마이크로 프런트엔드는 대형 프런트엔드 모놀리스를 더 작고 독립적으로 배포 가능한 애플리케이션으로 나누어, 조직과 코드베이스, 배포를 분리하면서도 사용자에게는 하나의 일관된 제품처럼 보이게 하는 아키텍처 스타일이다.
최근 몇 년간 마이크로서비스가 크게 유행하면서, 많은 조직이 거대하고 모놀리식인 백엔드의 한계를 피하기 위해 이 아키텍처 스타일을 사용하고 있다. 서버 사이드 소프트웨어를 이렇게 만드는 방식에 대해서는 많은 글이 나와 있지만, 여전히 많은 회사들이 모놀리식 프런트엔드 코드베이스 때문에 어려움을 겪고 있다.
점진적 웹 앱(PWA)이나 반응형 웹 애플리케이션을 만들고 싶은데, 기존 코드 어디에 이런 기능을 통합해야 할지 감이 오지 않을 수 있다. 새로운 JavaScript 언어 기능(또는 JavaScript로 컴파일되는 수많은 언어들 중 하나)을 사용하고 싶은데, 필요한 빌드 도구를 기존 빌드 프로세스에 넣을 수 없을 수도 있다. 또는 여러 팀이 하나의 제품을 동시에 개발할 수 있도록 규모를 키우고 싶은데, 기존 모놀리스의 결합도와 복잡도 때문에 모두가 서로의 발을 밟는 상황일 수도 있다. 이 모든 것은 실제로 존재하는 문제이며, 고객에게 고품질 경험을 효율적으로 제공하는 능력에 부정적인 영향을 줄 수 있다.
요즘 우리는 복잡하고 현대적인 웹 개발에 필요한 전체적인 아키텍처와 조직 구조에 점점 더 많은 관심이 쏠리고 있는 것을 보고 있다. 특히, 프런트엔드 모놀리스를 더 작고 단순한 조각으로 분해하는 패턴이 등장하고 있다. 이렇게 하면 각 조각을 독립적으로 개발·테스트·배포할 수 있으면서도, 고객에게는 하나의 응집력 있는 제품처럼 보이게 할 수 있다. 우리는 이 기법을 마이크로 프런트엔드(micro frontends) 라고 부르며, 다음과 같이 정의한다.
“서로 독립적으로 배포 가능한 프런트엔드 애플리케이션들을 조합해 더 큰 전체를 구성하는 아키텍처 스타일”
2016년 11월자 Thoughtworks 기술 레이더에서 우리는 마이크로 프런트엔드를 조직이 Assess(검토)해야 할 기법으로 올렸다. 이후 이를 Trial(시도)로 승격시켰고, 마지막으로 Adopt(도입)으로 올렸는데, 이는 이 접근이 검증된 방식이며, 상황에 맞는다면 실제로 사용해야 한다고 본다는 의미다.
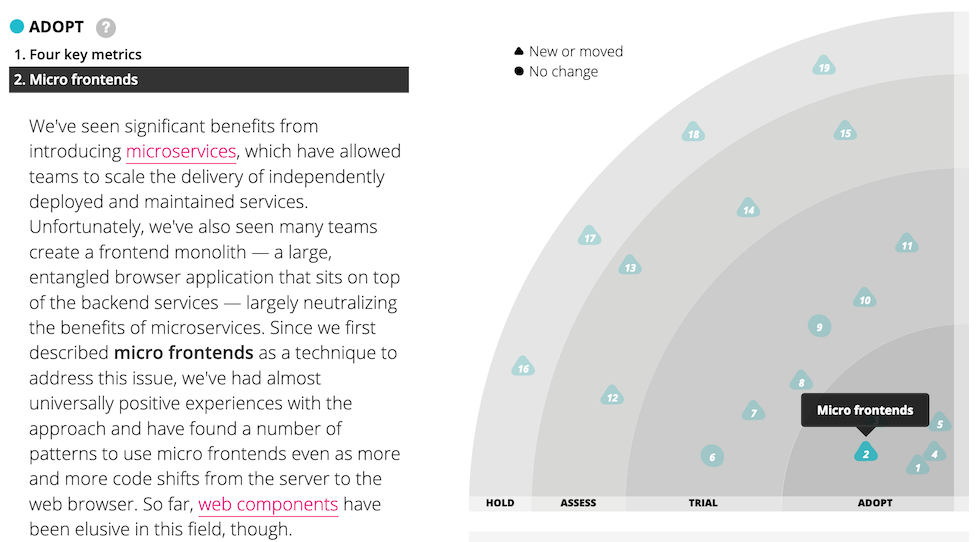
그림 1: 마이크로 프런트엔드는 기술 레이더에 여러 차례 등장했다.
우리가 마이크로 프런트엔드에서 보았던 주요 이점은 다음과 같다.
이러한 대표적인 장점들이 마이크로서비스가 제공할 수 있는 장점과 상당 부분 겹치는 것은 우연이 아니다.
물론, 소프트웨어 아키텍처에서 공짜 점심은 없다. 모든 것에는 비용이 따른다. 일부 마이크로 프런트엔드 구현은 의존성 중복을 야기할 수 있고, 이는 사용자가 다운로드해야 하는 바이트 수를 늘린다. 또한 팀 자율성의 급격한 증가는 팀 간의 작업 방식이 파편화되는 결과를 낳을 수 있다. 그럼에도 우리는 이러한 위험은 관리 가능하며, 마이크로 프런트엔드의 이점이 종종 비용을 상회한다고 본다.
우리는 마이크로 프런트엔드를 어떤 특정한 기술적 접근이나 구현 세부사항으로 정의하기보다는, 그로부터 나타나는 속성과 그 속성이 주는 이점을 중심에 두고 이야기하려 한다.
많은 조직에서, 이 지점이 바로 마이크로 프런트엔드 여정의 출발점이다. 오래되고 거대한 프런트엔드 모놀리스는 한때의 기술 스택이나, 납기 압박 속에서 작성된 코드에 발이 묶여 있고, 이제는 전면 재작성까지 고려할 정도로 상황이 악화되었을 수 있다. 하지만 완전한 재작성의 위험을 피하기 위해, 우리는 오래된 애플리케이션을 한 번에 갈아엎기보다는 조금씩 목 조르듯(strangle) 교체해 나가고 싶다. 그러는 동안에도 모놀리스의 발목에 잡히지 않고 고객에게 새로운 기능을 지속해서 제공해야 한다.
이 과정은 종종 마이크로 프런트엔드 아키텍처로 이어진다. 어떤 팀이 기존 세계(모놀리스)를 거의 건드리지 않고 기능을 프로덕션까지 밀어 넣는 경험을 한 번 하고 나면, 다른 팀들도 새로운 세계로 합류하고 싶어 한다. 기존 코드는 여전히 유지보수해야 하고, 경우에 따라 새로운 기능을 그 위에 추가하는 것이 더 말이 될 수 있다. 하지만 이제는 선택지가 생긴다.
최종적으로는 제품의 개별 부분별로 상황에 맞는 결정을 내릴 수 있는 자유가 커지고, 아키텍처·의존성·사용자 경험을 점진적으로 업그레이드할 수 있게 된다. 사용 중인 주요 프레임워크에 큰 브레이킹 체인지가 생기면, 각 마이크로 프런트엔드는 필요할 때마다 개별적으로 업그레이드할 수 있다. 더 이상 세상을 멈추고 모든 것을 한 번에 업그레이드할 필요가 없다. 새로운 기술이나 새로운 인터랙션 방식을 실험하고 싶다면, 이전보다 훨씬 더 격리된 환경에서 시도할 수 있다.
각 개별 마이크로 프런트엔드의 소스 코드는, 정의상, 하나의 단일 프런트엔드 모놀리스의 소스 코드보다 훨씬 작다. 작은 코드베이스는 대개 더 단순하고, 개발자가 다루기 쉽다. 특히 서로 알 필요가 없는 컴포넌트 사이에서 무심코 생겨나는, 부적절한 결합으로 인한 복잡성을 피할 수 있다. 애플리케이션의 경계 컨텍스트(bounded contexts) 주변에 더 두꺼운 선을 그어줌으로써, 그런 우발적 결합이 생기기 어렵게 만든다.
물론, 하나의 고수준 아키텍처 결정(예: “마이크로 프런트엔드를 하자”)이 오래된 의미의 깨끗한 코드(clean code)를 대체할 수는 없다. 코드를 깊이 생각하고 품질을 위해 노력하는 일에서 우리 자신을 면제하려는 것이 아니다. 대신, 나쁜 결정을 하기 어렵게 만들고 좋은 결정을 하기 쉽게 만들어서, 성공의 구덩이(pit of success)에 빠지도록 우리를 세팅하려는 것이다. 예를 들어, 경계 컨텍스트 간에 도메인 모델을 공유하는 것이 더 어려워지므로, 개발자가 그런 일을 할 가능성이 줄어든다. 마찬가지로, 마이크로 프런트엔드는 애플리케이션의 서로 다른 부분 간에 데이터와 이벤트가 어떻게 흐르는지 명시적이고 의도적으로 설계하도록 압박한다. 사실 이것은 어차피 해야 했던 일이다!
