LLM이 보편화된 환경에서 DSL(도메인 특화 언어) 설계가 맞닥뜨린 기회비용 증가 문제를 짚고, LLM과 공존·협업할 수 있는 세 가지 언어 설계 방향을 제안한다.

증명 유지보수, 그리고 그 너머까지!
LLM 시대의 프로그래밍 언어 설계: 평범함으로의 회귀?
내게 프로그래밍 언어(PL) 연구에서 가장 흥미로운 부분은 언제나 프로그래밍 언어 설계였다.
특정 도메인에 맞춰 문법과 의미론을 세심하게 다듬어 언어를 만들면, PL 설계자는 최종 사용자를 위한 인터페이스를 제공할 수 있다. 이 인터페이스는 해당 분야 실무자들의 감각과 직관에 자연스럽게 맞물리며, 사용자가 문제의 “흥미로운” 부분에 집중해 더 크고 복잡한 문제를 다루게 해준다.
예를 들어, 비주얼 노벨 게임에서 사용자에게 대화창을 띄우기 위해 장황한 API 호출을 나열하는 대신:
# example code for a VN
character.draw("alice", character.LEFT, 0.1)
character.draw("bob", character.RIGHT, 0.1)
character.say("alice", "hello there!")
character.say("bob", "hi!")
character.state("alice", "sad")
character.say("alice", "did you hear the news?")
DSL은 디자이너가 대화가 “무엇이어야 하는지”라는 고수준 에 집중할 수 있게 해준다:
# example DSL for dialog
[ alice @ left in 0.1, bob @right in 0.1 ]
alice: hello there!
bob: hi!
alice[sad]: did you hear the news?...
도메인의 “상식 규칙”을 언어 자체에 인코딩함으로써, 잘못된 프로그램을 작성하는 일을 원천적으로 불가능하게 만들 수 있고, 인지 부담을 줄이며 버그와 취약점이 생길 표면적 영역을 최소화할 수 있다.
모든 도메인에 DSL 하나씩. 잘못된 것을 모두 제거하고 나면, 남는 것이 무엇이든—아무리 복잡하고, 난해하고, 꼬여 있더라도—그것은 반드시 옳을 수밖에 없다.
이것은 지난 수십 년간 재미있고, 흥미롭고, 영향력 있는 연구 흐름이었지만, 지금 시점에서 방 안의 “e-LLM-ephant(코끼리)”를 언급하지 않는다면 소홀할 것이다. 불과 몇 년 만에 LLM과 LLM이 생성한 코드는 소프트웨어 생태계 전반에 널리 스며들었고, 개발자들로 하여금 기계가 생성할 수 있는 것과 없는 것에 대한 선입견을 계속해서 재평가하게 만들고 있다. 특히 여기에는 우리가 이전에는 언어 설계로 해결하려 했던 문제들(보일러플레이트 제거, 관례/상식 포착 등)도 포함된다.
이 새 지형은 잠재력이 크고, LLM이 소프트웨어 개발에 어떻게 기여할 수 있는지 묻는 흥미로운 질문도 많다. 하지만 지켜보는 동안 한 가지 걱정스러운 경향도 보인다. LLM의 발전이 DSL 설계의 진전과 관심을 대체해버리는 것이다. 보일러플레이트를 모두 없애는 DSL을 굳이 만들 필요가 있을까? LLM이 필요한 코드를 무엇이든 생성해준다면 말이다.
LLM의 새 시대에 언어 설계는 미래가 있을까? 이 글의 목적은 이 새 영역에서 내가 생각해온 몇 가지 생각을 공유하고, 논의를 촉발하며, 언어 설계가 LLM의 발전과 공존·협업할 수 있는 잠재적 전진 경로를 개략적으로 제시하는 데 있다.
LLM의 도입이 언어 설계에 던지는 가장 큰 문제부터 시작해보자. 나는 그것을 이렇게 본다: 파이썬에서는 모든 게 더 쉽다.
조금 과장한 표현이지만, 내가 말하고 싶은 핵심은 이렇다. LLM은 학습 데이터에서 충분히 잘 대표되는 프로그래밍 언어에서 훨씬 높은 효율(성능)을 보인다는 사실이 지속적으로 확인되고 있다. 파이썬, 자바스크립트, 타입스크립트 같은 언어들이 대표적이다.
