Rust가 새로운 코드에서 메모리 취약점을 극적으로 줄이고 있지만, 여전히 세상의 대부분의 시스템 코드는 C로 쓰여 있다. C에서 Rust로의 자동 변환(transpilation) 시도가 왜 근본적으로 잘못된 문제 설정인지, 그리고 형식적 의미론과 언어 간 정합성 측면에서 무엇이 빠져 있는지를 논한다.
최근 구글 시큐리티 블로그에서 Rust in Android 도입 경험을 다룬 글을 올렸다. 이 글은 메모리 취약점이 1000배 감소했다는 놀라운 수치를 보고하는 것 외에도, 세상에 다음과 같은 아름다운 그래프를 선물했다.
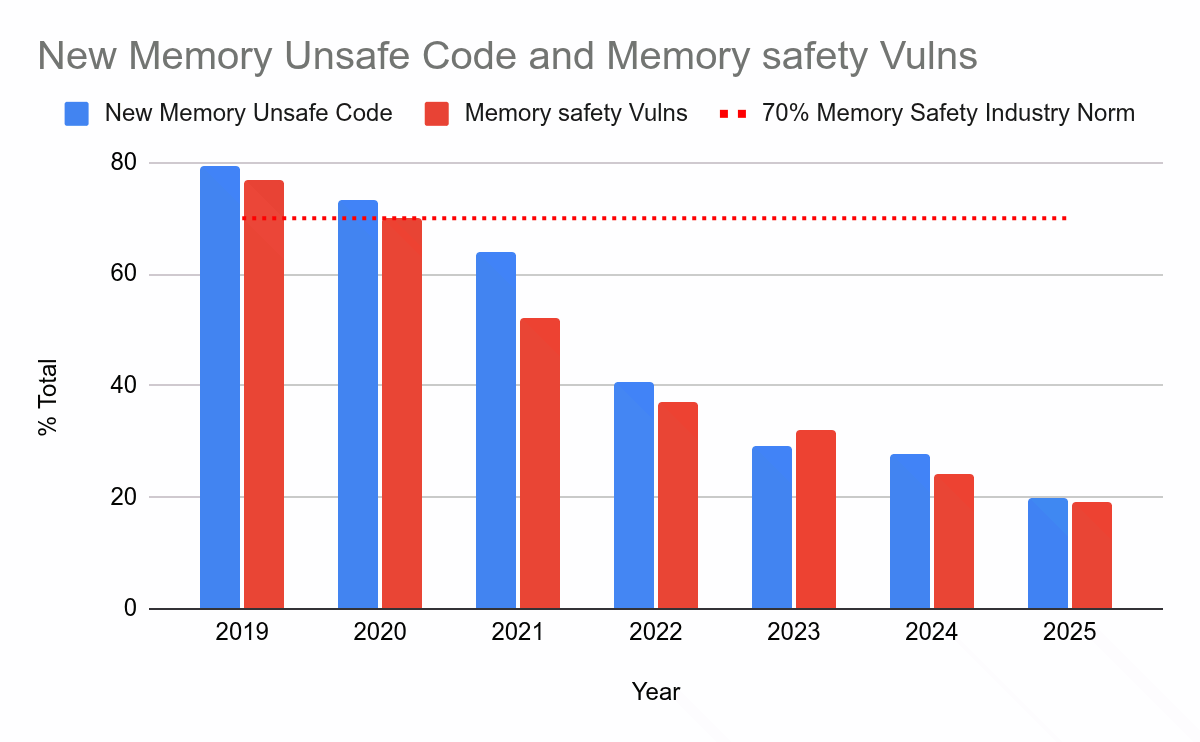
여기서 보이는 추세는 부정할 수 없다. 사실은 명백하다. Rust로 코드를 작성하면. 그냥. 된다. 더 이상 메모리 취약점도, 하이젠버그(잡기 힘든 버그)도 없다. 이제 먼지가 가라앉았고, 판결이 내려진 듯하다 —1 Rust가 승리했다.

