤 효과적일 수 있습니다. 모바일 애플리케이션이나 데이터를 조작하는 스크립트 작성에도 유용합니다. 적어도 프로토타입 수준에서는 특히 효과적입니다. 따라서 그런 분야에서 일하고 있다면 어느 정도는 위험할 수 있습니다.
적어도 지금으로서는 LLM은 ‘범용’ 목적의 일에 훌륭합니다. 왜냐하면 인터넷에서 찾은 코드로 학습되었기 때문입니다. 그리고 더 일반적일수록 더 잘합니다. 하지만 실제의 구체적인 시스템으로 내려가면 상황은 더 복잡합니다:
“더 흔하지 않은 도구와 인터페이스를 만나게 되고, 결국은 새로운 것이 필요해지기 때문에 더 어렵습니다. 예를 들어 AI는 stm32의 중요한 레지스터 대부분은 아마 맞게 추측할 수 있겠지만, 더 생소한 것(특히 ARM 코어가 아닌 경우)을 주면 전혀 모르면서도 계속 추측하려 들 겁니다. 데이터시트를 줄 수는 있겠지만, 적어도 어느 부분이 중요한지는 사람이 알려줘야 할 것 같고, 그렇게 해도 배운 내용을 금방 잊어버릴 겁니다(즉 같은 대화 안에서도 다시 환각을 시작할 것입니다).” (Reddit, Will AI take low level jobs)
적어도 지금은 그렇습니다. 하지만 실리콘 벤더들이 자사 부품과 데이터로 학습된 특수 모델을 만들기 시작한다면 바뀔 수도 있습니다. 다만 그것이 가능할지, 그리고 얼마나 걸릴지는 잘 모르겠습니다.
저는 VS Code에서 코딩할 때 Microsoft CoPilot을 사용합니다. 데이터 프라이버시 우려 때문에 오픈 소스 코드에만 사용해 왔습니다.
인터페이스 파일에 주석으로 문서화를 하거나, 코드에 더 많은 주석을 추가하는 데 사용했습니다. 약간의 검토와 수정이 필요했지만 매우 잘 작동했고, 문서화 생산성은 올라갔다고 느꼈습니다.
인터페이스 문서를 생성하는 CoPilot
완벽하지는 않았습니다. 경우에 따라 틀리기도 했습니다. 하지만 제가 그 인터페이스와 그 뒤의 코드를 알고 있었기 때문에 수정하는 것은 큰 문제가 아니었습니다. 만약 제가 직접 작성한 코드가 아니었다면, 분명 좋은 작업 방식이 아니었을 것입니다. 잘못된 결과를 만들어냈을 테니까요.
코딩에도 CoPilot을 사용해 보았습니다. CoPilot은 제 코드 스타일에 많이 적응했습니다. 제안한 코드 블록은 대부분 말이 되었습니다.
VS Code에서의 CoPilot 사용
그것들은 제가 작성하고 싶었던 코드와 어느 정도는 일치했습니다. 하지만 정확히 일치하지는 않았습니다. 대부분의 경우 저는 그 제안을 받아들였습니다. 그 다음에 맞게 ‘수정’했습니다. 그런데 어느 순간 제 생산성이 올라가는 것이 아니라 내려가고 있다는 것을 깨달았습니다. 동기도 마찬가지였습니다. IntelliSense의 도움을 받아 직접 코드를 쓰는 대신, LLM이 만든 코드를 수정하고 있었기 때문입니다. 이것은 좌절감을 주는 작업입니다. 결국 저는 계속해서 LLM 코드를 검토하고 수정하고 있었습니다:
“개발자 코드의 리뷰어가 AI 솔루션이 되는 것이 아니라, 그 반대가 됩니다. AI 솔루션이나 LLM에게 ‘이런 걸 하고 싶어’라고 말하면, 본질적으로 당신이 AI 코드의 리뷰어가 됩니다.” (Memfault)
제가 CoPilot을 매우 유용하게 느끼는 부분은 “이 함수의 대안 구현을 제안해 줘” 같은 요청입니다. 이것은 보통 코드 리뷰와 비슷한 사고 과정을 촉발합니다. 인간이 하는 코드 리뷰를 대체할까요? 저는 그렇게 생각하지 않습니다. 하지만 AI는 리뷰와 개선 과정을 보강해 줍니다.
