단일 코어 중심의 사고에서 벗어나 프로그램을 ‘기본적으로 멀티코어’로 작성하고, 필요할 때만 좁혀(single-core처럼) 실행하는 접근을 설명한다. 예제와 패턴(병렬 for, 배리어, 동적 작업 할당, 레인 개념 등)을 통해 여러 코어를 자연스럽게 활용하고 디버깅·유지보수 비용을 낮추는 방법을 다룬다.
단일 CPU 코어를 대상으로 프로그래밍을 배우는 것만으로도 어렵다. 효과적으로 다루기 위해 알아야 할 기법과 정보의 양, 쏟아야 할 시간이 엄청나다. 여기에 더해 여러 CPU 코어가 병렬로 일을 처리하고, 동시에 어떤 큰 작업을 함께 달성하도록 협력하게 만드는 법을 배우는 일은—말하자면—낙타의 등을 부러뜨리는 마지막 짐처럼 느껴졌다. 단일 코어 프로그래밍만 하더라도 이미 대처해야 할 것이 너무 많은데, 멀티코어 프로그래밍은 오랫동안 나로서는 편의상 외면해 온 주제였다.
하지만 최신 하드웨어 시대에는 방 안의 코끼리가 등장한다. 현대 CPU의 코어 수가 1을 훌쩍 넘어 8, 16, 32, 64 같은 숫자에 이르는 지금, 멀티코어라는 근본 현실을 무시하면 프로그래머는 엄청난 성능 잠재력을 테이블 위에 그대로 두고 가게 된다.
나는 “퍼포먼스 프로그래머”가 아니다. Casey Muratori처럼(그를 팔로우하기 시작한 이유 중 하나이기도 하다) 나는 언제나 합리적인 수준의 성능을 원했다(물론 소프트웨어 업계의 꽤 우려스러운 비율의 사람들에게는 이것만으로도 ‘퍼포먼스 프로그래밍’처럼 보일 수 있다). 나는 역사적으로 내 게임이나 엔진처럼 내가 데이터를 통제하는 영역에서 일을 많이 해 왔다. 미술, 디자인, 레벨을 내가 직접 만들거나 그 과정에 깊이 관여했다. 그래서 종종 내가 세운 프로그래밍 제약이 예술적 제약을 이끄는 식으로 활용할 수 있었다.
이 모든 것은 지난 몇 년 사이에 물거품이 됐다. 내가 디버거 작업을 하면서 다뤄야 하는 데이터는 내가 통제하지 못할 뿐 아니라, 내가 원하던 것과 정반대에 가깝다—극도로 크고, 믿기 힘들 정도로 구조가 형편없고, 엄청나게 복잡하며, 예측 불가능하고 변동도 심하다. 왜냐하면 내가 썼듯이, 디버거는 “분주한 교차로”에 서 있기 때문이다. 디버거는 외부 컴퓨팅 세계의 수많은 미지와 맞닥뜨린다. 그리고 디버거가—예를 들어—대성공을 거둔 회사들이 실제 제품을 출하하는 데 사용하는, 엄청나게 큰 코드베이스에서도 유용하기를 바란다면, 그 미지에는 불행한 코드베이스의 디테일들까지 포함된다.
그 결과 내 작업에서는 하드웨어를 더 효과적으로 쓰는 일이 이전보다 훨씬 중요해졌다. 그래서 나는 CPU 코어 수라는 ‘방 안의 코끼리’를 마주할 수밖에 없었고, 실제로 멀티코어 프로그래밍을 하기 시작했다.
지난 몇 년간 멀티코어 프로그래밍 측면에서 많은 것을 배웠고, 그 과정에서 배운 교훈을 멀티스레드 아키텍처를 계획하기 위한 기본적인 정신적 빌딩 블록, 여러 스레드가 거의 동기화를 필요로 하지 않도록 변이를 신중하게 조직하는 법 같은 글로 정리해 왔다.
그 아이디어들은 여전히 유용하고, 과거 글은 멀티코어 프로그래밍의 제1원리에 대한 내 생각을 잘 담고 있다. 하지만 최근에 Casey와 몇 차례 대화를 나눈 뒤 얻은 교훈 덕분에, 그 제1원리를 실제로 적용하는 능력이 한 단계 “레벨업”했다. 지금 이 글은 그 교훈을 기록하고 공유하기 위해 쓴다.
모든 프로그래머가 단일 코어 프로그래밍부터 배우기 때문에, 멀티코어 프로그래밍 기법을 처음 배운 후에도 기존의 단일 코어 코드 안에서 그 기법을 보수적으로 적용하는 일이 흔하다.
좀 더 구체적으로 보기 위해 다음의 간단한 예를 생각해 보자:
S64 *values = ...;
S64 values_count = ...;
S64 sum = 0;
for(S64 idx = 0; idx < values_count; idx += 1)
{
sum += values[idx];
}
이 예에서는 values 배열의 모든 원소 합을 계산한다. 합의 몇 가지 성질을 보자:
a + b + c + d = (a + b) + (c + d)a + b + c + d = d + c + b + a(a + b) + (c + d) = (c + d) + (a + b)합을 원소들의 그룹 합의 합으로 다시 생각할 수 있고, 합하는 순서가 결과에 영향을 주지 않으므로, 원래 코드는 다음처럼 다시 쓸 수 있다:
S64 *values = ...;
S64 values_count = ...;
S64 sum0 = 0;
for(S64 idx = 0; idx < values_count/4; idx += 1)
{
sum0 += values[idx];
}
S64 sum1 = 0;
for(S64 idx = values_count/4; idx < (2*values_count)/4; idx += 1)
{
sum1 += values[idx];
}
S64 sum2 = 0;
for(S64 idx = (2*values_count)/4; idx < (3*values_count)/4; idx += 1)
{
sum2 += values[idx];
}
S64 sum3 = 0;
for(S64 idx = (3*values_count)/4; idx < (4*values_count)/4 && idx < values_count; idx += 1)
{
sum3 += values[idx];
}
S64 sum = sum0 + sum1 + sum2 + sum3;
이렇게 썼다고 해서 당장 이득이 생기지는 않는다—하지만 이는 원래 계산을 몇 개의 더 작고 독립적인 계산으로 분할하더라도 같은 결과를 얻을 수 있음을 의미한다.
여러 개의 독립적인 계산은 같은 메모리에 쓰기(write)를 하지 않기 때문에 멀티코어 프로그래밍과 잘 맞는다—각 코어는 다른 코어와 동기화할 필요가 전혀 없다. 이는 멀티코어 프로그래밍을 크게 단순화할 뿐 아니라 성능을 개선한다—정확히 말하면, 병렬 실행으로 자연스럽게 얻는 성능을 갉아먹지 않는다.
이런 경우에는 소위 “parallel for”를 구현할 수 있다. 아이디어는 원래의 for 루프를 다음처럼 지정하고…
for(S64 idx = 0; idx < values_count; idx += 1)
{
sum += values[idx];
}
…동시에 이 루프가 독립적인 계산들로 분할될 수 있음을 표현하는 것이다(그 결과는 나중에 하나로 합칠 수 있다).
다시 말해, 우리는 보통의 단일 코어 코드로 시작한다. 하지만 어떤 계산에서 “폭을 넓혀” 병렬로 계산하고 싶다. 그리고 이 넓고 병렬적인 작업을 “조인”해 다시 단일 코어 코드로 돌아와, 병렬로 수행한 결과를 사용하고 싶다.
이것은 널리 알려져 있고 실제로 많이 쓰이는 개념이다. 현대 언어로 작성된 많은 코드베이스에서는 추상화를 간결하게 표현하기 위한 인상적인 곡예를 흔히 볼 수 있다.
내가 더 단순한 언어를 선호하는 이유 중 하나는, 어떤 추상화를 돕기 위해 궁극적으로 내 코드가 복잡한 것을 생성해야 한다면, 그 복잡함이 소스 코드에 곧장 드러나는 편이 어떤 구성물이 실제로 얼마나 “깔끔한지”에 대해 나 자신에게 솔직해지는 데 도움이 되기 때문이다.
반대로, 더 높은 수준의 유틸리티가 간단하고 직설적인 구체 구현으로 제공될 수 있다면, 그것이야말로 더 우월한 설계의 신호다—구현에서 타협하지 않으면서도, 높은 수준의 유용성에서도 타협하지 않는 설계다.
많은 사람은 이것이 불가능하다고 여긴다—높은 수준의 유틸리티는 필연적으로 낮은 수준에서 큰 대가를 치러야 하고, 또는 그 반대로, 낮은 수준의 성능 같은 특성은 상위 설계에서 바람직하지 않은 대가를 요구한다고 생각한다. 이는 보편적 진리가 아니다. 타협점을 찾는 데 익숙해진 많은 프로그래머는 케이크를 갖고 먹는 일이 가능한 경우를 스스로 외면하도록 훈련된다.