마이크로서비스와 마찬가지로, 마이크로 프런트엔드에서도 독립적으로 배포할 수 있는 능력이 핵심이다. 이는 각 배포의 범위를 줄이고, 그에 따라 위험도 줄인다. 프런트엔드 코드가 어디에, 어떻게 호스팅되든지 간에, 각 마이크로 프런트엔드는 자체적인 지속적 전달(continuous delivery) 파이프라인을 가져야 한다. 이 파이프라인은 코드를 빌드·테스트·배포하여 프로덕션까지 올린다. 우리는 다른 코드베이스나 파이프라인의 현재 상태를 크게 신경 쓰지 않고도 각 마이크로 프런트엔드를 배포할 수 있어야 한다. 오래된 모놀리스가 분기별로 한 번씩, 수동으로, 고정된 주기로 릴리즈되든, 옆 팀이 마스터 브랜치에 반쯤 끝난 기능이나 깨진 기능을 밀어 넣었든 상관없어야 한다. 특정 마이크로 프런트엔드가 프로덕션으로 갈 준비가 되었다면, 실제로 그렇게 할 수 있어야 하고, 그 결정은 그 코드를 만들고 유지보수하는 팀에게 달려 있어야 한다.
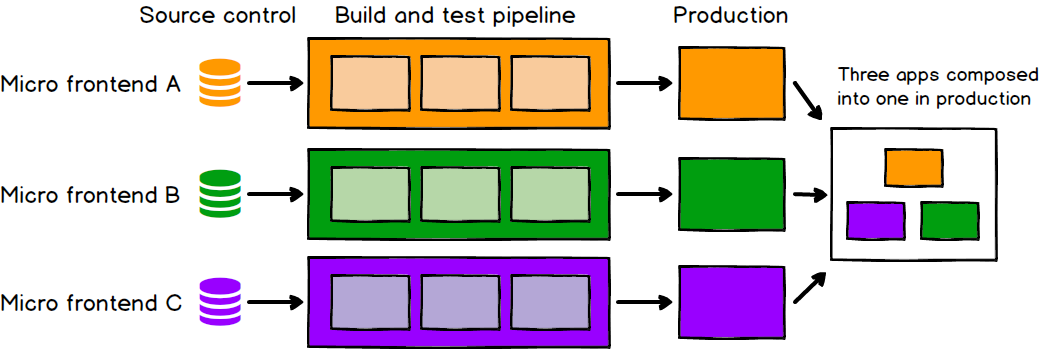
그림 2: 각 마이크로 프런트엔드는 독립적으로 프로덕션에 배포된다
코드베이스와 릴리즈 주기를 분리한 더 고차원적인 이점으로, 완전히 독립적인 팀에 한층 더 가까이 다가갈 수 있다. 이런 팀은 아이디어 발상부터 프로덕션, 그 이후까지 제품의 한 섹션을 소유할 수 있다. 팀은 고객에게 가치를 전달하는 데 필요한 모든 것에 대한 온전한 소유권을 가지며, 이는 빠르고 효과적으로 움직일 수 있게 해준다.
이것이 작동하려면 팀을 기술 역량이 아닌 비즈니스 기능의 수직 슬라이스 주변으로 구성해야 한다. 가장 쉬운 방법은 최종 사용자가 보게 될 화면을 기준으로 제품을 잘라내는 것이다. 각 마이크로 프런트엔드는 애플리케이션의 한 페이지를 캡슐화하고, 그 페이지는 하나의 팀이 끝에서 끝까지 소유한다. 이렇게 하면 스타일링, 폼, 검증 같은 기술적(수평적) 관심사 주변으로 팀을 구성했을 때보다 팀 작업의 응집도가 훨씬 높아진다.
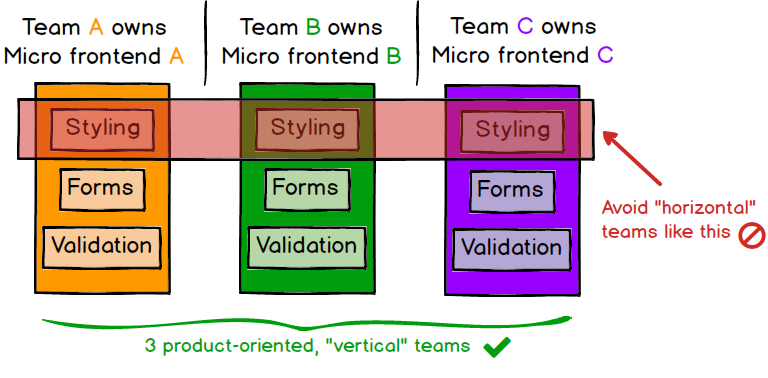
그림 3: 각 애플리케이션은 하나의 팀이 소유해야 한다
요약하자면, 마이크로 프런트엔드는 크고 무서운 것들을 더 작고 관리 가능한 조각으로 나눈 다음, 그 사이의 의존성을 명시적으로 만드는 것이다. 기술 선택, 코드베이스, 팀, 릴리즈 프로세스 모두가 과도한 조율 없이 서로 독립적으로 작동하고 진화할 수 있어야 한다.
이제 고객이 배달 음식을 주문할 수 있는 웹사이트를 상상해 보자. 겉보기에는 꽤 단순한 개념 같지만, 제대로 구현하려면 놀랄 만큼 많은 세부사항이 필요하다.
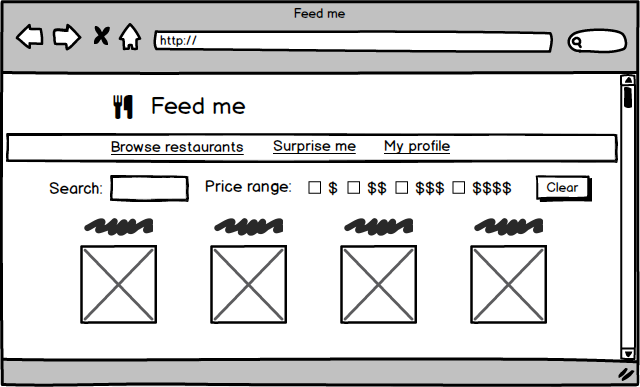
그림 4: 음식 배달 웹사이트는 상당히 복잡한 여러 페이지를 가질 수 있다
각 페이지마다 충분한 복잡도가 있기 때문에, 각 페이지에 전담 팀을 둘 만한 이유가 있다. 그리고 각 팀은 다른 팀과 독립적으로 자신의 페이지를 작업할 수 있어야 한다. 다른 팀과의 충돌이나 조율 걱정 없이, 코드 개발·테스트·배포·유지보수를 할 수 있어야 한다. 하지만 고객에게는 여전히 하나의 끊김 없는 웹사이트로 보여야 한다.
이 글의 나머지 부분에서는, 예제가 필요한 코드나 시나리오가 있을 때마다 이 예제 애플리케이션을 사용하겠다.
위에서 정한 느슨한 정의에 따르면, 마이크로 프런트엔드라고 부를 수 있는 접근 방식은 매우 다양하다. 이 섹션에서는 몇 가지 예시를 보여 주고 그 트레이드오프를 논의하겠다. 모든 접근을 관통해 비교적 자연스럽게 드러나는 아키텍처가 하나 있다. 일반적으로 애플리케이션의 각 페이지마다 하나의 마이크로 프런트엔드가 있고, 그 위에 단 하나의 컨테이너 애플리케이션(container application) 이 존재한다. 컨테이너는 다음을 담당한다.
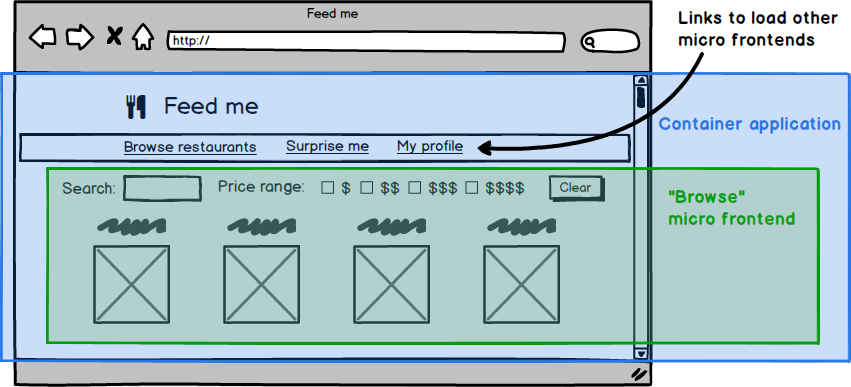
그림 5: 보통 페이지의 시각적 구조에서 아키텍처를 도출할 수 있다
먼저, 프런트엔드 개발로서는 새롭지 않은 접근부터 시작해 보자. 여러 템플릿이나 HTML 조각(fragment)을 서버에서 조합해 HTML을 렌더링하는 방식이다. 공통 페이지 요소를 담은 index.html이 있고, 서버 사이드 인클루드(SSI)를 사용해 페이지별 콘텐츠를 조각 HTML 파일로부터 끼워 넣는다.