몇 주 전, 저는 한 학생 그룹과 함께 실험을 했습니다. 그들의 과제는 로터리 스위치를 위한 쿼드러처 엔코더 코드를 구현하는 것이었습니다. 저는 쿼드러처 신호의 개념과 기초를 설명했고, Claude(위 참고)를 사용해 개념을 더 깊이 파고들었습니다.
그런 다음 ChatGTP4에게 코드를 달라고 했습니다:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53#include <stdint.h>
#define READ_A() ((GPIOB->PDIR >> 2) & 1) // Example: PTB2 = A
#define READ_B() ((GPIOB->PDIR >> 3) & 1) // Example: PTB3 = B
static``int8_t``quad_state = 0;
static``int32_t``encoder_count = 0;
static``const``int8_t``quad_table[16] = {
```0, +1, 0, -1,`
```-1, 0, +1, 0,`
```0, -1, 0, +1,`
```+1, 0, -1, 0`
};
void``Quadrature_Update(``void``)
{
```uint8_t``new_state = (READ_A() << 1) | READ_B();`
```printf("A:%d, B:%d\n"``, READ_A(), READ_B());`
```uint8_t``index = (quad_state << 2) | new_state;`
```int8_t``movement = quad_table[index];`
```encoder_count += movement;`
```quad_state = new_state;`
}
int32_t``Encoder_GetCount(``void``)
{
```return``encoder_count;`
}
void``Encoder_SetCount(``int32_t``v)
{
```encoder_count = v;`
}
위에서 제안된 코드는 괜찮아 보이지 않나요? 거의 맞지만, 틀렸습니다. 그래서 저는 학생들에게 그 해법을 사용해 디버거로 테스트해 보라고 했습니다. 물론 그들은 예상대로 동작하지 않는다는 것을 알아차렸습니다. 그래서 저는 그들에게 고치라고 했습니다. 대부분은 코드를 이해하고 수정하는 데 45분 이상이 필요했습니다. 그들은 ChatGTP에게 고쳐 달라고 요청했습니다. 하지만 결국 또 다른 잘못된 코드를 얻었고, 그것도 다시 고쳐야 했습니다. 대부분은 AI 없이 했다면 더 빨랐을 것이라고 동의했습니다. 하지만 그 코드는 ‘맞아 보였기’ 때문에 사용하고 싶은 유혹이 매우 컸고, 스스로의 기술을 신뢰하지 못했습니다. 그리고 점점 더 자신이 이해하지 못하는 코드를 추가하면서 technical dept를 쌓아 가게 됩니다.
하지만 이것은 제 경험과도 일치하는 듯합니다. 그리고 몇몇 연구들도 비슷한 결과를 보여줍니다. 예를 들어 AI 코드가 1.7배 더 많은 문제를 만든다는 결과가 있습니다:

AI PR 결과 (출처: CodeRabbit)
품질(코드 밀도, 저전력, 코드 크기, 테스트 커버리지, …)이 전혀 중요하지 않은 경우(예: 목업이나 개념 증명)에는 AI가 가치 있는 선택 또는 보완 수단이 될 수 있습니다. 다시 말해, AI는 ‘더 빠를’ 수 있지만 품질은 떨어집니다.