이제 Rust와 비슷한 메모리 안전 언어들이 새로운 코드를 위한 사실상의 기본 선택지가 되었고, 그로 인해 새로운 버그를 원천 차단하고 있지만, 한 가지 중요한 사실을 잊지 말아야 한다. 대다수의 이미 존재하는 시스템 코드는 실제로 Rust가 아니라는 점이다.
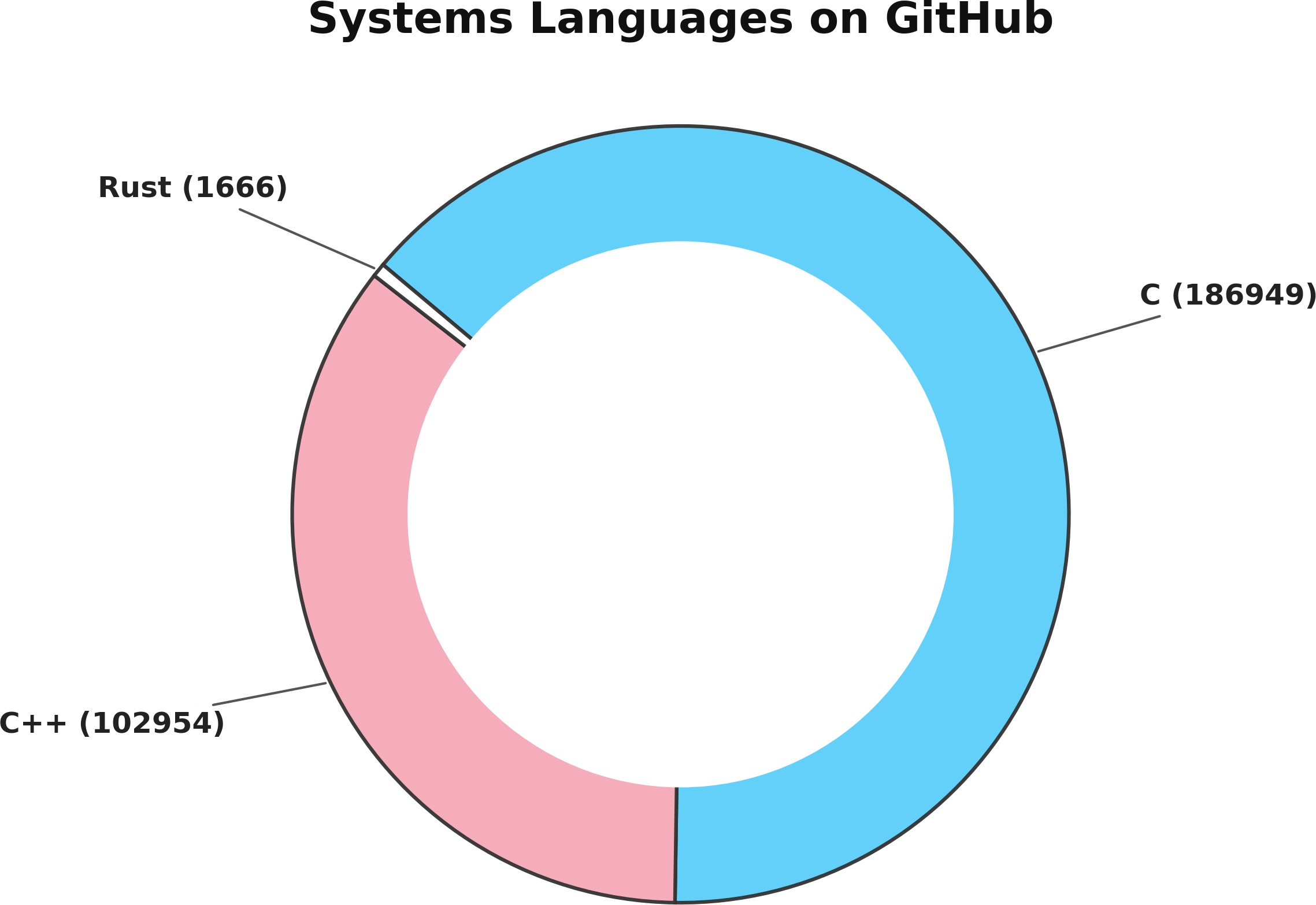
위 차트는 GitHut 공개 데이터셋에서 언어별 저장소 수를 대략 추정한 것이다. 하지만 꽤나 비논쟁적인 사실을 잘 반영한다. 세상에는 C 코드가 정말 미친 듯이 많다. 전부가 극도로 불안전하고, 전부가 언제든 악용될 수 있는 메모리 버그들로 들끓고 있다.
