순수 함수형 프로그래밍의 맥락에서 선언적 언어와 제어 구조를 탐구한다. 스프레드시트 기반 XL, 사용자 정의 함수를 가진 APP, 1급 함수를 가진 FUN을 통해 평가 전략과 컨텍스트 하의 축약을 설명한다.



지금까지 우리는 소스 코드가 프로그램에서 계산의 순서를 명시적으로 기술해야 하며, 프로그래밍 언어는 이 순서를 표현하기 위한 제어 구조를 제공해야 한다고 당연하게 여겨왔다. 그러나 이 가정은 선언적 언어에 의해 의문시된다. 선언적 언어는 계산의 순서를 소스 코드에 거의 암묵적으로 남겨두고, 컴파일러가 올바른 계산 순서를 결정하도록 맡긴다. 다시 말해, 선언적 언어는 ‘어떻게(how)’(계산을 어떻게 기본 단계로 나누는가? 어떤 순서로 수행하는가?)보다 ‘무엇(what)’(무엇을 계산할 것인가?)을 강조한다.
선언적 접근의 한 예는 SQL과 같은 데이터베이스 질의 언어이다. 질의는 데이터베이스에서 어떤 레코드를 가져올지를 기술하며, 데이터베이스를 어떻게 탐색할지는 데이터베이스 관리 시스템에 맡겨진다. 다른 선언적 프로그래밍 패러다임으로는 논리 프로그래밍(Prolog, Datalog), 순수 함수형 프로그래밍(Haskell, Agda), 데이터플로 프로그래밍(Simulink, Lustre)이 있다. Verilog, VHDL과 같은 하드웨어 기술 언어도 본질적으로 선언적이다.
선언적 언어는 1970년대에 프로그래밍을 단순화하고 “폰 노이만 스타일로부터 해방”하려는 목표로 도입되었다고 Backus (1978)는 표현했다. 1980년대에는 초점이 병렬 계산으로 옮겨갔다. 선언적 언어는 계산을 스케줄링하는 데 컴파일러에게 더 큰 유연성을 주기 때문에, 표준 명령형 언어보다 병렬 실행이 더 수월할 것이라 기대되었다. 1990년대 이후로 선언적 언어는 안전성 및 형식적 검증과의 근접성으로 인정받고 있다.
선언적 언어는 제어 구조 없이도 가능한가? 정말로 프로그래머를 프로그램 내 제어를 표현해야 하는 부담에서 “해방”시켜 주는가? 이 장에서는 순수 함수형 프로그래밍의 맥락에서 이러한 질문에 답하고자, 점차 표현력을 높여 가는 세 가지 작은 언어를 살펴본다: 스프레드시트 언어 XL, 값과 구분되는 함수가 있는 응용 언어 APP, 그리고 함수를 값으로 다루는 함수형 언어 FUN.
공유를 가진 식.다음과 같은 산술식과 방정식의 언어를 생각해 보자. “XL”이라는 별명을 붙이자.
식: e ::= 0 ∣ 1.2 ∣ 3.1415 ∣ … 상수 ∣ x ∣ y ∣ z ∣ … 변수 ∣ op(e 1, …, e n) 연산 프로그램: p ::= { x 1 = e 1; …; x n = e n } 방정식의 집합
x + 1, y × z 같은 산술식은 상수와 변수를 +, −, ×, / 등의 연산으로 결합해 만든다. 프로그램은 변수와 식 사이의 방정식 집합이다.
변수를 방정식으로 식에 결합해 두는 것은 계산의 공유라는 개념을 포착한다. 예를 들어 다음 두 프로그램은
p 1 = { x = 2 × 3; y = x + x }
p 2 = { x = 2 × 3; y = (2 × 3) + (2 × 3) }
같은 결과를 계산한다(정확한 의미는 뒤에서 정의). 하지만 p 1은 2 × 3을 한 번만 평가하고 그 결과 6을 x + x의 평가에 공유할 수 있는 반면, p 2는 2 × 3을 세 번 평가한다.
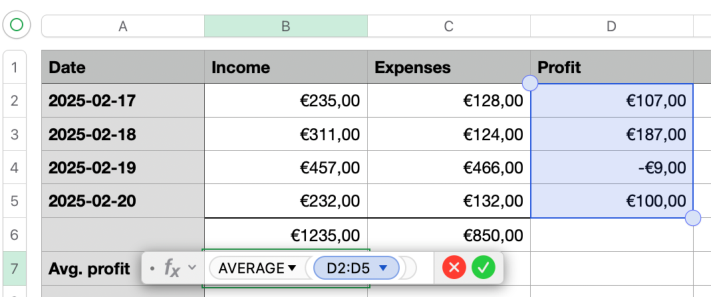
스프레드시트는 도표5.1에 보인 것처럼, 방정식 집합의 시각적 표현으로 볼 수 있다.
