자바스크립트 VM이 객체(클래스) 프로퍼티 접근을 CPU가 이해하는 메모리 접근으로 내리면서, 인라인 캐시와 모노모피즘/폴리모피즘/메가모피즘이 성능에 어떤 영향을 주는지 설명한다.
I tweeted about polymorphism and a lot of you were asking for a more in-depth dive into it. So let’s get to it.
가장 중요하게 이해해야 할 것은 virtual machine (VM)이라는 개념입니다. virtual이라는 단어가 뜻하듯, 프로그램이 실행되는 “machine”은 물리적인 것이 아니라 에뮬레이션된 것입니다. 이는 물리 CPU의 실행 모델이 너무 제한적이라 모듈, 클로저, 객체 같은 복잡한 구성 요소를 가진 JavaScript 같은 고수준 언어를 그대로 실행할 수 없다는 뜻입니다.
이를 다루는 방법은 두 가지가 있습니다. 객체/클로저/기타 고수준 개념을 CPU가 실행할 수 있는 저수준 개념인 메모리 접근과 서브루틴으로 매핑해 주는 컴파일러가 하나입니다. 이 변환이 미리 수행되면 컴파일러라고 부릅니다. 애플리케이션이 실행되는 동안 변환이 일어나면 JITing이라고 부르며(JIT는 _Just In Time_의 약자이고 Just-In-Time compilation을 뜻합니다), 우리가 VM을 실행하는 환경을 그렇게 부릅니다.
VM이 물리 CPU로 매핑해야 하는 것들은 많지만, 이 글에서는 객체/클래스에 대해 이야기하겠습니다. 앞으로는 배열(배열도 객체입니다)과 구분하기 위해 이를 그냥 클래스라고 부르겠습니다. 배열은 다르게 취급되기 때문입니다. 따라서 이 논의에서 객체 리터럴은 클래스입니다.
const obj = {
url: 'http://buildre.io',
desc: 'Visual CMS',
};
우리는 이를 클래스라고 생각하지 않지만, 위의 것은 JavaScript VM 내부에서는 클래스로 저장됩니다. 클래스의 핵심 개념은 프로퍼티 접근을 통해 그 내용을 읽을 수 있다는 점입니다.
obj.url // returns http://builder.io``
이해해야 할 점은, 물리 CPU에는 클래스라는 개념이 없다는 것입니다. 클래스는 더 고수준의 구성 요소이고, VM은 CPU가 이해할 수 있도록 이를 저수준 개념으로 번역해야 합니다.
CPU는 주소의 메모리를 읽거나, 어떤 주소로부터의 오프셋 위치에 있는 메모리를 읽는 것만 이해합니다. 이는 배열과 완전히 같지는 않지만, 배열은 매우 좋은 유사 비유입니다. 그래서 CPU 수준에서 무슨 일이 벌어지는지 설명하기 위해, 메모리 접근을 배열 접근으로 취급하겠습니다.
VM의 목적은 클래스 개념을 배열 접근으로 내리는(downlevel) 것이며, CPU가 클래스를 이해하는 “것처럼” 동작하도록 만드는 것입니다.
// Let's say we want to store these objects in a VM.
const builder = {
url: "https://builder.io",
desc: "Visual CMS",
};
const qwik = {
url: "https://qwik.builder.io",
desc: "Instant on web apps",
};
// Let's define a ClassShape which contains
// information about the shape of the object.
// This is greatly simplified from the actual
// implementation.
type ClassShape = string[];
// Define a type for an object. The first element
// is always a reference to the ClassShape the reminder
// are the values of the object.
type Object = [ClassShape, ...any];
// The ClassShape can store the offset and the
// property name information. The VM creates these
// on the fly for each possible object shape.
const vmShape1: ClassShape = ["url", "desc"];
// Now that the ClassShape is defined, we can use it
// create an object like so.
const vmBuilder: Object = [
vmShape1, // <-- ClassShape always at location [0]
"https://builder.io", // <-- The `url` property is at index 1
"Visual CMS", // <-- The `desc` property is at index 2
];
const vmQwik: Object = [
vmShape1, // Notice that this object is of the same shape
"https://qwik.builder.io",
"Instant on web apps",
];
위에서는 객체가 배열로 저장되는 방식을 설명했으니, 이제 프로퍼티 접근을 이야기해 봅시다. VM의 역할은 프로퍼티를 배열 접근으로 번역하는 것이며, 대략 다음과 같이 동작합니다.
