정적 분석의 핵심 개념을 AST에서 IR/CFG로의 변환, 데이터-플로우 분석(워크리스트 알고리즘), 도달 정의/라이브니스 분석 예제로 설명하고, MoonBit 기반 C 정적 분석 프레임워크 MCIL을 사례로 C 분석의 난제까지 살펴본다.
URL: https://www.moonbitlang.com/blog/moonbit-static-analysis

코딩하는 동안 마치 “미리 알고 있는 듯한(foresight)” 느낌을 주는 도구들이 어떻게 동작하는지 궁금했던 적이 있나요? C/C++ 컴파일러가 “변수가 초기화되지 않았을 수도 있음”이라고 경고하거나, TypeScript IDE가 어떤 객체를 “null일 가능성이 있음”이라고 표시할 때, 그들은 실제로 프로그램을 실행하는 것이 아닙니다. 대신 소스 코드를 단순히 “훑어보며(scan)” 런타임에서 발생할 수 있는 위험을 정확히 예측합니다. 그 뒤에는 프로그래밍 세계에서 가장 강력하고 우아한 기술 중 하나인 **정적 분석(Static Analysis)**이 있습니다.
하지만 많은 애플리케이션 개발자들에게 컴파일러와 정적 분석 도구의 내부 동작은 여전히 미스터리한 “블랙박스”로 남아 있습니다. 우리는 매일 그들의 통찰을 누리지만, 그 내부 설계 로직과 이를 움직이는 보편적 패턴을 항상 이해하진 못합니다.
이 글은 그 베일을 걷어내려 합니다. 여러분이 소프트웨어 엔지니어든 로우레벨 시스템 탐험가든, 우리는 바닥부터 이해하는 여정을 시작할 것입니다. 겉보기엔 올바른 코드가 왜 분석 도구에 의해 “표시(flag)”될까요? 이 도구들은 복잡한 문법 구조에서 어떻게 분석 가능한 로직을 추출할까요? 더 중요한 것은, 왜 이들은 모두 비슷한 설계 철학으로 수렴할까요?
마지막에는 성숙한 분석 프레임워크인 MCIL(MoonBit C Intermediate Language) 사례 연구로 마무리하며, 신흥 AI-네이티브 프로그래밍 언어 MoonBit이 C 정적 분석에 어떻게 우아하게 적용될 수 있는지 보여드리겠습니다. 또한 고성능 및 자원 제약 환경에서의 고유한 잠재력도 살펴볼 것입니다.
이 가이드를 따라가면 정적 분석의 핵심 개념을 마스터하는 것을 넘어, 그 설계와 구현을 지배하는 보편 원리까지 이해하게 될 것입니다. 기계가 코드의 의도를 “이해”하고 숨은 결함을 선제적으로 발견하도록 만드는 방법을 함께 탐구해봅시다.
최종 목표를 먼저 보여주며 시작해 보겠습니다. 다음 코드 조각을 보세요:
var x
var y = input()
if y > 0 {
x = y + 1
}
return x
이는 우리가 직접 설계한 단순 언어입니다. 변수 선언, 대입, if 문, while 루프, return 문을 지원합니다. 특히 이 언어에는 블록 레벨 스코프가 없기 때문에 모든 블록은 함수 스코프 안에서 동작합니다.
이 코드에는 버그가 있습니다. 변수 x는 if 문의 then 분기에서만 값이 대입되고, else 분기는 비어 있습니다. 만약 y <= 0이면 프로그램은 else 경로를 따라가게 되는데, 이때 x는 초기화되지 않은 채로 남아있습니다. 그런데 return x는 그 값을 사용하려 합니다. 이는 전형적인 “초기화되지 않은 변수 사용(use of uninitialized variable)” 오류로, 컴파일러 관점에서 논리/문법적으로는 멀쩡해 보일 수 있습니다.
우리가 만들 정적 분석기는 이런 문제를 자동으로 찾아낼 것입니다. 더 중요하게는, 왜 정적 분석기가 이런 방식으로 설계되는지, 그리고 이 설계가 분석을 어떻게 단순하면서도 견고하게 만드는지 탐구할 것입니다.