B2 = 235 … B5 = 232
C2 = 128 … C5 = 132
D2 = B2 − C2 … D5 = B5 − C5
B6 = SUM(B2, …, B5)
C6 = SUM(C2, …, C5)
B7 = AVERAGE(D2, …, D5)
변수는 스프레드시트 셀 B2, C6 등이다. 수동으로 입력된 값을 담은 셀은 자명한 방정식 variable = constant를 나타낸다. 수식을 담은 셀은 variable = formula라는 비자명한 방정식을 만든다.
그림 5.1: 간단한 스프레드시트.
비순환성 조건.XL 프로그램을 쉽게 평가할 수 있기를 원한다. 이는 풀기 어려운 방정식, 예컨대 x = x 3 − 2 x 2 + 2 같은 것을 피함을 뜻한다. 우리는 더 나아가 x = e에서 e가 x에 의존하는 모든 방정식을 배제한다. 이는 다른 방정식을 경유한 간접 의존도 포함한다. 예:
✘ { x = x + 1 }
✘ { x = y + 1; y = x − 1 }
다시 말해 방정식에 의존성 사이클이 있어서는 안 된다. 이 비순환성 조건은 프로그램이 방정식 집합일 뿐 아니라 다음과 같은 ‘순서있는 리스트’로도 쓸 수 있을 때 그리고 그 때에만 성립한다.
x 1 = e 1; …; x n = e n
여기서 e i 에 등장할 수 있는 변수는 오직 j < i인 x j 뿐이다.
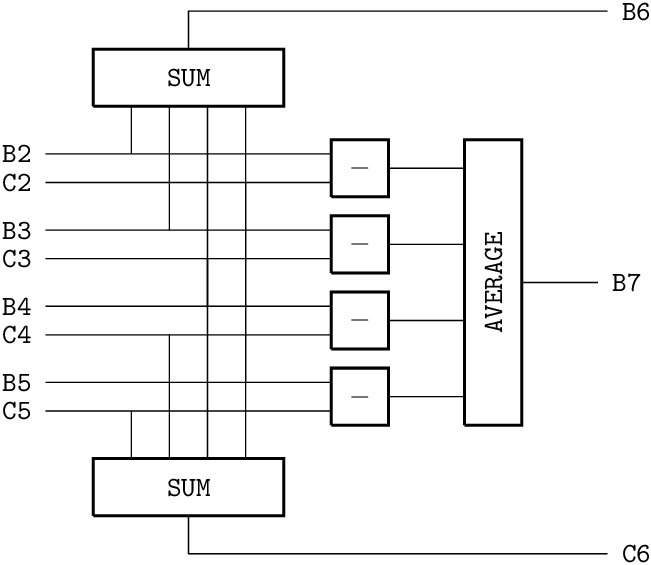
그림 5.2: 스프레드시트를 조합 회로로 본 모습.
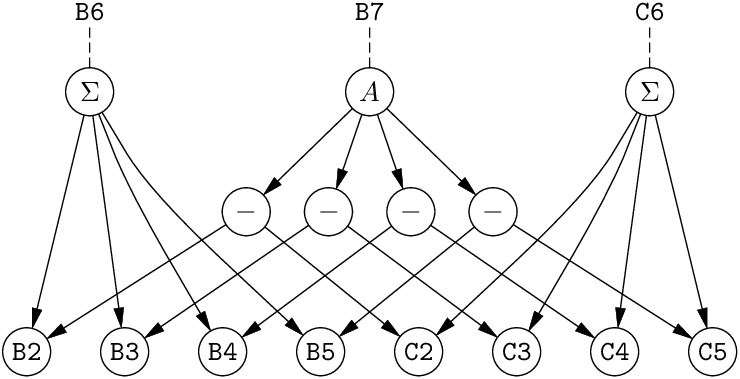
그림 5.3: 스프레드시트를 데이터플로 그래프로 본 모습. (Σ는 SUM, A는 AVERAGE 연산자)
회로와 데이터플로 그래프.도표5.2와5.3은 그림5.1의 스프레드시트를 두 가지 방식으로 나타낸다. 첫째는 회로로서, 변수(셀)를 와이어로, 연산자를 게이트로 표현한다. 비순환성 조건은 회로에 루프가 없음을 뜻한다. 즉 이는 조합 회로여야 한다.
또 다른 방식은 데이터플로 그래프이다. 이는 상수와 연산자가 노드인 유향 비순환 그래프(DAG)이며, 간선은 데이터의 흐름(자신의 값을 필요로 하는 연산자 쪽으로)을 나타낸다. 비순환성 조건은 그래프에 사이클이 없음을 뜻한다.
프로그램 평가.XL 프로그램 { x 1 = e 1; …; x n = e n }의 평가는 각 변수 x i 의 수치 값 v i 를 결정하는 일이다. 이 값들이 해당 스프레드시트의 셀에 표시된다.
