`Cow`를 `str`로 바꾸고 토큰과 상태 머신을 분리하면서 JSON 포매터 성능을 크게 끌어올린 과정을 다룹니다.
Cow를 없애자 내 JSON 포매터가 42% 더 빨라졌다Cow를 없애자 내 JSON 포매터가 42% 더 빨라졌다Em 대시: 12
2026년 5월 5일
포매터는 코드의 스타일을 일관되게 맞추며, 보통 사람이 읽기 쉽게 만들어 줍니다. 포매터, 토크나이저, 또는 추상 구문 트리에 익숙하지 않다면, 제 글 포매터는 어떻게 동작할까를 보세요.
JavaScript 생태계에는 공백이 하나 있습니다. 대부분의 포매터는 기능이 풍부하거나 혹은 빠릅니다. Prettier는 JavaScript 생태계의 표준이지만, 가장 빠르지는 않습니다. Oxfmt는 큰 진전을 이루었고, Prettier의 JavaScript 포매팅과 동등한 수준을 지원하면서도 성능을 크게 개선했습니다. 한 보고서에서는 Oxfmt로 마이그레이션한 뒤 저장소 포매팅 속도가 6.5배 빨라졌다고 합니다. 13.9초에서 2.1초로 줄었습니다.
하지만 이런 이점은 JSON에는 적용되지 않습니다. JSON에서는 Oxfmt가 Prettier보다 10–20% 느립니다. Oxfmt에는 네이티브 JavaScript 포매터가 있지만, 네이티브 구현이 없는 파일 형식은 합리적으로 Prettier에 위임합니다1. Oxfmt는 올해 네이티브 JSON 구현을 계획하고 있습니다!
Prettier와 Oxfmt는 둘 다 2MB JSON 파일을 포매팅하는 데 1초 이상 걸리지만, 제 포매터인 JJPWRGEM은 약 30밀리초가 걸립니다.
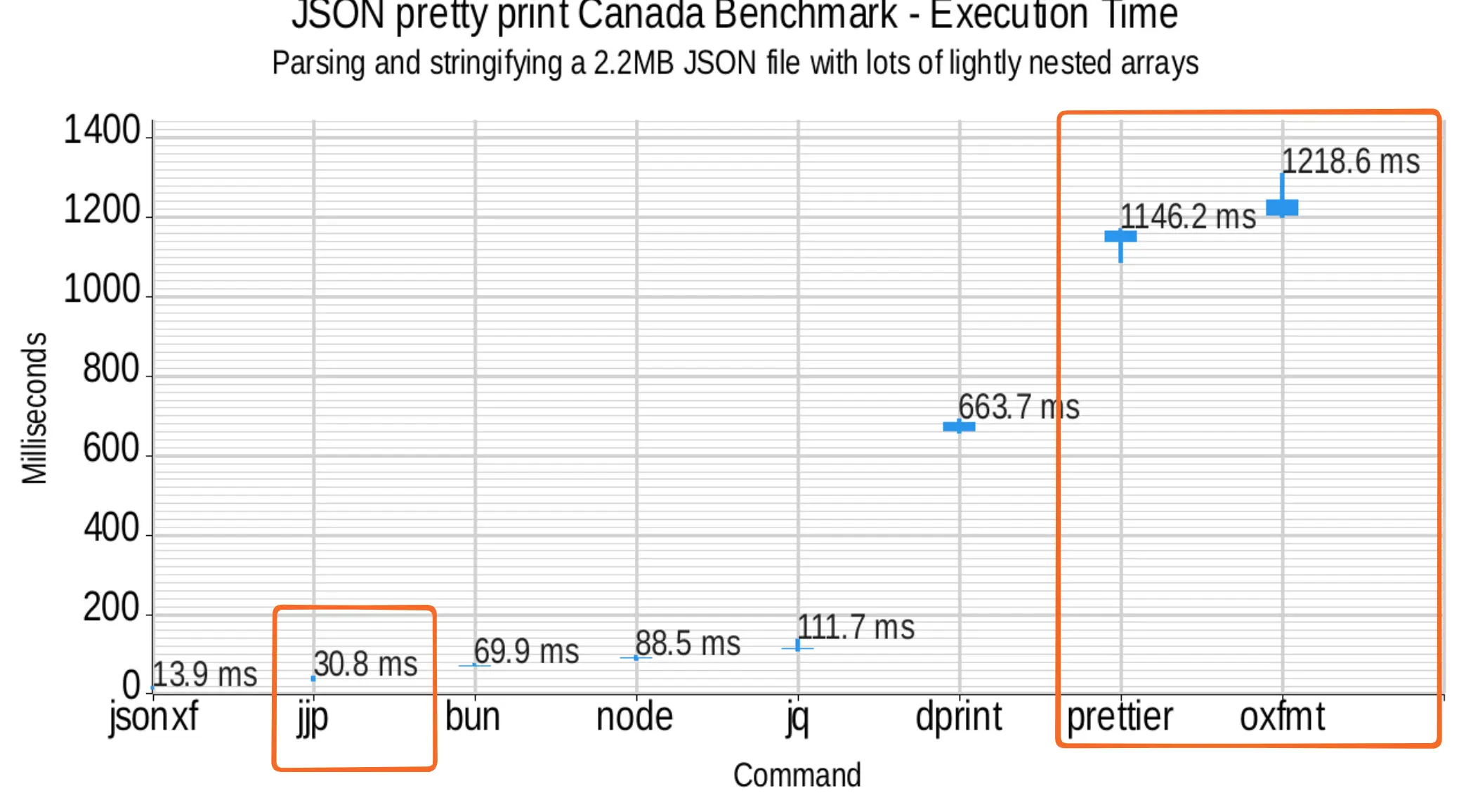
조밀한 부동소수점 벤치마크 - 실행 시간
가볍게 중첩된 배열이 많은 2.2MB JSON 파일을 파싱하고 문자열로 직렬화
표 형태 벤치마크 보기