정적 분석을 시작하기 전에 소스 코드를 구조화된 데이터로 변환해야 합니다. 이 과정은 두 단계로 구성됩니다. 어휘 분석과 구문 분석입니다.
var x = 0은 Var 키워드, 식별자 Ident("x"), 대입 기호 Eq, 정수 리터럴 IntLit(0)이라는 네 개의 토큰으로 인식됩니다. 렉서는 처음부터 끝까지 문자를 스캔하며 공백과 주석을 건너뛰고, 현재 문자들에 따라 토큰 타입을 결정합니다.우리의 AST는 다음과 같이 정의됩니다:
// Expressions
enum Expr {
Int(Int) // Integer: 0, 42
Var(String) // Variable: x, y
BinOp(BinOp, Expr, Expr) // Binary operation: x + 1
Call(String, Array[Expr]) // Function call: input()
Not(Expr) // Logical NOT: !x
}
// Statements
enum Stmt {
VarDecl(String, Expr?) // Variable declaration: var x or var x = 0
Assign(String, Expr) // Assignment: x = 1
If(Expr, Array[Stmt], Array[Stmt]) // if-else
While(Expr, Array[Stmt]) // while loop
Return(Expr) // Return
}
앞선 예제 코드는 다음과 같은 AST로 파싱됩니다:
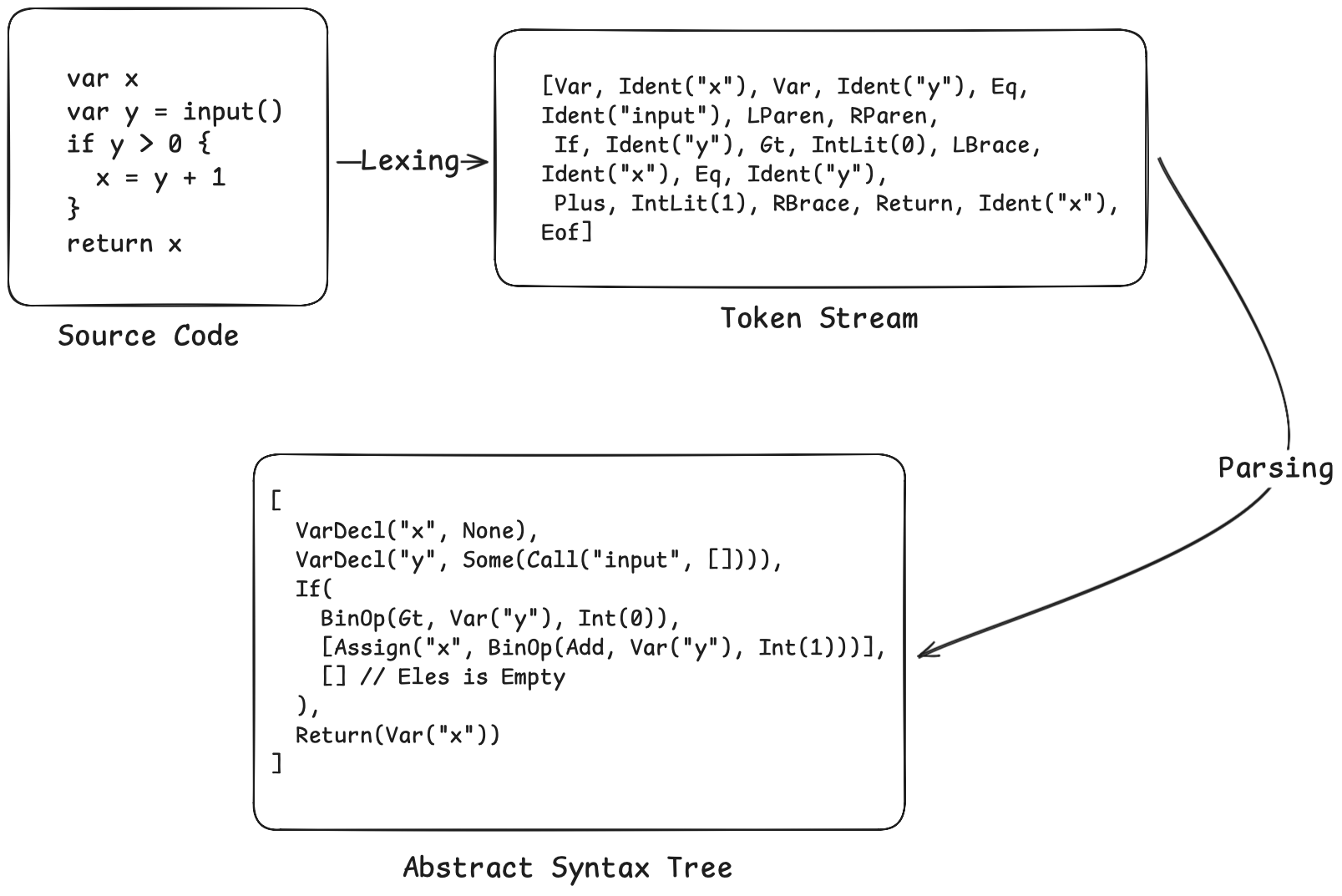
렉서/파서 전체 코드는 약 400줄이며, 글 마지막에 링크된 저장소에서 제공됩니다. 이 섹션은 글의 주요 초점이 아닙니다. 우리의 관심사는 AST를 얻은 뒤 어떻게 분석을 수행하는가에 있습니다.