특정 평가 알고리즘을 정하지 않고, 모든 가능한 평가를 프로그램의 연속적 ‘축약’으로 설명할 수 있다. 각 축약은 프로그램을 더 단순한 프로그램으로 다시 쓴다. 프로그램이 자명한 방정식 집합 { x 1 = v 1; …; x n = v n }으로 바뀌면 평가가 완료된다. 여기서 변수 x i 의 값 v i 는 분명해진다. 사용할 수 있는 두 가지 ‘축약 규칙’은 다음과 같다.
x → e (x = e 가 방정식일 때) (unfold)
op(v 1, …, v n) → v (v = op*(v 1, …, v n)일 때) (prim)
이 규칙들은 방정식의 오른편 어디에서든 적용할 수 있다. (unfold) 규칙은 Algol의 “복사 규칙”(3.2절)을 연상시킨다. 변수 x는 x와 연관된 식 e로 언제나 대체될 수 있음을 말한다.
(prim) 규칙은 값 v 1, …, v n에 적용된 연산자 op의 평가를 기술한다. 그 결과 값 v로 바꾼다. op*는 연산자 op의 의미를 나타낸다. 예를 들어 +*가 32비트 부동소수점 덧셈이라면 123000 + 0.005 → 123000.008 이다.
{ x = 1; y = (x+x) × 3 } → { x = 1; y = (1+x) × 3 } (x에 (unfold)) → { x = 1; y = (1+1) × 3 } (x에 (unfold)) → { x = 1; y = 2 × 3 } (+에 (prim)) → { x = 1; y = 6 } (×에 (prim))
주어진 프로그램에서 축약 규칙은 여러 부분식에 적용될 수 있으므로, 서로 다른 축약 순서를 만들 수 있다.
{ x = 1+1; y = x+2 } ↙ ↘ { x = 2; y = x+2 } { x = 1+1; y = (1+1)+2 } ↓↓ ↓↓ ⋯⋯ ⋯⋯ ↓↓ ↓↓ { x = 2; y = 4 } { x = 2; y = 4 }
그러나 모든 축약 순서는 같은 완전 평가 프로그램으로 끝난다. 이는 (prim)과 (unfold)의 ‘합류성’ 성질의 결과이다.
정리 1(합류성) p → p 1 그리고 p → p 2 이면, 어떤 프로그램 p′가 존재하여 p 1 →* p′ 그리고 p 2 →* p′가 성립한다.
평가 전략.모든 축약 순서가 같은 결과를 주더라도, 어떤 순서는 다른 것보다 비용이 크다—때로는 지수적으로. 다음 프로그램을 보자.
{ x 0 = 1; x 1 = x 0 + x 0; … ; x n = x n−1 + x n−1 }
“이름에 의한 호출(call by name)” 전략에서는 산술 평가를 하기 전에 각 x i 를 그 정의로 대체한다. 그러면 다음과 같은 중간 상태가 된다.
{ x 0 = 1; x 1 = 1+1; x 2 = (1+1)+(1+1); x 3 = ((1+1)+(1+1))+((1+1)+(1+1)); … }
크기는 𝒪(2 n)이며, 평가 완료까지 (prim) 규칙을 𝒪(2 n)번 적용해야 한다.
“값에 의한 호출(call by value)” 전략에서는 x i 를 정의하는 식을 값 v i 로 축약한 다음에야 x i 를 v i 로 대체한다. 그러면 다음과 같은 중간 상태들을 거친다.
{ x 0 = 1; x 1 = 2; x 2 = x 1 + x 1; …; x n = x n−1 + x n−1 } { x 0 = 1; x 1 = 2; x 2 = 4; x 3 = x 2 + x 2; …; x n = x n−1 + x n−1 } ⋮ { x 0 = 1; x 1 = 2; x 2 = 4; …; x n = 2 n }
이 프로그램을 평가하는 데 축약이 2 n 번만 필요하다.
이 절의 XL 언어에서는 “값에 의한 호출” 전략이 최적이다. 이 전략은 (unfold) 규칙을 다음과 같이 제한한 것으로 포착된다.
x → v (x = v 가 방정식이고 v가 값일 때) (unfold-val)
프로그램이 의존성을 보장하는 순서 리스트로 표현되어 있다면, 이 전략은 다음과 같은 평가 함수로 구현할 수 있다. 이 함수는 최종의 완전 평가된 프로그램을 반환한다.
eval(ε) = ε
eval(x = e; p) = (x = v; eval(p [x := v])) 여기서 v = eval(e)
닫힌 식 e(변수가 없는 식)의 값 eval(e)는 (prim) 규칙을 반복 적용하여 선형 시간에 얻는다.
함수 정의 추가.이제 5.2절의 XL 언어를 확장하여, 하나 이상의 매개변수 x 1, …, x n을 가진 함수 F를 정의하고, 식 안에서 이 함수들을 호출할 수 있게 하자.