<html lang="en" dir="ltr">
<head>
<meta charset="utf-8">
<title>Feed me</title>
</head>
<body>
<h1>🍽 Feed me</h1>
<!-- 여기서 페이지별 조각을 포함시킨다고 가정 -->
</body>
</html>우리는 이 파일을 Nginx로 서빙하고, 요청된 URL에 맞춰 $PAGE 변수를 설정한다.
server {
listen 8080;
server_name localhost;
root /usr/share/nginx/html;
index index.html;
ssi on;
# 기본 경로는 /browse로 리다이렉트
rewrite ^/$ http://localhost:8080/browse redirect;
# URL에 따라 $PAGE 변수 설정
location /browse {
set $PAGE 'browse';
}
location /order {
set $PAGE 'order';
}
location /profile {
set $PAGE 'profile';
}
# 404 발생 시 index.html로 포워딩 (클라이언트 라우팅 지원)
error_page 404 /index.html;
}이것은 꽤 전통적인 서버 사이드 조합 방식이다. 이걸 마이크로 프런트엔드라고 부를 수 있는 이유는, 코드를 각 부분이 독립적인 팀이 전달(deliver)할 수 있는 자족적인 도메인 개념을 대표하도록 나눴기 때문이다. 여기서는 각 HTML 파일이 어떻게 웹 서버에 올라오는지까지는 보여주지 않았지만, 각기 자체적인 배포 파이프라인을 가지고 있다고 가정한다. 그러면 한 페이지에 대한 변경을 다른 페이지에 영향을 주거나 고려하지 않고도 배포할 수 있다.
더 큰 독립성을 원한다면, 각 마이크로 프런트엔드를 렌더링하고 서빙하는 서버를 따로 두고, 그 앞에 있는 한 서버가 다른 서버들에 요청을 보내도록 할 수도 있다. 응답을 신중히 캐싱한다면, 레이턴시에 악영향을 주지 않고도 이 구성을 구현할 수 있다.
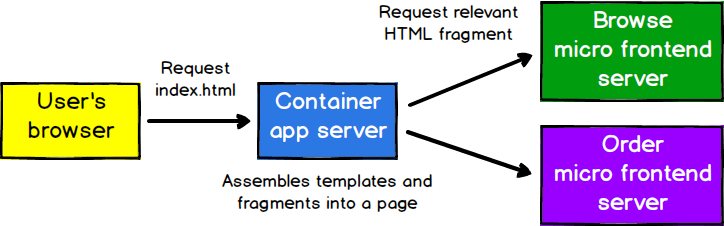
그림 6: 각 서버는 서로 독립적으로 빌드하고 배포할 수 있다
이 예시는 마이크로 프런트엔드가 반드시 새로운 기법일 필요도, 복잡할 필요도 없음을 보여준다. 디자인 결정이 코드베이스와 팀의 자율성에 어떤 영향을 미치는지 주의 깊게만 신경 쓴다면, 기술 스택이 무엇이든 상당수의 이점을 얻을 수 있다.
우리가 가끔 보는 한 가지 접근은, 각 마이크로 프런트엔드를 패키지로 발행한 후 컨테이너 애플리케이션이 이들을 라이브러리 의존성으로 포함하는 것이다. 예제 앱에서 컨테이너의 package.json은 다음과 같을 수 있다.
{
"name": "@feed-me/container",
"version": "1.0.0",
"description": "A food delivery web app",
"dependencies": {
"@feed-me/browse-restaurants": "^1.2.3",
"@feed-me/order-food": "^4.5.6",
"@feed-me/user-profile": "^7.8.9"
}
}처음에는 이런 식이 그럴듯해 보인다. 일반적인 방식대로 단일 배포용 JavaScript 번들을 만들 수 있고, 여러 애플리케이션에 공통인 의존성은 중복을 제거할 수 있다. 하지만 이 접근은 제품의 일부에 대한 변경을 배포하려 해도, 모든 마이크로 프런트엔드를 다시 컴파일·릴리즈해야 한다는 뜻이다. 마이크로서비스와 마찬가지로, 우리는 이런 보조 맞추기(lockstep) 릴리즈 프로세스 로 인해 충분히 많은 고통을 보아 왔기 때문에, 마이크로 프런트엔드를 이렇게 구현하는 방식은 강력히 말리고 싶다.
애플리케이션을 독립적으로 개발하고 테스트할 수 있는 개별 코드베이스로 나누는 데 그만한 노력을 기울였다면, 릴리즈 단계에서 그 모든 결합을 다시 들여오지는 말자. 마이크로 프런트엔드는 빌드 타임이 아니라 런타임에 통합하는 방식을 찾아야 한다.
브라우저에서 애플리케이션을 조합하는 가장 단순한 방법 중 하나는 오래된 iframe이다. iframe은 그 특성상, 독립적인 서브 페이지들로 페이지를 구성하기 쉽게 만들어 준다. 또한 스타일과 전역 변수들이 서로 간섭하지 않도록 하는 비교적 높은 수준의 격리도 제공한다.
<html>
<head>
<title>Feed me!</title>
</head>
<body>
<h1>Welcome to Feed me!</h1>
<iframe id="micro-frontend-container"></iframe>
<script type="text/javascript">
const microFrontendsByRoute = {
'/': 'https://browse.example.com/index.html',
'/order-food': 'https://order.example.com/index.html',
'/user-profile': 'https://profile.example.com/index.html',
};
const iframe = document.getElementById('micro-frontend-container');
iframe.src = microFrontendsByRoute[window.location.pathname];
</script>
</body>
</html>서버 사이드 인클루드 방식과 마찬가지로, iframe으로 페이지를 구성하는 것은 새로운 기법도 아니고, 그리 흥미롭게 보이지 않을 수도 있다. 하지만 앞에서 열거한 주요 이점들을 다시 보면, 애플리케이션을 어떻게 쪼개고 팀을 어떻게 구성하느냐에만 주의한다면 iframe도 대부분의 요건을 충족한다.
우리는 iframe 선택에 대해 주저하는 경우를 자주 본다. 그 주저함의 일부는 iframe이 왠지 “별로다(yuck)”라는 막연한 느낌에서 오지만, 사람들이 iframe을 피하는 데에는 실제로 그럴만한 이유도 있다. 앞서 언급한 손쉬운 격리는, 다른 옵션들에 비해 덜 유연하다는 의미이기도 하다. 애플리케이션의 서로 다른 부분을 통합하기 어렵고, 라우팅이나 히스토리, 딥링킹이 더 복잡해질 수 있다. 또한 페이지를 완전히 반응형으로 만드는 데에 추가적인 어려움을 야기한다.
다음으로 설명할 접근은 아마 가장 유연하며, 실제로 팀들이 가장 자주 채택하는 방식이다. 각 마이크로 프런트엔드는 <script> 태그를 통해 페이지에 포함되고, 로드가 끝나면 엔트리 포인트로써 전역 함수를 노출한다. 컨테이너 애플리케이션은 어떤 마이크로 프런트엔드를 마운트할지 결정하고, 해당 함수 호출을 통해 언제·어디에 렌더링해야 하는지 알려준다.
<html>
<head>
<title>Feed me!</title>
</head>
<body>
<h1>Welcome to Feed me!</h1>
<!-- 개별 마이크로 프런트엔드 번들을 스크립트로 로드 -->
<script src="https://browse.example.com/bundle.js"></script>
<script src="https://order.example.com/bundle.js"></script>
<script src="https://profile.example.com/bundle.js"></script>
<div id="micro-frontend-root"></div>
<script type="text/javascript">
const microFrontendsByRoute = {
'/': window.renderBrowseRestaurants,
'/order-food': window.renderOrderFood,
'/user-profile': window.renderUserProfile,
};
const renderFunction = microFrontendsByRoute[window.location.pathname];
renderFunction('micro-frontend-root');
</script>
</body>
</html>위 예시는 분명 단순한 수준이지만, 기본적인 기법을 잘 보여준다. 빌드 타임 통합과 달리, 여기서는 각 bundle.js 파일을 독립적으로 배포할 수 있다. 그리고 iframe과 달리, 마이크로 프런트엔드 간의 통합을 원하는 방식대로 자유롭게 구축할 수 있다. 위 코드는 여러 방향으로 확장할 수 있다. 예를 들어, 각 JavaScript 번들을 필요할 때만 다운로드하도록 하거나, 마이크로 프런트엔드를 렌더링할 때 데이터를 주고받도록 할 수 있다.