진행하기 전에 큰 그림을 보겠습니다. 전통적인 컴파일러와 정적 분석기는 서로 다른 길을 가지만, 공통의 출발점이 있습니다:
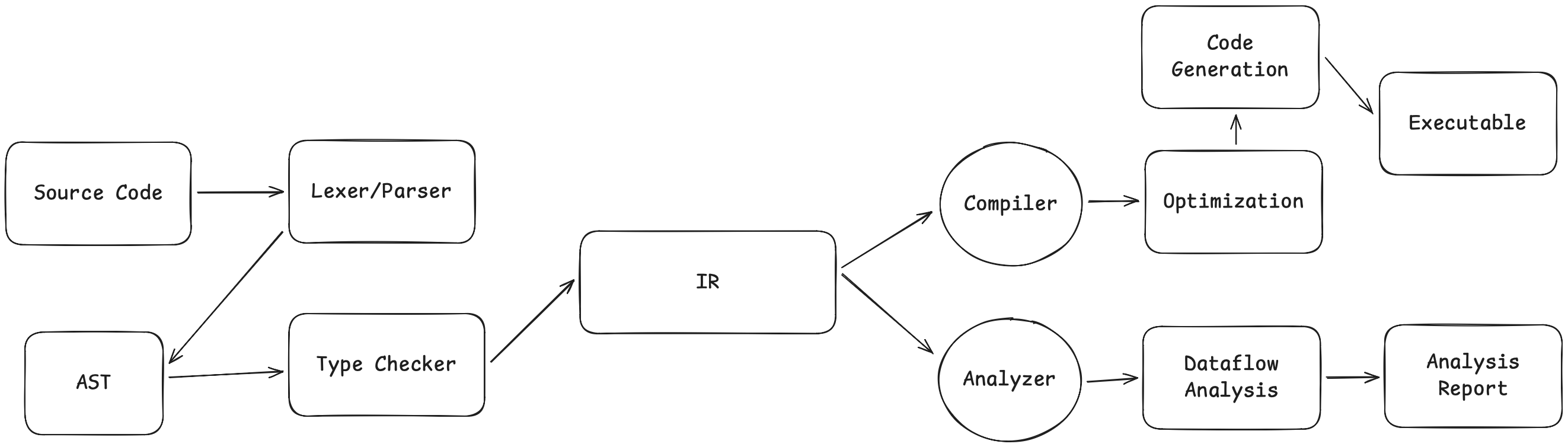
컴파일러와 정적 분석기는 소스 코드에서 IR(Intermediate Representation, 중간 표현)까지의 파이프라인 전반부를 공유합니다. 분기점은 IR 이후입니다. 컴파일러는 계속 아래로 내려가 실행 파일을 생성하지만, 정적 분석기는 여기서 “갈라져” IR 자체를 분석하며 기계어 대신 경고와 오류 리포트를 출력합니다.
둘 모두의 핵심 통찰은 같습니다: AST에서 바로 작업하는 것은 어렵지만, IR로 변환하면 훨씬 쉬워진다는 것입니다. 이것이 CIL(C Intermediate Language) 같은 프레임워크가 존재하는 이유입니다. CIL은 소스 언어의 의미(semantics)를 보존하면서도 분석하기 쉬운 구조를 제공하는 “분석 친화적” 중간 표현을 제공합니다.
이론적으로 AST에서 직접 정적 분석을 수행할 수는 있지만, 실전에서는 극도로 고통스럽습니다. 이유는 분석 목표 자체가 복잡해서가 아니라, AST가 제어 흐름(control flow)을 문법 구조 안에 내장하고 있기 때문입니다. if, while, break, continue, 조기 return 문은 분석 코드가 제어 흐름의 가능한 모든 실행 경로를 명시적으로 시뮬레이션하도록 강제하며, 고정점(fixed-point) 반복과 경로 병합(path merging) 로직이 필요해집니다. 결과적으로 분석기의 복잡도는 분석 문제 자체가 아니라 문법적 디테일에 의해 지배됩니다. 더 나쁜 점은 이 접근이 거의 재사용 불가능하다는 것입니다. “초기화되지 않은 변수 분석”과 “널 포인터 분석”이 추상적으로는 같은 데이터-플로우 분석 범주에 속하더라도, AST 위에서 구현하면 거의 동일한 제어 흐름 처리 코드를 다시 작성해야 합니다. 따라서 AST에 대한 재귀적 분석은 종종 비대하고, 오류가 나기 쉽고, 확장 불가능하며, 통일된 추상화 레벨이 없는 코드로 이어집니다.