Rust가 미래로 가는 길을 닦고 있는 것은 맞지만, 우리가 떠안은 기술 부채는 산더미 같고, 제 발로 사라지지 않는다.
이제 오늘 포스트의 주제로 자연스럽게 넘어가 보자. 방금 말한 관찰에서 출발해, 프로그래밍 언어(PL) 연구 커뮤니티 안에서 이 문제를 해결해 보려는 관심이 커지고 있다. Rust가 그렇게 안전하다면, 우리의 불안전한 C 코드를 자동으로 가져다 안전한 Rust로 매핑하는 트랜스파일러2를 만들면 되지 않겠냐는 것이다.
실제로 이 주제에 관한 DARPA 연구 과제가 하나 통째로 있다. 바로 TRACTOR: translating all C to Rust다. 이 덕분에 이 변환을 둘러싼 연구가 하나의 작은 산업처럼 생겨났고, 심지어 회사까지 등장했다.
초기 작업들은 전적으로 기호적(symbolic)이었지만, 최근에는 LLM을 활용한 연구들이 점점 성과를 내고 있다. 위에 적은 것들은 구글 스칼라를 대충 검색해도 나오는 일부에 불과하고, 현직 PL 연구자로서 말하자면, 이런 원고를 내 책상 위에서 수도 없이 봤고, 어딘가에서는 이 순간에도 수십 편이 진행 중이라고 봐도 무방하다.
그러니, 전반적으로 미래는 밝아 보이지 않는가? 앞으로의 모든 코드는 버그 없는 메모리 안전 Rust로 쓰이고, 과거의 버기한 불안전 C 코드는 전부 자동으로 Rust로 갈아 써져서 인류가 구원될 것이다…
…라고 말하고 싶지만, 여기엔 아주 작은 문제가 있다. 바로 C를 Rust로 번역한다는 문제 자체가 근본적으로 잘못 설정된 문제라는 점이다. 이건 심지어 ‘틀렸다’고 말할 수준조차 못 된다.
이 글의 나머지 부분에서는, 왜 그런지에 대한 상위 수준의 개요와 우리가 할 수 있는 것들을 이야기해 보겠다.
먼저, C를 Rust로 번역하는 현재 최첨단 기법에 초점을 맞춰보자. 바로 대부분의 관련 연구의 토대가 된 Immunant의 C2Rust 도구다(온라인 데모도 있다).
C2Rust는 높은 수준에서 보면, C 프로그램을 받아서 문법적인 규칙을 이용해 일종의 Rust 형태로 다시 써 준다.
가령 다음과 같은 C 코드가 있다고 하자.
// C Code
int arr[10] = {0};
for(int i = 1; i < 10; i++) {
arr[i] = i + arr[i - 1];
}여기에 C2Rust를 적용하면, 다음과 같은 Rust 코드가 나오게 된다 —
// Rust code
let mut arr: [libc::c_int; 10] = [
0 as libc::c_int, 0, 0, 0, 0, 0, 0, 0, 0, 0
];
let mut i: libc::c_int = 1 as libc::c_int;
while i < 10 as libc::c_int {
arr[i as usize] = i + arr[(i - 1 as libc::c_int) as usize];
i += 1;
i;
}…음, 그다지 러스틱(욱)하진 않은 코드다. 그래도 이 경우만 놓고 보면, 결과 프로그램은 완전히 안전한(safe) Rust 코드이며, Rust가 보장하는 번개처럼 빠르고 안전한 메모리 보장을 누릴 수 있다. 더 이상 우리 코드에 쓰레기 같은 C는 없다!