이 방식은 높은 유연성과 독립 배포 가능성을 동시에 제공하기 때문에 우리의 기본 선택(default choice)이자, 실제 현업에서 가장 자주 본 방식이다. 전체 예제를 설명할 때 이 방식을 더 자세히 살펴보겠다.
앞선 방식의 변형으로, 각 마이크로 프런트엔드가 컨테이너가 인스턴스화할 HTML 커스텀 엘리먼트를 정의하도록 할 수도 있다. 이때는 컨테이너가 호출할 전역 함수를 정의하는 대신, 커스텀 엘리먼트를 노출한다.
<html>
<head>
<title>Feed me!</title>
</head>
<body>
<h1>Welcome to Feed me!</h1>
<script src="https://browse.example.com/bundle.js"></script>
<script src="https://order.example.com/bundle.js"></script>
<script src="https://profile.example.com/bundle.js"></script>
<div id="micro-frontend-root"></div>
<script type="text/javascript">
const webComponentsByRoute = {
'/': 'micro-frontend-browse-restaurants',
'/order-food': 'micro-frontend-order-food',
'/user-profile': 'micro-frontend-user-profile',
};
const webComponentType = webComponentsByRoute[window.location.pathname];
const root = document.getElementById('micro-frontend-root');
const webComponent = document.createElement(webComponentType);
root.appendChild(webComponent);
</script>
</body>
</html>최종 결과는 앞선 예시와 꽤 비슷하며, 주된 차이점은 ‘웹 컴포넌트 방식’을 택하느냐 하는 점이다. 웹 컴포넌트 스펙을 좋아하고, 브라우저가 제공하는 기능을 활용하는 방식이 마음에 든다면 좋은 선택이다. 반대로 컨테이너 애플리케이션과 마이크로 프런트엔드 간 인터페이스를 스스로 정의하고 싶다면, 앞선 전역 함수 방식이 더 나을 수 있다.
언어로서의 CSS는 본질적으로 전역적이고, 상속되며, 캐스케이딩된다. 전통적으로는 모듈 시스템, 네임스페이스, 캡슐화가 없다. 일부 기능은 이제 존재하지만, 브라우저 지원이 부족한 경우가 많다. 마이크로 프런트엔드 환경에서 이러한 문제는 더 심해진다. 예를 들어 한 팀의 마이크로 프런트엔드에서 h2 { color: black; }를 정의하고, 다른 팀에서 h2 { color: blue; }를 정의했는데, 두 셀렉터가 같은 페이지에 붙는다면 누군가는 실망하게 된다! 이는 새로운 문제는 아니지만, 서로 다른 팀이 다른 시점에 작성한 코드이고, 코드가 아마 다른 저장소에 흩어져 있을 것이기 때문에 더 발견하기 어렵다는 점에서 상황이 악화된다.
수년 동안 CSS를 더 관리 가능하게 만들기 위한 다양한 접근이 고안되었다. 어떤 방식은 BEM 같은 엄격한 네이밍 규칙을 사용해, 셀렉터가 의도한 곳에만 적용되도록 한다. 다른 방식은 SASS 같은 프리프로세서를 사용해, 셀렉터 중첩을 일종의 네임스페이싱으로 활용한다. 좀 더 새로운 방식은 CSS Modules이나 다양한 CSS-in-JS 라이브러리를 통해 스타일을 프로그래밍 방식으로 적용하는 것이다. 이 방식은 스타일이 개발자가 의도한 곳에만 직접 적용되도록 보장한다. 혹은 더 플랫폼 친화적인 방식으로, Shadow DOM 역시 스타일 격리를 제공한다.
어떤 접근을 택하느냐는 크게 중요하지 않다. 중요한 것은, 개발자가 서로 독립적으로 스타일을 작성하더라도, 나중에 이 코드들이 하나의 애플리케이션으로 합쳐졌을 때 예측 가능하게 동작할 것이라는 자신감을 줄 수 있는 방법을 찾는 것이다.
앞서 마이크로 프런트엔드 간의 시각적 일관성이 중요하다고 언급했고, 이를 위한 한 가지 방법으로 재사용 가능한 UI 컴포넌트 공유 라이브러리를 만드는 방식을 들 수 있다. 일반적으로 이는 좋은 아이디어지만, 잘하기는 어렵다. 이런 라이브러리를 만들었을 때의 주요 이점은 코드 재사용을 통한 노력 감소와 시각적 일관성이다. 추가로, 컴포넌트 라이브러리는 살아 있는 스타일가이드 역할을 할 수 있고, 개발자와 디자이너 간 협업의 훌륭한 매개체가 된다.
가장 쉽게 잘못하기 쉬운 부분 중 하나는, 너무 이른 시점에 너무 많은 컴포넌트를 만드는 것이다. 모든 애플리케이션에서 필요할 공통 비주얼 요소들을 모아 Foundation Platform을 만들고 싶은 유혹이 든다. 하지만 경험상, 실사용 사례가 생기기 전에 컴포넌트의 API가 어떻게 되어야 할지 예측하는 것은 어렵고, 거의 불가능에 가깝다. 그 결과, 컴포넌트 초기 생애주기 동안 많은 변경이 발생한다. 그래서 우리는 각 팀이 처음에는 코드베이스 안에서 필요한 컴포넌트를 자체적으로 만들도록 두는 편을 선호한다. 초기에는 다소 중복이 발생하더라도 말이다. 패턴이 자연스럽게 드러나도록 두고, 컴포넌트의 API가 명확해졌을 때, 중복된 코드를 수확(harvest)해 공유 라이브러리로 옮긴다면, 검증된 무언가를 갖게 될 것이다.
가장 명백한 공유 후보는 아이콘, 라벨, 버튼 같은 “멍청한(dumb)” 시각적 프리미티브다. 상당한 양의 UI 로직을 담을 수 있는 더 복합적인 컴포넌트 역시 공유할 수 있다. 예를 들어 자동 완성 기능이 있는 드롭다운 검색 필드나, 정렬·필터링·페이지네이션이 가능한 테이블 등이 있다.
단, 공유 컴포넌트에는 오직 UI 로직만 포함되도록 주의해야 하며, 비즈니스 로직이나 도메인 로직은 포함하지 않아야 한다. 도메인 로직을 공유 라이브러리에 넣으면 애플리케이션 간 결합도가 거대해지고, 변경이 매우 어려워진다. 예를 들어 일반적으로는 ProductTable 같은 컴포넌트를 공유하려 해서는 안 된다. 그런 컴포넌트는 “제품”이 정확히 무엇인지, 어떻게 동작해야 하는지에 대한 온갖 가정을 품게 된다. 이런 도메인 모델링과 비즈니스 로직은 공유 라이브러리가 아니라, 마이크로 프런트엔드 애플리케이션 코드에 있어야 한다.
다른 모든 내부 공유 라이브러리와 마찬가지로, 소유권과 거버넌스에 관한 난제도 있다. 하나의 모델은, 공유 자산이니 “모두가” 소유한다고 말하는 것이다. 하지만 실제로는, 이는 아무도 소유하지 않는다는 말과 다를 바 없다. 곧 일관성 없는 코드들의 뒤죽박죽이 되어 버리고, 명확한 컨벤션이나 기술적 비전도 없어지기 쉽다.
반대편 극단에서는, 공유 라이브러리 개발을 완전히 중앙집중화하면, 컴포넌트를 만드는 사람과 그것을 사용하는 사람 간에 큰 단절이 생긴다. 우리가 본 가장 좋은 모델은, 누구나 라이브러리에 기여할 수 있지만, 그 기여의 품질·일관성·타당성을 책임지는 관리인(custodian) (개인 혹은 팀)이 있는 방식이다. 공유 라이브러리를 유지보수하는 일에는 강한 기술 역량이 필요하지만, 동시에 여러 팀을 가로질러 협업을 이끌어낼 수 있는 사람 간 기술도 필요하다.
마이크로 프런트엔드에서 가장 자주 나오는 질문 중 하나는, 서로 어떻게 통신하게 할 것인가이다. 일반적으로 우리는 마이크로 프런트엔드끼리 가능한 한 적게 통신하도록 권장한다. 통신이 많아지면, 애초에 피하려던 부적절한 결합이 다시 생겨나기 쉽기 때문이다.
그럼에도 일정 수준의 애플리케이션 간 통신은 종종 필요하다. 커스텀 이벤트를 사용하면 마이크로 프런트엔드가 간접적으로 통신할 수 있다. 이는 직접적인 결합을 최소화하는 좋은 방법이지만, 마이크로 프런트엔드 사이의 계약을 파악하고 강제하기가 더 어려워진다는 단점이 있다.
다른 한편으로, React에서 콜백과 데이터를 하위로 전달하는 패턴(이 경우 컨테이너 애플리케이션에서 마이크로 프런트엔드로)을 차용하는 방법도 있다. 이 방식은 계약이 더 명시적이라는 장점이 있다. 세 번째 대안으로, 주소 표시줄(라우트)을 통신 메커니즘으로 활용하는 방법이 있으며, 이는 뒤에서 더 자세히 살펴보겠다.