// Let's say you want to read these properties
const url1 = builder.url;
const url2 = qwik.url;
// The VM will translate it into something like this.
const url1 = vmBuilder[vmBuilder[0].indexOf("url") + 1];
const url2 = vmQwik[vmQwik[0].indexOf("url") + 1];
VM은 먼저 위치 0에서 ClassShape를 읽고, indexOf()로 원하는 프로퍼티를 찾습니다. 그리고 ClassShape가 들어있는 칸을 보정하기 위해 결과 인덱스에 +1을 하며, 그 인덱스로 실제 값을 읽습니다. (쓰기에도 비슷한 과정을 사용할 수 있습니다.)
NOTE: 실제 indexOf() 구현은 위 코드가 암시하는 O(n)이 아니라 O(1)에 가깝도록 더 복잡합니다. 하지만 설명을 단순하게 유지하기 위해 크게 단순화했습니다.
indexOf() 호출은 핫 패스에 있고 느리기도 합니다. (_Hot path_는 자주 실행되거나 중요한 코드 경로를 뜻합니다.) 강타입 언어는 컴파일 타임에 프로퍼티 이름에서 인덱스로의 변환을 할 수 있지만, 구조적 타이핑( duck-typed ) 언어는 그럴 수 없어서 런타임에 해야 합니다.
기억하실지 모르겠지만, V8이 2008년에 처음 나왔을 때 다른 JavaScript 엔진보다 훨씬 빨랐습니다. 그 이유 중 하나는 V8이 인라인 캐시를 JavaScript 세계에 도입했기 때문입니다(인라인 캐싱은 JVM과 Smalltalk에서 오래전부터 사용되어 왔으므로, 완전히 새로운 혁신은 아니었습니다).
V8은 JIT를 사용합니다. 이는 V8이 일반 모드에서 JavaScript를 실행하면서 애플리케이션이 어떻게 실행되는지에 대한 정보를 수집한다는 뜻입니다. 어떤 함수가 핫 패스에 있다고 판단되면, 일반 실행 모드에서 수집한 가정(assumptions)들의 집합을 바탕으로 다시 컴파일됩니다. 이런 가정 덕분에 JITter는 성능을 크게 개선하는 지름길을 사용할 수 있습니다.
[{
url: "https://builder.io",
desc: "Visual CMS",
}, {
url: "https://qwik.builder.io",
desc: "Instant on web apps",
}].map((obj) => obj.url)
일반 모드로 실행하는 동안:
const vmShape1: ClassShape = ["url", "desc"];
[
[vmShape1, "https://builder.io", "Visual CMS"],
[vmShape1, "https://qwik.builder.io","Instant on web apps",],
].map((obj) => obj[obj[0].indexOf('url')])
일반 실행이 학습하는 것은 obj[0]의 shape이 항상 vmShape1이라는 점입니다. 그래서 출력 코드를 훨씬 더 효율적인 형태로 JIT할 수 있습니다.
const vmShape1: ClassShape = ["url", "desc"];
[
[vmShape1, "https://builder.io", "Visual CMS"],
[vmShape1, "https://qwik.builder.io","Instant on web apps"],
].map((obj) => obj[
obj[0] === vmShape1 ? 1 : // if the class shape is vmShape1. then we know 1
obj[0].indexOf('url') // otherwise fallback to slow path
]
)
이 한 가지 트릭만으로도 프로퍼티 읽기가 60배 빨라질 수 있습니다! 엄청난 성능 향상입니다!
하지만 현실은 조금 더 복잡합니다. 위 코드는 map() 함수에 들어오는 객체들의 shape이 항상 같을 때만 빠르게 동작합니다. 서로 다른 객체 shape이 있다면 어떻게 될까요?
[{
url: "https://builder.io",
desc: "Visual CMS",
}, {
isOSS: true,
url: "https://qwik.builder.io",
}].map((obj) => obj.url)
이 경우 번역은 조금 더 복잡해집니다.
// Notice two different object shapes
const vmShape1: ClassShape = ["url", "desc"];
const vmShape2: ClassShape = ["isOSS", "url`"];
[
[vmShape1, "https://builder.io", "Visual CMS"],
[vmShape2, true, "https://qwik.builder.io"],
].map((obj) => obj[
obj[0] === vmShape1 ? 1 : // inline cache for vmShape1
obj[0] === vmShape2 ? 2 : // inline cache for mvShape2
obj[0].indexOf('url') // otherwise fallback to slow path
]
)
대부분의 VM은 느린 경로로 떨어지기 전에 최대 4개의 서로 다른 shape까지 인라인 처리하려고 합니다.
VM들은 이런 동작에 이름을 붙여 두었습니다. 각각 monomorphic, polymorphic, megamorphic 프로퍼티 읽기입니다. 이제 이를 조금 더 정의해 봅시다.