그래서, 현대 언어의 많은 장치를 쓰지 않고 “parallel for”를 구현하는 선택지를 생각해 보면, 다음 같은 것부터 시작할 수 있다:
struct SumParams
{
S64 *values;
S64 count;
S64 sum;
};
void SumTask(SumParams *p)
{
for(S64 idx = 0; idx < p->count; idx += 1)
{
p->sum += p->values[idx];
}
}
S64 ComputeSum(S64 *values, S64 count)
{
S64 count_per_core = count / NUMBER_OF_CORES;
SumParams params[NUMBER_OF_CORES] = {0};
Thread threads[NUMBER_OF_CORES] = {0};
for(S64 core_idx = 0; core_idx < NUMBER_OF_CORES; core_idx += 1)
{
params[core_idx].values = values + core_idx*count_per_core;
params[core_idx].count = count_per_core;
S64 overkill = ((core_idx+1)*count_per_core - count);
if(overkill > 0)
{
params[core_idx].count -= overkill;
}
threads[core_idx] = LaunchThread(SumTask, ¶ms[core_idx]);
}
S64 sum = 0;
for(S64 core_idx = 0; core_idx < NUMBER_OF_CORES; core_idx += 1)
{
JoinThread(threads[core_idx]);
sum += params[core_idx].sum;
}
return sum;
}
이 메커니즘에는 몇 가지 불편한 현실이 있다:
LaunchThread와 JoinThread 같은 곳에서 매번 합을 계산할 때마다 커널과 상호작용해(스레드라는) 커널 리소스를 생성·파괴한다.for 루프가 우리가 원하던 메커니즘의 여러 디테일—작업 준비, 작업 시작, 작업 결과의 조인과 결합—을 각각 구현하는 더 복잡한 여러 부분으로 흩어졌다. 병렬 for가 필요할 때마다 모든 부분을 함께 유지·수정해야 한다.for의 일부 반복에서 버그를 만나면, 특정 작업의 ‘출발’과 실제 작업을 서로 연관 지어야 한다. 예를 들어, 디버거에서 프로그램을 멈췄는데 병렬 for의 일부 반복을 수행 중인 스레드 안이라면, 그 작업을 누가(어떤 컨텍스트에서) 시작했는지에 대한 맥락을 잃는다(단일 코어 코드에서는 콜스택이 보편적으로 이 정보를 제공한다).첫 번째 문제는 코드가 커널 프리미티브 대신 사용할 새로운 하부 레이어로 어느 정도 완화할 수 있다. 많은 코드베이스에서 이 레이어를 “잡 시스템” 또는 “워커 스레드 풀”이라고 부른다. 이 경우 프로그램은 한 번에 일정 수의 스레드를 준비하고, 이 스레드들은 그냥 작업을 기다리다가 전달받으면 실행한다:
void JobThread(void *p)
{
for(;;)
{
Job job = GetNextJob(...);
job.Function(job.params);
}
}
void SumJob(SumParams *p)
{
...
}
S64 ComputeSum(S64 *values, S64 count)
{
Job jobs[NUMBER_OF_CORES] = {0};
for(S64 core_idx = 0; core_idx < NUMBER_OF_CORES; core_idx += 1)
{
...
jobs[core_idx] = LaunchJob(SumJob, ¶ms[core_idx]);
}
S64 sum = 0;
for(S64 core_idx = 0; core_idx < NUMBER_OF_CORES; core_idx += 1)
{
WaitForJob(jobs[core_idx]);
sum += params[core_idx].sum;
}
return sum;
}
이 경우에도 잡 스레드와 정보를 주고받는 오버헤드가 있지만, 커널과 상호작용하는 것보단 훨씬 가볍다.
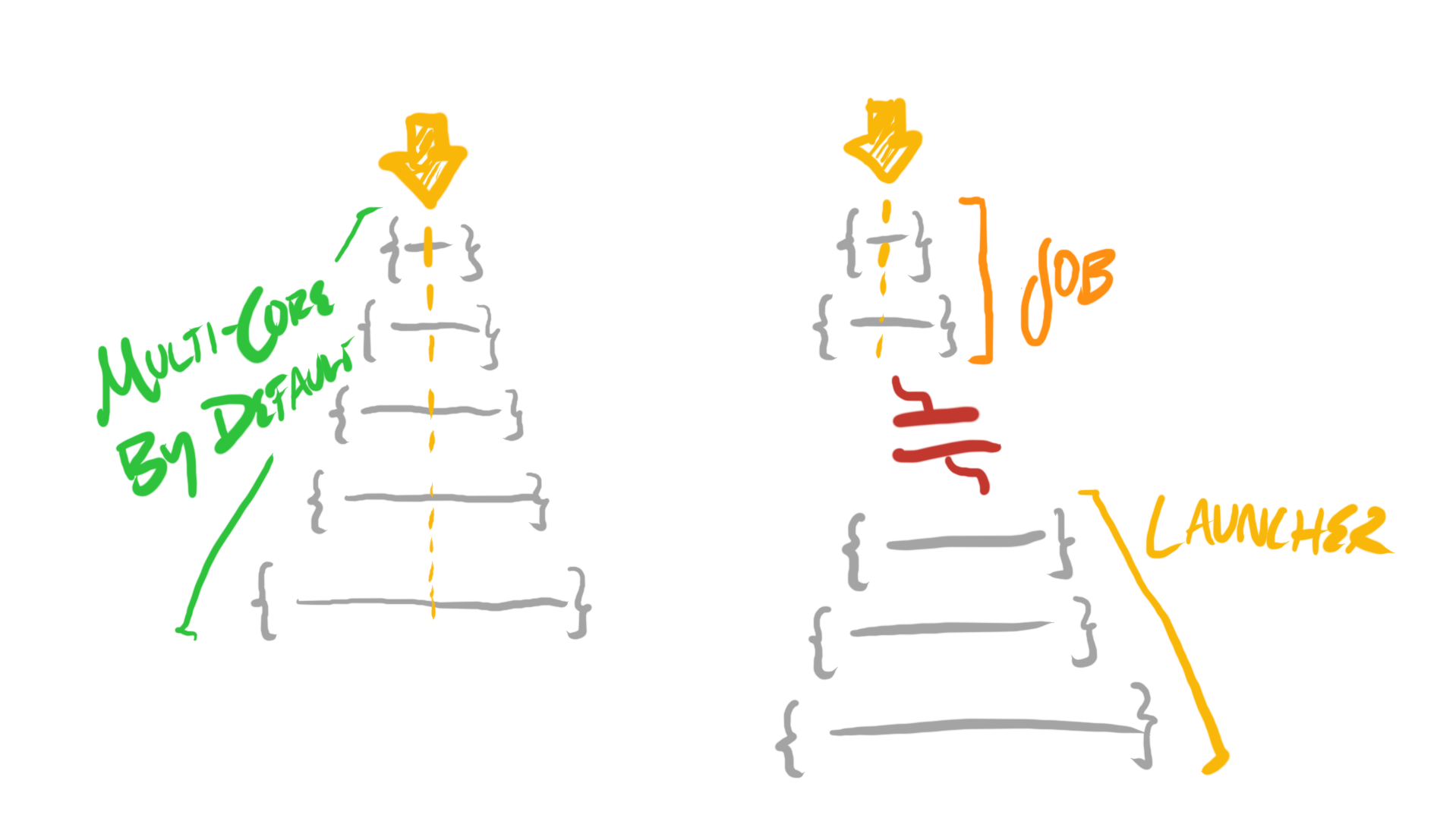
하지만 상위 수준 코드가 크게 개선된 것은 아니다—우리는 그저 “스레드”를 “잡”으로 바꿨을 뿐이다. 뒤의 두 문제는 여전하다. 여전히 “넓은 루프”—병렬 for—를 설정하기 위해 한바탕 춤을 춰야 하며, 문제의 제어 흐름은 소스 코드와 실행 시 일관된 컨텍스트(CPU 코어, 콜스택) 전반에 흩어져 버린다.
이 구체적 사례—합을 병렬로 계산하기—에서는 큰 문제가 아닐 수도 있다. 병렬로 합을 계산하나? 예. 공유 데이터 쓰기가 매우 적나? 예. 비슷하게 병렬화 가능한 모든 문제를 이런 식으로 병렬화할 수 있나? 예. 그러나 이 메커니즘을 쓸 때마다 이런 비용을 지불해야 한다. 만약 어떤 문제 전반에서 이런 비용을 아주 자주 지불해야 한다면, 이 모든 장치를 작성·디버그·유지보수하는 일이 버거워질 수 있다.
병렬 for의 바람직한 성질 중 하나는, 대략 같은 시간에 여러 코어에 걸쳐 실행되는 모든 잡의 “모양(shape)”이 동일하다는 것이다. 문제에 참여하는 각 잡 스레드는 정확히 같은 코드를 실행하고, 단지 약간 다른 파라미터로 각 코어에 다른 하위 문제를 분배할 뿐이다. 이는 이런 코드를 이해·예측·프로파일·디버깅하기를 훨씬 쉽게 만든다.
또한 병렬 for 안에서 각 잡의 수명은 원래 단일 코어 코드의 수명에 의해 스코프가 지정된다. 각 잡은 어느 스코프 안에서 시작하고 끝난다—그 스코프가 모든 잡을 시작하고 조인하는 책임을 진다. 따라서 수명 관리가 복잡해지지 않는다—병렬 for에서의 할당은 일반 단일 코어 코드만큼 단순하다.
하지만 실무에서는 병렬 for를 구현하는 수단인 잡 시스템이 이런 식으로만 사용되는 일은 드물다. 구조가 매우 일반적이기 때문에 이해할 수 있는 현상이다. 예를 들어, 잡 시스템은 서로 이질적인 잡을 여러 개 런치하는 데도 사용된다. 이런 경우 특정 잡의 문맥—누가 어떤 맥락에서 런치했는지—을 이해하기가 더 어려워진다. 또한 가능한 스레드 상태의 조합이 매우 많기 때문에, 스레드 시스템이 모든 경우에 견고한지 보장하기가 어려워져 시스템을 포괄적으로 이해하는 일도 어려워진다.