어떤 접근을 택하든, 마이크로 프런트엔드끼리는 서로에게 메시지나 이벤트를 보내는 방식으로 통신하게 하고, 공유 상태(shared state)는 피해야 한다. 마이크로서비스에서 데이터베이스를 공유했을 때와 마찬가지로, 데이터 구조나 도메인 모델을 공유하는 순간 엄청난 결합이 생기며, 변경이 극도로 어려워진다.
스타일링에서처럼, 여기에서도 잘 작동할 수 있는 여러 접근이 있다. 가장 중요한 것은, 어떤 종류의 결합을 도입하는지, 그리고 시간이 지나도 그 계약을 어떻게 유지할지 깊이 고민하는 것이다. 마이크로서비스 간 통합과 마찬가지로, 통합 방식에 브레이킹 체인지를 가한다면 서로 다른 애플리케이션과 팀에 걸친 조율된 업그레이드 과정을 피할 수 없다.
또한 통합이 깨지지 않았음을 자동으로 검증할 방법도 고민해야 한다. 기능 테스트는 하나의 방법이지만, 구현과 유지 비용 때문에 기능 테스트의 수는 제한하는 편을 선호한다. 대신, 각 마이크로 프런트엔드가 실제로 브라우저에서 모두 통합·실행되지 않더라도, 다른 마이크로 프런트엔드에 대해 어떤 것을 요구하는지 명시할 수 있는 컨슈머 주도 계약(consumer-driven contracts)을 사용할 수 있다.
프런트엔드 애플리케이션을 별도 팀이 독립적으로 개발한다면, 백엔드 개발은 어떻게 할까? 우리는 시각적 코드부터 API 개발, 데이터베이스 및 인프라 코드에 이르기까지 애플리케이션 개발 전체를 소유하는 풀스택 팀의 가치를 강하게 믿는다. 이를 돕는 패턴 중 하나가 BFF(Backend For Frontend)이다. 각 프런트엔드 애플리케이션이, 해당 프런트엔드의 요구를 충족시키는 데만 목적을 둔 백엔드를 하나씩 갖는 것이다. BFF 패턴은 원래 각 프런트엔드 채널(웹, 모바일 등)에 전용 백엔드를 두는 의미였을 수 있지만, 각 마이크로 프런트엔드마다 하나의 백엔드를 두는 의미로 쉽게 확장할 수 있다.
여기에는 고려해야 할 변수가 많다. BFF가 자체 비즈니스 로직과 데이터베이스를 갖춘 자족적인 서비스일 수도 있고, 다운스트림 서비스의 집계자(aggregator)에 불과할 수도 있다. 다운스트림 서비스가 있다면, 마이크로 프런트엔드와 그 BFF를 소유한 팀이 그 서비스들 중 일부를 함께 소유하는 것이 의미가 있을 수도, 없을 수도 있다. 마이크로 프런트엔드가 단 하나의 API와만 통신하고, 그 API가 꽤 안정적이라면, BFF를 따로 만드는 것이 큰 가치를 갖지 않을 수도 있다.
여기서의 핵심 원칙은, 특정 마이크로 프런트엔드를 만드는 팀이 다른 팀이 뭔가 만들어 줄 때까지 기다리지 않아도 되게 해야 한다는 것이다. 따라서 마이크로 프런트엔드에 새 기능을 하나 추가할 때마다 백엔드 변경이 필요하다면, 그 프런트엔드와 동일한 팀이 소유하는 BFF를 둘 강력한 근거가 된다.
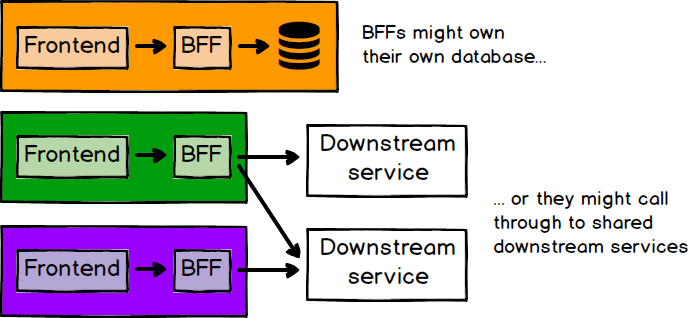
그림 7: 프런트엔드/백엔드 관계를 구성하는 방법은 매우 다양하다
또 자주 나오는 질문은, 마이크로 프런트엔드 애플리케이션의 사용자를 서버에서 어떻게 인증·인가할 것이냐이다. 당연히 고객은 한 번만 인증하면 되어야 하므로, 인증은 확실히 컨테이너 애플리케이션이 담당해야 할 횡단 관심사 범주에 속한다. 컨테이너에는 어떤 형태로든 로그인 폼이 있을 것이고, 이를 통해 토큰 같은 것을 얻는다. 이 토큰은 컨테이너가 소유하며, 초기화 시에 각 마이크로 프런트엔드에 주입할 수 있다. 마지막으로, 마이크로 프런트엔드는 서버에 요청을 보낼 때마다 이 토큰을 함께 보내고, 서버는 필요한 검증을 수행한다.
테스트 관점에서 보면, 모놀리식 프런트엔드와 마이크로 프런트엔드 사이에 큰 차이는 없다. 일반적으로 모놀리식 프런트엔드를 테스트하는 데 사용하던 전략은, 각 개별 마이크로 프런트엔드에도 그대로 적용할 수 있다. 즉, 각 마이크로 프런트엔드는 코드의 품질과 정확성을 보장하는 포괄적인 자동화 테스트 스위트를 가져야 한다.
그렇다면 남는 공백은 컨테이너 애플리케이션과 여러 마이크로 프런트엔드 간의 통합 테스트다. 이는 선호하는 기능/엔드투엔드 테스트 도구(예: Selenium, Cypress 등)를 사용해 수행할 수 있다. 하지만 선을 넘지는 말자. 기능 테스트는 테스트 피라미드(Test Pyramid)의 하위 레벨에서 테스트할 수 없는 부분만 다뤄야 한다. 즉, 저수준 비즈니스 로직과 렌더링 로직은 단위 테스트로 커버하고, 기능 테스트는 페이지가 올바르게 조합되었는지 검증하는 데만 사용하라는 뜻이다. 예를 들어, 완전히 통합된 애플리케이션을 특정 URL로 로드한 다음, 해당 마이크로 프런트엔드의 하드코딩된 제목이 페이지에 존재하는지 검증할 수 있다.
사용자 여정이 여러 마이크로 프런트엔드를 가로지른다면, 기능 테스트로 이를 커버할 수 있다. 다만 기능 테스트는 프런트엔드 간의 통합을 검증하는 데 초점을 맞추고, 각각의 마이크로 프런트엔드 내부 비즈니스 로직 검증은 이미 단위 테스트에서 끝냈어야 한다. 위에서 언급했듯이, 컨슈머 주도 계약은 통합 환경이나 기능 테스트가 가진 불안정함 없이도, 마이크로 프런트엔드 간 상호작용을 직접적으로 명세하는 데 도움을 줄 수 있다.
이제부터는 예제 애플리케이션을 구현하는 한 가지 방식을 자세히 설명하겠다. 특히 컨테이너 애플리케이션과 마이크로 프런트엔드가 JavaScript로 어떻게 통합되는지에 집중할 텐데, 이 부분이 아마 가장 흥미롭고 복잡하기 때문이다. 최종 결과는 실제로 https://demo.microfrontends.com에서 볼 수 있고, 전체 소스 코드는 Github에서 확인할 수 있다.
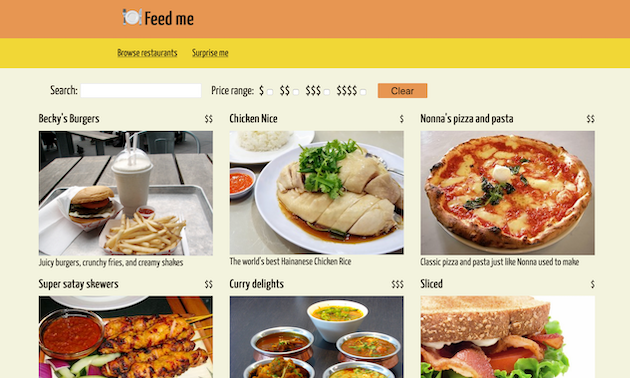
그림 8: 전체 마이크로 프런트엔드 데모 애플리케이션의 'browse' 랜딩 페이지
데모는 모두 React.js로 작성되었지만, React가 이 아키텍처를 독점한 것은 아니다. 마이크로 프런트엔드는 다양한 도구나 프레임워크로 구현할 수 있다. 우리는 React의 인기와, 우리가 잘 아는 도구라는 이유로 React를 선택했을 뿐이다.