Command Median Time jsonxf 14.0ms jjp 31.0ms bun 70.0ms node 89.0ms jq 112.0ms dprint 665.0ms prettier 1149.0ms oxfmt 1218.0ms
공정하게 말하자면, JJPWRGEM은 Prettier와 기능 동등성을 갖추지는 않았습니다. 하지만 만약 갖추게 된다면 어떨까요? 이미 훌륭한 기반을 갖추고 있고, 기능을 구현하면서도 성능 향상을 더 찾아낼 수 있다고 저는 확신합니다.
저는 범위가 잘 정해져 있고 영향도 큰 변화 하나로 시작했습니다. 숫자를 Prettier처럼 정규화하는 작업이었는데, 그 과정에서 포매터를 42% 더 빠르게 만들게 되었습니다. 이 수치가 어떻게 계산되었는지 궁금하다면 최종 벤치마크로 건너뛰세요.
간단하게 과학적 표기법과 관련된 정규화 3가지부터 시작해 봅시다. 이들은 서로 자연스럽게 이어집니다.
1E5에서 1e5로)+를 제거합니다 (1e+5에서 1e5로)1e0에서 1로)현재 JJPWRGEM은 숫자를 그대로 두고, 이를 하나의 Cow<str>로 표현합니다. Cow에 대해서는 필요한 맥락에서 더 설명하겠습니다.
저는 다양한 데이터 형태를 가진 여러 파일을 대상으로 벤치마크하고 있습니다. 샘플 몇 가지는 다음과 같습니다.
조밀한 부동소수점
{ "type": "FeatureCollection",
"features": [{
"type": "Feature",
"properties": { "name": "Canada" },
"geometry": {"type":"Polygon","coordinates":[
[[-65.613616999999977,43.420273000000009],
[-65.619720000000029,43.418052999999986],
[-65.625,43.421379000000059], ...]