식: e ::= true ∣ false ∣ 0 ∣ 1.2 ∣ … 상수
∣ x ∣ y ∣ z ∣ … 변수
∣ if e 1 then e 2 else e 3 조건식
∣ op(e 1, …, e n) 내장 연산
∣ F(e 1, …, e n) 함수 적용
정의: def ::= x = e 변수 정의
∣ F(x 1, …, x n) = e 함수 정의
프로그램: p ::= def ; … ; def
예시를 좀 더 흥미롭게 하려고, 불리언 값과 조건식 if e 1 then e 2 else e 3도 추가한다. 이는 e 1의 진릿값에 따라 e 2의 값 또는 e 3의 값을 돌려준다.
평가를 용이하게 하려고, 프로그램은 정의들의 순서 있는 리스트로 쓴다. 단, 하나의 정의는 함수 매개변수와 이전 정의로 정의된 변수들만 언급할 수 있고, 나중에 정의되는 함수는 언급할 수 있다. 이 기준은 함수 적용을 경유하지 않는 의존성 사이클을 배제하면서, 재귀 함수는 허용한다.
예를 들어, 다음은 피보나치 수열을 계산하는 함수 F와 이 수열의 20번째 수를 구하는 정의 x이다.
F(n) = if n ≤ 1 then n else F(n−1) + F(n−2)
x = F(20)
다음은 반복적 알고리즘에 더 가까운 피보나치의 다른 정의이다.
G(n, a, b) = if n = 0 then a else G(n−1, b, a+b)
F(n) = G(n, 0, 1)
x = F(20)
APP 언어는 일반 재귀를 지원함을 주목하자. 계산은 종료하지 않을 수 있다(위 예에서 G(−1, 0, 1) 등). 실제로 APP는 Kleene의 부분 재귀 함수를 포함하므로 튜링 완전하다.
APP의 제어 구조.한편으로 APP 언어는 의심할 바 없이 선언적이다. 특히 계산의 명시적 순서는 없고, 어떤 연산이 다른 연산보다 먼저 평가되어야 한다는 데이터 의존성만 존재한다. 예컨대 (1 + 2) × 3에서는 덧셈이 곱셈보다 먼저 수행되어야 한다.
다른 한편으로 APP는 확실히 두 가지 핵심 제어 구조를 지원한다: 조건과 반복. 조건은 if e 1 then e 2 else e 3 표현식으로 지원되며, 이는 명령형 언어의 if…then…else 문과 유사하다(불리언 식 e 1의 값에 따라 then 또는 else 분기가 실행된다).
반복은 ‘꼬리 재귀(tail-recursive)’ 함수로 지원된다. 즉, 재귀 호출이 함수의 마지막 동작으로 수행되는 함수다. 예컨대 다음 꼬리 재귀 함수
G(n, a, b) = if n = 0 then a else G(n−1, b, a+b)
는 다음 명령형 루프와 유사하다.
while (n != 0) { n = n - 1; tmp = a + b; a = b; b = tmp; } return a;
단일 수준의 break와 continue를 포함하여, 많은 형태의 루프를 꼬리 재귀 함수로 표현할 수 있다.
상호 재귀 함수는 명령형 언어에서 goto 점프가 필요한 더 복잡한 형태의 루프까지 표현할 수 있다. 예를 들어,
F(n) = if n < 0 then Odd(−n−1) else Even(n)
Even(n) = if n = 0 then true else Odd(n−1)
Odd(n) = if n = 0 then false else Even(n−1)
이는 다음과 같은 비구조적 명령형 코드와 유사하며, 그 제어 흐름 그래프는 환원 불가능(irreducible)하다.
if (n < 0) { n = -n - 1; goto Odd; } else { goto Even; } Even: if (n == 0) return true; n = n - 1; Odd: if (n == 0) return false; n = n - 1; goto Even;
더 일반적으로, 모든 순서도(flowchart)는 상호 재귀 함수 집합으로 표현될 수 있으며, 이는 McCarthy (1960, section 6)이 관찰했다.
평가 전략.조건과 반복이 의도대로 동작하도록 하려면, 단지 “데이터 의존성을 만족하는 아무 순서의 평가”보다 더 제약된 ‘평가 전략’을 정해야 한다. 사소한 예로, if…then…else 조건식이 then과 else 분기를 둘 다 평가한 뒤 값 하나를 고르면 안 된다. 그렇지 않으면 다음과 같은 루프
G(n, a, b) = if n = 0 then a else G(n−1, b, a+b)
은 어떤 n 값에 대해서도 발산(미종료)할 것이다. n−1, n−2, …에 대해 무한히 많은 재귀 호출을 평가하기 때문이다.