VM에는 2차 캐시도 있습니다. indexOf() 메서드는 VM에서 실제로 벌어지는 일을 거칠게 근사한 것입니다. 실제 메서드 구현은 indexOf()가 암시하는 것처럼 O(n)이 아니라 O(1)입니다.
indexOf() 메서드는 또한 최근 N개의 프로퍼티-ClassShape 읽기(또는 쓰기)를 추적하는 캐시를 사용합니다. V8에서는 N이 1024이므로, 최근에 본 적이 있는 프로퍼티-ClassShape에 대해 indexOf()를 호출하면, 최근에 본 적이 없는 프로퍼티-ClassShape에 대해 호출하는 것보다 훨씬 더 빠르게 응답할 수 있습니다.
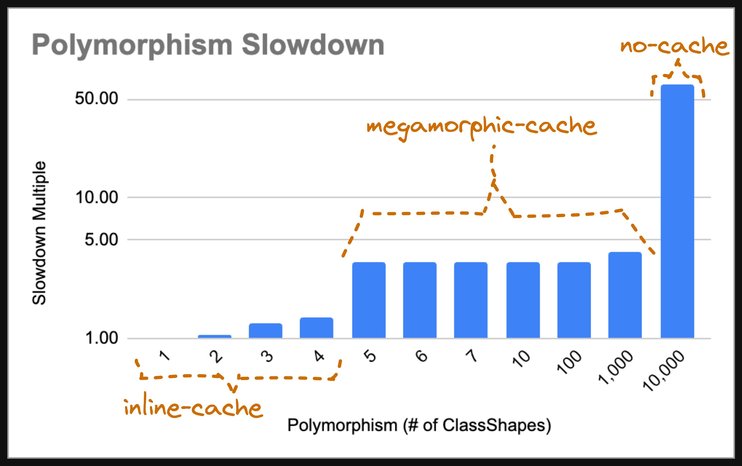
그렇다면 이 모든 것이 실제로 얼마나 큰 차이를 만들까요? 사실 꽤 큽니다! 아래 벤치마크와 결과를 확인해 보세요.
monomorphic 케이스를 단위 비용 1로 가정합니다. 다형성의 정도가 1-4로 증가하는 동안에는 인라인 캐시가 따라갈 수 있고, 결과도 꽤 좋습니다. 4-way 인라인 캐시는 1-way 인라인 캐시(이상적인 경우)보다 40%만 느립니다. 4-way 이후에는 VM이 포기하고 indexOf()로 되돌아갑니다.
하지만 indexOf()에는 megamorphic 캐시가 있으므로, 1-way 캐시보다 약 3.5배 느리긴 해도 여전히 꽤 잘 동작합니다. 다만 shape이 1000개로 늘어나면 성능이 떨어지기 시작하는데, 이는 megamorphic 캐시가 넘쳐서 최악의 시나리오로 되돌아가기 때문입니다. 최악의 시나리오는 megamorphic 케이스보다 60배 느립니다. 이는 매우 큰 차이입니다!
사람들은 자신의 주장을 증명하기 위해 마이크로벤치마크를 작성하는 것을 좋아합니다. 하지만 주의해야 합니다. 많은 마이크로벤치마크는 실제 사용 사례를 반영하지 못하는 함정에 빠집니다. 그중 대부분은 함수에 흘려보내는 class shape의 개수가 실제 사용 사례를 반영하지 않기 때문에 실패합니다.
이는 인라인 캐시가 개입해 코드가 실제보다 훨씬 더 빠르게 보이게 만듭니다. 그리고 shape을 더 많이 넣더라도, 마이크로벤치마크에서 megamorphic 캐시를 넘쳐버릴 정도로 만들기는 쉽지 않습니다.
CPU는 우리가 고수준 프로그래밍 언어에서 당연하게 여기는 많은 개념을 이해하지 못합니다. VM의 역할은 CPU가 이해하는 저수준 프리미티브로부터 고수준 개념을 에뮬레이션하는 것입니다.
이런 에뮬레이션 중 상당수는 비용이 크기 때문에, VM은 코드 실행을 가속하기 위한 트릭들을 사용합니다. 이러한 트릭을 이해하면, 어떤 코드가 빠를 때와 느려질 수 있는 때를 더 잘 이해하는 데 도움이 됩니다.
가장 크게 주의해야 할 점은 마이크로벤치마크를 있는 그대로 받아들이는 것입니다. 마이크로벤치마크는 종종 더 현실적인 실제 시나리오에서(더 많은 class shape이 등장하는 상황에서) 사라져버릴 성능을 보여주기 때문입니다.