하지만 우리는 정말 더 빨라진 걸까요? 일부 사람들은 LLM을 사용하면 성능이 향상된다고 진심으로 믿는 듯합니다. 하지만 한 연구는 다른 결과를 보여줍니다:
“AI 도구가 자신들의 생산성을 높여줄 것이라고 믿었던 소프트웨어 개발자들은 이 기술이 작업 완료 시간을 평균 24% 줄일 것이라고 예측했습니다. 그러나 실제로는 AI를 사용하지 않았을 때보다 작업 시간이 19% 더 늘어났습니다.” (Fortune)
이 연구는 Cornell University 또는 metr.org에서 볼 수 있습니다:
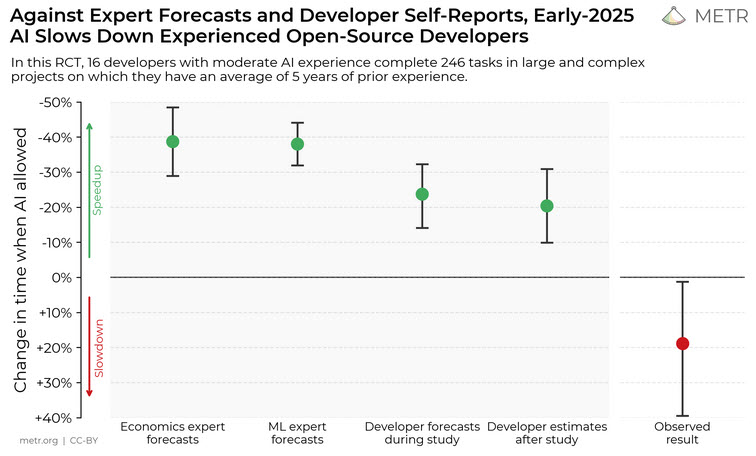
예상 생산성과 실제 생산성 (출처: metr.org)
“The Impact of Artifical Intelligence on Productivity, Distribution and Growth” 연구는 여기서 ‘조정 비용(adjustment costs)’이 기여할 수 있다고 보여줍니다. 저는 개발자들의 ‘과도한 자기확신’과 인식이 매우 흥미롭다고 생각합니다. 그리고 이것은 여러 엔지니어링 그룹과의 토론에서 제가 관찰한 것과도 일치합니다. 하지만 이것은 AI와 LLM 사용에만 국한된 것이 아닙니다. 인간은 자신의 능력을 과대평가하는 경향이 있습니다. 인구의 절반이 넘는 사람들이 자신이 ‘평균보다 더 낫고 뛰어나다’고 생각합니다 :-).
아마 이런 경험이 있을 것입니다. 예전에는 우리는 지형지물과 지도를 사용해 길을 찾았습니다. GPS와 내비게이션 시스템 이전의 일이었습니다. 이제는 인터넷이나 GPS 신호가 없으면 많은 사람이 길을 잃습니다. 또는 예전에는 전화번호를 많이 외웠지만, 이제는 자기 번호조차 잘 기억하지 못합니다. 또는 전자 계산기가 발명된 뒤에는 아주 간단한 수학 계산 능력조차 잃어버렸습니다. 기계가 그것을 우리 대신 해 주기 때문입니다. 좋든 나쁘든 말입니다.
비슷한 맥락에서 하나의 연구 질문이 있습니다. AI와 LLM을 사용하면서 우리는 비판적 사고 능력을 잃고 있는 걸까요?
Microsoft는 “The Impact of Generative AI on Critical Thinking: Self-Reported Reductions in Cognitive Effort and Confidence Effects From a Survey of Knowledge Workers”에 대한 연구를 했습니다. 이 연구는 ‘자신감’과 ‘비판적 사고’ 사이의 흥미로운 관계를 보여줍니다:

자신감과 비판적 사고 (출처: Confidence and Critical Thinking (Source https://www.nsta.org/blog/think-or-not-think-impact-ai-critical-thinking-skills)
엔지니어와 학생들이 장기적으로 성공하기 위해 필요한 것은 비판적 사고입니다.
“우리가 AI 도구에 아무리 영리한 프롬프트를 입력하더라도 인간의 비판적 사고를 대체할 수는 없습니다. 특히 ChatGPT 같은 도구는 자주 부정확하기 때문입니다. 현실에서는 AI 시대에 비판적 사고가 오히려 더 필요합니다. AI를 올바르게 사용하기 위해서도, 그리고 그것을 더 신뢰할 수 있는 도구로 만들기 위해 배후에서 필요한 작업을 수행하기 위해서도 그렇습니다.” (Forbes)
학생들과 주니어 엔지니어들은 종종 LLM 시스템이 만들어낸 코드를 신뢰합니다. 자신이 작성한 코드보다 그것을 더 믿는 것처럼 보입니다. 기계가 준 코드를 받아들이고, 그것을 믿고, 동작하게 만들려고 합니다.