분명히 조건식 if e 1 then e 2 else e 3은 세 인자에 대해 ‘엄격(strict)’해서는 안 된다. 즉, e 1을 먼저 불리언 b로 평가한 다음 b가 참이면 e 2의 평가를, 거짓이면 e 3의 평가를 시작해야 한다. 함수 적용을 어떻게 평가할지는 조금 덜 명확하다. 인자에 대해 ‘엄격’해야 할까 아닐까? 이 문제는 다음 절의 더 풍부한 FUN 언어 맥락에서 다시 논의한다.
상수: c ::= true ∣ false ∣ 0 ∣ 1.2 ∣ …
식: e ::= c 상수
∣ x ∣ y ∣ z ∣ … 변수
∣ λ x . e 함수 추상
∣ e 1 e 2 함수 적용
∣ if e 1 then e 2 else e 3 조건식그림 5.4: 장난감 함수형 언어 FUN의 추상 구문.
식 안의 함수 추상.5.2절의 XL 언어에 사용자 정의 함수를 추가하는 또 다른 방법은 식 e에 함수 추상 λ x . e와 함수 적용 e 1 e 2를 추가하는 것이다. 함수 이름과 변수 이름을 구분할 필요가 없다. 변수 x는 함수들을 포함해 임의의 값을 나타낼 수 있다. APP와 달리, 함수는 중첩될 수 있으며 바깥쪽 함수의 자유 변수를 참조할 수 있다.
이 확장을 FUN이라 부르며, 그 구문은 그림5.4에 요약되어 있다. 식 λ x . e는 인자 x를 결과 e로 사상하는 함수를 나타낸다. n개의 인자 x 1, …, x n을 받는 함수는 λ x 1 . λ x 2 … λ x n . e로 정의할 수 있다. 이런 함수 f를 n개의 인자 e 1, …, e n에 적용하는 것은 단인자 적용을 n−1번 연쇄해 쓴다.
f e 1 e 2 ⋯ e n = (⋯ ((f e 1) e 2) ⋯) e n
f 같은 다인자 함수는 논리학자 H.B. Curry의 이름을 따 ‘커리된(curried)’ 함수라 부른다. 연산자(+ , − 등)를 상수로 추가하면, 산술 연산 x + y도 ((+) x) y와 같은 커리된 함수 적용으로 볼 수 있다.
그림5.4의 구문은 정의를 포함하지 않아 재귀를 지원하지 않는 듯 보인다. 하지만 이 기능들은 FUN 언어의 핵심 구성요소만으로 표현할 수 있다. 그럼에도 아래 예시에서는 재귀 정의를 사용할 것이다.
고차 함수.FUN에서는 함수가 1급 값이다. 즉, 수치나 불리언 값이 쓰일 수 있는 어디든, 다른 함수의 인자를 포함해 함수도 쓸 수 있다.
함수를 인자로 받는 함수를 고차 함수라 부른다. 이는 부분 프로그램을 조합하고 재사용하는 새로운 방법을 제공한다. 예를 들어 함수 합성 f ∘ g는 고차 함수로 정의할 수 있고, 함수 거듭제곱 f ∘ ⋯ ∘ f (n번)도 마찬가지다.
Compose = λ f . λ g . λ x . f (g x)
Exp = λ f . λ n . if n = 0 then λ x . x else Compose f (Exp f (n−1))
다음은 술어 stop이 참이 될 때까지 step 함수를 x에서 시작해 반복 적용하는 일반 루프이다.
Iter = λ stop . λ step . λ x . if stop x then x else Iter stop step (step x)
고차 함수는 리스트 같은 자료구조의 일반 순회를 표현할 수 있다. 예컨대 Map은 리스트 각 원소에 함수를 적용하고, Fold는 이항 함수로 리스트를 축약한다.
Map = λ f . λ ℓ . if ℓ = nil then nil else cons (f (head ℓ)) (Map f (tail ℓ))
Fold = λ f . λ a . λ ℓ . if ℓ = nil then a else Fold f (f a (head ℓ)) (tail ℓ)
정의의 인코딩. 위 예시들은 FUN 프로그램을 x 1 = e 1 ; … ; x n = e n 같은 정의 리스트로 보여주지만, 이러한 정의를 FUN의 추상 구문에 포함할 필요는 없다. 정의는 식으로 인코딩할 수 있기 때문이다.
비재귀 정의 x = e ; …는 let 바인딩 let x = e in …이 되는데, 이는 단지 함수 적용일 뿐이다.
let x = e in e′ ≜ (λ x . e′) e
단순 재귀 정의 f = e는 let rec 바인딩 let rec f = e in e′가 되며, 이는 고정점 콤비네이터 Y를 사용해 정의된다.
let rec f = e in e′ ≜ let f = Y (λ f . e) in e′
예컨대 위의 Exp 함수는 다음과 같이 정의된다.