컨테이너는 고객을 위한 진입점이므로 여기부터 시작하자. package.json을 보면 무엇을 알 수 있을까?
{
"name": "@micro-frontends-demo/container",
"description": "Entry point and container for a micro frontends demo",
"scripts": {
"start": "PORT=3000 react-app-rewired start",
"build": "react-app-rewired build",
"test": "react-app-rewired test"
},
"dependencies": {
"react": "^16.4.0",
"react-dom": "^16.4.0",
"react-router-dom": "^4.2.2",
"react-scripts": "^2.1.8"
},
"devDependencies": {
"enzyme": "^3.3.0",
"enzyme-adapter-react-16": "^1.1.1",
"jest-enzyme": "^6.0.2",
"react-app-rewire-micro-frontends": "^0.0.1",
"react-app-rewired": "^2.1.1"
},
"config-overrides-path": "node_modules/react-app-rewire-micro-frontends"
}react와 react-scripts 의존성을 보면, create-react-app으로 만든 React.js 애플리케이션임을 알 수 있다. 더 흥미로운 것은 여기에 없는 것이다. 최종 애플리케이션을 구성할 마이크로 프런트엔드에 대한 어떤 언급도 없다. 만약 이를 라이브러리 의존성으로 여기 명시했다면, 앞서 이야기한 빌드 타임 통합 경로로 가는 셈이 된다. 이미 언급했듯이, 이는 릴리즈 주기에 문제적인 결합을 야기하는 경향이 있다.
어떤 마이크로 프런트엔드를 선택해 보여줄지 보려면 App.js를 보자. React Router를 사용해 현재 URL을 미리 정의된 라우트 목록과 매칭하고, 해당 컴포넌트를 렌더링한다.
<Switch>
<Route exact path="/" component={Browse} />
<Route exact path="/restaurant/:id" component={Restaurant} />
<Route exact path="/random" render={Random} />
</Switch>Random 컴포넌트는 별로 흥미롭지 않다. 단지 페이지를 임의의 레스토랑 URL로 리다이렉트할 뿐이다. Browse와 Restaurant 컴포넌트는 다음과 같다.
const Browse = ({ history }) => (
<MicroFrontend history={history} name="Browse" host={browseHost} />
);
const Restaurant = ({ history }) => (
<MicroFrontend history={history} name="Restaurant" host={restaurantHost} />
);두 경우 모두 MicroFrontend 컴포넌트를 렌더링한다. history 객체(이것은 곧 설명하겠다)를 제외하면, 애플리케이션의 고유 이름과 번들을 다운로드할 호스트를 지정한다. 이 구성 기반 URL은 로컬에서 실행할 때는 http://localhost:3001 정도이고, 프로덕션에서는 https://browse.demo.microfrontends.com 같은 값이 된다.
App.js에서 마이크로 프런트엔드를 선택했다면, 이제 MicroFrontend.js에서 이를 렌더링하자. 이 파일도 단지 또 하나의 React 컴포넌트다.
class MicroFrontend extends React.Component {
render() {
return <main id={`${this.props.name}-container`} />;
}
}렌더링 시, 우리는 단지 마이크로 프런트엔드마다 고유한 ID를 가진 컨테이너 엘리먼트를 페이지에 놓는다. 이 엘리먼트가 마이크로 프런트엔드가 자신을 렌더링할 위치가 된다. React의 componentDidMount를, 마이크로 프런트엔드를 다운로드하고 마운트하는 트리거로 사용한다.
class MicroFrontend extends React.Component {
componentDidMount() {
const { name, host } = this.props;
const scriptId = `micro-frontend-script-${name}`;
if (document.getElementById(scriptId)) {
this.renderMicroFrontend();
return;
}
fetch(`${host}/asset-manifest.json`)
.then(res => res.json())
.then(manifest => {
const script = document.createElement('script');
script.id = scriptId;
script.src = `${host}${manifest['main.js']}`;
script.onload = this.renderMicroFrontend;
document.head.appendChild(script);
});
}
renderMicroFrontend = () => {
const { name, history } = this.props;
window[`render${name}`](`${name}-container`, history);
};
componentWillUnmount() {
const { name } = this.props;
window[`unmount${name}`](`${name}-container`);
}
render() {
return <main id={`${this.props.name}-container`} />;
}
}먼저, 해당 스크립트(고유한 ID를 가진)가 이미 다운로드된 적이 있는지 확인한다. 이미 있다면, 바로 렌더링만 하면 된다. 그렇지 않다면, 해당 호스트에서 asset-manifest.json 파일을 가져와 메인 스크립트 자산의 전체 URL을 조회한다. 스크립트의 URL을 지정한 뒤에는, 이것을 문서에 첨부하고, onload 핸들러에서 마이크로 프런트엔드를 렌더링한다.
위 코드에서, 우리는 방금 다운로드한 스크립트가 정의한 전역 함수 window.renderBrowse 같은 것을 호출한다. 이때 마이크로 프런트엔드가 자신을 렌더링할 <main> 엘리먼트의 ID와 history 객체를 전달한다(이 history는 곧 설명하겠다). 이 전역 함수의 시그니처가 컨테이너 애플리케이션과 마이크로 프런트엔드 간의 핵심 계약(key contract) 이다. 컨테이너와 마이크로 프런트엔드 간의 모든 통신과 통합은 이 지점을 통해 일어나야 한다. 이 인터페이스를 가볍게 유지하면 유지보수가 쉬워지고, 새로운 마이크로 프런트엔드를 추가하기도 쉬워진다. 이 코드를 변경해야 하는 요구가 생길 때마다, 코드베이스 간 결합과 계약 유지에 어떤 의미가 있는지 심각하게 고민해야 한다.
마지막으로 정리(clean-up)를 처리해야 한다. MicroFrontend 컴포넌트가 언마운트(즉, DOM에서 제거)될 때, 해당 마이크로 프런트엔드도 언마운트해야 한다. 각 마이크로 프런트엔드는 이를 위해 대응되는 전역 함수를 정의하며, 우리는 적절한 React 라이프사이클 메서드에서 이 함수를 호출한다. 위의 componentWillUnmount가 바로 그 부분이다.
컨테이너 자체가 직접 렌더링하는 콘텐츠는 사이트의 최상위 헤더와 내비게이션 바뿐이다. 이들은 모든 페이지에서 공통이기 때문이다. 이 요소들을 위한 CSS는 헤더 내의 엘리먼트에만 스타일이 적용되도록 신중히 작성되었기 때문에, 마이크로 프런트엔드의 스타일링 코드와 충돌하지 않아야 한다.
이것이 컨테이너 애플리케이션의 전부다. 꽤 단순하지만, 런타임에 마이크로 프런트엔드를 동적으로 다운로드하고 하나의 페이지로 결합해주는 껍데기(shell)를 제공한다. 마이크로 프런트엔드들은 다른 마이크로 프런트엔드나 컨테이너를 수정하지 않고도 프로덕션까지 독립적으로 배포될 수 있다.
이야기를 이어갈 논리적인 지점은 우리가 계속 언급했던 전역 렌더 함수다. 애플리케이션의 홈 페이지는 필터 가능한 레스토랑 목록이며, 이의 진입점은 다음과 같다.
import React from 'react';
import ReactDOM from 'react-dom';
import App from './App';
import registerServiceWorker from './registerServiceWorker';
window.renderBrowse = (containerId, history) => {
ReactDOM.render(
<App history={history} />,
document.getElementById(containerId)
);
registerServiceWorker();
};
window.unmountBrowse = containerId => {
ReactDOM.unmountComponentAtNode(document.getElementById(containerId));
};보통 React.js 애플리케이션에서는 ReactDOM.render 호출이 최상위 스코프에 있다. 즉, 이 스크립트 파일이 로드되자마자 하드코딩된 DOM 엘리먼트에 바로 렌더링을 시작한다. 하지만 이 애플리케이션에서는 언제·어디에 렌더링할지를 제어할 수 있어야 하므로, DOM 엘리먼트 ID를 파라미터로 받는 함수로 감싸고, 이 함수를 전역 window 객체에 붙인다. 정리를 위해 사용하는 대응되는 언마운트 함수도 볼 수 있다.
이미 살펴본 것처럼, 이 함수는 마이크로 프런트엔드가 컨테이너에 통합될 때 호출된다. 하지만 여기서 성공의 가장 중요한 기준 중 하나는, 마이크로 프런트엔드가 서로 독립적으로 개발·실행될 수 있어야 한다는 것이다. 그래서 각 마이크로 프런트엔드는 컨테이너 밖, “독립 실행(standalone)” 모드에서 애플리케이션을 렌더링하기 위한 자체 index.html을 갖는다.