이러한 잡은 또한 흔히 런처 스코프에 의해 경계 지어지지 않는다. 그 결과 메모리 할당 같은 리소스 관리에 더 많은 엔지니어링이 필요해진다. 수명은 이제 여러 스레드와 여러 컨텍스트에서 벌어지는 일에 의해 정의되기 때문이다.
그리고 이것은 빙산의 일각에 불과하다. 더 정교한 시스템에서는 잡들 사이에 의존성이 있음을 관찰할 수 있고, 의존성이 충족될 때 잡이 암묵적으로 런치되어 더 길고(그리고 검사하기 어려운) 컨텍스트 체인을 만들기도 한다.
결국 이는 일반 단일 코어 코드에서는 존재하지 않는, 반복적인 작성·읽기·디버깅·유지보수 비용을 야기한다. 병렬 for든 그 밖의 용도든, 이 잡 시스템 설계로 인해 발생하는 비용은 새로운 병렬 작업을 도입하거나 기존 병렬 작업을 유지할 때마다—항상—지불한다.
물론, 우리 코드에서 이런 식으로 병렬화할 수 있는 부분이 얼마 없으면, 이는 큰 비용이 아니다.
…하지만 그 ‘만약’은 꽤나 무거운 일을 떠맡는다.
실제로 나는, 많은 시스템의 상당히 많은 부분이 서로 직렬 의존성이 부족하기 때문에 병렬화 기회로 가득하다는 것을 발견했다. 하지만 직렬적 독립성을 활용하는 매 순간마다 단일 코어 성능을 받아들이는 것보다 훨씬 많은 엔지니어링이 필요하다면, 많은 프로그래머는 후자를 선택하게 된다.
다시 말하지만—잡 시스템을 사용해 이런 시스템을 병렬화할 수 없다는 의미는 아니다. 하지만 동시에, 잡 시스템을 사용할 때 드는 비용—움직이는 부품의 증가, 작성·읽기·디버그해야 할 추가 코드와 개념—을 더 자주 지불하게 된다는 의미이기도 하다. 광범위한 직렬 독립성을 활용하려고 하거나, 특정 알고리즘의 성능을 코어 수에 맞춰 스케일시키고자 한다면 특히 그렇다.
Casey와 대화하며 내가 얻은 핵심 통찰은, 이런 비용이 발생하는 중요한 이유가 단일 코어 코드에서 멀티코어 코드로 ‘전환’하기 위해 시스템이 필요로 하는 세심한 구성 때문이라는 점이다. 잡 시스템과 그것의 특수한 사용법인 병렬 for 같은 메커니즘은 어떤 의미에서는 멀티코어 코드를 가장 보수적으로 적용한 형태를 대표한다. 코드의 절대 다수는 단일 코어로 작성되고, 멀티코어가 결정적으로 중요할 때만 몇몇 부분에서 예외를 둔다. 다시 말해, 코드는 기본적으로 단일 코어이고, 몇몇 특수한 경우에만 잠깐 멀티코어 시스템에 작업을 넘긴다.
코드 실행의 문맥이 시간에 따라 바뀌기 때문에—작업이 한 시스템에서 다른 시스템으로 ‘넘겨지기’ 때문에—설정하는 데 더 많은 코드가 필요하고, 어느 시점에서든 전체 문맥을 디버그하고 이해하기가 더 어려워진다.
그런데 이것이 최선일까? 혹시, 기본적으로 가끔 넓어지는 단일 코어 코드 대신, 가끔 좁아지는 멀티코어 코드를 기본으로 작성할 수는 없을까?
실무에서는 어떻게 보일까?
아마 이미 다른 영역—특히 GPU 셰이더 프로그래밍—에서 이런 스타일을 경험했을 것이다.
GPU 셰이더(전통적 렌더링 파이프라인에서 쓰이는 버텍스/픽셀 셰이더 같은)는 기본적으로 멀티코어다. 하나의 함수(셰이더의 엔트리 포인트)를 작성하지만, 이 함수는 항상 암묵적으로 매우 많은 코어에서 실행된다. 언어의 구성과 규칙은 데이터의 읽기/쓰기 범위가 코드를 실행하는 코어에 의해 항상 스코프가 지정되도록 설계되어 있다. 버텍스 셰이더의 단일 실행은 ‘하나의 버텍스’에, 픽셀 셰이더는 ‘하나의 픽셀’에 스코프가 지정되는 식이다.
근본적인 기반 아키텍처가 항상 기본적으로 멀티코어이며, 각 셰이더가 멀티코어 병렬화를 달성하는 방식에 관여하는 부분이 거의 없기 때문에, GPU 프로그래밍은 엄청난 성능을 누리면서도 셰이더 프로그래머 입장에서는 지불해야 할 비용이 거의 없어 보인다. 비용이 너무 적어서 누군가가 고성능 시각 셰이더 스크립팅을 빠르게 반복할 수 있는—Shadertoy—같은 전체 웹사이트를 만들 정도다.
잠깐만… “고성능”, “빠른 반복 스크립팅”? 많은 사람이 이 둘이 서로 양립 불가능하다고 믿지 않던가!
왜 CPU 프로그래밍은 이렇게 다르게 느껴질까?
GPU 프로그래밍 모델과 보통의 CPU 프로그래밍 모델을 대비해 보자—하나의 함수(프로그램의 엔트리 포인트)를 작성하면, 보통 커널 스케줄러가 하나의 스레드 상태로 단 하나의 코어에 스케줄한다. 이 모델은 대비적으로 기본이 단일 코어다.
요약하면: 반드시 그럴 필요는 없다!
접근을 정확히 뒤집어 보자. 하나의 스레드가 많은 스레드에게 작업을 차일드를 띄우는 대신, 그냥 기본적으로 동일한 코드를 실행하는 많은 스레드를 갖자. 어떤 의미에서는, _하나의 거대한 parallel for_만 있자:
void BootstrapEntryPoint(void)
{
Thread threads[NUMBER_OF_CORES] = {0};
for(S64 thread_idx = 0; thread_idx < NUMBER_OF_CORES; thread_idx += 1)
{
threads[thread_idx] = LaunchThread(EntryPoint, (void *)thread_idx);
}
for(S64 thread_idx = 0; thread_idx < NUMBER_OF_CORES; thread_idx += 1)
{
JoinThread(threads[thread_idx]);
}
}
void EntryPoint(void *params)
{
S64 thread_idx = (S64)params;
// 프로그램의 실제 작업은 여기서!
}
단일 스레드 엔트리 포인트를 가정하는 아키텍처에 맞추기 위해 BootstrapEntryPoint로 시작했다. 하지만 이 함수가 실제로 하는 일은 실제 엔트리 포인트인 EntryPoint를 실행하는 모든 스레드를 띄우는 것뿐이다.
앞서의 합계 예시를 생각해 보자. 먼저 원래 단일 스레드 코드를 EntryPoint에 그대로 넣고, 거기서부터 어떻게 계속할 수 있을지 보자.
void EntryPoint(void *params)
{
S64 thread_idx = (S64)params;
// 뭔가 방식으로 얻어온다고 하자:
S64 *values = ...;
S64 values_count = ...;
// 합 계산
S64 sum = 0;
for(S64 idx = 0; idx < values_count; idx += 1)
{
sum += values[idx];
}
}
실제로 무슨 일이 벌어지고 있을까? “여러 코어에 걸쳐 합을 계산하고 있다.” …기술적으로는 사실이다! 이제 출하하자!
단 한 가지 작은 문제가 있다… 이건 단일 코어 버전만큼만 빠르다. 거기에 엄청난 에너지를 더 쓰고, CPU가 다른 작업을 할 시간을 빼앗는다. 왜냐하면 단지 모든 코어에서 같은 일을 중복 수행하고 있기 때문이다.