Memfault는 이에 대해 좋은 팟캐스트 “AI code means more critical thinking, not less”를 진행했습니다:
“우리는 다시 스스로를 신뢰하는 법을 배워야 합니다. 그리고 우리가 더 숙련될수록 그런 LLM 시스템을 더 잘 사용할 수 있습니다.” (Memfault)
“그 시스템들은 지식과 기술을 가진 사람들에게 정말 좋은 시스템입니다. 그리고 그들은 정말 숙련되어 있어야 합니다. 왜냐하면 LLM 시스템을 신뢰하는 것보다 자신의 기술 세트를 더 신뢰해야 하기 때문입니다.” (Memfault)
“제 생각에 우리는 집단적으로 더 멍청해지고 있습니다. 왜냐하면 비판적 사고를 잃기 때문입니다 … 우리는 그냥 LLM을 믿고, 방금 말했듯이 그저 다음으로 가장 그럴듯한 단어를 내놓는 비결정적 시스템을 믿어버립니다.” (Memfault)
결국 엔지니어는 자신이 전달하는 결과물에 책임을 져야 합니다. 이것이 ‘vibe coding’으로 생성된 거대한 코드 덩어리라면 매우 어려운 일이 될 것입니다. 취미로 무언가를 ‘vibe code’하는 것과 실제 현업에서 그렇게 하는 것은 근본적으로 다릅니다. 안전 필수 코드나 중요 인프라를 생각해 보세요.
Christine Anne Royce는 비판적 사고를 위한 좋은 전략들을 제안합니다:
안타깝게도 이것은 항상 쉽게 구현되지는 않습니다.
“AI는 학생들의 비판적 사고를 파괴할 것입니다. 대부분은 과제와 프로젝트를 AI에 위임할 것입니다(이미 그렇게 하기 시작했습니다). 또한 많은 교수들이 그런 과제의 검증과 채점을 AI에 위임할 가능성도 큽니다. 정말 장관이겠죠. AI가 숙제를 하고, AI가 그것을 채점하는 겁니다.” (LinkedIn)
학생들이 과제와 숙제에 AI에 크게 의존하고 있다는 점은 저도 확인할 수 있습니다. 이것 자체가 문제는 아닙니다. AI 도구와 LLM은 올바르게 사용하면 도움도 되고 유용하기도 하기 때문입니다. 그것은 시간을 절약하거나 지름길을 만드는 데가 아니라 학습 과정을 돕는 데 사용되어야 합니다. 시장에서 의미 있는 사람이 되려면 경험이 있어야 합니다. 이는 힘들게 코딩하고, 실수하고, 실수에서 배우고, 시간이 지나며 개선된다는 뜻입니다. 요즘 같은 시대에도 새로운 프로그래밍 언어를 배우는 것은 매우 의미가 있습니다. 그렇다면 로봇도 걷기 때문에 우리는 걷는 법을 배우는 것을 멈춰야 할까요?
AI는 이미 여기 있고, 앞으로도 계속 있을 것입니다. 하지만 분명한 영향이 있습니다:
“저는 응용과학 대학의 교사인데, 학생들의 문제 해결 능력과 비판적 사고 능력이 급격히 떨어지는 것을 보았습니다. 학생들은 지식을 반복해서 말하는 것은 문제없이 하지만, 그것을 새로운 상황이나 맥락에 적용하는 것은 안 됩니다. 전혀 안 됩니다. 그래서 이전 학생 집단보다 훨씬 더 느리게 진도를 나가고 있습니다. 다행히 적응하는 데 시간이 좀 걸리긴 했지만, 이제는 AI 사용을 허용하면서도 학생들이 비판적으로 사고하도록 훈련시키는 방법을 찾았습니다. 다만 이 때문에 예전 같았으면 의지력만으로도 어떻게든 통과했을 일부 학생들에게는 교육 과정이 훨씬 더 어려워졌습니다.” (Reddit)
AI 분야는 물론 교육에도 영향을 미칩니다. “Flipped Classroom” 개념은 새로운 것이 아닙니다. 많은 학생들이 이를 좋아하지 않는데, 전달 방식이 좋지 않을 수 있기 때문입니다. 그리고 ‘전통적인’ 수업 개념과 비교하면 모두에게 더 많은 일이 될 수도 있습니다. 학생들은 수업 전에 미리 자료를 읽고 학습해야 합니다. 그러면 수업 시간은 문제 해결과 비판적 사고에 집중할 수 있습니다. 제 수업 자료의 절반 정도는 이제 이런 형식입니다. 처음부터 모든 것이 잘 작동한 것은 아니어서, 저는 내용과 형식을 계속 조정해 왔습니다. 이제는 더 이상 ‘교과서적인 flipped format’이 아닙니다. 저는 이를 사전 녹화 입력 뒤에 수업 중 과제와 그룹 활동이 이어지는 ‘하이브리드’ 접근이라고 부릅니다. 준비 단계에서는 AI를 포함한 모든 도구를 사용하게 두세요. 교실 시간은 그룹 활동, 토론, 비판적 사고에 할애합니다.