CIL(C Intermediate Language)은 UC Berkeley에서 개발된 C 프로그램 분석 프레임워크입니다. 핵심 아이디어는 단순하지만 강력합니다. AST에서 분석하는 대신, 먼저 AST를 분석에 더 적합한 중간 표현(IR)으로 변환하자는 것입니다.
이 IR에는 두 가지 핵심 특징이 있습니다.
기본 블록은 중간에 분기가 없는 선형 실행 코드의 시퀀스이며, 외부에서 블록 중간으로 점프해 들어오는 진입점이 존재하지 않고 시작 지점에서만 들어올 수 있습니다. 즉, 어떤 기본 블록의 첫 명령을 실행하기 시작하면, 끝까지 순서대로 모두 실행하게 되며 중간에 빠져나가거나 중간 진입이 발생하지 않습니다.
기본 블록은 명시적인 점프로 연결됩니다. 예를 들어:
if cond { ──▶ Block0: if cond goto Block1 else Block2
A Block1: A; goto Block3
} else { Block2: B; goto Block3
B Block3: ...
}
while cond { ──▶ Block0: goto Block1
A Block1: if cond goto Block2 else Block3
} Block2: A; goto Block1 ← Backward jump
Block3: ...
if 문은 조건 분기 점프로 바뀌고, while 루프는 사이클로 바뀝니다. Block 2가 실행된 뒤 Block 1로 되돌아가 조건을 다시 검사합니다.
3-주소 코드는 각 명령이 최대 세 개의 “주소(변수)”만 다루는 단순한 명령 형식입니다. 예를 들어 x = y + z * w 같은 복합 표현식은 다음처럼 분해됩니다:
t1 = z * w
t2 = y + t1
x = t2
여기서 t1, t2는 컴파일러가 생성한 임시 변수입니다.
우리 코드에서 IR은 다음과 같이 정의됩니다:
// Instructions: Three-address code format
enum Instr {
BinOp(Operand, BinOp, Operand, Operand) // dest = left op right
Copy(Operand, Operand) // dest = src
Call(Operand, String, Array[Operand]) // dest = func(args...)
}