Exp = Y (λ E . λ f . λ n . if n = 0 then λ x . x else Compose f (E f (n−1)))
Y ≜ λ f . (λ x . f (λ v . x x v)) (λ x . f (λ v . x x v))
마지막으로, 상호 재귀 정의는 단순 재귀 정의로 표현할 수 있다. 여기서는 두 개의 상호 재귀 정의 f = e 1; g = e 2의 인코딩을 보인다.
let rec f = e 1 and g = e 2 in e ≜ let rec f = λ g . e 1 in let rec g = let f = f g in e 2 in let f = f g in e
축약 규칙.5.2절과 마찬가지로, FUN 식의 평가를 축약들의 열로 본다. 각 축약은 계산 한 단계를 수행하도록 식을 다시 쓴다. 필요한 축약 규칙은 다음과 같다.
(λ x . e) e′ → e [x := e′] (β)
if true then e 1 else e 2 → e 1 (if-true)
if false then e 1 else e 2 → e 2 (if-false)
op v 1 ⋯ v n → v (v = op*(v 1, …, v n)일 때) (prim)
(λ x . e) e′ → e [x := e′] 규칙은 람다 계산법의 베타(β) 축약으로 알려져 있다. 이는 함수 적용의 본질을 포착한다. 즉, 형식 매개변수 x를 함수 본문 e에서 실제 인자 e′로 치환한다.
(prim) 규칙 등에서 v는 값을 나타내며, 값은 상수 또는 함수 추상이다.
값: v ::= c ∣ λ x . e
다음은 축약 열의 예들이다. Δ = λ x . x x, Ω = Δ Δ라 하자.
Δ (λ x . x) → (x x) [x := λ x . x] = (λ x . x) (λ x . x) → λ x . x (i)
Ω → (x x) [x := Δ] = Δ Δ = Ω → Ω → Ω → ⋯ (ii)
(λ x . 0) Ω → 0 (iii)
(λ x . 0) Ω → (λ x . 0) Ω → (λ x . 0) Ω → ⋯ (iv)
(ii)와 (iv)에서 보이듯, 어떤 항(term)들은 무한한 축약 열을 가진다. 이는 발산(비종료)을 뜻한다. 또한 (iii)과 (iv)에서 보듯, 어느 한 항이, 각 단계에서 어느 부분항을 축약하느냐에 따라 유한한 축약 열과 무한한 축약 열을 모두 가질 수 있다.
이 예들은 축약 규칙만으로는 FUN 프로그램의 의미가 유일하게 정해지지 않음을 보여준다. 따라서 식을 평가하기 위해 어느 곳에서 언제 축약 규칙을 적용할 수 있을지를 제한하는 축약 전략을 명시해야 한다.
평가 전략.모든 함수형 언어는 ‘약한 축약(weak reduction)’만 사용한다. 즉, 함수 추상(‘람다 아래’) 내부와 조건식의 then, else 분기 내부에서는 축약을 금한다. 대신 함수가 적용되거나 if-then-else의 불리언 조건이 정해질 때까지 기다린 뒤 더 축약한다. 5.3절 끝에서 언급했듯, ‘강한 축약(strong reduction)’은 일반 재귀와 결합될 때 문제가 많으며, 종종 비종료로 이어진다.
약한 축약으로 제한하더라도, 함수 적용의 전략은 선택해야 한다.
이름에 의한 호출은 가능한 한 발산을 피하지만, 계산을 중복할 수 있다. 예를 들어, 재귀 피보나치 함수 Fib와 발산하는 식 Ω에 대해 다음과 같다.
(λ x . 0) Ω → 0
(λ x . x + x) (Fib 20) → Fib 20 + Fib 20 →+ 6765 + Fib 20 →+ 6765 + 6765 → 13530
값에 의한 호출은 위 마지막 예의 Fib 20 같은 반복 평가를 피하지만, 불필요하게 발산할 수 있다.
(λ x . 0) Ω → (λ x . 0) Ω → (λ x . 0) Ω → …
(λ x . x + x) (Fib 20) →+ (λ x . x + x) 6765 → 6765 + 6765 → 13530
필요에 의한 호출은 양쪽의 장점을 얻으려 한다. 이름에 의한 호출처럼 발산을 피하면서, 값에 의한 호출처럼 반복 평가도 피한다. 그러나 평가 공유는 개념적 난점과 구현 비용을 수반한다.
(λ x . 0) Ω → 0
(λ x . x + x) (Fib 20) → Fib 20 + Fib 20 ↖↗ 공유 →+ 6765 + 6765 ↖↗ 공유 → 13530
두 번 등장하는 Fib 20은 같은 변수 x의 치환에서 왔다. 따라서 그 평가가 공유된다. 한 번의 평가가 6765로 끝나면, 다른 한 번도 값이 6765임을 알 수 있다.