]}
}]
}
많은 객체와 정수
{
"events": {
"138586341": {
"description": null,
"id": 138586341,
"name": "30th Anniversary Tour",
"subTopicIds": [337184269, 337184283],
"topicIds": [324846099, 107888604]
}
},
"areaNames": {
"205705993": "Arrière-scène central",
"205705994": "1er balcon central"
}
}
문자열과 깊은 중첩
{
"statuses": [{
"metadata": { "result_type": "recent", "iso_language_code": "ja" },
"created_at": "Sun Aug 31 00:29:15 +0000 2014",
"id": 505874924095815700,
"text": "@aym0566x \n\n名前:前田あゆみ\n第...",
...
}]
}
Deser는 추상 구문 트리로 역직렬화하는 것을 뜻합니다. 성능은 크기에 따른 차이를 피하기 위해 처리량으로 표현합니다. 1MB 파일은 3MB 파일보다 더 빨리 포매팅되겠지만, MB/s는 둘 다 비교할 수 있습니다!
| benchmark | baseline (MB/s) |
|---|---|
| deser/dense floats | 115.6 |
| deser/many objects and integers | 385.5 |
| deser/strings and deep nesting | 257.8 |
가장 단순한 접근은 형식이 올바르지 않은 숫자에 대해 새 문자열을 만드는 것입니다.
안타깝게도 각 숫자를 두 번 순회해야 합니다. 한 번은 범위를 찾기 위해, 또 한 번은 이를 검증하기 위해서입니다. 입력에 숫자가 하나도 없더라도 느린 힙 할당이 필요합니다.
입력 문자열의 조각들을 참조하는, 좀 더 복잡한 접근이 필요합니다.
Cow 2개각 숫자에서 중요한 부분은 2개뿐입니다. e 왼쪽의 가수와 오른쪽의 지수입니다. 이것이 과학적 표기법이라는 점을 알아보실 수도 있습니다. 1e5는 1 e 5를 나타냅니다.
1E+5가 있다고 해 봅시다. 그러면 1과 5를 저장해서 1e5로 다시 만들 수 있습니다. 지수가 있다면 e 또는 E는 소문자로 바뀝니다. 1e5와 1e+5는 동등하므로 +는 건너뛸 수 있습니다.
pub enum Token<'a> {
Number {
mantissa: Cow<'a, str>,
exponent: Cow<'a, str>
},
}
이 접근은 동작하긴 하지만, 전반적으로 성능을 떨어뜨립니다. Cow<str>에는 순수한 str에는 없는 오버헤드가 있어서, 숫자가 많지 않은 데이터셋에도 부정적인 영향을 줍니다.
| benchmark | baseline (MB/s) | this (MB/s) | delta |
|---|---|---|---|
| deser/dense floats | 115.6 | 101.1 | -12.5% |
| deser/many objects and integers | 385.5 | 289.3 | -25.0% |
| deser/strings and deep nesting | 257.8 | 214.8 | -16.7% |
Cow가 뭐죠?Cow는 Clone On Write의 약자입니다. 변경이 필요해질 때까지는 데이터를 참조하고, 변경이 필요해지면 복제합니다. 대부분의 값이 바뀌지 않을 때 이 방식이 유리합니다. 수정이 필요한 데이터만 복제되기 때문입니다.
to_lowercase 함수는 아주 좋은 사용 사례입니다. 입력이 이미 소문자라면 같은 문자열에 대한 참조를 그대로 돌려줄 수 있습니다! Rust 식으로 말하면, 데이터는 “borrowed” 상태입니다.