// Terminators: The exit point of a basic block
enum Terminator {
CondBr(Operand, Int, Int) // if cond goto block1 else block2
Goto(Int) // goto block
Return(Operand) // return value
}
// Basic Block
struct Block {
id : Int
instrs : Array[Instr] // Sequence of instructions within the block
term : Terminator // Terminator instruction
preds : Array[Int] // Predecessor blocks
succs : Array[Int] // Successor blocks
}
앞선 예제가 IR로 변환되면 다음과 같습니다:
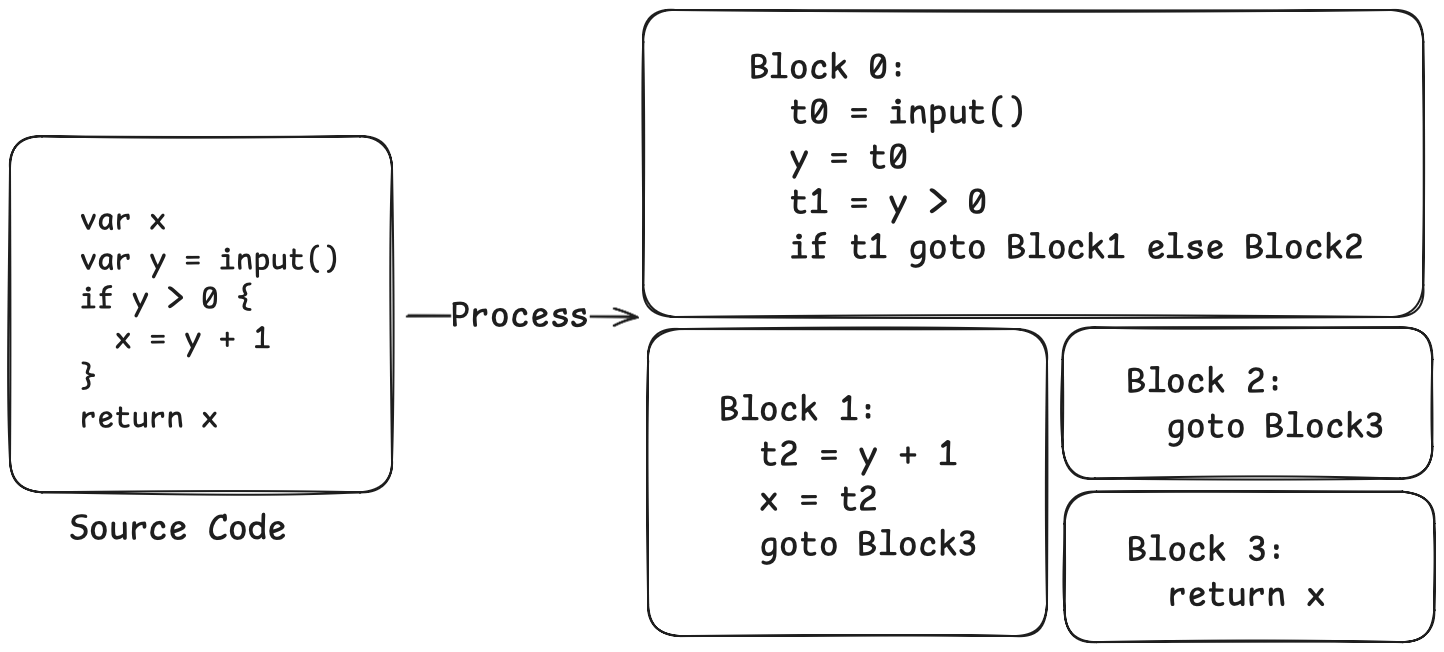
이제 제어 흐름 구조가 한눈에 들어옵니다. Block 0이 엔트리이며, 조건에 따라 Block 1 또는 Block 2로 점프합니다. Block 1과 Block 2는 결국 Block 3로 점프하고, Block 3에서 반환합니다.
이 구조에는 특정 이름이 있습니다: CFG(Control Flow Graph, 제어 흐름 그래프). 그래프의 노드는 기본 블록이며, 간선은 점프 관계를 나타냅니다. 시각화하면 다음과 같습니다:
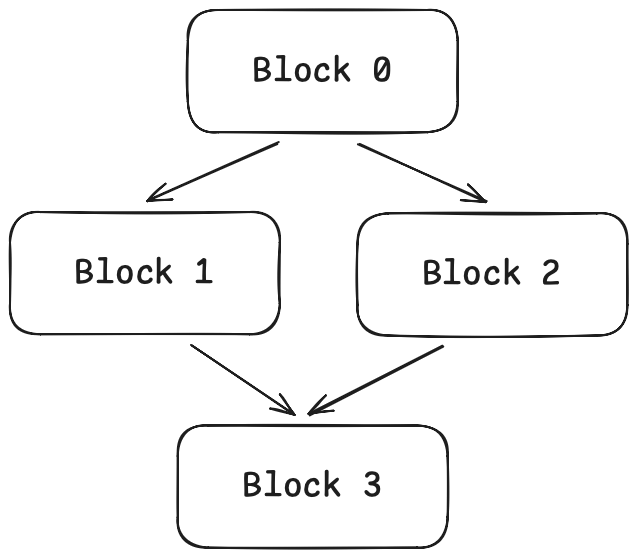
CFG를 얻고 나면, 정보를 그래프를 따라 “흐르게(flow)” 하여 우아하게 분석할 수 있습니다.
“초기화되지 않은 변수 탐지”를 예로 들어봅시다. 우리는 프로그램의 모든 지점에서 어떤 변수가 이미 정의되었는지 알고 싶습니다.
CFG 위에서는 다음처럼 생각할 수 있습니다:
x = 0 이후에는 x가 “정의됨”이 됩니다.x = 1은 x에 대한 이전 정의를 무효화합니다.이것이 데이터-플로우 분석의 핵심 아이디어입니다. 각 기본 블록에 “진입 상태(entry state)”와 “탈출 상태(exit state)”를 붙이고(여기서는 “정의된 변수 집합”), 다음을 정의합니다.
엔트리에서 시작해 모든 블록의 상태가 더 이상 변하지 않을 때(“고정점(fixed point)” 도달)까지 반복합니다.