Haskell은 기본적으로 필요에 의한 호출을 사용한다. 그 외 대부분의 함수형 언어(Lisp, Scheme, SML, OCaml 등)와 현대의 모든 명령형/객체지향 언어는 값에 의한 호출을 사용한다. 이름에 의한 호출은 Algol 60에서 중요한 역할을 했으나(3.2절), 오늘날에는 컴파일 타임 매크로 확장과 템플릿 확장에서만 쓰인다.
평가 전략의 인코딩.언어가 값에 의한 호출일지라도, 인자 e를 ‘thunk’(λ z . e, 여기서 z는 e에 쓰이지 않는 새로운 변수)로 전달하면 이름에 의한 호출 의미론을 구현할 수 있다. 약한 축약만 유지하는 한, 이 thunk λ z . e는 적용될 때까지 내부의 e가 축약되지 않는다.
이 생각은 프로그램 변환 𝒩(e)로 이어진다. e 안의 모든 함수 적용이 이름에 의한 호출을 사용하도록 보장한다.
𝒩(x) = x( )
𝒩(λ x . e) = λ x . 𝒩(e)
𝒩(e 1 e 2) = 𝒩(e 1) (λ z . 𝒩(e 2))
𝒩(c) = c
𝒩(if e 1 then e 2 else e 3) = if 𝒩(e 1) then 𝒩(e 2) else 𝒩(e 3)
일반 thunk 대신 메모이즈된 thunk(OCaml의 lazy e)를 사용하면 이름에 의한 호출 대신 필요에 의한 호출을 얻는다.
이름/필요에 의한 호출 언어에서 값에 의한 호출을 구현하는 것은 더 어렵다. 한 가지 접근은 CPS(Continuation-Passing Style) 변환을 사용하는 것으로, 6.5절에서 설명한다. Haskell은 seq 연산자와 $! 엄격 적용 연산자처럼 함수 인자의 평가를 강제하는 원시 연산을 제공한다.
평가 전략을 수학적 정밀도로 형식화해 정의하려면 어떻게 해야 할까? 이 책 전반에서 따르는 접근은 제한된 컨텍스트 아래에서의 축약으로 평가를 정의하는 것이다.
컨텍스트.‘컨텍스트’는 구멍 하나([ ])가 있는 식이다. 예컨대 (1 + [ ]) × 3는 컨텍스트다.
컨텍스트 C와 식 e가 주어지면, C[e]는 C의 구멍 [ ]을 e로 대체해 얻는 식을 뜻한다. 예컨대 C = (1 + [ ]) × 3, e = 2/5라면 C[e] = (1 + 2/5) × 3이다.
컨텍스트 하의 축약.컨텍스트를 사용하면 지금까지 “식의 아무 곳에서나” 축약 규칙을 적용한다는 말을 더 정밀히 설명할 수 있다. ‘전체 프로그램 축약’ p → p′을 ‘헤드 축약’ e →ε e′과 ‘축약 컨텍스트’ C를 통해 아래와 같이 정의한다.
p = C[e]
e →ε e′
C[e′] = p′
p → p′
즉, 프로그램 p를 축약하는 과정은 다음과 같다.
p를 C[e]로 분해한다. 여기서 C는 컨텍스트이고, e는 p의 부분식으로 축약 가능하다.
축약 규칙 중 하나를 e “맨 위”(즉 e 자체에, e의 부분식이 아니라)에 적용하여 e′를 얻는다.
C에서 e를 e′로 바꾸어 축약된 프로그램 p′ = C[e′]을 얻는다.
예를 들어, 1 + 2 →ε 3이 헤드 축약이라면, C = 4 × [ ]를 써서 4 × (1 + 2) → 4 × 3이다.
만약 임의의 컨텍스트를 축약 컨텍스트 C로 허용하면, 전체 프로그램 축약은 프로그램 어디서든 발생할 수 있다. 그러나 축약 컨텍스트로 사용할 수 있는 C를 제한함으로써, 축약이 일어날 수 있는 위치를 제한하고 그에 따라 축약 전략을 명세할 수 있다.
C ::= [ ] ∣ C e ∣ e C ∣ if C then e 2 else e 3
이 문법은 λ x . C나 if e 1 then C else e 2 혹은 if e 1 then e 2 else C를 축약 컨텍스트로 허용하지 않는다. 따라서 함수 본문(‘람다 아래’)이나 조건식의 then/else 분기 내부에서는 축약이 일어날 수 없다.
FUN의 헤드 축약 규칙은 5.4절에 나온 네 규칙과 같다.
(λ x . e) e′ →ε e [x := e′] (β)
if true then e 1 else e 2 →ε e 1 (if-true)
if false then e 1 else e 2 →ε e 2 (if-false)
op v 1 ⋯ v n →ε v (v = op*(v 1, …, v n)일 때) (prim)
값에 의한 호출은 β 헤드 축약을 다음으로 대체하여 얻는다.
(λ x . e) v →ε e [x := v] (β v)
이로써 인자가 값 v로 평가되기 전에는 적용의 축약을 막는다. 이것이 값에 의한 호출의 핵심이다.