fn to_lowercase(string: &str) -> Cow<'_, str> {
if string.is_lowercase() {
// 입력 문자열을 참조
Cow::Borrowed(string)
} else {
// 새로운 문자열 만들기
Cow::Owned(string.to_lowercase())
}
}
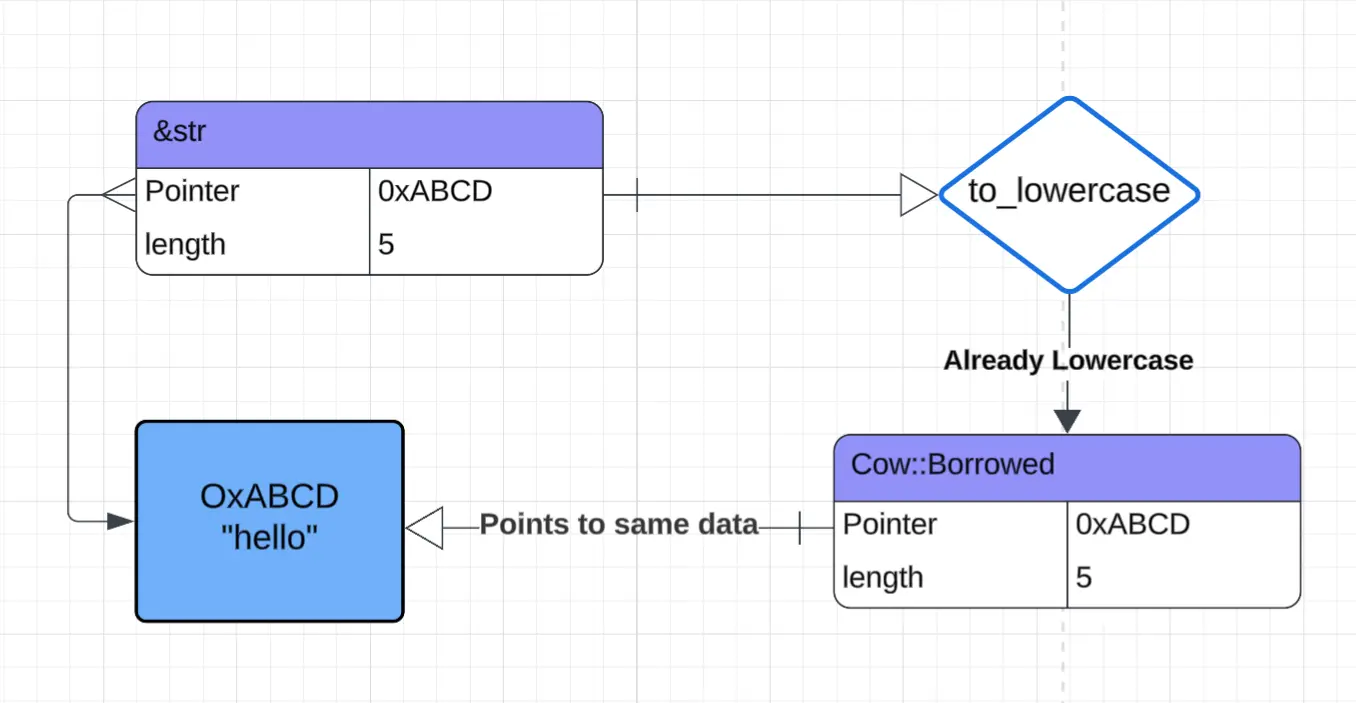
이미 소문자인
&str로to_lowercase를 호출하면 같은 메모리를 가리키는Cow::Borrowed가 반환되어 할당을 피하는 모습을 보여 주는 다이어그램
이제 대문자 입력을 상상해 봅시다. 참조 중인 문자열을 바꾸지 않기 위해 새 문자열이 만들어집니다. Cow는 새 데이터를 “소유”하며, 재할당 없이 할당된 용량을 갱신할 수 있지만, 스코프를 벗어날 때 그 데이터를 정리해야 합니다.