하지만 실제 비용을 측정하고 프로파일링을 해 보면, 프로파일은 대략 다음처럼 보일 것이다:
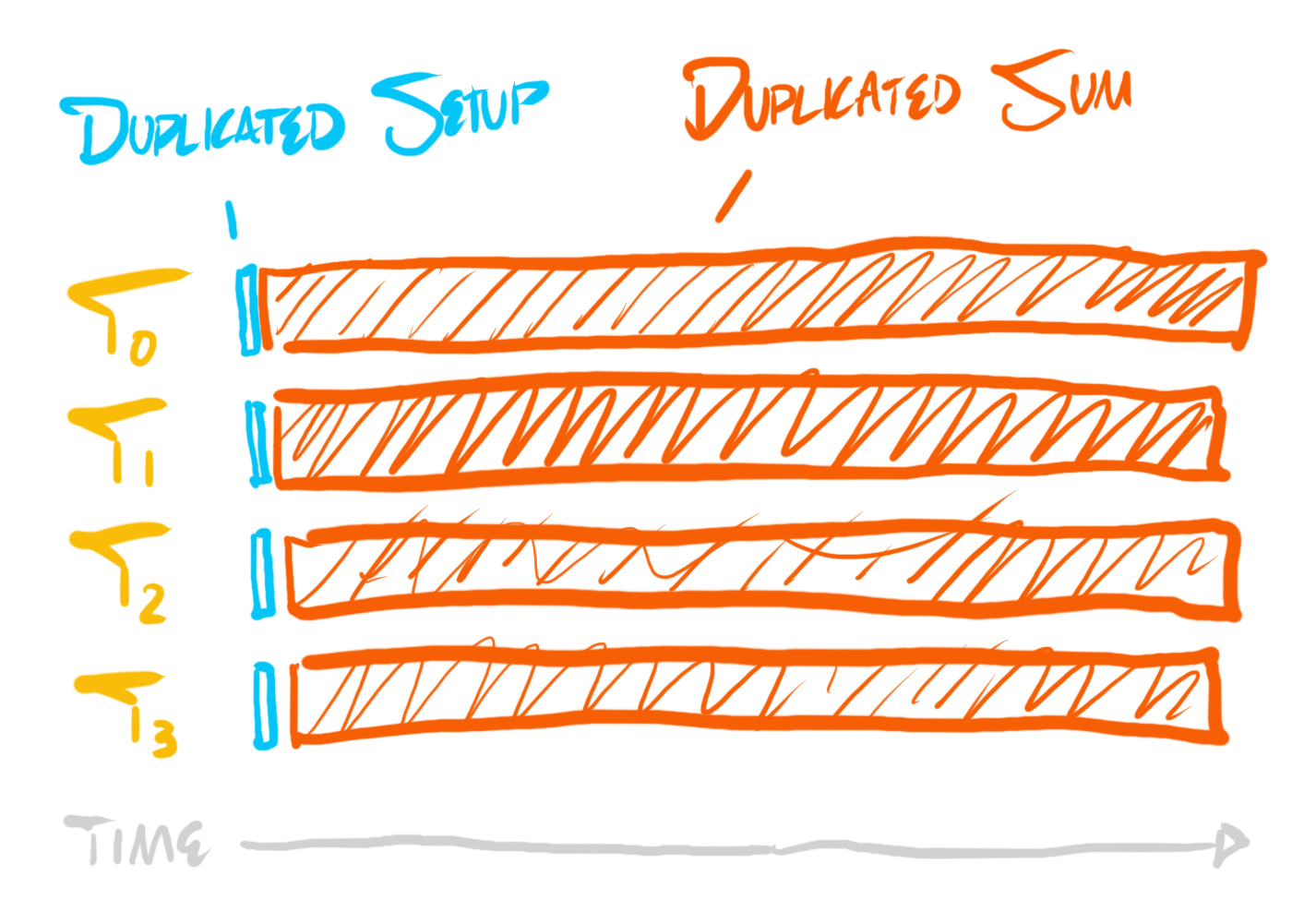
중복 자체가 원칙적으로 문제는 아니며, 때로는 피할 수 없다. 왜냐하면 ‘중복 제거’가 ‘중복’보다 더 비싸게 먹히는 경우가 있기 때문이다. 예를 들어, 어떤 하나의 add 명령의 결과를 여러 스레드에 전달해 그 add의 일을 중복 제거하려 한다면, 그 비용은 그 add 자체를 그냥 중복 수행하는 것보다 훨씬 크다. 우리는 중복 제거를 원하지만, 필요한 경우나 실제로 도움이 될 때만 해야 한다.
그렇다면 어디에서 도움이 될까? 놀랍지 않게, 여기서는 지배적인 비용—우리가 멀티코어를 아예 쓰려는 이유—은 values의 모든 원소를 합하는 데 있다. 합의 서로 다른 부분을 코어에 분산하고 싶다. 우선 전체 합을 계산하는 대신, _스레드별 합_을 계산하자. 그리고 각 _스레드별 합_을 계산하고 나서 결합하자:
void EntryPoint(void *params)
{
S64 thread_idx = (S64)params;
// 뭔가 방식으로 얻어온다고 하자:
S64 *values = ...;
S64 values_count = ...;
// 이 스레드의 합 범위를 결정
S64 thread_first_value_idx = ???;
S64 thread_opl_value_idx = ???; // one past last
// 스레드 합 계산
S64 thread_sum = 0;
for(S64 idx = thread_first_value_idx;
idx < thread_opl_value_idx;
idx += 1)
{
thread_sum += values[idx];
}
// 스레드 합을 결합
S64 sum = ???;
}
채워야 할 빈칸이 두 개 있다:
차례로 보자.
현재 각 스레드에 제공한 유일한 입력은 _인덱스_다. 이는 [0, N) 범위의 값이고, 여기서 _N_은 스레드 수다. 이 값은 지역 변수 thread_idx에 저장되어 있고, 각 스레드는 _[0, N)_의 다른 값을 갖는다. 이 예제는 쉬운 편인데, 합 작업을 모든 스레드에 분배하는 좋은 방법은 합해야 할 값의 개수를 스레드 사이에 균등하게 나누는 것이다. 즉, 우리는 _[0, M)_을 _[0, N)_에 매핑하려는 것이고, 여기서 _M_은 값의 개수(values_count), _N_은 스레드 수다.
거의 다음처럼 계산할 수 있다:
S64 values_count = ...;
S64 thread_idx = ...;
S64 thread_count = NUMBER_OF_CORES;
S64 values_per_thread = values_count / thread_count;
S64 thread_first_value_idx = values_per_thread * thread_idx;
S64 thread_opl_value_idx = thread_first_value_idx + values_per_thread;
거의 맞지만 완전히는 아니다. values_count가 thread_count로 나누어떨어지지 않는 경우를 고려해야 하기 때문이다. values_per_thread가 내림(truncate)되므로, 이 분배는 스레드마다 처리할 값의 수를 0(깔끔히 나눠떨어지면)에서 thread_count-1 사이만큼—즉 나머지만큼—_과소 추정_한다.
따라서 분배가 과소 추정하는 값의 수—“남는 값”—는 다음처럼 계산할 수 있다:
S64 leftover_values_count = values_count % thread_count;
그리고 이 남은 값을 앞쪽의 leftover_values_count개 스레드에 분배한다:
// 스레드당 값 수, 남은 값 수 계산
S64 values_per_thread = values_count / thread_count;
S64 leftover_values_count = values_count % thread_count;
// 현재 스레드가 남은 값을 하나 받는지 결정
// (앞쪽 스레드들에 남은 값을 배분한다)
B32 thread_has_leftover = (thread_idx < leftover_values_count);
// 현재 스레드 범위 앞에 배분된 남은 값의 개수 결정
S64 leftovers_before_this_thread_idx = 0;
if(thread_has_leftover)
{
leftovers_before_this_thread_idx = thread_idx;
}
else
{
leftovers_before_this_thread_idx = leftover_values_count;
}
// [first, opl) 범위 결정
// 앞에 배치된 남은 값 수만큼 first를 이동하고,
// 이 스레드가 남은 값을 받으면 opl을 1 증가
S64 thread_first_value_idx = (values_per_thread * thread_idx +
leftovers_before_this_thread_idx);
S64 thread_opl_value_idx = thread_first_value_idx + values_per_thread;
if(thread_has_leftover)
{
thread_opl_value_idx += 1;
}
좀 더 간결하게 쓰면:
S64 values_per_thread = values_count / thread_count;
S64 leftover_values_count = values_count % thread_count;
B32 thread_has_leftover = (thread_idx < leftover_values_count);
S64 leftovers_before_this_thread_idx = (thread_has_leftover
? thread_idx
: leftover_values_count);
S64 thread_first_value_idx = (values_per_thread * thread_idx +
leftovers_before_this_thread_idx);
S64 thread_opl_value_idx = (thread_first_value_idx + values_per_thread +
!!thread_has_leftover);
이제 이 [first, opl) 계산을 사용해 각 스레드가 자신의 범위만 루프 돌도록 하면, 다른 스레드가 한 합산 작업을 중복하지 않게 된다.
이제 각 스레드의 합을 어떻게 결합해 전체 합을 만들까? 간단한 선택지가 두 가지 있다: (a) 전역 합 카운터를 두고 각 스레드가 자신의 합을 원자적 덧셈(atomic add)으로 더하게 하거나, (b) 모든 스레드의 합을 저장하는 전역 저장소를 두고, 각 스레드가 전체 합을 계산하는 작업을 중복 수행하게 하는 것이다.
(a)의 경우, sum을 static으로 정의하고 각 thread_sum을 원자적으로 더하면 된다:
static S64 sum = 0;
void EntryPoint(void *params)
{
// ...
// `thread_sum` 계산
// ...
AtomicAddEval64(&sum, thread_sum);
}
참고: 이 방식의 단점은 이 코드 경로를 한 번에 하나의 스레드 그룹만 실행할 수 있다는 점이다. 하지만 폭을 넓혀 실행한다면 대개 사용 가능한 모든 코어를 쓰고 있으므로, 동일 코드 경로를 다른 목적으로 다른 스레드 그룹이 동시에 실행하는 것이 유익하지 않을 가능성이 크다. 그렇다 하더라도 이는 이제 이 코드의 새로운 숨은 제약이며, 치명적 문제가 될 수도 있다. 이 문제를 해결하는 기법이 몇 가지 있는데, 이는 뒤에서 다룬다—지금은 중요한 개념만 짚자면, 이 데이터가 참여하는 스레드들 사이에서 공유된다는 점이다.
(b)의 경우, 전역 테이블을 두고 모든 스레드 합의 합을 중복 계산하게 한다. 하지만 이는 각 스레드가 자신의 합산 작업을 끝마친 뒤에만 할 수 있다—그렇지 않으면 다른 스레드의 합이 아직 계산되기도 전에 더해 버릴 수 있다!
static S64 thread_sums[NUMBER_OF_CORES] = {0};
void EntryPoint(void *params)
{
// ...