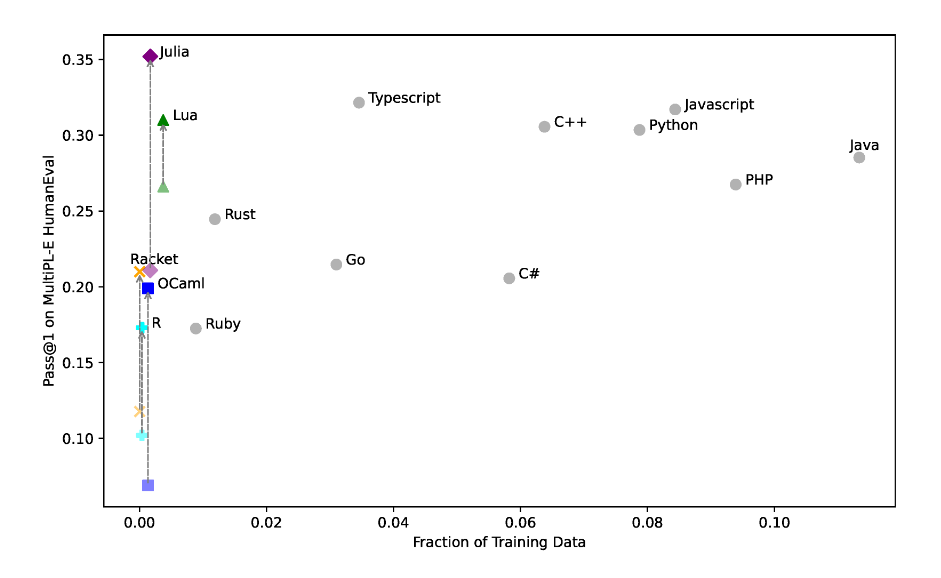 예를 들어, 위 그래프는 논문 "Knowledge Transfer from High-Resource to Low-Resource Programming Languages for Code LLMs" (2024)에서 가져온 것이다. 한 LLM 모델(StarCoderBase-15B)의 여러 언어에서의 프로그래밍 과제 해결 성능을, 해당 언어 파일이 학습 데이터에서 차지하는 비율과 비교해 보여준다.
예를 들어, 위 그래프는 논문 "Knowledge Transfer from High-Resource to Low-Resource Programming Languages for Code LLMs" (2024)에서 가져온 것이다. 한 LLM 모델(StarCoderBase-15B)의 여러 언어에서의 프로그래밍 과제 해결 성능을, 해당 언어 파일이 학습 데이터에서 차지하는 비율과 비교해 보여준다.
이 논문은 합성 데이터를 생성해 이러한 “저자원(low-resource)” 언어의 성능을 개선하는 기법을 제시한다. 따라서 그래프의 상승하는 선들은 이 데이터를 이용해 파인튜닝한 뒤의 개선을 나타낸다. 하지만 이런 변환은 더 작은 모델에만 적용되어 왔고, 오늘날 가장 활발히 쓰이는 프로덕션급 모델(ChatGPT, CoPilot, Gemini, Claude 등) 규모에서는 확실히 적용된 바가 없다.
원래 점들(파인튜닝 전)을 보면, 그래프는 암울한 그림을 그린다. 언어가 더 니치하고 특수해질수록 성능은 절벽처럼 떨어져 처참해진다. 그리고 기억해야 할 점은, 이 “저자원” 언어들조차도 자체적으로는 수백만 사용자를 가진 생산·산업용 시스템이라는 것이다. 다만 LLM이 잘할 만큼 충분한 코드가 생산되지 않았을 뿐이다.
일반 목적 언어들조차 이렇게 급격히 성능이 떨어진다면, 도메인 특화 언어에서 LLM을 돌렸을 때 무엇을 기대할 수 있을까?
갑자기 DSL의 기회비용이 두 배로 늘었다. LLM의 세계에서는 DSL이 언어와 툴링 자체를 만들고 설계하는 투자뿐 아니라, 최종 사용자들이 DSL 코드를 생성하는 데 LLM을 활용하는 능력을 포기해야 하는 비용까지 요구한다.
그래서 앞으로의 가장 큰 두려움으로 이어진다. DSL은 정체될까? 니치 언어를 쓰는 것이 LLM 사용을 사실상 배제한다면, 누가 DSL을 만들려고 할까? 아니면 DSL 설계의 진입장벽이 그냥 높아진 걸까? 이제 개발자는 DSL로 LLM 사용 능력을 잃는 것을 정당화할 만큼, 더 열심히 “가치 있는” DSL을 만들어야 하는 걸까?
자, 암울한 얘기는 여기까지 하고, 이 절에서는 조금 더 낙관적인 관점에서 언어 설계가 LLM과 협력하며 진화·적응할 수 있는 방식들을 생각해보려 한다.
현재로서는 미래에 대해 즉각 떠오르는 흥미로운 방향이 세 가지 있다. 더 있다면 꼭 듣고 싶다!
DSL에서 LLM을 쓰기 어려운 이유는, 본질적으로 DSL의 문법과 의미론이 일반 프로그래밍 언어와 크게 다르기 때문이다. 그래서 추가 맥락이 없으면 LLM이 DSL의 구성요소가 무엇을 의미하는지, 그리고 서로 어떻게 조합해 다양한 프로그래밍 과제를 달성하는지 이해하기가 어렵다…
그렇다면… 그 맥락을 주면 어떨까?