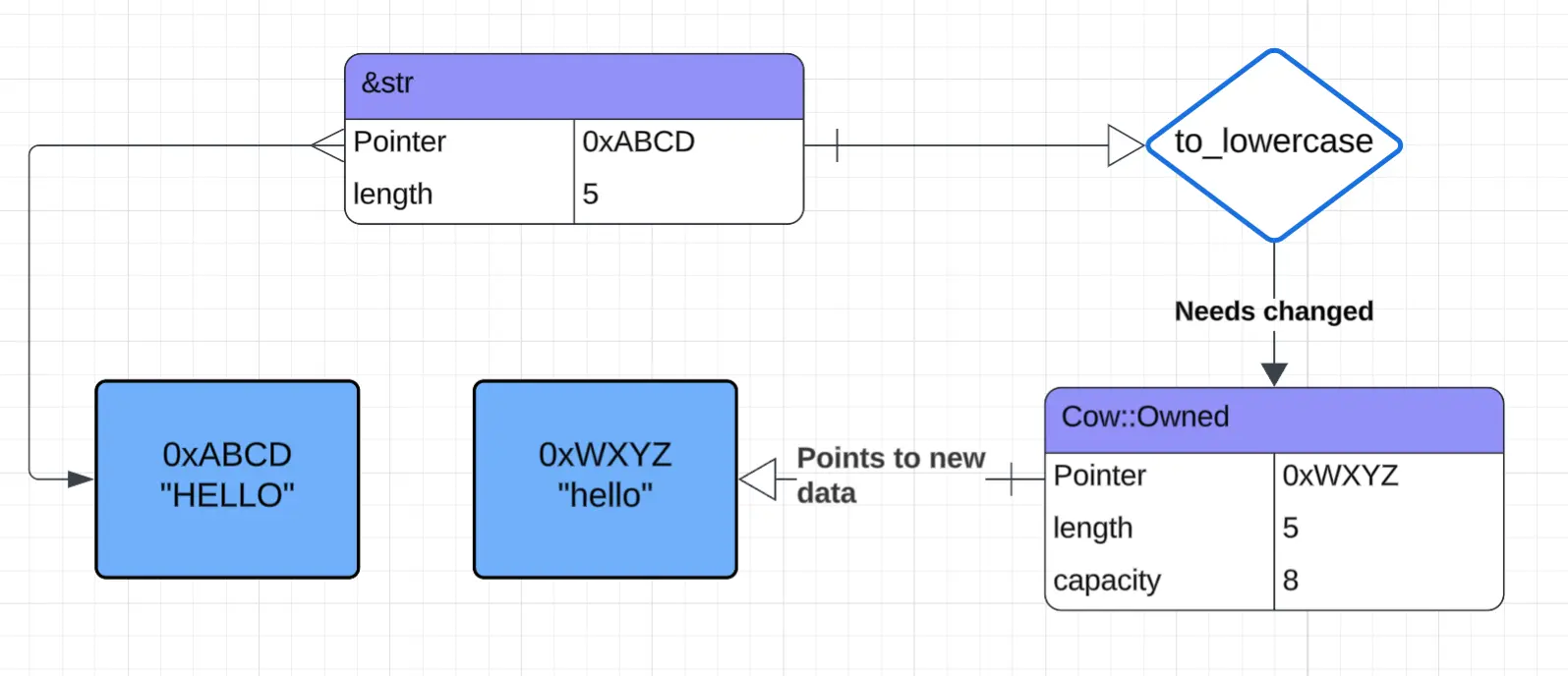
대문자인
&str로to_lowercase를 호출하면 새 할당을 가리키는Cow::Owned가 반환되는 모습을 보여 주는 다이어그램
Cow는 잠재적으로 자기 데이터를 정리할 책임이 있기 때문에, 스코프를 벗어날 때 작은 성능 페널티를 치릅니다. 결국 이 때문에 프로그램 명령의 20%가 쓸모없어집니다! Cow의 유연성은 전혀 사용되지 않았습니다.
더 나쁜 점은, 모든 Token이 Number일 수도 있기 때문에, 데이터가 전혀 없는 OpenCurlyBrace 같은 토큰에서도 정리 확인이 실행된다는 것입니다.
이제 Cow들을 없애 봅시다!