// `thread_sum` 계산
// ...
thread_sums[thread_idx] = thread_sum;
// ??? 여기서 모든 스레드가 끝날 때까지 기다려야 함!
S64 sum = 0;
for(S64 t_idx = 0; t_idx < NUMBER_OF_CORES; t_idx += 1)
{
sum += thread_sums[t_idx];
}
}
이 추가 대기 요건은 (a)보다 불리한 것처럼 보일 수 있지만, 실제로 합을 _사용_하려는 시점이 오면 (a)에서도 같은 메커니즘이 필요하다—모든 스레드가 어떤 지점에 도달해 sum에 원자적 업데이트를 완료했음을 알기 위해 모두가 그 지점에 도달할 때까지 기다려야 한다.
이를 위해 _배리어(barrier)_를 사용할 수 있다. (a)의 경우:
static S64 sum = 0;
static Barrier barrier = {0};
void EntryPoint(void *params)
{
// ...
// `thread_sum` 계산
// ...
AtomicAddEval64(&sum, thread_sum);
BarrierSync(barrier);
// 이제 `sum`은 완전히 계산되었다!
}
(b)의 경우:
static S64 thread_sums[NUMBER_OF_CORES] = {0};
static Barrier barrier = {0};
void EntryPoint(void *params)
{
// ...
// `thread_sum` 계산
// ...
thread_sums[thread_idx] = thread_sum;
BarrierSync(barrier);
S64 sum = 0;
for(S64 t_idx = 0; t_idx < NUMBER_OF_CORES; t_idx += 1)
{
sum += thread_sums[t_idx];
}
// 이제 `sum`은 완전히 계산되었다!
}
이 시점에서 (a)와 (b)에 필요한 것은 모두 갖췄다. 둘 다 단순하고, 아마 성능 차이도 미세할 것이다. (a)는 모든 스레드에서 원자적 합산이 필요해 하드웨어 차원의 동기화를 수반하고, (b)는 스레드별 합의 합을 중복 계산한다—이 둘의 비용은 미묘하게 다르겠지만, 실제 values 합산에 비하면 큰 차이는 아닐 가능성이 높다.
이 합산 예제가 유용한 도입부가 되었기를 바라지만, 약간 인위적이고 불완전하다는 것도 안다. 특히 프로그램의 두 핵심 부분—입력과 출력—이 빠져 있다. 이 합으로 무엇을 하며, 이를 어떤 출력으로 사용하는가? 입력은 어떻게 얻어 values와 values_count에 저장하는가?
입출력에 대한 이야기를 아주 약간만 덧붙여 보자. 입력은 바이너리 파일에서 values를 읽는다고 하자. 메모리에 저장될 배열이 통째로 들어 있는 파일이다. 출력은 간단히 printf로 stdout에 합을 출력하자.
합을 출력하는 일부터 시작하자. 이게 가장 쉽다.
단일 코어 코드에서는 합을 계산한 뒤 간단히 printf를 호출한다:
S64 sum = ...;
// ...
printf("Sum: %I64d", sum);
우리의 “기본적으로 멀티코어” 코드에서도 똑같이 해 보자. 그러면 출력은 대략 다음처럼 나온다:
Sum: 12345678
Sum: 12345678
Sum: 12345678
Sum: 12345678
Sum: 12345678
Sum: 12345678
Sum: 12345678
Sum: 12345678
당연히, 계산의 대부분에는 여러 코어가 관여하길 원하지만, 실제 printf는 스레드 하나만 하면 된다. 즉, 폭을 좁혀야 한다. 다행히, 넓은 코드에서 좁게 가는 것은, 좁은 코드에서 넓게 가는 것보다 훨씬 쉽다:
S64 sum = ...;
// ...
if(thread_idx == 0)
{
printf("Sum: %I64d", sum);
}
그냥 하나를 제외한 모든 스레드에서 작업을 마스킹하면 된다.
이제 입력 문제를 생각해 보자. 입력 파일의 크기로부터 values_count를 계산하고, values를 위한 저장공간을 할당한 다음, 파일에서 모든 데이터를 읽어 values를 채워야 한다.
이를 단일 스레드 코드로 쓰면 대략 다음과 같다:
char *input_path = ...;
File file = FileOpen(input_path);
S64 size = SizeFromFile(file);
S64 values_count = (size / sizeof(S64));
S64 *values = (S64 *)Allocate(values_count * sizeof(values[0]));
FileRead(file, 0, values_count * sizeof(values[0]), values);
FileClose(file);
그러니, 이를 좁게 처리하는 것이 당연한 한 가지 선택지다:
if(thread_idx == 0)
{
char *input_path = ...;
File file = FileOpen(input_path);
S64 size = SizeFromFile(file);
S64 values_count = (size / sizeof(S64));
S64 *values = (S64 *)Allocate(values_count * sizeof(values[0]));
FileRead(file, 0, values_count * sizeof(values[0]), values);
FileClose(file);
}
BarrierSync(barrier); // 이 지점 이후 `values`, `values_count` 사용 가능
이렇게도 된다. 하지만 계산한 values와 values_count를 모든 스레드에 브로드캐스트해야 한다. 쉬운 방법은 앞서 공유 데이터에서 했던 것처럼 이들을 그냥 static으로 빼는 것이다:
static S64 values_count = 0;
static S64 *values = 0;
if(thread_idx == 0)
{
char *input_path = ...;
File file = FileOpen(input_path);
S64 size = SizeFromFile(file);
values_count = (size / sizeof(S64));
values = (S64 *)Allocate(values_count * sizeof(values[0]));
FileRead(file, 0, values_count * sizeof(values[0]), values);
FileClose(file);
}
BarrierSync(barrier);
하지만 이를 완전히 단일 스레드로 하고 싶지 않을 수도 있다. 여러 스레드에서 FileRead를 발행하는 편이 하나에서만 하는 것보다 효율적일 때도 있다. 실제로 이는 부분적으로 사실이다(다만 커널, 스토리지 하드웨어 등 전체 스택에 따라, 특정 스레드 수를 넘어가면 이득이 없거나, 읽기 크기에 따라 달라질 수 있다).
그러니 FileRead도 넓게 하고 싶다고 해 보자. values의 할당은 단일 스레드에서 해야 하지만, 그 뒤의 작업 분배는 아주 간단하다:
// 모든 스레드에서 파일을 열 수 있다(다만 경우에 따라
// 이것도 중복 제거하는 편이 나을 수 있다—단순화를 위해 모든 스레드에서 열자)
File file = FileOpen(input_path);
// 값의 개수 계산 및 할당(단일 스레드)
static S64 values_count = 0;
static S64 *values = 0;
if(thread_idx == 0)
{
S64 size = SizeFromFile(file);
values_count = (size / sizeof(S64));
values = (S64 *)Allocate(values_count * sizeof(values[0]));
}
BarrierSync(barrier);
// 스레드의 값 범위 계산(앞서 계산과 동일)
S64 thread_first_value_idx = ...;
S64 thread_opl_value_idx = ...;
// 이 스레드가 맡은 부분 읽기
S64 num_values_this_thread = (thread_opl_value_idx - thread_first_value_idx);
FileRead(file,
thread_first_value_idx*sizeof(values[0]),
num_values_this_thread*sizeof(values[0]),
values + thread_first_value_idx);
// 모든 스레드에서 파일 닫기
FileClose(file);
이제는 _훨씬 간단_하다—예를 들어, 원래의 병렬 for 방식과 비교하면—문제의 또 다른 부분을 이렇게 쉽게 스레드에 분산할 수 있다. 프로그램의 기본 모양이 _넓음_이기 때문에 가능한 일이다.
우리는 단일 코어 머신에 있는 것처럼 대부분의 시간을 보내는 대신, 실제 환경—코어가 여러 개이며, 가끔 몇 가지 직렬 의존성으로 묶어줘야 한다—을 그냥 가정한다.
앞서 values 배열 분배 계산을 다시 보자:
S64 values_per_thread = values_count / thread_count;
S64 leftover_values_count = values_count % thread_count;
B32 thread_has_leftover = (thread_idx < leftover_values_count);
S64 leftovers_before_this_thread_idx = (thread_has_leftover
? thread_idx
: leftover_values_count);
S64 thread_first_value_idx = (values_per_thread * thread_idx +
leftovers_before_this_thread_idx);
S64 thread_opl_value_idx = (thread_first_value_idx + values_per_thread +
!!thread_has_leftover);
이 예는 쉬운 경우다. values를 균일하게 나누면 각 코어가 맡는 _일_도 거의 균일하기 때문이다.
반대로 어떤 시나리오에서는 각 코어에 분배되는 일이 거의 균일하지 않을 수 있다. 이 경우에는 문제가 생긴다. 어떤 코어는 어떤 섹션에서 일을 훨씬 빨리 끝내고 다음 배리어 동기화 지점에서 다른 코어를 기다리게 된다. 이는 우리가 애초에 넓게 가서 얻고자 한 이익을 갉아먹는다.
따라서 가능한 경우에는 항상 _일_을 균일하게 분배하는 것이 중요하다. 이를 위한 정확한 전략은 문제마다 다르다. 하지만 나는 세 가지 흔한 전략을 보았다:
첫 번째 전략은 합 예제로 이미 다뤘다—이제 뒤의 두 가지를 보자.