선택적으로, 적용 e 1 e 2의 ‘평가 순서’를 명세하고 싶을 수 있다. 함수 부분 e 1을 먼저, 인자 부분 e 2를 나중에 평가하는 좌에서 우로의 평가(left-to-right)는 다음 축약 컨텍스트 문법으로 강제된다.
C ::= [ ] ∣ C e ∣ v C ∣ if C then e 2 else e 3
여기서는 v C는 허용하지만 e C는 허용하지 않는다. 즉, 적용의 인자 부분은 함수 부분이 이미 값으로 평가된 경우에만 축약될 수 있다.
대칭적으로, 우에서 좌로의 평가는 다음을 택한다.
C ::= [ ] ∣ C v ∣ e C ∣ if C then e 2 else e 3
(λ x . e) e′ →ε e [x := e′] (β)
이로써 인자 e′를 평가하지 않은 채 함수에 전달할 수 있다. 추가로, 이름에 의한 호출은 인자가 전달되기 전에 평가될 수 없도록 평가 컨텍스트를 다음처럼 제한한다.
C ::= [ ] ∣ C e ∣ if C then e 2 else e 3
(λ x . e) e′에서 e′을 축약하도록 허용하는 컨텍스트는 없다. 여기서 일어날 수 있는 유일한 축약은 (β) 규칙이다.
필요에 의한 호출은 축약 규칙만으로 기술하기 어렵다. 문제는 β 규칙 (λ x . e) e′ →ε e [x := e′]에 있다. 함수 본문 e에서 매개변수 x의 모든 발생이 같은 인자 e′를 공유해야 한다. 그래야 한 발생이 e′의 값 v로 바뀌면 다른 모든 발생도 v로 바뀌기 때문이다. 한 가지 해법은 식을 항(term) 대신 DAG(유향 비순환 그래프)로 표현하고, 축약 규칙을 항 재작성 대신 그래프 재작성으로 보는 것이다. 이 접근은 이름에 의한 호출과 같은 축약 규칙과 같은 축약 컨텍스트를 사용한다.
Ariola et al. (1995)는 공유를 표현하기 위해 항에 변수 바인딩을 도입하는 다른 접근을 제시한다. 식 언어를 명시적 let 바인딩으로 확장한다.
식: e ::= … ∣ let x = e 1 in e 2
함수 적용은 치환 대신 함수 인자를 함수 매개변수에 let-바인딩한다.
(λ x . e) e′ →ε let x = e′ in e
인자 e′이 값 v로 축약되었을 때에만, 이 값 v를 x에 치환할 수 있다.
let x = v in C[x] →ε let x = v in C[v]
다른 규칙들은 let-바인딩을 식의 위쪽으로 끌어올리는 역할을 한다.
(let x = e 1 in e 2) e →ε let x = e 1 in e 2 e
e (let x = e 1 in e 2) →ε let x = e 1 in e e 2
if (let x = e 1 in e 2) then e′ else e″ →ε let x = e 1 in if e 2 then e′ else e″
let x = (let y = e 1 in e 2) in C[x] →ε let y = e 1 in let x = e 2 in C[x]
축약 컨텍스트는 이름에 의한 호출의 그것에, let 바인딩을 위한 두 경우를 더한 것이다.
C, C′ ::= [ ] ∣ C e ∣ if C then e 2 else e 3 ∣ let x = e in C ∣ let x = C in C′[x]
컨텍스트 let x = C in C′[x]는 필요에 의한 호출의 본질을 포착한다. 즉, 변수 x의 값이 프로그램이 진행하는 데 필요할 때에만(즉, 프로그램의 나머지가 어떤 평가 컨텍스트 C′에 대해 C′[x]로 쓸 수 있을 때에만) x에 바인딩된 식을 축약할 수 있다. 컨텍스트는 재귀적이므로, let x = C in let y = C′[x] in C″[y] 같은 임의 길이의 의존 사슬도 이 두 종류의 let 컨텍스트로 포착할 수 있다.
Abelson and Sussman (1996)의 교과서 ‘Structure and Interpretation of Computer Programs’ 1장은 함수형 관점에서 선언적 프로그래밍을 고전적으로 소개한다. Van Roy and Haridi (2004)의 교과서는 특히 논리 및 관계형 프로그래밍 관점에서 선언적 프로그래밍을 더 자세히 다룬다.
Pierce (2002)의 1부는 (이 장의 장난감 언어 FUN처럼) 비형식(untyped) 함수형 언어와 그 형식 의미론을 설명한다. 축약 컨텍스트의 사용은 Wright and Felleisen (1994)에서 도입되었고, Harper (2016)의 5장에서 다른 방식의 운영 의미론과 함께 다시 설명되고 비교된다.
Peyton Jones (1987)의 2부는 그래프 축약을 이용한 지연 평가 구현을 다룬다.