Cow<str> 대신 &str 사용하기pub enum Token<'a> {
Number {
mantissa: &'a str,
exponent: &'a str
},
}
컴파일러는 그 모든 정리 명령과 분기를 제거할 수 있게 되고, 이것은 모든 데이터셋에서 큰 이점입니다.
하지만 “조밀한 부동소수점” 데이터셋은 기준선 아래에 있습니다. 지수가 전혀 없는데도, 끝내 나타나지 않을 지수를 확인하는 비용을 치르기 때문입니다. 그 비용을 피하기 위해 토큰을 2개로 나누는 방법을 시도해 봅시다.
| benchmark | baseline (MB/s) | this (MB/s) | delta |
|---|---|---|---|
| deser/dense floats | 115.6 | 111.0 | -3.9% |
| deser/many objects and integers | 385.6 | 442.9 | +14.9% |
| deser/strings and deep nesting | 258.7 | 341.4 | +32.0% |
Mantissa와 Exponent 변형 분리하기전체 숫자를 담는 변형 하나 대신, 이를 2개로 나누겠습니다. 그러면 CPU가 한 번에 토큰 2개를 읽을 수 있어 명령 하나를 절약할 수 있습니다.
pub enum Token<'a> {
Mantissa(&'a str),
Exponent(&'a str),
}
CPU는 메모리를 덩어리 단위로 읽습니다. 문장 전체 대신 한 번에 단어 하나를 읽는 것과 비슷합니다.
집중한 CPU가 JSON Token을 한 번에 하나씩 생각하며 읽는 모습
CPU는 처리하기 위해 한 번에 64바이트의 RAM을 캐시에 가져오므로, 토큰당 &str 2개나 Cow<str> 2개를 가지면 한 번에 Token 하나만 읽을 수 있습니다.
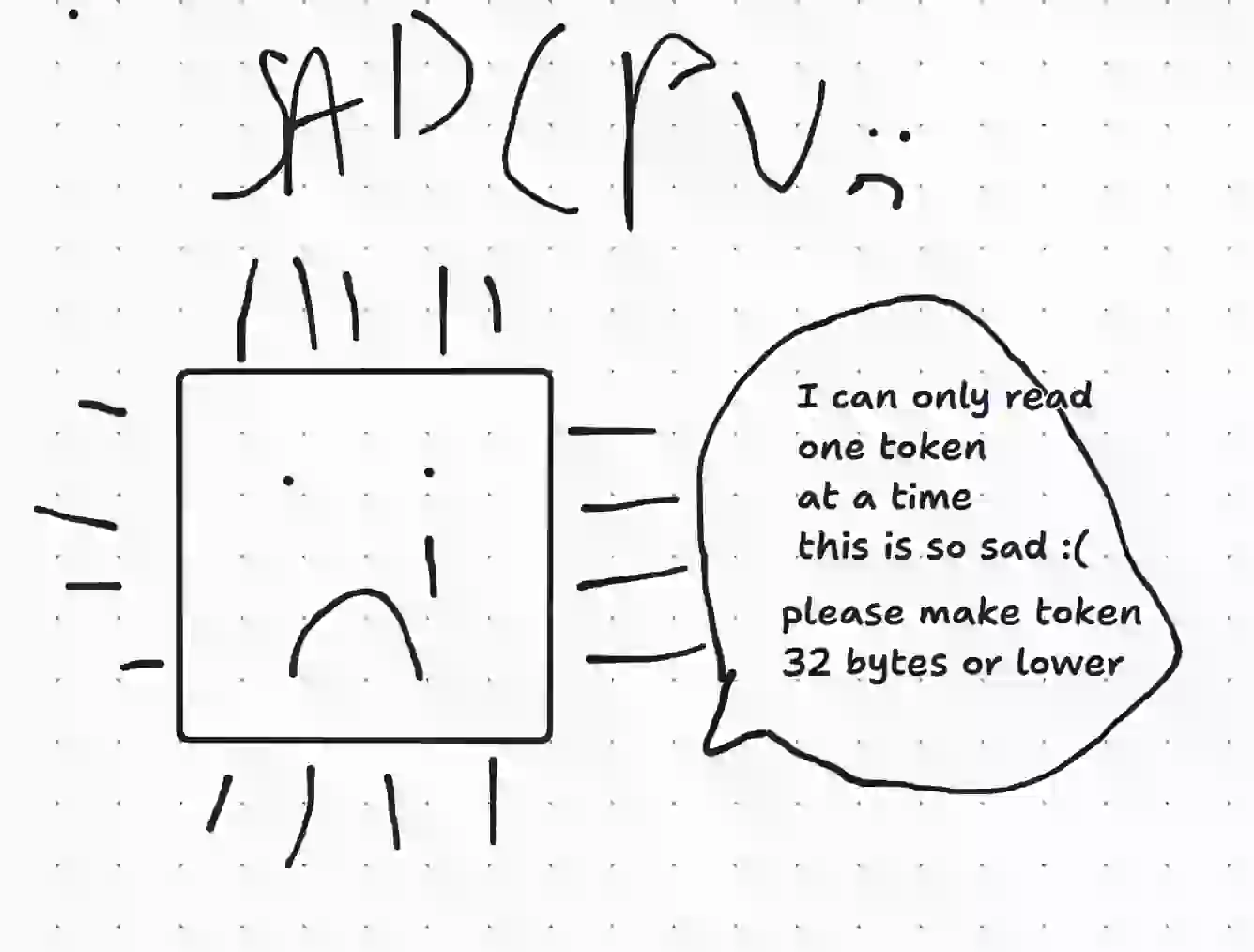