많은 작업 유닛—“태스크”—이 있고, 이를 코어에 분배하고 싶다고 하자. 앞서 합에서 그랬던 것처럼 태스크를 분배하는 것으로 시작할 수 있다:
Task *tasks = ...;
S64 tasks_count = ...;
S64 thread_first_task_idx = ...;
S64 thread_opl_task_idx = ...;
for(S64 task_idx = thread_first_task_idx;
task_idx < thread_last_task_idx;
task_idx += 1)
{
// do task
}
각 태스크가 요구하는 일의 양이 가변적이라면, 프로그램의 프로파일은 대략 다음처럼 보일 수 있다:

태스크 분할을 사전에 정하는 대신, 동적으로 태스크를 배정할 수 있다. 큰 태스크를 수행하느라 바쁜 스레드는 끝날 때까지 새 태스크를 배정받지 않고, 더 짧은 태스크를 먼저 끝내는 스레드는 가능한 경우 더 빨리 새 태스크를 배정받는다.
이는 각 스레드가 증가시키는 공유 원자적 카운터로 간단히 구현할 수 있다:
Task *tasks = ...;
S64 tasks_count = ...;
// 카운터 설정
static S64 task_take_counter = 0;
task_take_counter = 0;
BarrierSync(barrier);
// 모든 스레드에서 루프—가져갈 태스크가 있는 동안 계속 가져간다
for(;;)
{
S64 task_idx = AtomicIncEval64(&task_take_counter) - 1;
if(task_idx >= tasks_count)
{
break;
}
// do task
}
이렇게 하면 태스크가 코어에 동적으로 분배되어, 프로그램의 프로파일은 다음처럼 보일 것이다:
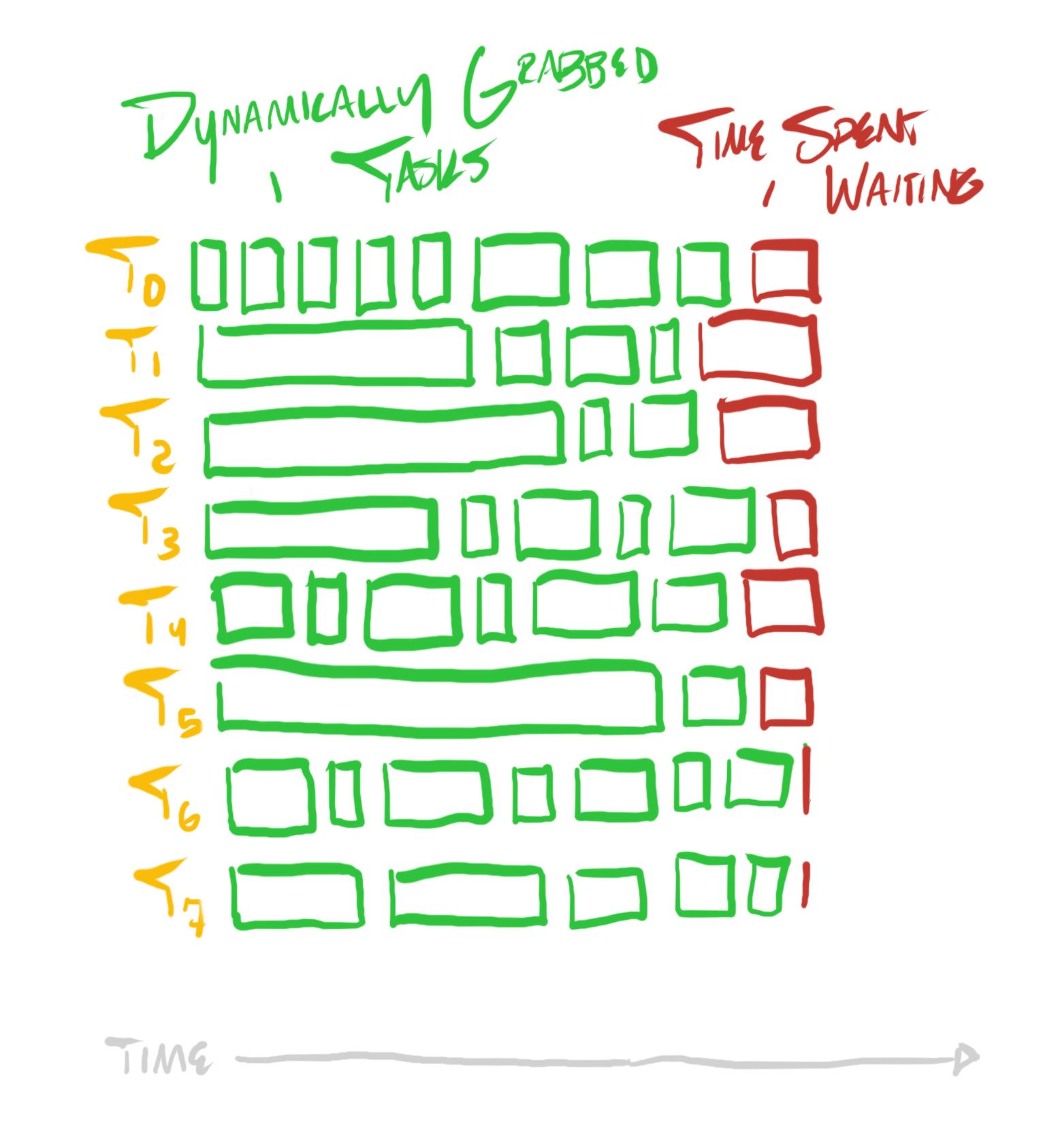
동적으로 태스크를 코어에 배정하는 것은 많은 경우 도움이 되지만, 태스크의 편차가 매우 커서 어떤 것은 지나치게 길거나(작은 태스크보다 훨씬 비싼 경우), 태스크 수가 코어 수보다 적다면 효과가 떨어진다.
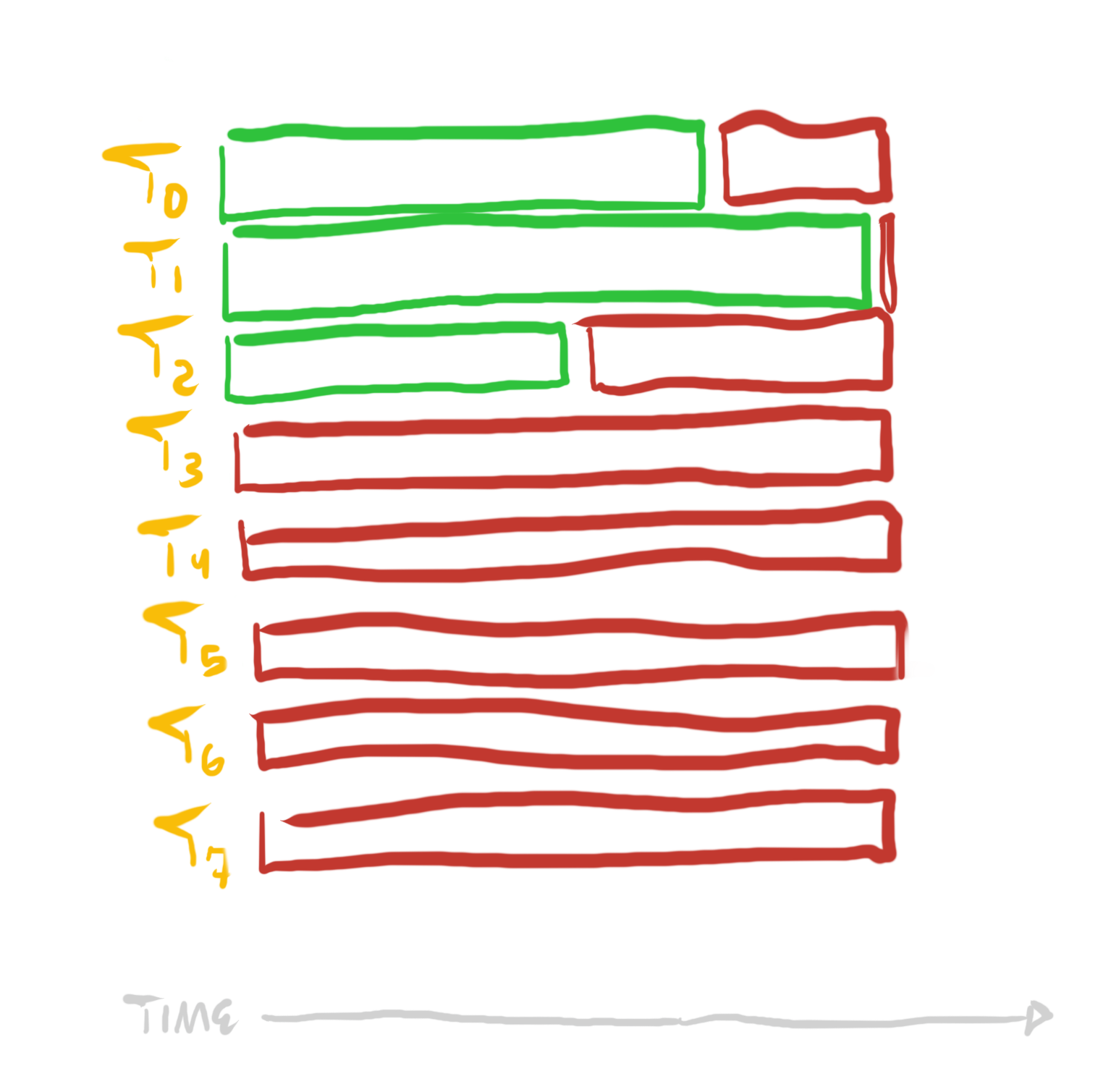
이런 경우에는 단일 태스크 _내부_의 직렬 독립성을 다시 생각해 보거나, 직렬 의존성이 큰 알고리즘과 동일한 _효과_를 더 높은 직렬 _독립성_을 가진 대체 알고리즘으로 제공할 수 있는지 고민해 보면 도움이 된다. 단일 태스크를 더 쪼갤 수 있을까? 다른 방식으로 수행할 수 있을까? 직렬 의존 작업을, 직렬 독립적으로 할 수 있는 더 무거운 작업과 분리해 낼 수 있을까?