최근의 논문들, 예컨대 Verified Code Transpilation with LLMs (2024) 같은 연구에서 나는 한 가지 흐름을 보았다. 연구자들은 니치 언어(여기서는 논리 불변식)로의 표현식을 직접 생성하게 하기보다는, LLM에게 잘 알려진 언어(여기서는 파이썬)로 표현식을 생성하게 한 뒤, 관심 있는 난해한 언어로 수동 번역함으로써 성공을 거두었다.
해당 논문에서 저자들은 LLM을 이용해 텐서 처리 코드를 서로 다른 DSL로 자동 트랜스파일하고자 한다. 코드의 정확성을 보장하기 위해, 두 프로그램의 동치성을 증명하는 데 사용할 수 있는 불변식 생성도 LLM에게 요청한다:
# example invariant from the paper Verified Code Transpilation with LLMs
def invariant_outer(row, col, b, a, out):
return row >= 0 and row <= len(b) and
out == matrix_scalar_sub(255, matrix_add(b[:i], a[:i])
이 논문의 핵심 트릭은 파이썬을 중간 언어로 쓰는 것이다. 저자들은 먼저 LLM에게 제한된 파이썬 부분집합에서 코드를 생성하도록 한 뒤, 그 파이썬 표현식을 자신들이 선택한 DSL로 “끌어올리는(lift)” 프로그램을 작성한다. 이렇게 하면 비싼 파인튜닝 단계나 모델 재학습 없이도, LLM을 사실상 맞춤형 DSL 코드 생성에 활용할 수 있다.
이 아이디어를 일반화하고 언어 설계 전반의 문제로 넓혀보면, 내가 던지고 싶은 질문은 이렇다. 이런 번역을 자동으로 할 수 있을까? 예를 들어 DSL 설계 프레임워크를 만들되, 그 의미론을 LLM 친화적인 파이썬 기술로 함께 제공할 수 있을까? 그 파이썬 인코딩이 모델링하는 코드와 같은 동작을 하는지 테스트하는 프레임워크를 만들 수 있을까? DSL 자체의 구현으로부터 파이썬 기술을 자동 생성할 수 있을까?
문제를 다른 각도에서 보자면, DSL과 LLM의 교차점에서 흥미로운 또 다른 방향은 LLM 기반 코딩 워크플로우와 함께 작동하는 DSL 설계의 새로운 방식들을 탐구하는 것이다.
잠깐 내가 LLM을 내 작업에서 어떻게 쓰는지, 그리고 특정 종류의 코드—즉 스크립트—를 작성하는 방식이 어떻게 바뀌었는지 짧게 얘기해보겠다.
내 일상적인 프로그래밍 업무의 상당 부분은 여러 검증(verification) 시스템의 내부 구현을 다루는 것이다. 이런 시스템의 코드는 매우 복잡하고 정교해서, 나는 사실상 모든 줄을 직접 써야 한다. 이런 상황에서 LLM은 별 도움이 되지 않으며, LLM이 생성한 코드는 대개 시스템의 중요한 불변식을 유지하지 못하거나 적절한 API를 사용하지 못한다.
반면 스크립트는 자주 쓰지 않고, 보통 일회성이며, 이런 프로그램을 작성하는 방식은 LLM 사용으로 크게 바뀌었다.
다음은 최근 내가 기본적인 데이터 분석을 위한 파이썬 코드를 생성하려고 작성한 프롬프트의 예다:
afp-versions안의 모든thy파일을 순회하고, 파일의 텍스트 내용을 넘기면name,start_line,end_line,first_word컬럼을 가진 pandas df를 반환하는 함수split_file을 실행하는, 매우 병렬적인 스크립트를 작성해줘- 각 파일마다 version(우리가 있는
afp-versions바로 아래 하위 디렉터리 이름)과 project를 기록해줘. (thy파일들은 version 다음에thys라는 하위 디렉터리 아래에 있으니 project는 그 바로 아래의 하위 디렉터리 이름이야). (split_file이 반환한 df의 모든 행에 이 파라미터들을 추가해줘)- tqdm로 진행 상황을 보여주면서, 재시작 가능한 방식으로, 모든 파일을 반복적으로 하나의 데이터프레임으로 점진적으로 병합하고, 병렬성은 threadpool을 사용해줘
위 설명은 이 코드가 무엇을 하려는지 대부분을 설명하고 있고, LLM이 생성한 코드는 내가 원했던 일을 정확히 수행했다.
언어 설계 관점에서 흥미로운 점은, 이 스니펫이 “불완전한” 프로그램을 생성한다는 것이다. 특히 나는 LLM에게 split_file 함수를 생성하라고 하지 않고, 대신 나머지 작업과 관련해 그 입력과 출력이 무엇이어야 하는지 사양만 준다.