슬픈 CPU가 “토큰이 32바이트 이하가 되어서 한 번에 2개 읽을 수 있게 해 주세요. 지금은 토큰을 한 번에 하나만 읽을 수 있어서 너무 슬퍼요”라고 말하는 모습
&str 하나 또는 Cow<str> 하나를 담는 변형은 둘 다 24바이트이므로, 2개가 한 번의 읽기에 들어갑니다.

행복한 CPU가 “토큰이 24바이트라서 한 번에 토큰 두 개를 읽을 수 있어요. 정말 감사합니다. 더 높은 처리량을 즐기세요”라고 말하는 모습
이제 “조밀한 부동소수점” 역직렬화는 기준선보다 좋아졌지만, “많은 객체와 정수”는 숫자 파싱 오버헤드가 더 커져 이전 반복보다 퇴보했습니다.
| benchmark | prev (MB/s) | this (MB/s) | delta |
|---|---|---|---|
| deser/dense floats | 111.0 | 122.6 | +10.5% |
| deser/many objects and integers | 442.9 | 401.7 | -9.3% |
| deser/strings and deep nesting | 341.4 | 356.8 | +4.5% |
가수와 지수를 모두 파싱하도록 하면서 숫자 상태 머신의 크기가 88바이트까지 불어났습니다. 더 큰 토큰과 마찬가지로, CPU는 상태가 바뀔 때마다 두 번 읽어야 합니다.
상태 머신은 순서대로 따라가는 체크리스트와 비슷합니다. 숫자의 시작과 끝을 찾기 위해 우리는 이런 체크리스트를 따를 수 있습니다.
.처음에는 전체 숫자 상태 머신을 두는 것이 말이 되었지만, 이제는 그 숫자의 서로 다른 2개 조각에 관심이 있습니다.
분리하면 CPU가 전체 상태를 한 번의 읽기로 가져올 수 있을 뿐 아니라, 컴파일러도 고려해야 할 경우의 수가 줄어들어 더 잘 최적화할 수 있습니다.
enum MantissaState { ... }
enum ExponentState {
MinusOrPlusOrDigit,
AfterSign,
Digits,
Zero,
End
}
이제 “많은 객체와 정수” 데이터셋은 기준선보다도 더 빨라졌습니다!