“처음에는 flipped classroom 형식에 회의적이었지만, 구현이 정말 훌륭했습니다. Erich Styger가 매우 잘 설계된 개념을 구현했습니다.” (2025년 강의 평가)
교육에서 중요한 부분 중 하나는 평가입니다. AI 시대에는 ‘누구나 좋고 설득력 있는 보고서를 쓸 수 있습니다.’ 그리고 여기에는 학생 개인 기기에서 작성된 모든 평가 결과물이 포함됩니다. 결과가 AI에서 나온 것일 수 있기 때문입니다.
“우리는 모든 시험을 비판적 사고 적용형으로 재구성함으로써 이 문제를 피했습니다. 그래서 학생들은 구두 발표를 하고, 새로운 맥락에 기술을 적용해야 하는 압박 세션을 하고, 인터넷 없이 실제 장치에서 제한 시간 안에 capture the flag를 수행하고, 구두 평가를 받고, 교실 활동에서 서로 피드백을 주고, 함께 아이디어를 브레인스토밍합니다… 재미있는 해결책입니다.” (Reddit)
저는 보고서 작성이나 서면 결과물 제출 같은 것의 비중을 줄였습니다. 대신 더 많은 구두 평가나 수업 중 과제로 옮겨 갔습니다. 그리고 학생들의 이해도는 구두 토론과 ‘방어’로 확인합니다. 특히 ‘비판적 사고’와 관련해서 그렇습니다.
그럼에도 불구하고 일반적인 ‘시험’은 여전히 존재하고 사용됩니다. 다만 ‘온라인/전자’ 시험은 다시 종이로 돌아갔습니다.
형성평가와 총괄평가를 위해 저는 전자 또는 온라인 시험 시스템을 사용해 왔습니다. 예를 들면 SEB, MOODLE, ILIAS 같은 것들입니다. 학생들은 자기 기기를 사용했습니다.
AI 시대에 저는 이런 구성을 ‘불안전하다’ 혹은 ‘불공정하다’고 생각합니다. 학생들은 자신의 기기에서 학습된 AI 모델을 실행할 수 있습니다. 또는 유료 모델을 사용해 이점을 얻을 수도 있습니다. 시험은 쉽게 부정행위를 할 수 없어야 하며, 모두에게 공평해야 합니다. 대학들이 이러한 지속적인 도전에 대응하기 위해 많은 돈과 시간을 투자하는 것을 봅니다. 그들은 기술적 문제를 더 많은 IT 인프라와 기술로 해결하려고 합니다. 하지만 제게 이것은 끝없는 쫓고 쫓기는 게임이며, 지속 가능하지 않습니다.
저는 (전자식) e-assessments 사용을 중단했습니다. 지난 몇 달 동안 제가 구축하기 시작한 것은 종이 기반 평가, 즉 p-assessments로 돌아가는 것입니다.
저는 AMC 또는 auto-multiple-choice를 사용합니다. 이것은 시험이나 설문을 위한 오픈 소스 소프트웨어 모음입니다. AMC는 LLM이나 AI 기반은 아니지만, AI 시대에 적합한 도구입니다. 답안지를 분석하기 위해 컴퓨터 비전을 사용합니다. 이를 통해 온라인 시험에 견줄 만한 자동화 수준에 도달할 수 있습니다.