넓게 보면, 이런 허술한 일회성 스크립트에서 LLM과 상호작용할 때 나는 고수준 계획을 개략적으로 설명하고, LLM에게 접착(glue) 코드를 생성하게 한 뒤, 문제의 “흥미로운” 핵심 부분은 내가 직접 구현한다.
언어 설계 관점에서 이 경험을 통해 던지고 싶은 질문은, 이런 워크플로우를 DSL에 어떻게 통합할 수 있을까 하는 것이다. 즉, 형식(formal)과 비형식(informal) 사이의 간극을 어떻게 메울 수 있을까? 내가 수동으로 작성한 코드는 “형식”의 영역에 있고, 내 텍스트 프롬프트는 “비형식”의 영역에 있다. 그리고 이 스니펫에서는 형식에 대한 사양을 비형식 텍스트 구성요소로 인코딩함으로써 그 둘을 잇는다. 이것을 자동으로 할 수 있을까? 비형식 텍스트와 매끄럽게 통합되는 DSL을 만들 수 있을까? 예를 들어 DSL이 수행하는 타입/분석에 기반해 자연어 사양을 자동 생성할 수 있을까?
이 글에서 다룬 방향들 중 아마 가장 활발히 연구되고 있는 분야일 텐데, LLM의 등장 이후 언어 설계가 나아갈 또 다른 흥미로운 영역은 사양(specification) 언어의 설계다.
개략적으로 말해, LLM이 부상한 이후 연구자들은 Dafny나 Boogie 같은 검증 언어를 사용해 LLM이 생성한 코드의 출력을 검증할 수 있는지 탐구하는 데 뛰어들었다. 내가 이 방향에서 처음 본 논문은 "Towards AI-Assisted Synthesis of Verified Dafny Methods" (2024)였지만, 지금쯤은 훨씬 더 많은 논문이 나왔고, 더 많은 작업이 진행 중일 것이다.
// Example from Towards AI-Assisted Synthesis of Verified Dafny Methods
method FindSmallest(s: array<int>) returns (min: int)
requires s.Length > 0
ensures forall i :: 0 <= i < s.Length ==> min <= s[i]
ensures exists i :: 0 <= i < s.Length && min == s[i] {
...
}
복잡하고 정교하며 버그가 있을 수 있는 코드를 모델에게 그냥 생성하게 요청하는 대신, 저자들은 Dafny 같은 검증 언어로 사양을 포함한 프로그램을 생성하게 요청하자고 제안한다. 그러면 사용자는 프로그램이 무엇을 하는지 이해하기 위해 LLM 코드를 전부 이해할 필요 없이 사양만 보면 되고, 검증이 실패할 때만 코드를 들여다보면 된다.1
언어 설계 관점에서 이 도메인의 흥미로운 질문은 다음을 묻는 것이다. a) 이런 사양을 DSL에 어떻게 통합할까? b) 특정 도메인에서 관심 있는 속성을 포착하도록 검증 DSL을 더 잘 설계하려면 어떻게 해야 할까? 물론 대화 DSL에서 원하는 속성과 패킷 라우팅 DSL에서 원하는 속성은 꽤 다를 것이다. 언어 DSL의 구현으로부터 사양 언어를 자동으로 만들 수 있을까?
이 글을 마무리하며, 나는 LLM이 DSL 설계자들에게 흥미로운 문제를 던진다고 생각한다. 니치 언어를 사용하는 기회비용이 이제 크게 증가했고, 따라서 우리 언어 설계자들은 DSL 사용을 정당화하기 위해 더 높은 기준으로 평가받게 될 것이다. 동시에 LLM은 가능성의 공간을 급격히 바꿔놓았고, 앞으로 탐구할 흥미로운 문제들도 여러 개 열어주었다.
핵심 요지는 이렇다. 언어 설계와 DSL은 우리가 살고 있는 이 미친 새 세계에 맞춰 조정되어야 한다. 조심하지 않으면 언어 설계 분야가 정체되어, 재미있고 흥미로운 DSL의 다양성을 잃고, 결국 모두가 파이썬만 쓰게 될 현실적 가능성도 아주 크다…
물론 이런 프로그램을 검사(checking)하는 일 자체가 간단하지 않으며, 증명이 느리거나 취약해지는 등의 추가 문제를 야기할 수 있다. 다행히도 이것은 내가 마침 연구하고 있는 문제이기도 하다(여기).
 별도 표기가 없는 한 모든 콘텐츠는 Creative Commons Zero License v1.0에 따라 이용할 수 있다
별도 표기가 없는 한 모든 콘텐츠는 Creative Commons Zero License v1.0에 따라 이용할 수 있다