<html lang="en">
<head>
<title>Restaurant order</title>
</head>
<body>
<main id="container"></main>
<script type="text/javascript">
window.onload = () => {
window.renderRestaurant('container');
};
</script>
</body>
</html>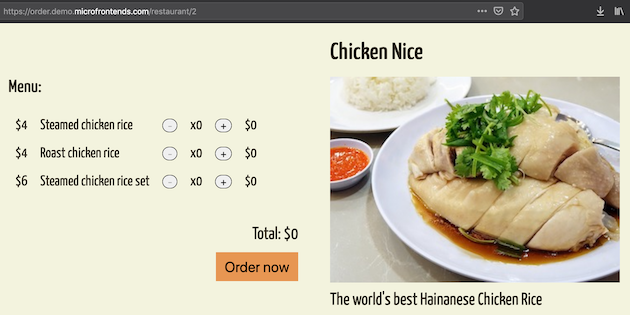
그림 9: 각 마이크로 프런트엔드는 컨테이너 밖에서 독립 실행 애플리케이션으로 동작할 수 있다.
이 지점부터 마이크로 프런트엔드는 대부분 평범한 React 앱이다. 'browse' 애플리케이션은 백엔드에서 레스토랑 목록을 가져오고, 검색·필터링을 위한 <input> 엘리먼트를 제공하며, 특정 레스토랑으로 이동하기 위한 React Router의 <Link> 엘리먼트를 렌더링한다. 여기서 특정 레스토랑으로 이동하면 두 번째 마이크로 프런트엔드인 'order'로 넘어가며, 이 프런트엔드는 단일 레스토랑과 그 메뉴를 렌더링한다.
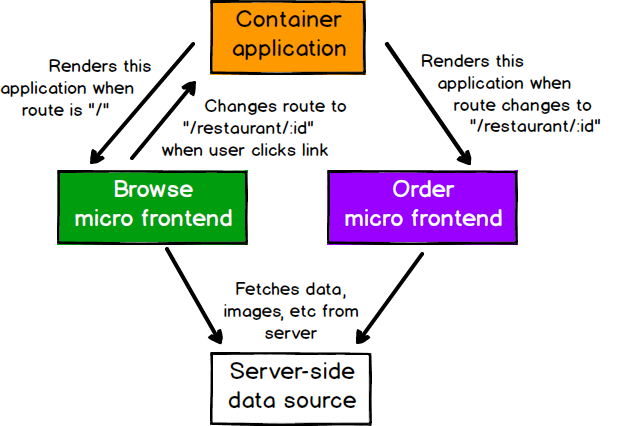
그림 10: 이 마이크로 프런트엔드들은 라우트 변경을 통해서만 상호작용하며, 직접적으로는 통신하지 않는다
마이크로 프런트엔드에 대해 마지막으로 언급할 점은, 두 애플리케이션 모두 스타일링에 styled-components를 사용한다는 것이다. 이 CSS-in-JS 라이브러리는 스타일을 특정 컴포넌트와 쉽게 연계해 주기 때문에, 마이크로 프런트엔드의 스타일이 컨테이너나 다른 마이크로 프런트엔드에 새어 나가지 않음을 보장해 준다.
앞서 애플리케이션 간 통신은 최소화해야 한다고 언급했다. 이 예제에서 필요한 유일한 요구사항은, 브라우징 페이지가 레스토랑 페이지에게 어떤 레스토랑을 로드해야 하는지 알려야 한다는 점뿐이다. 여기서는 클라이언트 사이드 라우팅을 통해 이 문제를 해결하는 방법을 살펴보자.
여기 관련된 세 개의 React 애플리케이션은 모두 선언적 라우팅을 위해 React Router를 사용하지만, 초기화 방식에는 약간 차이가 있다. 컨테이너 애플리케이션은 <BrowserRouter>를 생성하는데, 이 컴포넌트는 내부적으로 history 객체를 인스턴스화한다. 이 객체가 우리가 계속 언급해온 바로 그 history다. 우리는 이 객체로 클라이언트 사이드 히스토리를 조작할 수 있고, 여러 React Router를 서로 연결할 수도 있다.
마이크로 프런트엔드 내부에서는 Router를 다음과 같이 초기화한다.
<Router history={this.props.history}>이 경우 React Router가 또 다른 history 객체를 인스턴스화하게 두는 대신, 컨테이너 애플리케이션이 전달한 인스턴스를 그대로 제공한다. 이렇게 하면 모든 <Router> 인스턴스가 연결되며, 어느 곳에서 라우트 변경을 트리거하든 모두에게 반영된다. 이를 통해, URL을 통해 한 마이크로 프런트엔드에서 다른 마이크로 프런트엔드로 “파라미터”를 전달하는 쉬운 방법을 얻는다.
예를 들어 browse 마이크로 프런트엔드에서는 다음과 같은 링크가 있다.
<Link to={`/restaurant/${restaurant.id}`}>이 링크를 클릭하면, 컨테이너에서 라우트가 업데이트되고, 컨테이너는 새로운 URL을 보고 레스토랑 마이크로 프런트엔드를 마운트해 렌더링해야 함을 인지한다. 레스토랑 마이크로 프런트엔드의 라우팅 로직은 URL에서 레스토랑 ID를 추출하고, 적절한 정보를 렌더링한다.
이 예제 흐름은 겸손한 URL의 유연성과 강력함을 잘 보여준다. 공유 및 북마크에 유용하다는 점 외에도, 이 아키텍처에서는 마이크로 프런트엔드 간 의도를 전달하는 유용한 수단이 될 수 있다. 페이지 URL을 이런 용도로 사용하는 것은 여러 장점을 가진다.
라우팅을 마이크로 프런트엔드 간 통신 수단으로 사용할 때, 우리가 선택한 라우트는 하나의 계약(contract) 이 된다. 이 예제에서는 /restaurant/:restaurantId 경로에서 레스토랑을 볼 수 있다는 개념을 고정시켰고, 이 경로를 참조하는 모든 애플리케이션을 업데이트하지 않고는 이 라우트를 변경할 수 없다. 이 계약의 중요성을 감안할 때, 계약이 제대로 지켜지고 있는지를 확인하는 자동화 테스트가 필요하다.
팀과 마이크로 프런트엔드가 가능한 한 독립적이기를 바라지만, 공통으로 유지해야 하는 것들도 있다. 앞서 공유 컴포넌트 라이브러리가 마이크로 프런트엔드 간의 일관성을 돕는 방법이라고 언급했지만, 이 작은 데모에 컴포넌트 라이브러리를 도입하는 것은 과도할 것이다. 대신, 우리는 이미지, JSON 데이터, CSS를 포함한 작은 공통 콘텐츠 저장소를 두고, 이들을 네트워크를 통해 모든 마이크로 프런트엔드에 서빙한다.
마이크로 프런트엔드 간에 공유할 수 있는 또 다른 것은 라이브러리 의존성이다. 곧 설명하겠지만, 의존성 중복은 마이크로 프런트엔드의 일반적인 단점이다. 애플리케이션 간에 의존성을 공유하면 자체적인 어려움이 따르지만, 이 데모 애플리케이션에서는 이를 어떻게 할 수 있는지 이야기할 가치가 있다.
첫 번째 단계는 어떤 의존성을 공유할지 선택하는 것이다. 빌드된 코드를 간단히 분석해 보니 번들의 약 50%가 react와 react-dom에서 온 것이었다. 크기뿐 아니라, 이 두 라이브러리는 가장 “핵심적인” 의존성이므로, 모든 마이크로 프런트엔드가 이를 공통으로 뽑아 쓸 수 있다. 게다가 이 라이브러리들은 안정되고 성숙했으며, 일반적으로 두 개의 메이저 버전 간에 브레이킹 체인지가 생긴다. 따라서 애플리케이션 간 업그레이드 작업도 크게 어렵지 않다.
실제 추출은 webpack 설정에서 이 라이브러리들을 externals로 표시하는 것뿐이다. 이는 앞서 설명한 리와이어(rewire) 방식으로 할 수 있다.
module.exports = (config, env) => {
config.externals = {
react: 'React',
'react-dom': 'ReactDOM'
};
return config;
};그런 다음 각 index.html 파일에 script 태그를 추가해, 두 라이브러리를 공유 콘텐츠 서버에서 가져온다.
<body>
<noscript>
You need to enable JavaScript to run this app.
</noscript>
<div id="root"></div>
<script src="%REACT_APP_CONTENT_HOST%/react.prod-16.8.6.min.js"></script>
<script src="%REACT_APP_CONTENT_HOST%/react-dom.prod-16.8.6.min.js"></script>
</body>팀 간에 코드를 공유하는 일은 항상 잘하기 어려운 일이다. 진정으로 공통으로 유지하고 싶은 것, 여러 곳에서 동시에 변경되기를 바라는 것만 공유해야 한다. 하지만 무엇을 공유하고 무엇을 공유하지 않을지 신중히 선택한다면, 실질적인 이득을 얻을 수 있다.