AMC는 e-assessments의 장점과 종이 기반 시험의 장점을 결합합니다. 여기에는 단일 선택형이나 KPRIM 문제처럼 특정 문제 유형의 자동 채점이 포함됩니다. 학생들에게는 기술 장벽이 없습니다. 학생들은 펜만 있으면 됩니다. 노트북 고장, 복잡한 설정, 호환되지 않는 소프트웨어나 도구를 걱정할 필요가 없습니다.
AMC 기반 시험은 LaTeX로 작성됩니다. 학생들은 펜(지워지는 펜도 가능)을 사용해 종이에 답을 쓰고 표시합니다. 아래의 용지는 일부 기능과 형태를 보여주기 위한 예시일 뿐입니다. 단일 선택형, 서술형, KPRIM, 수치형 문제 유형이 포함되어 있습니다:

작성된 AMC 문제지 예시
종이 답안지에는 특별한 마킹과 답을 체크하는 영역이 포함됩니다. 서술형 문항은 종이 위에서 직접 채점합니다(위의 예시 문제 2). 그 다음 모든 용지를 스캔하면 이미지 처리 소프트웨어가 채점을 마무리합니다.
amc를 이용한 데이터 캡처
저는 이것을 형성평가와 총괄평가 모두에 사용합니다.
“저는 이 하이브리드 접근이 정말 좋습니다. 주제를 미리 알게 되고, 수업 시간 중 시험으로 얼마나 잘 이해했는지 확인할 수 있습니다. 또 시험은 실제 시험이 어떤 모습일지 준비시키고 보여줍니다. 학기 중에 샘플 시험을 보는 것은 보통 실제 시험 성과 향상으로 이어진다고 생각합니다. 그리고 또 하나, 실제 하드웨어를 가지고 놀고 배우는 점이 정말 좋습니다.” (학생 피드백)
AMC는 LLM이나 AI와 직접 관련되어 있지는 않습니다. 하지만 AI 시대에 빠른 시험과 평가를 위한 좋은 도구입니다.
AI와 LLM은 앞으로도 계속 존재할 것이며, 꾸준히 개선될 것입니다. 여기에서 제가 설명한 것은 현재 상태이며, 1년 후에는 상황이 매우 달라질 수도 있습니다. 만약 기본 원리가 오늘과 같다면, 저는 점진적인 개선만을 예상합니다. 또한 과열된 분위기가 끝나고, 거품이 꺼지면서 보다 현실적인 기대 수준으로 돌아갈 수도 있습니다.
하지만 AI와 LLM은 사라지지 않을 것입니다. 그것들은 기계이며, 무언가를 완전히 대체하기보다는 보강하고 보조하는 데 강합니다. 오늘날 LLM을 이용한 코딩은 착암기를 사용하는 것과 비슷합니다. 큰 덩어리의 초안을 만들어내는 것이죠. 그리고 그것을 제대로 다듬고 정제하는 일은 책임 있는 엔지니어의 몫입니다.
이 모든 것에는 비판적 사고가 필요합니다. 주니어 엔지니어뿐 아니라 시니어 엔지니어에게도 마찬가지입니다. 그리고 이에 따라 교육 분야도 변해야 합니다. 단지 코딩만 하는 방향에서 벗어나, 더 전체적인 역할로 나아가야 합니다:
“프로그래머에게 가장 중요한 기술은 배우는 법을 배우는 것입니다.” (Memfault)
이것은 LLM 시대 이전에도 이미 중요했습니다. 이제는 필수입니다. 여러분의 의견도 정말 궁금하니, 댓글로 남겨 주세요!
LLM과 함께 즐겁게:-)
PS: Prof. Dr. Katharina Zweig는 LLM이 할 수 있는 것과 할 수 없는 것에 대해 흥미로운 관점을 가지고 있습니다. 예를 들어 Are Machines the Better Decision Makers? (영어, 2024)나, 2025년의 Katharina Zweig: Weiß die KI, dass sie nichts weiß? (독일어)를 참고해 보세요.