답은 문제마다 다르므로, 이만큼 일반적 수준에서 더 유용한 조언을 제공하기는 어렵다. 하지만 반직관적일 때조차 가능하다는 것을 보여 주기 위해, 최근 작업에서 관찰한 한 예를 들겠다. 더 균일한 일 분배를 찾기 위해 단일 스레드 비교 기반 정렬에서 높은 병렬성을 가지는 기수 정렬(radix sort)로 전환해야 했다.
이 문제에서 나는 소수의 배열만 정렬하면 됐지만, 배열은 매우 클 수 있어 정렬 과정이 꽤 비싼 패스가 되곤 했다.
처음 시도는 비교 정렬 태스크 자체를 분배하는 것이었다. 즉, 하나의 배열을 하나의 코어에서 정렬하고, 다른 코어들은 다른 배열을 정렬하게 했다. 하지만 앞서 말했듯이 배열 수는 상대적으로 적고 배열은 크기 때문에, 정렬이 꽤 비쌌다—결국 대부분의 코어는 아무것도 하지 않고, 소수의 정렬을 수행하는 코어가 끝나기를 기다리게 됐다.
이 접근은 더 작은 태스크가 많았다면 괜찮았을 것이다. 사실 같은 프로그램의 다른 부분에서는 단일 스레드 비교 정렬 태스크를 이런 방식으로 분배한다. 그 부분에서는 더 작은 태스크가 많기 때문이다.
여기서는 64비트 정수 키를 기준으로 배열 원소를 정렬해야 했다. 정렬 후에는 키 값이 오름차순이 되도록 원소를 배치해야 했다.
마침 이 문제는 기수 정렬로 해결할 수 있다. 여기서 알고리즘의 모든 세부를 다루지는 않겠다(최근 스트림에서 간단히 다뤘고, 이곳에 녹화 영상을 올려 두었다). 중요한 점은 기수 정렬은 배열에 대해 고정된 횟수의 O(N) 패스를 요구하고, 각 패스에서의 큰 작업 덩어리 대부분을 코어들에 균등하게 분배할 수 있다는 것이다(앞서 합 작업을 분배한 것과 같은 방식으로).
이제 모든 코어가 모든 큰 정렬 태스크에 참여하지만, 각 정렬에서 거의 균등한 비율의 작업만 수행한다. 결과적으로 일 분배가 훨씬 균일해지고, 정렬에 소요되는 전체 시간도 훨씬 짧아진다:

이는 내가 관찰한 더 큰 패턴의 한 구체적 사례다: 많은 문제에서 면밀히 살펴보면 직렬 의존성은 사라지기도 하고, 더 무거운 작업과의 분리로 인해 풀려나기도 한다.
어떤 문제에서는 알고리즘의 직렬 의존 부분을 고립시켜, 이후의 알고리즘이 직렬 독립적으로 수행될 수 있도록 데이터를 준비하게 만들 수 있다. 예를 들어, 프로그램이 초반에 단일 코어에서 링크드 리스트를 순회해 직렬 의존적인 방식으로 레이아웃을 계산한다고 하자. 그러면 이후의 작업은 포인터 추적 같은 직렬 의존 작업을 강요하지 않고, 완성된 레이아웃만 사용해 실행될 수 있게 된다.
기본적으로 멀티코어인 코드 스타일은, 몇 가지 작은 보강만 더해 주면, 평범한 단일 스레드 코드처럼 느껴진다—여러 코어에서 실행하는 데 필요한 빠진 정보를 표현하는 기본적인 구성요소들, 예컨대 LaneIdx(), LaneCount(), LaneSync() 같은 것들 말이다. 이 스타일은 많은 실제 멀티코어 코드에서 볼 수 있는 인기 있는 스타일들보다, 여러 면에서 더 유용하고 흥미로운 성질을 갖기 때문에 여러 문맥에서 선호될 수 있다.
이런 방식으로—기본적으로 멀티코어—작성된 코드의 흥미로운 함의 하나는, 단일 코어로 작성된 코드보다 엄밀히 더 큰 _상위 집합_의 기능을 제공한다는 것이다. 여기서 “멀티코어”에는 ‘단일 코어’가 한 가지 경우로 포함되기 때문이다. 동일한 코드를 단지 하나의 스레드에서만 실행하고, 그 스레드에 thread_idx = 0, thread_count = 1을 넘기기만 하면, 단일 코어에서 실행할 수 있다.
이 경우 하나의 코어가 모든 일을 받는다. BarrierSync는 아무 일도 하지 않는다(기다릴 다른 스레드가 없기 때문에). 따라서 이는 단일 코어 기능과 같다.
이 스타일의 멀티코어 프로그래밍은, 어떤 코드 경로에서 여러 코어를 쓰기 위해 필요한 잡일과 장치가 훨씬 적다. 하지만 앞서 잡 시스템과 병렬 for의 문제로 지적한 것은, 잡일과 장치가 많다는 점뿐 아니라, 디버깅이 더 어렵다는 점이기도 했다.
이번 경우에는 디버깅이 훨씬 간단하다—사실 단일 코어 디버깅과 크게 다르지 않다. 어느 지점에서든, 디버거로 들여다보는 시점까지 도달하게 만든 전체 콜스택과 문맥 데이터를 볼 수 있다.
게다가 참여하는 모든 스레드가 거의 동질적이기 때문에(잡 시스템에서는 모든 스레드가 항상 이질적이다), _하나의 스레드_를 디버깅하는 것이 _모든 스레드_를 디버깅하는 것과 매우 유사하다. 특히 배리어 동기화 지점 사이에서는 모든 스레드가 같은 코드를 실행하기 때문에 더욱 그렇다. 다시 말해, 하나의 스레드에서의 컨텍스트와 상태는 모든 스레드의 컨텍스트와 상태를 매우 잘 알려주는 경향이 있다.
전통적 잡 시스템에서는 어떤 작업의 관통선(through line)에 해당하는 문맥이 자주 바뀌기 때문에, 한 문맥에서 다른 문맥—잡과 스레드를 가로질러—으로 데이터를 전달하고, 관련 할당과 수명을 유지하기 위한 추가 장치가 필요하다. 반면 이 스타일에서는 리소스와 수명이 단일 스레드 코드만큼 단순한 수준으로 유지된다.
어떤 시점의 모든 문맥 상태를 담는 스택은, 유용한 스레드 로컬 저장소를 위한 단일 바스켓이 된다. 잡 시스템에서 스택은 멀티코어 스레드 로컬 저장소로 유용하지만, 잡의 지속 시간 동안에만 그렇다. 잡은 for 루프의 내부 몸체에 해당하며, 이는 아주 작은 파편적 스코프다. 이 스타일에서는 언제든 전체 스택을 사용할 수 있다.
나는 기본적으로 멀티코어인 코드에서 널리 추출해 쓸 수 있는 몇 가지 유용한 패턴을 찾았다. 이 패턴들은 아레나만큼 널리 적용 가능해 보이며, 따라서 코드베이스의 베이스 레이어에 유용한 추가물이 될 수 있다.
이전 예제 코드에서는 thread_idx, thread_count, barrier 변수를 자주 사용했다. 이들이 필요할 수도 있는 모든 코드 경로에 이것들을 넘기는 일은 중복이고 번거롭다. 따라서 이들은 스레드 로컬 저장소에 넣기 좋은 후보들이다.
내 코드에서는 이것들을 베이스 레이어의 “스레드 컨텍스트”에 묶었다. 이는 어디서든 접근 가능한 스레드 로컬 구조체이며—예를 들어 스레드별 스크래치 아레나가 저장되는 곳이다.
이를 통해 모든 코드는 자신이 스레드 그룹에서 몇 번째인지(thread_idx), 그룹의 스레드 수가 얼마인지(thread_count)를 읽을 수 있고, 다른 레인들과 동기화(BarrierSync)할 수 있다.
앞서 말했듯이, 어떤 코드의 _호출자_는 이 스레드 로컬 저장소를 구성함으로써 이 코드를 “얼마나 넓게”—몇 개의 코어에서—실행할지 선택할 수 있다. 일반적으로 콜스택의 얕은 부분이, 그 아래 깊은 부분이 얼마나 넓게 실행될지 결정할 수 있다. 어떤 작업이 아주 작아서(많은 코어에서 실행해도 이득이 없고) 다른 코어가 다른 유용한 일을 하는 편이 낫다면, 그 작업을 하기 전에 호출 코드는 간단히 thread_idx = 0, thread_count = 1, barrier = {0}로 설정하면 된다.