이 과정은 일반적인 알고리즘 프레임워크인 **워크리스트 알고리즘(Worklist Algorithm)**으로 구현할 수 있습니다:
마지막으로 이 프레임워크를 일반화하면, 사용자는 전달/병합 함수만 제공하면 되는 제네릭 함수로 추상화할 수 있습니다:
struct ForwardConfig[T] {
init : T // Initial state at the entry
transfer : (Block, T) -> T // Transfer function: entry state -> exit state
merge : (T, T) -> T // Merge function: multiple states -> one state
equal : (T, T) -> Bool // Check if states are equal (to detect fixed point)
copy : (T) -> T // Copy state (to avoid shared references)
}
fn forward_dataflow[T](fun_ir : FunIR, config : ForwardConfig[T]) -> Result[T] {
// Initialize the state of each block
// Iterate until fixed point
// ...
}
이 프레임워크의 아름다움은 범용성에 있습니다. 어떤 분석이든(초기화되지 않은 변수, 널 포인터, 정수 오버플로 등) 전달/병합 함수를 정의할 수만 있다면, 매번 복잡한 로직을 다시 작성하지 않고도 같은 프레임워크를 재사용할 수 있습니다.
지금까지 논의한 것은 “전방 분석(Forward Analysis)”입니다. 정보가 프로그램의 진입점에서 종료점으로 흘러갑니다. 하지만 자연스럽게 “후방 분석(Backward Analysis)”이 되는 분석도 있습니다.
“라이브니스 분석(Liveness Analysis)”을 생각해 봅시다. 프로그램의 각 지점에서, 어떤 변수의 값이 이후에 사용될 것인지 알고 싶습니다. 이 질문은 프로그램의 종료점에서 거꾸로 바라봐야 답할 수 있습니다. 어떤 지점 이후로 변수가 다시는 쓰이지 않는다면 그 변수는 “죽었다(dead)”고 하며, 그 이전에 그 변수에 대한 대입은 쓸모없는(죽은 코드, dead code) 것이 됩니다.
후방 분석은 전방 분석의 대칭입니다. 정보가 종료점에서 진입점으로 흘러갑니다. 전달 함수는 “진입 상태 → 탈출 상태”가 아니라 “탈출 상태 → 진입 상태”가 되며, 병합 함수는 선행 블록이 아니라 후속 블록들을 대상으로 동작합니다.
struct BackwardConfig[T] {
init : T // Initial state at the exit
transfer : (Block, T) -> T // Transfer function: exit state -> entry state
merge : (T, T) -> T // Merge the states of successors
equal : (T, T) -> Bool
copy : (T) -> T
}
라이브니스 분석의 전달 함수는 다음처럼 작성됩니다:
fn liveness_transfer(block : Block, out_state : LiveSet) -> LiveSet {
let live = out_state.copy()
// Process instructions from last to first (since it's backward analysis)
for i = block.instrs.length() - 1; i >= 0; i = i - 1 {
let instr = block.instrs[i]
// First, remove the variable defined by this instruction
match get_def(instr) { Some(v) => live.remove(v), None => () }
// Then, add the variables used by this instruction
for v in get_uses(instr) { live.add(v) }
}
live
}
왜 “정의(def)를 먼저 제거하고, 사용(use)을 나중에 추가”할까요? x = x + 1을 생각해 봅시다. 이 명령 이전에는 x를 읽어야 하므로 x는 라이브여야 합니다. 하지만 이 명령 이후에는 x의 이전 값은 더 이상 필요하지 않습니다(덮어쓰였기 때문). 따라서 후방 분석에서는 정의를 먼저 처리해 라이브니스를 죽이고(kill), 그 다음 사용을 처리해 라이브니스를 생성(generate)합니다.
병합 함수로는 라이브니스 분석에서 합집합(union)을 사용합니다. 어떤 변수가 현재 지점에서 라이브인지 여부는, 어떤 나가는 간선에서든 라이브라면 라이브로 봅니다. 프로그램은 어느 분기로든 갈 수 있고, 변수가 사용될 _가능성_만 있어도 라이브로 유지해야 하기 때문입니다.
이제 실용적인 분석 하나를 구현해봅시다. “초기화되지 않았을 가능성이 있는 변수”를 탐지하는 것입니다.
아이디어는 다음과 같습니다. “도달 정의 분석(Reaching Definitions Analysis)”을 사용해 프로그램의 각 지점까지 어떤 변수 정의가 도달할 수 있는지 추적합니다. 어떤 지점에서 변수가 사용되는데 그 변수의 어떤 정의도 그 지점까지 도달할 수 없다면, 이는 초기화되지 않은 사용입니다.