이 방식이 무너지는 유일한 지점은, C 프로그램이 포인터를 사용하는 순간이다3.
void swap(int *a, int *b) {
int tmp = *a;
*a = *b;
*b = tmp;
}이런 프로그램에서는, 수명(lifetime)과 에일리어싱(aliasing) 정보가 없기 때문에, C2Rust는 레퍼런스를 사용하는 코드를 만들 수 없고, 대신 포인터와 unsafe Rust로 돌아갈 수밖에 없다.
#[no_mangle]
pub unsafe extern "C" fn swap(
mut a: *mut libc::c_int,
mut b: *mut libc::c_int
) {
let mut tmp: libc::c_int = *a;
*a = *b;
*b = tmp;
}이 컨텍스트가, 이 분야 대부분의 연구가 겨누고 있는 지점을 보여 준다. 즉, 포인터를 사용하는 C 프로그램에 대해 안전한 Rust를 자동으로 생성하도록 리팩터링할 수 있는가? 예를 들어, 포인터를 수명 기반 레퍼런스로 번역하는 식으로 말이다.
pub fn swap<'a,'b>(a: &'a mut c_int, b: &'b mut c_int) {
let mut tmp: c_int = *a;
*a = *b;
*b = tmp;
}이게 어려운 문제라는 것은 금방 드러난다. 이걸 더 잘하려고 별의별 접근법이 쏟아져 나오는 중이다.
C를 Rust로 번역하는 문제의 핵심에는 좀 더 근본적인 문제가 있다고 본다. 관용적인(idiomatic) C 코드는 관용적인 Rust 코드가 아니다. 사실 두 언어에서 ‘관용적인 코드’라고 불리는 것들은 서로 꽤 다르게 생겼다.
예를 들어, C에서 연결 리스트를 순회한다고 해 보자. 아마 이런 코드를 쓸 것이다.
struct list {
int vl;
struct list *next;
};
int sum(struct list *ls) {
int res = 0;
for(; ls; ls = ls->next) {
res = res + ls->vl;
}
return res
}깔끔하고 단순하다. 루프 증감식에서 약간 장난도 쳐 봤다.
이걸 C2Rust에 넣으면, 다음과 같은 멋진 결과를 얻는다.
#[derive(Copy, Clone)]
#[repr(C)]
pub struct list {
pub vl: libc::c_int,
pub next: *mut list,
}
#[no_mangle]
pub unsafe extern "C" fn sum(mut ls: *mut list) -> libc::c_int {
let mut res: libc::c_int = 0 as libc::c_int;
while !ls.is_null() {
res = res + (*ls).vl;
ls = (*ls).next;
}
return res;
}이 정도면 (적어도 이 예시에서는) 그렇게까지 지저분하진 않다. 하지만 unsafe 이고, 따라서 Rust가 제공하는 온갖 멋진 보장을 전혀 얻지 못한다. 이 코드는 우리가 시작했던 C 코드만큼이나 불안전하고 쓰레기 같다.
Rust 개발자가 이걸 처음부터 쓴다면, 관용적인 Rust 방식은 아예 명시적인 루프를 꺼내지 않을 것이고, 대신 (리스트 타입이 이를 지원한다고 가정하면) 이터레이터 인터페이스를 사용할 것이다.
pub fn sum(ls: &List) -> i32 {
ls.iter().sum()
}이게 사소해 보일지도 모르겠다. 생성된 코드가 전문가가 생각하는 플라토닉 이상형보다 좀 못생겼을 뿐인데, 그게 뭐 그리 큰 문제냐고 생각할 수 있다. 하지만 나는 그게 핵심을 완전히 놓치는 관점이라고 본다.