이는 하나의 스레드가 서로 다른 여러 스레드 그룹에 참여할 수 있음을 의미한다—다시 말해, 하나의 스레드 실행 동안 thread_idx와 thread_count가 고정되어 있지는 않다. 그래서 나는 구분을 위해 용어 하나를 더 도입했다: 레인(lane). 레인은 스레드와 구분된다. 레인은 단지 잠정적인 그룹 안에서 같은 코드를 실행하는 스레드 중 하나를 의미한다.
그래서 내 용어에서 thread_idx는 LaneIdx()로, thread_count는 LaneCount()로 노출된다. 다른 레인과 동기화하려면, 현재 선택된 배리어를 기다리는 헬퍼 LaneSync()를 사용한다.
다음 계산을 여러 번 언급했다:
S64 values_per_thread = values_count / thread_count;
S64 leftover_values_count = values_count % thread_count;
B32 thread_has_leftover = (thread_idx < leftover_values_count);
S64 leftovers_before_this_thread_idx = (thread_has_leftover
? thread_idx
: leftover_values_count);
S64 thread_first_value_idx = (values_per_thread * thread_idx +
leftovers_before_this_thread_idx);
S64 thread_opl_value_idx = (thread_first_value_idx + values_per_thread +
!!thread_has_leftover);
균일하게 분배된 범위가 코어 간 균일한 작업량에 대응할 때 유용하다. 물론 항상 바람직한 것은 아니다. 그럼에도 불구하고 매우 흔한 경우다. 그래서 이를 LaneRange(count)로 노출해 두면 유용했다:
Rng1U64 range = LaneRange(count);
for(U64 idx = range.min; idx < range.max; idx += 1)
{
// ...
}
앞서, 레인 간에 변수를 공유해야 할 때는 그 변수를 static으로 표시하면 된다고 했다. 하지만 이는 불행히도 한 번에 하나의 그룹만 그 코드를 실행할 수 있게 된다. 아직 한 그룹이 static 변수를 사용 중인데 다른 그룹이 덮어써 버릴 수 있기 때문이다. 이는 때로 문제가 되지 않을 수 있다(어떤 코드는 애초에 하나의 레인 그룹만 실행하는 것이 바람직하므로). 하지만 보이지 않는 제약이 되어, 어떤 경우에는 코드를 부적합하게 만든다.
예를 들어, 기본적으로 멀티코어로 작성된 코드가 있다고 하자. 입력에 따라 이 코드 경로를 전 코어에서 실행하고 싶을 수도 있지만, 다른 경우에는 하나의 코어에서만 실행하고 싶을 수도 있다—여전히 다른 코어에서 이 코드 경로를 실행하고 싶지만, 입력이 다를 수 있다. 이는 여러 레인 그룹이 동시에 같은 코드를 실행함을 의미하므로, 한 그룹에서 레인 간 데이터를 공유하기 위해 static을 쓸 수 없게 된다.
이를 해결하기 위해, 나는 레인 간에 소량의 데이터를 브로드캐스트하는 간단한 메커니즘을 만들었다.
각 스레드 컨텍스트는—레인 인덱스, 레인 수, 레인 그룹 배리어 외에—공유 버퍼에 대한 포인터도 저장한다. 이 포인터는 같은 그룹의 모든 레인에서 같은 값을 가진다.
어떤 레인이 다른 레인에 브로드캐스트해야 할 값을 갖고 있다면—예를 들면, 다른 레인이 곧 채울 버퍼를 할당했다면—다음과 같은 방식으로 값을 전달할 수 있다:
U64 broadcast_size = ...; // 브로드캐스트할 바이트 수
U64 broadcast_src_lane_idx = ...; // 브로드캐스트하는 레인의 인덱스
void *lane_local_storage = ...; // 레인마다 고유
void *lane_shared_storage = ...; // 같은 그룹의 레인에서 동일
// 브로드캐스터 -> 공유로 복사
if(LaneIdx() == broadcast_src_lane_idx)
{
MemoryCopy(lane_shared_storage, lane_local_storage, broadcast_size);
}
LaneSync();
// 공유 -> 브로드캐스티로 복사
if(LaneIdx() != broadcast_src_lane_idx)
{
MemoryCopy(lane_local_storage, lane_shared_storage, broadcast_size);
}
LaneSync();
이 공유 버퍼는 대개 8바이트를 브로드캐스트할 수 있을 정도면 충분했다. 대부분의 소량 데이터는 8바이트 브로드캐스트 몇 번으로 전달할 수 있고, 큰 데이터는 포인터 하나만 브로드캐스트하면 되기 때문이다.
이 메커니즘은 다음 API로 노출한다:
U64 some_value = 0;
U64 src_lane_idx = 0;
LaneSyncU64(&some_value, src_lane_idx);
// 이 줄 이후 모든 레인이 `some_value`의 동일한 값을 공유한다
다음처럼 사용할 수 있다:
```// values_count를 설정하고, 레인 0에서 values를 할당한 뒤
// 두 값을 모든 레인에 브로드캐스트
S64 values_count = 0;
S64 *values = 0;
if(LaneIdx() == 0)
{
values_count = ...;
values = Allocate(sizeof(values[0]) * values_count);
}
LaneSyncU64(&values_count, 0);
LaneSyncU64(&values, 0);
위 메커니즘으로, 원래 합산 예제를 다음 단계로 프로그래밍할 수 있다.
먼저 파일에서 값을 로드한다:
U64 values_count = 0; S64 *values = 0; { File file = FileOpen(input_path); values_count = SizeFromFile(file) / sizeof(values[0]); if(LaneIdx() == 0) { values = (S64 *)Allocate(values_count * sizeof(values[0])); } LaneSyncU64(&values); Rng1U64 value_range = LaneRange(values_count); Rng1U64 byte_range = R1U64(value_range.min * sizeof(values[0]), value_range.max * sizeof(values[0])); FileRead(file, byte_range, values + value_range.min); FileClose(file); } LaneSync();
그 다음, 모든 레인에 걸쳐 합을 계산한다:
```// 공유 카운터 가져오기
S64 sum = 0;
S64 *sum_ptr = ∑
LaneSyncU64(&sum_ptr, 0);
// 레인의 합 계산
S64 lane_sum = 0;
Rng1U64 range = LaneRange(values_count);
for(U64 idx = range.min; idx < range.max; idx += 1)
{
lane_sum += values[idx];
}
// 이 레인의 합을 전체 합에 기여
AtomicAddEval64(sum_ptr, lane_sum);
LaneSync();
LaneSyncU64(&sum, 0);
마지막으로 합을 출력한다:
if(LaneIdx() == 0)
{
printf("Sum: %I64d\n");
}
이 글에서 공유한 개념은, 프로그래머라면 누구나 익숙한 보통의 단일 코어 코드와 비교해, CPU 코드를 표현하는 근본적 전환이라고 생각한다. 코드에 작은 주석(annotations)—LaneIdx(), LaneCount(), LaneSync() 같은 기본 개념—을 추가함으로써, 코드 전체가 여러 코어에서 넓게 실행되는 데 필요한 정보를 갖추게 되고, 현대 머신의 근본적인 멀티코어 현실을 활용해 직렬 독립성을 더 잘 살릴 수 있다.
같은 코드가 단일 코어에서도 그대로 실행될 수 있다. 즉, 이런 추가 주석 덕분에, 그 코드는 단일 코어 등가물(이 주석이 없는)보다 저수준에서 _엄밀히 더 유연_해진다.
물론 이것만으로 멀티스레딩 기법 전체를 포괄하는 것은 아니다. 여기서는 하나의 _타임라인_을 확대해 보며, 한 타임라인이 현대 머신의 멀티코어 현실을 이용해 어떻게 가속될 수 있는지만 본다. 하지만 프로그램은 종종 다수의 이질적인 타임라인을 요구한다. 어떤 레인 그룹은 다른 그룹과 보조를 맞추지 않으며, 따라서 서로의 진행을 방해해서는 안 된다.
하지만 내가 이 글에서 좋아하는 점은, 불필요하게 추가적인 타임라인을 도입하지 않는다는 것이다. 두 이질적 타임라인 사이의 통신에는 상대성에 수반되는 고유 복잡성이 있다. 그런 것들은 항상 필요하다. 하지만 단순한 멀티코어 실행을 달성하기 위해 왜 그 복잡성 비용을 모든 곳에서 지불해야 하는가?
많은 이들에게는 이 아이디어가 새삼스러운 일이 아닐 수 있다는 것을 안다—누구나 각자 다른 시기에 다른 것을 배운다. 하지만 내 과거의 프로그래밍 경험과, 다른 많은 사람들의 프로그래밍을 보면, 사소해 보이는 일을 과도하게 설계하는 경우가 너무 많다. 실제로 다른 도메인(예: 셰이더 프로그래밍)에서는 정말 사소한 일인데도 말이다. 그래서 최소한 많은 사람들에게는 이 개념들이 잘 알려져 있거나 오래된 것으로 보이지 않는다(비록 어떤 커뮤니티나 도메인에서는 그렇겠지만).
어쨌든 이 글에서 공유한 개념들은, 과도한 복잡화 없이 멀티코어 코드를 구성하는 내 능력을 크게 향상시키는 데 아주 도움이 되었다. 그래서 여기에 조심스럽게 문서화할 만큼 중요한 전환이라 느꼈다.
이 개념을 몰랐다면 도움이 되었기를, 이미 알고 있었다면 그래도 흥미롭게 읽었기를 바란다.
이 글이 마음에 들었다면 구독을 고려해 주시길. 읽어줘서 고맙다.
-Ryan