안타깝게도 “조밀한 부동소수점”은 다시 약간 기준선 아래로 내려갔지만, 일반적인 JSON에는 더 다양한 데이터가 섞여 있으므로 받아들일 만한 절충입니다.
| benchmark | prev (MB/s) | this (MB/s) | delta |
|---|---|---|---|
| deser/dense floats | 122.6 | 111.3 | -9.2% |
| deser/many objects and integers | 401.7 | 456.9 | +13.7% |
| deser/strings and deep nesting | 356.8 | 385.1 | +7.9% |
Cow에서 str로 바꾸고 Number 토큰과 상태 머신을 분리한 것은 모두 성능 향상에 도움이 됩니다.
제목의 “42%” 향상은 문자열과 깊은 중첩 데이터셋의 역직렬화 + 예쁘게 포매팅 단계를 가리킵니다. 느린 단계가 빠른 단계를 끌어내리므로, 둘의 시간을 더한 뒤 다시 MB/s로 환산합니다.
throughput combined=throughput deser1+throughput prettify11 기준선의 경우
257.8 1+2091.1 11≈229.5 MB/s 새 구현의 경우
385.1 1+2105.0 11≈325.5 MB/s 그 결과 약 42%의 향상이 나왔습니다.
229.5 325.5−229.5≈0.418≈41.8%.
문자열을 AST로 변환하는 벤치마크입니다.
“조밀한 부동소수점”은 숫자마다 추가된, 사용되지 않는 토큰의 비용을 치르지만, “많은 객체와 정수”와 “문자열과 깊은 중첩”은 Cow를 str로 바꾼 덕분에 큰 향상을 보입니다.
| baseline (MB/s) | new (MB/s) | delta | |
|---|---|---|---|
| dense floats | 115.6 | 111.3 | -3.7% |
| many objects and integers | 385.5 | 456.9 | +18.5% |
| strings and deep nesting | 257.8 | 385.1 | +49.4% |
AST를 사람이 읽기 쉬운 문자열로 직렬화하는 벤치마크입니다.
“조밀한 부동소수점”은 출력할 지수가 있는지 확인하는 분기를 각 Number마다 수행해야 해서 가장 큰 손해를 봤습니다. 다른 데이터셋은 거의 평평합니다.
| baseline (MB/s) | new (MB/s) | delta | |
|---|---|---|---|
| dense floats | 1424.7 | 1332.0 | -6.5% |
| many objects and integers | 1853.2 | 1845.3 | -0.4% |
| strings and deep nesting | 2091.1 | 2105.0 | +0.7% |
문자열을 토큰으로 변환한 뒤 압축된 문자열로 직렬화합니다.
전반적으로 큰 향상이 있습니다. 구문 트리를 만들지 않기 때문에, AST를 문자열로 바꾸는 경로에서처럼 포매팅 관련 분기로 인한 직렬화 비용을 피할 수 있습니다.
| baseline (MB/s) | new (MB/s) | delta | |
|---|---|---|---|
| dense floats | 198.9 | 251.2 | +26.3% |
| many objects and integers | 449.8 | 630.4 | +40.2% |
| strings and deep nesting | 269.9 | 418.2 | +54.9% |
이 벤치마크들은 포매터가 빠르면서도 기능이 풍부할 수 있음을 보여 줍니다. 저는 더 많은 작업을 했고, 대부분의 범주에서 성능을 개선했습니다. 다음 Prettier 기능을 구현할 때 다시 찾아뵙겠습니다!
제 RSS 피드를 구독해 주세요. 그렇지 않으면 여러분의 프로그램이 CPU를 우울하게 만들지도 모릅니다.
축전기가 CPU에게 상담을 해 주고 있습니다. 축전기는 “요즘 cache miss 때문에 많이 힘드셨다고 들었어요…”라고 말합니다.
CPU는 소파에 누워 있고, 축전기는 안경을 쓰고 클립보드를 들고 있습니다.
←PreviousReally Cool Blogger Web RingNext→ © 2026 Jacob Asper. © 2020 VSCode Orange Theme Rax Team. All rights reserved.