애플리케이션은 AWS에 호스팅된다. 핵심 인프라(S3 버킷, CloudFront 배포, 도메인, 인증서 등)는 중앙화된 저장소의 Terraform 코드를 사용해 한 번에 프로비저닝한다. 각 마이크로 프런트엔드는 고유한 소스 저장소와 Travis CI에 있는 자체 지속적 배포 파이프라인을 가진다. 이 파이프라인은 정적 자산을 빌드·테스트·배포해 해당 S3 버킷에 올린다. 이렇게 하면 중앙화된 인프라 관리의 편리함과, 독립적인 배포 가능성의 유연성을 모두 얻을 수 있다.
각 마이크로 프런트엔드(그리고 컨테이너)는 자체 버킷을 가진다는 점에 주목하자. 덕분에 각 팀은 버킷 안에 무엇을 넣을지 자유롭게 결정할 수 있고, 다른 팀이나 애플리케이션 때문에 오브젝트 이름 충돌이나 액세스 규칙 충돌을 걱정할 필요가 없다.
글 서두에서 언급했듯, 마이크로 프런트엔드에는 다른 어떤 아키텍처와 마찬가지로 트레이드오프가 있다. 지금까지 언급한 이점들에는 비용이 따른다. 이 섹션에서는 그 비용을 살펴보겠다.
독립적으로 빌드된 JavaScript 번들은 공통 의존성의 중복을 야기해, 최종 사용자에게 보내야 하는 바이트 수를 늘릴 수 있다. 예를 들어, 각 마이크로 프런트엔드가 자체적으로 React를 포함한다면, 고객에게 React를 n 번 다운로드하도록 강제하는 셈이다. 페이지 성능과 사용자 참여/전환 사이에는 직접적인 관계가 있고, 전 세계의 인터넷 인프라는 고도로 발달한 도시에서 익숙한 수준보다 훨씬 느린 경우가 많다. 따라서 다운로드 크기를 신경 쓸 이유는 충분하다.
이 문제는 해결하기 쉽지 않다. 팀이 애플리케이션을 독립적으로 컴파일해 자율적으로 일할 수 있게 하고 싶은 욕구와, 애플리케이션이 공통 의존성을 공유할 수 있도록 빌드하고 싶은 욕구 사이에는 본질적인 긴장이 있다. 한 가지 접근은 데모 애플리케이션에서 했듯이, 공통 의존성을 번들에서 외부로 빼내는 것이다. 하지만 이렇게 하는 순간, 우리는 마이크로 프런트엔드에 빌드 타임 결합을 다시 들여온다. 이제 “우리는 모두 이 정확한 버전의 의존성을 사용해야 한다”는 암묵적인 계약이 생긴다. 어떤 의존성에 브레이킹 체인지가 생기면, 대규모 조율된 업그레이드 작업과 한 번에 락스텝 릴리즈를 해야 할 수도 있다. 이는 우리가 애초에 마이크로 프런트엔드를 통해 피하고자 했던 상황 그대로다.
이 내재된 긴장은 어려운 문제지만, 그렇다고 전부 나쁜 소식만 있는 것은 아니다. 먼저, 의존성 중복에 대해 아무 조치도 취하지 않더라도, 각 개별 페이지는 단일 프런트엔드 모놀리스보다 더 빨리 로드될 가능성이 있다. 그 이유는 각 페이지를 독립적으로 컴파일함으로써, 어떤 의미에서는 자체적인 코드 스플리팅을 구현했기 때문이다. 고전적인 모놀리스에서는 애플리케이션의 어떤 페이지를 로드하든, 종종 모든 페이지의 소스 코드와 의존성을 한 번에 다운로드한다. 반면, 독립적으로 빌드된 구조에서는 단일 페이지 로드 시 해당 페이지의 소스와 의존성만 다운로드한다.
이는 초기 페이지 로드는 더 빠르지만, 사용자가 각 페이지마다 동일한 의존성을 반복해서 다운로드해야 하므로 이후 네비게이션은 더 느려질 수 있다는 뜻이다. 하지만 마이크로 프런트엔드에 불필요한 의존성을 마구 추가하지 않는 규율을 지키거나, 사용자가 일반적으로 애플리케이션 내 한두 페이지에만 머무른다는 것을 안다면, 의존성이 중복되더라도 성능 측면에서 순 이득을 얻을 수 있다.
이전 단락에 “~할 수도 있다(may)”와 “가능성(possibly)”이라는 표현이 많이 쓰인 것은, 애플리케이션마다 고유한 성능 특성이 항상 존재한다는 사실을 강조한다. 특정 변경사항이 성능에 어떤 영향을 미칠지 확실히 알고 싶다면, 현실 세계에서, 가능하면 프로덕션에서 실제로 측정하는 것만큼 좋은 방법은 없다. 우리는 겨우 몇 킬로바이트의 JavaScript를 두고 고민하다가, 정작 몇 메가바이트에 달하는 고해상도 이미지를 다운로드하거나 느린 데이터베이스에 비용이 큰 쿼리를 던지는 팀을 본 적이 있다. 모든 아키텍처 결정이 성능에 어떤 영향을 주는지 고심하는 것은 중요하지만, 진짜 병목이 어디에 있는지 파악하는 것도 그만큼 중요하다.
단일 마이크로 프런트엔드를 개발하는 동안에는, 다른 팀이 개발 중인 모든 마이크로 프런트엔드를 의식할 필요가 없어야 한다. 심지어는 프로덕션에서 이것을 담을 컨테이너 애플리케이션이 아니라, 빈 페이지에 “독립 실행” 모드로 띄워둘 수 있어야 한다. 이는 특히 실제 컨테이너가 복잡한 레거시 코드베이스인 경우(우리가 구세계에서 신세계로 점진적 마이그레이션을 위해 마이크로 프런트엔드를 사용하는 경우 자주 그렇다)에 개발을 훨씬 단순하게 해 준다.
하지만 프로덕션과 꽤 다른 환경에서 개발하면 위험이 따른다. 개발 시점의 컨테이너가 프로덕션 컨테이너와 다르게 동작한다면, 프로덕션에 배포했을 때 마이크로 프런트엔드가 깨지거나, 예상과 다르게 동작하는 상황에 놓일 수 있다. 특히 컨테이너나 다른 마이크로 프런트엔드가 끌고 들어오는 전역 스타일은 주의해야 한다.
이 문제에 대한 해법은, 사실 다른 어떤 환경 차이 문제와 크게 다르지 않다. 프로덕션과 비슷하지 않은 환경에서 로컬 개발을 한다면, 프로덕션과 비슷한 환경에 규칙적으로 마이크로 프런트엔드를 통합·배포하고, 이러한 환경에서 수동 및 자동 테스트를 수행해 통합 문제를 가능한 한 빨리 잡아내야 한다. 이를 통해 문제를 완전히 없앨 수는 없지만, 궁극적으로는 또 하나의 트레이드오프로 귀결된다. 단순화된 개발 환경이 주는 생산성 향상이, 통합 이슈의 위험을 감수할 만큼 가치가 있는가? 답은 프로젝트에 따라 달라질 것이다.
마지막 단점은 마이크로서비스와 직접적인 평행 관계에 있다. 더 분산된 아키텍처인 마이크로 프런트엔드는 필연적으로 더 많은 것들을 만들어 낸다. 더 많은 저장소, 더 많은 도구, 더 많은 빌드/배포 파이프라인, 더 많은 서버, 더 많은 도메인 등. 따라서 이런 아키텍처를 도입하기 전에 몇 가지 질문을 해야 한다.
이 주제들만으로도 한 편의 글을 더 채울 수 있을 것이다. 여기서 전하고 싶은 핵심은, 마이크로 프런트엔드를 선택한다는 것은 정의상 하나의 큰 것 대신 여러 개의 작은 것을 만드는 길을 택하는 것이라는 점이다. 이런 접근을 도입했을 때 혼돈을 만들지 않을 만큼의 기술적·조직적 성숙도가 있는지 반드시 고려해야 한다.
프런트엔드 코드베이스가 해마다 더 복잡해짐에 따라, 우리는 더 확장 가능한 아키텍처에 대한 수요가 커지는 것을 보고 있다. 기술적·도메인적 엔티티들 사이의 올바른 결합도와 응집도를 설정해 주는 명확한 경계를 그릴 수 있어야 한다. 또한 독립적이고 자율적인 팀으로 소프트웨어 전달을 확장할 수 있어야 한다.
마이크로 프런트엔드가 유일한 접근은 아니지만, 우리는 여러 실제 사례에서 이 패턴이 이런 이점을 제공하는 것을 보았고, 레거시 코드베이스와 신규 코드베이스 모두에 점진적으로 적용해 왔다. 마이크로 프런트엔드가 여러분과 여러분 조직에 올바른 접근인지 여부와 상관없이, 프런트엔드 엔지니어링과 아키텍처가 그에 걸맞은 진지함과 중요성을 인정받는 흐름의 일부가 되기를 바랄 뿐이다.