Rust가 메모리 버그를 줄이는 데 효과적인 이유는,
iter같은 고수준 추상화를 제공함으로써, 사용자가 타입 시스템을 이용해 안전성 보장을 유지할 수 있게 해 주기 때문이다.
C 코드를 Rust로 번역하고 싶다면, int를 libc::c_int로 치환하는 식의 단순한 찾기-바꾸기로는 턱없이 부족하다. 프로그래밍 패턴 자체(리스트를 순회한다는 행위)를 해당 언어 수준의 추상화(이터레이터 인터페이스 활용)로 옮기는 것이 필수적이다. 안타깝게도, 여기서 C→Rust 시도의 심장부에 있는 더 깊은 문제가 드러난다. 정확성(correctness)에 대한 개념 자체가 부재하다는 것이다.
가령, for 루프를 이터레이터 기반 루프로 번역하는 규칙을 만들었다고 해 보자. 그래서 다음과 같은 C 프로그램이
for(int i = 0; i < 10; i++) {
arr[i] = i;
}다음과 같은 관용적인 Rust 코드로 번역된다고 하자.
for i in 0 .. 10 {
arr[i] = i;
}괜찮아 보이지 않는가? 느낌상으로도 맞는 것 같지 않은가?
…그런데 왜 맞는가? 이 번역이 옳다고 정당화할 수 있는가? 둘은 근본적으로 다른 언어다. 동치성을 쉽게 실험적으로 확인할 방법이 없다. 두 코드 조각은 서로 다른 바이너리로 컴파일될 것이기 때문이다.
실제로, 이건 사소하지 않은 문제다. 이유는 두 가지다.
…잠깐. …다시 말하겠다. Rust에는 형식 의미론이 없다4. 이 번역이 옳다고 주장할 수 있는 수단이, 말 그대로 “감” 말고는 없다. 그리고 감(vibes)이야말로 주말에 대충 SaaS 똥앱을 짜는 데는 괜찮을지 몰라도, 대규모 코드베이스에 진지하게 돌릴 도구에 기대기엔 턱없이 부족하다.
다행히 Rustbelt 프로젝트처럼 의미론을 구축하기 위해 열심히 일하는 연구자들이 많고, 10년쯤 뒤에는 쓸 만한 결과물이 나올지도 모른다. 하지만 두 번째 문제가 해결된다고 해도, 우리는 여전히 첫 번째 문제에 맞닥뜨린다. 이런 리라이팅이 올바르다는 걸 입증하는 작업은, 본질적으로 섬세한 언어 간(inter-language) 논증에 의존하기 때문이다.
이게 의외라고 느껴질지도 모르겠다. 저 두 코드 조각을 사람 눈으로 보면, 직관적으로 같은 계산을 표현하는 것처럼 느껴진다.
그 직관을 조금만 파헤쳐 보면, 우리 뇌가 이 등가성을 성립시키기 위해 꽤 많은 일을 하고 있음을 깨닫게 된다. 두 프로그램의 의미론은 실제로는 꽤 다르기 때문이다.
C 프로그램에서는, 스택에 int를 하나 할당하고, 이 스택 주소에 저장된 값을 반복적으로 증가시키다가 10에 도달하면 루프를 빠져나온다.
int i;
loop:
i = i + 1
if(i > 10) goto end;
// body
goto loop;
end:Rust 프로그램에서는, 대신 std::Range<i32>를 만들고, 그 위에 Iter::into_iter()를 호출한 뒤, None이 나올 때까지 .next를 반복 호출한다.
let mut iter = (0..10).into_iter();
loop {
match iter.next() {
Some(i) => // body
None => break,
}
}이 경우 두 프로그램은 같은 계산을 수행하지만, C 프로그램은 본질적으로 꽤 다른 보장을 제공한다. 예를 들어, 반복의 인덱스가 그냥 스택 위의 또 다른 변수이고, 그 변수의 주소를 가질 수 있으며, 다른 변수와 똑같이 조작할 수 있다는 점이다.