도달 정의 분석은 전방 분석입니다. 각 대입문은 새 정의를 생성하고, 동일 변수에 대한 이전 정의를 제거(kill)합니다. 병합 지점에서는 여러 분기에서 온 정의 집합을 합집합(union)으로 결합합니다(어떤 경로에서든 온 정의가 도달할 수 있으므로).
도달 정의 정보가 있으면 탐지는 간단합니다:
for block in fun_ir.blocks {
let mut defs = reaching.defs_in[block.id]
for instr in block.instrs {
// Check used variables
for var in get_uses(instr) {
if not(defs.has_def(var)) && not(is_param(var)) {
warn("Variable may be uninitialized: " + var)
}
}
// Update definitions
match get_def(instr) {
Some(var) => defs = defs.update(var, current_def)
None => ()
}
}
}
앞선 예제에 적용해 테스트해 봅시다:
Warning: Variable may be uninitialized: x (at Block 3, Return)
훌륭합니다! 바로 우리가 원하던 결과입니다.
데모에 사용한 프로젝트는 MiniCIL이라 부르며, CIL을 본뜬 단순 교육용 프로젝트입니다. DSL은 몇 가지 기본 문장 타입만 갖습니다. 하지만 실제 C는 훨씬 복잡합니다. 이를 다루기 위해 우리는 CIL을 MoonBit으로 완전 구현한 MCIL을 개발했습니다. MCIL은 전체 C 언어를 처리할 수 있으며 정교한 정적 분석 작업을 수행할 수 있습니다.
MCIL의 아키텍처는 MiniCIL과 동일합니다:
C Source Code → Lexer/Parser → AST → cabs2cil → CIL IR → Analysis
MCIL의 렉서는 sizeof, typedef, struct, -> 등 모든 C 토큰을 처리합니다. 파서는 함수 포인터, 복합 리터럴(compound literals), 지정 초기화(designated initializers), GCC 확장 등 완전한 C 문법을 처리합니다. cabs2cil 변환은 타입 추론, 암묵 변환, 상수 폴딩, 스코프 해석을 담당합니다.
하지만 핵심 분석 프레임워크와 그 밑바닥 원리는 동일합니다. MiniCIL을 이해하면 MCIL 코드베이스를 읽는 것이 훨씬 쉬워집니다.
아래는 MCIL이 C 코드에 대해 간단한 정적 분석을 수행하는 예시입니다:
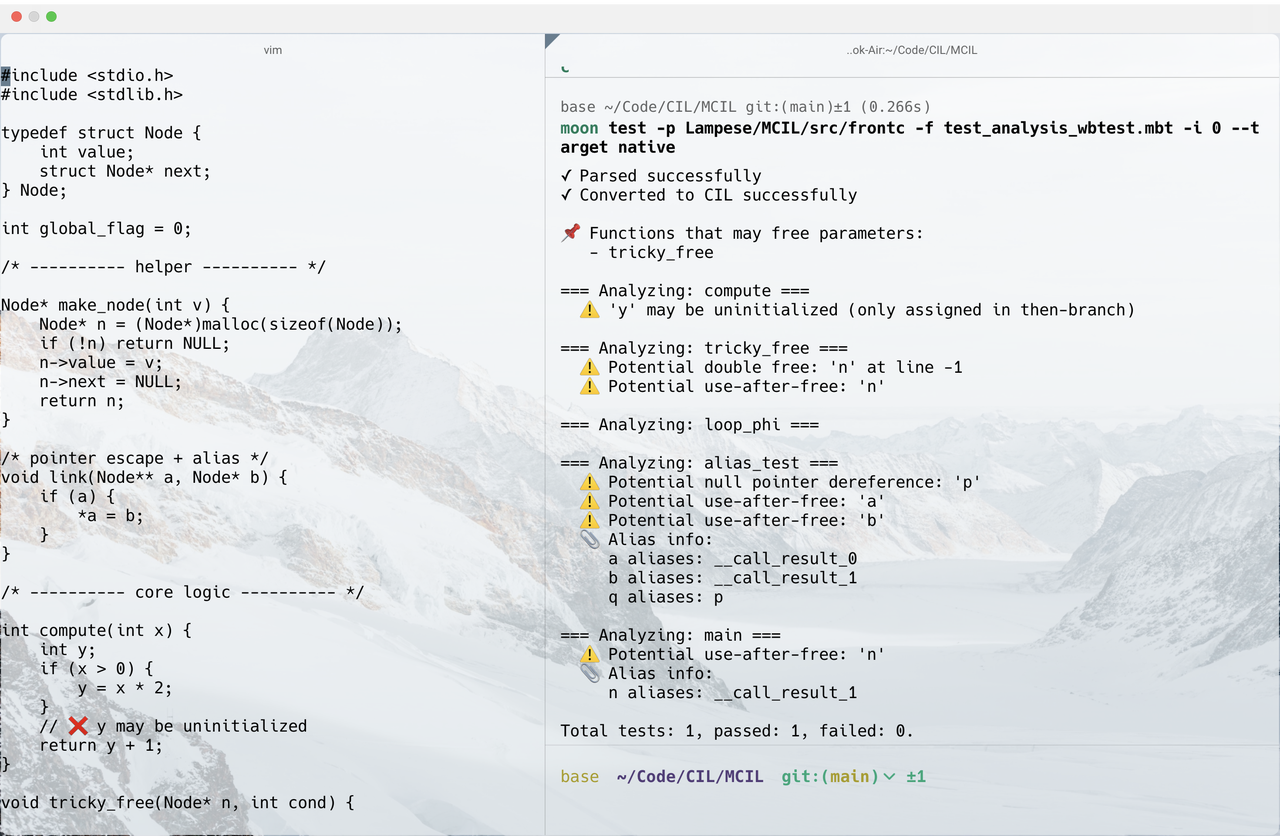
MCIL에 관심 있는 독자를 위해, C 정적 분석에서 특히 중요한 주요 도전 과제는 다음과 같습니다:
*p = 1을 쓸 때, 어떤 변수를 수정하는 걸까요? p가 x 또는 y를 가리킬 수 있다면, 이 문장은 둘 중 어느 쪽이든 수정할 수 있습니다. 더 나아가 p와 q가 동일 메모리 위치를 가리킬 수도(별칭) 있으므로, *p를 수정하면 *q 값도 영향을 받습니다. 포인터 관계를 추적하는 것을 **별칭 분석(Alias Analysis)**이라 하며, 정적 분석에서 가장 어려운 문제 중 하나입니다.foo(x)를 호출할 때 foo가 x가 가리키는 메모리를 수정할까요? 해제(free)할까요? 함수별로만 분석하면 이런 정보가 사라집니다. 절차 간 분석은 **콜 그래프(Call Graph)**를 구축하고 함수 경계를 넘어 데이터 흐름을 추적합니다. MCIL은 기본적인 절차 간 분석을 구현하여 free(p) 호출 후 p를 사용하는 use-after-free 같은 시나리오를 탐지할 수 있습니다.cabs2cil 변환은 이를 정규화하여 통일된 형태로 바꿉니다. 예를 들어 모든 암묵 타입 변환은 명시적 CastE 표현식으로 바꾸고, 배열→포인터 변환은 StartOf로 표현합니다.이 글에서는 정적 분석의 기본 워크플로를 살펴보았습니다. 소스 코드에서 시작해 어휘/구문 분석을 거쳐 AST를 얻고, 이를 기본 블록과 명시적 점프로 구성된 CFG로 변환한 뒤, 데이터-플로우 분석 프레임워크로 고정점에 도달할 때까지 반복합니다. 예시로 라이브니스 분석과 초기화되지 않은 변수 탐지를 구현하며 이 접근의 범용성을 보여주었습니다.
CIL은 2000년대 초반으로 거슬러 올라가며, 2002년 논문 _"CIL: Intermediate Language and Tools for Analysis and Transformation of C Programs"_에서 처음 발표되었습니다. 간결한 설계 덕분에 훌륭한 교육 사례로 여전히 유효합니다. 하지만 컴파일러 기술이 발전하면서 LLVM/Clang 같은 SSA(Static Single Assignment) 중심 인프라가 업계 표준이 되었습니다. 이 프레임워크들은 중간 표현에서의 확장성과 보편성, 단계 간 최적화, 코드 생성에서 더 뛰어난 능력을 제공하며, 실무 엔지니어링에서는 CIL 같은 특화 도구를 점차 대체하고 있습니다. 관심 있는 독자들은 현대적이고 강력한 정적 분석 기법들도 더 탐구해 보길 권합니다.
원본 CIL 논문: CIL: Intermediate Language and Tools for Analysis and Transformation of C Programs
Mini MoonBit C Intermediate Language(교육용 코드): https://github.com/Lampese/MiniCIL
MoonBit C Intermediate Language(MCIL): https://github.com/Lampese/MCIL