이 차이는, 예를 들어 루프 본문이 이 사실에 의존하고 있을 경우 문제가 된다.
for(int i = 0; i < 10; i++) {
foo(&i); // i의 주소를 임의의 함수 foo에 넘긴다
}Rust 쪽 인터페이스는 이런 패턴을 애초에 허용하지 않는다. Rust에서 i라는 변수는 임시값일 뿐이고, 스택의 값을 바꿈으로써 갱신되는 것이 아니라 Iter 객체에서 뽑아 온 값으로 갱신된다.
위에서 든 예제에서는, 우연히도 이 번역이 유효했다. 루프 본문이 C가 제공하는 추가 보장에 의존하지 않았기 때문이다.
여기서 이 문제의 핵심이 드러난다.
C 프로그램은, 프로그래머 머릿속의 추상적인 계산을 코드로 표현하는데, 이 추상 계산은 코드에 명시된 의미보다 더 좁은 부분집합일 뿐이다. C의 의미를 전부 그대로 보존하려 하면, 필연적으로 unsafe Rust가 나온다. 왜냐하면 임의의 C 코드는 근본적으로 불안전하기 때문이다.
이 문제는 본질적으로 언더스펙(underspecified) 되어 있다. 여기에다, 우리는 여전히 우리가 하는 일을 정당화할 형식적 토대조차 없다는 사실이 이 문제를 한층 더 악화시킨다. 그래서 이 문제는 ‘틀렸다’고 부를 수준에도 미달한다.
여기까지가 C에서 Rust로 번역하는 작업의 현황이며, 왜 현재로선 이 방향에 근본적인 열린 문제가 있다고 보는지에 대한 대략적인 설명이다.
그래도 마지막은 조금 더 긍정적인 어조로 마무리하고 싶다. C에서 Rust로 번역하는 연구가 중요하다고 나는 믿는다. 그리고 지금까지 나온 작업들만으로도 유용한 성과가 꽤 있다. 이 맥락에서는 흥미로운 크고 작은 문제들이 많이 드러나고, 비록 전체 문제는 언더스펙 상태라 하더라도, 그 안에서 더 작고 다루기 쉬운 영역을 잘라내 보다 엄밀하게 논증하려는 작업들도 있다.
인류는 C의 죄로 얼룩져 있고, 세상 그 어떤 LLM도 우리가 한 나쁜 선택의 결과에서 우리를 마법처럼 구해내지 못할 것이다.
문법적으로는 여기서 보통 콜론을 쓰는 편이 내 취향이지만, LLM들이 이엠 대시(em dash)를 독점하려 드는 듯한 이 시대에, 나는 이 인간 표현 수단을 차가운 기계에게 순순히 내어줄 생각이 없다. 그래서 이렇게 쓴다…
믿기 어렵겠지만, PL 커뮤니티는 워낙 폐쇄적이고 드라마가 부족해서, 이 용어 하나만으로도 약간 논쟁거리가 된다. 일부 PL 연구자들은 ‘트랜스파일러’라는 말을 인정하기를 거부하고, 누군가 와서 그들의 삶에 기쁨을 가져다줄까 봐 매일같이 두려워하며 산다.
나는 시스템 프로그래머가 아니라서 잘 모르겠지만, 이런, 음… 뭐라 하더라, "poinhnt-ehrs" 같은 코드는 별로 흔치 않지 않을까? 정말 못생긴 프로그래밍 추상화다, 으엑.
좀 더 정확히 말하면, Oxide, KRust 같은 여러 경쟁 연구 제안들이 있다. 다만 현재 최첨단 연구들은 아직까지 실제 프로덕션 코드와는 거리가 먼, 단순화된 Rust 모델을 다루는 수준에 머물러 있다.